Embed Size (px)
Citation preview

1
Cross Language Information Retrieval (CLIR)
Modern Information RetrievalSharif University of TechnologyFall 2005
Mohsen Jamali

2
The General Problem
Find documents written in any language– Using queries expressed in a single language

3
The General Problem (cont)
• Traditional IR identifies relevant documents in the same language as the query (monolingual IR)
• Cross-language information retrieval (CLIR) tries to identify relevant documents in a language different from that of the query
• This problem is more and more acute for IR on the Web due to the fact that the Web is a truly multilingual environment

4
Why is CLIR important?
5
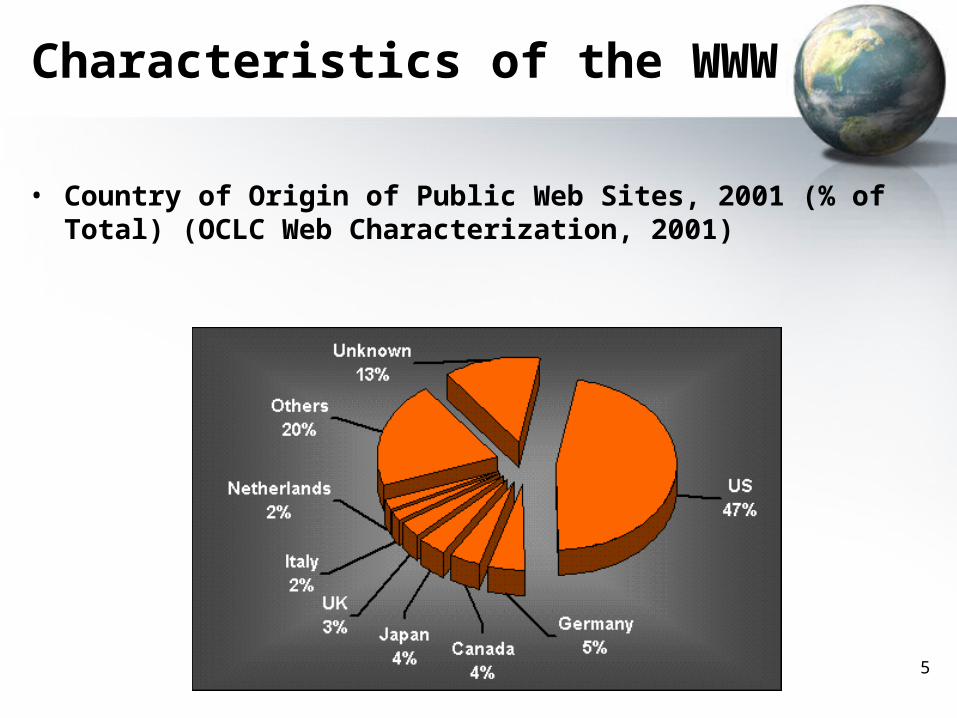
Characteristics of the WWW
• Country of Origin of Public Web Sites, 2001 (% of Total) (OCLC Web Characterization, 2001)
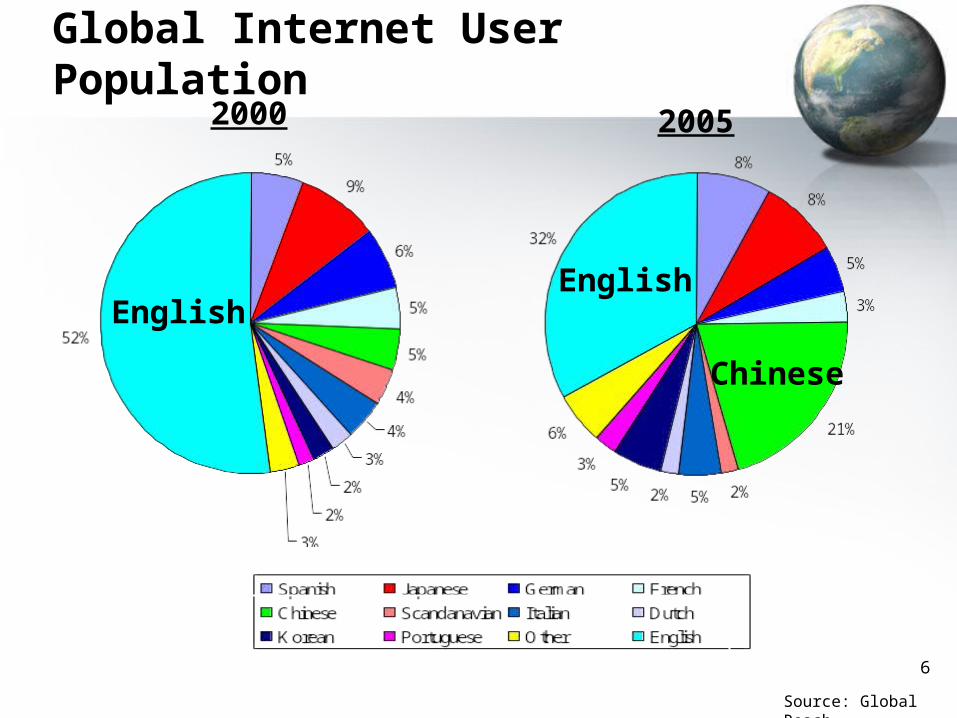
6
Source: Global Reach
EnglishEnglish
2000 2005
Global Internet User Population
Chinese

7
Importance of CLIR
• CLIR research is becoming more and more important for global information exchange and knowledge sharing.– National Security– Foreign Patent Information Access– Medical Information Access for Patients

8
CLIR is Multidisciplinary
CLIR involves researchers from the following fields:
information retrieval, natural language processing, machine translation and summarization, speech processing, document image understanding, human-computer interaction

9
User Needs
• Search a monolingual collection in a language that the user cannot read.
• Retrieve information from a multilingual collection using a query in a single language.
• Select images from a collection indexed with free text captions in an unfamiliar language.
• Locate documents in a multilingual collection of scanned page images.

10
Why Do Cross-Language IR?
• When users can read several languages– Eliminates multiple queries– Query in most fluent language
• Monolingual users can also benefit– If translations can be provided– If it suffices to know that a document exists– If text captions are used to search for images

11
Language Identification
• Can be specified using metadata– Included in HTTP and HTML
• Determined using word-scale features– Which dictionary gets the most hits?
• Determined using subword features– Letter n-grams in electronic and printed text– Phoneme n-grams in speech

12
Language Encoding Standards
• Language (alphabet) specific native encoding:– Chinese GB, Big5, – Western European ISO-8859-1 (Latin1)– Russian KOI-8, ISO-8859-5, CP-1251
• UNICODE (ISO/IEC 10646)– UTF-8 variable-byte length– UTF-16, UCS-2 fixed double-byte
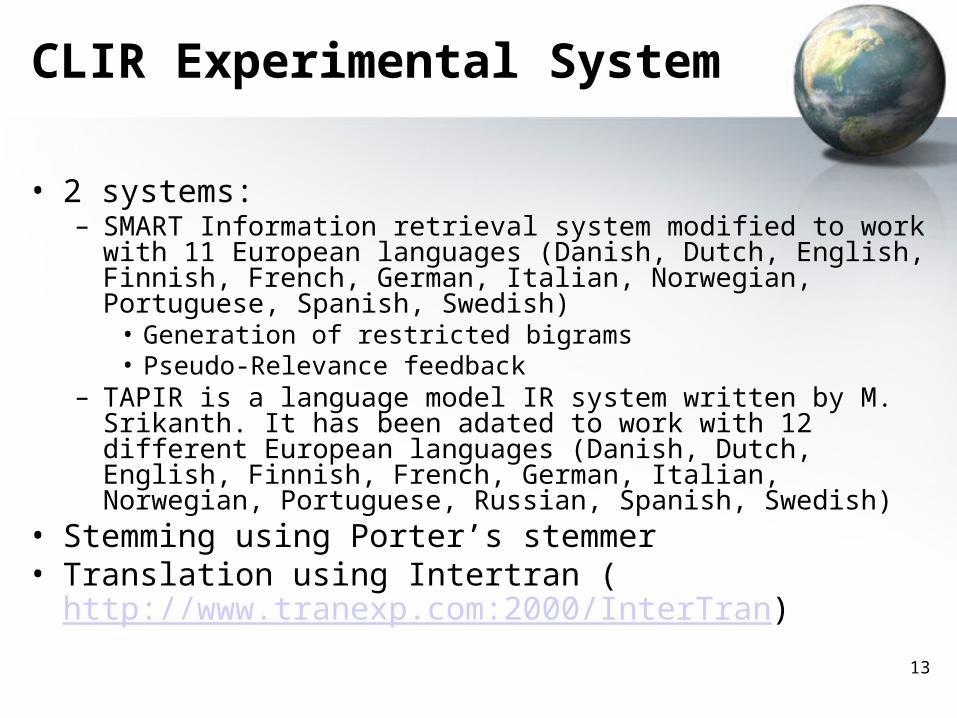
13
CLIR Experimental System
• 2 systems:– SMART Information retrieval system modified to work with 11
European languages (Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Spanish, Swedish)
• Generation of restricted bigrams• Pseudo-Relevance feedback
– TAPIR is a language model IR system written by M. Srikanth. It has been adated to work with 12 different European languages (Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish, Swedish)
• Stemming using Porter’s stemmer• Translation using Intertran (
http://www.tranexp.com:2000/InterTran)

14
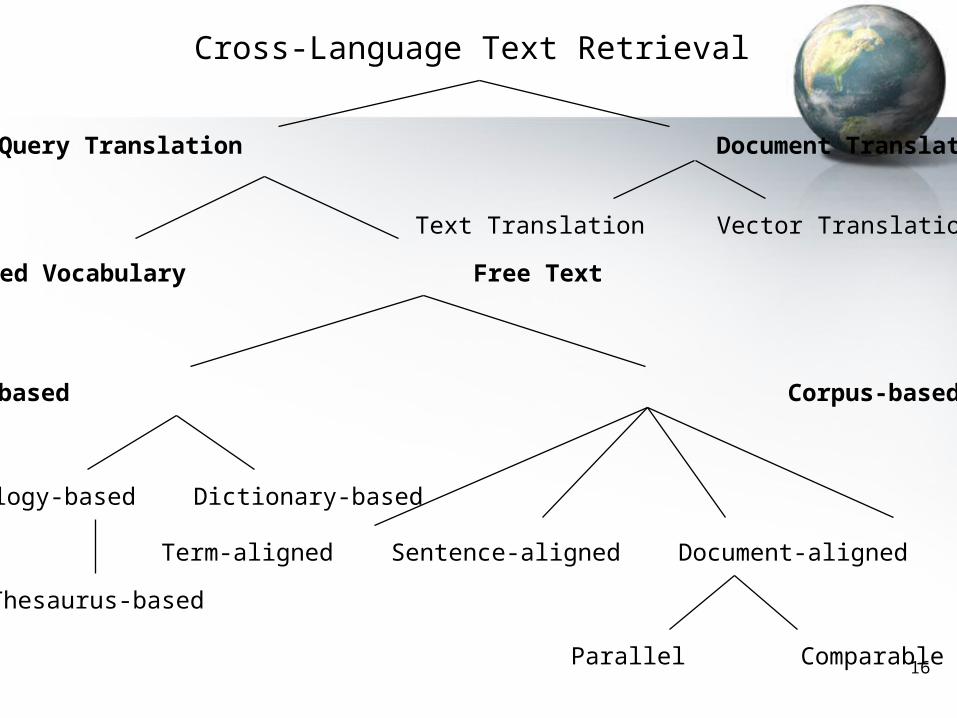
Approaches to CLIR

15
Design Decisions
• What to index?– Free text or controlled vocabulary
• What to translate?– Queries or documents
• Where to get translation knowledge?– Dictionary, ontology, training corpus
16
Term-aligned Sentence-aligned Document-aligned Unaligned
Parallel Comparable
Knowledge-based Corpus-based
Controlled Vocabulary Free Text
Cross-Language Text Retrieval
Query Translation Document Translation
Text Translation Vector Translation
Ontology-based Dictionary-based
Thesaurus-based

17
Early Development
• 1964 International Road Research Documentation– English, French and German thesaurus
• 1969 Pevzner– Exact match with a large Russian/English thesaurus
• 1970 Salton– Ranked retrieval with small English/German dictionary
• 1971 UNESCO– Proposed standard for multilingual thesauri

18
Controlled Vocabulary Matures
• 1977 IBM STAIRS-TLS– Large-scale commercial cross-language IR
• 1978 ISO Standard 5964– Guidelines for developing multilingual thesauri
• 1984 EUROVOC thesaurus– Now includes all 9 EC languages
• 1985 ISO Standard 5964 revised

19
Free Text Developments
• 1970, 1973 Salton– Hand coded bilingual term lists
• 1990 Latent Semantic Indexing
• 1994 European multilingual IR project– First precision/recall evaluation
• 1996 SIGIR Cross-lingual IR workshop
• 1998 EU/NSF digital library working group

20
Query vs. Document Translation
• Query translation– Very efficient for short queries
• Not as big an advantage for relevance feedback
– Hard to resolve ambiguous query terms
• Document translation– May be needed by the selection interface
• And supports adaptive filtering well
– Slow, but only need to do it once per document• Poor scale-up to large numbers of languages

21
Document Translation Example
• Approach– Select a single query language– Translate every document into that language– Perform monolingual retrieval
• Long documents provide enough context– And many translation errors do not hurt retrieval
• Much of the generation effort is wasted– And choosing a single translation can hurt

22
Text Translation
• One weakness of present fully automatic machine translation systems is that they are able to produce high quality translations only in limited domains
• Text retrieval systems are typically more tolerant of syntactic than semantic translation errors but that semantic accuracy suffers when insufficient domain knowledge is encoded into a translation system
• In fact some of the work done by a machine translation system could actually reduce some measures of retrieval effectiveness

23
Query Translation Example
• Select controlled vocabulary search terms
• Retrieve documents in desired language
• Form monolingual query from the documents
• Perform a monolingual free text search
Information Need
Thesaurus
ControlledVocabulary MultilingualText RetrievalSystem
Alta Vista
FrenchQueryTerms
EnglishAbstracts
English Web Pages
24
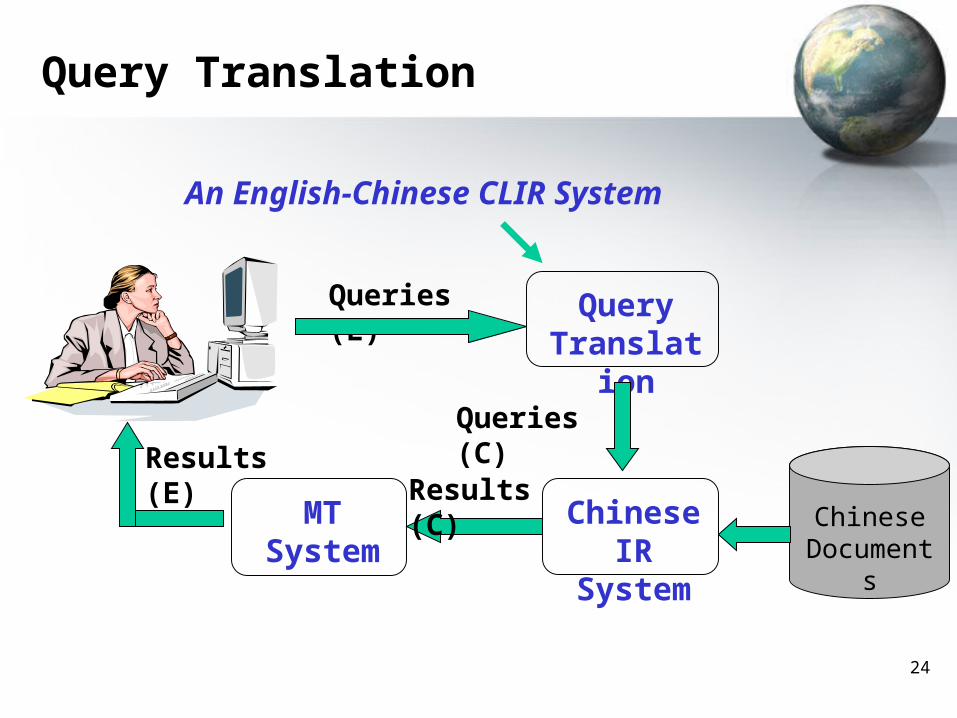
Query Translation
Queries (E) Query Translation
Chinese IR System
MT System
An English-Chinese CLIR System
Queries (C)
Results (C)Results (E)
Chinese Documents

25
Controlled Vocabulary
• A controlled vocabulary information retrieval system can be very useful in the hands of a skilled searcher, but end users often find free text searching to be more helpful.
• Experience has shown that although the domain knowledge that can be encoded in a thesaurus permits experienced users to form more precise queries casual and intermittent users have diffculty exploiting the expressive power of a traditional query interface in exact match retrieval systems
• Controlled vocabulary text retrieval systems are widely used in libraries and user needs assessment has received considerable attention from library and information science researchers.

26
Knowledge-based Techniquesfor Free Text Searching

27
Knowledge Structures for IR
• Ontology– Representation of concepts and relationships
• Thesaurus– Ontology specialized for retrieval
• Bilingual lexicon– Ontology specialized for machine translation
• Bilingual dictionary– Ontology specialized for human translation

28
Machine Readable Dictionaries
• Based on printed bilingual dictionaries– Becoming widely available
• Used to produce bilingual term lists– Cross-language term mappings are accessible
• Sometimes listed in order of most common usage
– Some knowledge structure is also present• Hard to extract and represent automatically
• The challenge is to pick the right translation

29
CLIR: Dictionary Based
• Problems– Limitations of dictionaries– Inflected word forms– Phrases and compound words– Lexical ambiguity
• Possible solution
– Approximate string matching

30
Unconstrained Query Translation
• Replace each word with every translation– Typically 5-10 translations per word
• About 50% of monolingual effectiveness– Ambiguity is a serious problem– Example: Fly (English)
• 8 word senses (e.g., to fly a flag)
• 13 Spanish translations (enarbolar, ondear, …)
• 38 English retranslations (hoist, brandish, lift…)
31
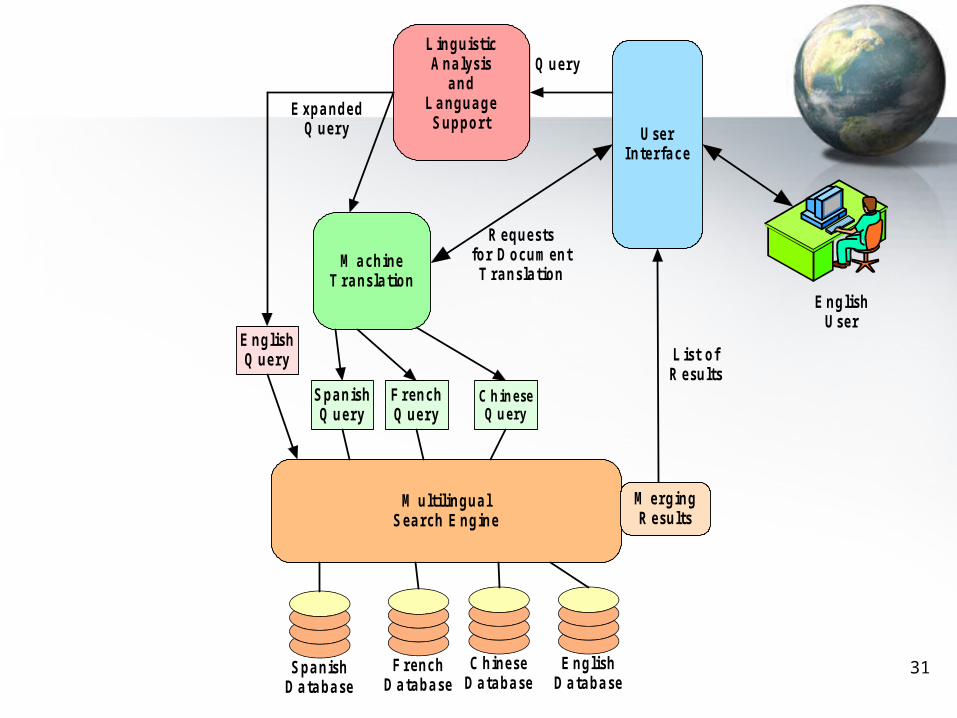
Ling uis ticA na lys is
a ndLa ng ua g e
S uppo rt
M a c hineT ra ns la tio n
M ultiling ua lS e a rc h E ng ine
U s e rInte rfa c e
F re nc hQ ue ry
S pa nis hQ ue ry
C h in eseQ u ery
E ng lis hQ ue ry
S pa nis hD a ta ba s e
F re nc hD a ta ba s e
C hine s eD a ta ba s e
E ng lis hD a ta ba s e
M e rg ingR e s ults
E ng lis hU s e r
Q ue ry
E xpa nde dQ ue ry
Lis t o fR e s ults
R e que s tsfo r D o c um e nt
T ra ns la tio n

32
Exploiting Part-of-Speech Tags
• Constrain translations by part of speech– Noun, verb, adjective, …– Effective taggers are available
• Works well when queries are full sentences– Short queries provide little basis for tagging
• Constrained matching can hurt monolingual IR– Nouns in queries often match verbs in documents

33
Phrase Indexing
• Improves retrieval effectiveness two ways– Phrases are less ambiguous than single words– Idiomatic phrases translate as a single concept
• Three ways to identify phrases– Semantic (e.g., appears in a dictionary)– Syntactic (e.g., parse as a noun phrase)– Cooccurrence (words found together often)
• Semantic phrase results are impressive

34
Corpus-based Techniquesfor Free Text Searching

35
Types of Bilingual Corpora
• Parallel corpora: translation-equivalent pairs– Document pairs– Sentence pairs – Term pairs
• Comparable corpora– Content-equivalent document pairs
• Unaligned corpora – Content from the same domain

36
Pseudo-Relevance Feedback
• Enter query terms in French
• Find top French documents in parallel corpus
• Construct a query from English translations
• Perform a monolingual free text search Top ranked
FrenchDocuments French
Text Retrieval
System
Alta Vista
FrenchQueryTerms
EnglishTranslations
English Web Pages
ParallelCorpus
37
Learning From Document Pairs
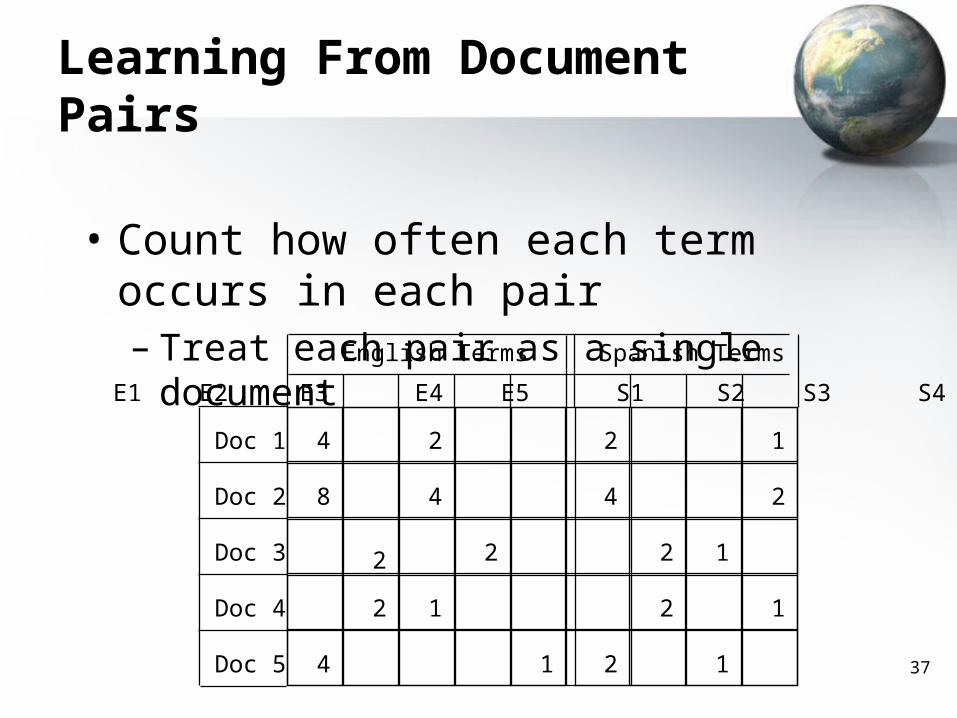
• Count how often each term occurs in each pair– Treat each pair as a single document
E1 E2 E3 E4 E5 S1 S2 S3 S4
Doc 1
Doc 2
Doc 3
Doc 4
Doc 5
4 2 2 1
8 4 4 2
2 2 2 1
2 1 2 1
4 1 2 1
English Terms Spanish Terms

38
Similarity-Based Dictionaries
• Automatically developed from aligned documents– Terms E1 and E3 are used in similar ways
• Terms E1 & S1 (or E3 & S4) are even more similar
• For each term, find most similar in other language– Retain only the top few (5 or so)
• Performs as well as dictionary-based techniques– Evaluated on a comparable corpus of news stories
• Stories were automatically linked based on date and subject

39
Generalized Vector Space Model
• “Term space” of each language is different– But the “document space” for a corpus is the same
• Describe new documents based on the corpus– Vector of cosine similarity to each corpus document– Easily generated from a vector of term weights
• Multiply by the term-document matrix
• Compute cosine similarity in document space
• Excellent results when the domain is the same

40
Latent Semantic Indexing
• Designed for better monolingual effectiveness– Works well across languages too
• Cross-language is just a type of term choice variation
• Produces short dense document vectors– Better than long sparse ones for adaptive filtering
• Training data needs grow with dimensionality
– Not as good for retrieval efficiency• Always 300 multiplications, even for short queries

41
Sentence-Aligned Parallel Corpora
• Easily constructed from aligned documents– Match pattern of relative sentence lengths
• Not yet used directly for effective retrieval– But all experiments have included domain shift
• Good first step for term alignment– Sentences define a natural context

42
Cooccurrence-Based Translation
• Align terms using cooccurrence statistics– How often do a term pair occur in sentence pairs?
• Weighted by relative position in the sentences
– Retain term pairs that occur unusually often
• Useful for query translation– Excellent results when the domain is the same
• Also practical for document translation– Term usage reinforces good translations

43
Exploiting Unaligned Corpora
• Documents about the same set of subjects– No known relationship between document pairs– Easily available in many applications
• Two approaches– Use a dictionary for rough translation
• But refine it using the unaligned bilingual corpus
– Use a dictionary to find alignments in the corpus• Then extract translation knowledge from the alignments

44
Feedback with Unaligned Corpora
• Pseudo-relevance feedback is fully automatic– Augment the query with top ranked documents
• Improves recall– “Recenters” queries based on the corpus– Short queries get the most dramatic improvement
• Two opportunities:– Query language: Improve the query– Document language: Suppress translation error

45
Context Linking
• Automatically align portions of documents– For each query term:
• Find translation pairs in corpus using dictionary
• Select a “context” of nearby terms– e.g., +/- 5 words in each language
• Choose translations from most similar contexts– Based on cooccurrence with other translation pairs
• No reported experimental results

46
Problems with CLIR
• Morphological processing difficult for some languages (e.g. Arabic)– Many different encodings for Arabic
• Windows Arabic (e.g. dictionaries)• Unicode (UTF-8) (e.g. corpus)• Macintosh Arabic (e.g. queries)
– Normalization• Remove diacritics• ِب�َّي�ة Arabic (language) الَعَرِب�َّية to الَع�َر�
– Standardize spellings for foreign names• Kleentoon” vs “Klntoon” for Clinton“ آلنتون vs آلَّينتون

47
Problems with CLIR (contd)
• Morphological processing (contd.)– Arabic stemming
Root + patterns+suffixes+prefixes=wordktb+CiCaC=kitabAll verbs and nouns derived from fewer than 2000 rootsRoots too abstract for information retrievalktb → kitab a book kitabi my bookalkitab the book kitabuki your book (f)kataba to write kitabuka your book (m)maktab office kitabuhu his bookmaktaba library, bookstore ...Want stem=root+pattern+derivational affixes?No standard stemmers available,only morphological (root) analyzers

48
Problems with CLIR (contd)
• Availability of resources– Names and phrases are very important, most lexicons
do not have good coverage– Difficult to get hold of bilingual dictionaries
• can sometimes be found on the Web
• e.g. for recent Arabic cross-lingual evaluation we used 3 on-line Arabic- English dictionaries (including harvesting) and a small lexicon of country and city names
– Parallel corpora are more difficult and require more formal arrangements

49
CLIR better than IR?
• How can cross-language beat within-language?– We know there are translation errors– Surely those errors should hurt performance
• Hypothesis is that translation process may disambiguate some query terms– Words that are ambiguous in Arabic may not be ambiguous in
English– Expansion during translation from English to Arabic prevents the
ambiguity from re-appearing• Has been proposed that CLIR is a model for IR
– Translate query into one language and then back to original– Given hypothesis, should have an improved query– Should be reasonable to do this across many different languages

50
“Low Density Languages”
• Languages for which few on-line resources exist– Rumor has it that 25 languages are well represented on Web– Extreme is “kitchen languages” that are only spoken– More extreme: a language made up of whistling
• Corpus to be searched may also be very small• Bilingual dictionaries often exist in print, may need to use
“interlingua” such as French• Some approaches, such as those relying on translation
probabilities may not work well• Solution depends on specific application

51
Performance Evaluation

52
Constructing Test Collections
• One collection for retrospective retrieval– Start with a monolingual test collection
• Documents, queries, relevance judgments
– Translate the queries by hand
• Need 2 collections for adaptive filtering– Monolingual test collection in one language– Plus a document collection in the other language
• Generate relevance judgments for the same queries

53
Evaluating Corpus-Based Techniques
• Same domain evaluation– Partition a bilingual corpus– Design queries– Generate relevance judgments for evaluation part
• Cross-domain evaluation– Can use existing collections and corpora– No good metric for degree of domain shift
54
Evaluation Example
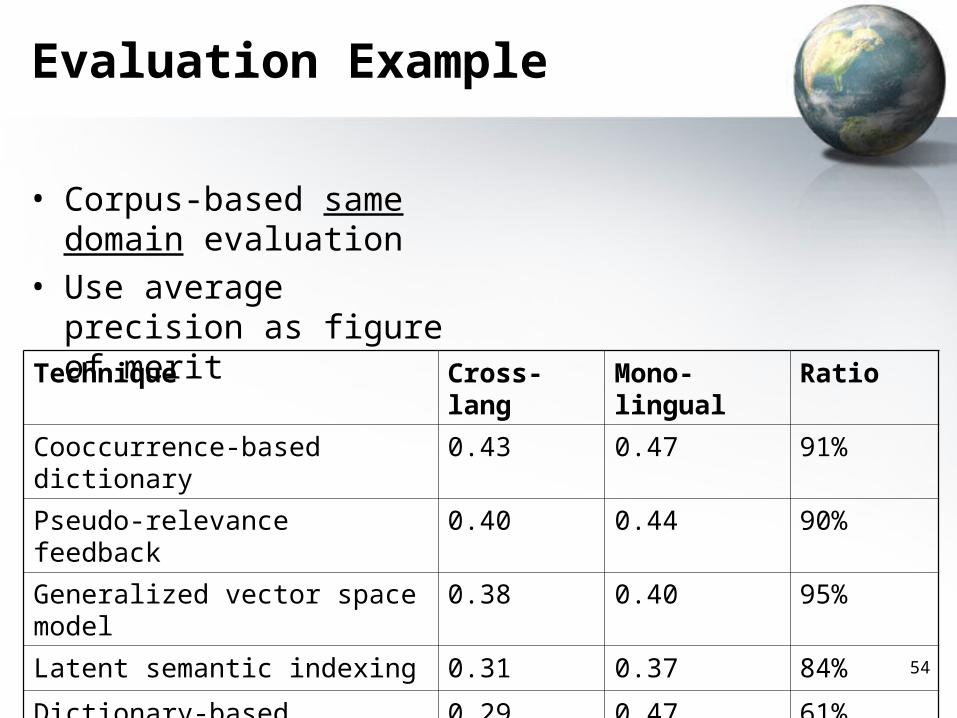
• Corpus-based same domain evaluation
• Use average precision as figure of merit
Technique Cross-lang Mono-lingual Ratio
Cooccurrence-based dictionary 0.43 0.47 91%
Pseudo-relevance feedback 0.40 0.44 90%
Generalized vector space model 0.38 0.40 95%
Latent semantic indexing 0.31 0.37 84%
Dictionary-based translation 0.29 0.47 61%

55
User Interface Design

56
Query Formulation
• Interactive word sense disambiguation
• Show users the translated query– Retranslate it for monolingual users
• Provide an easy way of adjusting it– But don’t require that users adjust or approve it

57
Selection and Examination
• Document selection is a decision process– Relevance feedback, problem refinement, read it– Based on factors not used by the retrieval system
• Provide information to support that decision– May not require very good translations
• e.g., Word-by-word title translation
– People can “read past” some ambiguity• May help to display a few alternative translations

58
References
• Miguel E. Ruiz. Cross Language Information Retrieval (CLIR). Power point presentation, University of Buffalo. 2002
• Douglas W Oard, Bonnie J Dorr. A Survey of Multilingual Text Retrieval .1996
• Jian-Yun Nie: Cross-Language Information Retrieval. IEEE Computational Intelligence Bulletin 2(1): 19-24 (2003)
• Hansen, Preben and Petrelli, Daniela and Karlgren, Jussi and Beaulieu, Micheline and Sanderson, Mark (2002) User-Centered Interface Design for Cross-Language Information Retrieval. In: Proceedings of the Twenty-fifth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland. 2002
• Elizabeth D. Liddy and Anne R. Diekema. Cross-Language Information Exploitation of Arabic. Power point presentation April 2005








![Building Bilingual Dictionaries From Parallel Web Documents · The bilingual dictionary can then be put to a variety of uses including Cross-Language Information Retrieval (CLIR)[7]](https://img.pdfslide.us/doc/110x75/5f42923032efa8693f20f617/building-bilingual-dictionaries-from-parallel-web-documents-the-bilingual-dictionary.jpg)




















