Embed Size (px)
Citation preview

1
Deep Facial Expression Recognition A SurveyShan Li and Weihong Denglowast Member IEEE
AbstractmdashWith the transition of facial expression recognition (FER) from laboratory-controlled to challenging in-the-wild conditionsand the recent success of deep learning techniques in various fields deep neural networks have increasingly been leveraged to learndiscriminative representations for automatic FER Recent deep FER systems generally focus on two important issues overfittingcaused by a lack of sufficient training data and expression-unrelated variations such as illumination head pose and identity bias In thispaper we provide a comprehensive survey on deep FER including datasets and algorithms that provide insights into these intrinsicproblems First we introduce the available datasets that are widely used in the literature and provide accepted data selection andevaluation principles for these datasets We then describe the standard pipeline of a deep FER system with the related backgroundknowledge and suggestions of applicable implementations for each stage For the state of the art in deep FER we review existingnovel deep neural networks and related training strategies that are designed for FER based on both static images and dynamic imagesequences and discuss their advantages and limitations Competitive performances on widely used benchmarks are also summarizedin this section We then extend our survey to additional related issues and application scenarios Finally we review the remainingchallenges and corresponding opportunities in this field as well as future directions for the design of robust deep FER systems
Index TermsmdashFacial Expressions Recognition Facial expression datasets Affect Deep Learning Survey
F
1 INTRODUCTION
F ACIAL expression is one of the most powerful natural anduniversal signals for human beings to convey their emotional
states and intentions [1] [2] Numerous studies have been con-ducted on automatic facial expression analysis because of itspractical importance in sociable robotics medical treatment driverfatigue surveillance and many other human-computer interactionsystems In the field of computer vision and machine learningvarious facial expression recognition (FER) systems have beenexplored to encode expression information from facial represen-tations As early as the twentieth century Ekman and Friesen [3]defined six basic emotions based on cross-culture study [4] whichindicated that humans perceive certain basic emotions in the sameway regardless of culture These prototypical facial expressionsare anger disgust fear happiness sadness and surprise Contemptwas subsequently added as one of the basic emotions [5] Recentlyadvanced research on neuroscience and psychology argued that themodel of six basic emotions are culture-specific and not universal[6]
Although the affect model based on basic emotions is limitedin the ability to represent the complexity and subtlety of ourdaily affective displays [7] [8] [9] and other emotion descriptionmodels such as the Facial Action Coding System (FACS) [10] andthe continuous model using affect dimensions [11] are consideredto represent a wider range of emotions the categorical modelthat describes emotions in terms of discrete basic emotions isstill the most popular perspective for FER due to its pioneeringinvestigations along with the direct and intuitive definition of facialexpressions And in this survey we will limit our discussion onFER based on the categorical model
FER systems can be divided into two main categories accord-ing to the feature representations static image FER and dynamicsequence FER In static-based methods [12] [13] [14] the feature
bull The authors are with the Pattern Recognition and Intelligent System Lab-oratory School of Information and Communication Engineering BeijingUniversity of Posts and Telecommunications Beijing 100876 ChinaE-maills1995 whdengbupteducn
representation is encoded with only spatial information from thecurrent single image whereas dynamic-based methods [15] [16][17] consider the temporal relation among contiguous frames inthe input facial expression sequence Based on these two vision-based methods other modalities such as audio and physiologicalchannels have also been used in multimodal systems [18] to assistthe recognition of expression
The majority of the traditional methods have used handcraftedfeatures or shallow learning (eg local binary patterns (LBP) [12]LBP on three orthogonal planes (LBP-TOP) [15] non-negativematrix factorization (NMF) [19] and sparse learning [20]) for FERHowever since 2013 emotion recognition competitions such asFER2013 [21] and Emotion Recognition in the Wild (EmotiW)[22] [23] [24] have collected relatively sufficient training datafrom challenging real-world scenarios which implicitly promotethe transition of FER from lab-controlled to in-the-wild settings Inthe meanwhile due to the dramatically increased chip processingabilities (eg GPU units) and well-designed network architecturestudies in various fields have begun to transfer to deep learningmethods which have achieved the state-of-the-art recognition ac-curacy and exceeded previous results by a large margin (eg [25][26] [27] [28]) Likewise given with more effective training dataof facial expression deep learning techniques have increasinglybeen implemented to handle the challenging factors for emotionrecognition in the wild Figure 1 illustrates this evolution on FERin the aspect of algorithms and datasets
Exhaustive surveys on automatic expression analysis havebeen published in recent years [7] [8] [29] [30] These surveyshave established a set of standard algorithmic pipelines for FERHowever they focus on traditional methods and deep learninghas rarely been reviewed Very recently FER based on deeplearning has been surveyed in [31] which is a brief review withoutintroductions on FER datasets and technical details on deep FERTherefore in this paper we make a systematic research on deeplearning for FER tasks based on both static images and videos(image sequences) We aim to give a newcomer to this filed anoverview of the systematic framework and prime skills for deep
arX
iv1
804
0834
8v2
[cs
CV
] 2
2 O
ct 2
018
2
2017
2015
2013
2011
2009
2007
Zhao et al [15] (LBP-TOP SVM)
Shan et al [12] (LBP AdaBoost)CK+
MMI
FER2013
Zhi et al [19] (NMF)
Zhong et al [20] (Sparse learning)
Tang (CNN) [130] (winner of FER2013)
Kahou et al [57] (CNN DBN DAE) (winner of EmotiW 2013)
EmotioNet
RAF-DB
AffectNet
----gt----gt
EmotiW
Fan et al [108] (CNN-LSTM C3D) (winner of EmotiW 2016)
LP losstuplet cluster loss
Island losshellip hellip
HoloNetPPDNIACNNFaceNet2ExpNethellip hellip
Algorithm Dataset
Fig 1 The evolution of facial expression recognition in terms of datasetsand methods
FERDespite the powerful feature learning ability of deep learning
problems remain when applied to FER First deep neural networksrequire a large amount of training data to avoid overfittingHowever the existing facial expression databases are not sufficientto train the well-known neural network with deep architecture thatachieved the most promising results in object recognition tasksAdditionally high inter-subject variations exist due to differentpersonal attributes such as age gender ethnic backgrounds andlevel of expressiveness [32] In addition to subject identity biasvariations in pose illumination and occlusions are common inunconstrained facial expression scenarios These factors are non-linearly coupled with facial expressions and therefore strengthenthe requirement of deep networks to address the large intra-classvariability and to learn effective expression-specific representa-tions
In this paper we introduce recent advances in research onsolving the above problems for deep FER We examine the state-of-the-art results that have not been reviewed in previous surveypapers The rest of this paper is organized as follows Frequentlyused expression databases are introduced in Section 2 Section 3identifies three main steps required in a deep FER system anddescribes the related background Section 4 provides a detailedreview of novel neural network architectures and special networktraining tricks designed for FER based on static images anddynamic image sequences We then cover additional related issuesand other practical scenarios in Section 5 Section 6 discussessome of the challenges and opportunities in this field and identifiespotential future directions
2 FACIAL EXPRESSION DATABASES
Having sufficient labeled training data that include as manyvariations of the populations and environments as possible isimportant for the design of a deep expression recognition systemIn this section we discuss the publicly available databases thatcontain basic expressions and that are widely used in our reviewedpapers for deep learning algorithms evaluation We also introducenewly released databases that contain a large amount of affectiveimages collected from the real world to benefit the training ofdeep neural networks Table 1 provides an overview of thesedatasets including the main reference number of subjects number
of image or video samples collection environment expressiondistribution and additional information
CK+ [33] The Extended CohnKanade (CK+) database is themost extensively used laboratory-controlled database for evaluat-ing FER systems CK+ contains 593 video sequences from 123subjects The sequences vary in duration from 10 to 60 framesand show a shift from a neutral facial expression to the peakexpression Among these videos 327 sequences from 118 subjectsare labeled with seven basic expression labels (anger contemptdisgust fear happiness sadness and surprise) based on the FacialAction Coding System (FACS) Because CK+ does not providespecified training validation and test sets the algorithms evaluatedon this database are not uniform For static-based methods themost common data selection method is to extract the last one tothree frames with peak formation and the first frame (neutral face)of each sequence Then the subjects are divided into n groups forperson-independent n-fold cross-validation experiments wherecommonly selected values of n are 5 8 and 10
MMI [34] [35] The MMI database is laboratory-controlledand includes 326 sequences from 32 subjects A total of 213sequences are labeled with six basic expressions (without ldquocon-temptrdquo) and 205 sequences are captured in frontal view Incontrast to CK+ sequences in MMI are onset-apex-offset labeledie the sequence begins with a neutral expression and reachespeak near the middle before returning to the neutral expressionFurthermore MMI has more challenging conditions ie there arelarge inter-personal variations because subjects perform the sameexpression non-uniformly and many of them wear accessories(eg glasses mustache) For experiments the most commonmethod is to choose the first frame (neutral face) and the three peakframes in each frontal sequence to conduct person-independent10-fold cross-validation
JAFFE [36] The Japanese Female Facial Expression (JAFFE)database is a laboratory-controlled image database that contains213 samples of posed expressions from 10 Japanese females Eachperson has 3˜4 images with each of six basic facial expressions(anger disgust fear happiness sadness and surprise) and oneimage with a neutral expression The database is challenging be-cause it contains few examples per subjectexpression Typicallyall the images are used for the leave-one-subject-out experiment
TFD [37]The Toronto Face Database (TFD) is an amalgama-tion of several facial expression datasets TFD contains 112234images 4178 of which are annotated with one of seven expres-sion labels anger disgust fear happiness sadness surprise andneutral The faces have already been detected and normalized to asize of 4848 such that all the subjects eyes are the same distanceapart and have the same vertical coordinates Five official folds areprovided in TFD each fold contains a training validation and testset consisting of 70 10 and 20 of the images respectively
FER2013 [21] The FER2013 database was introduced duringthe ICML 2013 Challenges in Representation Learning FER2013is a large-scale and unconstrained database collected automati-cally by the Google image search API All images have beenregistered and resized to 4848 pixels after rejecting wrongfullylabeled frames and adjusting the cropped region FER2013 con-tains 28709 training images 3589 validation images and 3589test images with seven expression labels (anger disgust fearhappiness sadness surprise and neutral)
AFEW [48] The Acted Facial Expressions in the Wild(AFEW) database was first established and introduced in [49]and has served as an evaluation platform for the annual Emo-
3
TABLE 1An overview of the facial expression datasets P = posed S = spontaneous Condit = Collection condition Elicit = Elicitation method
Database Samples Subject Condit Elicit Expression distribution Access
CK+ [33] 593 imagesequences
123 Lab P amp S 6 basic expressions plus contemptand neutral httpwwwconsortiumricmueduckagree
MMI [34] [35]740 imagesand 2900
videos25 Lab P 6 basic expressions plus neutral httpsmmifacedbeu
JAFFE [36] 213 images 10 Lab P 6 basic expressions plus neutral httpwwwkasrlorgjaffehtml
TFD [37] 112234images
NA Lab P 6 basic expressions plus neutral joshmplabucsdedu
FER-2013 [21] 35887 images NA Web P amp S 6 basic expressions plus neutral httpswwwkagglecomcchallenges-in-representation-learning-facial-expression-recognition-challenge
AFEW 70 [24] 1809 videos NA Movie P amp S 6 basic expressions plus neutral httpssitesgooglecomsiteemotiwchallenge
SFEW 20 [22] 1766 images NA Movie P amp S 6 basic expressions plus neutral httpscsanueduaufewemotiw2015html
Multi-PIE [38] 755370images
337 Lab P Smile surprised squint disgustscream and neutral httpwwwflintboxcompublicproject4742
BU-3DFE [39] 2500 images 100 Lab P 6 basic expressions plus neutral httpwwwcsbinghamtonedusimlijunResearch3DFE3DFE Analysishtml
Oulu-CASIA [40] 2880 imagesequences
80 Lab P 6 basic expressions httpwwwcseoulufiCMVDownloadsOulu-CASIA
RaFD [41] 1608 images 67 Lab P 6 basic expressions plus contemptand neutral httpwwwsocscirunl8180RaFD2RaFD
KDEF [42] 4900 images 70 Lab P 6 basic expressions plus neutral httpwwwemotionlabsekdef
EmotioNet [43] 1000000images
NA Web P amp S 23 basic expressions or compoundexpressions httpcbcsleceohio-stateedudbform emotionethtml
RAF-DB [44] [45] 29672 images NA Web P amp S 6 basic expressions plus neutral and12 compound expressions httpwwwwhdengcnRAFmodel1html
AffectNet [46]450000images
(labeled)NA Web P amp S 6 basic expressions plus neutral httpmohammadmahoorcomdatabases-codes
ExpW [47] 91793 images NA Web P amp S 6 basic expressions plus neutral httpmmlabiecuhkeduhkprojectssocialrelationindexhtml
tion Recognition In The Wild Challenge (EmotiW) since 2013AFEW contains video clips collected from different movies withspontaneous expressions various head poses occlusions and il-luminations AFEW is a temporal and multimodal database thatprovides with vastly different environmental conditions in bothaudio and video Samples are labeled with seven expressionsanger disgust fear happiness sadness surprise and neutral Theannotation of expressions have been continuously updated andreality TV show data have been continuously added The AFEW70 in EmotiW 2017 [24] is divided into three data partitions inan independent manner in terms of subject and movieTV sourceTrain (773 samples) Val (383 samples) and Test (653 samples)which ensures data in the three sets belong to mutually exclusivemovies and actors
SFEW [50] The Static Facial Expressions in the Wild(SFEW) was created by selecting static frames from the AFEWdatabase by computing key frames based on facial point clusteringThe most commonly used version SFEW 20 was the bench-marking data for the SReco sub-challenge in EmotiW 2015 [22]SFEW 20 has been divided into three sets Train (958 samples)Val (436 samples) and Test (372 samples) Each of the images isassigned to one of seven expression categories ie anger disgustfear neutral happiness sadness and surprise The expressionlabels of the training and validation sets are publicly availablewhereas those of the testing set are held back by the challengeorganizer
Multi-PIE [38] The CMU Multi-PIE database contains
755370 images from 337 subjects under 15 viewpoints and 19illumination conditions in up to four recording session Each facialimage is labeled with one of six expressions disgust neutralscream smile squint and surprise This dataset is typically usedfor multiview facial expression analysis
BU-3DFE [39] The Binghamton University 3D Facial Ex-pression (BU-3DFE) database contains 606 facial expression se-quences captured from 100 people For each subject six universalfacial expressions (anger disgust fear happiness sadness andsurprise) are elicited by various manners with multiple intensitiesSimilar to Multi-PIE this dataset is typically used for multiview3D facial expression analysis
Oulu-CASIA [40] The Oulu-CASIA database includes 2880image sequences collected from 80 subjects labeled with sixbasic emotion labels anger disgust fear happiness sadness andsurprise Each of the videos is captured with one of two imagingsystems ie near-infrared (NIR) or visible light (VIS) underthree different illumination conditions Similar to CK+ the firstframe is neutral and the last frame has the peak expressionTypically only the last three peak frames and the first frame(neutral face) from the 480 videos collected by the VIS Systemunder normal indoor illumination are employed for 10-fold cross-validation experiments
RaFD [41] The Radboud Faces Database (RaFD) islaboratory-controlled and has a total of 1608 images from 67subjects with three different gaze directions ie front left andright Each sample is labeled with one of eight expressions anger
4
contempt disgust fear happiness sadness surprise and neutralKDEF [42] The laboratory-controlled Karolinska Directed
Emotional Faces (KDEF) database was originally developed foruse in psychological and medical research KDEF consists ofimages from 70 actors with five different angles labeled with sixbasic facial expressions plus neutral
In addition to these commonly used datasets for basic emo-tion recognition several well-established and large-scale publiclyavailable facial expression databases collected from the Internetthat are suitable for training deep neural networks have emergedin the last two years
EmotioNet [43] EmotioNet is a large-scale database with onemillion facial expression images collected from the Internet Atotal of 950000 images were annotated by the automatic actionunit (AU) detection model in [43] and the remaining 25000images were manually annotated with 11 AUs The second track ofthe EmotioNet Challenge [51] provides six basic expressions andten compound expressions [52] and 2478 images with expressionlabels are available
RAF-DB [44] [45] The Real-world Affective Face Database(RAF-DB) is a real-world database that contains 29672 highlydiverse facial images downloaded from the Internet With man-ually crowd-sourced annotation and reliable estimation sevenbasic and eleven compound emotion labels are provided for thesamples Specifically 15339 images from the basic emotion setare divided into two groups (12271 training samples and 3068testing samples) for evaluation
AffectNet [46] AffectNet contains more than one millionimages from the Internet that were obtained by querying differentsearch engines using emotion-related tags It is by far the largestdatabase that provides facial expressions in two different emotionmodels (categorical model and dimensional model) of which450000 images have manually annotated labels for eight basicexpressions
ExpW [47] The Expression in-the-Wild Database (ExpW)contains 91793 faces downloaded using Google image searchEach of the face images was manually annotated as one of theseven basic expression categories Non-face images were removedin the annotation process
3 DEEP FACIAL EXPRESSION RECOGNITION
In this section we describe the three main steps that are commonin automatic deep FER ie pre-processing deep feature learningand deep feature classification We briefly summarize the widelyused algorithms for each step and recommend the existing state-of-the-art best practice implementations according to the referencedpapers
31 Pre-processing
Variations that are irrelevant to facial expressions such as differentbackgrounds illuminations and head poses are fairly common inunconstrained scenarios Therefore before training the deep neuralnetwork to learn meaningful features pre-processing is requiredto align and normalize the visual semantic information conveyedby the face
311 Face alignmentFace alignment is a traditional pre-processing step in many face-related recognition tasks We list some well-known approaches
TABLE 2Summary of different types of face alignment detectors that are widely
used in deep FER models
type points real-time speed performance used in
Holistic AAM [53] 68 7 fairpoor
generalization[54] [55]
Part-based MoT [56] 3968 7 slowfast
good [57] [58]DRMF [59] 66 7 [60] [61]
Cascadedregression
SDM [62] 49 3fast
very fastgood
very good
[16] [63]3000 fps [64] 68 3 [55]Incremental [65] 49 3 [66]
Deeplearning
cascaded CNN [67] 5 3 fast goodvery good
[68]MTCNN [69] 5 3 [70] [71]
and publicly available implementations that are widely used indeep FER
Given a series of training data the first step is to detect theface and then to remove background and non-face areas TheViola-Jones (VampJ) face detector [72] is a classic and widelyemployed implementation for face detection which is robust andcomputationally simple for detecting near-frontal faces
Although face detection is the only indispensable procedure toenable feature learning further face alignment using the coordi-nates of localized landmarks can substantially enhance the FERperformance [14] This step is crucial because it can reduce thevariation in face scale and in-plane rotation Table 2 investigatesfacial landmark detection algorithms widely-used in deep FER andcompares them in terms of efficiency and performance The ActiveAppearance Model (AAM) [53] is a classic generative model thatoptimizes the required parameters from holistic facial appearanceand global shape patterns In discriminative models the mixturesof trees (MoT) structured models [56] and the discriminativeresponse map fitting (DRMF) [59] use part-based approaches thatrepresent the face via the local appearance information aroundeach landmark Furthermore a number of discriminative modelsdirectly use a cascade of regression functions to map the imageappearance to landmark locations and have shown better resultseg the supervised descent method (SDM) [62] implementedin IntraFace [73] the face alignment 3000 fps [64] and theincremental face alignment [65] Recently deep networks havebeen widely exploited for face alignment Cascaded CNN [67]is the early work which predicts landmarks in a cascaded wayBased on this Tasks-Constrained Deep Convolutional Network(TCDCN) [74] and Multi-task CNN (MTCNN) [69] further lever-age multi-task learning to improve the performance In generalcascaded regression has become the most popular and state-of-the-art methods for face alignment as its high speed and accuracy
In contrast to using only one detector for face alignmentsome methods proposed to combine multiple detectors for betterlandmark estimation when processing faces in challenging uncon-strained environments Yu et al [75] concatenated three differentfacial landmark detectors to complement each other Kim et al[76] considered different inputs (original image and histogramequalized image) and different face detection models (VampJ [72]and MoT [56]) and the landmark set with the highest confidenceprovided by the Intraface [73] was selected
312 Data augmentationDeep neural networks require sufficient training data to ensuregeneralizability to a given recognition task However most pub-licly available databases for FER do not have a sufficient quantity
5
EmotionLabels
Training
TrainedModel
Anger
Neutral
Surprise
Happiness
ContemptDisgust
Fear
Sadness
RBM
119907
ℎ2
ℎ1
ℎ3
label
Convolutions
P1 LayerC1 Layer C2 Layer P2 Layer
Subsampling Convolutions Subsampling
FullConnected
CNN
119882 119882 119882 119882
119881
119926119957minus120783
119956119957minus120783
119880119961119957minus120783
119881
119926119957
119956119957
119880119961119957
119880119961119957+120783
119956119957+120783
119881
119926119957+120783
119900
119904 Unfold
119881
119880
119882
119909
Data Augmentation
Images ampSequences
Pre-processingInput
Face
Normalization
scaling rotation colors noiseshellip
Illumination Pose
Alignment
Input Images
Testing Deep Networks OutputTrainedModel
DBN
DAE
119933
Image visible variables
119945
119934
hidden variables
BipartiteStructure
RNN
Inp
ut Layer
Layer
Layer
bo
ttle
Ou
tpu
t Layer
Layer
Layer
Layer
Layer
hellip hellip
Code
As close as possible
119909 119909
11988211198821
1198791198822
1198822119879
Encoder Decoder
Data sample
Discriminator Generator
Yes No
Noise
Generatedsample
Data sample
GAN
Fig 2 The general pipeline of deep facial expression recognition systems
of images for training Therefore data augmentation is a vitalstep for deep FER Data augmentation techniques can be dividedinto two groups on-the-fly data augmentation and offline dataaugmentation
Usually the on-the-fly data augmentation is embedded in deeplearning toolkits to alleviate overfitting During the training stepthe input samples are randomly cropped from the four corners andcenter of the image and then flipped horizontally which can resultin a dataset that is ten times larger than the original training dataTwo common prediction modes are adopted during testing onlythe center patch of the face is used for prediction (eg [61] [77])or the prediction value is averaged over all ten crops (eg [76][78])
Besides the elementary on-the-fly data augmentation variousoffline data augmentation operations have been designed to furtherexpand data on both size and diversity The most frequently usedoperations include random perturbations and transforms eg rota-tion shifting skew scaling noise contrast and color jittering Forexample common noise models salt amp pepper and speckle noise[79] and Gaussian noise [80] [81] are employed to enlarge the datasize And for contrast transformation saturation and value (S andV components of the HSV color space) of each pixel are changed[70] for data augmentation Combinations of multiple operationscan generate more unseen training samples and make the networkmore robust to deviated and rotated faces In [82] the authorsapplied five image appearance filters (disk average Gaussianunsharp and motion filters) and six affine transform matrices thatwere formalized by adding slight geometric transformations to theidentity matrix In [75] a more comprehensive affine transformmatrix was proposed to randomly generate images that varied interms of rotation skew and scale Furthermore deep learningbased technology can be applied for data augmentation Forexample a synthetic data generation system with 3D convolutionalneural network (CNN) was created in [83] to confidentially createfaces with different levels of saturation in expression And thegenerative adversarial network (GAN) [84] can also be applied toaugment data by generating diverse appearances varying in posesand expressions (see Section 417)
313 Face normalization
Variations in illumination and head poses can introduce largechanges in images and hence impair the FER performanceTherefore we introduce two typical face normalization methodsto ameliorate these variations illumination normalization andpose normalization (frontalization)
Illumination normalization Illumination and contrast canvary in different images even from the same person with the sameexpression especially in unconstrained environments which canresult in large intra-class variances In [60] several frequentlyused illumination normalization algorithms namely isotropicdiffusion (IS)-based normalization discrete cosine transform(DCT)-based normalization [85] and difference of Gaussian(DoG) were evaluated for illumination normalization And [86]employed homomorphic filtering based normalization which hasbeen reported to yield the most consistent results among all othertechniques to remove illumination normalization Furthermorerelated studies have shown that histogram equalization combinedwith illumination normalization results in better face recognitionperformance than that achieved using illumination normalizationon it own And many studies in the literature of deep FER (eg[75] [79] [87] [88]) have employed histogram equalization toincrease the global contrast of images for pre-processing Thismethod is effective when the brightness of the background andforeground are similar However directly applying histogramequalization may overemphasize local contrast To solve thisproblem [89] proposed a weighted summation approach tocombine histogram equalization and linear mapping And in[79] the authors compared three different methods globalcontrast normalization (GCN) local normalization and histogramequalization GCN and histogram equalization were reportedto achieve the best accuracy for the training and testing stepsrespectively
Pose normalization Considerable pose variation is anothercommon and intractable problem in unconstrained settings Somestudies have employed pose normalization techniques to yield
6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

2
2017
2015
2013
2011
2009
2007
Zhao et al [15] (LBP-TOP SVM)
Shan et al [12] (LBP AdaBoost)CK+
MMI
FER2013
Zhi et al [19] (NMF)
Zhong et al [20] (Sparse learning)
Tang (CNN) [130] (winner of FER2013)
Kahou et al [57] (CNN DBN DAE) (winner of EmotiW 2013)
EmotioNet
RAF-DB
AffectNet
----gt----gt
EmotiW
Fan et al [108] (CNN-LSTM C3D) (winner of EmotiW 2016)
LP losstuplet cluster loss
Island losshellip hellip
HoloNetPPDNIACNNFaceNet2ExpNethellip hellip
Algorithm Dataset
Fig 1 The evolution of facial expression recognition in terms of datasetsand methods
FERDespite the powerful feature learning ability of deep learning
problems remain when applied to FER First deep neural networksrequire a large amount of training data to avoid overfittingHowever the existing facial expression databases are not sufficientto train the well-known neural network with deep architecture thatachieved the most promising results in object recognition tasksAdditionally high inter-subject variations exist due to differentpersonal attributes such as age gender ethnic backgrounds andlevel of expressiveness [32] In addition to subject identity biasvariations in pose illumination and occlusions are common inunconstrained facial expression scenarios These factors are non-linearly coupled with facial expressions and therefore strengthenthe requirement of deep networks to address the large intra-classvariability and to learn effective expression-specific representa-tions
In this paper we introduce recent advances in research onsolving the above problems for deep FER We examine the state-of-the-art results that have not been reviewed in previous surveypapers The rest of this paper is organized as follows Frequentlyused expression databases are introduced in Section 2 Section 3identifies three main steps required in a deep FER system anddescribes the related background Section 4 provides a detailedreview of novel neural network architectures and special networktraining tricks designed for FER based on static images anddynamic image sequences We then cover additional related issuesand other practical scenarios in Section 5 Section 6 discussessome of the challenges and opportunities in this field and identifiespotential future directions
2 FACIAL EXPRESSION DATABASES
Having sufficient labeled training data that include as manyvariations of the populations and environments as possible isimportant for the design of a deep expression recognition systemIn this section we discuss the publicly available databases thatcontain basic expressions and that are widely used in our reviewedpapers for deep learning algorithms evaluation We also introducenewly released databases that contain a large amount of affectiveimages collected from the real world to benefit the training ofdeep neural networks Table 1 provides an overview of thesedatasets including the main reference number of subjects number
of image or video samples collection environment expressiondistribution and additional information
CK+ [33] The Extended CohnKanade (CK+) database is themost extensively used laboratory-controlled database for evaluat-ing FER systems CK+ contains 593 video sequences from 123subjects The sequences vary in duration from 10 to 60 framesand show a shift from a neutral facial expression to the peakexpression Among these videos 327 sequences from 118 subjectsare labeled with seven basic expression labels (anger contemptdisgust fear happiness sadness and surprise) based on the FacialAction Coding System (FACS) Because CK+ does not providespecified training validation and test sets the algorithms evaluatedon this database are not uniform For static-based methods themost common data selection method is to extract the last one tothree frames with peak formation and the first frame (neutral face)of each sequence Then the subjects are divided into n groups forperson-independent n-fold cross-validation experiments wherecommonly selected values of n are 5 8 and 10
MMI [34] [35] The MMI database is laboratory-controlledand includes 326 sequences from 32 subjects A total of 213sequences are labeled with six basic expressions (without ldquocon-temptrdquo) and 205 sequences are captured in frontal view Incontrast to CK+ sequences in MMI are onset-apex-offset labeledie the sequence begins with a neutral expression and reachespeak near the middle before returning to the neutral expressionFurthermore MMI has more challenging conditions ie there arelarge inter-personal variations because subjects perform the sameexpression non-uniformly and many of them wear accessories(eg glasses mustache) For experiments the most commonmethod is to choose the first frame (neutral face) and the three peakframes in each frontal sequence to conduct person-independent10-fold cross-validation
JAFFE [36] The Japanese Female Facial Expression (JAFFE)database is a laboratory-controlled image database that contains213 samples of posed expressions from 10 Japanese females Eachperson has 3˜4 images with each of six basic facial expressions(anger disgust fear happiness sadness and surprise) and oneimage with a neutral expression The database is challenging be-cause it contains few examples per subjectexpression Typicallyall the images are used for the leave-one-subject-out experiment
TFD [37]The Toronto Face Database (TFD) is an amalgama-tion of several facial expression datasets TFD contains 112234images 4178 of which are annotated with one of seven expres-sion labels anger disgust fear happiness sadness surprise andneutral The faces have already been detected and normalized to asize of 4848 such that all the subjects eyes are the same distanceapart and have the same vertical coordinates Five official folds areprovided in TFD each fold contains a training validation and testset consisting of 70 10 and 20 of the images respectively
FER2013 [21] The FER2013 database was introduced duringthe ICML 2013 Challenges in Representation Learning FER2013is a large-scale and unconstrained database collected automati-cally by the Google image search API All images have beenregistered and resized to 4848 pixels after rejecting wrongfullylabeled frames and adjusting the cropped region FER2013 con-tains 28709 training images 3589 validation images and 3589test images with seven expression labels (anger disgust fearhappiness sadness surprise and neutral)
AFEW [48] The Acted Facial Expressions in the Wild(AFEW) database was first established and introduced in [49]and has served as an evaluation platform for the annual Emo-
3
TABLE 1An overview of the facial expression datasets P = posed S = spontaneous Condit = Collection condition Elicit = Elicitation method
Database Samples Subject Condit Elicit Expression distribution Access
CK+ [33] 593 imagesequences
123 Lab P amp S 6 basic expressions plus contemptand neutral httpwwwconsortiumricmueduckagree
MMI [34] [35]740 imagesand 2900
videos25 Lab P 6 basic expressions plus neutral httpsmmifacedbeu
JAFFE [36] 213 images 10 Lab P 6 basic expressions plus neutral httpwwwkasrlorgjaffehtml
TFD [37] 112234images
NA Lab P 6 basic expressions plus neutral joshmplabucsdedu
FER-2013 [21] 35887 images NA Web P amp S 6 basic expressions plus neutral httpswwwkagglecomcchallenges-in-representation-learning-facial-expression-recognition-challenge
AFEW 70 [24] 1809 videos NA Movie P amp S 6 basic expressions plus neutral httpssitesgooglecomsiteemotiwchallenge
SFEW 20 [22] 1766 images NA Movie P amp S 6 basic expressions plus neutral httpscsanueduaufewemotiw2015html
Multi-PIE [38] 755370images
337 Lab P Smile surprised squint disgustscream and neutral httpwwwflintboxcompublicproject4742
BU-3DFE [39] 2500 images 100 Lab P 6 basic expressions plus neutral httpwwwcsbinghamtonedusimlijunResearch3DFE3DFE Analysishtml
Oulu-CASIA [40] 2880 imagesequences
80 Lab P 6 basic expressions httpwwwcseoulufiCMVDownloadsOulu-CASIA
RaFD [41] 1608 images 67 Lab P 6 basic expressions plus contemptand neutral httpwwwsocscirunl8180RaFD2RaFD
KDEF [42] 4900 images 70 Lab P 6 basic expressions plus neutral httpwwwemotionlabsekdef
EmotioNet [43] 1000000images
NA Web P amp S 23 basic expressions or compoundexpressions httpcbcsleceohio-stateedudbform emotionethtml
RAF-DB [44] [45] 29672 images NA Web P amp S 6 basic expressions plus neutral and12 compound expressions httpwwwwhdengcnRAFmodel1html
AffectNet [46]450000images
(labeled)NA Web P amp S 6 basic expressions plus neutral httpmohammadmahoorcomdatabases-codes
ExpW [47] 91793 images NA Web P amp S 6 basic expressions plus neutral httpmmlabiecuhkeduhkprojectssocialrelationindexhtml
tion Recognition In The Wild Challenge (EmotiW) since 2013AFEW contains video clips collected from different movies withspontaneous expressions various head poses occlusions and il-luminations AFEW is a temporal and multimodal database thatprovides with vastly different environmental conditions in bothaudio and video Samples are labeled with seven expressionsanger disgust fear happiness sadness surprise and neutral Theannotation of expressions have been continuously updated andreality TV show data have been continuously added The AFEW70 in EmotiW 2017 [24] is divided into three data partitions inan independent manner in terms of subject and movieTV sourceTrain (773 samples) Val (383 samples) and Test (653 samples)which ensures data in the three sets belong to mutually exclusivemovies and actors
SFEW [50] The Static Facial Expressions in the Wild(SFEW) was created by selecting static frames from the AFEWdatabase by computing key frames based on facial point clusteringThe most commonly used version SFEW 20 was the bench-marking data for the SReco sub-challenge in EmotiW 2015 [22]SFEW 20 has been divided into three sets Train (958 samples)Val (436 samples) and Test (372 samples) Each of the images isassigned to one of seven expression categories ie anger disgustfear neutral happiness sadness and surprise The expressionlabels of the training and validation sets are publicly availablewhereas those of the testing set are held back by the challengeorganizer
Multi-PIE [38] The CMU Multi-PIE database contains
755370 images from 337 subjects under 15 viewpoints and 19illumination conditions in up to four recording session Each facialimage is labeled with one of six expressions disgust neutralscream smile squint and surprise This dataset is typically usedfor multiview facial expression analysis
BU-3DFE [39] The Binghamton University 3D Facial Ex-pression (BU-3DFE) database contains 606 facial expression se-quences captured from 100 people For each subject six universalfacial expressions (anger disgust fear happiness sadness andsurprise) are elicited by various manners with multiple intensitiesSimilar to Multi-PIE this dataset is typically used for multiview3D facial expression analysis
Oulu-CASIA [40] The Oulu-CASIA database includes 2880image sequences collected from 80 subjects labeled with sixbasic emotion labels anger disgust fear happiness sadness andsurprise Each of the videos is captured with one of two imagingsystems ie near-infrared (NIR) or visible light (VIS) underthree different illumination conditions Similar to CK+ the firstframe is neutral and the last frame has the peak expressionTypically only the last three peak frames and the first frame(neutral face) from the 480 videos collected by the VIS Systemunder normal indoor illumination are employed for 10-fold cross-validation experiments
RaFD [41] The Radboud Faces Database (RaFD) islaboratory-controlled and has a total of 1608 images from 67subjects with three different gaze directions ie front left andright Each sample is labeled with one of eight expressions anger
4
contempt disgust fear happiness sadness surprise and neutralKDEF [42] The laboratory-controlled Karolinska Directed
Emotional Faces (KDEF) database was originally developed foruse in psychological and medical research KDEF consists ofimages from 70 actors with five different angles labeled with sixbasic facial expressions plus neutral
In addition to these commonly used datasets for basic emo-tion recognition several well-established and large-scale publiclyavailable facial expression databases collected from the Internetthat are suitable for training deep neural networks have emergedin the last two years
EmotioNet [43] EmotioNet is a large-scale database with onemillion facial expression images collected from the Internet Atotal of 950000 images were annotated by the automatic actionunit (AU) detection model in [43] and the remaining 25000images were manually annotated with 11 AUs The second track ofthe EmotioNet Challenge [51] provides six basic expressions andten compound expressions [52] and 2478 images with expressionlabels are available
RAF-DB [44] [45] The Real-world Affective Face Database(RAF-DB) is a real-world database that contains 29672 highlydiverse facial images downloaded from the Internet With man-ually crowd-sourced annotation and reliable estimation sevenbasic and eleven compound emotion labels are provided for thesamples Specifically 15339 images from the basic emotion setare divided into two groups (12271 training samples and 3068testing samples) for evaluation
AffectNet [46] AffectNet contains more than one millionimages from the Internet that were obtained by querying differentsearch engines using emotion-related tags It is by far the largestdatabase that provides facial expressions in two different emotionmodels (categorical model and dimensional model) of which450000 images have manually annotated labels for eight basicexpressions
ExpW [47] The Expression in-the-Wild Database (ExpW)contains 91793 faces downloaded using Google image searchEach of the face images was manually annotated as one of theseven basic expression categories Non-face images were removedin the annotation process
3 DEEP FACIAL EXPRESSION RECOGNITION
In this section we describe the three main steps that are commonin automatic deep FER ie pre-processing deep feature learningand deep feature classification We briefly summarize the widelyused algorithms for each step and recommend the existing state-of-the-art best practice implementations according to the referencedpapers
31 Pre-processing
Variations that are irrelevant to facial expressions such as differentbackgrounds illuminations and head poses are fairly common inunconstrained scenarios Therefore before training the deep neuralnetwork to learn meaningful features pre-processing is requiredto align and normalize the visual semantic information conveyedby the face
311 Face alignmentFace alignment is a traditional pre-processing step in many face-related recognition tasks We list some well-known approaches
TABLE 2Summary of different types of face alignment detectors that are widely
used in deep FER models
type points real-time speed performance used in
Holistic AAM [53] 68 7 fairpoor
generalization[54] [55]
Part-based MoT [56] 3968 7 slowfast
good [57] [58]DRMF [59] 66 7 [60] [61]
Cascadedregression
SDM [62] 49 3fast
very fastgood
very good
[16] [63]3000 fps [64] 68 3 [55]Incremental [65] 49 3 [66]
Deeplearning
cascaded CNN [67] 5 3 fast goodvery good
[68]MTCNN [69] 5 3 [70] [71]
and publicly available implementations that are widely used indeep FER
Given a series of training data the first step is to detect theface and then to remove background and non-face areas TheViola-Jones (VampJ) face detector [72] is a classic and widelyemployed implementation for face detection which is robust andcomputationally simple for detecting near-frontal faces
Although face detection is the only indispensable procedure toenable feature learning further face alignment using the coordi-nates of localized landmarks can substantially enhance the FERperformance [14] This step is crucial because it can reduce thevariation in face scale and in-plane rotation Table 2 investigatesfacial landmark detection algorithms widely-used in deep FER andcompares them in terms of efficiency and performance The ActiveAppearance Model (AAM) [53] is a classic generative model thatoptimizes the required parameters from holistic facial appearanceand global shape patterns In discriminative models the mixturesof trees (MoT) structured models [56] and the discriminativeresponse map fitting (DRMF) [59] use part-based approaches thatrepresent the face via the local appearance information aroundeach landmark Furthermore a number of discriminative modelsdirectly use a cascade of regression functions to map the imageappearance to landmark locations and have shown better resultseg the supervised descent method (SDM) [62] implementedin IntraFace [73] the face alignment 3000 fps [64] and theincremental face alignment [65] Recently deep networks havebeen widely exploited for face alignment Cascaded CNN [67]is the early work which predicts landmarks in a cascaded wayBased on this Tasks-Constrained Deep Convolutional Network(TCDCN) [74] and Multi-task CNN (MTCNN) [69] further lever-age multi-task learning to improve the performance In generalcascaded regression has become the most popular and state-of-the-art methods for face alignment as its high speed and accuracy
In contrast to using only one detector for face alignmentsome methods proposed to combine multiple detectors for betterlandmark estimation when processing faces in challenging uncon-strained environments Yu et al [75] concatenated three differentfacial landmark detectors to complement each other Kim et al[76] considered different inputs (original image and histogramequalized image) and different face detection models (VampJ [72]and MoT [56]) and the landmark set with the highest confidenceprovided by the Intraface [73] was selected
312 Data augmentationDeep neural networks require sufficient training data to ensuregeneralizability to a given recognition task However most pub-licly available databases for FER do not have a sufficient quantity
5
EmotionLabels
Training
TrainedModel
Anger
Neutral
Surprise
Happiness
ContemptDisgust
Fear
Sadness
RBM
119907
ℎ2
ℎ1
ℎ3
label
Convolutions
P1 LayerC1 Layer C2 Layer P2 Layer
Subsampling Convolutions Subsampling
FullConnected
CNN
119882 119882 119882 119882
119881
119926119957minus120783
119956119957minus120783
119880119961119957minus120783
119881
119926119957
119956119957
119880119961119957
119880119961119957+120783
119956119957+120783
119881
119926119957+120783
119900
119904 Unfold
119881
119880
119882
119909
Data Augmentation
Images ampSequences
Pre-processingInput
Face
Normalization
scaling rotation colors noiseshellip
Illumination Pose
Alignment
Input Images
Testing Deep Networks OutputTrainedModel
DBN
DAE
119933
Image visible variables
119945
119934
hidden variables
BipartiteStructure
RNN
Inp
ut Layer
Layer
Layer
bo
ttle
Ou
tpu
t Layer
Layer
Layer
Layer
Layer
hellip hellip
Code
As close as possible
119909 119909
11988211198821
1198791198822
1198822119879
Encoder Decoder
Data sample
Discriminator Generator
Yes No
Noise
Generatedsample
Data sample
GAN
Fig 2 The general pipeline of deep facial expression recognition systems
of images for training Therefore data augmentation is a vitalstep for deep FER Data augmentation techniques can be dividedinto two groups on-the-fly data augmentation and offline dataaugmentation
Usually the on-the-fly data augmentation is embedded in deeplearning toolkits to alleviate overfitting During the training stepthe input samples are randomly cropped from the four corners andcenter of the image and then flipped horizontally which can resultin a dataset that is ten times larger than the original training dataTwo common prediction modes are adopted during testing onlythe center patch of the face is used for prediction (eg [61] [77])or the prediction value is averaged over all ten crops (eg [76][78])
Besides the elementary on-the-fly data augmentation variousoffline data augmentation operations have been designed to furtherexpand data on both size and diversity The most frequently usedoperations include random perturbations and transforms eg rota-tion shifting skew scaling noise contrast and color jittering Forexample common noise models salt amp pepper and speckle noise[79] and Gaussian noise [80] [81] are employed to enlarge the datasize And for contrast transformation saturation and value (S andV components of the HSV color space) of each pixel are changed[70] for data augmentation Combinations of multiple operationscan generate more unseen training samples and make the networkmore robust to deviated and rotated faces In [82] the authorsapplied five image appearance filters (disk average Gaussianunsharp and motion filters) and six affine transform matrices thatwere formalized by adding slight geometric transformations to theidentity matrix In [75] a more comprehensive affine transformmatrix was proposed to randomly generate images that varied interms of rotation skew and scale Furthermore deep learningbased technology can be applied for data augmentation Forexample a synthetic data generation system with 3D convolutionalneural network (CNN) was created in [83] to confidentially createfaces with different levels of saturation in expression And thegenerative adversarial network (GAN) [84] can also be applied toaugment data by generating diverse appearances varying in posesand expressions (see Section 417)
313 Face normalization
Variations in illumination and head poses can introduce largechanges in images and hence impair the FER performanceTherefore we introduce two typical face normalization methodsto ameliorate these variations illumination normalization andpose normalization (frontalization)
Illumination normalization Illumination and contrast canvary in different images even from the same person with the sameexpression especially in unconstrained environments which canresult in large intra-class variances In [60] several frequentlyused illumination normalization algorithms namely isotropicdiffusion (IS)-based normalization discrete cosine transform(DCT)-based normalization [85] and difference of Gaussian(DoG) were evaluated for illumination normalization And [86]employed homomorphic filtering based normalization which hasbeen reported to yield the most consistent results among all othertechniques to remove illumination normalization Furthermorerelated studies have shown that histogram equalization combinedwith illumination normalization results in better face recognitionperformance than that achieved using illumination normalizationon it own And many studies in the literature of deep FER (eg[75] [79] [87] [88]) have employed histogram equalization toincrease the global contrast of images for pre-processing Thismethod is effective when the brightness of the background andforeground are similar However directly applying histogramequalization may overemphasize local contrast To solve thisproblem [89] proposed a weighted summation approach tocombine histogram equalization and linear mapping And in[79] the authors compared three different methods globalcontrast normalization (GCN) local normalization and histogramequalization GCN and histogram equalization were reportedto achieve the best accuracy for the training and testing stepsrespectively
Pose normalization Considerable pose variation is anothercommon and intractable problem in unconstrained settings Somestudies have employed pose normalization techniques to yield
6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9
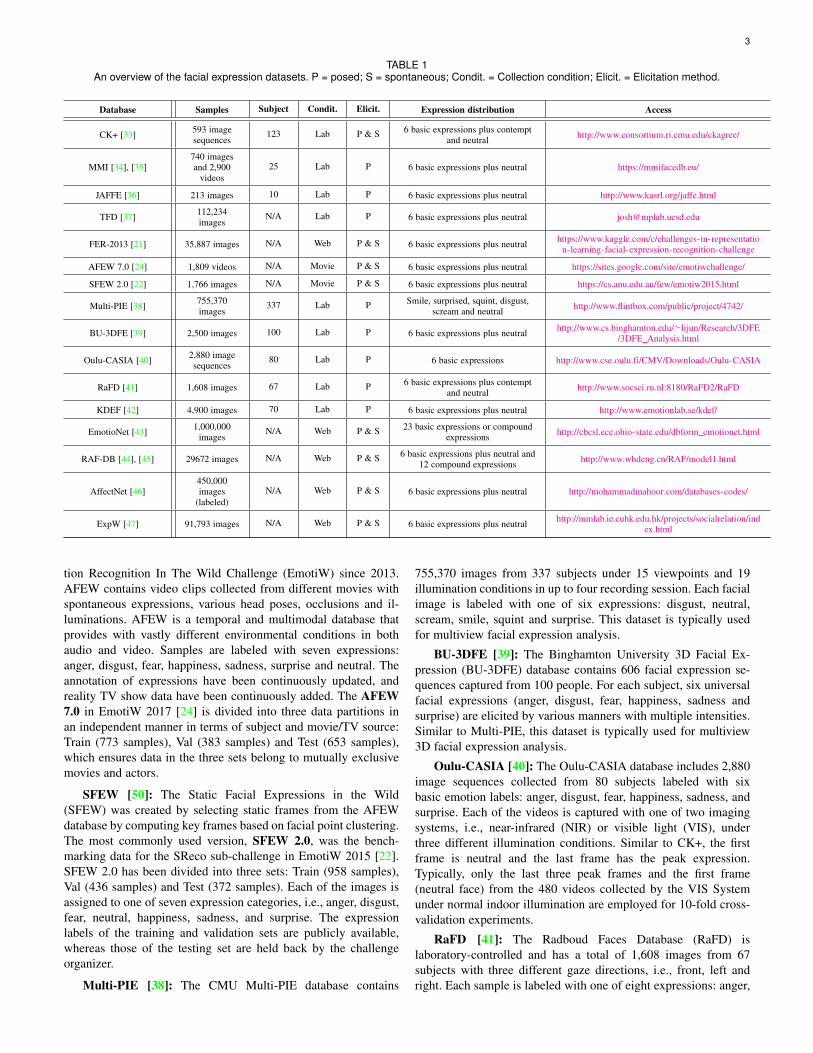
3
TABLE 1An overview of the facial expression datasets P = posed S = spontaneous Condit = Collection condition Elicit = Elicitation method
Database Samples Subject Condit Elicit Expression distribution Access
CK+ [33] 593 imagesequences
123 Lab P amp S 6 basic expressions plus contemptand neutral httpwwwconsortiumricmueduckagree
MMI [34] [35]740 imagesand 2900
videos25 Lab P 6 basic expressions plus neutral httpsmmifacedbeu
JAFFE [36] 213 images 10 Lab P 6 basic expressions plus neutral httpwwwkasrlorgjaffehtml
TFD [37] 112234images
NA Lab P 6 basic expressions plus neutral joshmplabucsdedu
FER-2013 [21] 35887 images NA Web P amp S 6 basic expressions plus neutral httpswwwkagglecomcchallenges-in-representation-learning-facial-expression-recognition-challenge
AFEW 70 [24] 1809 videos NA Movie P amp S 6 basic expressions plus neutral httpssitesgooglecomsiteemotiwchallenge
SFEW 20 [22] 1766 images NA Movie P amp S 6 basic expressions plus neutral httpscsanueduaufewemotiw2015html
Multi-PIE [38] 755370images
337 Lab P Smile surprised squint disgustscream and neutral httpwwwflintboxcompublicproject4742
BU-3DFE [39] 2500 images 100 Lab P 6 basic expressions plus neutral httpwwwcsbinghamtonedusimlijunResearch3DFE3DFE Analysishtml
Oulu-CASIA [40] 2880 imagesequences
80 Lab P 6 basic expressions httpwwwcseoulufiCMVDownloadsOulu-CASIA
RaFD [41] 1608 images 67 Lab P 6 basic expressions plus contemptand neutral httpwwwsocscirunl8180RaFD2RaFD
KDEF [42] 4900 images 70 Lab P 6 basic expressions plus neutral httpwwwemotionlabsekdef
EmotioNet [43] 1000000images
NA Web P amp S 23 basic expressions or compoundexpressions httpcbcsleceohio-stateedudbform emotionethtml
RAF-DB [44] [45] 29672 images NA Web P amp S 6 basic expressions plus neutral and12 compound expressions httpwwwwhdengcnRAFmodel1html
AffectNet [46]450000images
(labeled)NA Web P amp S 6 basic expressions plus neutral httpmohammadmahoorcomdatabases-codes
ExpW [47] 91793 images NA Web P amp S 6 basic expressions plus neutral httpmmlabiecuhkeduhkprojectssocialrelationindexhtml
tion Recognition In The Wild Challenge (EmotiW) since 2013AFEW contains video clips collected from different movies withspontaneous expressions various head poses occlusions and il-luminations AFEW is a temporal and multimodal database thatprovides with vastly different environmental conditions in bothaudio and video Samples are labeled with seven expressionsanger disgust fear happiness sadness surprise and neutral Theannotation of expressions have been continuously updated andreality TV show data have been continuously added The AFEW70 in EmotiW 2017 [24] is divided into three data partitions inan independent manner in terms of subject and movieTV sourceTrain (773 samples) Val (383 samples) and Test (653 samples)which ensures data in the three sets belong to mutually exclusivemovies and actors
SFEW [50] The Static Facial Expressions in the Wild(SFEW) was created by selecting static frames from the AFEWdatabase by computing key frames based on facial point clusteringThe most commonly used version SFEW 20 was the bench-marking data for the SReco sub-challenge in EmotiW 2015 [22]SFEW 20 has been divided into three sets Train (958 samples)Val (436 samples) and Test (372 samples) Each of the images isassigned to one of seven expression categories ie anger disgustfear neutral happiness sadness and surprise The expressionlabels of the training and validation sets are publicly availablewhereas those of the testing set are held back by the challengeorganizer
Multi-PIE [38] The CMU Multi-PIE database contains
755370 images from 337 subjects under 15 viewpoints and 19illumination conditions in up to four recording session Each facialimage is labeled with one of six expressions disgust neutralscream smile squint and surprise This dataset is typically usedfor multiview facial expression analysis
BU-3DFE [39] The Binghamton University 3D Facial Ex-pression (BU-3DFE) database contains 606 facial expression se-quences captured from 100 people For each subject six universalfacial expressions (anger disgust fear happiness sadness andsurprise) are elicited by various manners with multiple intensitiesSimilar to Multi-PIE this dataset is typically used for multiview3D facial expression analysis
Oulu-CASIA [40] The Oulu-CASIA database includes 2880image sequences collected from 80 subjects labeled with sixbasic emotion labels anger disgust fear happiness sadness andsurprise Each of the videos is captured with one of two imagingsystems ie near-infrared (NIR) or visible light (VIS) underthree different illumination conditions Similar to CK+ the firstframe is neutral and the last frame has the peak expressionTypically only the last three peak frames and the first frame(neutral face) from the 480 videos collected by the VIS Systemunder normal indoor illumination are employed for 10-fold cross-validation experiments
RaFD [41] The Radboud Faces Database (RaFD) islaboratory-controlled and has a total of 1608 images from 67subjects with three different gaze directions ie front left andright Each sample is labeled with one of eight expressions anger
4
contempt disgust fear happiness sadness surprise and neutralKDEF [42] The laboratory-controlled Karolinska Directed
Emotional Faces (KDEF) database was originally developed foruse in psychological and medical research KDEF consists ofimages from 70 actors with five different angles labeled with sixbasic facial expressions plus neutral
In addition to these commonly used datasets for basic emo-tion recognition several well-established and large-scale publiclyavailable facial expression databases collected from the Internetthat are suitable for training deep neural networks have emergedin the last two years
EmotioNet [43] EmotioNet is a large-scale database with onemillion facial expression images collected from the Internet Atotal of 950000 images were annotated by the automatic actionunit (AU) detection model in [43] and the remaining 25000images were manually annotated with 11 AUs The second track ofthe EmotioNet Challenge [51] provides six basic expressions andten compound expressions [52] and 2478 images with expressionlabels are available
RAF-DB [44] [45] The Real-world Affective Face Database(RAF-DB) is a real-world database that contains 29672 highlydiverse facial images downloaded from the Internet With man-ually crowd-sourced annotation and reliable estimation sevenbasic and eleven compound emotion labels are provided for thesamples Specifically 15339 images from the basic emotion setare divided into two groups (12271 training samples and 3068testing samples) for evaluation
AffectNet [46] AffectNet contains more than one millionimages from the Internet that were obtained by querying differentsearch engines using emotion-related tags It is by far the largestdatabase that provides facial expressions in two different emotionmodels (categorical model and dimensional model) of which450000 images have manually annotated labels for eight basicexpressions
ExpW [47] The Expression in-the-Wild Database (ExpW)contains 91793 faces downloaded using Google image searchEach of the face images was manually annotated as one of theseven basic expression categories Non-face images were removedin the annotation process
3 DEEP FACIAL EXPRESSION RECOGNITION
In this section we describe the three main steps that are commonin automatic deep FER ie pre-processing deep feature learningand deep feature classification We briefly summarize the widelyused algorithms for each step and recommend the existing state-of-the-art best practice implementations according to the referencedpapers
31 Pre-processing
Variations that are irrelevant to facial expressions such as differentbackgrounds illuminations and head poses are fairly common inunconstrained scenarios Therefore before training the deep neuralnetwork to learn meaningful features pre-processing is requiredto align and normalize the visual semantic information conveyedby the face
311 Face alignmentFace alignment is a traditional pre-processing step in many face-related recognition tasks We list some well-known approaches
TABLE 2Summary of different types of face alignment detectors that are widely
used in deep FER models
type points real-time speed performance used in
Holistic AAM [53] 68 7 fairpoor
generalization[54] [55]
Part-based MoT [56] 3968 7 slowfast
good [57] [58]DRMF [59] 66 7 [60] [61]
Cascadedregression
SDM [62] 49 3fast
very fastgood
very good
[16] [63]3000 fps [64] 68 3 [55]Incremental [65] 49 3 [66]
Deeplearning
cascaded CNN [67] 5 3 fast goodvery good
[68]MTCNN [69] 5 3 [70] [71]
and publicly available implementations that are widely used indeep FER
Given a series of training data the first step is to detect theface and then to remove background and non-face areas TheViola-Jones (VampJ) face detector [72] is a classic and widelyemployed implementation for face detection which is robust andcomputationally simple for detecting near-frontal faces
Although face detection is the only indispensable procedure toenable feature learning further face alignment using the coordi-nates of localized landmarks can substantially enhance the FERperformance [14] This step is crucial because it can reduce thevariation in face scale and in-plane rotation Table 2 investigatesfacial landmark detection algorithms widely-used in deep FER andcompares them in terms of efficiency and performance The ActiveAppearance Model (AAM) [53] is a classic generative model thatoptimizes the required parameters from holistic facial appearanceand global shape patterns In discriminative models the mixturesof trees (MoT) structured models [56] and the discriminativeresponse map fitting (DRMF) [59] use part-based approaches thatrepresent the face via the local appearance information aroundeach landmark Furthermore a number of discriminative modelsdirectly use a cascade of regression functions to map the imageappearance to landmark locations and have shown better resultseg the supervised descent method (SDM) [62] implementedin IntraFace [73] the face alignment 3000 fps [64] and theincremental face alignment [65] Recently deep networks havebeen widely exploited for face alignment Cascaded CNN [67]is the early work which predicts landmarks in a cascaded wayBased on this Tasks-Constrained Deep Convolutional Network(TCDCN) [74] and Multi-task CNN (MTCNN) [69] further lever-age multi-task learning to improve the performance In generalcascaded regression has become the most popular and state-of-the-art methods for face alignment as its high speed and accuracy
In contrast to using only one detector for face alignmentsome methods proposed to combine multiple detectors for betterlandmark estimation when processing faces in challenging uncon-strained environments Yu et al [75] concatenated three differentfacial landmark detectors to complement each other Kim et al[76] considered different inputs (original image and histogramequalized image) and different face detection models (VampJ [72]and MoT [56]) and the landmark set with the highest confidenceprovided by the Intraface [73] was selected
312 Data augmentationDeep neural networks require sufficient training data to ensuregeneralizability to a given recognition task However most pub-licly available databases for FER do not have a sufficient quantity
5
EmotionLabels
Training
TrainedModel
Anger
Neutral
Surprise
Happiness
ContemptDisgust
Fear
Sadness
RBM
119907
ℎ2
ℎ1
ℎ3
label
Convolutions
P1 LayerC1 Layer C2 Layer P2 Layer
Subsampling Convolutions Subsampling
FullConnected
CNN
119882 119882 119882 119882
119881
119926119957minus120783
119956119957minus120783
119880119961119957minus120783
119881
119926119957
119956119957
119880119961119957
119880119961119957+120783
119956119957+120783
119881
119926119957+120783
119900
119904 Unfold
119881
119880
119882
119909
Data Augmentation
Images ampSequences
Pre-processingInput
Face
Normalization
scaling rotation colors noiseshellip
Illumination Pose
Alignment
Input Images
Testing Deep Networks OutputTrainedModel
DBN
DAE
119933
Image visible variables
119945
119934
hidden variables
BipartiteStructure
RNN
Inp
ut Layer
Layer
Layer
bo
ttle
Ou
tpu
t Layer
Layer
Layer
Layer
Layer
hellip hellip
Code
As close as possible
119909 119909
11988211198821
1198791198822
1198822119879
Encoder Decoder
Data sample
Discriminator Generator
Yes No
Noise
Generatedsample
Data sample
GAN
Fig 2 The general pipeline of deep facial expression recognition systems
of images for training Therefore data augmentation is a vitalstep for deep FER Data augmentation techniques can be dividedinto two groups on-the-fly data augmentation and offline dataaugmentation
Usually the on-the-fly data augmentation is embedded in deeplearning toolkits to alleviate overfitting During the training stepthe input samples are randomly cropped from the four corners andcenter of the image and then flipped horizontally which can resultin a dataset that is ten times larger than the original training dataTwo common prediction modes are adopted during testing onlythe center patch of the face is used for prediction (eg [61] [77])or the prediction value is averaged over all ten crops (eg [76][78])
Besides the elementary on-the-fly data augmentation variousoffline data augmentation operations have been designed to furtherexpand data on both size and diversity The most frequently usedoperations include random perturbations and transforms eg rota-tion shifting skew scaling noise contrast and color jittering Forexample common noise models salt amp pepper and speckle noise[79] and Gaussian noise [80] [81] are employed to enlarge the datasize And for contrast transformation saturation and value (S andV components of the HSV color space) of each pixel are changed[70] for data augmentation Combinations of multiple operationscan generate more unseen training samples and make the networkmore robust to deviated and rotated faces In [82] the authorsapplied five image appearance filters (disk average Gaussianunsharp and motion filters) and six affine transform matrices thatwere formalized by adding slight geometric transformations to theidentity matrix In [75] a more comprehensive affine transformmatrix was proposed to randomly generate images that varied interms of rotation skew and scale Furthermore deep learningbased technology can be applied for data augmentation Forexample a synthetic data generation system with 3D convolutionalneural network (CNN) was created in [83] to confidentially createfaces with different levels of saturation in expression And thegenerative adversarial network (GAN) [84] can also be applied toaugment data by generating diverse appearances varying in posesand expressions (see Section 417)
313 Face normalization
Variations in illumination and head poses can introduce largechanges in images and hence impair the FER performanceTherefore we introduce two typical face normalization methodsto ameliorate these variations illumination normalization andpose normalization (frontalization)
Illumination normalization Illumination and contrast canvary in different images even from the same person with the sameexpression especially in unconstrained environments which canresult in large intra-class variances In [60] several frequentlyused illumination normalization algorithms namely isotropicdiffusion (IS)-based normalization discrete cosine transform(DCT)-based normalization [85] and difference of Gaussian(DoG) were evaluated for illumination normalization And [86]employed homomorphic filtering based normalization which hasbeen reported to yield the most consistent results among all othertechniques to remove illumination normalization Furthermorerelated studies have shown that histogram equalization combinedwith illumination normalization results in better face recognitionperformance than that achieved using illumination normalizationon it own And many studies in the literature of deep FER (eg[75] [79] [87] [88]) have employed histogram equalization toincrease the global contrast of images for pre-processing Thismethod is effective when the brightness of the background andforeground are similar However directly applying histogramequalization may overemphasize local contrast To solve thisproblem [89] proposed a weighted summation approach tocombine histogram equalization and linear mapping And in[79] the authors compared three different methods globalcontrast normalization (GCN) local normalization and histogramequalization GCN and histogram equalization were reportedto achieve the best accuracy for the training and testing stepsrespectively
Pose normalization Considerable pose variation is anothercommon and intractable problem in unconstrained settings Somestudies have employed pose normalization techniques to yield
6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

4
contempt disgust fear happiness sadness surprise and neutralKDEF [42] The laboratory-controlled Karolinska Directed
Emotional Faces (KDEF) database was originally developed foruse in psychological and medical research KDEF consists ofimages from 70 actors with five different angles labeled with sixbasic facial expressions plus neutral
In addition to these commonly used datasets for basic emo-tion recognition several well-established and large-scale publiclyavailable facial expression databases collected from the Internetthat are suitable for training deep neural networks have emergedin the last two years
EmotioNet [43] EmotioNet is a large-scale database with onemillion facial expression images collected from the Internet Atotal of 950000 images were annotated by the automatic actionunit (AU) detection model in [43] and the remaining 25000images were manually annotated with 11 AUs The second track ofthe EmotioNet Challenge [51] provides six basic expressions andten compound expressions [52] and 2478 images with expressionlabels are available
RAF-DB [44] [45] The Real-world Affective Face Database(RAF-DB) is a real-world database that contains 29672 highlydiverse facial images downloaded from the Internet With man-ually crowd-sourced annotation and reliable estimation sevenbasic and eleven compound emotion labels are provided for thesamples Specifically 15339 images from the basic emotion setare divided into two groups (12271 training samples and 3068testing samples) for evaluation
AffectNet [46] AffectNet contains more than one millionimages from the Internet that were obtained by querying differentsearch engines using emotion-related tags It is by far the largestdatabase that provides facial expressions in two different emotionmodels (categorical model and dimensional model) of which450000 images have manually annotated labels for eight basicexpressions
ExpW [47] The Expression in-the-Wild Database (ExpW)contains 91793 faces downloaded using Google image searchEach of the face images was manually annotated as one of theseven basic expression categories Non-face images were removedin the annotation process
3 DEEP FACIAL EXPRESSION RECOGNITION
In this section we describe the three main steps that are commonin automatic deep FER ie pre-processing deep feature learningand deep feature classification We briefly summarize the widelyused algorithms for each step and recommend the existing state-of-the-art best practice implementations according to the referencedpapers
31 Pre-processing
Variations that are irrelevant to facial expressions such as differentbackgrounds illuminations and head poses are fairly common inunconstrained scenarios Therefore before training the deep neuralnetwork to learn meaningful features pre-processing is requiredto align and normalize the visual semantic information conveyedby the face
311 Face alignmentFace alignment is a traditional pre-processing step in many face-related recognition tasks We list some well-known approaches
TABLE 2Summary of different types of face alignment detectors that are widely
used in deep FER models
type points real-time speed performance used in
Holistic AAM [53] 68 7 fairpoor
generalization[54] [55]
Part-based MoT [56] 3968 7 slowfast
good [57] [58]DRMF [59] 66 7 [60] [61]
Cascadedregression
SDM [62] 49 3fast
very fastgood
very good
[16] [63]3000 fps [64] 68 3 [55]Incremental [65] 49 3 [66]
Deeplearning
cascaded CNN [67] 5 3 fast goodvery good
[68]MTCNN [69] 5 3 [70] [71]
and publicly available implementations that are widely used indeep FER
Given a series of training data the first step is to detect theface and then to remove background and non-face areas TheViola-Jones (VampJ) face detector [72] is a classic and widelyemployed implementation for face detection which is robust andcomputationally simple for detecting near-frontal faces
Although face detection is the only indispensable procedure toenable feature learning further face alignment using the coordi-nates of localized landmarks can substantially enhance the FERperformance [14] This step is crucial because it can reduce thevariation in face scale and in-plane rotation Table 2 investigatesfacial landmark detection algorithms widely-used in deep FER andcompares them in terms of efficiency and performance The ActiveAppearance Model (AAM) [53] is a classic generative model thatoptimizes the required parameters from holistic facial appearanceand global shape patterns In discriminative models the mixturesof trees (MoT) structured models [56] and the discriminativeresponse map fitting (DRMF) [59] use part-based approaches thatrepresent the face via the local appearance information aroundeach landmark Furthermore a number of discriminative modelsdirectly use a cascade of regression functions to map the imageappearance to landmark locations and have shown better resultseg the supervised descent method (SDM) [62] implementedin IntraFace [73] the face alignment 3000 fps [64] and theincremental face alignment [65] Recently deep networks havebeen widely exploited for face alignment Cascaded CNN [67]is the early work which predicts landmarks in a cascaded wayBased on this Tasks-Constrained Deep Convolutional Network(TCDCN) [74] and Multi-task CNN (MTCNN) [69] further lever-age multi-task learning to improve the performance In generalcascaded regression has become the most popular and state-of-the-art methods for face alignment as its high speed and accuracy
In contrast to using only one detector for face alignmentsome methods proposed to combine multiple detectors for betterlandmark estimation when processing faces in challenging uncon-strained environments Yu et al [75] concatenated three differentfacial landmark detectors to complement each other Kim et al[76] considered different inputs (original image and histogramequalized image) and different face detection models (VampJ [72]and MoT [56]) and the landmark set with the highest confidenceprovided by the Intraface [73] was selected
312 Data augmentationDeep neural networks require sufficient training data to ensuregeneralizability to a given recognition task However most pub-licly available databases for FER do not have a sufficient quantity
5
EmotionLabels
Training
TrainedModel
Anger
Neutral
Surprise
Happiness
ContemptDisgust
Fear
Sadness
RBM
119907
ℎ2
ℎ1
ℎ3
label
Convolutions
P1 LayerC1 Layer C2 Layer P2 Layer
Subsampling Convolutions Subsampling
FullConnected
CNN
119882 119882 119882 119882
119881
119926119957minus120783
119956119957minus120783
119880119961119957minus120783
119881
119926119957
119956119957
119880119961119957
119880119961119957+120783
119956119957+120783
119881
119926119957+120783
119900
119904 Unfold
119881
119880
119882
119909
Data Augmentation
Images ampSequences
Pre-processingInput
Face
Normalization
scaling rotation colors noiseshellip
Illumination Pose
Alignment
Input Images
Testing Deep Networks OutputTrainedModel
DBN
DAE
119933
Image visible variables
119945
119934
hidden variables
BipartiteStructure
RNN
Inp
ut Layer
Layer
Layer
bo
ttle
Ou
tpu
t Layer
Layer
Layer
Layer
Layer
hellip hellip
Code
As close as possible
119909 119909
11988211198821
1198791198822
1198822119879
Encoder Decoder
Data sample
Discriminator Generator
Yes No
Noise
Generatedsample
Data sample
GAN
Fig 2 The general pipeline of deep facial expression recognition systems
of images for training Therefore data augmentation is a vitalstep for deep FER Data augmentation techniques can be dividedinto two groups on-the-fly data augmentation and offline dataaugmentation
Usually the on-the-fly data augmentation is embedded in deeplearning toolkits to alleviate overfitting During the training stepthe input samples are randomly cropped from the four corners andcenter of the image and then flipped horizontally which can resultin a dataset that is ten times larger than the original training dataTwo common prediction modes are adopted during testing onlythe center patch of the face is used for prediction (eg [61] [77])or the prediction value is averaged over all ten crops (eg [76][78])
Besides the elementary on-the-fly data augmentation variousoffline data augmentation operations have been designed to furtherexpand data on both size and diversity The most frequently usedoperations include random perturbations and transforms eg rota-tion shifting skew scaling noise contrast and color jittering Forexample common noise models salt amp pepper and speckle noise[79] and Gaussian noise [80] [81] are employed to enlarge the datasize And for contrast transformation saturation and value (S andV components of the HSV color space) of each pixel are changed[70] for data augmentation Combinations of multiple operationscan generate more unseen training samples and make the networkmore robust to deviated and rotated faces In [82] the authorsapplied five image appearance filters (disk average Gaussianunsharp and motion filters) and six affine transform matrices thatwere formalized by adding slight geometric transformations to theidentity matrix In [75] a more comprehensive affine transformmatrix was proposed to randomly generate images that varied interms of rotation skew and scale Furthermore deep learningbased technology can be applied for data augmentation Forexample a synthetic data generation system with 3D convolutionalneural network (CNN) was created in [83] to confidentially createfaces with different levels of saturation in expression And thegenerative adversarial network (GAN) [84] can also be applied toaugment data by generating diverse appearances varying in posesand expressions (see Section 417)
313 Face normalization
Variations in illumination and head poses can introduce largechanges in images and hence impair the FER performanceTherefore we introduce two typical face normalization methodsto ameliorate these variations illumination normalization andpose normalization (frontalization)
Illumination normalization Illumination and contrast canvary in different images even from the same person with the sameexpression especially in unconstrained environments which canresult in large intra-class variances In [60] several frequentlyused illumination normalization algorithms namely isotropicdiffusion (IS)-based normalization discrete cosine transform(DCT)-based normalization [85] and difference of Gaussian(DoG) were evaluated for illumination normalization And [86]employed homomorphic filtering based normalization which hasbeen reported to yield the most consistent results among all othertechniques to remove illumination normalization Furthermorerelated studies have shown that histogram equalization combinedwith illumination normalization results in better face recognitionperformance than that achieved using illumination normalizationon it own And many studies in the literature of deep FER (eg[75] [79] [87] [88]) have employed histogram equalization toincrease the global contrast of images for pre-processing Thismethod is effective when the brightness of the background andforeground are similar However directly applying histogramequalization may overemphasize local contrast To solve thisproblem [89] proposed a weighted summation approach tocombine histogram equalization and linear mapping And in[79] the authors compared three different methods globalcontrast normalization (GCN) local normalization and histogramequalization GCN and histogram equalization were reportedto achieve the best accuracy for the training and testing stepsrespectively
Pose normalization Considerable pose variation is anothercommon and intractable problem in unconstrained settings Somestudies have employed pose normalization techniques to yield
6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

5
EmotionLabels
Training
TrainedModel
Anger
Neutral
Surprise
Happiness
ContemptDisgust
Fear
Sadness
RBM
119907
ℎ2
ℎ1
ℎ3
label
Convolutions
P1 LayerC1 Layer C2 Layer P2 Layer
Subsampling Convolutions Subsampling
FullConnected
CNN
119882 119882 119882 119882
119881
119926119957minus120783
119956119957minus120783
119880119961119957minus120783
119881
119926119957
119956119957
119880119961119957
119880119961119957+120783
119956119957+120783
119881
119926119957+120783
119900
119904 Unfold
119881
119880
119882
119909
Data Augmentation
Images ampSequences
Pre-processingInput
Face
Normalization
scaling rotation colors noiseshellip
Illumination Pose
Alignment
Input Images
Testing Deep Networks OutputTrainedModel
DBN
DAE
119933
Image visible variables
119945
119934
hidden variables
BipartiteStructure
RNN
Inp
ut Layer
Layer
Layer
bo
ttle
Ou
tpu
t Layer
Layer
Layer
Layer
Layer
hellip hellip
Code
As close as possible
119909 119909
11988211198821
1198791198822
1198822119879
Encoder Decoder
Data sample
Discriminator Generator
Yes No
Noise
Generatedsample
Data sample
GAN
Fig 2 The general pipeline of deep facial expression recognition systems
of images for training Therefore data augmentation is a vitalstep for deep FER Data augmentation techniques can be dividedinto two groups on-the-fly data augmentation and offline dataaugmentation
Usually the on-the-fly data augmentation is embedded in deeplearning toolkits to alleviate overfitting During the training stepthe input samples are randomly cropped from the four corners andcenter of the image and then flipped horizontally which can resultin a dataset that is ten times larger than the original training dataTwo common prediction modes are adopted during testing onlythe center patch of the face is used for prediction (eg [61] [77])or the prediction value is averaged over all ten crops (eg [76][78])
Besides the elementary on-the-fly data augmentation variousoffline data augmentation operations have been designed to furtherexpand data on both size and diversity The most frequently usedoperations include random perturbations and transforms eg rota-tion shifting skew scaling noise contrast and color jittering Forexample common noise models salt amp pepper and speckle noise[79] and Gaussian noise [80] [81] are employed to enlarge the datasize And for contrast transformation saturation and value (S andV components of the HSV color space) of each pixel are changed[70] for data augmentation Combinations of multiple operationscan generate more unseen training samples and make the networkmore robust to deviated and rotated faces In [82] the authorsapplied five image appearance filters (disk average Gaussianunsharp and motion filters) and six affine transform matrices thatwere formalized by adding slight geometric transformations to theidentity matrix In [75] a more comprehensive affine transformmatrix was proposed to randomly generate images that varied interms of rotation skew and scale Furthermore deep learningbased technology can be applied for data augmentation Forexample a synthetic data generation system with 3D convolutionalneural network (CNN) was created in [83] to confidentially createfaces with different levels of saturation in expression And thegenerative adversarial network (GAN) [84] can also be applied toaugment data by generating diverse appearances varying in posesand expressions (see Section 417)
313 Face normalization
Variations in illumination and head poses can introduce largechanges in images and hence impair the FER performanceTherefore we introduce two typical face normalization methodsto ameliorate these variations illumination normalization andpose normalization (frontalization)
Illumination normalization Illumination and contrast canvary in different images even from the same person with the sameexpression especially in unconstrained environments which canresult in large intra-class variances In [60] several frequentlyused illumination normalization algorithms namely isotropicdiffusion (IS)-based normalization discrete cosine transform(DCT)-based normalization [85] and difference of Gaussian(DoG) were evaluated for illumination normalization And [86]employed homomorphic filtering based normalization which hasbeen reported to yield the most consistent results among all othertechniques to remove illumination normalization Furthermorerelated studies have shown that histogram equalization combinedwith illumination normalization results in better face recognitionperformance than that achieved using illumination normalizationon it own And many studies in the literature of deep FER (eg[75] [79] [87] [88]) have employed histogram equalization toincrease the global contrast of images for pre-processing Thismethod is effective when the brightness of the background andforeground are similar However directly applying histogramequalization may overemphasize local contrast To solve thisproblem [89] proposed a weighted summation approach tocombine histogram equalization and linear mapping And in[79] the authors compared three different methods globalcontrast normalization (GCN) local normalization and histogramequalization GCN and histogram equalization were reportedto achieve the best accuracy for the training and testing stepsrespectively
Pose normalization Considerable pose variation is anothercommon and intractable problem in unconstrained settings Somestudies have employed pose normalization techniques to yield
6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

6
frontal facial views for FER (eg [90] [91]) among which themost popular was proposed by Hassner et al [92] Specificallyafter localizing facial landmarks a 3D texture reference modelgeneric to all faces is generated to efficiently estimate visiblefacial components Then the initial frontalized face is synthesizedby back-projecting each input face image to the referencecoordinate system Alternatively Sagonas et al [93] proposed aneffective statistical model to simultaneously localize landmarksand convert facial poses using only frontal faces Very recently aseries of GAN-based deep models were proposed for frontal viewsynthesis (eg FF-GAN [94] TP-GAN [95]) and DR-GAN [96])and report promising performances
32 Deep networks for feature learning
Deep learning has recently become a hot research topic and hasachieved state-of-the-art performance for a variety of applications[97] Deep learning attempts to capture high-level abstractionsthrough hierarchical architectures of multiple nonlinear transfor-mations and representations In this section we briefly introducesome deep learning techniques that have been applied for FERThe traditional architectures of these deep neural networks areshown in Fig 2
321 Convolutional neural network (CNN)CNN has been extensively used in diverse computer vision ap-plications including FER At the beginning of the 21st centuryseveral studies in the FER literature [98] [99] found that theCNN is robust to face location changes and scale variations andbehaves better than the multilayer perceptron (MLP) in the caseof previously unseen face pose variations [100] employed theCNN to address the problems of subject independence as wellas translation rotation and scale invariance in the recognition offacial expressions
A CNN consists of three types of heterogeneous layersconvolutional layers pooling layers and fully connected layersThe convolutional layer has a set of learnable filters to convolvethrough the whole input image and produce various specific typesof activation feature maps The convolution operation is associ-ated with three main benefits local connectivity which learnscorrelations among neighboring pixels weight sharing in the samefeature map which greatly reduces the number of the parametersto be learned and shift-invariance to the location of the object Thepooling layer follows the convolutional layer and is used to reducethe spatial size of the feature maps and the computational cost ofthe network Average pooling and max pooling are the two mostcommonly used nonlinear down-sampling strategies for translationinvariance The fully connected layer is usually included at theend of the network to ensure that all neurons in the layer are fullyconnected to activations in the previous layer and to enable the2D feature maps to be converted into 1D feature maps for furtherfeature representation and classification
We list the configurations and characteristics of some well-known CNN models that have been applied for FER in Table 3Besides these networks several well-known derived frameworksalso exist In [101] [102] region-based CNN (R-CNN) [103]was used to learn features for FER In [104] Faster R-CNN[105] was used to identify facial expressions by generating high-quality region proposals Moreover Ji et al proposed 3D CNN[106] to capture motion information encoded in multiple adjacentframes for action recognition via 3D convolutions Tran et al [107]
TABLE 3Comparison of CNN models and their achievements DA = Data
augmentation BN = Batch normalization
AlexNet VGGNet GoogleNet ResNet[25] [26] [27] [28]
Year 2012 2014 2014 2015 of layersdagger 5+3 1316 + 3 21+1 151+1Kernel size 11 5 3 3 7 1 3 5 7 1 3 5
DA 3 3 3 3
Dropout 3 3 3 3
Inception 7 7 3 7
BN 7 7 7 3
Used in [110] [78] [111] [17] [78] [91] [112]dagger number of convolutional layers + fully connected layers size of the convolution kernel
proposed the well-designed C3D which exploits 3D convolutionson large-scale supervised training datasets to learn spatio-temporalfeatures Many related studies (eg [108] [109]) have employedthis network for FER involving image sequences
322 Deep belief network (DBN)DBN proposed by Hinton et al [113] is a graphical model thatlearns to extract a deep hierarchical representation of the trainingdata The traditional DBN is built with a stack of restricted Boltz-mann machines (RBMs) [114] which are two-layer generativestochastic models composed of a visible-unit layer and a hidden-unit layer These two layers in an RBM must form a bipartitegraph without lateral connections In a DBN the units in higherlayers are trained to learn the conditional dependencies among theunits in the adjacent lower layers except the top two layers whichhave undirected connections The training of a DBN contains twophases pre-training and fine-tuning [115] First an efficient layer-by-layer greedy learning strategy [116] is used to initialize thedeep network in an unsupervised manner which can prevent poorlocal optimal results to some extent without the requirement ofa large amount of labeled data During this procedure contrastivedivergence [117] is used to train RBMs in the DBN to estimate theapproximation gradient of the log-likelihood Then the parametersof the network and the desired output are fine-tuned with a simplegradient descent under supervision
323 Deep autoencoder (DAE)DAE was first introduced in [118] to learn efficient codings fordimensionality reduction In contrast to the previously mentionednetworks which are trained to predict target values the DAEis optimized to reconstruct its inputs by minimizing the recon-struction error Variations of the DAE exist such as the denoisingautoencoder [119] which recovers the original undistorted inputfrom partially corrupted data the sparse autoencoder network(DSAE) [120] which enforces sparsity on the learned featurerepresentation the contractive autoencoder (CAE1) [121] whichadds an activity dependent regularization to induce locally invari-ant features the convolutional autoencoder (CAE2) [122] whichuses convolutional (and optionally pooling) layers for the hiddenlayers in the network and the variational auto-encoder (VAE)[123] which is a directed graphical model with certain types oflatent variables to design complex generative models of data
7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

7
324 Recurrent neural network (RNN)RNN is a connectionist model that captures temporal informationand is more suitable for sequential data prediction with arbitrarylengths In addition to training the deep neural network in a singlefeed-forward manner RNNs include recurrent edges that spanadjacent time steps and share the same parameters across all stepsThe classic back propagation through time (BPTT) [124] is usedto train the RNN Long-short term memory (LSTM) introducedby Hochreiter amp Schmidhuber [125] is a special form of thetraditional RNN that is used to address the gradient vanishingand exploding problems that are common in training RNNs Thecell state in LSTM is regulated and controlled by three gatesan input gate that allows or blocks alteration of the cell state bythe input signal an output gate that enables or prevents the cellstate to affect other neurons and a forget gate that modulates thecellrsquos self-recurrent connection to accumulate or forget its previousstate By combining these three gates LSTM can model long-termdependencies in a sequence and has been widely employed forvideo-based expression recognition tasks
325 Generative Adversarial Network (GAN)GAN was first introduced by Goodfellow et al [84] in 2014 whichtrains models through a minimax two-player game between agenerator G(z) that generates synthesized input data by mappinglatents z to data space with z sim p(z) and a discriminator D(x)that assigns probability y = Dis(x) isin [01] that x is an actualtraining sample to tell apart real from fake input data The gen-erator and the discriminator are trained alternatively and can bothimprove themselves by minimizingmaximizing the binary crossentropy LGAN = log(D(x))+log(1minusD(G(z))) with respect toD G with x being a training sample and z sim p(z) Extensionsof GAN exist such as the cGAN [126] that adds a conditionalinformation to control the output of the generator the DCGAN[127] that adopts deconvolutional and convolutional neural net-works to implement G and D respectively the VAEGAN [128]that uses learned feature representations in the GAN discriminatoras basis for the VAE reconstruction objective and the InfoGAN[129] that can learn disentangled representations in a completelyunsupervised manner
33 Facial expression classificationAfter learning the deep features the final step of FER is to classifythe given face into one of the basic emotion categories
Unlike the traditional methods where the feature extractionstep and the feature classification step are independent deepnetworks can perform FER in an end-to-end way Specificallya loss layer is added to the end of the network to regulate theback-propagation error then the prediction probability of eachsample can be directly output by the network In CNN softmaxloss is the most common used function that minimizes the cross-entropy between the estimated class probabilities and the ground-truth distribution Alternatively [130] demonstrated the benefit ofusing a linear support vector machine (SVM) for the end-to-endtraining which minimizes a margin-based loss instead of the cross-entropy Likewise [131] investigated the adaptation of deep neuralforests (NFs) [132] which replaced the softmax loss layer withNFs and achieved competitive results for FER
Besides the end-to-end learning way another alternative is toemploy the deep neural network (particularly a CNN) as a featureextraction tool and then apply additional independent classifiers
such as support vector machine or random forest to the extractedrepresentations [133] [134] Furthermore [135] [136] showedthat the covariance descriptors computed on DCNN featuresand classification with Gaussian kernels on Symmetric PositiveDefinite (SPD) manifold are more efficient than the standardclassification with the softmax layer
4 THE STATE OF THE ART
In this section we review the existing novel deep neural networksdesigned for FER and the related training strategies proposedto address expression-specific problems We divide the workspresented in the literature into two main groups depending onthe type of data deep FER networks for static images and deepFER networks for dynamic image sequences We then providean overview of the current deep FER systems with respect tothe network architecture and performance Because some of theevaluated datasets do not provide explicit data groups for trainingvalidation and testing and the relevant studies may conductexperiments under different experimental conditions with differentdata we summarize the expression recognition performance alongwith information about the data selection and grouping methods
41 Deep FER networks for static images
A large volume of the existing studies conducted expression recog-nition tasks based on static images without considering temporalinformation due to the convenience of data processing and theavailability of the relevant training and test material We firstintroduce specific pre-training and fine-tuning skills for FER thenreview the novel deep neural networks in this field For each ofthe most frequently evaluated datasets Table 4 shows the currentstate-of-the-art methods in the field that are explicitly conducted ina person-independent protocol (subjects in the training and testingsets are separated)
411 Pre-training and fine-tuning
As mentioned before direct training of deep networks on rela-tively small facial expression datasets is prone to overfitting Tomitigate this problem many studies used additional task-orienteddata to pre-train their self-built networks from scratch or fine-tunedon well-known pre-trained models (eg AlexNet [25] VGG [26]VGG-face [148] and GoogleNet [27]) Kahou et al [57] [149]indicated that the use of additional data can help to obtain modelswith high capacity without overfitting thereby enhancing the FERperformance
To select appropriate auxiliary data large-scale face recogni-tion (FR) datasets (eg CASIA WebFace [150] Celebrity Facein the Wild (CFW) [151] FaceScrub dataset [152]) or relativelylarge FER datasets (FER2013 [21] and TFD [37]) are suitableKaya et al [153] suggested that VGG-Face which was trainedfor FR overwhelmed ImageNet which was developed for objectedrecognition Another interesting result observed by Knyazev etal [154] is that pre-training on larger FR data positively affectsthe emotion recognition accuracy and further fine-tuning withadditional FER datasets can help improve the performance
Instead of directly using the pre-trained or fine-tuned modelsto extract features on the target dataset a multistage fine-tuningstrategy [63] (see ldquoSubmission 3rdquo in Fig 3) can achieve betterperformance after the first-stage fine-tuning using FER2013 on
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9
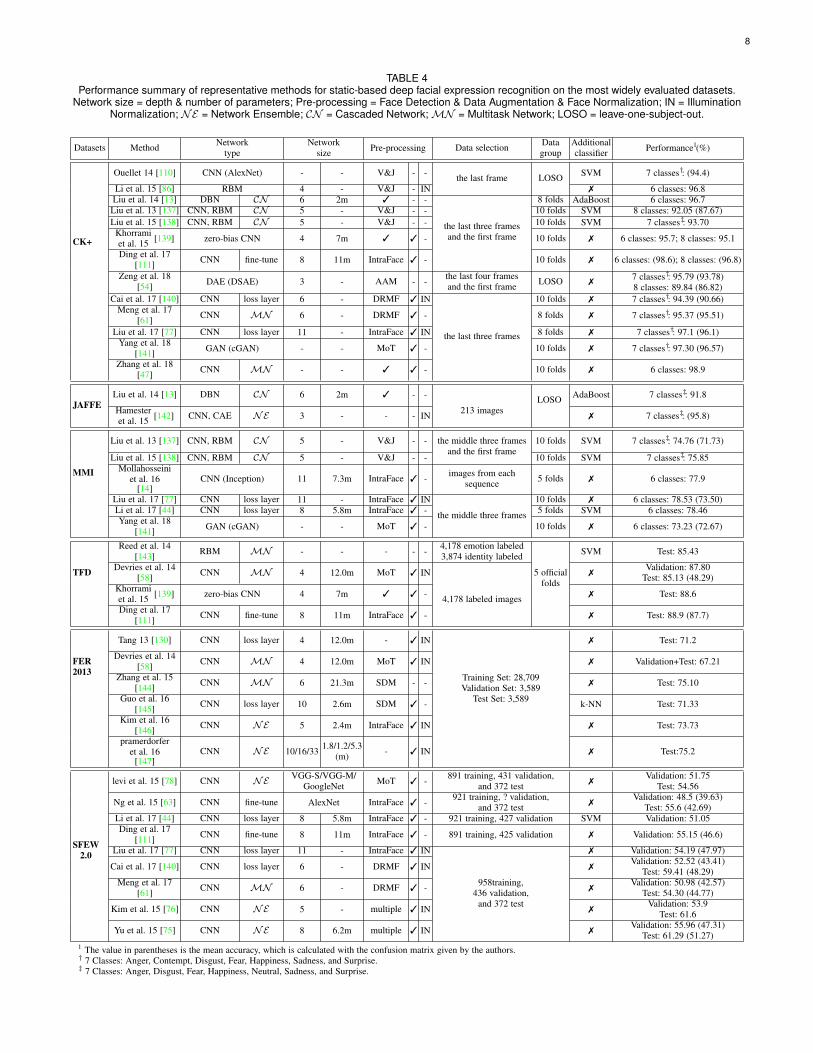
8
TABLE 4Performance summary of representative methods for static-based deep facial expression recognition on the most widely evaluated datasets
Network size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization NE = Network Ensemble CN = Cascaded NetworkMN = Multitask Network LOSO = leave-one-subject-out
Datasets Method Networktype
Networksize Pre-processing Data selection Data
groupAdditionalclassifier Performance1()
CK+
Ouellet 14 [110] CNN (AlexNet) - - VampJ - - the last frame LOSO SVM 7 classesdagger (944)
Li et al 15 [86] RBM 4 - VampJ - IN 7 6 classes 968Liu et al 14 [13] DBN CN 6 2m 3 - -
the last three framesand the first frame
8 folds AdaBoost 6 classes 967Liu et al 13 [137] CNN RBM CN 5 - VampJ - - 10 folds SVM 8 classes 9205 (8767)Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 9370
Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 10 folds 7 6 classes 957 8 classes 951
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 10 folds 7 6 classes (986) 8 classes (968)
Zeng et al 18[54] DAE (DSAE) 3 - AAM - - the last four frames
and the first frame LOSO 77 classesdagger 9579 (9378)8 classes 8984 (8682)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN
the last three frames
10 folds 7 7 classesdagger 9439 (9066)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 8 folds 7 7 classesdagger 9537 (9551)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN 8 folds 7 7 classesdagger 971 (961)Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 7 classesdagger 9730 (9657)
Zhang et al 18[47] CNN MN - - 3 3 - 10 folds 7 6 classes 989
JAFFELiu et al 14 [13] DBN CN 6 2m 3 - -
213 imagesLOSO AdaBoost 7 classesDagger 918
Hamesteret al 15 [142] CNN CAE NE 3 - - - IN 7 7 classesDagger (958)
MMI
Liu et al 13 [137] CNN RBM CN 5 - VampJ - - the middle three framesand the first frame
10 folds SVM 7 classesDagger 7476 (7173)
Liu et al 15 [138] CNN RBM CN 5 - VampJ - - 10 folds SVM 7 classesDagger 7585Mollahosseini
et al 16[14]
CNN (Inception) 11 73m IntraFace 3 - images from eachsequence 5 folds 7 6 classes 779
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
the middle three frames
10 folds 7 6 classes 7853 (7350)Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 5 folds SVM 6 classes 7846Yang et al 18
[141] GAN (cGAN) - - MoT 3 - 10 folds 7 6 classes 7323 (7267)
TFD
Reed et al 14[143] RBM MN - - - - - 4178 emotion labeled
3874 identity labeled
5 officialfolds
SVM Test 8543
Devries et al 14[58] CNN MN 4 120m MoT 3 IN
4178 labeled images
7Validation 8780
Test 8513 (4829)Khorramiet al 15 [139] zero-bias CNN 4 7m 3 3 - 7 Test 886
Ding et al 17[111] CNN fine-tune 8 11m IntraFace 3 - 7 Test 889 (877)
FER2013
Tang 13 [130] CNN loss layer 4 120m - 3 IN
Training Set 28709Validation Set 3589
Test Set 3589
7 Test 712
Devries et al 14[58] CNN MN 4 120m MoT 3 IN 7 Validation+Test 6721
Zhang et al 15[144] CNN MN 6 213m SDM - - 7 Test 7510
Guo et al 16[145] CNN loss layer 10 26m SDM 3 - k-NN Test 7133
Kim et al 16[146] CNN NE 5 24m IntraFace 3 IN 7 Test 7373
pramerdorferet al 16
[147]CNN NE 101633 181253
(m) - 3 IN 7 Test752
SFEW20
levi et al 15 [78] CNN NE VGG-SVGG-MGoogleNet MoT 3 - 891 training 431 validation
and 372 test 7Validation 5175
Test 5456
Ng et al 15 [63] CNN fine-tune AlexNet IntraFace 3 - 921 training validationand 372 test 7
Validation 485 (3963)Test 556 (4269)
Li et al 17 [44] CNN loss layer 8 58m IntraFace 3 - 921 training 427 validation SVM Validation 5105Ding et al 17
[111] CNN fine-tune 8 11m IntraFace 3 - 891 training 425 validation 7 Validation 5515 (466)
Liu et al 17 [77] CNN loss layer 11 - IntraFace 3 IN
958training436 validation
and 372 test
7 Validation 5419 (4797)
Cai et al 17 [140] CNN loss layer 6 - DRMF 3 IN 7Validation 5252 (4341)
Test 5941 (4829)Meng et al 17
[61] CNN MN 6 - DRMF 3 - 7Validation 5098 (4257)
Test 5430 (4477)
Kim et al 15 [76] CNN NE 5 - multiple 3 IN 7Validation 539
Test 616
Yu et al 15 [75] CNN NE 8 62m multiple 3 IN 7Validation 5596 (4731)
Test 6129 (5127)1 The value in parentheses is the mean accuracy which is calculated with the confusion matrix given by the authorsdagger 7 Classes Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes Anger Disgust Fear Happiness Neutral Sadness and Surprise
9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

9
Fig 3 Flowchart of the different fine-tuning combinations used in [63]Here ldquoFER28rdquo and ldquoFER32rdquo indicate different parts of the FER2013datasets ldquoEmotiWrdquo is the target dataset The proposed two-stage fine-tuning strategy (Submission 3) exhibited the best performance
Fig 4 Two-stage training flowchart in [111] In stage (a) the deeper facenet is frozen and provides the feature-level regularization that pushesthe convolutional features of the expression net to be close to the facenet by using the proposed distribution function Then in stage (b) tofurther improve the discriminativeness of the learned features randomlyinitialized fully connected layers are added and jointly trained with thewhole expression net using the expression label information
pre-trained models a second-stage fine-tuning based on the train-ing part of the target dataset (EmotiW) is employed to refine themodels to adapt to a more specific dataset (ie the target dataset)
Although pre-training and fine-tuning on external FR data canindirectly avoid the problem of small training data the networksare trained separately from the FER and the face-dominatedinformation remains in the learned features which may weakenthe networks ability to represent expressions To eliminate thiseffect a two-stage training algorithm FaceNet2ExpNet [111] wasproposed (see Fig 4) The fine-tuned face net serves as a goodinitialization for the expression net and is used to guide thelearning of the convolutional layers only And the fully connectedlayers are trained from scratch with expression information toregularize the training of the target FER net
Fig 5 Image intensities (left) and LBP codes (middle) [78] proposedmapping these values to a 3D metric space (right) as the input of CNNs
412 Diverse network input
Traditional practices commonly use the whole aligned face ofRGB images as the input of the network to learn features forFER However these raw data lack important information such ashomogeneous or regular textures and invariance in terms of imagescaling rotation occlusion and illumination which may representconfounding factors for FER Some methods have employeddiverse handcrafted features and their extensions as the networkinput to alleviate this problem
Low-level representations encode features from small regionsin the given RGB image then cluster and pool these featureswith local histograms which are robust to illumination variationsand small registration errors A novel mapped LBP feature [78](see Fig 5) was proposed for illumination-invariant FER Scale-invariant feature transform (SIFT) [155]) features that are robustagainst image scaling and rotation are employed [156] for multi-view FER tasks Combining different descriptors in outline tex-ture angle and color as the input data can also help enhance thedeep network performance [54] [157]
Part-based representations extract features according to thetarget task which remove noncritical parts from the whole imageand exploit key parts that are sensitive to the task [158] indicatedthat three regions of interest (ROI) ie eyebrows eyes and mouthare strongly related to facial expression changes and croppedthese regions as the input of DSAE Other researches proposedto automatically learn the key parts for facial expression For ex-ample [159] employed a deep multi-layer network [160] to detectthe saliency map which put intensities on parts demanding visualattention And [161] applied the neighbor-center difference vector(NCDV) [162] to obtain features with more intrinsic information
413 Auxiliary blocks amp layers
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
Based on the foundation architecture of CNN several studieshave proposed the addition of well-designed auxiliary blocks orlayers to enhance the expression-related representation capabilityof learned features
A novel CNN architecture HoloNet [90] was designed forFER where CReLU [163] was combined with the powerfulresidual structure [28] to increase the network depth withoutefficiency reduction and an inception-residual block [164] [165]was uniquely designed for FER to learn multi-scale features tocapture variations in expressions Another CNN model Super-vised Scoring Ensemble (SSE) [91] was introduced to enhance
10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

10
(a) Three different supervised blocks in [91] SS Block for shallow-layersupervision IS Block for intermediate-layer supervision and DS Block fordeep-layer supervision
(b) Island loss layer in [140] The island loss calculated at the featureextraction layer and the softmax loss calculated at the decision layer arecombined to supervise the CNN training
(c) (N+M)-tuple clusters loss layer in [77] During training the identity-aware hard-negative mining and online positive mining schemes are used todecrease the inter-identity variation in the same expression class
Fig 6 Representative functional layers or blocks that are specificallydesigned for deep facial expression recognition
the supervision degree for FER where three types of super-vised blocks were embedded in the early hidden layers of themainstream CNN for shallow intermediate and deep supervisionrespectively (see Fig 6(a))
And a feature selection network (FSN) [166] was designedby embedding a feature selection mechanism inside the AlexNetwhich automatically filters irrelevant features and emphasizescorrelated features according to learned feature maps of facial ex-pression Interestingly Zeng et al [167] pointed out that the incon-sistent annotations among different FER databases are inevitablewhich would damage the performance when the training set isenlarged by merging multiple datasets To address this problemthe authors proposed an Inconsistent Pseudo Annotations to LatentTruth (IPA2LT) framework In IPA2LT an end-to-end trainableLTNet is designed to discover the latent truths from the humanannotations and the machine annotations trained from differentdatasets by maximizing the log-likelihood of these inconsistentannotations
The traditional softmax loss layer in CNNs simply forcesfeatures of different classes to remain apart but FER in real-world scenarios suffers from not only high inter-class similaritybut also high intra-class variation Therefore several works haveproposed novel loss layers for FER Inspired by the center loss[168] which penalizes the distance between deep features andtheir corresponding class centers two variations were proposed toassist the supervision of the softmax loss for more discriminativefeatures for FER (1) island loss [140] was formalized to furtherincrease the pairwise distances between different class centers (seeFig 6(b)) and (2) locality-preserving loss (LP loss) [44] was
TABLE 5Three primary ensemble methods on the decision level
definitionused in
(example)
MajorityVoting
determine the class with the mostvotes using the predicted labelyielded from each individual
[76] [146][173]
SimpleAverage
determine the class with thehighest mean score using theposterior class probabilities
yielded from each individualwith the same weight
[76] [146][173]
WeightedAverage
determine the class with thehighest weighted mean score
using the posterior classprobabilities yielded from each
individual with different weights
[57] [78][147] [153]
formalized to pull the locally neighboring features of the sameclass together so that the intra-class local clusters of each class arecompact Besides based on the triplet loss [169] which requiresone positive example to be closer to the anchor than one negativeexample with a fixed gap two variations were proposed to replaceor assist the supervision of the softmax loss (1) exponentialtriplet-based loss [145] was formalized to give difficult samplesmore weight when updating the network and (2) (N+M)-tuplescluster loss [77] was formalized to alleviate the difficulty of anchorselection and threshold validation in the triplet loss for identity-invariant FER (see Fig 6(c) for details) Besides a feature loss[170] was proposed to provide complementary information for thedeep feature during early training stage
414 Network ensemblePrevious research suggested that assemblies of multiple networkscan outperform an individual network [171] Two key factorsshould be considered when implementing network ensembles (1)sufficient diversity of the networks to ensure complementarity and(2) an appropriate ensemble method that can effectively aggregatethe committee networks
In terms of the first factor different kinds of training data andvarious network parameters or architectures are considered to gen-erate diverse committees Several pre-processing methods [146]such as deformation and normalization and methods described inSection 412 can generate different data to train diverse networksBy changing the size of filters the number of neurons and thenumber of layers of the networks and applying multiple randomseeds for weight initialization the diversity of the networks canalso be enhanced [76] [172] Besides different architectures ofnetworks can be used to enhance the diversity For example aCNN trained in a supervised way and a convolutional autoencoder(CAE) trained in an unsupervised way were combined for networkensemble [142]
For the second factor each member of the committee networkscan be assembled at two different levels the feature level and thedecision level For feature-level ensembles the most commonlyadopted strategy is to concatenate features learned from differentnetworks [88] [174] For example [88] concatenated featureslearned from different networks to obtain a single feature vectorto describe the input image (see Fig 7(a)) For decision-level
11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

11
(a) Feature-level ensemble in [88] Three different features (fc5 of VGG13+ fc7 of VGG16 + pool of Resnet) after normalization are concatenated tocreate a single feature vector (FV) that describes the input frame
(b) Decision-level ensemble in [76] A 3-level hierarchical committee archi-tecture with hybrid decision-level fusions was proposed to obtain sufficientdecision diversity
Fig 7 Representative network ensemble systems at the feature leveland decision level
ensembles three widely-used rules are applied majority votingsimple average and weighted average A summary of these threemethods is provided in Table 5 Because the weighted average ruleconsiders the importance and confidence of each individual manyweighted average methods have been proposed to find an optimalset of weights for network ensemble [57] proposed a randomsearch method to weight the model predictions for each emotiontype [75] used the log-likelihood loss and hinge loss to adaptivelyassign different weights to each network [76] proposed an ex-ponentially weighted average based on the validation accuracy toemphasize qualified individuals (see Fig 7(b)) [172] used a CNNto learn weights for each individual model
415 Multitask networksMany existing networks for FER focus on a single task andlearn features that are sensitive to expressions without consideringinteractions among other latent factors However in the real worldFER is intertwined with various factors such as head poseillumination and subject identity (facial morphology) To solvethis problem multitask leaning is introduced to transfer knowledgefrom other relevant tasks and to disentangle nuisance factors
Reed et al [143] constructed a higher-order Boltzmann ma-chine (disBM) to learn manifold coordinates for the relevantfactors of expressions and proposed training strategies for dis-entangling so that the expression-related hidden units are invariantto face morphology Other works [58] [175] suggested thatsimultaneously conducted FER with other tasks such as faciallandmark localization and facial AUs [176] detection can jointlyimprove FER performance
Besides several works [61] [68] employed multitask learn-ing for identity-invariant FER In [61] an identity-aware CNN(IACNN) with two identical sub-CNNs was proposed One streamused expression-sensitive contrastive loss to learn expression-discriminative features and the other stream used identity-
Fig 8 Representative multitask network for FER In the proposedMSCNN [68] a pair of images is sent into the MSCNN during trainingThe expression recognition task with cross-entropy loss which learnsfeatures with large between-expression variation and the face verifi-cation task with contrastive loss which reduces the variation in within-expression features are combined to train the MSCNN
Fig 9 Representative cascaded network for FER The proposed AU-aware deep network (AUDN) [137] is composed of three sequentialmodules in the first module a 2-layer CNN is trained to generate anover-complete representation encoding all expression-specific appear-ance variations over all possible locations in the second module anAU-aware receptive field layer is designed to search subsets of theover-complete representation in the last module a multilayer RBM isexploited to learn hierarchical features
sensitive contrastive loss to learn identity-related features foridentity-invariant FER In [68] a multisignal CNN (MSCNN)which was trained under the supervision of both FER and faceverification tasks was proposed to force the model to focus on ex-pression information (see Fig 8) Furthermore an all-in-one CNNmodel [177] was proposed to simultaneously solve a diverse setof face analysis tasks including smile detection The network wasfirst initialized using the weight pre-trained on face recognitionthen task-specific sub-networks were branched out from differentlayers with domain-based regularization by training on multipledatasets Specifically as smile detection is a subject-independenttask that relies more on local information available from the lowerlayers the authors proposed to fuse the lower convolutional layersto form a generic representation for smile detection Conventionalsupervised multitask learning requires training samples labeled forall tasks To relax this [47] proposed a novel attribute propagationmethod which can leverage the inherent correspondences betweenfacial expression and other heterogeneous attributes despite thedisparate distributions of different datasets
416 Cascaded networks
In a cascaded network various modules for different tasks arecombined sequentially to construct a deeper network where theoutputs of the former modules are utilized by the latter modulesRelated studies have proposed combinations of different structuresto learn a hierarchy of features through which factors of variationthat are unrelated with expressions can be gradually filtered out
12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

12
Most commonly different networks or learning methods arecombined sequentially and individually and each of them con-tributes differently and hierarchically In [178] DBNs were trainedto first detect faces and to detect expression-related areas Thenthese parsed face components were classified by a stacked autoen-coder In [179] a multiscale contractive convolutional network(CCNET) was proposed to obtain local-translation-invariant (LTI)representations Then contractive autoencoder was designed to hi-erarchically separate out the emotion-related factors from subjectidentity and pose In [137] [138] over-complete representationswere first learned using CNN architecture then a multilayer RBMwas exploited to learn higher-level features for FER (see Fig9) Instead of simply concatenating different networks Liu et al[13] presented a boosted DBN (BDBN) that iteratively performedfeature representation feature selection and classifier constructionin a unified loopy state Compared with the concatenation withoutfeedback this loopy framework propagates backward the classi-fication error to initiate the feature selection process alternatelyuntil convergence Thus the discriminative ability for FER can besubstantially improved during this iteration
417 Generative adversarial networks (GANs)
Recently GAN-based methods have been successfully used inimage synthesis to generate impressively realistic faces numbersand a variety of other image types which are beneficial to train-ing data augmentation and the corresponding recognition tasksSeveral works have proposed novel GAN-based models for pose-invariant FER and identity-invariant FER
For pose-invariant FER Lai et al [180] proposed a GAN-based face frontalization framework where the generator frontal-izes input face images while preserving the identity and expressioncharacteristics and the discriminator distinguishes the real imagesfrom the generated frontal face images And Zhang et al [181]proposed a GAN-based model that can generate images withdifferent expressions under arbitrary poses for multi-view FERFor identity-invariant FER Yang et al [182] proposed an Identity-Adaptive Generation (IA-gen) model with two parts The upperpart generates images of the same subject with different expres-sions using cGANs respectively Then the lower part conductsFER for each single identity sub-space without involving otherindividuals thus identity variations can be well alleviated Chen etal [183] proposed a Privacy-Preserving Representation-LearningVariational GAN (PPRL-VGAN) that combines VAE and GANto learn an identity-invariant representation that is explicitlydisentangled from the identity information and generative forexpression-preserving face image synthesis Yang et al [141]proposed a De-expression Residue Learning (DeRL) procedure toexplore the expressive information which is filtered out during thede-expression process but still embedded in the generator Thenthe model extracted this information from the generator directly tomitigate the influence of subject variations and improve the FERperformance
418 Discussion
The existing well-constructed deep FER systems focus on two keyissues the lack of plentiful diverse training data and expression-unrelated variations such as illumination head pose and identityTable 6 shows relative advantages and disadvantages of thesedifferent types of methods with respect to two open issues (datasize requirement and expression-unrelated variations) and other
focuses (computation efficiency performance and difficulty ofnetwork training)
Pre-training and fine-tuning have become mainstream indeep FER to solve the problem of insufficient training data andoverfitting A practical technique that proved to be particularlyuseful is pre-training and fine-tuning the network in multiplestages using auxiliary data from large-scale objection or facerecognition datasets to small-scale FER datasets ie from large tosmall and from general to specific However when compared withthe end-to-end training framework the representational structurethat are unrelated to expressions are still remained in the off-the-shelf pre-trained model such as the large domain gap with theobjection net [153] and the subject identification distraction in theface net [111] Thus the extracted features are usually vulnerableto identity variations and the performance would be degradedNoticeably with the advent of large-scale in-the-wild FER datasets(eg AffectNet and RAF-DB) the end-to-end training usingdeep networks with moderate size can also achieve competitiveperformances [45] [167]
In addition to directly using the raw image data to train thedeep network diverse pre-designed features are recommended tostrengthen the networkrsquos robustness to common distractions (egillumination head pose and occlusion) and to force the networkto focus more on facial areas with expressive information More-over the use of multiple heterogeneous input data can indirectlyenlarge the data size However the problem of identity bias iscommonly ignored in this methods Moreover generating diversedata accounts for additional time consuming and combining thesemultiple data can lead to high dimension which may influence thecomputational efficiency of the network
Training a deep and wide network with a large number ofhidden layers and flexible filters is an effective way to learndeep high-level features that are discriminative for the target taskHowever this process is vulnerable to the size of training data andcan underperform if insufficient training data is available to learnthe new parameters Integrating multiple relatively small networksin parallel or in series is a natural research direction to overcomethis problem Network ensemble integrates diverse networks atthe feature or decision level to combine their advantages whichis usually applied in emotion competitions to help boost theperformance However designing different kinds of networksto compensate each other obviously enlarge the computationalcost and the storage requirement Moreover the weight of eachsub-network is usually learned according to the performance onoriginal training data leading to overfitting on newly unseentesting data Multitask networks jointly train multiple networkswith consideration of interactions between the target FER task andother secondary tasks such as facial landmark localization facialAU recognition and face verification thus the expression-unrelatedfactors including identity bias can be well disentangled Thedownside of this method is that it requires labeled data from alltasks and the training becomes increasingly cumbersome as moretasks are involved Alternatively cascaded networks sequentiallytrain multiple networks in a hierarchical approach in which casethe discriminative ability of the learned features are continuouslystrengthened In general this method can alleviate the overfittingproblem and in the meanwhile progressively disentangling fac-tors that are irrelevant to facial expression A deficiency worthsconsidering is that the sub-networks in most existing cascadedsystems are training individually without feedback and the end-to-end training strategy is preferable to enhance the training
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9
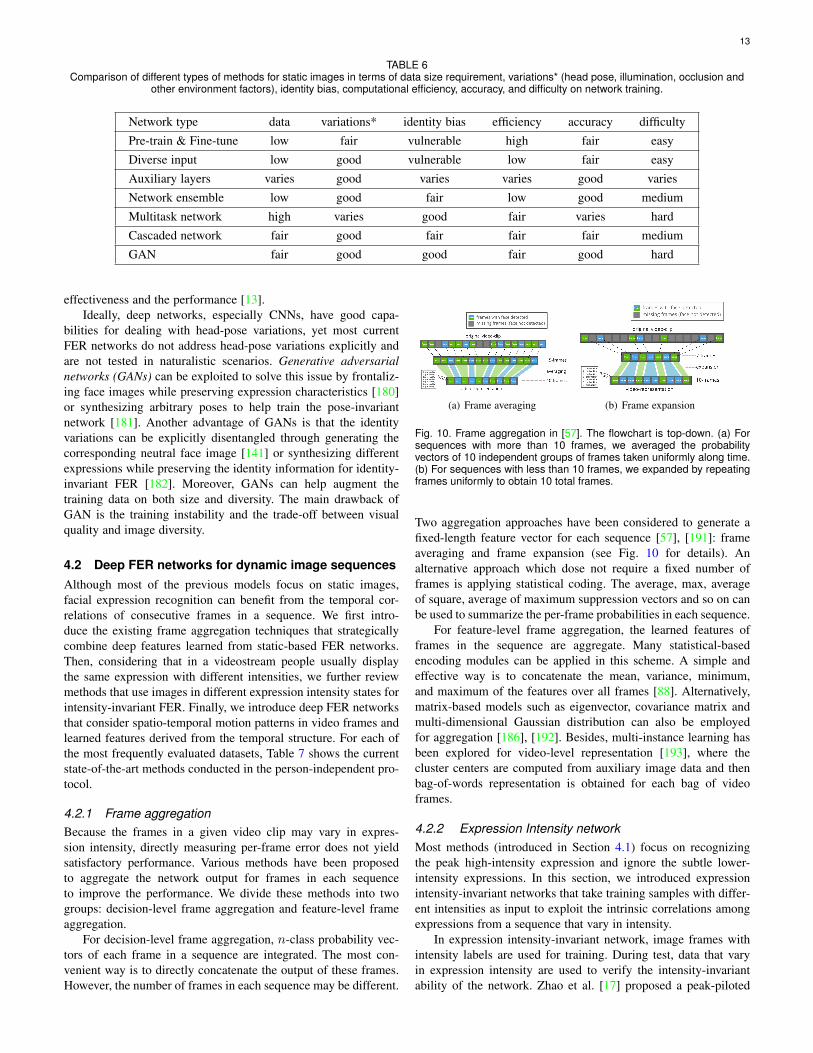
13
TABLE 6Comparison of different types of methods for static images in terms of data size requirement variations (head pose illumination occlusion and
other environment factors) identity bias computational efficiency accuracy and difficulty on network training
Network type data variations identity bias efficiency accuracy difficultyPre-train amp Fine-tune low fair vulnerable high fair easyDiverse input low good vulnerable low fair easyAuxiliary layers varies good varies varies good variesNetwork ensemble low good fair low good mediumMultitask network high varies good fair varies hardCascaded network fair good fair fair fair mediumGAN fair good good fair good hard
effectiveness and the performance [13]Ideally deep networks especially CNNs have good capa-
bilities for dealing with head-pose variations yet most currentFER networks do not address head-pose variations explicitly andare not tested in naturalistic scenarios Generative adversarialnetworks (GANs) can be exploited to solve this issue by frontaliz-ing face images while preserving expression characteristics [180]or synthesizing arbitrary poses to help train the pose-invariantnetwork [181] Another advantage of GANs is that the identityvariations can be explicitly disentangled through generating thecorresponding neutral face image [141] or synthesizing differentexpressions while preserving the identity information for identity-invariant FER [182] Moreover GANs can help augment thetraining data on both size and diversity The main drawback ofGAN is the training instability and the trade-off between visualquality and image diversity
42 Deep FER networks for dynamic image sequencesAlthough most of the previous models focus on static imagesfacial expression recognition can benefit from the temporal cor-relations of consecutive frames in a sequence We first intro-duce the existing frame aggregation techniques that strategicallycombine deep features learned from static-based FER networksThen considering that in a videostream people usually displaythe same expression with different intensities we further reviewmethods that use images in different expression intensity states forintensity-invariant FER Finally we introduce deep FER networksthat consider spatio-temporal motion patterns in video frames andlearned features derived from the temporal structure For each ofthe most frequently evaluated datasets Table 7 shows the currentstate-of-the-art methods conducted in the person-independent pro-tocol
421 Frame aggregationBecause the frames in a given video clip may vary in expres-sion intensity directly measuring per-frame error does not yieldsatisfactory performance Various methods have been proposedto aggregate the network output for frames in each sequenceto improve the performance We divide these methods into twogroups decision-level frame aggregation and feature-level frameaggregation
For decision-level frame aggregation n-class probability vec-tors of each frame in a sequence are integrated The most con-venient way is to directly concatenate the output of these framesHowever the number of frames in each sequence may be different
(a) Frame averaging (b) Frame expansion
Fig 10 Frame aggregation in [57] The flowchart is top-down (a) Forsequences with more than 10 frames we averaged the probabilityvectors of 10 independent groups of frames taken uniformly along time(b) For sequences with less than 10 frames we expanded by repeatingframes uniformly to obtain 10 total frames
Two aggregation approaches have been considered to generate afixed-length feature vector for each sequence [57] [191] frameaveraging and frame expansion (see Fig 10 for details) Analternative approach which dose not require a fixed number offrames is applying statistical coding The average max averageof square average of maximum suppression vectors and so on canbe used to summarize the per-frame probabilities in each sequence
For feature-level frame aggregation the learned features offrames in the sequence are aggregate Many statistical-basedencoding modules can be applied in this scheme A simple andeffective way is to concatenate the mean variance minimumand maximum of the features over all frames [88] Alternativelymatrix-based models such as eigenvector covariance matrix andmulti-dimensional Gaussian distribution can also be employedfor aggregation [186] [192] Besides multi-instance learning hasbeen explored for video-level representation [193] where thecluster centers are computed from auxiliary image data and thenbag-of-words representation is obtained for each bag of videoframes
422 Expression Intensity networkMost methods (introduced in Section 41) focus on recognizingthe peak high-intensity expression and ignore the subtle lower-intensity expressions In this section we introduced expressionintensity-invariant networks that take training samples with differ-ent intensities as input to exploit the intrinsic correlations amongexpressions from a sequence that vary in intensity
In expression intensity-invariant network image frames withintensity labels are used for training During test data that varyin expression intensity are used to verify the intensity-invariantability of the network Zhao et al [17] proposed a peak-piloted
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9
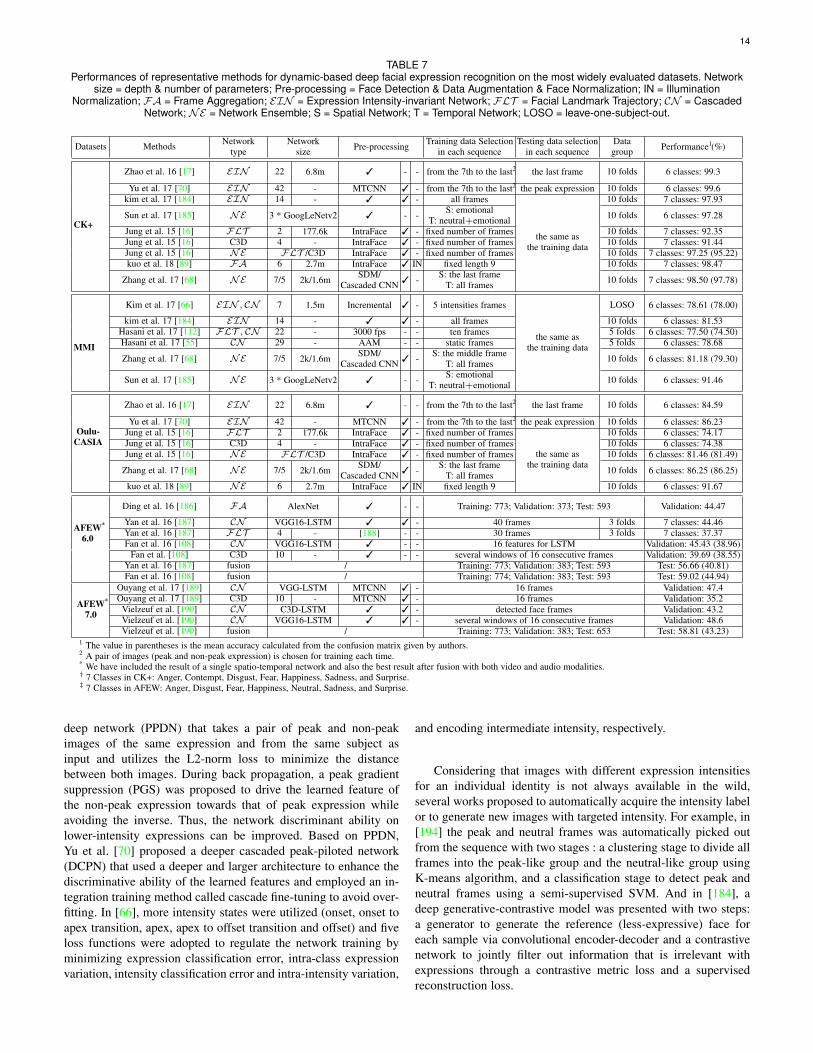
14
TABLE 7Performances of representative methods for dynamic-based deep facial expression recognition on the most widely evaluated datasets Network
size = depth amp number of parameters Pre-processing = Face Detection amp Data Augmentation amp Face Normalization IN = IlluminationNormalization FA = Frame Aggregation EIN = Expression Intensity-invariant Network FLT = Facial Landmark Trajectory CN = Cascaded
Network NE = Network Ensemble S = Spatial Network T = Temporal Network LOSO = leave-one-subject-out
Datasets Methods Networktype
Networksize Pre-processing Training data Selection
in each sequenceTesting data selection
in each sequenceDatagroup Performance1()
CK+
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 993
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 996kim et al 17 [184] EIN 14 - 3 3 - all frames
the same asthe training data
10 folds 7 classes 9793
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9728
Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames 10 folds 7 classes 9235Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 7 classes 9144Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 7 classes 9725 (9522)kuo et al 18 [89] FA 6 27m IntraFace 3 IN fixed length 9 10 folds 7 classes 9847
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 7 classes 9850 (9778)
MMI
Kim et al 17 [66] EIN CN 7 15m Incremental 3 - 5 intensities frames
the same asthe training data
LOSO 6 classes 7861 (7800)
kim et al 17 [184] EIN 14 - 3 3 - all frames 10 folds 6 classes 8153Hasani et al 17 [112] FLT CN 22 - 3000 fps - - ten frames 5 folds 6 classes 7750 (7450)Hasani et al 17 [55] CN 29 - AAM - - static frames 5 folds 6 classes 7868
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the middle frame
T all frames 10 folds 6 classes 8118 (7930)
Sun et al 17 [185] NE 3 GoogLeNetv2 3 - - S emotionalT neutral+emotional 10 folds 6 classes 9146
Oulu-CASIA
Zhao et al 16 [17] EIN 22 68m 3 - - from the 7th to the last2 the last frame 10 folds 6 classes 8459
Yu et al 17 [70] EIN 42 - MTCNN 3 - from the 7th to the last2 the peak expression 10 folds 6 classes 8623Jung et al 15 [16] FLT 2 1776k IntraFace 3 - fixed number of frames
the same asthe training data
10 folds 6 classes 7417Jung et al 15 [16] C3D 4 - IntraFace 3 - fixed number of frames 10 folds 6 classes 7438Jung et al 15 [16] NE FLT C3D IntraFace 3 - fixed number of frames 10 folds 6 classes 8146 (8149)
Zhang et al 17 [68] NE 75 2k16m SDMCascaded CNN 3 - S the last frame
T all frames 10 folds 6 classes 8625 (8625)
kuo et al 18 [89] NE 6 27m IntraFace 3 IN fixed length 9 10 folds 6 classes 9167
AFEW
60
Ding et al 16 [186] FA AlexNet 3 - - Training 773 Validation 373 Test 593 Validation 4447
Yan et al 16 [187] CN VGG16-LSTM 3 3 - 40 frames 3 folds 7 classes 4446Yan et al 16 [187] FLT 4 - [188] - - 30 frames 3 folds 7 classes 3737Fan et al 16 [108] CN VGG16-LSTM 3 - - 16 features for LSTM Validation 4543 (3896)
Fan et al [108] C3D 10 - 3 - - several windows of 16 consecutive frames Validation 3969 (3855)Yan et al 16 [187] fusion Training 773 Validation 383 Test 593 Test 5666 (4081)Fan et al 16 [108] fusion Training 774 Validation 383 Test 593 Test 5902 (4494)
AFEW
70
Ouyang et al 17 [189] CN VGG-LSTM MTCNN 3 - 16 frames Validation 474Ouyang et al 17 [189] C3D 10 - MTCNN 3 - 16 frames Validation 352
Vielzeuf et al [190] CN C3D-LSTM 3 3 - detected face frames Validation 432Vielzeuf et al [190] CN VGG16-LSTM 3 3 - several windows of 16 consecutive frames Validation 486Vielzeuf et al [190] fusion Training 773 Validation 383 Test 653 Test 5881 (4323)
1 The value in parentheses is the mean accuracy calculated from the confusion matrix given by authors2 A pair of images (peak and non-peak expression) is chosen for training each time We have included the result of a single spatio-temporal network and also the best result after fusion with both video and audio modalitiesdagger 7 Classes in CK+ Anger Contempt Disgust Fear Happiness Sadness and SurpriseDagger 7 Classes in AFEW Anger Disgust Fear Happiness Neutral Sadness and Surprise
deep network (PPDN) that takes a pair of peak and non-peakimages of the same expression and from the same subject asinput and utilizes the L2-norm loss to minimize the distancebetween both images During back propagation a peak gradientsuppression (PGS) was proposed to drive the learned feature ofthe non-peak expression towards that of peak expression whileavoiding the inverse Thus the network discriminant ability onlower-intensity expressions can be improved Based on PPDNYu et al [70] proposed a deeper cascaded peak-piloted network(DCPN) that used a deeper and larger architecture to enhance thediscriminative ability of the learned features and employed an in-tegration training method called cascade fine-tuning to avoid over-fitting In [66] more intensity states were utilized (onset onset toapex transition apex apex to offset transition and offset) and fiveloss functions were adopted to regulate the network training byminimizing expression classification error intra-class expressionvariation intensity classification error and intra-intensity variation
and encoding intermediate intensity respectively
Considering that images with different expression intensitiesfor an individual identity is not always available in the wildseveral works proposed to automatically acquire the intensity labelor to generate new images with targeted intensity For example in[194] the peak and neutral frames was automatically picked outfrom the sequence with two stages a clustering stage to divide allframes into the peak-like group and the neutral-like group usingK-means algorithm and a classification stage to detect peak andneutral frames using a semi-supervised SVM And in [184] adeep generative-contrastive model was presented with two stepsa generator to generate the reference (less-expressive) face foreach sample via convolutional encoder-decoder and a contrastivenetwork to jointly filter out information that is irrelevant withexpressions through a contrastive metric loss and a supervisedreconstruction loss
15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

15
Fig 11 The proposed PPDN in [17] During training PPDN is trained byjointly optimizing the L2-norm loss and the cross-entropy losses of twoexpression images During testing the PPDN takes one still image asinput for probability prediction
423 Deep spatio-temporal FER network
Although the frame aggregation can integrate frames in thevideo sequence the crucial temporal dependency is not explicitlyexploited By contrast the spatio-temporal FER network takesa range of frames in a temporal window as a single inputwithout prior knowledge of the expression intensity and utilizesboth textural and temporal information to encode more subtleexpressions
RNN and C3D RNN can robustly derive information fromsequences by exploiting the fact that feature vectors for successivedata are connected semantically and are therefore interdependentThe improved version LSTM is flexible to handle varying-lengthsequential data with lower computation cost Derived from RNNan RNN that is composed of ReLUs and initialized with theidentity matrix (IRNN) [195] was used to provide a simplermechanism for addressing the vanishing and exploding gradientproblems [87] And bidirectional RNNs (BRNNs) [196] wereemployed to learn the temporal relations in both the original andreversed directions [68] [187] Recently a Nested LSTM wasproposed in [71] with two sub-LSTMs Namely T-LSTM modelsthe temporal dynamics of the learned features and C-LSTMintegrates the outputs of all T-LSTMs together so as to encodethe multi-level features encoded in the intermediate layers of thenetwork
Compared with RNN CNN is more suitable for computervision applications hence its derivative C3D [107] which uses3D convolutional kernels with shared weights along the timeaxis instead of the traditional 2D kernels has been widely usedfor dynamic-based FER (eg [83] [108] [189] [197] [198])to capture the spatio-temporal features Based on C3D manyderived structures have been designed for FER In [199] 3D CNNwas incorporated with the DPM-inspired [200] deformable facialaction constraints to simultaneously encode dynamic motionand discriminative part-based representations (see Fig 12 fordetails) In [16] a deep temporal appearance network (DTAN)was proposed that employed 3D filters without weight sharingalong the time axis hence each filter can vary in importanceover time Likewise a weighted C3D was proposed [190] whereseveral windows of consecutive frames were extracted from each
Fig 12 The proposed 3DCNN-DAP [199] The input n-frame sequenceis convolved with 3D filters then 13 lowast c lowast k part filters corresponding to13 manually defined facial parts are used to convolve k feature maps forthe facial action part detection maps of c expression classes
sequence and weighted based on their prediction scores Insteadof directly using C3D for classification [109] employed C3D forspatio-temporal feature extraction and then cascaded with DBNfor prediction In [201] C3D was also used as a feature extractorfollowed by a NetVLAD layer [202] to aggregate the temporalinformation of the motion features by learning cluster centers
Facial landmark trajectory Related psychological studieshave shown that expressions are invoked by dynamic motionsof certain facial parts (eg eyes nose and mouth) that containthe most descriptive information for representing expressionsTo obtain more accurate facial actions for FER facial landmarktrajectory models have been proposed to capture the dynamicvariations of facial components from consecutive frames
To extract landmark trajectory representation the most directway is to concatenate coordinates of facial landmark pointsfrom frames over time with normalization to generate a one-dimensional trajectory signal for each sequence [16] or to forman image-like map as the input of CNN [187] Besides relativedistance variation of each landmark in consecutive frames canalso be used to capture the temporal information [203] Furtherpart-based model that divides facial landmarks into several partsaccording to facial physical structure and then separately feedsthem into the networks hierarchically is proved to be efficient forboth local low-level and global high-level feature encoding [68](see ldquoPHRNNrdquo in Fig 13) Instead of separately extracting thetrajectory features and then input them into the networks Hasaniet al [112] incorporated the trajectory features by replacing theshortcut in the residual unit of the original 3D Inception-ResNetwith element-wise multiplication of facial landmarks and the inputtensor of the residual unit Thus the landmark based network canbe trained end-to-end
Cascaded networks By combining the powerful perceptualvision representations learned from CNNs with the strength ofLSTM for variable-length inputs and outputs Donahue et al[204] proposed a both spatially and temporally deep model whichcascades the outputs of CNNs with LSTMs for various visiontasks involving time-varying inputs and outputs Similar to thishybrid network many cascaded networks have been proposed forFER (eg [66] [108] [190] [205])
Instead of CNN [206] employed a convolutional sparseautoencoder for sparse and shift-invariant features then anLSTM classifier was trained for temporal evolution [189]employed a more flexible network called ResNet-LSTM whichallows nodes in lower CNN layers to directly contact with
16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

16
Fig 13 The spatio-temporal network proposed in [68] The tempo-ral network PHRNN for landmark trajectory and the spatial networkMSCNN for identity-invariant features are trained separately Then thepredicted probabilities from the two networks are fused together forspatio-temporal FER
Fig 14 The joint fine-tuning method for DTAGN proposed in [16] Tointegrate DTGA and DTAN we freeze the weight values in the grayboxes and retrain the top layer in the green boxes The logit valuesof the green boxes are used by Softmax3 to supervise the integratednetwork During training we combine three softmax loss functions andfor prediction we use only Softmax3
LSTMs to capture spatio-temporal information In additionto concatenating LSTM with the fully connected layer ofCNN a hypercolumn-based system [207] extracted the lastconvolutional layer features as the input of the LSTM for longerrange dependencies without losing global coherence Insteadof LSTM the conditional random fields (CRFs) model [208]that are effective in recognizing human activities was employedin [55] to distinguish the temporal relations of the input sequences
Network ensemble A two-stream CNN for action recognition invideos which trained one stream of the CNN on the multi-framedense optical flow for temporal information and the other streamof the CNN on still images for appearance features and then fusedthe outputs of two streams was introduced by Simonyan et al[209] Inspired by this architecture several network ensemblemodels have been proposed for FER
Sun et al [185] proposed a multi-channel network that ex-tracted the spatial information from emotion-expressing faces andtemporal information (optical flow) from the changes betweenemotioanl and neutral faces and investigated three feature fusionstrategies score average fusion SVM-based fusion and neural-network-based fusion Zhang et al [68] fused the temporal net-work PHRNN (discussed in ldquoLandmark trajectoryrdquo) and thespatial network MSCNN (discussed in section 415) to extractthe partial-whole geometry-appearance and static-dynamic in-formation for FER (see Fig 13) Instead of fusing the networkoutputs with different weights Jung et al [16] proposed a jointfine-tuning method that jointly trained the DTAN (discussed inthe ldquoRNN and C3Drdquo ) the DTGN (discussed in the ldquoLandmark
trajectoryrdquo) and the integrated network (see Fig 14 for details)which outperformed the weighed sum strategy
424 DiscussionIn the real world people display facial expressions in a dynamicprocess eg from subtle to obvious and it has become a trend toconduct FER on sequencevideo data Table 8 summarizes relativemerits of different types of methods on dynamic data in regardsto the capability of representing spatial and temporal informationthe requirement on training data size and frame length (variable orfixed) the computational efficiency and the performance
Frame aggregation is employed to combine the learned featureor prediction probability of each frame for a sequence-levelresult The output of each frame can be simply concatenated(fixed-length frames is required in each sequence) or statisticallyaggregated to obtain video-level representation (variable-lengthframes processible) This method is computationally simple andcan achieve moderate performance if the temporal variations ofthe target dataset is not complicated
According to the fact that the expression intensity in a videosequence varies over time the expression intensity-invariant net-work considers images with non-peak expressions and furtherexploits the dynamic correlations between peak and non-peakexpressions to improve performance Commonly image frameswith specific intensity states are needed for intensity-invariantFER
Despite the advantages of these methods frame aggregationhandles frames without consideration of temporal informationand subtle appearance changes and expression intensity-invariantnetworks require prior knowledge of expression intensity whichis unavailable in real-world scenarios By contrast Deep spatio-temporal networks are designed to encode temporal dependenciesin consecutive frames and have been shown to benefit fromlearning spatial features in conjunction with temporal featuresRNN and its variations (eg LSTM IRNN and BRNN) and C3Dare foundational networks for learning spatio-temporal featuresHowever the performance of these networks is barely satisfac-tory RNN is incapable of capturing the powerful convolutionalfeatures And 3D filers in C3D are applied over very shortvideo clips ignoring long-range dynamics Also training sucha huge network is computationally a problem especially fordynamic FER where video data is insufficient Alternativelyfacial landmark trajectory methods extract shape features basedon the physical structures of facial morphological variations tocapture dynamic facial component activities and then apply deepnetworks for classification This method is computationally simpleand can get rid of the issue on illumination variations Howeverit is sensitive to registration errors and requires accurate faciallandmark detection which is difficult to access in unconstrainedconditions Consequently this method performs less well and ismore suitable to complement appearance representations Networkensemble is utilized to train multiple networks for both spatial andtemporal information and then to fuse the network outputs in thefinal stage Optic flow and facial landmark trajectory can be usedas temporal representations to collaborate spatial representationsOne of the drawbacks of this framework is the pre-computingand storage consumption on optical flow or landmark trajectoryvectors And most related researches randomly selected fixed-length video frames as input leading to the loss of useful temporalinformation Cascaded networks were proposed to first extractdiscriminative representations for facial expression images and
17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

17
TABLE 8Comparison of different types of methods for dynamic image sequences in terms of data size requirement representability of spatial and temporal
information requirement on frame length performance and computational efficiency FLT = Facial Landmark Trajectory CN = CascadedNetwork NE = Network Ensemble
Network type data spatial temporal frame length accuracy efficiencyFrame aggregation low good no depends fair highExpression intensity fair good low fixed fair varies
Spatio-temporalnetwork
RNN low low good variable low fairC3D high good fair fixed low fairFLT fair fair fair fixed low highCN high good good variable good fairNE low good good fixed good low
then input these features to sequential networks to reinforce thetemporal information encoding However this model introducesadditional parameters to capture sequence information and thefeature learning network (eg CNN) and the temporal informationencoding network (eg LSTM) in current works are not trainedjointly which may lead to suboptimal parameter settings Andtraining in an end-to-end fashion is still a long road
Compared with deep networks on static data Table 4 and Table7 demonstrate the powerful capability and popularity trend of deepspatio-temporal networks For instance comparison results onwidely evaluated benchmarks (eg CK+ and MMI) illustrate thattraining networks based on sequence data and analyzing temporaldependency between frames can further improve the performanceAlso in the EmotiW challenge 2015 only one system employeddeep spatio-networks for FER whereas 5 of 7 reviewed systemsin the EmotiW challenge 2017 relied on such networks
5 ADDITIONAL RELATED ISSUES
In addition to the most popular basic expression classificationtask reviewed above we further introduce a few related issuesthat depend on deep neural networks and prototypical expression-related knowledge
51 Occlusion and non-frontal head poseOcclusion and non-frontal head pose which may change thevisual appearance of the original facial expression are two majorobstacles for automatic FER especially in real-world scenarios
For facial occlusion Ranzato et al [210] [211] proposed adeep generative model that used mPoT [212] as the first layerof DBNs to model pixel-level representations and then trainedDBNs to fit an appropriate distribution to its inputs Thus theoccluded pixels in images could be filled in by reconstructingthe top layer representation using the sequence of conditionaldistributions Cheng et al [213] employed multilayer RBMswith a pre-training and fine-tuning process on Gabor featuresto compress features from the occluded facial parts Xu et al[214] concatenated high-level learned features transferred fromtwo CNNs with the same structure but pre-trained on differentdata the original MSRA-CFW database and the MSRA-CFWdatabase with additive occluded samples
For multi-view FER Zhang et al [156] introduced a projectionlayer into the CNN that learned discriminative facial featuresby weighting different facial landmark points within 2D SIFTfeature matrices without requiring facial pose estimation Liu et al
[215] proposed a multi-channel pose-aware CNN (MPCNN) thatcontains three cascaded parts (multi-channel feature extractionjointly multi-scale feature fusion and the pose-aware recognition)to predict expression labels by minimizing the conditional jointloss of pose and expression recognition Besides the technologyof generative adversarial network (GAN) has been employed in[180] [181] to generate facial images with different expressionsunder arbitrary poses for multi-view FER
52 FER on infrared dataAlthough RBG or gray data are the current standard in deep FERthese data are vulnerable to ambient lighting conditions Whileinfrared images that record the skin temporal distribution producedby emotions are not sensitive to illumination variations which maybe a promising alternative for investigation of facial expressionFor example He et al [216] employed a DBM model that consistsof a Gaussian-binary RBM and a binary RBM for FER The modelwas trained by layerwise pre-training and joint training and wasthen fine-tuned on long-wavelength thermal infrared images tolearn thermal features Wu et al [217] proposed a three-stream3D CNN to fuse local and global spatio-temporal features onillumination-invariant near-infrared images for FER
53 FER on 3D static and dynamic dataDespite significant advances have achieved in 2D FER it failsto solve the two main problems illumination changes and posevariations [29] 3D FER that uses 3D face shape models withdepth information can capture subtle facial deformations whichare naturally robust to pose and lighting variations
Depth images and videos record the intensity of facial pixelsbased on distance from a depth camera which contain criticalinformation of facial geometric relations For example [218] usedkinect depth sensor to obtain gradient direction information andthen employed CNN on unregistered facial depth images for FER[219] [220] extracted a series of salient features from depthvideos and combined them with deep networks (ie CNN andDBN) for FER To emphasize the dynamic deformation patternsof facial expression motions Li et al [221] explore the 4D FER(3D FER using dynamic data) using a dynamic geometrical imagenetwork Furthermore Chang et al [222] proposed to estimate 3Dexpression coefficients from image intensities using CNN withoutrequiring facial landmark detection Thus the model is highlyrobust to extreme appearance variations including out-of-planehead rotations scale changes and occlusions
18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

18
Recently more and more works trend to combine 2D and 3Ddata to further improve the performance Oyedotun et al [223]employed CNN to jointly learn facial expression features fromboth RGB and depth map latent modalities And Li et al [224]proposed a deep fusion CNN (DF-CNN) to explore multi-modal2D+3D FER Specifically six types of 2D facial attribute maps(ie geometry texture curvature normal components x y and z)were first extracted from the textured 3D face scans and werethen jointly fed into the feature extraction and feature fusionsubnets to learn the optimal combination weights of 2D and 3Dfacial representations To improve this work [225] proposed toextract deep features from different facial parts extracted from thetexture and depth images and then fused these features together tointerconnect them with feedback Wei et al [226] further exploredthe data bias problem in 2D+3D FER using unsupervised domainadaption technique
54 Facial expression synthesisRealistic facial expression synthesis which can generate variousfacial expressions for interactive interfaces is a hot topic Susskindet al [227] demonstrated that DBN has the capacity to capturethe large range of variation in expressive appearance and can betrained on large but sparsely labeled datasets In light of this work[210] [211] [228] employed DBN with unsupervised learningto construct facial expression synthesis systems Kaneko et al[149] proposed a multitask deep network with state recognitionand key-point localization to adaptively generate visual feedbackto improve facial expression recognition With the recent successof the deep generative models such as variational autoencoder(VAE) adversarial autoencoder (AAE) and generative adversarialnetwork (GAN) a series of facial expression synthesis systemshave been developed based on these models (eg [229] [230][231] [232] and [233]) Facial expression synthesis can also beapplied to data augmentation without manually collecting andlabeling huge datasets Masi et al [234] employed CNN tosynthesize new face images by increasing face-specific appearancevariation such as expressions within the 3D textured face model
55 Visualization techniquesIn addition to utilizing CNN for FER several works (eg [139][235] [236]) employed visualization techniques [237] on thelearned CNN features to qualitatively analyze how the CNNcontributes to the appearance-based learning process of FER andto qualitatively decipher which portions of the face yield themost discriminative information The deconvolutional results allindicated that the activations of some particular filters on thelearned features have strong correlations with the face regions thatcorrespond to facial AUs
56 Other special issuesSeveral novel issues have been approached on the basis of theprototypical expression categories dominant and complementaryemotion recognition challenge [238] and the Real versus Fakeexpressed emotions challenge [239] Furthermore deep learningtechniques have been thoroughly applied by the participants ofthese two challenges (eg [240] [241] [242]) Additional relatedreal-world applications such as the Real-time FER App forsmartphones [243] [244] Eyemotion (FER using eye-trackingcameras) [245] privacy-preserving mobile analytics [246] Unfeltemotions [247] and Depression recognition [248] have also beendeveloped
6 CHALLENGES AND OPPORTUNITIES
61 Facial expression datasetsAs the FER literature shifts its main focus to the challeng-ing in-the-wild environmental conditions many researchers havecommitted to employing deep learning technologies to handledifficulties such as illumination variation occlusions non-frontalhead poses identity bias and the recognition of low-intensityexpressions Given that FER is a data-driven task and that traininga sufficiently deep network to capture subtle expression-relateddeformations requires a large amount of training data the majorchallenge that deep FER systems face is the lack of training datain terms of both quantity and quality
Because people of different age ranges cultures and gendersdisplay and interpret facial expression in different ways an idealfacial expression dataset is expected to include abundant sampleimages with precise face attribute labels not just expression butother attributes such as age gender and ethnicity which wouldfacilitate related research on cross-age range cross-gender andcross-cultural FER using deep learning techniques such as mul-titask deep networks and transfer learning In addition althoughocclusion and multipose problems have received relatively wideinterest in the field of deep face recognition the occlusion-robust and pose-invariant issues have receive less attention in deepFER One of the main reasons is the lack of a large-scale facialexpression dataset with occlusion type and head-pose annotations
On the other hand accurately annotating a large volume ofimage data with the large variation and complexity of naturalscenarios is an obvious impediment to the construction of expres-sion datasets A reasonable approach is to employ crowd-sourcingmodels [44] [46] [249] under the guidance of expert annotatorsAdditionally a fully automatic labeling tool [43] refined by expertsis alternative to provide approximate but efficient annotations Inboth cases a subsequent reliable estimation or labeling learningprocess is necessary to filter out noisy annotations In particularfew comparatively large-scale datasets that consider real-worldscenarios and contain a wide range of facial expressions haverecently become publicly available ie EmotioNet [43] RAF-DB [44] [45] and AffectNet [46] and we anticipate that withadvances in technology and the wide spread of the Internet morecomplementary facial expression datasets will be constructed topromote the development of deep FER
62 Incorporating other affective modelsAnother major issue that requires consideration is that while FERwithin the categorical model is widely acknowledged and re-searched the definition of the prototypical expressions covers onlya small portion of specific categories and cannot capture the fullrepertoire of expressive behaviors for realistic interactions Twoadditional models were developed to describe a larger range ofemotional landscape the FACS model [10] [176] where variousfacial muscle AUs are combined to describe the visible appearancechanges of facial expressions and the dimensional model [11][250] where two continuous-valued variables namely valenceand arousal are proposed to continuously encode small changes inthe intensity of emotions Another novel definition ie compoundexpression was proposed by Du et al [52] who argued that somefacial expressions are actually combinations of more than onebasic emotion These works improve the characterization of facialexpressions and to some extent can complement the categoricalmodel For instance as discussed above the visualization results
19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

19
of CNNs have demonstrated a certain congruity between thelearned representations and the facial areas defined by AUs Thuswe can design filters of the deep neural networks to distributedifferent weights according to the importance degree of differentfacial muscle action parts
63 Dataset bias and imbalanced distribution
Data bias and inconsistent annotations are very common amongdifferent facial expression datasets due to different collectingconditions and the subjectiveness of annotating Researchers com-monly evaluate their algorithms within a specific dataset and canachieve satisfactory performance However early cross-databaseexperiments have indicated that discrepancies between databasesexist due to the different collection environments and constructionindicators [12] hence algorithms evaluated via intra-databaseprotocols lack generalizability on unseen test data and the per-formance in cross-dataset settings is greatly deteriorated Deepdomain adaption and knowledge distillation are alternatives toaddress this bias [226] [251] Furthermore because of the in-consistent expression annotations FER performance cannot keepimproving when enlarging the training data by directly mergingmultiple datasets [167]
Another common problem in facial expression is class imbal-ance which is a result of the practicalities of data acquisitioneliciting and annotating a smile is easy however capturing in-formation for disgust anger and other less common expressionscan be very challenging As shown in Table 4 and Table 7 theperformance assessed in terms of mean accuracy which assignsequal weights to all classes decreases when compared with theaccuracy criterion and this decline is especially evident in real-world datasets (eg SFEW 20 and AFEW) One solution is tobalance the class distribution during the pre-processing stage usingdata augmentation and synthesis Another alternative is to developa cost-sensitive loss layer for deep networks during training
64 Multimodal affect recognition
Last but not the least human expressive behaviors in realisticapplications involve encoding from different perspectives and thefacial expression is only one modality Although pure expressionrecognition based on visible face images can achieve promis-ing results incorporating with other models into a high-levelframework can provide complementary information and furtherenhance the robustness For example participants in the EmotiWchallenges and Audio Video Emotion Challenges (AVEC) [252][253] considered the audio model to be the second most importantelement and employed various fusion techniques for multimodalaffect recognition Additionally the fusion of other modalitiessuch as infrared images depth information from 3D face modelsand physiological data is becoming a promising research directiondue to the large complementarity for facial expressions
REFERENCES
[1] C Darwin and P Prodger The expression of the emotions in man andanimals Oxford University Press USA 1998
[2] Y-I Tian T Kanade and J F Cohn ldquoRecognizing action units forfacial expression analysisrdquo IEEE Transactions on pattern analysis andmachine intelligence vol 23 no 2 pp 97ndash115 2001
[3] P Ekman and W V Friesen ldquoConstants across cultures in the face andemotionrdquo Journal of personality and social psychology vol 17 no 2pp 124ndash129 1971
[4] P Ekman ldquoStrong evidence for universals in facial expressions a replyto russellrsquos mistaken critiquerdquo Psychological bulletin vol 115 no 2pp 268ndash287 1994
[5] D Matsumoto ldquoMore evidence for the universality of a contemptexpressionrdquo Motivation and Emotion vol 16 no 4 pp 363ndash368 1992
[6] R E Jack O G Garrod H Yu R Caldara and P G Schyns ldquoFacialexpressions of emotion are not culturally universalrdquo Proceedings of theNational Academy of Sciences vol 109 no 19 pp 7241ndash7244 2012
[7] Z Zeng M Pantic G I Roisman and T S Huang ldquoA survey of affectrecognition methods Audio visual and spontaneous expressionsrdquoIEEE transactions on pattern analysis and machine intelligence vol 31no 1 pp 39ndash58 2009
[8] E Sariyanidi H Gunes and A Cavallaro ldquoAutomatic analysis of facialaffect A survey of registration representation and recognitionrdquo IEEEtransactions on pattern analysis and machine intelligence vol 37 no 6pp 1113ndash1133 2015
[9] B Martinez and M F Valstar ldquoAdvances challenges and opportuni-ties in automatic facial expression recognitionrdquo in Advances in FaceDetection and Facial Image Analysis Springer 2016 pp 63ndash100
[10] P Ekman ldquoFacial action coding system (facs)rdquo A human face 2002[11] H Gunes and B Schuller ldquoCategorical and dimensional affect analysis
in continuous input Current trends and future directionsrdquo Image andVision Computing vol 31 no 2 pp 120ndash136 2013
[12] C Shan S Gong and P W McOwan ldquoFacial expression recognitionbased on local binary patterns A comprehensive studyrdquo Image andVision Computing vol 27 no 6 pp 803ndash816 2009
[13] P Liu S Han Z Meng and Y Tong ldquoFacial expression recognition viaa boosted deep belief networkrdquo in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition 2014 pp 1805ndash1812
[14] A Mollahosseini D Chan and M H Mahoor ldquoGoing deeper in facialexpression recognition using deep neural networksrdquo in Applications ofComputer Vision (WACV) 2016 IEEE Winter Conference on IEEE2016 pp 1ndash10
[15] G Zhao and M Pietikainen ldquoDynamic texture recognition using localbinary patterns with an application to facial expressionsrdquo IEEE trans-actions on pattern analysis and machine intelligence vol 29 no 6 pp915ndash928 2007
[16] H Jung S Lee J Yim S Park and J Kim ldquoJoint fine-tuning in deepneural networks for facial expression recognitionrdquo in Computer Vision(ICCV) 2015 IEEE International Conference on IEEE 2015 pp2983ndash2991
[17] X Zhao X Liang L Liu T Li Y Han N Vasconcelos andS Yan ldquoPeak-piloted deep network for facial expression recognitionrdquoin European conference on computer vision Springer 2016 pp 425ndash442
[18] C A Corneanu M O Simon J F Cohn and S E GuerreroldquoSurvey on rgb 3d thermal and multimodal approaches for facialexpression recognition History trends and affect-related applicationsrdquoIEEE transactions on pattern analysis and machine intelligence vol 38no 8 pp 1548ndash1568 2016
[19] R Zhi M Flierl Q Ruan and W B Kleijn ldquoGraph-preserving sparsenonnegative matrix factorization with application to facial expressionrecognitionrdquo IEEE Transactions on Systems Man and CyberneticsPart B (Cybernetics) vol 41 no 1 pp 38ndash52 2011
[20] L Zhong Q Liu P Yang B Liu J Huang and D N MetaxasldquoLearning active facial patches for expression analysisrdquo in ComputerVision and Pattern Recognition (CVPR) 2012 IEEE Conference onIEEE 2012 pp 2562ndash2569
[21] I J Goodfellow D Erhan P L Carrier A Courville M MirzaB Hamner W Cukierski Y Tang D Thaler D-H Lee et alldquoChallenges in representation learning A report on three machinelearning contestsrdquo in International Conference on Neural InformationProcessing Springer 2013 pp 117ndash124
[22] A Dhall O Ramana Murthy R Goecke J Joshi and T GedeonldquoVideo and image based emotion recognition challenges in the wildEmotiw 2015rdquo in Proceedings of the 2015 ACM on InternationalConference on Multimodal Interaction ACM 2015 pp 423ndash426
[23] A Dhall R Goecke J Joshi J Hoey and T Gedeon ldquoEmotiw 2016Video and group-level emotion recognition challengesrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 427ndash432
[24] A Dhall R Goecke S Ghosh J Joshi J Hoey and T GedeonldquoFrom individual to group-level emotion recognition Emotiw 50rdquo inProceedings of the 19th ACM International Conference on MultimodalInteraction ACM 2017 pp 524ndash528
20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

20
[25] A Krizhevsky I Sutskever and G E Hinton ldquoImagenet classifica-tion with deep convolutional neural networksrdquo in Advances in neuralinformation processing systems 2012 pp 1097ndash1105
[26] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo arXiv preprint arXiv14091556 2014
[27] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing deeper with convolutionsrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2015 pp 1ndash9
[28] K He X Zhang S Ren and J Sun ldquoDeep residual learning for imagerecognitionrdquo in Proceedings of the IEEE conference on computer visionand pattern recognition 2016 pp 770ndash778
[29] M Pantic and L J M Rothkrantz ldquoAutomatic analysis of facialexpressions The state of the artrdquo IEEE Transactions on pattern analysisand machine intelligence vol 22 no 12 pp 1424ndash1445 2000
[30] B Fasel and J Luettin ldquoAutomatic facial expression analysis a surveyrdquoPattern recognition vol 36 no 1 pp 259ndash275 2003
[31] T Zhang ldquoFacial expression recognition based on deep learning Asurveyrdquo in International Conference on Intelligent and InteractiveSystems and Applications Springer 2017 pp 345ndash352
[32] M F Valstar M Mehu B Jiang M Pantic and K Scherer ldquoMeta-analysis of the first facial expression recognition challengerdquo IEEETransactions on Systems Man and Cybernetics Part B (Cybernetics)vol 42 no 4 pp 966ndash979 2012
[33] P Lucey J F Cohn T Kanade J Saragih Z Ambadar andI Matthews ldquoThe extended cohn-kanade dataset (ck+) A completedataset for action unit and emotion-specified expressionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2010 IEEE Com-puter Society Conference on IEEE 2010 pp 94ndash101
[34] M Pantic M Valstar R Rademaker and L Maat ldquoWeb-based databasefor facial expression analysisrdquo in Multimedia and Expo 2005 ICME2005 IEEE International Conference on IEEE 2005 pp 5ndashpp
[35] M Valstar and M Pantic ldquoInduced disgust happiness and surprise anaddition to the mmi facial expression databaserdquo in Proc 3rd InternWorkshop on EMOTION (satellite of LREC) Corpora for Research onEmotion and Affect 2010 p 65
[36] M Lyons S Akamatsu M Kamachi and J Gyoba ldquoCoding facialexpressions with gabor waveletsrdquo in Automatic Face and GestureRecognition 1998 Proceedings Third IEEE International Conferenceon IEEE 1998 pp 200ndash205
[37] J M Susskind A K Anderson and G E Hinton ldquoThe toronto facedatabaserdquo Department of Computer Science University of TorontoToronto ON Canada Tech Rep vol 3 2010
[38] R Gross I Matthews J Cohn T Kanade and S Baker ldquoMulti-pierdquoImage and Vision Computing vol 28 no 5 pp 807ndash813 2010
[39] L Yin X Wei Y Sun J Wang and M J Rosato ldquoA 3d facialexpression database for facial behavior researchrdquo in Automatic faceand gesture recognition 2006 FGR 2006 7th international conferenceon IEEE 2006 pp 211ndash216
[40] G Zhao X Huang M Taini S Z Li and M PietikaInen ldquoFacialexpression recognition from near-infrared videosrdquo Image and VisionComputing vol 29 no 9 pp 607ndash619 2011
[41] O Langner R Dotsch G Bijlstra D H Wigboldus S T Hawk andA van Knippenberg ldquoPresentation and validation of the radboud facesdatabaserdquo Cognition and Emotion vol 24 no 8 pp 1377ndash1388 2010
[42] D Lundqvist A Flykt and A Ohman ldquoThe karolinska directedemotional faces (kdef)rdquo CD ROM from Department of Clinical Neu-roscience Psychology section Karolinska Institutet no 1998 1998
[43] C F Benitez-Quiroz R Srinivasan and A M Martinez ldquoEmotionetAn accurate real-time algorithm for the automatic annotation of amillion facial expressions in the wildrdquo in Proceedings of IEEE Interna-tional Conference on Computer Vision amp Pattern Recognition (CVPR)Las Vegas NV USA 2016
[44] S Li W Deng and J Du ldquoReliable crowdsourcing and deep locality-preserving learning for expression recognition in the wildrdquo in 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE 2017 pp 2584ndash2593
[45] S Li and W Deng ldquoReliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognitionrdquoIEEE Transactions on Image Processing 2018
[46] A Mollahosseini B Hasani and M H Mahoor ldquoAffectnet A databasefor facial expression valence and arousal computing in the wildrdquo IEEETransactions on Affective Computing vol PP no 99 pp 1ndash1 2017
[47] Z Zhang P Luo C L Chen and X Tang ldquoFrom facial expressionrecognition to interpersonal relation predictionrdquo International Journalof Computer Vision vol 126 no 5 pp 1ndash20 2018
[48] A Dhall R Goecke S Lucey T Gedeon et al ldquoCollecting large richlyannotated facial-expression databases from moviesrdquo IEEE multimediavol 19 no 3 pp 34ndash41 2012
[49] A Dhall R Goecke S Lucey and T Gedeon ldquoActed facial expres-sions in the wild databaserdquo Australian National University CanberraAustralia Technical Report TR-CS-11 vol 2 p 1 2011
[50] mdashmdash ldquoStatic facial expression analysis in tough conditions Dataevaluation protocol and benchmarkrdquo in Computer Vision Workshops(ICCV Workshops) 2011 IEEE International Conference on IEEE2011 pp 2106ndash2112
[51] C F Benitez-Quiroz R Srinivasan Q Feng Y Wang and A MMartinez ldquoEmotionet challenge Recognition of facial expressions ofemotion in the wildrdquo arXiv preprint arXiv170301210 2017
[52] S Du Y Tao and A M Martinez ldquoCompound facial expressions ofemotionrdquo Proceedings of the National Academy of Sciences vol 111no 15 pp E1454ndashE1462 2014
[53] T F Cootes G J Edwards and C J Taylor ldquoActive appearance mod-elsrdquo IEEE Transactions on Pattern Analysis amp Machine Intelligenceno 6 pp 681ndash685 2001
[54] N Zeng H Zhang B Song W Liu Y Li and A M DobaieldquoFacial expression recognition via learning deep sparse autoencodersrdquoNeurocomputing vol 273 pp 643ndash649 2018
[55] B Hasani and M H Mahoor ldquoSpatio-temporal facial expression recog-nition using convolutional neural networks and conditional randomfieldsrdquo in Automatic Face amp Gesture Recognition (FG 2017) 201712th IEEE International Conference on IEEE 2017 pp 790ndash795
[56] X Zhu and D Ramanan ldquoFace detection pose estimation and land-mark localization in the wildrdquo in Computer Vision and Pattern Recogni-tion (CVPR) 2012 IEEE Conference on IEEE 2012 pp 2879ndash2886
[57] S E Kahou C Pal X Bouthillier P Froumenty C GulcehreR Memisevic P Vincent A Courville Y Bengio R C Ferrariet al ldquoCombining modality specific deep neural networks for emotionrecognition in videordquo in Proceedings of the 15th ACM on Internationalconference on multimodal interaction ACM 2013 pp 543ndash550
[58] T Devries K Biswaranjan and G W Taylor ldquoMulti-task learning offacial landmarks and expressionrdquo in Computer and Robot Vision (CRV)2014 Canadian Conference on IEEE 2014 pp 98ndash103
[59] A Asthana S Zafeiriou S Cheng and M Pantic ldquoRobust discrimina-tive response map fitting with constrained local modelsrdquo in ComputerVision and Pattern Recognition (CVPR) 2013 IEEE Conference onIEEE 2013 pp 3444ndash3451
[60] M Shin M Kim and D-S Kwon ldquoBaseline cnn structure analysisfor facial expression recognitionrdquo in Robot and Human InteractiveCommunication (RO-MAN) 2016 25th IEEE International Symposiumon IEEE 2016 pp 724ndash729
[61] Z Meng P Liu J Cai S Han and Y Tong ldquoIdentity-aware convo-lutional neural network for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 558ndash565
[62] X Xiong and F De la Torre ldquoSupervised descent method and its appli-cations to face alignmentrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 532ndash539
[63] H-W Ng V D Nguyen V Vonikakis and S Winkler ldquoDeep learningfor emotion recognition on small datasets using transfer learningrdquo inProceedings of the 2015 ACM on international conference on multi-modal interaction ACM 2015 pp 443ndash449
[64] S Ren X Cao Y Wei and J Sun ldquoFace alignment at 3000 fpsvia regressing local binary featuresrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2014 pp1685ndash1692
[65] A Asthana S Zafeiriou S Cheng and M Pantic ldquoIncremental facealignment in the wildrdquo in Proceedings of the IEEE conference oncomputer vision and pattern recognition 2014 pp 1859ndash1866
[66] D H Kim W Baddar J Jang and Y M Ro ldquoMulti-objective basedspatio-temporal feature representation learning robust to expression in-tensity variations for facial expression recognitionrdquo IEEE Transactionson Affective Computing 2017
[67] Y Sun X Wang and X Tang ldquoDeep convolutional network cascadefor facial point detectionrdquo in Computer Vision and Pattern Recognition(CVPR) 2013 IEEE Conference on IEEE 2013 pp 3476ndash3483
[68] K Zhang Y Huang Y Du and L Wang ldquoFacial expression recognitionbased on deep evolutional spatial-temporal networksrdquo IEEE Transac-tions on Image Processing vol 26 no 9 pp 4193ndash4203 2017
[69] K Zhang Z Zhang Z Li and Y Qiao ldquoJoint face detection andalignment using multitask cascaded convolutional networksrdquo IEEESignal Processing Letters vol 23 no 10 pp 1499ndash1503 2016
21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

21
[70] Z Yu Q Liu and G Liu ldquoDeeper cascaded peak-piloted network forweak expression recognitionrdquo The Visual Computer pp 1ndash9 2017
[71] Z Yu G Liu Q Liu and J Deng ldquoSpatio-temporal convolutionalfeatures with nested lstm for facial expression recognitionrdquo Neurocom-puting vol 317 pp 50ndash57 2018
[72] P Viola and M Jones ldquoRapid object detection using a boosted cascadeof simple featuresrdquo in Computer Vision and Pattern Recognition2001 CVPR 2001 Proceedings of the 2001 IEEE Computer SocietyConference on vol 1 IEEE 2001 pp IndashI
[73] F De la Torre W-S Chu X Xiong F Vicente X Ding and J F CohnldquoIntrafacerdquo in IEEE International Conference on Automatic Face andGesture Recognition (FG) 2015
[74] Z Zhang P Luo C C Loy and X Tang ldquoFacial landmark detection bydeep multi-task learningrdquo in European Conference on Computer VisionSpringer 2014 pp 94ndash108
[75] Z Yu and C Zhang ldquoImage based static facial expression recognitionwith multiple deep network learningrdquo in Proceedings of the 2015 ACMon International Conference on Multimodal Interaction ACM 2015pp 435ndash442
[76] B-K Kim H Lee J Roh and S-Y Lee ldquoHierarchical committeeof deep cnns with exponentially-weighted decision fusion for staticfacial expression recognitionrdquo in Proceedings of the 2015 ACM onInternational Conference on Multimodal Interaction ACM 2015pp 427ndash434
[77] X Liu B Kumar J You and P Jia ldquoAdaptive deep metric learningfor identity-aware facial expression recognitionrdquo in Proc IEEE ConfComput Vis Pattern Recognit Workshops (CVPRW) 2017 pp 522ndash531
[78] G Levi and T Hassner ldquoEmotion recognition in the wild via convolu-tional neural networks and mapped binary patternsrdquo in Proceedings ofthe 2015 ACM on international conference on multimodal interactionACM 2015 pp 503ndash510
[79] D A Pitaloka A Wulandari T Basaruddin and D Y LilianaldquoEnhancing cnn with preprocessing stage in automatic emotion recog-nitionrdquo Procedia Computer Science vol 116 pp 523ndash529 2017
[80] A T Lopes E de Aguiar A F De Souza and T Oliveira-SantosldquoFacial expression recognition with convolutional neural networks cop-ing with few data and the training sample orderrdquo Pattern Recognitionvol 61 pp 610ndash628 2017
[81] M V Zavarez R F Berriel and T Oliveira-Santos ldquoCross-databasefacial expression recognition based on fine-tuned deep convolutionalnetworkrdquo in Graphics Patterns and Images (SIBGRAPI) 2017 30thSIBGRAPI Conference on IEEE 2017 pp 405ndash412
[82] W Li M Li Z Su and Z Zhu ldquoA deep-learning approach tofacial expression recognition with candid imagesrdquo in Machine VisionApplications (MVA) 2015 14th IAPR International Conference onIEEE 2015 pp 279ndash282
[83] I Abbasnejad S Sridharan D Nguyen S Denman C Fookes andS Lucey ldquoUsing synthetic data to improve facial expression analysiswith 3d convolutional networksrdquo in Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition 2017 pp 1609ndash1618
[84] I Goodfellow J Pouget-Abadie M Mirza B Xu D Warde-FarleyS Ozair A Courville and Y Bengio ldquoGenerative adversarial netsrdquo inAdvances in neural information processing systems 2014 pp 2672ndash2680
[85] W Chen M J Er and S Wu ldquoIllumination compensation and nor-malization for robust face recognition using discrete cosine transformin logarithm domainrdquo IEEE Transactions on Systems Man and Cyber-netics Part B (Cybernetics) vol 36 no 2 pp 458ndash466 2006
[86] J Li and E Y Lam ldquoFacial expression recognition using deep neuralnetworksrdquo in Imaging Systems and Techniques (IST) 2015 IEEEInternational Conference on IEEE 2015 pp 1ndash6
[87] S Ebrahimi Kahou V Michalski K Konda R Memisevic and C PalldquoRecurrent neural networks for emotion recognition in videordquo in Pro-ceedings of the 2015 ACM on International Conference on MultimodalInteraction ACM 2015 pp 467ndash474
[88] S A Bargal E Barsoum C C Ferrer and C Zhang ldquoEmotionrecognition in the wild from videos using imagesrdquo in Proceedings of the18th ACM International Conference on Multimodal Interaction ACM2016 pp 433ndash436
[89] C-M Kuo S-H Lai and M Sarkis ldquoA compact deep learning modelfor robust facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 2121ndash2129
[90] A Yao D Cai P Hu S Wang L Sha and Y Chen ldquoHolonet towardsrobust emotion recognition in the wildrdquo in Proceedings of the 18th ACM
International Conference on Multimodal Interaction ACM 2016 pp472ndash478
[91] P Hu D Cai S Wang A Yao and Y Chen ldquoLearning supervisedscoring ensemble for emotion recognition in the wildrdquo in Proceedingsof the 19th ACM International Conference on Multimodal InteractionACM 2017 pp 553ndash560
[92] T Hassner S Harel E Paz and R Enbar ldquoEffective face frontalizationin unconstrained imagesrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2015 pp 4295ndash4304
[93] C Sagonas Y Panagakis S Zafeiriou and M Pantic ldquoRobust sta-tistical face frontalizationrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3871ndash3879
[94] X Yin X Yu K Sohn X Liu and M Chandraker ldquoTowards large-pose face frontalization in the wildrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp3990ndash3999
[95] R Huang S Zhang T Li and R He ldquoBeyond face rotation Global andlocal perception gan for photorealistic and identity preserving frontalview synthesisrdquo in Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition 2017 pp 2439ndash2448
[96] L Tran X Yin and X Liu ldquoDisentangled representation learninggan for pose-invariant face recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2017 pp1415ndash1424
[97] L Deng D Yu et al ldquoDeep learning methods and applicationsrdquoFoundations and Trends Rcopy in Signal Processing vol 7 no 3ndash4 pp197ndash387 2014
[98] B Fasel ldquoRobust face analysis using convolutional neural networksrdquo inPattern Recognition 2002 Proceedings 16th International Conferenceon vol 2 IEEE 2002 pp 40ndash43
[99] mdashmdash ldquoHead-pose invariant facial expression recognition using convo-lutional neural networksrdquo in Proceedings of the 4th IEEE InternationalConference on Multimodal Interfaces IEEE Computer Society 2002p 529
[100] M Matsugu K Mori Y Mitari and Y Kaneda ldquoSubject independentfacial expression recognition with robust face detection using a convolu-tional neural networkrdquo Neural Networks vol 16 no 5-6 pp 555ndash5592003
[101] B Sun L Li G Zhou X Wu J He L Yu D Li and Q WeildquoCombining multimodal features within a fusion network for emotionrecognition in the wildrdquo in Proceedings of the 2015 ACM on Interna-tional Conference on Multimodal Interaction ACM 2015 pp 497ndash502
[102] B Sun L Li G Zhou and J He ldquoFacial expression recognition inthe wild based on multimodal texture featuresrdquo Journal of ElectronicImaging vol 25 no 6 p 061407 2016
[103] R Girshick J Donahue T Darrell and J Malik ldquoRich featurehierarchies for accurate object detection and semantic segmentationrdquoin Proceedings of the IEEE conference on computer vision and patternrecognition 2014 pp 580ndash587
[104] J Li D Zhang J Zhang J Zhang T Li Y Xia Q Yan and L XunldquoFacial expression recognition with faster r-cnnrdquo Procedia ComputerScience vol 107 pp 135ndash140 2017
[105] S Ren K He R Girshick and J Sun ldquoFaster r-cnn Towards real-timeobject detection with region proposal networksrdquo in Advances in neuralinformation processing systems 2015 pp 91ndash99
[106] S Ji W Xu M Yang and K Yu ldquo3d convolutional neural networksfor human action recognitionrdquo IEEE transactions on pattern analysisand machine intelligence vol 35 no 1 pp 221ndash231 2013
[107] D Tran L Bourdev R Fergus L Torresani and M Paluri ldquoLearningspatiotemporal features with 3d convolutional networksrdquo in ComputerVision (ICCV) 2015 IEEE International Conference on IEEE 2015pp 4489ndash4497
[108] Y Fan X Lu D Li and Y Liu ldquoVideo-based emotion recognitionusing cnn-rnn and c3d hybrid networksrdquo in Proceedings of the 18thACM International Conference on Multimodal Interaction ACM2016 pp 445ndash450
[109] D Nguyen K Nguyen S Sridharan A Ghasemi D Dean andC Fookes ldquoDeep spatio-temporal features for multimodal emotionrecognitionrdquo in Applications of Computer Vision (WACV) 2017 IEEEWinter Conference on IEEE 2017 pp 1215ndash1223
[110] S Ouellet ldquoReal-time emotion recognition for gaming using deepconvolutional network featuresrdquo arXiv preprint arXiv14083750 2014
[111] H Ding S K Zhou and R Chellappa ldquoFacenet2expnet Regularizinga deep face recognition net for expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 118ndash126
22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

22
[112] B Hasani and M H Mahoor ldquoFacial expression recognition usingenhanced deep 3d convolutional neural networksrdquo in Computer Visionand Pattern Recognition Workshops (CVPRW) 2017 IEEE Conferenceon IEEE 2017 pp 2278ndash2288
[113] G E Hinton S Osindero and Y-W Teh ldquoA fast learning algorithm fordeep belief netsrdquo Neural computation vol 18 no 7 pp 1527ndash15542006
[114] G E Hinton and T J Sejnowski ldquoLearning and releaming in boltz-mann machinesrdquo Parallel distributed processing Explorations in themicrostructure of cognition vol 1 no 282-317 p 2 1986
[115] G E Hinton ldquoA practical guide to training restricted boltzmannmachinesrdquo in Neural networks Tricks of the trade Springer 2012pp 599ndash619
[116] Y Bengio P Lamblin D Popovici and H Larochelle ldquoGreedy layer-wise training of deep networksrdquo in Advances in neural informationprocessing systems 2007 pp 153ndash160
[117] G E Hinton ldquoTraining products of experts by minimizing contrastivedivergencerdquo Neural computation vol 14 no 8 pp 1771ndash1800 2002
[118] G E Hinton and R R Salakhutdinov ldquoReducing the dimensionality ofdata with neural networksrdquo science vol 313 no 5786 pp 504ndash5072006
[119] P Vincent H Larochelle I Lajoie Y Bengio and P-A ManzagolldquoStacked denoising autoencoders Learning useful representations in adeep network with a local denoising criterionrdquo Journal of MachineLearning Research vol 11 no Dec pp 3371ndash3408 2010
[120] Q V Le ldquoBuilding high-level features using large scale unsupervisedlearningrdquo in Acoustics Speech and Signal Processing (ICASSP) 2013IEEE International Conference on IEEE 2013 pp 8595ndash8598
[121] S Rifai P Vincent X Muller X Glorot and Y Bengio ldquoCon-tractive auto-encoders Explicit invariance during feature extractionrdquoin Proceedings of the 28th International Conference on InternationalConference on Machine Learning Omnipress 2011 pp 833ndash840
[122] J Masci U Meier D Ciresan and J Schmidhuber ldquoStacked convolu-tional auto-encoders for hierarchical feature extractionrdquo in InternationalConference on Artificial Neural Networks Springer 2011 pp 52ndash59
[123] D P Kingma and M Welling ldquoAuto-encoding variational bayesrdquo arXivpreprint arXiv13126114 2013
[124] P J Werbos ldquoBackpropagation through time what it does and how todo itrdquo Proceedings of the IEEE vol 78 no 10 pp 1550ndash1560 1990
[125] S Hochreiter and J Schmidhuber ldquoLong short-term memoryrdquo Neuralcomputation vol 9 no 8 pp 1735ndash1780 1997
[126] M Mirza and S Osindero ldquoConditional generative adversarial netsrdquoarXiv preprint arXiv14111784 2014
[127] A Radford L Metz and S Chintala ldquoUnsupervised representationlearning with deep convolutional generative adversarial networksrdquoarXiv preprint arXiv151106434 2015
[128] A B L Larsen S K Soslashnderby H Larochelle and O WintherldquoAutoencoding beyond pixels using a learned similarity metricrdquo arXivpreprint arXiv151209300 2015
[129] X Chen Y Duan R Houthooft J Schulman I Sutskever andP Abbeel ldquoInfogan Interpretable representation learning by informa-tion maximizing generative adversarial netsrdquo in Advances in neuralinformation processing systems 2016 pp 2172ndash2180
[130] Y Tang ldquoDeep learning using linear support vector machinesrdquo arXivpreprint arXiv13060239 2013
[131] A Dapogny and K Bailly ldquoInvestigating deep neural forests for facialexpression recognitionrdquo in Automatic Face amp Gesture Recognition (FG2018) 2018 13th IEEE International Conference on IEEE 2018 pp629ndash633
[132] P Kontschieder M Fiterau A Criminisi and S Rota Bulo ldquoDeepneural decision forestsrdquo in Proceedings of the IEEE internationalconference on computer vision 2015 pp 1467ndash1475
[133] J Donahue Y Jia O Vinyals J Hoffman N Zhang E Tzeng andT Darrell ldquoDecaf A deep convolutional activation feature for genericvisual recognitionrdquo in International conference on machine learning2014 pp 647ndash655
[134] A S Razavian H Azizpour J Sullivan and S Carlsson ldquoCnn featuresoff-the-shelf an astounding baseline for recognitionrdquo in ComputerVision and Pattern Recognition Workshops (CVPRW) 2014 IEEE Con-ference on IEEE 2014 pp 512ndash519
[135] N Otberdout A Kacem M Daoudi L Ballihi and S Berretti ldquoDeepcovariance descriptors for facial expression recognitionrdquo in BMVC2018
[136] D Acharya Z Huang D Pani Paudel and L Van Gool ldquoCovariancepooling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2018 pp 367ndash374
[137] M Liu S Li S Shan and X Chen ldquoAu-aware deep networks for facialexpression recognitionrdquo in Automatic Face and Gesture Recognition(FG) 2013 10th IEEE International Conference and Workshops onIEEE 2013 pp 1ndash6
[138] mdashmdash ldquoAu-inspired deep networks for facial expression feature learn-ingrdquo Neurocomputing vol 159 pp 126ndash136 2015
[139] P Khorrami T Paine and T Huang ldquoDo deep neural networks learnfacial action units when doing expression recognitionrdquo arXiv preprintarXiv151002969v3 2015
[140] J Cai Z Meng A S Khan Z Li J OReilly and Y Tong ldquoIsland lossfor learning discriminative features in facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 302ndash309
[141] H Yang U Ciftci and L Yin ldquoFacial expression recognition by de-expression residue learningrdquo in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition 2018 pp 2168ndash2177
[142] D Hamester P Barros and S Wermter ldquoFace expression recognitionwith a 2-channel convolutional neural networkrdquo in Neural Networks(IJCNN) 2015 International Joint Conference on IEEE 2015 pp1ndash8
[143] S Reed K Sohn Y Zhang and H Lee ldquoLearning to disentangle fac-tors of variation with manifold interactionrdquo in International Conferenceon Machine Learning 2014 pp 1431ndash1439
[144] Z Zhang P Luo C-C Loy and X Tang ldquoLearning social relationtraits from face imagesrdquo in Proceedings of the IEEE InternationalConference on Computer Vision 2015 pp 3631ndash3639
[145] Y Guo D Tao J Yu H Xiong Y Li and D Tao ldquoDeep neuralnetworks with relativity learning for facial expression recognitionrdquo inMultimedia amp Expo Workshops (ICMEW) 2016 IEEE InternationalConference on IEEE 2016 pp 1ndash6
[146] B-K Kim S-Y Dong J Roh G Kim and S-Y Lee ldquoFusing alignedand non-aligned face information for automatic affect recognition inthe wild A deep learning approachrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition Workshops2016 pp 48ndash57
[147] C Pramerdorfer and M Kampel ldquoFacial expression recognition us-ing convolutional neural networks State of the artrdquo arXiv preprintarXiv161202903 2016
[148] O M Parkhi A Vedaldi A Zisserman et al ldquoDeep face recognitionrdquoin BMVC vol 1 no 3 2015 p 6
[149] T Kaneko K Hiramatsu and K Kashino ldquoAdaptive visual feedbackgeneration for facial expression improvement with multi-task deepneural networksrdquo in Proceedings of the 2016 ACM on MultimediaConference ACM 2016 pp 327ndash331
[150] D Yi Z Lei S Liao and S Z Li ldquoLearning face representation fromscratchrdquo arXiv preprint arXiv14117923 2014
[151] X Zhang L Zhang X-J Wang and H-Y Shum ldquoFinding celebritiesin billions of web imagesrdquo IEEE Transactions on Multimedia vol 14no 4 pp 995ndash1007 2012
[152] H-W Ng and S Winkler ldquoA data-driven approach to cleaning largeface datasetsrdquo in Image Processing (ICIP) 2014 IEEE InternationalConference on IEEE 2014 pp 343ndash347
[153] H Kaya F Gurpınar and A A Salah ldquoVideo-based emotion recogni-tion in the wild using deep transfer learning and score fusionrdquo Imageand Vision Computing vol 65 pp 66ndash75 2017
[154] B Knyazev R Shvetsov N Efremova and A Kuharenko ldquoConvolu-tional neural networks pretrained on large face recognition datasets foremotion classification from videordquo arXiv preprint arXiv1711045982017
[155] D G Lowe ldquoObject recognition from local scale-invariant featuresrdquo inComputer vision 1999 The proceedings of the seventh IEEE interna-tional conference on vol 2 Ieee 1999 pp 1150ndash1157
[156] T Zhang W Zheng Z Cui Y Zong J Yan and K Yan ldquoA deep neuralnetwork-driven feature learning method for multi-view facial expressionrecognitionrdquo IEEE Transactions on Multimedia vol 18 no 12 pp2528ndash2536 2016
[157] Z Luo J Chen T Takiguchi and Y Ariki ldquoFacial expression recogni-tion with deep agerdquo in Multimedia amp Expo Workshops (ICMEW) 2017IEEE International Conference on IEEE 2017 pp 657ndash662
[158] L Chen M Zhou W Su M Wu J She and K Hirota ldquoSoftmaxregression based deep sparse autoencoder network for facial emotionrecognition in human-robot interactionrdquo Information Sciences vol 428pp 49ndash61 2018
[159] V Mavani S Raman and K P Miyapuram ldquoFacial expressionrecognition using visual saliency and deep learningrdquo arXiv preprintarXiv170808016 2017
23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

23
[160] M Cornia L Baraldi G Serra and R Cucchiara ldquoA deep multi-levelnetwork for saliency predictionrdquo in Pattern Recognition (ICPR) 201623rd International Conference on IEEE 2016 pp 3488ndash3493
[161] B-F Wu and C-H Lin ldquoAdaptive feature mapping for customizingdeep learning based facial expression recognition modelrdquo IEEE Access2018
[162] J Lu V E Liong and J Zhou ldquoCost-sensitive local binary featurelearning for facial age estimationrdquo IEEE Transactions on Image Pro-cessing vol 24 no 12 pp 5356ndash5368 2015
[163] W Shang K Sohn D Almeida and H Lee ldquoUnderstanding andimproving convolutional neural networks via concatenated rectifiedlinear unitsrdquo in International Conference on Machine Learning 2016pp 2217ndash2225
[164] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRe-thinking the inception architecture for computer visionrdquo in Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition2016 pp 2818ndash2826
[165] C Szegedy S Ioffe V Vanhoucke and A A Alemi ldquoInception-v4inception-resnet and the impact of residual connections on learningrdquo inAAAI vol 4 2017 p 12
[166] S Zhao H Cai H Liu J Zhang and S Chen ldquoFeature selectionmechanism in cnns for facial expression recognitionrdquo in BMVC 2018
[167] J Zeng S Shan and X Chen ldquoFacial expression recognition withinconsistently annotated datasetsrdquo in Proceedings of the EuropeanConference on Computer Vision (ECCV) 2018 pp 222ndash237
[168] Y Wen K Zhang Z Li and Y Qiao ldquoA discriminative featurelearning approach for deep face recognitionrdquo in European Conferenceon Computer Vision Springer 2016 pp 499ndash515
[169] F Schroff D Kalenichenko and J Philbin ldquoFacenet A unified embed-ding for face recognition and clusteringrdquo in Proceedings of the IEEEconference on computer vision and pattern recognition 2015 pp 815ndash823
[170] G Zeng J Zhou X Jia W Xie and L Shen ldquoHand-crafted featureguided deep learning for facial expression recognitionrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 423ndash430
[171] D Ciregan U Meier and J Schmidhuber ldquoMulti-column deep neuralnetworks for image classificationrdquo in Computer vision and patternrecognition (CVPR) 2012 IEEE conference on IEEE 2012 pp 3642ndash3649
[172] G Pons and D Masip ldquoSupervised committee of convolutional neuralnetworks in automated facial expression analysisrdquo IEEE Transactionson Affective Computing 2017
[173] B-K Kim J Roh S-Y Dong and S-Y Lee ldquoHierarchical committeeof deep convolutional neural networks for robust facial expressionrecognitionrdquo Journal on Multimodal User Interfaces vol 10 no 2pp 173ndash189 2016
[174] K Liu M Zhang and Z Pan ldquoFacial expression recognition with cnnensemblerdquo in Cyberworlds (CW) 2016 International Conference onIEEE 2016 pp 163ndash166
[175] G Pons and D Masip ldquoMulti-task multi-label and multi-domainlearning with residual convolutional networks for emotion recognitionrdquoarXiv preprint arXiv180206664 2018
[176] P Ekman and E L Rosenberg What the face reveals Basic and appliedstudies of spontaneous expression using the Facial Action CodingSystem (FACS) Oxford University Press USA 1997
[177] R Ranjan S Sankaranarayanan C D Castillo and R Chellappa ldquoAnall-in-one convolutional neural network for face analysisrdquo in AutomaticFace amp Gesture Recognition (FG 2017) 2017 12th IEEE InternationalConference on IEEE 2017 pp 17ndash24
[178] Y Lv Z Feng and C Xu ldquoFacial expression recognition via deeplearningrdquo in Smart Computing (SMARTCOMP) 2014 InternationalConference on IEEE 2014 pp 303ndash308
[179] S Rifai Y Bengio A Courville P Vincent and M Mirza ldquoDisentan-gling factors of variation for facial expression recognitionrdquo in EuropeanConference on Computer Vision Springer 2012 pp 808ndash822
[180] Y-H Lai and S-H Lai ldquoEmotion-preserving representation learningvia generative adversarial network for multi-view facial expressionrecognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 263ndash270
[181] F Zhang T Zhang Q Mao and C Xu ldquoJoint pose and expressionmodeling for facial expression recognitionrdquo in Proceedings of the IEEEConference on Computer Vision and Pattern Recognition 2018 pp3359ndash3368
[182] H Yang Z Zhang and L Yin ldquoIdentity-adaptive facial expressionrecognition through expression regeneration using conditional genera-
tive adversarial networksrdquo in Automatic Face amp Gesture Recognition(FG 2018) 2018 13th IEEE International Conference on IEEE 2018pp 294ndash301
[183] J Chen J Konrad and P Ishwar ldquoVgan-based image representationlearning for privacy-preserving facial expression recognitionrdquo in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops 2018 pp 1570ndash1579
[184] Y Kim B Yoo Y Kwak C Choi and J Kim ldquoDeep generative-contrastive networks for facial expression recognitionrdquo arXiv preprintarXiv170307140 2017
[185] N Sun Q Li R Huan J Liu and G Han ldquoDeep spatial-temporalfeature fusion for facial expression recognition in static imagesrdquo PatternRecognition Letters 2017
[186] W Ding M Xu D Huang W Lin M Dong X Yu and H LildquoAudio and face video emotion recognition in the wild using deepneural networks and small datasetsrdquo in Proceedings of the 18th ACMInternational Conference on Multimodal Interaction ACM 2016 pp506ndash513
[187] J Yan W Zheng Z Cui C Tang T Zhang Y Zong and N SunldquoMulti-clue fusion for emotion recognition in the wildrdquo in Proceedingsof the 18th ACM International Conference on Multimodal InteractionACM 2016 pp 458ndash463
[188] Z Cui S Xiao Z Niu S Yan and W Zheng ldquoRecurrent shape regres-sionrdquo IEEE Transactions on Pattern Analysis and Machine Intelligence2018
[189] X Ouyang S Kawaai E G H Goh S Shen W Ding H Ming andD-Y Huang ldquoAudio-visual emotion recognition using deep transferlearning and multiple temporal modelsrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 577ndash582
[190] V Vielzeuf S Pateux and F Jurie ldquoTemporal multimodal fusion forvideo emotion classification in the wildrdquo in Proceedings of the 19thACM International Conference on Multimodal Interaction ACM2017 pp 569ndash576
[191] S E Kahou X Bouthillier P Lamblin C Gulcehre V Michal-ski K Konda S Jean P Froumenty Y Dauphin N Boulanger-Lewandowski et al ldquoEmonets Multimodal deep learning approachesfor emotion recognition in videordquo Journal on Multimodal User Inter-faces vol 10 no 2 pp 99ndash111 2016
[192] M Liu R Wang S Li S Shan Z Huang and X Chen ldquoCombiningmultiple kernel methods on riemannian manifold for emotion recogni-tion in the wildrdquo in Proceedings of the 16th International Conferenceon Multimodal Interaction ACM 2014 pp 494ndash501
[193] B Xu Y Fu Y-G Jiang B Li and L Sigal ldquoVideo emotionrecognition with transferred deep feature encodingsrdquo in Proceedingsof the 2016 ACM on International Conference on Multimedia RetrievalACM 2016 pp 15ndash22
[194] J Chen R Xu and L Liu ldquoDeep peak-neutral difference feature forfacial expression recognitionrdquo Multimedia Tools and Applications pp1ndash17 2018
[195] Q V Le N Jaitly and G E Hinton ldquoA simple way to ini-tialize recurrent networks of rectified linear unitsrdquo arXiv preprintarXiv150400941 2015
[196] M Schuster and K K Paliwal ldquoBidirectional recurrent neural net-worksrdquo IEEE Transactions on Signal Processing vol 45 no 11 pp2673ndash2681 1997
[197] P Barros and S Wermter ldquoDeveloping crossmodal expression recogni-tion based on a deep neural modelrdquo Adaptive behavior vol 24 no 5pp 373ndash396 2016
[198] J Zhao X Mao and J Zhang ldquoLearning deep facial expressionfeatures from image and optical flow sequences using 3d cnnrdquo TheVisual Computer pp 1ndash15 2018
[199] M Liu S Li S Shan R Wang and X Chen ldquoDeeply learningdeformable facial action parts model for dynamic expression analysisrdquoin Asian conference on computer vision Springer 2014 pp 143ndash157
[200] P F Felzenszwalb R B Girshick D McAllester and D RamananldquoObject detection with discriminatively trained part-based modelsrdquoIEEE transactions on pattern analysis and machine intelligence vol 32no 9 pp 1627ndash1645 2010
[201] S Pini O B Ahmed M Cornia L Baraldi R Cucchiara and B HuetldquoModeling multimodal cues in a deep learning-based framework foremotion recognition in the wildrdquo in Proceedings of the 19th ACMInternational Conference on Multimodal Interaction ACM 2017pp 536ndash543
[202] R Arandjelovic P Gronat A Torii T Pajdla and J Sivic ldquoNetvladCnn architecture for weakly supervised place recognitionrdquo in Pro-
24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

24
ceedings of the IEEE Conference on Computer Vision and PatternRecognition 2016 pp 5297ndash5307
[203] D H Kim M K Lee D Y Choi and B C Song ldquoMulti-modalemotion recognition using semi-supervised learning and multiple neuralnetworks in the wildrdquo in Proceedings of the 19th ACM InternationalConference on Multimodal Interaction ACM 2017 pp 529ndash535
[204] J Donahue L Anne Hendricks S Guadarrama M Rohrbach S Venu-gopalan K Saenko and T Darrell ldquoLong-term recurrent convolutionalnetworks for visual recognition and descriptionrdquo in Proceedings of theIEEE conference on computer vision and pattern recognition 2015 pp2625ndash2634
[205] D K Jain Z Zhang and K Huang ldquoMulti angle optimal pattern-baseddeep learning for automatic facial expression recognitionrdquo PatternRecognition Letters 2017
[206] M Baccouche F Mamalet C Wolf C Garcia and A Baskurt ldquoSpatio-temporal convolutional sparse auto-encoder for sequence classificationrdquoin BMVC 2012 pp 1ndash12
[207] S Kankanamge C Fookes and S Sridharan ldquoFacial analysis in thewild with lstm networksrdquo in Image Processing (ICIP) 2017 IEEEInternational Conference on IEEE 2017 pp 1052ndash1056
[208] J D Lafferty A Mccallum and F C N Pereira ldquoConditional randomfields Probabilistic models for segmenting and labeling sequence datardquoProceedings of Icml vol 3 no 2 pp 282ndash289 2001
[209] K Simonyan and A Zisserman ldquoTwo-stream convolutional networksfor action recognition in videosrdquo in Advances in neural informationprocessing systems 2014 pp 568ndash576
[210] J Susskind V Mnih G Hinton et al ldquoOn deep generative modelswith applications to recognitionrdquo in Computer Vision and PatternRecognition (CVPR) 2011 IEEE Conference on IEEE 2011 pp2857ndash2864
[211] V Mnih J M Susskind G E Hinton et al ldquoModeling natural imagesusing gated mrfsrdquo IEEE transactions on pattern analysis and machineintelligence vol 35 no 9 pp 2206ndash2222 2013
[212] V Mnih G E Hinton et al ldquoGenerating more realistic images usinggated mrfrsquosrdquo in Advances in Neural Information Processing Systems2010 pp 2002ndash2010
[213] Y Cheng B Jiang and K Jia ldquoA deep structure for facial expressionrecognition under partial occlusionrdquo in Intelligent Information Hidingand Multimedia Signal Processing (IIH-MSP) 2014 Tenth InternationalConference on IEEE 2014 pp 211ndash214
[214] M Xu W Cheng Q Zhao L Ma and F Xu ldquoFacial expression recog-nition based on transfer learning from deep convolutional networksrdquo inNatural Computation (ICNC) 2015 11th International Conference onIEEE 2015 pp 702ndash708
[215] Y Liu J Zeng S Shan and Z Zheng ldquoMulti-channel pose-aware con-volution neural networks for multi-view facial expression recognitionrdquoin Automatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 458ndash465
[216] S He S Wang W Lan H Fu and Q Ji ldquoFacial expression recognitionusing deep boltzmann machine from thermal infrared imagesrdquo inAffective Computing and Intelligent Interaction (ACII) 2013 HumaineAssociation Conference on IEEE 2013 pp 239ndash244
[217] Z Wu T Chen Y Chen Z Zhang and G Liu ldquoNirexpnet Three-stream 3d convolutional neural network for near infrared facial expres-sion recognitionrdquo Applied Sciences vol 7 no 11 p 1184 2017
[218] E P Ijjina and C K Mohan ldquoFacial expression recognition using kinectdepth sensor and convolutional neural networksrdquo in Machine Learningand Applications (ICMLA) 2014 13th International Conference onIEEE 2014 pp 392ndash396
[219] M Z Uddin M M Hassan A Almogren M Zuair G Fortino andJ Torresen ldquoA facial expression recognition system using robust facefeatures from depth videos and deep learningrdquo Computers amp ElectricalEngineering vol 63 pp 114ndash125 2017
[220] M Z Uddin W Khaksar and J Torresen ldquoFacial expression recog-nition using salient features and convolutional neural networkrdquo IEEEAccess vol 5 pp 26 146ndash26 161 2017
[221] W Li D Huang H Li and Y Wang ldquoAutomatic 4d facial expressionrecognition using dynamic geometrical image networkrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 24ndash30
[222] F-J Chang A T Tran T Hassner I Masi R Nevatia and G MedionildquoExpnet Landmark-free deep 3d facial expressionsrdquo in AutomaticFace amp Gesture Recognition (FG 2018) 2018 13th IEEE InternationalConference on IEEE 2018 pp 122ndash129
[223] O K Oyedotun G Demisse A E R Shabayek D Aouada andB Ottersten ldquoFacial expression recognition via joint deep learning
of rgb-depth map latent representationsrdquo in 2017 IEEE InternationalConference on Computer Vision Workshop (ICCVW) 2017
[224] H Li J Sun Z Xu and L Chen ldquoMultimodal 2d+ 3d facial expressionrecognition with deep fusion convolutional neural networkrdquo IEEETransactions on Multimedia vol 19 no 12 pp 2816ndash2831 2017
[225] A Jan H Ding H Meng L Chen and H Li ldquoAccurate facial partslocalization and deep learning for 3d facial expression recognitionrdquo inAutomatic Face amp Gesture Recognition (FG 2018) 2018 13th IEEEInternational Conference on IEEE 2018 pp 466ndash472
[226] X Wei H Li J Sun and L Chen ldquoUnsupervised domain adaptationwith regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognitionrdquo in Automatic Face amp Gesture Recognition (FG 2018)2018 13th IEEE International Conference on IEEE 2018 pp 31ndash37
[227] J M Susskind G E Hinton J R Movellan and A K AndersonldquoGenerating facial expressions with deep belief netsrdquo in AffectiveComputing InTech 2008
[228] M Sabzevari S Toosizadeh S R Quchani and V Abrishami ldquoAfast and accurate facial expression synthesis system for color faceimages using face graph and deep belief networkrdquo in Electronics andInformation Engineering (ICEIE) 2010 International Conference Onvol 2 IEEE 2010 pp V2ndash354
[229] R Yeh Z Liu D B Goldman and A Agarwala ldquoSemanticfacial expression editing using autoencoded flowrdquo arXiv preprintarXiv161109961 2016
[230] Y Zhou and B E Shi ldquoPhotorealistic facial expression synthesis bythe conditional difference adversarial autoencoderrdquo in Affective Com-puting and Intelligent Interaction (ACII) 2017 Seventh InternationalConference on IEEE 2017 pp 370ndash376
[231] L Song Z Lu R He Z Sun and T Tan ldquoGeometry guided adversarialfacial expression synthesisrdquo arXiv preprint arXiv171203474 2017
[232] H Ding K Sricharan and R Chellappa ldquoExprgan Facial expres-sion editing with controllable expression intensityrdquo in AAAI 2018 p67816788
[233] F Qiao N Yao Z Jiao Z Li H Chen and H Wang ldquoGeometry-contrastive generative adversarial network for facial expression synthe-sisrdquo arXiv preprint arXiv180201822 2018
[234] I Masi A T Tran T Hassner J T Leksut and G Medioni ldquoDo wereally need to collect millions of faces for effective face recognitionrdquoin European Conference on Computer Vision Springer 2016 pp579ndash596
[235] N Mousavi H Siqueira P Barros B Fernandes and S WermterldquoUnderstanding how deep neural networks learn face expressionsrdquo inNeural Networks (IJCNN) 2016 International Joint Conference onIEEE 2016 pp 227ndash234
[236] R Breuer and R Kimmel ldquoA deep learning perspective on the originof facial expressionsrdquo arXiv preprint arXiv170501842 2017
[237] M D Zeiler and R Fergus ldquoVisualizing and understanding convolu-tional networksrdquo in European conference on computer vision Springer2014 pp 818ndash833
[238] I Lusi J C J Junior J Gorbova X Baro S Escalera H DemirelJ Allik C Ozcinar and G Anbarjafari ldquoJoint challenge on dominantand complementary emotion recognition using micro emotion featuresand head-pose estimation Databasesrdquo in Automatic Face amp GestureRecognition (FG 2017) 2017 12th IEEE International Conference onIEEE 2017 pp 809ndash813
[239] J Wan S Escalera X Baro H J Escalante I Guyon M MadadiJ Allik J Gorbova and G Anbarjafari ldquoResults and analysis ofchalearn lap multi-modal isolated and continuous gesture recognitionand real versus fake expressed emotions challengesrdquo in ChaLearn LaPAction Gesture and Emotion Recognition Workshop and CompetitionsLarge Scale Multimodal Gesture Recognition and Real versus Fakeexpressed emotions ICCV vol 4 no 6 2017
[240] Y-G Kim and X-P Huynh ldquoDiscrimination between genuine versusfake emotion using long-short term memory with parametric bias andfacial landmarksrdquo in Computer Vision Workshop (ICCVW) 2017 IEEEInternational Conference on IEEE 2017 pp 3065ndash3072
[241] L Li T Baltrusaitis B Sun and L-P Morency ldquoCombining sequentialgeometry and texture features for distinguishing genuine and deceptiveemotionsrdquo in Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition 2017 pp 3147ndash3153
[242] J Guo S Zhou J Wu J Wan X Zhu Z Lei and S Z Li ldquoMulti-modality network with visual and geometrical information for microemotion recognitionrdquo in Automatic Face amp Gesture Recognition (FG2017) 2017 12th IEEE International Conference on IEEE 2017 pp814ndash819
[243] I Song H-J Kim and P B Jeon ldquoDeep learning for real-timerobust facial expression recognition on a smartphonerdquo in Consumer
25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9

25
Electronics (ICCE) 2014 IEEE International Conference on IEEE2014 pp 564ndash567
[244] S Bazrafkan T Nedelcu P Filipczuk and P Corcoran ldquoDeep learningfor facial expression recognition A step closer to a smartphone thatknows your moodsrdquo in Consumer Electronics (ICCE) 2017 IEEEInternational Conference on IEEE 2017 pp 217ndash220
[245] S Hickson N Dufour A Sud V Kwatra and I Essa ldquoEyemotionClassifying facial expressions in vr using eye-tracking camerasrdquo arXivpreprint arXiv170707204 2017
[246] S A Ossia A S Shamsabadi A Taheri H R Rabiee N Lane andH Haddadi ldquoA hybrid deep learning architecture for privacy-preservingmobile analyticsrdquo arXiv preprint arXiv170302952 2017
[247] K Kulkarni C A Corneanu I Ofodile S Escalera X BaroS Hyniewska J Allik and G Anbarjafari ldquoAutomatic recognition offacial displays of unfelt emotionsrdquo arXiv preprint arXiv1707040612017
[248] X Zhou K Jin Y Shang and G Guo ldquoVisually interpretable repre-sentation learning for depression recognition from facial imagesrdquo IEEETransactions on Affective Computing pp 1ndash1 2018
[249] E Barsoum C Zhang C C Ferrer and Z Zhang ldquoTraining deepnetworks for facial expression recognition with crowd-sourced labeldistributionrdquo in Proceedings of the 18th ACM International Conferenceon Multimodal Interaction ACM 2016 pp 279ndash283
[250] J A Russell ldquoA circumplex model of affectrdquo Journal of personalityand social psychology vol 39 no 6 p 1161 1980
[251] S Li and W Deng ldquoDeep emotion transfer network for cross-databasefacial expression recognitionrdquo in Pattern Recognition (ICPR) 201826th International Conference IEEE 2018 pp 3092ndash3099
[252] M Valstar J Gratch B Schuller F Ringeval D Lalanne M Tor-res Torres S Scherer G Stratou R Cowie and M Pantic ldquoAvec 2016Depression mood and emotion recognition workshop and challengerdquoin Proceedings of the 6th International Workshop on AudioVisualEmotion Challenge ACM 2016 pp 3ndash10
[253] F Ringeval B Schuller M Valstar J Gratch R Cowie S SchererS Mozgai N Cummins M Schmitt and M Pantic ldquoAvec 2017Real-life depression and affect recognition workshop and challengerdquoin Proceedings of the 7th Annual Workshop on AudioVisual EmotionChallenge ACM 2017 pp 3ndash9











![Feature Representation for Facial Expression Recognition Based … · 2017. 8. 25. · face recognition[13, 14], facial expression recognition[15−17], and texture analysis[18−20]](https://img.pdfslide.us/doc/110x75/61171da91bffe7006f63dbca/feature-representation-for-facial-expression-recognition-based-2017-8-25-face.jpg)

















