Embed Size (px)
Citation preview

1
Lect 17: RISCs

Maeng Lect 17-2
Reduced Instruction Set Computer Architectures
Introduction To provide performance for programs written in HLLs: simpler implementation without the us
e of microcode IBM in 1975 : minicomputer known as the 801 (ECL) Berkeley in 1980 : VLSI processors RISC I, RISC II Stanford in 1981 : MIPS chip
The Effectiveness of a Computer Architecture How well it can be used to carry out an application and the performance attainable by impleme
ntations of that architecture in various technology The performance of an implementation running a particular benchmark
nInstructiocycles timecycle nsInstructio of No
1
ePerformanc

Maeng Lect 17-3
The implications on architecture and machine organization that arise from the technology To make up for the limited speed of a technology parallel implementations The complexity of the circuits that can be implemented in hardware limits what can be done.
“no architectural feature is free” In VLSI, chip boundaries become a major design influence in two different ways.
• a hard limit on the bandwidth onto and off the chip
• a substantial disparity between on-chip and off-chip communication delays
CISC to decrease the number of instructions needed,
but increase the cycles per instruction,
and often increase the cycle time as well
RISC attempt to significantly decrease the average execution time per instruction shifts complexity from HW and program runtime to SW and program compile time

Maeng Lect 17-4
CISC Approach
Microprogramming
• A small control memory and an elegant way of building the processor control unit for a large instruction set
• The small control memory were usually 10 times faster than core
CISC Approach Reduce the semantic gap, Richer instruction set
• Richer instruction sets would simplify compilers
– As the story was told, compilers were very hard to build
• Richer instruction sets would alleviate the software crisis
– At a time when software costs were rising as fast as HW costs were dropping.
– SW function HW function
– Reduce the semantic gap
• Richer Instruction sets would improve architecture quality
– After IBM differentiated architecture from implementation
– To measure the quality of an architecture: not execution speed, program size, the number of bits of instructions, and bits of data fetched from memory during program execution

Maeng Lect 17-5
Some of the Key Characteristics of the RISC architectures
• Single cycle execution time
• Functionality : migrated to SW
• Load/Store Architecture(Register-Register)
• Simple Instruction Format (Few addressing mode, fixed format)
• Hardwired Control
A level of runtime translation is eliminated Little overhead per instruction Instruction decoding is faster Execution is fast Simple instructions are a better match for a compiler Hardware resources can be devoted to other uses A simple design should require less design time
More instructions, both statically and dynamically, will require higher instruction memory bandwidth (static : 40~50%, dynamic: 10~30%)

Maeng Lect 17-6
Examples of RISC Architectures
IBM 801 delayed branch Berkeley RISC delayed branch register windows MIPS delayed branch compiler technique
• Delayed Branch Pipelined machine
• branch : not known till the branch completes execution
• 30%-50% of the machine performance RISC I Pipeline
Fetch I1 Exec I1
Fetch I2 Exec I2
Fetch I3 Exec I3 Normal branch Delayed branch With branch slot scheduling
or r1, r2 or r1, r2 branch 1005
branch 1005 branch 1005 or r1, r2
sub r3, r5 no-op sub r3, r5
sub r7, r6 sub r3, r5 sub r7, r6
..... ..... .....
delayed branch

Maeng Lect 17-7
Berkeley RISC microprocessor
RISC I, RISC II : register windows 31 instructions and a 32-bit data path ALU - only integer operations: add, sub, shift,... but not multiply and divide only one addressing mode
• Register Windows RISC II register windows Total 138 registers with 8 frames of 16 registers and 10 global registers
r9
r0
r9
r0
r9
r0
r15r10
r31r26r25r16
r15r10
r31r26r25r16
r15r10
r31r26r25r16

Maeng Lect 17-8
CASE STUDY: SPARC Version 9
SPARC (Scalable Processor ARChitecutre) Architecture : 1987
• SPARC International : a consortium of computer makers SPARC-V9 for the 90s and Beyond
• enhancing SPARC-V8 to provide explicit support for
– 64-bit virtual addresses and 64-bit integer data
– Improved system performance
– Superscalar implementations
– Advanced operation systems
– Fault tolerance
– Extremely fast trap handling and context switching
– Big- and little-endian byte orders
• Be able to execute programs compiled for 32-bit SPARC-V8 processors
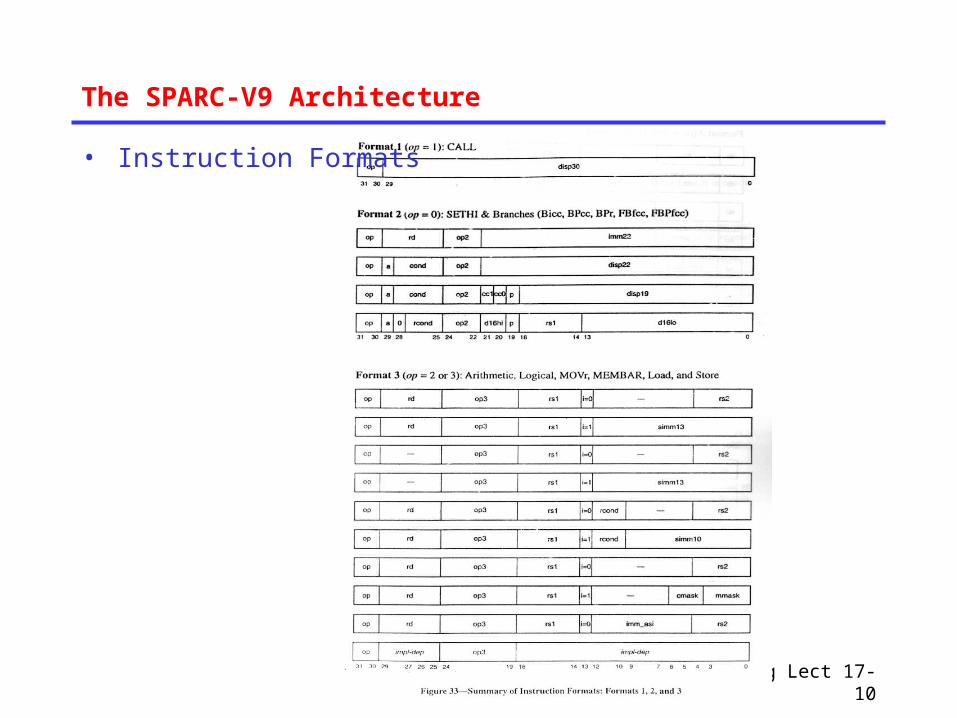
The SPARC-V9 Architecture A linear address space with 64-bit addressing Few and simple instruction formats:
• All instructions are 32 bits wide
• Only load and store instructions

Maeng Lect 17-9
The SPARC-V9 Architecture
Few addressing modes
• Memory address : “reg+reg” or “reg+immediate” Triadic register addresses A large windowed register file
• At any one instance, 8 global registers plus a 24-register window Floating-point
• IEEE 754 : 32 SP(32-bit), 32 DP(64-bit), 16 QP(128-bit), or a mixture thereof Fast trap handlers Multiprocessor synchronization instructions Predicted branches
• The branch with prediction instructions to give the HW a hint Branch elimination instructions
• Several instructions can be used to eliminate branches altogether(e.g., move on condition) Hardware trap stack Relaxed memory order (RMO) model
Maeng Lect 17-10
The SPARC-V9 Architecture
• Instruction Formats

Maeng Lect 17-11
The SPARC-V9 Architecture

Maeng Lect 17-12
The SPARC-V9 Architecture Overview
SPARC-V9 Processor Integer Unit(IU)
• General purpose registers
– 8 globals (or the 8 alternate globals) and a register window
– 2-register window : 8 in, 8 out, 8 local
• Controls the overall operations of the processor
• Address Space Identifier (ASI): 8 bits Floating Point Unit (FPU)
• Floating-point registers
– 32 32-bit SP, 32 64-bit DP, 16 128-bit QP
• IEEE 754
Data Formats Data types
• Signed Integer: 8, 16, 32, and 64 bits
• Unsigned Integer: 8, 16, 32, and 64 bits
• Floating Point: 32, 64, and 128 bits

Maeng Lect 17-13
The SPARC-V9 Architecture Overview
Registers Privileged Registers and Nonprivileged Registers
• General Purpose r Registers 8 globals or 8 alternate globals An implementation-dependent number of 16-register sets A window
• 8 in, 8 local, and 8 out registers
g0
g7
o0
o7
i7
i0
l7
l0
r15
r8
r7
r0
r31
r24
r23
r16
Maeng Lect 17-14
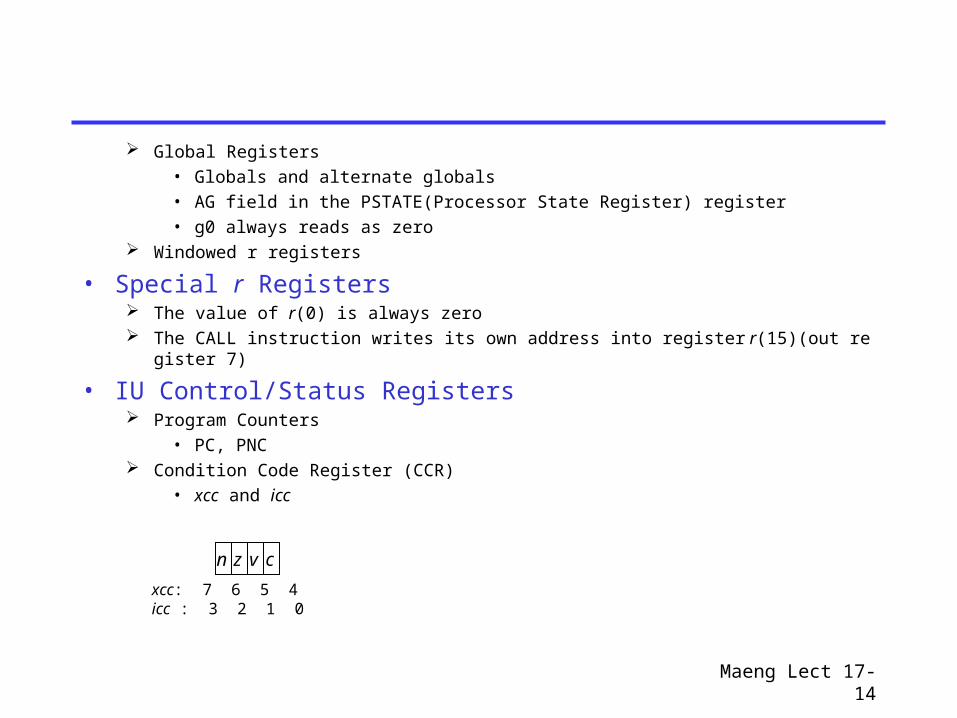
Global Registers
• Globals and alternate globals
• AG field in the PSTATE(Processor State Register) register
• g0 always reads as zero Windowed r registers
• Special r Registers The value of r(0) is always zero The CALL instruction writes its own address into register r(15)(out register 7)
• IU Control/Status Registers Program Counters
• PC, PNC Condition Code Register (CCR)
• xcc and icc
n z cv
xcc: 7 6 5 4icc : 3 2 1 0

Maeng Lect 17-15
Registers

Maeng Lect 17-16
• Address Space Identifier Register(ASI)
ASI
7 0

Maeng Lect 17-17
The SPARC-V9 Architecture
• Instruction Categories Memory access Memory synchronization Integer arithmetic Control transfer(CTI) Conditional moves Register window management State register access Privileged register access Floating-point operation Implementation-dependent Reserved
• Memory Access Instructions Load, Store, Prefetch, Load Store Unsigned Byte, and Compare and Swap
• 64-bit address : two r registers or an r register and simm13
• Compare and Swap: a single r register
• Prefetch : at least 64 bytes

Maeng Lect 17-18
Instruction Categories
• Memory Synchronization Instructions MEMBAR : memory barrier
• Allows programs to manage the order and completion of memory references
• Integer Arithmetic Instructions Triadic-register-address Setting condition codes
• Two versions; one sets the integer condition codes as a side effect; the other does not affect the condition codes
• Control Transfer Instructions Conditional Branches
• Branch on integer condition codes with prediction
• Branch on integer condition codes
• Branch on contents of integer register with prediction
• Annul bit Unconditional Branches CALL and JMPL

Maeng Lect 17-19
Instruction Categories
• Conditional Move Instructions MOVcc and FMOVcc
• Move if a condition is satisfied
• if (A>B) X=1; else X=0;
cmp i0, i2 ; A > B
or g0, 0, i3 ; set X =0
movg xcc, 1, i3 ; overwrite X with 1 if A>B MOVr and FMOVr
• mov on contents of integer or floating point register
• NZ, Z, GEZ, LZ, LEZ, GZ
• Register Window Management Instructions SAVE, RESTORE
• Implementation-Dependent Instructions
10 impl-depimpl-dep op3
31 30 29 25 181924 0
11 011011 0111
IMPDEP1IMPDEP2