Embed Size (px)
Citation preview

1
How Charm works its magic
Laxmikant Kale
http://charm.cs.uiuc.eduParallel Programming Laboratory
Dept. of Computer Science
University of Illinois at Urbana Champaign

2
Parallel Programming Environment• Charm++ and AMPI
– Embody the idea of processor virtualization
• Processor Virtualization– Divide the computation into a large number of pieces
• Independent of number of processors• Typically larger than number of processors
– Let the system map objects to processors
User View
System implementation

3
Charm++ and AMPI
• Charm++– Parallel C++
– “Arrays” of Objects
– Automatic load balancing
– Prioritization
– Mature System
– Available on all parallel machines we know
• Several applications:– Mol. Dynamics
– QM/MM
– Cosmology
– Materials/processes
– Operations Research
• AMPI = MPI + virtualization – A migration path for MPI codes
– Automatic dynamic load balancing for MPI applications
– Uses Charm++ object arrays and migratable threads
– Bindings for C, C++, Fortran90
• Porting MPI applications– Minimal modifications needed
– Automated via AMPizer
• AMPI progress– Ease of use: automatic packing
– Asynchronous communication
• Split-phase interfaces

4
Charm++
• Parallel C++ with Data Driven Objects• Object Arrays/ Object Collections• Object Groups:
– Global object with a “representative” on each PE
• Asynchronous method invocation• Prioritized scheduling• Mature, robust, portable• http://charm.cs.uiuc.edu

5
AMPI:
7 MPI processes

6
AMPI:
Real Processors
7 MPI “processes”
Implemented as virtual processors (user-level migratable threads)

7
Benefits of Virtualization
• Software Engineering– Number of virtual processors can be
independently controlled– Separate VPs for different modules
• Message Driven Execution– Adaptive overlap of communication– Modularity– Predictability:
• Automatic Out-of-core– Asynchronous reductions
• Dynamic mapping– Heterogeneous clusters:
• Vacate, adjust to speed, share– Automatic checkpointing– Change the set of processors used
• Principle of Persistence– Enables Runtime
Optimizations
– Automatic Dynamic Load Balancing
– Communication Optimizations
– Other Runtime Optimizations
More: http://charm.cs.uiuc.edu
We will illustrate:
-- An application breakthrough
-- Cluster Performance Optimization
-- A Communication Optimization

8
Technology Demonstration
• Recent breakthrough in Molecular Dynamics performance– NAMD, implemented using Charm++– Demonstrates power of techniques, applicable to CSAR
• Collection of charged atoms, with bonds– Thousands of atoms (10,000 - 500,000)– 1 femtosecond time-step, millions needed!
• At each time-step– Bond forces– Non-bonded: electrostatic and van der Waal’s
• Short-distance: every timestep• Long-distance: every 4 timesteps using PME (3D FFT)• Multiple Time Stepping
– Calculate velocities and advance positionsCollaboration with K. Schulten, R. Skeel, and coworkers

9
700 VPs
192 + 144 VPs
30,000 VPs
Virtualized Approach to Parallelization using Charm++
These 30,000+ Virtual Processors (VPs) are mapped to real processors by Charm runtime system

10
Asynchronous reductions, and message-driven execution in Charm allow applications to tolerate random variations

11
Performance: NAMD on Lemieux
0
500
1000
1500
2000
0 500 1000 1500 2000 2500
Cutoff
PME
MTS
ATPase: 320,000+ atoms including water
To be Published in SC2002: Gordon Bell
Award Finalist
15.6 ms,
0.8 TF

12
Component Frameworks
Motivation• Reduce tedium of parallel
programming for commonly used paradigms & parallel data structures
• Encapsulate parallel data structures and algorithms
• Provide easy to use interface, – Sequential programming
style preserved• Use adaptive load balancing
framework• Used to build parallel
components
Frameworks• Unstructured Grids
– Generalized ghost regions– Used in
• RocFrac version,• RocFlu• Outside CSAR
– Fast Collision Detection
• Multiblock Framework– Structured Grids– Automates communication
• AMR– Common for both above
• Particles– Multiphase flows– MD, Tree codes

13
Component Frameworks
Objective:• For commonly used
structures, application scientists– Shouldn’t have to deal
with parallel implementation issues
– Should be able to reuse code
Components and Challenges• Unstructured meshes:
Unmesh– Dynamic refinement support
for FEM– Solver interfaces– Multigrid support
• Structured meshes: Mblock– Multigrid support– Study applications
• Particles• Adaptive mesh refinement:
– Shrinking and growing trees– Applicable to the three
above

14
Charm/AMPI
MPI/lower layers
D
Unmesh MBlock Particles
AMR support
Application
Orchestration / Intergration Support
Application Components
Parallel Standard Libraries
Solvers
Data transfer
CA B
Framework Components

15
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Object Groups (BOCs)
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

16
Converse• Converse is a layer on which Charm++ is built
– Provides machine-dependent code
– Provides “utilities” needed by the RTS of many parallel programming languages
– Used for implementing many mini-languages
• Main Components of Converse:– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Machine model:– Collections of nodes, each node is a collection processes.
– Processes on a node can share memory
– Macros for supporting node-level (shared) and processor level globals

17
Data driven execution
Scheduler Scheduler
Message Q Message Q

18
Converse Scheduler• The core of converse is message-driven execution
– But scheduled entities are not just “messgese” from remote processors
• Genalized notion of messages: any schedulable entity• From scheduler’s point of view: a block of memory,
– First few bytes encode a handler function (as an index into a table)
– Scheduler, in each iteration:• Polls network, enqueuing messages in a fifo• Selects a message from either the fifo or local-queue• Executes handler of of selected message
– This may result in enqueuing of message in the local-queue– Local queue is prioritized lifo/fifo– Priorities may be integers (smaller: higher) or bitvectors
(lexicographic)

19
Converse: communication and threads• Communication support:
– “send” a converse message to a remote processor
– Message must have handler-index encoded at the beginning
– Variety of send-variations (sync/async, memory deallocation) and broadcasts supproted
• Threads: bigger topic– User level threads
– Migratable threads
– Scheduled via converse scheduler
– Suspend and awaken : low level thread package

20
Communication ArchitectureCommunication Architecture
Communication API (Send/Recv)
Net MPI Shmem
UDP(machine-eth.c)
TCP(machine-tcp.c)
Myrinet(machine-gm.c)

21
Parallel Program StartupParallel Program Startup
• Net version - nodelist
Charmrun node compute node
Rsh/ssh(IP, port)
my node
(IP, port)
Broadcast all nodes
(IP, port)
compute node
Rsh/ssh(IP, port)

22
Converse InitializationConverse Initialization• ConverseInit
– Global variables initialization;
– Start worker threads;
• ConverseRunPE for each Charm PE– Per thread initialization;
– Loop into scheduler: CsdScheduler()

23
Message formatsMessage formats
• Net version#define CMK_MSG_HEADER_BASIC { CmiUInt2 d0,d1,d2,d3,d4,d5,hdl,d7; }
Dgram Header length handlerxhandler
• MPI version#define CMK_MSG_HEADER_BASIC { CmiUInt2 rank, root, hdl,xhdl,info,d3; }
infohandlerxhandlerrank root d3

24
SMP support• MPI-smp as an example
– Create threads: CmiStartThreads
– Worker threads work cycle
• See code in mahcine-smp.c
– Communication thread work cycle
• See code in machine-smp.c

25
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

26
Charm++ translator

27
Need for Proxies• Consider:
– Object x of class A wants to invoke method f of obj y of class B.
– x and y are on different processors
– what should the syntax be?
• y->f( …)? : doesn’t work because y is not a local pointer
• Needed:– Instead of “y” we must use an ID that is valid across processors
– Method Invocation should use this ID
– Some part of the system must pack the parameters and send them
– Some part of the system on the remote processor must invoke the right method on the right object with the parameters supplied

28
Charm++ solution: proxy classes• Classes with remotely invokeable methods
– inherit from “chare” class (system defined)
– entry methods can only have one parameter: a subclass of message
• For each chare class D – which has methods that we want to remotely invoke
– The system will automatically generate a proxy class Cproxy_D
– Proxy objects know where the real object is
– Methods invoked on this class simply put the data in an “envelope” and send it out to the destination
• Each chare object has a proxy– CProxy_D thisProxy; // thisProxy inherited from “CBase_D”
– Also you can get a proxy for a chare when you create it:
• CProxy_D myNewChare = CProxy_D::ckNew(arg);

29
Generation of proxy classes• How does charm generate the proxy classes?
– Needs help from the programmer
– name classes and methods that can be remotely invoked
– declare this in a special “charm interface” file (pgm.ci)
– Include the generated code in your program
pgm.ci
mainmodule PiMod {
mainchare main {
entry main();
entry results(int pc);
};
chare piPart {
entry piPart(void);
};
Generates
PiMod.def.h
PiMod.def.h
pgm.h
#include “PiMod.decl.h”
..
Pgm.c
…
#include “PiMod.def.h”

30
Object Groups• A group of objects (chares)
– with exactly one representative on each processor
– A single proxy for the group as a whole
– invoke methods in a branch (asynchronously), all branches (broadcast), or in the local branch
– creation:
• agroup = Cproxy_C::ckNew(msg)
– remote invocation:
• p.methodName(msg); // p.methodName(msg, peNum);
• p.ckLocalBranch()->f(….);

31
Information sharing abstractions• Observation:
– Information is shared in several specific modes in parallel programs
• Other models support only a limited sets of modes:– Shared memory: everything is shared: sledgehammer
approach
– Message passing: messages are the only method
• Charm++: identifies and supports several modes– Readonly / writeonce
– Tables (hash tables)
– accumulators
– Monotonic variables

32
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

33
Seed Balancing• Applies (currently) to singleton chares
– Not chare array elements
– When a new chare is created, the system has freedom to assign it any processor
– The “seed” message (containing constructor parameters) may be moved around among procs until it takes root
• Use– Tree-structured computations
– State-space search, divide-conquer
– Early applications of Charm
– See papers

34
Object Arrays• A collection of data-driven objects
– With a single global name for the collection
– Each member addressed by an index
• [sparse] 1D, 2D, 3D, tree, string, ...
– Mapping of element objects to procS handled by the system
A[0] A[1] A[2] A[3] A[..]
User’s view

35
Object Arrays• A collection of data-driven objects
– With a single global name for the collection
– Each member addressed by an index
• [sparse] 1D, 2D, 3D, tree, string, ...
– Mapping of element objects to procS handled by the system
A[0] A[1] A[2] A[3] A[..]
A[3]A[0]
User’s view
System view

36
Object Arrays• A collection of data-driven objects
– With a single global name for the collection
– Each member addressed by an index
• [sparse] 1D, 2D, 3D, tree, string, ...
– Mapping of element objects to procS handled by the system
A[0] A[1] A[2] A[3] A[..]
A[3]A[0]
User’s view
System view

37
Migration support• Forwarding of messages
– Optimized by hop-counts:
– If a message took multiple hops, the receiver sends the current address to sender
– Array manager maintains a cache of known addresses
• Home processor for each element – Defined by a hash function on the index
• Reductions and broadcasts– Must work in presence of migrations!
• Also, in presence of deletions/insertions
– Communication time proportional to number of processors not objects
– Uses spanning tree based on processors, handling migrated “stragglers” separately

38
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

39
Flexible mapping: using migratibility• Vacating workstations
– If the “owner” starts using it,• Migrate objects away
– Detection:
• Adjusting to speed:– Static:
• measure speeds at the beginning
• Use speed ratios in load balancing
– Dynamic:• In a time-shared
environment• Measure unix “load”• Migrate proportional set of
objects if machine is loaded
• Adaptive job scheduler– Tells jobs to change the sets of
processors used
– Each job maintains a bit-vector of processors they can use.
– Scheduler can change bit-vector
– Jobs obey by migrating objects
– Forwarding, reductions:
• Residual process is left behind

40
Job Monitor
Job SubmissionFile UploadJob Specs
Bids
Job Specs
File Upload
Job Id
Job Id
Cluster
Cluster
Cluster
Faucets: Optimizing Utilization Within/across Clustershttp://charm.cs.uiuc.edu/research/faucets
41
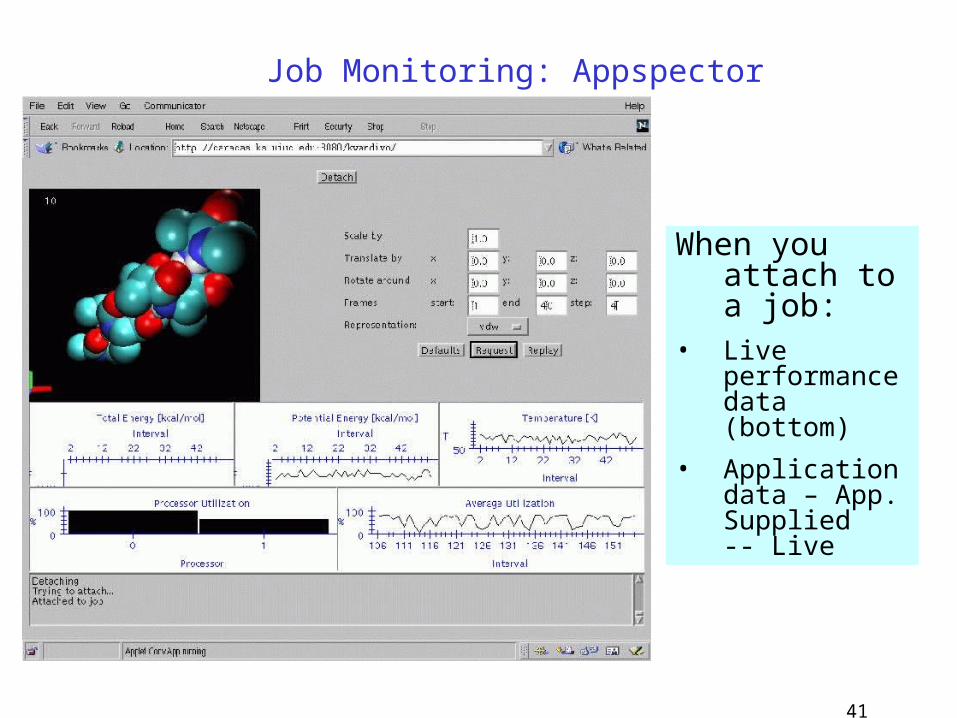
When you attach to a job:
• Live performance data (bottom)
• Application data – App. Supplied -- Live
Job Monitoring: Appspector

42
Inefficient Utilization Within A Cluster
Job A 10 proce
ssors
Allocate A
Job B
8 processors
B QueuedConflict !16 Processor system
Job A
Job B
Current Job Schedulers can yield low system utilization..A competitive problem in Faucets-like systems
Parallel Servers are “profit centers” in faucets: need high utilization

43
Two Adaptive Jobs
Job A Max_pe = 10
Min_pe = 1
A Expands !
Job B
Min_pe = 8Max_pe= 16
Shrink AAllocate B !16 Processor system
Job A
Job B
B FinishesAllocate A !
Adaptive Jobs can shrink or expand the number of processors they use, at runtime: by migrating virtual processors in Charm/AMPI

44
AQS: Adaptive Queuing System
• AQS: A Scheduler for Clusters– Has the ability to manage adaptive jobs
• Currently, those implemented in Charm++ and AMPI– Handles regular (non-adaptive) MPI jobs– Experimental results on CSE Turing Cluster
0
20
40
60
80
100
120
12 30 60 100 108
System Load (%)
Sys
tem
Utli
zatio
n (%
)
Traditional Job
Adaptive Jobs
0
50
100
150
200
250
300
350
12 30 60 100 108
System Load (%)
Mea
n R
espo
nse
Tim
e (s
)
Traditional Job Adaptive Jobs

45
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

46
IV: Principle of Persistence• Once the application is expressed in terms of
interacting objects:– Object communication patterns and computational loads
tend to persist over time
– In spite of dynamic behavior
• Abrupt and large,but infrequent changes (eg:AMR)
• Slow and small changes (eg: particle migration)
• Parallel analog of principle of locality– Heuristics, that holds for most CSE applications
– Learning / adaptive algorithms
– Adaptive Communication libraries
– Measurement based load balancing

47
Measurement Based Load Balancing• Based on Principle of persistence• Runtime instrumentation
– Measures communication volume and computation time
• Measurement based load balancers– Use the instrumented data-base periodically to make new
decisions
– Many alternative strategies can use the database
• Centralized vs distributed
• Greedy improvements vs complete reassignments
• Taking communication into account
• Taking dependences into account (More complex)

48
Load balancer in action
0
5
10
15
20
25
30
35
40
45
501 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91
Iteration Number
Nu
mb
er
of
Ite
rati
on
s P
er
se
con
dAutomatic Load Balancing in Crack Propagation
1. ElementsAdded 3. Chunks
Migrated
2. Load Balancer Invoked

49
Measurement based load balancing

50
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

51
Optimizing for Communication Patterns• The parallel-objects Runtime System can observe,
instrument, and measure communication patterns– Communication is from/to objects, not processors
– Load balancers can use this to optimize object placement
– Communication libraries can optimize
• By substituting most suitable algorithm for each operation
• Learning at runtime
V. Krishnan, MS Thesis, 1996

52
Delegation mechanism• Messages to array elements
– Normally, an array message is handled by the BOC responsible for that array
– But, you can delegate message sending to another library (boc)
• All proxies support the following delegation routines. – void CProxy::ckDelegate(CkGroupID delMgr);
– This is useful for constructing communication libraries
• Suppose you want to combine many small messages
• Use: – At the beginning: proxy.delegate(libID),
– In loops: {lib.start(), proxy[I]->f(m1);…; lib.end()}
– Lib can maintain internal data structures for bugffering msgs
– User’s interface remains unchanged (except for the lib calls)

53
• Messages to array elements– Normally, an array message is handled by the BOC
responsible for that array
– But, you can delegate message sending to another library (boc)
• All proxies support the following delegation routines. – void CProxy::ckDelegate(CkGroupID delMgr);
– This is useful for constructing communication libraries
• Suppose you want to combine many small messages

54
• Messages to array elements– Normally, an array message is handled by the BOC
responsible for that array
– But, you can delegate message sending to another library (boc)
• All proxies support the following delegation routines.
– void CProxy::ckDelegate(CkGroupID delMgr);
– This is useful for constructing communication libraries
• Suppose you want to combine many small messages

55
Communication Optimizations
• Persistence principle– Observing
communication behavior across iterations
– Communication patterns
• Who sends to whom
• Size of messages
• “Collective” Communication– Substitute optimal
algorithms
– Tune parameters
0
20
40
60
80
100
120
140
256 512 1024
Processors
Mesh Direct MPI
This approach makes a difference in applications
-- E.g. Transpose in NAMD
Time/step (ms)

56
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

57
Outline• There is magic:
– Overview of charm capabilities
– Virtualization paper
– Summary of charm features:
• Converse– Machine model
– Scheduler and General Msgs
– Communication
– Threads
• Proxies and generated code
• Support for migration– Seed balancing
– Migration support w reduction
• How migration is used– Vacating workstations and
adjusting to speed
– Adaptive Scheduler
• Principle of persistence:– Measurement based load
balancing
• Centralized strategies, refinement, commlb
• Distributed strategies (nbr)
– Collective communication opts
• Delegation
• Converse client-server interface
• Libraries: – liveviz, fft, ..

58
Object-based Parallelization
User View
System implementation
User is only concerned with interaction between objects

59
Data driven execution
Scheduler Scheduler
Message Q Message Q

60

61
Scaling to 64K/128K processors of BG/L• What issues will arise?
– Communication
• Bandwidth use more important than processor overhead
• Locality:
– Global Synchronizations
• Costly, but not because it takes longer
• Rather, small “jitters” have a large impact
• Sum of Max vs Max of Sum
– Load imbalance important, but low grainsize is crucial
– Critical paths gains importance

62
Runtime Optimization Challenges
• Full exploitation of object decomposition– Load balance within individual phases– Automatic Identification of phases
• 10K-100K processors– Inadequate load balancing strategies– Need topology-aware balancing– Also fully-distributed decision making
• But based on “reasonable” global information
• Communication Optimizations– Identify patterns, develop algorithms suitable for each, and implement “learning”
strategies
• Fault tolerance and incremental checkpointing– Objects as the unit of checkpointing.– In-memory checkpoints– Tradeoff between forward-path overhead and fault-handling cost