Embed Size (px)
Citation preview

1
CS 430 / INFO 430: Information Retrieval
Lecture 16
Web Search 2

2
CS 430 / INFO 430: Information Retrieval
Completion of Lecture 16
3
Mercator/Heritrix: Domain Name Lookup
Resolving domain names to IP addresses is a major bottleneck of web crawlers.
Approach:
• Separate DNS resolver and cache on each crawling computer.
• Create multi-threaded version of DNS code (BIND).
In Mercator, these changes reduced DNS loop-up from 70% to 14% of each thread's elapsed time.

4
QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.

5
Research Topics in Web Crawling
• How frequently to crawl and what strategies to use.
• Identification of anomalies and crawling traps.
• Strategies for crawling based on the content of web pages (focused and selective crawling).
• Duplicate detection.

6
Further Reading
Heritrixhttp://crawler.archive.org/
Allan Heydon and Marc Najork, Mercator: A Scalable, Extensible Web Crawler. World Wide Web 2(4):219-229, December 1999. http://research.microsoft.com/~najork/mercator.pdf

7
CS 430 / INFO 430: Information Retrieval
Lecture 16
Web Search 2

8
Course Administration

9
Indexing the Web Goals: Precision
Short queries applied to very large numbers of items
leads to large numbers of hits.
• Goal is that the first 10-100 hits presented should satisfy the user's information need
-- requires ranking hits in order that fits user's requirements
• Recall is not an important criterion
Completeness of index is not an important factor.
• Comprehensive crawling is unnecessary

10
Graphical Methods
Document A refers to document B
Document A provides
information about
document B
11
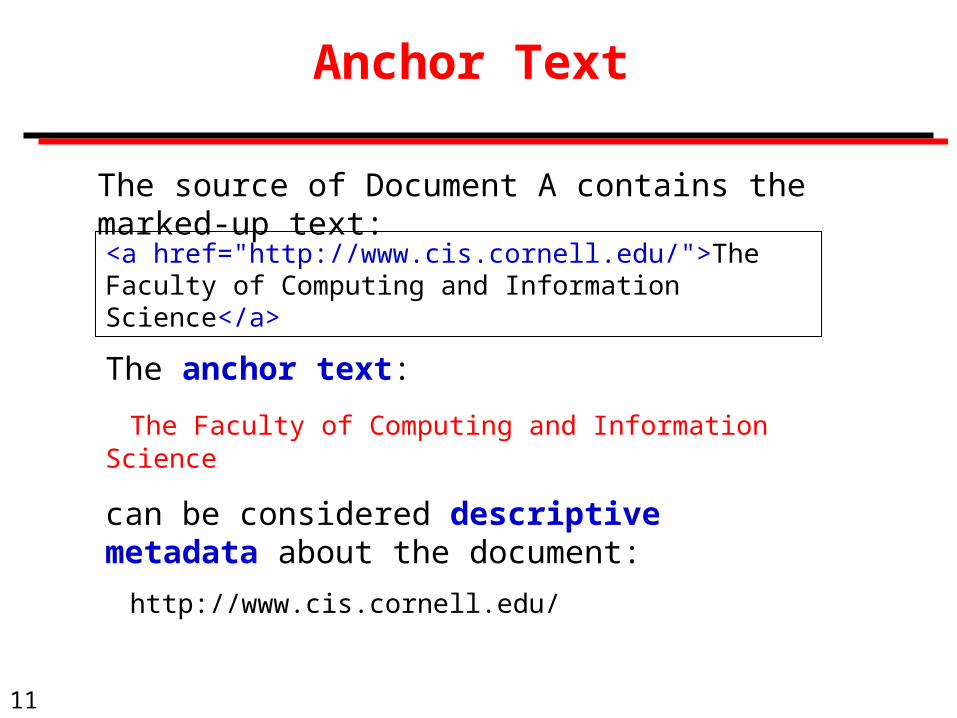
Anchor Text
<a href="http://www.cis.cornell.edu/">The Faculty of Computing and Information Science</a>
The source of Document A contains the marked-up text:
The anchor text:
The Faculty of Computing and Information Science
can be considered descriptive metadata about the document:
http://www.cis.cornell.edu/

12
Concept of Relevance and Importance
Document measures
Relevance, as conventionally defined, is binary (relevant or not relevant). It is usually estimated by the similarity between the terms in the query and each document.
Importance measures documents by their likelihood of being useful to a variety of users. It is usually estimated by some measure of popularity.
Web search engines rank documents by a combination of estimates of relevance and importance.

13
Ranking Options
1. Paid advertisers
2. Manually created classification
3. Vector space ranking with corrections for document length, and extra weighting for specific fields, e.g., title, anchors, etc.
4. Popularity, e.g., PageRank
The details of 3 and the balance between 3 and 4 are not made public.
14
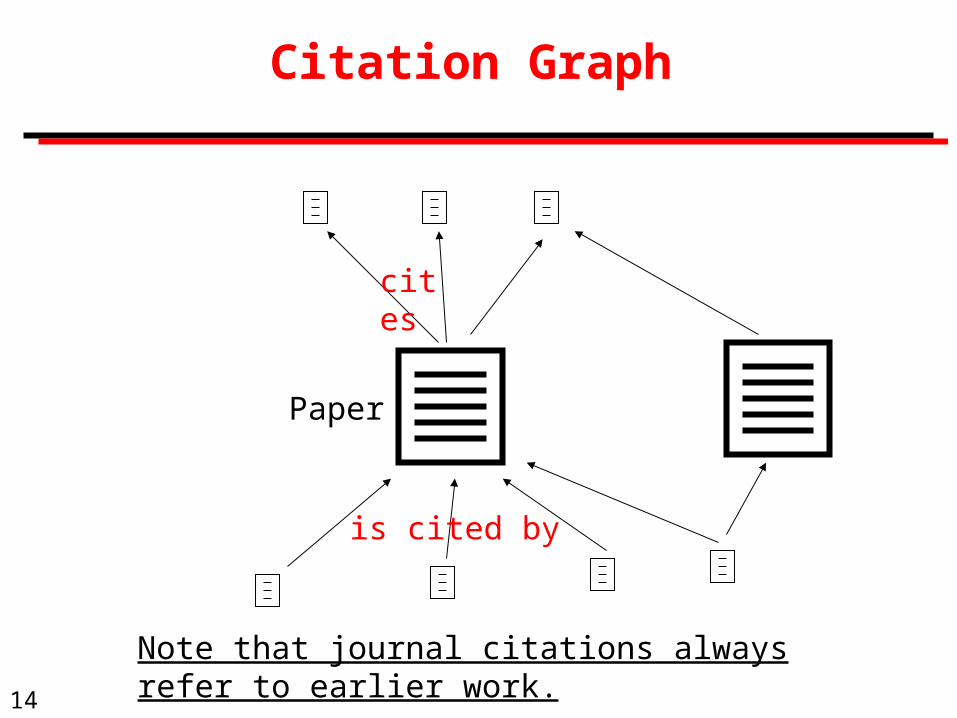
Citation Graph
Paper
cites
is cited by
Note that journal citations always refer to earlier work.

15
Bibliometrics
Techniques that use citation analysis to measure the similarity of journal articles or their importance
Bibliographic coupling: two papers that cite many of the same papers
Co-citation: two papers that were cited by many of the same papers
Impact factor (of a journal): frequency with which the average article in a journal has been cited in a particular year or period

16
Bibliometrics: Impact Factor
Impact Factor (Garfield, 1972)
• Set of journals in Journal Citation Reports of the Institute for Scientific Information
• Impact factor of a journal j in a given year is the average number of citations received by papers published in the previous two years of journal j. Impact factor counts in-degrees of nodes in the network.
Influence Weight (Pinski and Narin, 1976)
• A journal is influential if, recursively, it is heavily cited by other influential journals.
17
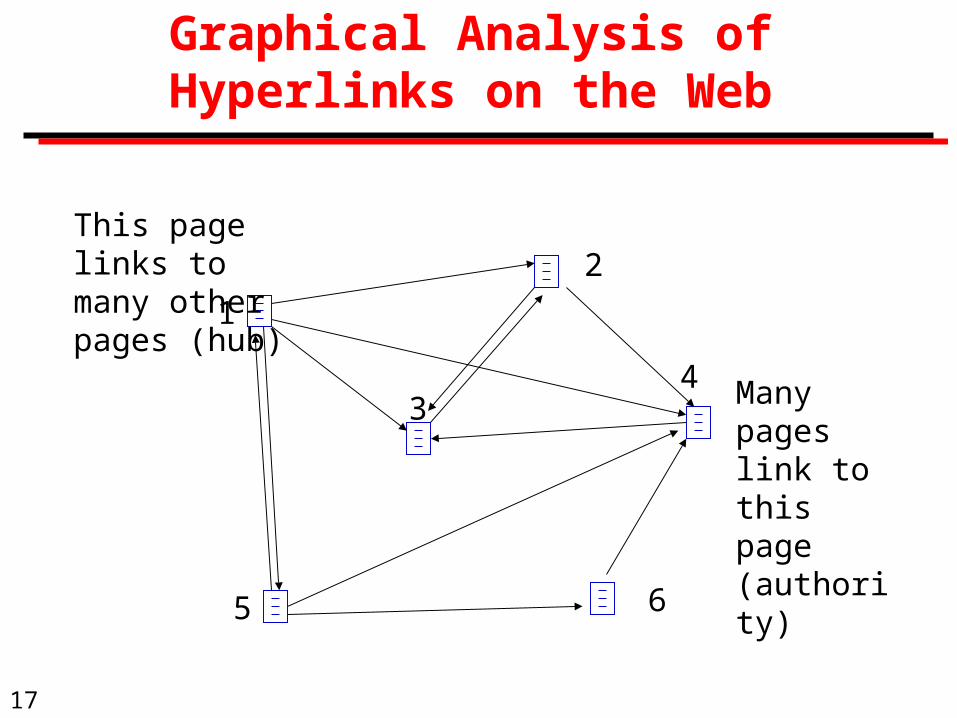
Graphical Analysis of Hyperlinks on the Web
This page links to many other pages (hub)
Many pages link to this page (authority)
1
2
34
5 6

18
Graphical Methods on Web Links
Choices
• Graph of full Web or subgraph
• In-links to a node or all links
Algorithms
• Hubs and Authorities -- subgraph, all links (Kleinberg, 1997)
• PageRank -- full graph, in-links only (Brin and Page, 1998)

19
PageRank Algorithm
Used to estimate popularity of documents
Concept:
The rank of a web page is higher if many pages link to it.
Links from highly ranked pages are given greater weight than links from less highly ranked pages.
PageRank is essentially a modified version of Pinski and Narin's influence weights applied to the Web graph.

20
Intuitive Model (Basic Concept)
Basic (no damping)
A user:
1. Starts at a random page on the web
2. Selects a random hyperlink from the current page and jumps to the corresponding page
3. Repeats Step 2 a very large number of times
Pages are ranked according to the relative frequency with which they are visited.
21
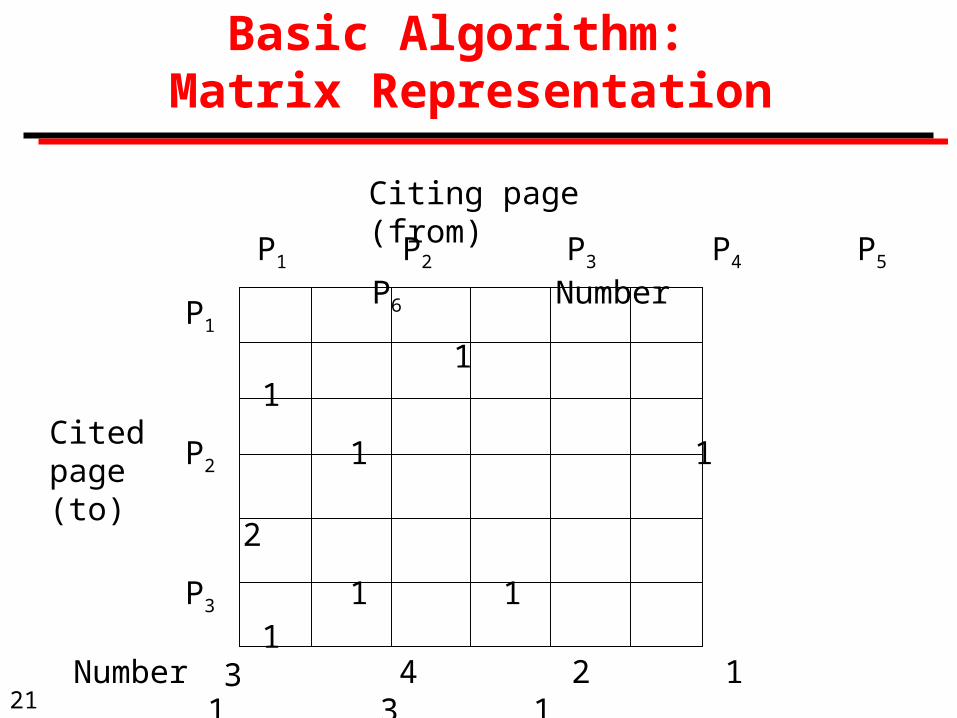
Basic Algorithm: Matrix Representation
P1 P2 P3 P4 P5 P6 Number
P1 1 1
P2 1 1 2
P3 1 1 1 3
P4 1 1 1 1 4
P5 1 1
P6 1 1
Cited page (to)
Citing page (from)
Number 4 2 1 1 3 1
22
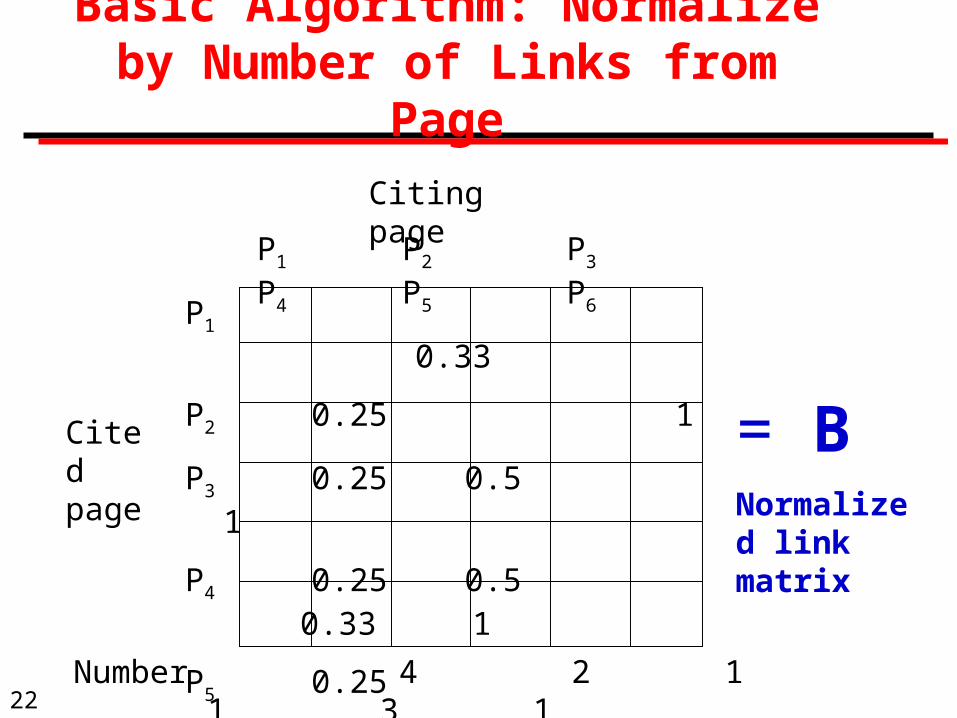
Basic Algorithm: Normalize by Number of Links from Page
P1 P2 P3 P4 P5 P6
P1 0.33
P2 0.25 1
P3 0.25 0.5 1
P4 0.25 0.5 0.33 1
P5 0.25
P6 0.33
Cited page
Citing page
Number 4 2 1 1 3 1
= BNormalized link matrix

23
Basic Algorithm: Weighting of Pages
Initially all pages have weight 1/n
w0 =
0.17
0.17
0.17
0.17
0.17
0.17
Recalculate weights
w1 = Bw0 =
0.06
0.21
0.29
0.35
0.04
0.06
If the user starts at a random page, the jth element of w1 is the probability of reaching page j after one step.

24
Basic Algorithm: Iterate
Iterate: wk = Bwk-1
0.01
0.32
0.46
0.19
0.01
0.01
0.01
0.47
0.34
0.17
0.00
0.00
->
->
->
->
->
->
0.00
0.40
0.40
0.20
0.00
0.00
w0 w1 w2 w3 ... converges to ... w
At each iteration, the sum of the weights is 1.
0.17
0.17
0.17
0.17
0.17
0.17
0.06
0.21
0.29
0.35
0.04
0.06
25
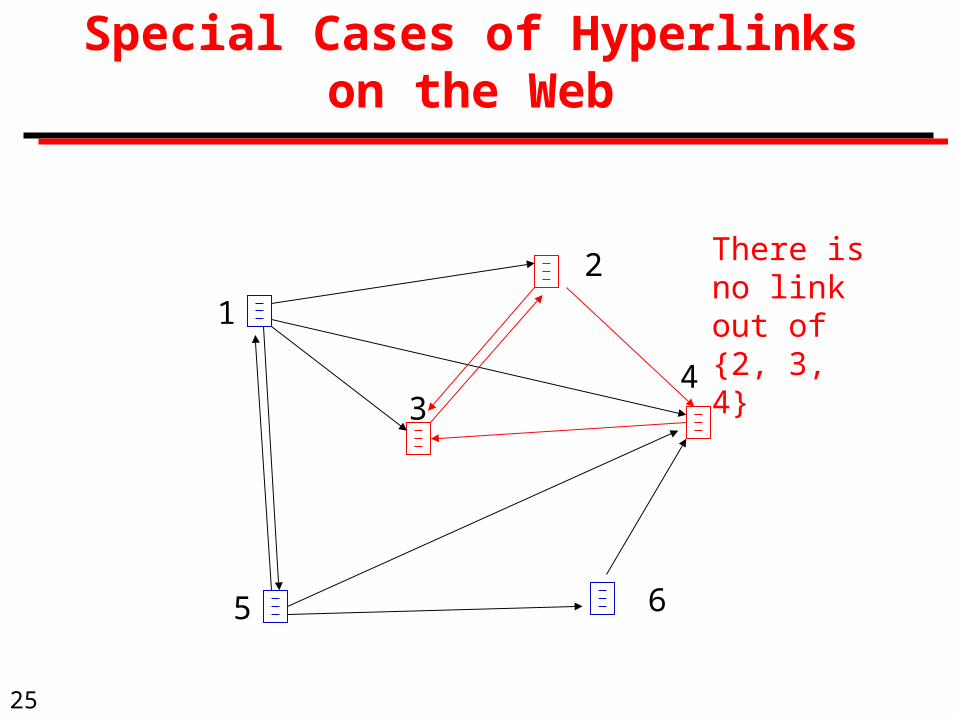
Special Cases of Hyperlinks on the Web
There is no link out of {2, 3, 4}1
2
34
5 6
26
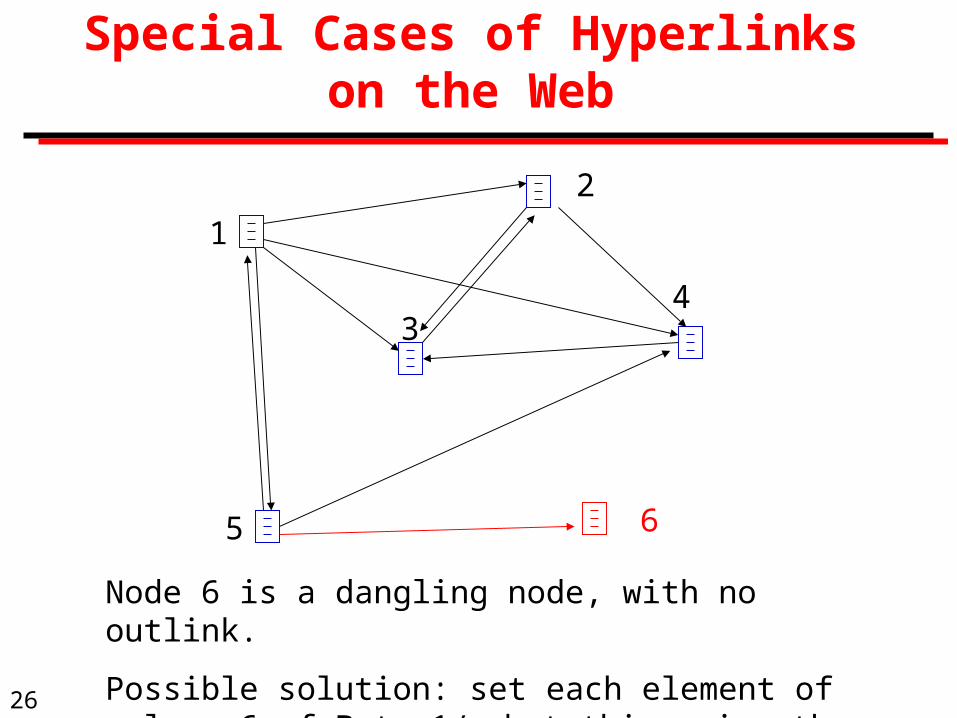
Special Cases of Hyperlinks on the Web
1
2
34
5 6
Node 6 is a dangling node, with no outlink.
Possible solution: set each element of column 6 of B to 1/n, but this ruins the sparsity of matrix B.

27
Google PageRank with Damping
A user:
1. Starts at a random page on the web
2a. With probability 1-d, selects any random page and jumps to it
2b. With probability d, selects a random hyperlink from the current page and jumps to the corresponding page
3. Repeats Step 2a and 2b a very large number of times
Pages are ranked according to the relative frequency with which they are visited.
[For dangling nodes, always follow 2a.]

28
The PageRank Iteration
The basic method iterates using the normalized link matrix, B.
wk = Bwk-1
This w is an eigenvector of B
PageRank iterates using a damping factor. The method iterates:
wk = (1 - d)w0 + dBwk-1
w0 is a vector with every element equal to 1/n.

29
The PageRank Iteration
The iteration expression with damping can be re-written.
Let R be a matrix with every element equal to 1/n
Rwk-1 = w0 (The sum of the elements of wk-1 equals 1)
Let G = dB + (1-d)R (G is called the Google matrix)
The iteration formula
wk = (1-d)w0 + dBwk-1
is equivalent to
wk = Gwk-1
so that w is an eigenvector of G
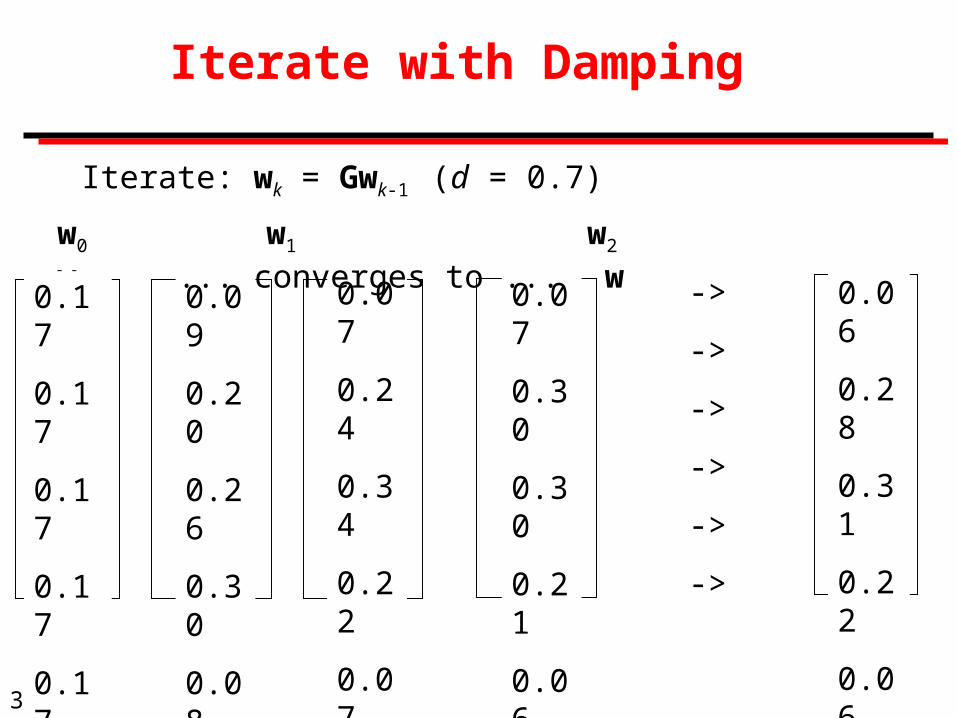
30
Iterate with Damping
Iterate: wk = Gwk-1 (d = 0.7)
0.09
0.20
0.26
0.30
0.08
0.09
0.07
0.24
0.34
0.22
0.07
0.07
0.07
0.30
0.30
0.21
0.06
0.06
->
->
->
->
->
->
0.06
0.28
0.31
0.22
0.06
0.06
w0 w1 w2 w3 ... converges to ... w
0.17
0.17
0.17
0.17
0.17
0.17

31
Convergence of the Iteration
The following results can be proved for the Google matrix, G. (See for example, Langville and Meyer.)
• The iteration always converges
• The largest eignenvalue 1 = 1
• The value of 2 the second largest eigenvalue, depends on d.
• As d approaches 1, 2 also approaches 1
• The rate of convergence depends on (2\1)k, where k is the number of iterations

32
Computational Efficiency
B is a very sparse matrix.
Let average number of outlinks per page = p.
Each iteration of wk = Bwk-1 requires O(np) = O(n) multiplications.
G is a dense matrix.
Each iteration of wk = Gwk-1 requires O(n2) multiplications.
But each iteration of wk = (1-d)w0 + dBwk-1 requires O(n) multiplications. Therefore this is the form used in practical computations.

33
Choice of d
Conceptually, values of d that are close to 1 are desirable as they emphasize the link structure of the Web graph, but...
• The rate of convergence of the iteration decreases as d approaches 1.
• The sensitivity of PageRank to small variations in data increases as d approaches 1.
It is reported that Google uses a value of d = 0.85 and that the computation converges in about 50 iterations

34
Suggested Reading
See: Jon Kleinberg. Authoritative sources in a hyperlinked environment. Journal of the ACM, 46, 1999, for descriptions of all these methods
Book: Amy Langville and Carl Meyer, Google's PageRank and Beyond: the Science of Search Engine Rankings. Princeton University Press, 2006.
Or take: CS/Info 685,The Structure of Information Networks





























