Embed Size (px)
Citation preview

11
Grids/CI for Scholarly Researchand application to
Chemical InformaticsHPC 2006 in Cetraro – Italy
July 4 2006
Geoffrey Fox
Computer Science, Informatics, PhysicsPervasive Technology Laboratories
Indiana University Bloomington IN 47401
[email protected]://www.infomall.org

22
Motivation Build Cyberinfrastructure (Grids) that
• Support science from beginning (planning, instruments) through middle (analysis) and end (refereed publications, follow-on work)
• Integrates with the popular Web 2.0 (community) tools whose successes point to interesting ways of working together
• Integrate with Digital Library technology• Does not redo previous work but rather augments it• Assumes a heterogeneous fragmented world with multiple
platforms• Allows one to specify and manage all the services and data
that a project needs with a mix of synchronous, asynchronous, close (classic workflow) and loose (including zero) coupling

33
Application Drivers Chemical Informatics as this has very precise naming
rules for compounds that allow accurate searches in documents• Suggesting how to tag scientific documents either when
writing it or after the fact “Global Information Grid” (Military Net-Centric
systems) as these inevitably need Grid of Grids to support “systems of systems”
Journal web site of the future as illustrated by Nature building social bookmarking tool Connotea
Conference support tools as can benefit from features needed by journals

44
The Science Drivers From Workshop on Challenges of Scientific Workflows
http://vtcpc.isi.edu/wiki/index.php/Main_Page Workflow is underlying support for current science
model• Distributed interdisciplinary data deluged scientific
methodology as an end (instrument, conjecture) to end (paper, Nobel prize) process is a transformative approach
Reproducibility core to scientific method and requires rich provenance, interoperable persistent repositories with linkage of open data and publication as well as distributed simulations, data analysis and new algorithms.
Distributed Science Methodology publishes all steps in a new electronic logbook capturing scientific process (data analysis) as a rich cloud of resources including emails, PPT, Wikis as well as databases, compiler options, build time/runtime configuration…

Community (? VO) Tools e-mail and list-serves are oldest and best used Kazaa, Instant Messengers, Skype, Napster, BitTorrent for P2P
Collaboration – text, audio-video conferencing, files del.icio.us, Connotea, Citeulike, Bibsonomy, Biolicious manage
shared bookmarks (later) MySpace, Bebo, Hotornot, Facebook, or similar sites allow you to
create (upload) community resources and share them; Friendster, LinkedIn create networks• http://en.wikipedia.org/wiki/List_of_social_networking_websites
Writely, Wikis and Blogs are powerful specialized shared document systems
ConferenceXP and WebEx share general applications Google Scholar (Citeseer) tells you who has cited your papers
while publisher sites tell you about co-authors• Windows Live Academic Search has similar goals (later)
Note sharing resources creates (implicit) communities• Social network tools study graphs to both define communities
and extract their properties

How to use Web2.0 Community tools in CI Nearly all of them have “profiles”, “users”, “groups”, “friends”
etc.• Need to integrate these
P2P File Sharing: Maybe this is useful for sharing files in research groups (virtual organizations)• Will modify Maze http://maze.pku.edu.cn – popular Chinese social P2P
system with 2.5 million users BitTorrent: more popular than FTP – why not use for higher
performance fault tolerant cached file sharing? MySpace etc.: Could consider MyGridSpace or MyScienceSpace
that supports a similar document sharing model with users uploading pictures, papers and even data/services of interest• Could include uploaded material in workflows• Can impose different policies
Social Bookmarking and linking: discuss later• http://gf6.ucs.indiana.edu:48990/SemanticResearchGrid/
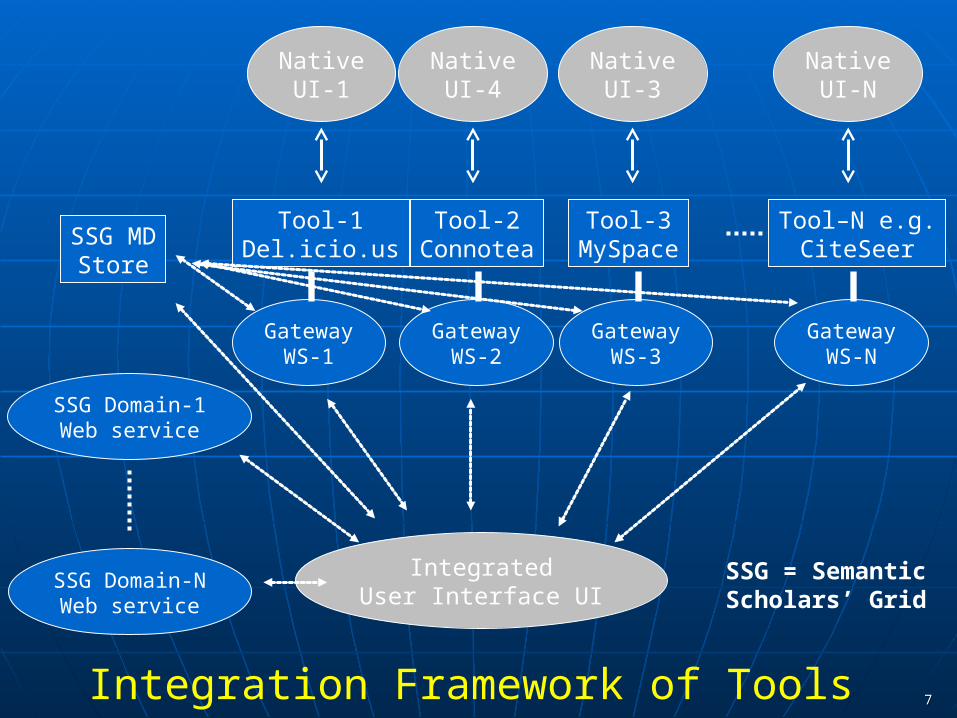
77
SSG Domain-1Web service
SSG Domain-NWeb service
Tool-1Del.icio.us
Tool-2Connotea
Tool-3MySpace
Tool–N e.g.CiteSeer
NativeUI-1
NativeUI-4
NativeUI-3
NativeUI-N
IntegratedUser Interface UI
GatewayWS-1
GatewayWS-2
GatewayWS-3
GatewayWS-N
SSG MDStore
Integration Framework of Tools
SSG = Semantic Scholars’ Grid

Strategy Doesn’t seem useful to build the 251st community tool In fact a major barrier to use of existing tools is
• What happens when a better tool comes along and/or chosen tool disappears (unsupported/removed from Web)
So assume use existing tools but wrap them all as web services so can transfer information to new tools and integrate information between tools• Need some “glue” logic, a “unification” database and minimal user
interface Bookmarking tools: del.icio.us, Connotea, CiteULike (includes
plug-ins to major publisher sites) Document: Google Scholar, Windows Live, Citeseer tools,
OSCAR3 for Chemistry (later), Science.gov Journals: Manuscript Central Conferences: CMT from Microsoft or ?
99
Connotea
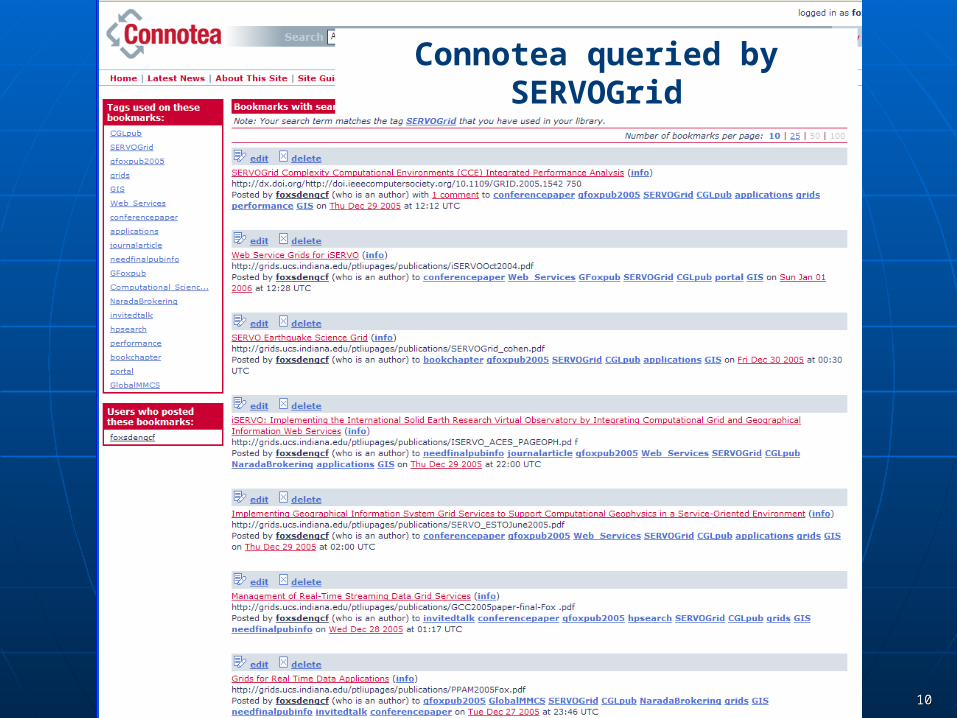
1010
Connotea queried by SERVOGrid

1111
Delicious Semantic Web/Grid http://del.icio.us purchased by Yahoo for ~$30M http://www.CiteULike.org http://www.connotea.org (Nature) Associate metadata with Bookmarks specified by
URL’s, DOI’s (Digital Object Identifiers) Users add comments and keywords (called tags) Users are linked together into groups (communities) Information such as title and authors extracted
automatically from some sites (PubMed, ACM, IEEE, Wiley etc.)
Bibtex like additional information in CiteULike This is perhaps de facto Semantic Web – remarkable
for its simplicity

1212
Document-enhanced Cyberinfrastructureaka Semantic Scholar Grid I
Citeseer and Google Scholar scour the Internet and analyze documents for incidental metadata• Title, author and institution of documents• Citations with their own metadata allowing one to match
to other documents Science.gov extracts metadata from lots of US Government
databases These capabilities are sure to become more powerful and to
be extended• Give “Citation Index” in real time• Tell you all authors of all papers that cite a paper that
cites you etc. (Note it’s a small world so don’t go too far in link analysis)
• Tell you all citations of all papers in a workshop

1313
Document-enhanced Cyberinfrastructureaka Semantic Scholar Grid II
It is natural to develop core document Services such as those used in Citeseer/Google Scholar but applied to “your” documents of interest that may not have been processed yet • As just submitted to a conference perhaps
These tools can help form useful lists such as authors of all cited or submitted papers to a journal
OSCAR2/3 (from Peter Murray-Rust’s group at Cambridge) augment the application independent “core” metadata (Title, authors, institutions, Citations) with a list of all chemical terms • This tool is a Service that can be applied to “your” document or to a set of
documents harvested in some fashion
• Other fields have natural application specific metadata and OSCAR like tools can be developed for them
Such high value tools could appear on “publisher” sites of future (or else publishers will disappear)
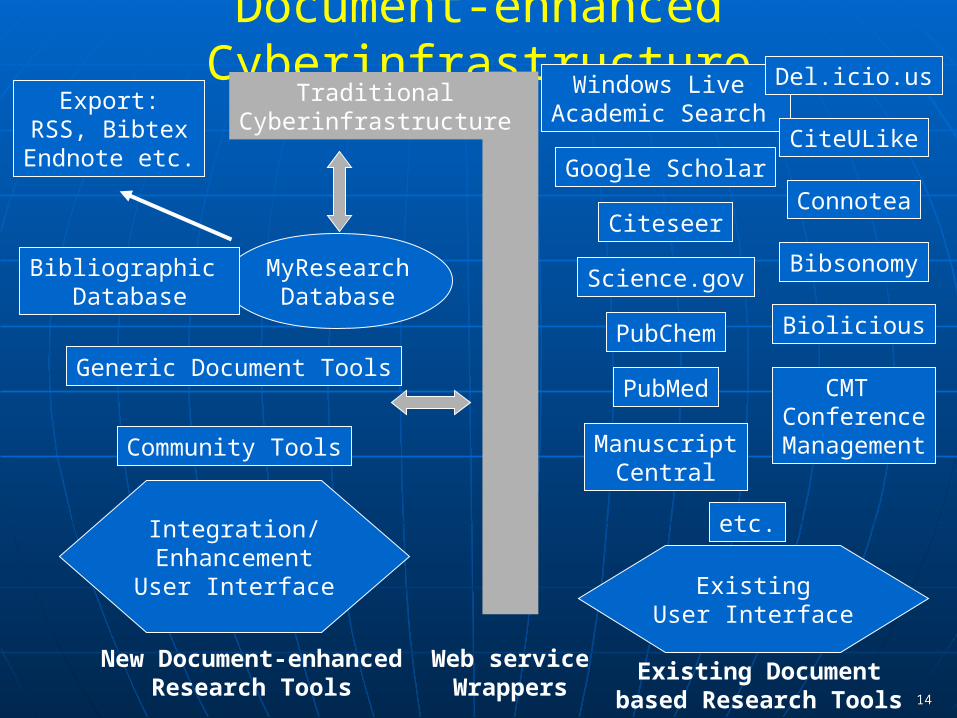
1414
ExistingUser Interface
Document-enhanced Cyberinfrastructure
etc.
Google Scholar
ManuscriptCentral
Science.gov
Windows Live Academic Search
Citeseer
CMT Conference
Management
Existing Documentbased Research Tools
Web serviceWrappers
New Document-enhancedResearch Tools
Integration/EnhancementUser Interface
Community Tools
Generic Document Tools
MyResearchDatabase
Bibliographic Database
Export:RSS, BibtexEndnote etc.
CiteULike
Connotea
Del.icio.us
Bibsonomy
BioliciousPubChem
PubMed
TraditionalCyberinfrastructure

1515
Chemical Informatics as a Grid Application Chemical Informatics is the application of information technology to
problems in chemistry.• Example problems: managing data in large scale drug discovery
and molecular modeling Building Blocks: Chemical Informatics Resources:
• Chemical databases maintained by various groups NIH PubChem, NIH DTP, http://nihroadmap.nih.gov/
• Application codes (both commercial and open source) Data mining such as clustering Quantum chemistry and molecular modeling
• Screening centers (with HTS High Throughput Screening devices) measuring interaction of chemicals with biological samples
• Visualization tools• Web resources: journal articles, etc.
Chemical Informatics Grid http://www.chembiogrid.org needs to integrate these into a common, loosely coupled, distributed computing environment.
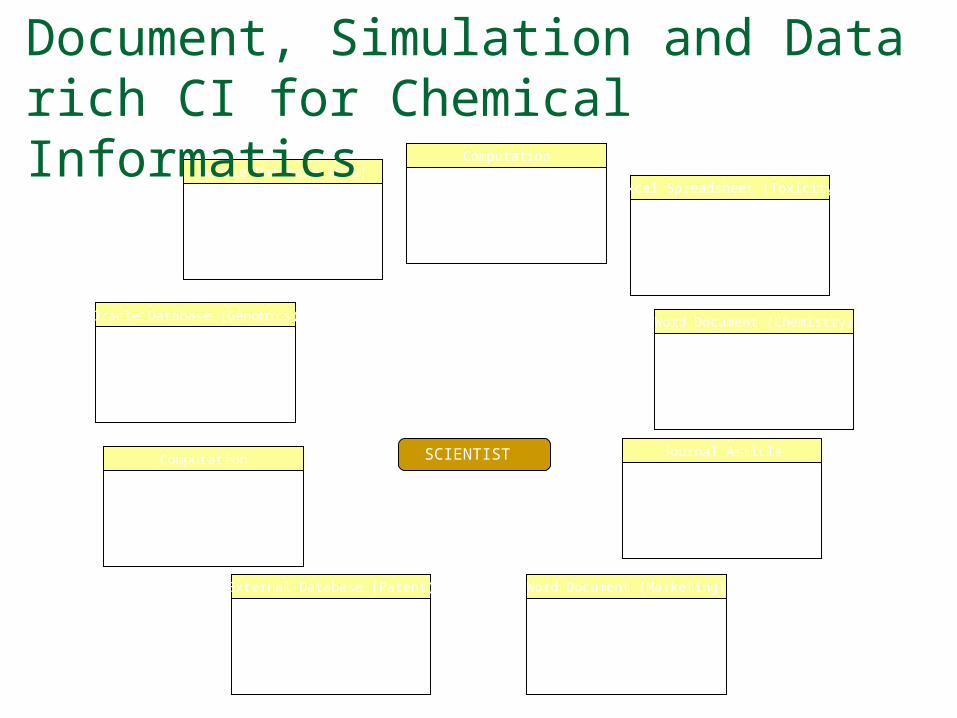
Oracle Database (HTS)
Compounds were tested against related assays and showed activity, including
selectivity within target families
Oracle Database (Genomics)
? None of these compounds have been tested in a
microarray assay
Computation
The information in the structures and known activity data is good enough to create
a QSAR model with a confidence of 75%
External Database (Patent)
Some structures with a similarity > 0.75 to these
appear to be covered by a patent held by a competitor
Computation
All the compounds pass the Lipinksi Rule of Five and
toxicity filters
Excel Spreadsheet (Toxicity)
One of the compounds was previously tested for
toxicology and was found to have no liver toxicity
Word Document (Chemistry)
Several of the compounds had been followed up in a
previous project, and solubility problems prevented further
development
Journal Article
A recent journal article reported the effectiveness of some compounds in a related series against a target in the same family
Word Document (Marketing)
A report by a team in Marketing casts doubt on
whether the market for this target is big enough to make development cost-effective
SCIENTIST
“These compounds look promising from their HTS results. Should I commit some
chemistry resources to following them up?”
?
Document, Simulation and Data rich CI for Chemical Informatics
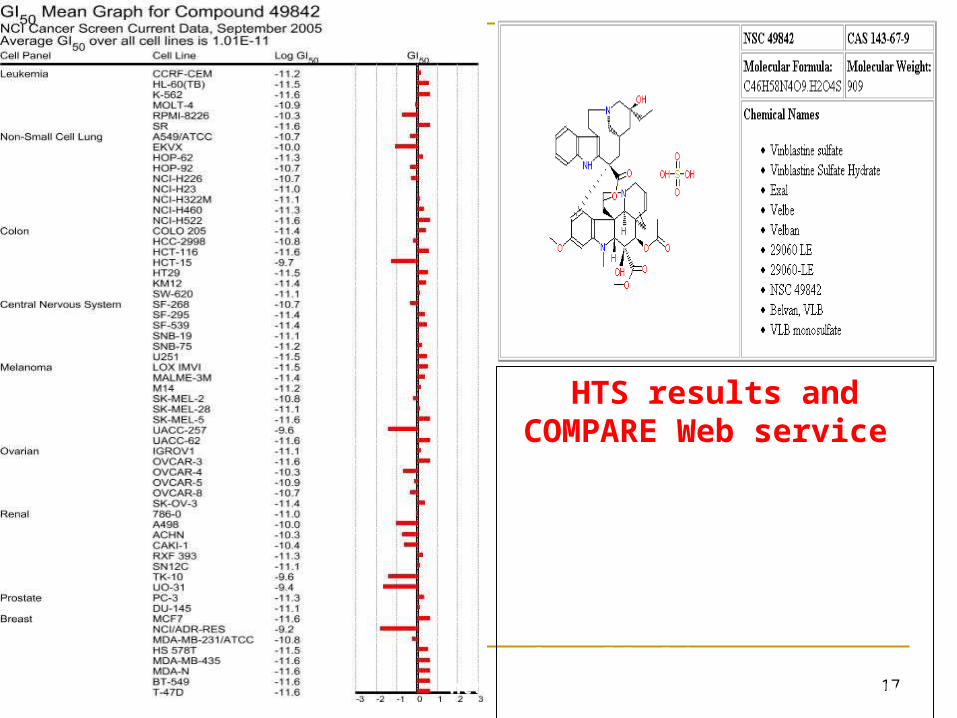
17
HTS results and COMPARE Web service
Positive results (red bar to right of vertical line) indicates greater than average toxicity of cell line to tested agent.
http://dtp.nci.nih.gov/docs/compare/compare.html
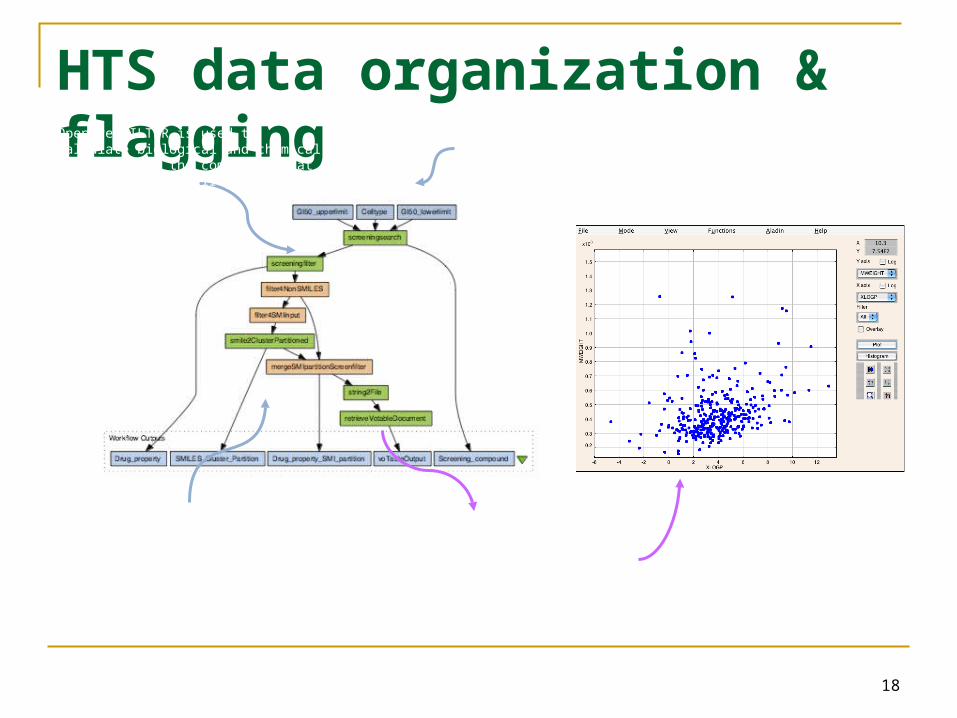
18
HTS data organization & flagging
A tumor cell line is selected. The activity results for all the compounds in the DTP database in the given range are extracted from the PostgreSQL database
The compounds are clustered on chemical structure
similarity, to group similar compounds together
The compounds along with property and cluster information are converted to VOTABLES format and displayed in VOPLOT
OpenEye FILTER is used to calculate biological and chemical properties of the compounds that are related to their potential effectiveness as drugs
Use Taverna for Workflow and VOTable (from astronomy) as basic data structure; VOTable of compounds and properties with
Excel-like spreadsheet services
VOPlot
Taverna
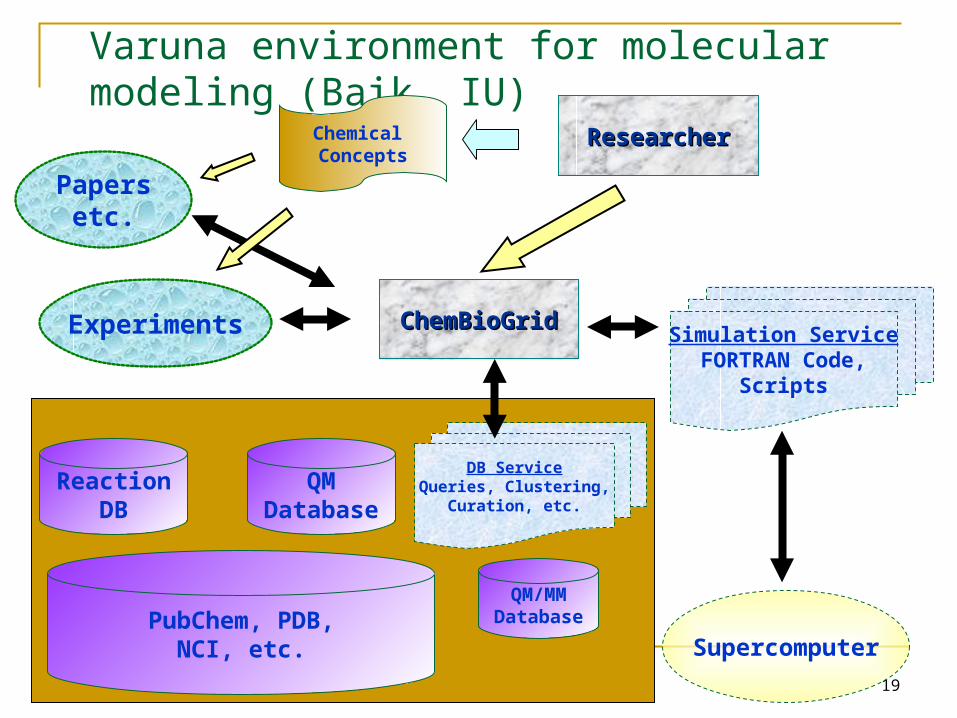
19
Varuna environment for molecular modeling (Baik, IU)
QMDatabase
Supercomputer
ResearcherResearcher
Simulation ServiceFORTRAN Code,
Scripts
Chemical Concepts
Experiments
QM/MMDatabasePubChem, PDB,
NCI, etc.
ChemBioGridChemBioGrid
ReactionDB
DB ServiceQueries, Clustering,
Curation, etc.
Papersetc.
Condor

20
OSCAR3 Service from Cambridge UK Oscar3 is a tool for shallow, chemistry-specific
natural language parsing of chemical documents (i.e. journal articles).
It identifies (or attempts to identify): Chemical names: singular nouns, plurals, verbs etc., also
formulae and acronyms. Chemical data: Spectra, melting/boiling point, yield etc. in
experimental sections. Other entities: Things like N(5)-C(3) and so on.
Uses SMILES, InChI and CML There is a larger effort, SciBorg, in this area
http://www.cl.cam.ac.uk/~aac10/escience/sciborg.html
http://wwmm.ch.cam.ac.uk/wikis/wwmm/index.php/Oscar3
2121
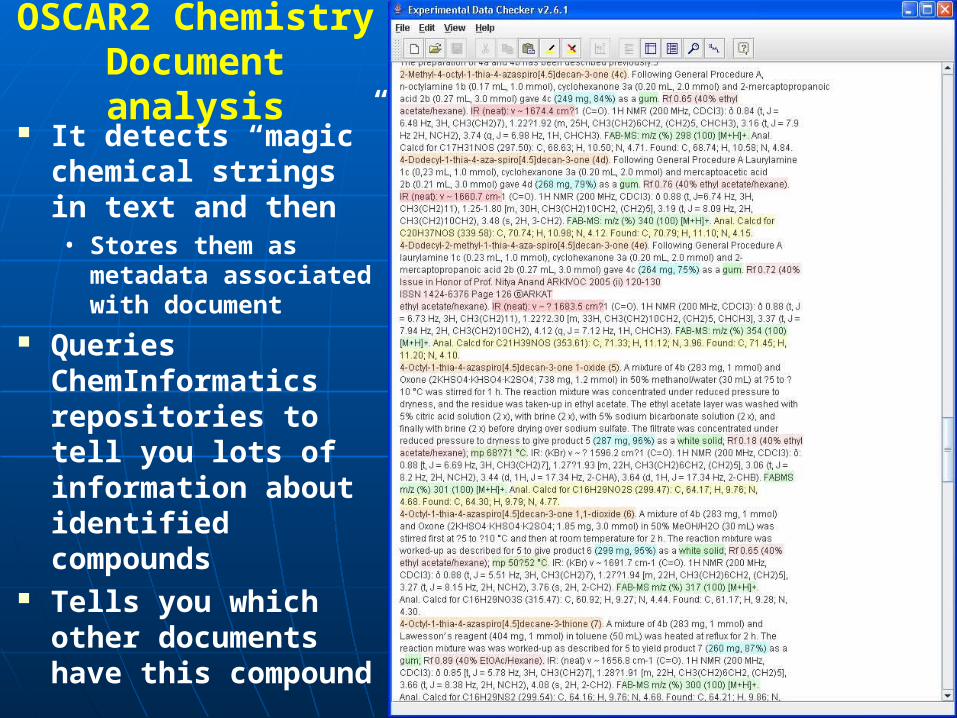
OSCAR2 Chemistry Document analysis
It detects “magic” chemical strings in text and then• Stores them as
metadata associated with document
Queries ChemInformatics repositories to tell you lots of information about identified compounds
Tells you which other documents have this compound
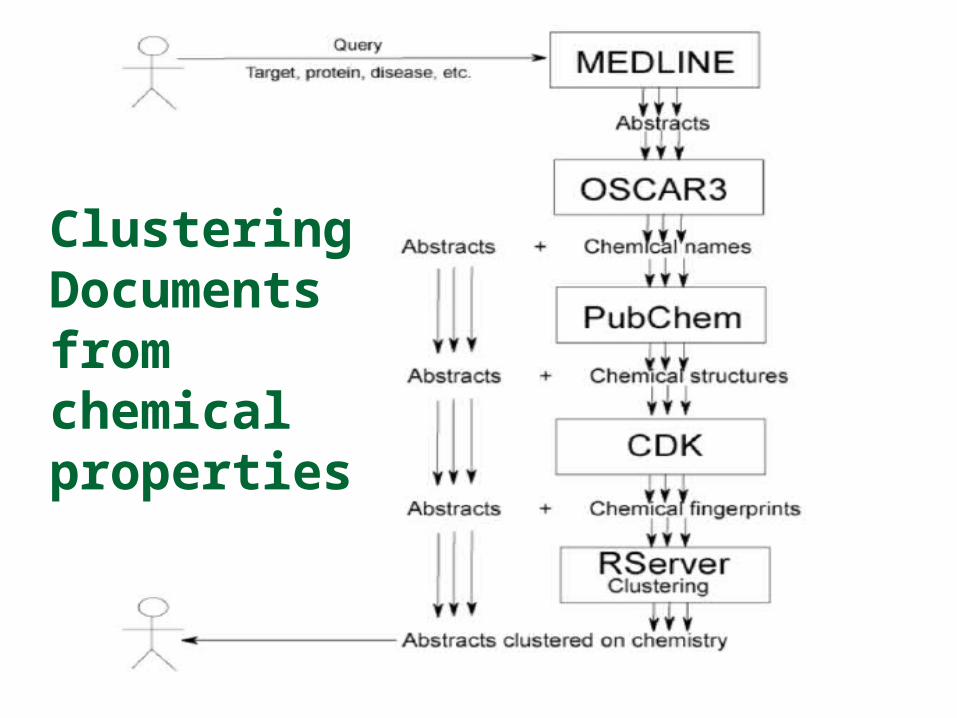
Clustering Documents from chemicalproperties

2323
Provenance and Delicious CI We can use del.icio.us style interface to annotate Application
Data with (extra) provenance and user comments of any type (describing quality of data or a keyword relating different data etc.)• All data should be labeled by a URI to enable this
• One has in addition Citeseer/OSCAR metadata
Current major tagging systems support flat list of tags without name=value (RDF triple) or schema organization• RDF Triples << Full Semantic Web
• Delicious << RDF
• Tradeoff between features and pervasive deployment
Some extra features are easy to add as a custom service Features not supported by del.icio.us can be uploaded as
comments
2424
Current Status Google Scholar, Windows Live Academic Search, del.icio.us,
Connotea, CiteULike, OSCAR3 are Web Services Debugging on 500 presentations and papers from my CGL
research group Experiment with GGF Presentations, Broad collection of
Chemical Informatics resources (explore science document CI link) and Concurrency&Computation: Practice&Experience Web site (?business model for journals)

2525
Collection (Grid) Builder Tool This can perhaps be built on top of workflow systems Unlike ordinary workflow, this is a tool to manage collections of
Grids and the key metadata adorning Grids and Services It instantiates needed mediation between Grids (systems) to
convert
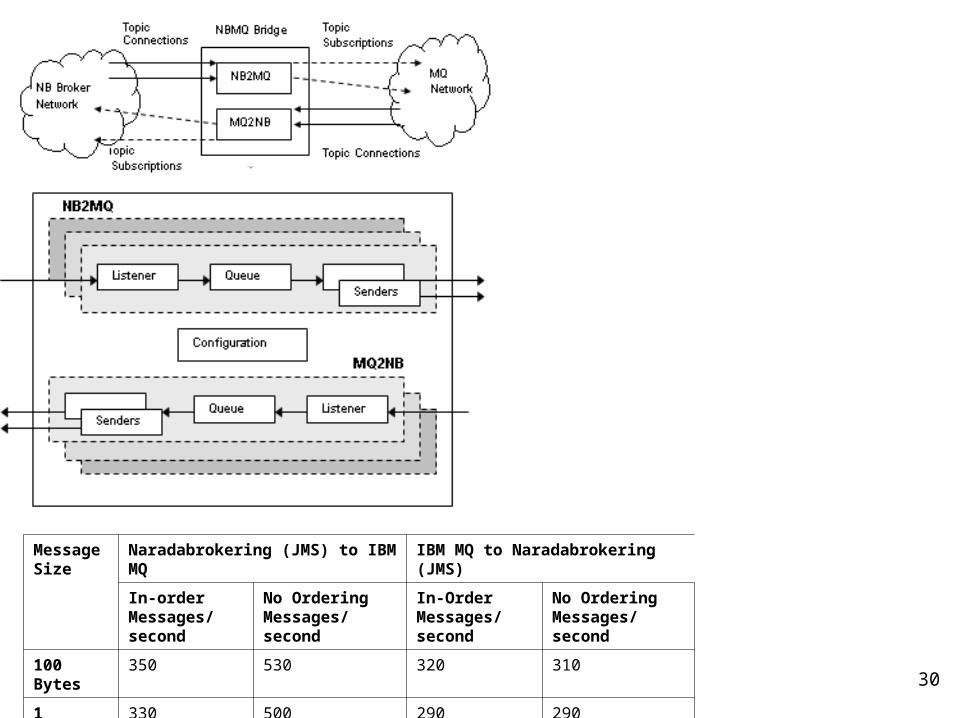
• JMS to MQSeries
• GT4 to WS-I+
• WS-Eventing to WS-Notification It supports conventional workflow as tightly coupled services It supports system wide “management” (configuration)
• We are using WS-Management – see CLADE paper Deploy services and mediation brokers on demand to deliver
real-time performance • DoD can’t pause the battle while WS-RM and TCP catch up if data
saturated
26
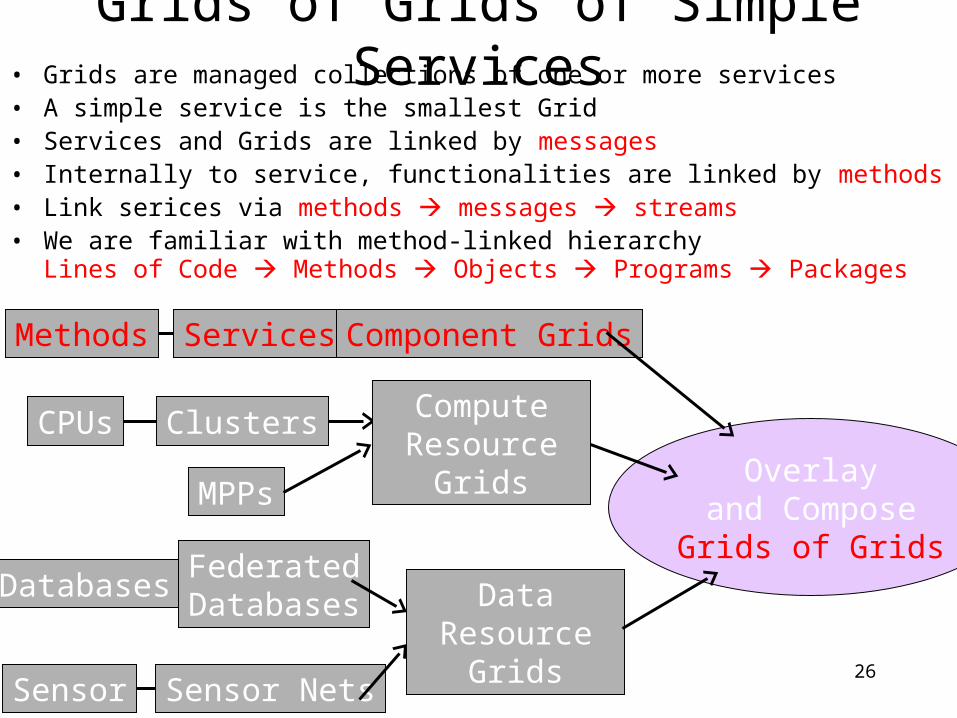
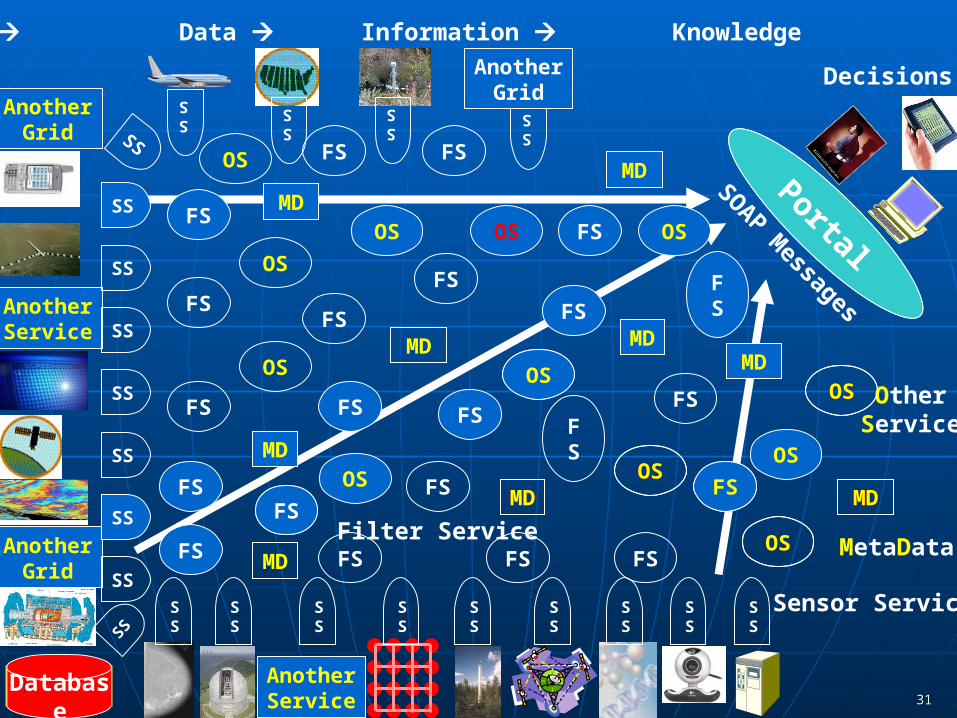
Grids of Grids of Simple Services• Grids are managed collections of one or more services• A simple service is the smallest Grid• Services and Grids are linked by messages• Internally to service, functionalities are linked by methods• Link serices via methods messages streams • We are familiar with method-linked hierarchy
Lines of Code Methods Objects Programs Packages
Overlayand ComposeGrids of Grids
Methods Services Component Grids
CPUs Clusters ComputeResource Grids
MPPs
DatabasesFederatedDatabases
Sensor Sensor Nets
DataResource Grids

2727
Component Grids? So we build collections of Web Services which we package as
component Grids
• Visualization Grid
• Sensor Grid
• Utility Computing Grid
• Collaboration Grid
• Earthquake Simulation Grid
• Control Room Grid
• Crisis Management Grid
• Drug Discovery Grid
• Bioinformatics Sequence Analysis Grid
• Intelligence Data-mining Grid We build bigger Grids by composing component Grids
28
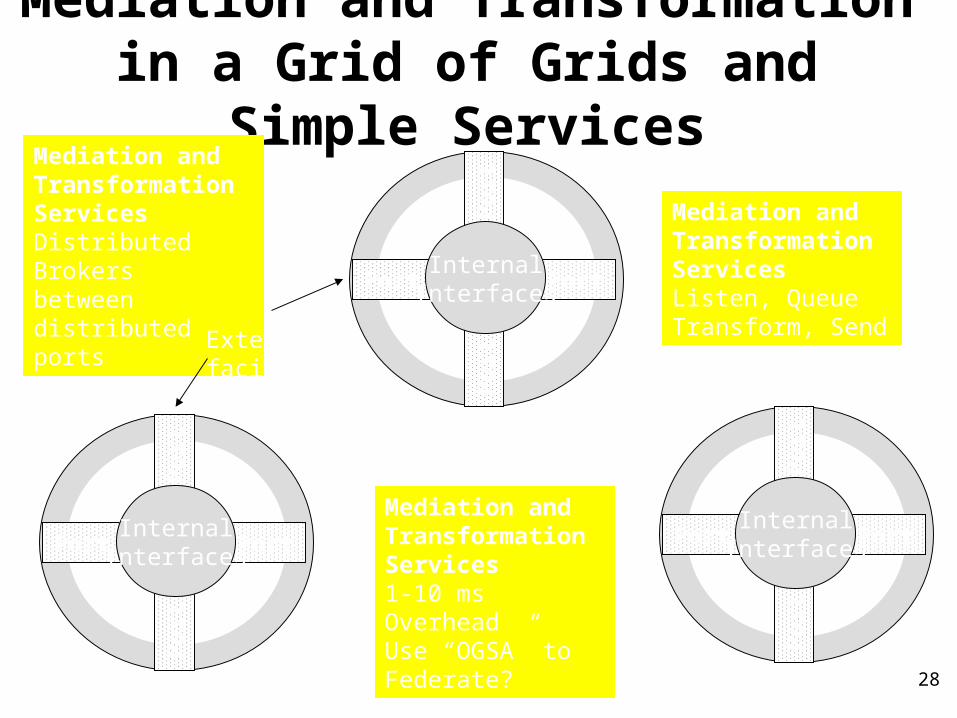
Mediation and Transformation in a Grid of Grids and Simple Services
Po
rtP
ort
Port PortInternal
Interfaces
Grid or Service
Po
rtP
ort
Port PortInternal
Interfaces
Grid or Service
Po
rtP
ort
Port PortInternal
Interfaces
Grid or Service
Mediation andTransformation ServicesDistributed Brokersbetween distributedports
ExternalfacingInterfaces
Mediation andTransformation ServicesListen, QueueTransform, Send
Mediation andTransformation Services1-10 ms OverheadUse “OGSA” toFederate?
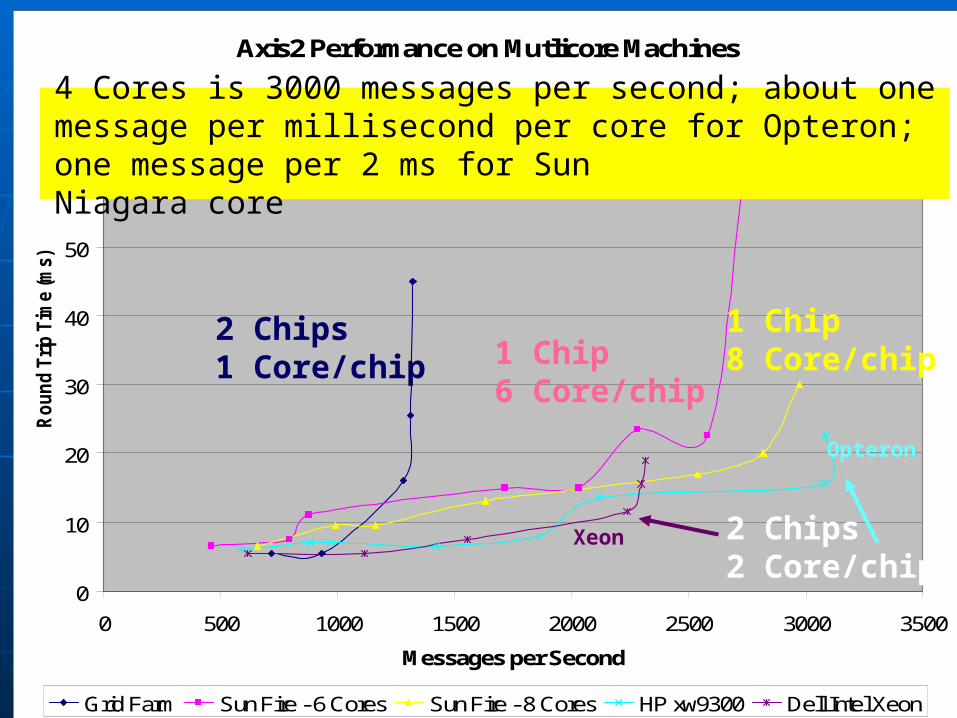
Axis2 Performance on Mutlicore Machines
0
10
20
30
40
50
60
70
0 500 1000 1500 2000 2500 3000 3500
Messages per Second
Round T
rip T
ime (m
s) (
ms)
Grid Farm Sun Fire - 6 Cores Sun Fire - 8 Cores HP xw9300 Dell Intel Xeon
2 Chips2 Core/chip
2 Chips1 Core/chip
1 Chip8 Core/chip1 Chip
6 Core/chip
Xeon
Opteron
4 Cores is 3000 messages per second; about one message per millisecond per core for Opteron; one message per 2 ms for Sun Niagara core
30
Message Size
Naradabrokering (JMS) to IBM MQ IBM MQ to Naradabrokering (JMS)
In-orderMessages/second
No OrderingMessages/second
In-OrderMessages/second
No OrderingMessages/second
100 Bytes 350 530 320 310
1 Kbytes 330 500 290 290
4 Kbytes 200 390 220 210
Pentium 4 (3.4GHz) with 1GB of RAM while IBM- MQ Series, Naradabrokering and the Message Bridge are all running on it.
NaradaBrokering running in JMS emulation mode
3131Database
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
FS
FS
FS
FS
FS
FS
FS
FS FS
FS
FS
FS
FS
FS
FS
FS
FS FS
FS
FS
PortalFS
OS
OS
OS
OS
OS
OS
OS
OS
OS
OS
OS
OS
MD
MD
MD
MD
MD
MD
MD
MD
MD
MetaDataFilter Service
Sensor Service
OtherService
AnotherGrid
Raw Data Data Information Knowledge Wisdom
Decisions
SS
SS
AnotherService
AnotherService
SSAnother
Grid SS
AnotherGrid
SS
SS
SS
SS
SS
SS
SS
SS
FS
SOAP Messages
Portal
OS
OS
FS
OS
OS
MD MD
MD
FS















![arXiv:math/0512372v3 [math.AG] 4 Jan 2006 · Cetraro were of great value for the preparation of this text. Thanks are due to Maxim Kontsevich and Lev Borisov who gave permission to](https://img.pdfslide.us/doc/110x75/5f66a8dbf96f741ada3b4159/arxivmath0512372v3-mathag-4-jan-2006-cetraro-were-of-great-value-for-the-preparation.jpg)













