Embed Size (px)
Citation preview

1
Conditional Dependencies
Wenfei Fan
University of Edinburgh
and
Bell Laboratories

2
Conditional functional dependencies (CFDs)
– Motivation for extending FDs with conditions: data cleaning
– Syntax and semantics
– Static analysis: satisfiability, implication, axiomatizability Conditional inclusion dependencies (CINDs)
– Motivation: data cleaning and schema matching
– Syntax and semantics
– Static analysis: satisfiability, implication, axiomatizability Algorithms and open research issues
– SQL techniques for inconsistency detection– Heuristic for satisfiability and implication checking– Repair
Outline of Part III

3
Conditional functional dependencies (CFDs)
– Motivation for extending FDs with conditions: data cleaning
– Syntax and semantics
– Static analysis: satisfiability, implication, axiomatizability Conditional inclusion dependencies (CINDs)
– Motivation: data cleaning and schema matching
– Syntax and semantics
– Static analysis: consistency, implication, axiomatizability Algorithms and open research issues
– SQL techniques for inconsistency detection– Heuristic for satisfiability and implication checking– Repair
Conditional functional dependencies (CFDs)

4
Data in real-life is often dirty
Errors, conflicts and inconsistencies
Australia: 500,000 dead people retain active Medicare cards
US: Pentagon asked 275 dead/wounded officers to re-enlist.
UK: there are 81 million National Insurance numbers but only 60
million eligible citizens.
It is estimated that in a 500,000 customer database, 120,000
customer records become invalid within a year, due to deaths,
divorces, marriages, moves.
typical data error rate in industry: 1% - 5%, up to 30%
. . .

5
Dirty data is costly
Poor data costs US companies $600 billion annually
Wrong price data in retail databases costs US customers $2.5
billion each year
AAA improves data quality by 20%, and saves $150,000… in
postage stamps alone
30%-80% of the development time for data cleaning in a data
integration project
and don’t forget
CIA intelligence on WMD in Iraq!
The need for (semi-)automated methods to clean data!

6
Characterizing the consistency of data
One of the central technical problems is how to tell whether the
data is dirty or clean
Specify consistency using integrity constraints
Inconsistencies emerge as violations of constraints
Constraints considered so far: traditional – functional dependencies– inclusion dependencies– denial constraints (a special case of full dependencies)– . . .
Question: are these traditional dependencies sufficient?
7
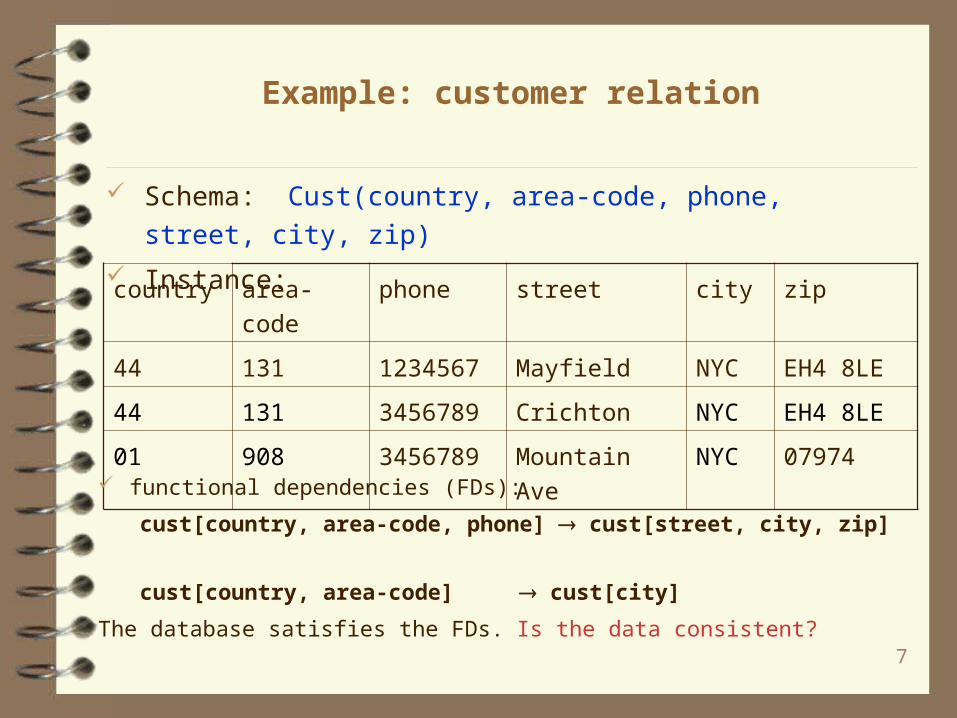
Example: customer relation
Schema: Cust(country, area-code, phone, street, city, zip)
Instance:
country area-code phone street city zip
44 131 1234567 Mayfield NYC EH4 8LE
44 131 3456789 Crichton NYC EH4 8LE
01 908 3456789 Mountain Ave NYC 07974
functional dependencies (FDs):
cust[country, area-code, phone] cust[street, city, zip]
cust[country, area-code] cust[city]
The database satisfies the FDs. Is the data consistent?
8
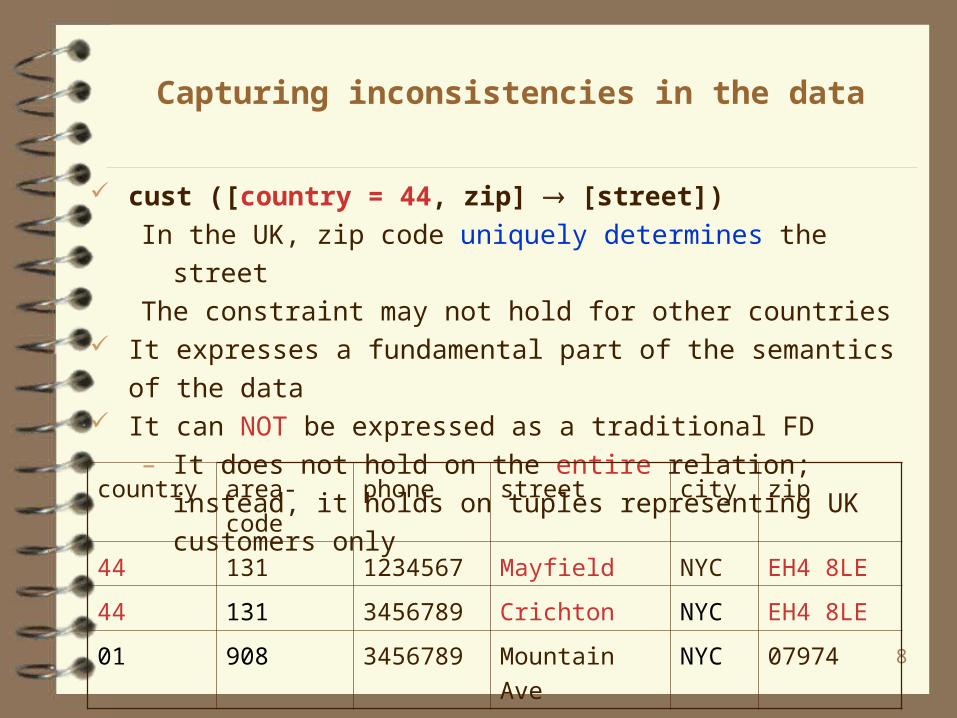
Capturing inconsistencies in the data
cust ([country = 44, zip] [street])
In the UK, zip code uniquely determines the street
The constraint may not hold for other countries It expresses a fundamental part of the semantics of the data It can NOT be expressed as a traditional FD
– It does not hold on the entire relation; instead, it holds on
tuples representing UK customers only
country area-code phone street city zip
44 131 1234567 Mayfield NYC EH4 8LE
44 131 3456789 Crichton NYC EH4 8LE
01 908 3456789 Mountain Ave NYC 07974
9
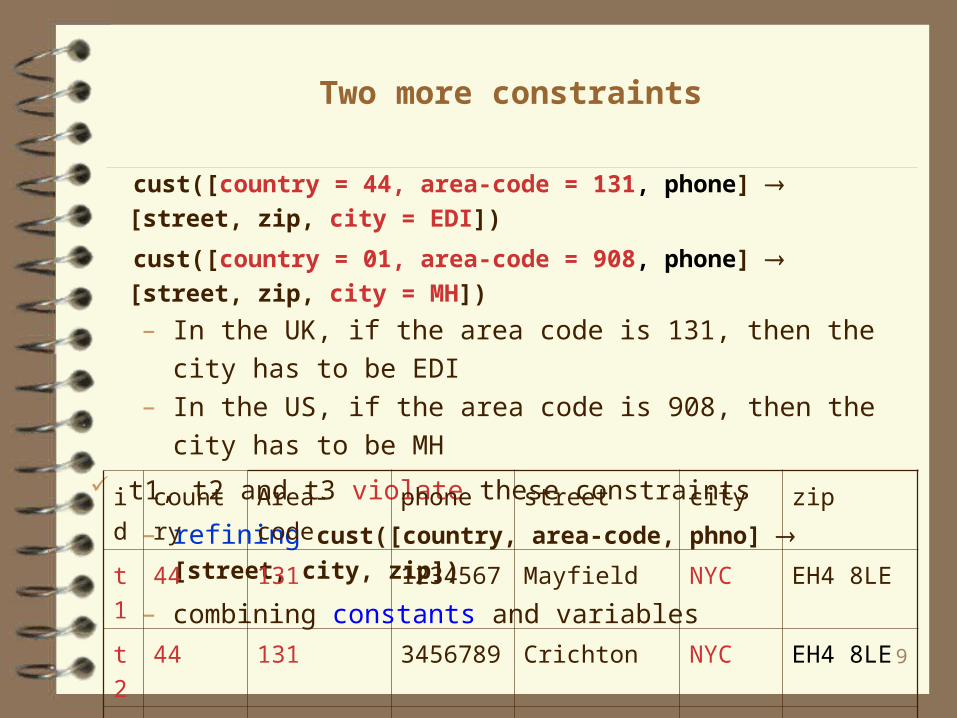
Two more constraints
cust([country = 44, area-code = 131, phone] [street, zip, city = EDI])
cust([country = 01, area-code = 908, phone] [street, zip, city = MH])
– In the UK, if the area code is 131, then the city has to be EDI– In the US, if the area code is 908, then the city has to be MH
t1, t2 and t3 violate these constraints
– refining cust([country, area-code, phno] [street, city, zip])
– combining constants and variables
id country Area-code phone street city zip
t1 44 131 1234567 Mayfield NYC EH4 8LE
t2 44 131 3456789 Crichton NYC EH4 8LE
t3 01 908 3456789 Mountain Ave NYC 07974

10
The need for new constraints
cust([country = 44, zip] [street])
cust([country = 44, area-code = 131, phone] [street, zip, city = EDI])
cust([country = 01, area-code = 908, phone] [street, zip, city = MH])
They capture inconsistencies that traditional FDs cannot detect
Traditional constraints were developed for schema design, not for
data cleaning! Data integration in real-life: source constraints
– hold on a subset of sources– hold conditionally on the integrated data
They are NOT expressible as traditional FDs– do not hold on the entire relation– contain constant data values, besides logical variables

11
An extension of traditional FDs: (R: X Y, Tp) X Y: embedded traditional FD on R Tp: a pattern tableau
– attributes: X Y
– each tuple in Tp consists of constants and unnamed
variable _
Example: cust([country = 44, zip] [street]) (cust (country, zip street), Tp) pattern tableau Tp
Conditional Functional Dependencies (CFDs)
country zip street
44 _ _

12
Represent
cust([country = 44, area-code = 131, phone] [street, zip, city = EDI])
cust([country = 01, area-code = 908, phone] [street, zip, city = MH])
cust([country, area-code, phone] [street, city, zip])
as a SINGLE CFD: (cust(country, area-code, phone street, city, zip), Tp) pattern tableau Tp: one tuple for each constraint
Example CFDs
country area-code phone street city zip
44 131 _ _ Edi _
01 908 _ _ MH _
_ _ _ _ _ _

13
Express
cust[country, area-code] cust[city]
as a CFD: (cust(country, area-code, city), Tp) pattern tableau Tp: a single tuple consisting of _ only
CFDs subsume traditional FDs
Traditional FDs as a special case
country area-code city
_ _ _

14
a b (a matches b) if – either a or b is _ – both a and b are constants and a = b
tuple t1 matches t2: t1 t2
(a, b) (a, _), but (a, b) does not match (a, c)
DB satisfies (R: X Y, Tp) iff for any tuple tp in the pattern tableau Tp and for any tuples t1, t2 in DB, if t1[X] = t2[X] tp[X], then t1[Y] = t2[Y] tp[Y]– tp[X]: identifying the set of tuples on which the constraint tp
applies, ie, { t | t[X] tp[X]} – t1[Y] = t2[Y] tp[Y]: enforcing the embedded FD, and the
pattern of tp
Semantics of CFDs
15
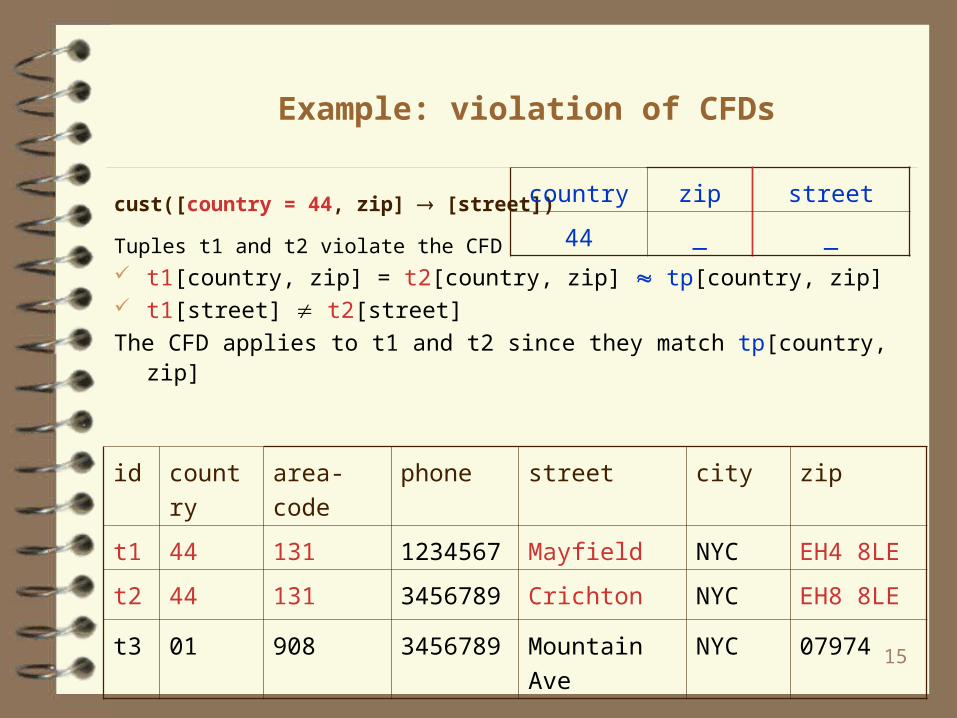
cust([country = 44, zip] [street])
Tuples t1 and t2 violate the CFD t1[country, zip] = t2[country, zip] tp[country, zip] t1[street] t2[street]
The CFD applies to t1 and t2 since they match tp[country, zip]
Example: violation of CFDs
id country area-code phone street city zip
t1 44 131 1234567 Mayfield NYC EH4 8LE
t2 44 131 3456789 Crichton NYC EH8 8LE
t3 01 908 3456789 Mountain Ave NYC 07974
country zip street
44 _ _
16
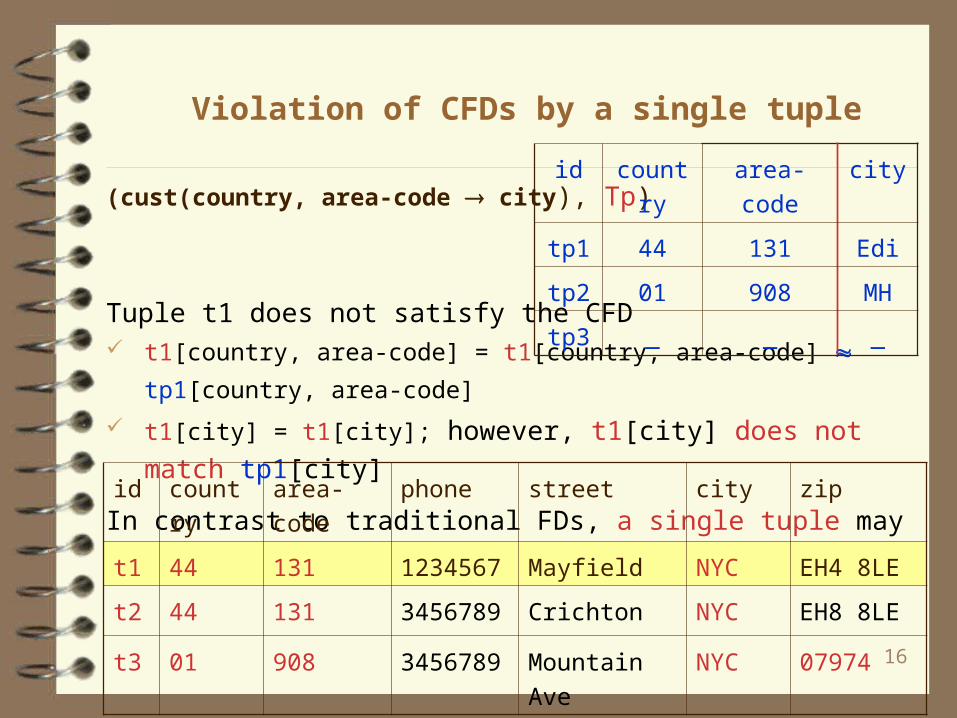
(cust(country, area-code city), Tp)
Tuple t1 does not satisfy the CFD t1[country, area-code] = t1[country, area-code] tp1[country, area-code] t1[city] = t1[city]; however, t1[city] does not match tp1[city]
In contrast to traditional FDs, a single tuple may violate a CFD
Violation of CFDs by a single tuple
id country area-code city
tp1 44 131 Edi
tp2 01 908 MH
tp3 _ _ _
id country area-code phone street city zip
t1 44 131 1234567 Mayfield NYC EH4 8LE
t2 44 131 3456789 Crichton NYC EH8 8LE
t3 01 908 3456789 Mountain Ave NYC 07974

17
Conditional tables, Codd tables and variable tables have been studied for incomplete information
Conditional tables: representing infinitely many relation instances, one for each instantiation of variables
Pattern tableau in a CFD: each pattern tuple is a constraint, and all constraints applying to the same relation instance
Relational table, traditional dependencies and CFDs One end of the spectrum: relations consisting of data only The other end of the spectrum: traditional dependencies defined
in terms of logic variables CFD: in the between, both data values and logic variables
CFDs: enforcing binding of semantically related data values
CFDs vs. conditional tables

18
“Dirty” constraints?
A set of CFDs may be inconsistent!
Inconsistent: (R(A B), Tp)
In any nonempty database DB and for any tuple t in DB,– tp1: t[B] must be b– tp2: t[B] must be c– Inconsistent if b and c are different
inconsistent = { 1, 2 }, 1 = (R(A B), Tp1), 2 = (R(B A), Tp2)
Why?
id A B
tp1 _ b
tp2 _ cTp
id A B
tp1 true b
tp2 false c
id B A
tp3 b false
tp4 c true

19
The satisfiability problem
The satisfiability problem for CFDs is to determine, given a set
of CFDs, whether or not there exists a nonempty database DB
that satisfies , i.e., for any in , DB satisfies .
Whether or not makes sense
For traditional FDs, it is not an issue: one can specify any FDs
without worrying about their consistency
In contrast, a set of CFDs may be inconsistent!

20
The complexity of the satisfiability analysis
Theorem. The satisfiability problem for CFDs is NP-complete.
Nontrivial: contrast this with the trivial consistency analysis of FDs!
Proof idea: Upper bound: the small model property: if is satisfiable, then
there is DB that satisfies and consists of a single tuple! Lower bound: reduction from the non-tautology problem
Good news: PTIME special cases
Theorem. Given a set of CFDs on a relation schema R, the
satisfiability of can be determined in O(| |2) time if either the schema R is predefined (fixed), or no attributes in have a finite domain
Proof idea: an extension of chase for CFDs

21
The implication problem
The implication problem for CFDs is to determine, given a set of
CFDs and a single CFD , whether implies , denoted by |=
, i.e., for any database DB, if DB satisfies , then DB satisfies .
Example:
= { 1, 2 } , 1 = (R(A B), Tp1), 2 = (R(B C), Tp2)
= (R(A C), Tp)
|= . Why?
id A B
tp1 _ b
Tp1 Tp2 id B C
tp1 _ c
id A C
tp a c

22
The complexity of the implication problem
For traditional FDs, the implication problem is in linear time
In contrast, the implication problem for CFDs is intractable
Theorem. The implication problem for CFDs is coNP-complete.
Tractable special cases
Theorem. Given a set of CFDs and a single CFD on a relation
schema R, whether |= can be determined in O((| | + | |)2)
time if either the schema R is predefined, or no attributes in and have a finite domain
Proof idea: an extension of chase for CFDs

23
Finite axiomatizability: Flashback
Armstrong’s axioms can be found in every database textbook:
Reflexivity: If Y X, then X Y
Augmentation: If X Y , then XZ YZ
Transitivity: If X Y and Y Z, then X Z
Sound and complete for FD implication, i.e, |= iff can be
inferred from using reflexivity, augmentation, transitivity.
Question: is there a sound and complete inference system for the
implication analysis of CFDs?

24
Finite axiomatizability of CFDs
Theorem. There is a sound and complete inference system I for
implication analysis of CFDs
Sound: if |- , i.e., can be proved from using I, then |= Complete: if |= , then |- using I
The inference system is more involved than its counterpart for
traditional FDs, namely, Armstrong’s axioms.
There are 5 axioms.
A normal form of CFDs: (R: X A, tp), tp is a single pattern tuple.

25
Axioms for CFDs: extension of Armstrong’s axioms
Reflexivity: If A X, then (R : X A, tp), where
A1 … Ak A A
_ … _ _ _ or
A1 … Ak A A
_ … _ a a
Augmentation: If (X A, tp) and B attr(R), then (BX A, t’p)
A1 … Ak A
tp[A1] … tp[Ak] tp[A]
A1 … Ak B A
tp[A1] … tp[Ak] _ tp[A]
tp t’p
26
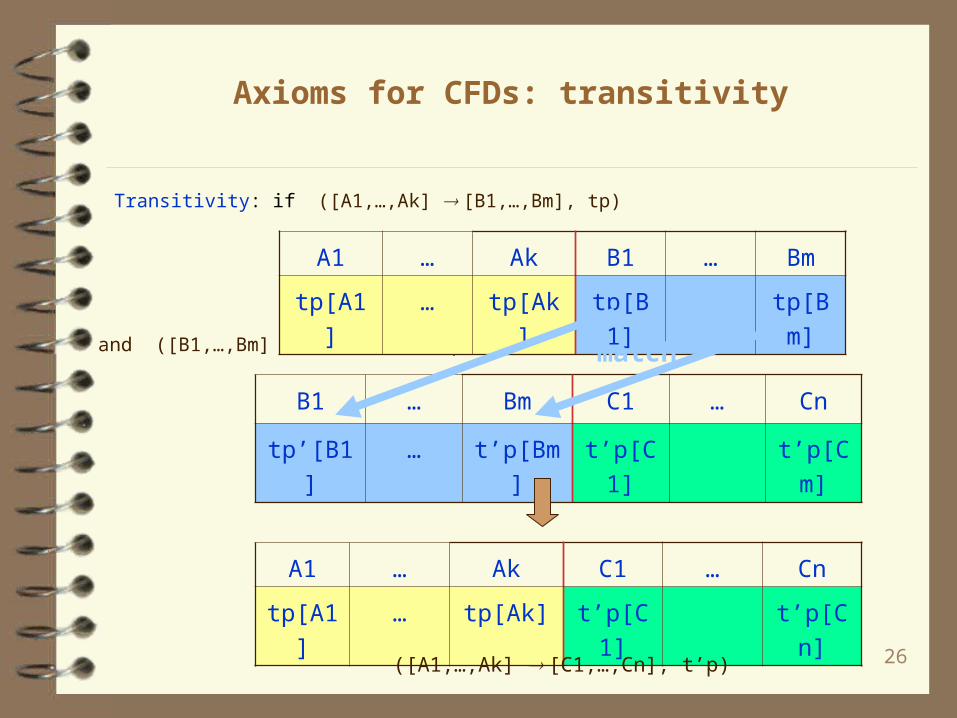
Axioms for CFDs: transitivity
Transitivity: if ([A1,…,Ak] [B1,…,Bm], tp)
and ([B1,…,Bm] [C1,…,Cn], t’p)
A1 … Ak B1 … Bm
tp[A1] … tp[Ak] tp[B1] tp[Bm]
A1 … Ak C1 … Cn
tp[A1] … tp[Ak] t’p[C1] t’p[Cn]
B1 … Bm C1 … Cn
tp’[B1] … t’p[Bm] t’p[C1] t’p[Cm]
([A1,…,Ak] [C1,…,Cn], t’p)
match
27
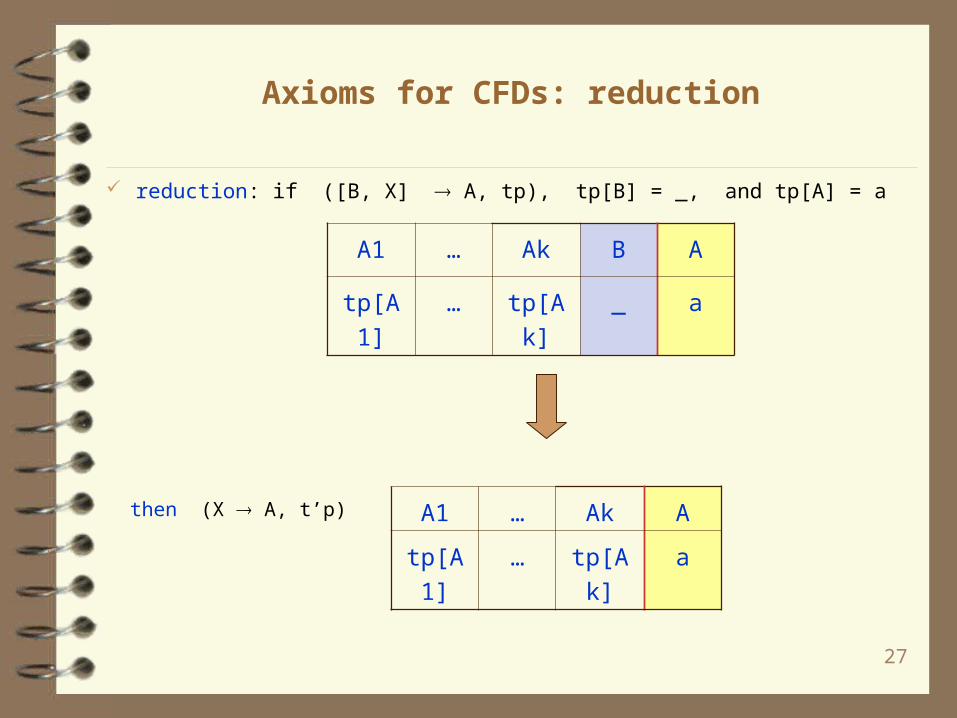
Axioms for CFDs: reduction
reduction: if ([B, X] A, tp), tp[B] = _, and tp[A] = a
A1 … Ak B A
tp[A1] … tp[Ak] _ a
then (X A, t’p) A1 … Ak A
tp[A1] … tp[Ak] a

28
Axioms for CFDs: finite domain upgrade
upgrade: if only consistent values for B are b1, b2, . . . , bn, dom(B) = { b1, …, bn, …,
bm}, and (R : [A1, . . . ,Ak, B] A, tp)
A1 … Ak B A
tp[A1] … tp[Ak] b1 tp[A]
tp[A1] … tp[Ak] … tp[A]
tp[A1] … tp[Ak] bn tp[A]
then (R : [A1, . . . ,Ak, B] A, tp)
A1 … Ak B A
tp[A1] … tp[Ak] _ tp[A]

29
Static analyses: CFD vs. FD
satisfiability implication finite axiom’tyCFD NP-complete coNP-complete yes
FD O(1) O(n) yes
General setting:
satisfiability implication finite axiom’tyCFD O(n2) O(n2) yes
FD O(1) O(n) yes
in the absence of finite-domain attributes:
Theorem: In the absence of finite-domain attributes, Reflexivity, Augmentation, Transitivity and Reduction are sound and completefor CFD implication complications: finite-domain attributes, interaction between satisfiability and implication analyses

30
Conditional functional dependencies (CFDs)
– Motivation for extending FDs with conditions: data cleaning
– Syntax and semantics
– Static analysis: satisfiability, implication, axiomatizability Conditional inclusion dependencies (CINDs)
– Motivation: data cleaning and schema matching
– Syntax and semantics
– Static analysis: consistency, implication, axiomatizability Algorithms and open research issues
– SQL techniques for inconsistency detection– Heuristic for satisfiability and implication checking– Repair
Conditional Inclusion dependencies (CINDs)
31
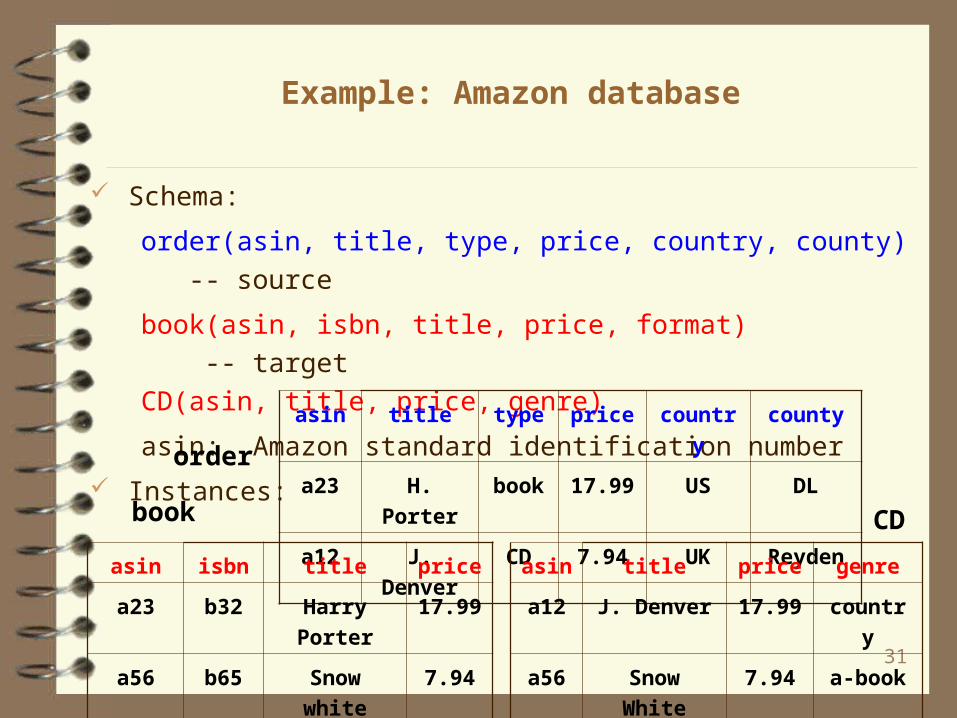
Example: Amazon database
Schema:
order(asin, title, type, price, country, county) -- source
book(asin, isbn, title, price, format) -- target
CD(asin, title, price, genre)
asin: Amazon standard identification number
Instances: asin title type price country county
a23 H. Porter book 17.99 US DL
a12 J. Denver CD 7.94 UK Reyden
asin isbn title price
a23 b32 Harry Porter 17.99
a56 b65 Snow white 7.94
asin title price genre
a12 J. Denver 17.99 country
a56 Snow White 7.94 a-book
order
book CD
32
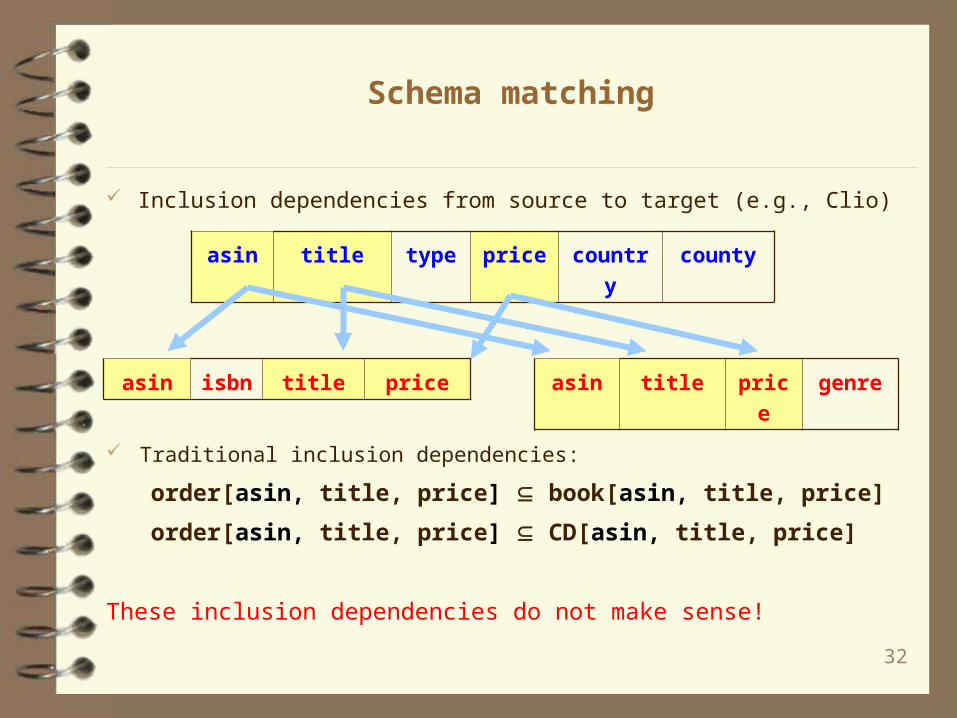
Schema matching
Traditional inclusion dependencies:
order[asin, title, price] book[asin, title, price]
order[asin, title, price] CD[asin, title, price]
These inclusion dependencies do not make sense!
Inclusion dependencies from source to target (e.g., Clio)
asin title type price country county
asin isbn title price asin title price genre
33
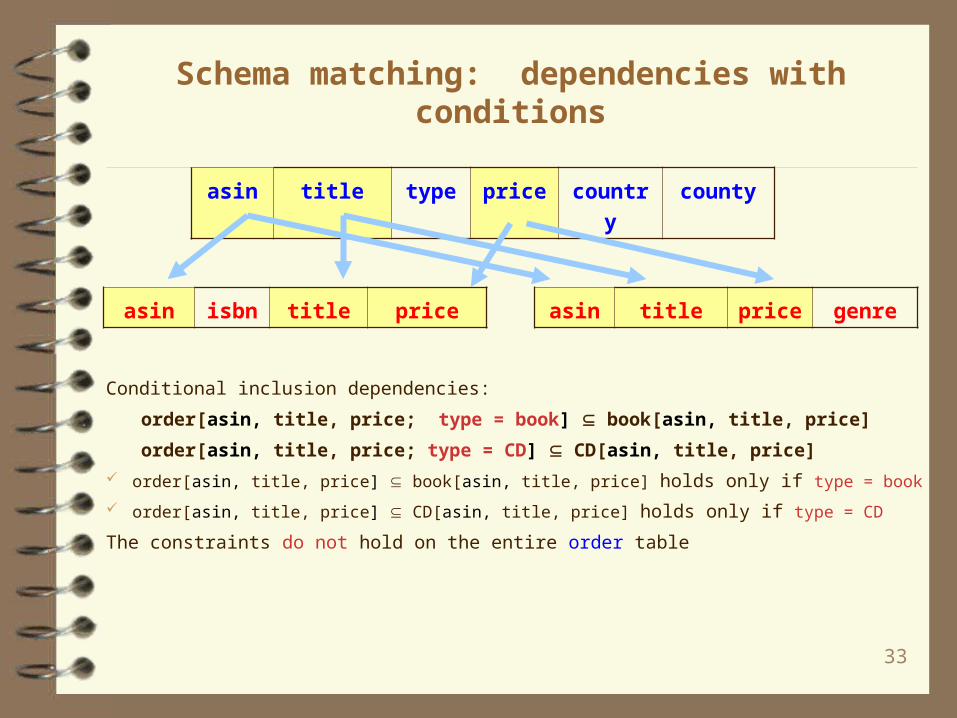
Schema matching: dependencies with conditions
asin title type price country county
asin isbn title price asin title price genre
Conditional inclusion dependencies:
order[asin, title, price; type = book] book[asin, title, price]
order[asin, title, price; type = CD] CD[asin, title, price]
order[asin, title, price] book[asin, title, price] holds only if type = book
order[asin, title, price] CD[asin, title, price] holds only if type = CD
The constraints do not hold on the entire order table
34
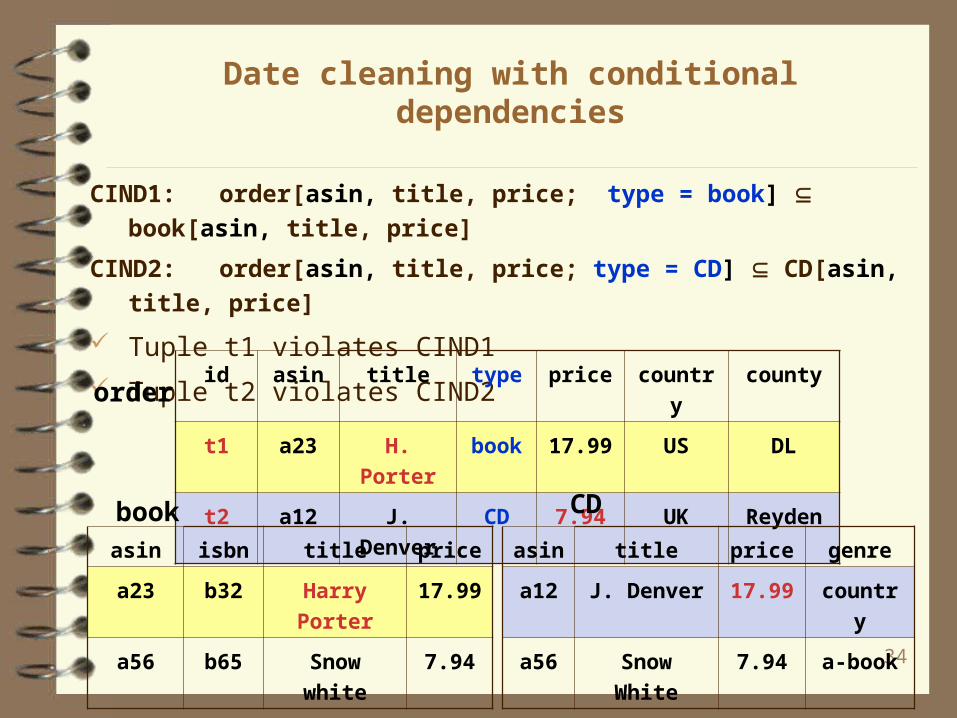
Date cleaning with conditional dependencies
CIND1: order[asin, title, price; type = book] book[asin, title, price]
CIND2: order[asin, title, price; type = CD] CD[asin, title, price]
Tuple t1 violates CIND1
Tuple t2 violates CIND2
id asin title type price country county
t1 a23 H. Porter book 17.99 US DL
t2 a12 J. Denver CD 7.94 UK Reyden
asin isbn title price
a23 b32 Harry Porter 17.99
a56 b65 Snow white 7.94
asin title price genre
a12 J. Denver 17.99 country
a56 Snow White 7.94 a-book
order
book CD

35
More on data cleaning
CD[asin, title, price; genre = ‘a-book’] book[asin, title, price; format = ‘audio’]
Inclusion relation CD[asin, title, price] book[asin, title, price] holds only if genre = ‘a-book’, i.e., when the CD is an audio book
In addition, the format of the corresponding book must be audio – a pattern for the referenced tuple
asin isbn title price format
a23 b32 Harry Porter 17.99 Hard cover
a56 b65 Snow White 17.94 audio
asin title price genre
a12 J. Denver 17.99 country
a56 Snow White 7.94 a-book
book
CD

36
(R1[X; Xp] R2[Y; Yp], Tp) R1[X] R2[Y]: embedded traditional IND from R1 to R2 Tp: a pattern tableau
– attributes: X Xp Y Yp
– tuples in Tp consist of constants and unnamed variable _
Example: express
CIND1: order[asin, title, price; type = book] book[asin, title, price]
(order[asin, title, price; type] book[asin, title, price; nil], Tp)
nil: empty list pattern tableau Tp
Conditional Inclusion Dependencies (CINDs)
asin title price type asin title price
_ _ _ book _ _ _

37
CIND2: order[asin, title, price; type = CD] CD[asin, title, price]
CIND3: CD[asin, title, price; genre = ‘a-book’] book[asin, title,
price; format = ‘audio’]
Examples CINDs
asin title price type asin title price
_ _ _ CD _ _ _
asin title price genre asin title price format
_ _ _ a-book _ _ _ audio
(order[asin, title, price; type] CD[asin, title, price; nil], Tp)
(CD[asin, title, price; genre] book[asin, title, price; format], Tp)

38
R1[X] R2[Y] X: [A1, …, An] Y : [B1, …, Bn]
As a CIND: (R1[X; nil] R2[Y; nil], Tp) pattern tableau Tp: a single tuple consisting of _ only
CINDs subsume traditional INDs
Traditional CINDs as a special case
A1 … An B1 … Bn
_ _ _ _ _ _

39
DB = (DB1, DB2), where DBj is an instance of Rj, j = 1, 2.
DB satisfies (R1[X; Xp] R2[Y; Yp], Tp) iff for any tuples t1 in DB1,
and any tuple tp in the pattern tableau Tp, if t1[X, Xp] tp[X,
Xp], then there exists t2 in DB2 such that t1[Y] = t2[Y] (traditional IND semantics) t2[Y, Yp] tp[Y, Yp] (matching the pattern tuple on Y, Yp)
Patterns: t1[X, Xp] tp[X, Xp]: identifying the set of R1 tuples on which tp
applies: { t1 | t1[X, Xp] tp[X, Xp] } t2[Y, Yp] tp[Y, Yp]: enforcing the embedded IND and the
constraint specified by patterns Y, Yp
Semantics of CINDs

40
(CD[asin, title, price; genre] book[asin, title, price; format], Tp)
The following DB satisfies the CIND
Example
asin isbn title price format
a23 b32 Harry Porter 17.99 Hard cover
a56 b65 Snow white 7.94 audio
asin title price genre
a12 J. Denver 17.99 country
a56 Snow White 7.94 a-book
book
CD
asin title price genre asin title price format
_ _ _ a-book _ _ _ audio

41
More examples
CIND1: (order[asin, title, price; type] book[asin, title, price; nil], Tp)
The following DB violates CIND1. Why?
id asin title type price country county
t1 a23 H. Porter book 17.99 US DL
t2 a12 J. Denver CD 7.94 UK Reyden
asin isbn title price
a23 b32 Harry Porter 17.99
a56 b65 Snow white 7.94
asin title price genre
a12 J. Denver 17.99 country
a56 S. White 7.94 a-book
order
book CD
asin title price type asin title price
_ _ _ book _ _ _

42
The satisfiability problem for CINDs
The satisfiability problem for CINDs is to determine, given a set of
CINDs, whether or not there exists a nonempty database DB
that satisfies , i.e., for any in , DB satisfies .
Recall
Any set of traditional INDs is always satisfiable!
For CFDs, the satisfiability problem is intractable.
In contrast.
Theorem. Any set of CINDs is always satisfiable!
Despite the increased expressive power, the complexity of the
satisfiability analysis does not go up.

43
The implication problem for CINDs
The implication problem for CINDs is to decide, given a set of
CINDs and a single CIND , whether implies ( |= ).
For traditional INDs, the implication problem is PS PACE-complete
For CINDs, the complexity does not hike up, to an extent:
Theorem. For CINDs containing no finite-domain attributes, the
implication problem is PSPACE-complete
In the general setting, however, we have to pay a price:
Theorem. The implication problem for CINDs is EXPTIME-complete
Proof idea:
Lower bound: reduction from two-player tiling game
Upper bound: an extension of the chase for CINDs

44
Finite axiomatizability of CINDs
Rules for inferring IND implication:
– Reflexivity: If R[X] R[X]
– Projection and Permutation: If R1[A1, …, Ak] R2[B1, …, Bk],
then R1[Ai1, …, Aik] R2[Bi1, …, Bik],
– Transitivity: If R1[X] R2[Y] and R2[Y] R3[Z], then
R1[X] R3[Z]
Sound and complete for IND implication
CINDs retain the finite axiomatizability
Theorem. There is a sound and complete inference system for
implication analysis of CINDs
There are 8 axioms.

45
Inference rules for CINDs
Normal form of CINDs: (R1[X; Xp] R2[Y; Yp], tp), tp is a single pattern tuple tp[A] is a constant iff A is in Xp or Yp (tp[B] = _ if B is in X or Y)
Inference rules
Reflexivity: (R[X; nil] R[X; nil], tp), where
A1 … Ak A1 … Ak
_ … _ _ … _
Projection and permutation: If (R1[X; Xp] R2[Y; Yp], tp), then (R1[X’; X’p] R2[Y’; Y’p], t’p), for any permutation of X, Xp
X Xp Y Yp
_ tp[Xp] _ tp[Yp]
tp t’p
X’ X’p Y’ Y’p
_ tp[X’p] _ tp[Y’p]
46
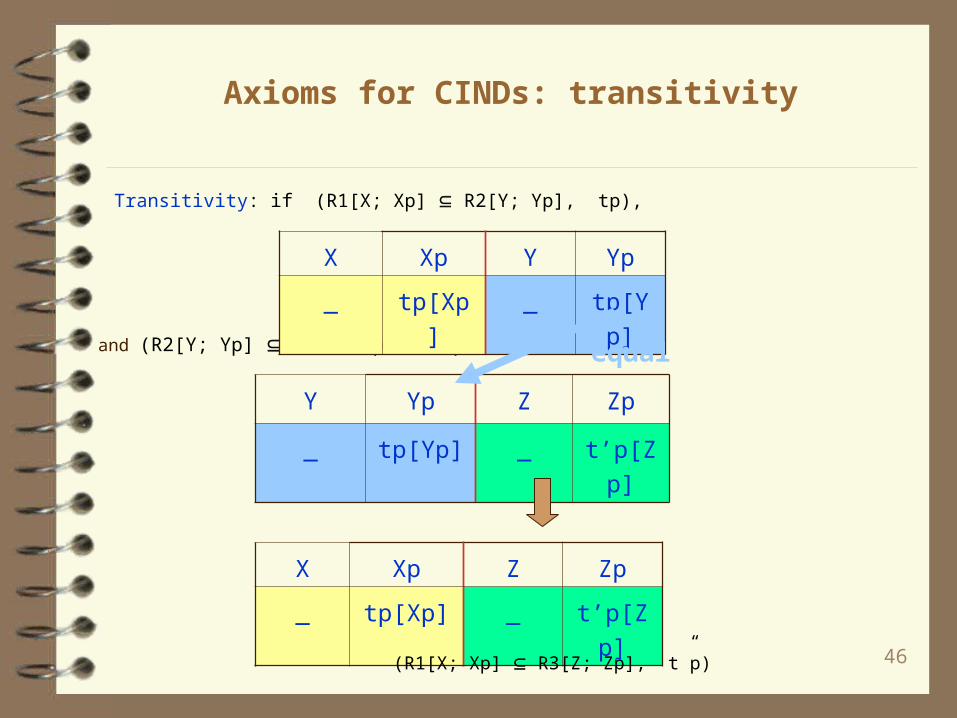
Axioms for CINDs: transitivity
Transitivity: if (R1[X; Xp] R2[Y; Yp], tp),
and (R2[Y; Yp] R3[Z; Zp], t’p),
X Xp Y Yp
_ tp[Xp] _ tp[Yp]
X Xp Z Zp
_ tp[Xp] _ t’p[Zp]
Y Yp Z Zp
_ tp[Yp] _ t’p[Zp]
(R1[X; Xp] R3[Z; Zp], t”p)
equal
47
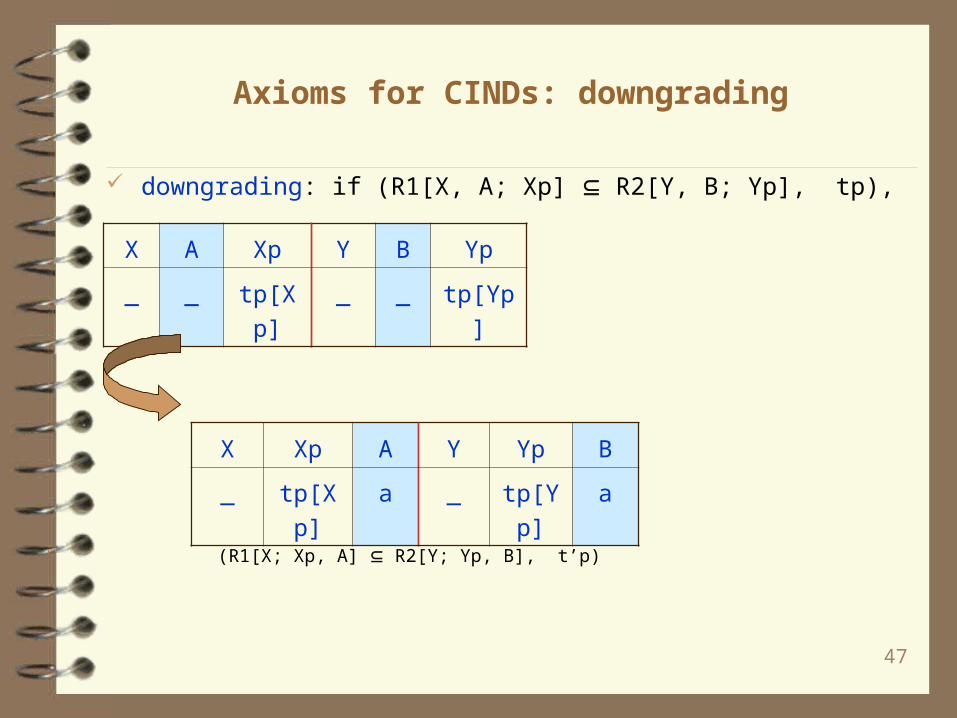
downgrading: if (R1[X, A; Xp] R2[Y, B; Yp], tp),
X A Xp Y B Yp
_ _ tp[Xp] _ _ tp[Yp]
(R1[X; Xp, A] R2[Y; Yp, B], t’p)
X Xp A Y Yp B
_ tp[Xp] a _ tp[Yp] a
Axioms for CINDs: downgrading
48
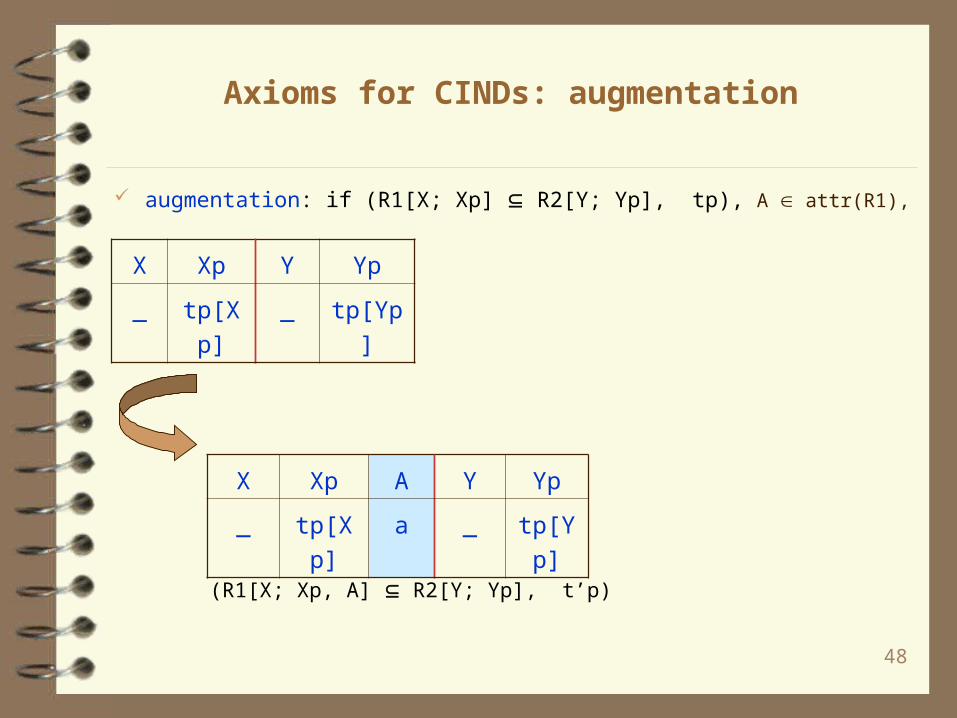
Axioms for CINDs: augmentation
augmentation: if (R1[X; Xp] R2[Y; Yp], tp), A attr(R1),
X Xp Y Yp
_ tp[Xp] _ tp[Yp]
X Xp A Y Yp
_ tp[Xp] a _ tp[Yp]
(R1[X; Xp, A] R2[Y; Yp], t’p)
49
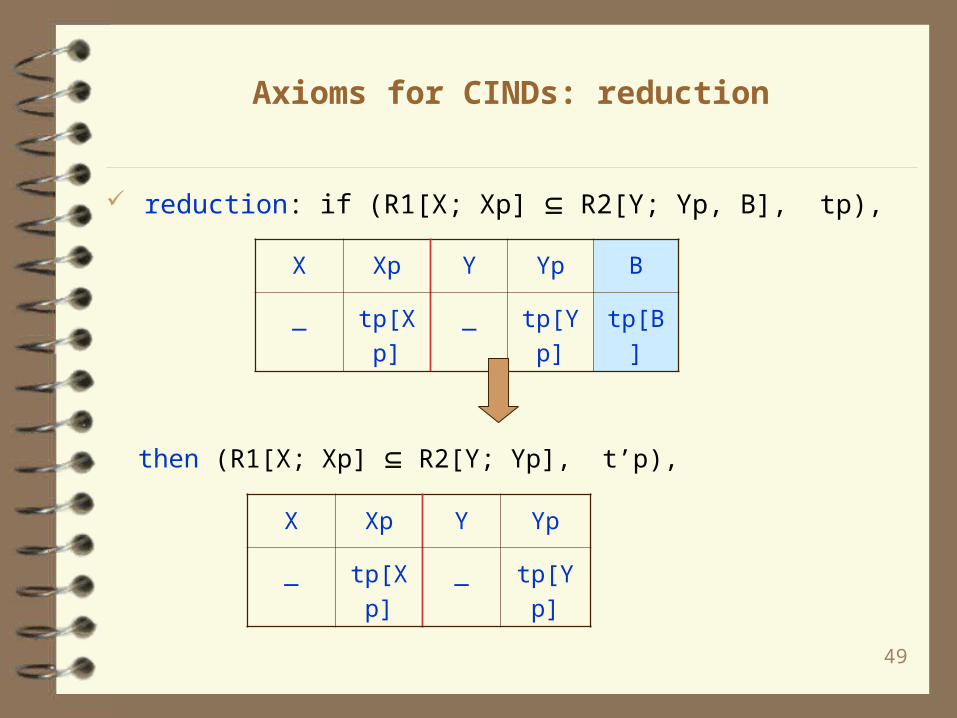
Axioms for CINDs: reduction
reduction: if (R1[X; Xp] R2[Y; Yp, B], tp),
X Xp Y Yp B
_ tp[Xp] _ tp[Yp] tp[B]
then (R1[X; Xp] R2[Y; Yp], t’p),
X Xp Y Yp
_ tp[Xp] _ tp[Yp]

50
Axioms for CFDs: finite domain reduction
F-reduction: if (R1[X; Xp, A] R2[Y; Yp], tp),
dom(A) = { a1,…, an}
X Xp A Y Yp
_ tp[Xp] a1 _ tp[Yp]
_ tp[Xp] … _ tp[Yp]
_ tp[Xp] an _ tp[Yp]
then (R1[X; Xp] R2[Y; Yp], tp),
X Xp Y Yp
_ tp[Xp] _ tp[Yp]

51
Axioms for CFDs: finite domain upgrade
upgrade: if (R1[X; Xp, A] R2[Y, B; Yp], tp),
dom(A) = { a1,…, an}
X Xp A Y Yp B
_ tp[Xp] a1 _ tp[Yp] a1
_ tp[Xp] … _ tp[Yp] …
_ tp[Xp] an _ tp[Yp] an
then (R1[X,A; Xp] R2[Y, B; Yp], tp),
X A Xp Y B Yp
_ _ tp[Xp] _ _ tp[Yp]
52
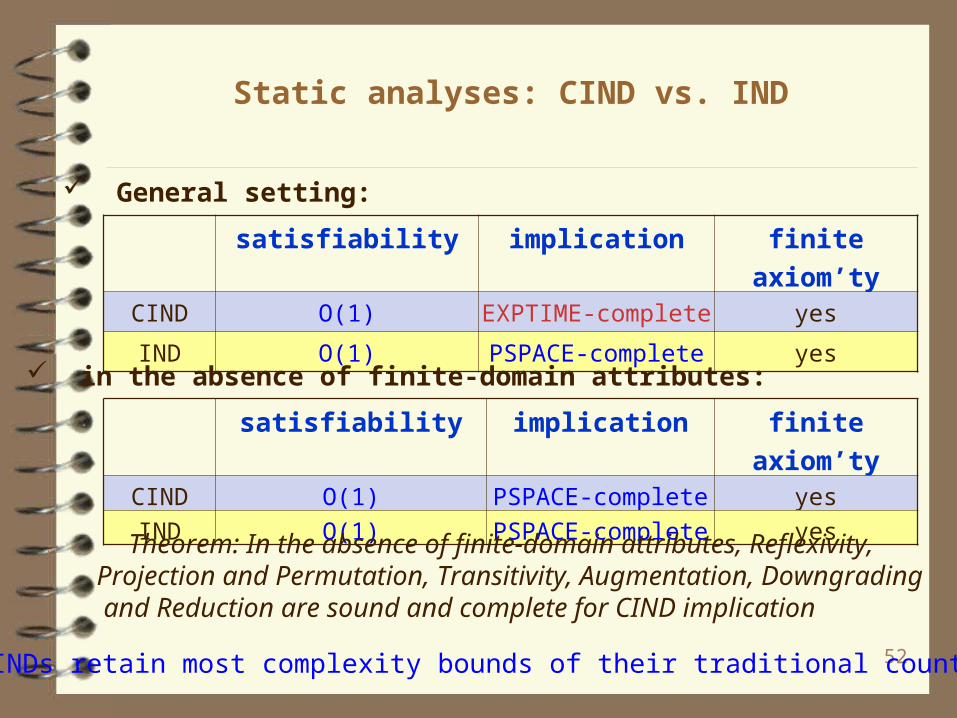
Static analyses: CIND vs. IND
satisfiability implication finite axiom’tyCIND O(1) EXPTIME-complete yes
IND O(1) PSPACE-complete yes
General setting:
satisfiability implication finite axiom’tyCIND O(1) PSPACE-complete yes
IND O(1) PSPACE-complete yes
in the absence of finite-domain attributes:
Theorem: In the absence of finite-domain attributes, Reflexivity, Projection and Permutation, Transitivity, Augmentation, Downgrading and Reduction are sound and complete for CIND implication
CINDs retain most complexity bounds of their traditional counterpart

53
CFDs and CINDs taken together
We need both CFDs and CINDs for data cleaning schema matching
Theorem. The implication problem for CFDs and CINDs is
undecidable
Not surprising: The implication problem for traditional FDs and INDs
is already undecidable
Theorem. The consistency problem for CFDs and CINDs is
undecidable
In contrast, any set of traditional FDs and INDs is consistent!
Proof idea: induction from the implication problem for FDs and INDs

54
Static analyses: CFD + CIND vs. FD + IND
satisfiability implication finite axiom’tyCFD + CIND undecidable undecidable No
FD + IND O(1) undecidable No
CINDs and CFDs properly subsume FDs and INDs
Both the satisfiability analysis and implication analysis are
beyond reach in practice
This calls for effective heuristic methods

55
Conditional functional dependencies (CFDs)
– Motivation for extending FDs with conditions: data cleaning
– Syntax and semantics
– Static analysis: satisfiability, implication, axiomatizability Conditional inclusion dependencies (CINDs)
– Motivation: data cleaning and schema matching
– Syntax and semantics
– Static analysis: consistency, implication, axiomatizability Algorithms and open research issues
– SQL techniques for inconsistency detection– Heuristic for satisfiability and implication checking– Repair
Algorithms and open research issues
56
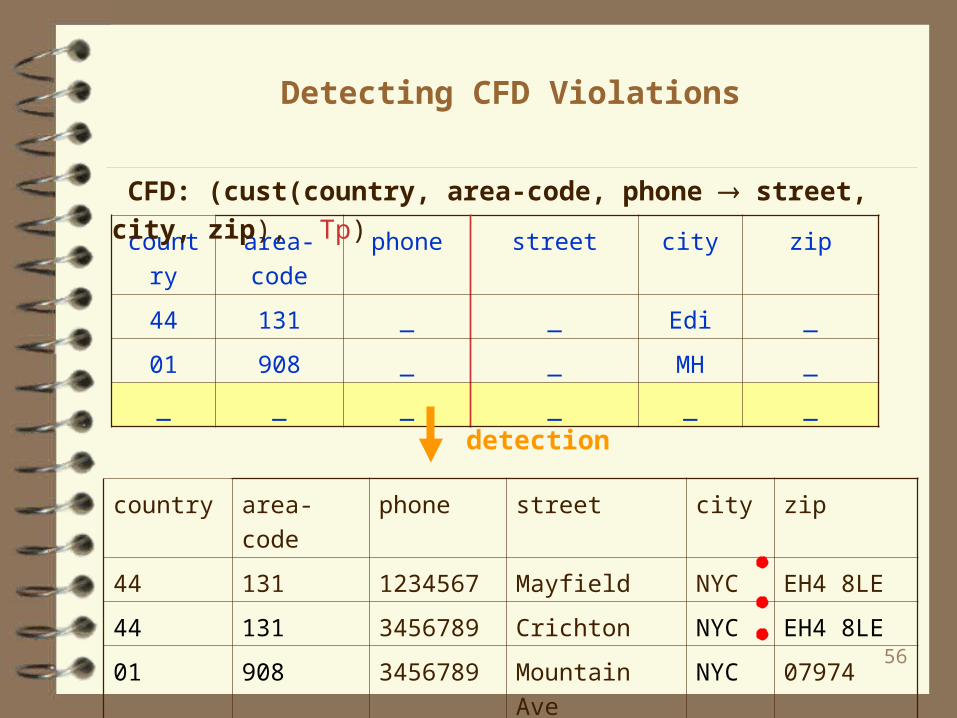
Detecting CFD Violations
country area-code phone street city zip
44 131 _ _ Edi _
01 908 _ _ MH _
_ _ _ _ _ _
country area-code phone street city zip
44 131 1234567 Mayfield NYC EH4 8LE
44 131 3456789 Crichton NYC EH4 8LE
01 908 3456789 Mountain Ave NYC 07974
CFD: (cust(country, area-code, phone street, city, zip),
Tp)
detection

57
Detecting CFD violations
Input: a set of CFDs and a database DB
Output: the set of tuples in DB that violate at least one CFD in
Approach: automatically generate SQL queries to find violations
Complication 1: consider (R: X Y, Tp), the pattern tableau may be
large (recall that each tuple in Tp is in fact a constraint)
Goal: the size of the SQL queries is independent of Tp
Trick: treat Tp as a data table
CINDs can be checked along the same lines

58
Single CFD: step 1
A pair of SQL queries, treating Tp as a data table
– Single-tuple violation (pattern matching)
– Multi-tuple violations (traditional FDs)
(cust(country, area-code, phone street, city, zip), Tp)
Single-tuple violation: Qc
select *
from R t, Tp tp
where t[country] tp[country] AND t[area-code] tp[area-code]
AND t[phone] tp[phone]
(t[street] <> tp[street] OR t[city] <> tp[city] OR t[zip] <> tp[zip]))
– <>: not matching;
– t[A1] tp[A1]: (t[A1] = tp[A1] OR tp[A1] = _)

59
Single CFD: step 2
Multi-tuple violations (the semantics of traditional FDs): Qvselect distinct t.country, t.area-code, t.phone
from R t, Tp tp
where t[country] tp[country] AND t[area-code] tp[area-code]
AND t[phone] tp[phone]
group by t.country, t.area-code, t.phone
having count(distinct street, city, zip) > 1
Tp is treated as a data table
(cust(country, area-code, phone street, city, zip), Tp)

60
Multiple CFDs
Complication 2: if the set has n CFDs, do we use 2n SQL queries,
and thus 2n passes of the database DB?
Goal: 2 SQL queries no matter how many CFDs are in the size of the SQL queries is independent of Tp
Trick: merge multiple CFDs into one Given (R: X1 Y1, Tp1), (R: X2 Y2, Tp2) Create a single pattern table: Tm = X1 X2 Y1 Y2, Introduce @, a don’t-care variable, to populate attributes of
pattern tuples in X1 – X2, etc (tp[A] = @) Modify the pair of SQL queries by using Tm

61
Handling multiple CFDs
zip state
07974 NJ
90291 CA
01202 _
CFD2: (zipstate, T2)area state
_ _
212 NY
CFD1: (areastate, T1)
area zip state
480 95120 CA
310 90995 CA
CFD3: (area,zipstate, T3)
area zip state
CFD2: @ 07974 NJ
CFD2: @ 90291 CA
CFD2: @ 01202 _
CFD1: _ @ _
CFD1: 212 @ NY
CFD3: 480 95120 CA
CFD3: 310 90995 CA
CFDM:(area,zipstate, TM)
Qc: select * from R t, TM tp where t[area] ≍ tp[area] AND t[zip] ≍ tp[zip] AND t[state] <> tp[state]
Qv: select distinct area, zip from Macro group by area, zip having count(distinct state) > 1
Macro:
select (case tp[area] when “@” then “@” else t[area] end) as area . . .
from R t, TM tp
where t[area] ≍ tp[area] AND t[zip] ≍ tp[zip] AND tp[state] =_

62
Keeping things tidy…
cc area phone addr city zip statet1: +1 908 111-1111 Elm Str. MH 07974 NJt2: +1 908 222-2222 Pine Str. MH 07974 NYt3: +1 212 333-3333 Oak Str. NYC 01202 NYt4: +1 310 444-4444 Main Str. LA 90291 CA
area state
_ _
212 NY
CFD: (areastate, T)
t5: +1 310 555-5555 Rice Str. LA 90291 CT
Tuple deletions: A tuple deletion might remove violations.
Tuples that were dirty, before the deletion, might become clean!
Tuple insertions: A tuple insertion might introduce violations.
Tuples that were clean, before the insertion, might become dirty!
Updating database

63
Incremental inconsistency detection
Incremental approach: compute change V such that
the new violations V’ = the old violations V + V
Why?
Input: a set of CFDs, a database DB, the set V of tuples in DB
that violate , and changes DB to DB
Output: the set V’ of tuples in DB + DB that violate CFDs in
DB: a set of tuples to be inserted into DB or deleted from DB
Approaches: Batch approach:
– Compute DB’ = DB + DB – Apply the SQL detection queries to DB’

64
The need for incremental inconsistency detection
Small DB to DB tends to incur only small changes V to V
– more efficient to compute V then computing V’ starting from
scratch
Minimize unnecessary recomputation and traversal of DB
Goal: generate new SQL queries that perform incremental detection
modify the SQL detection queries by leveraging DB and V
design and maintain auxiliary structures (indexing, mark)
65
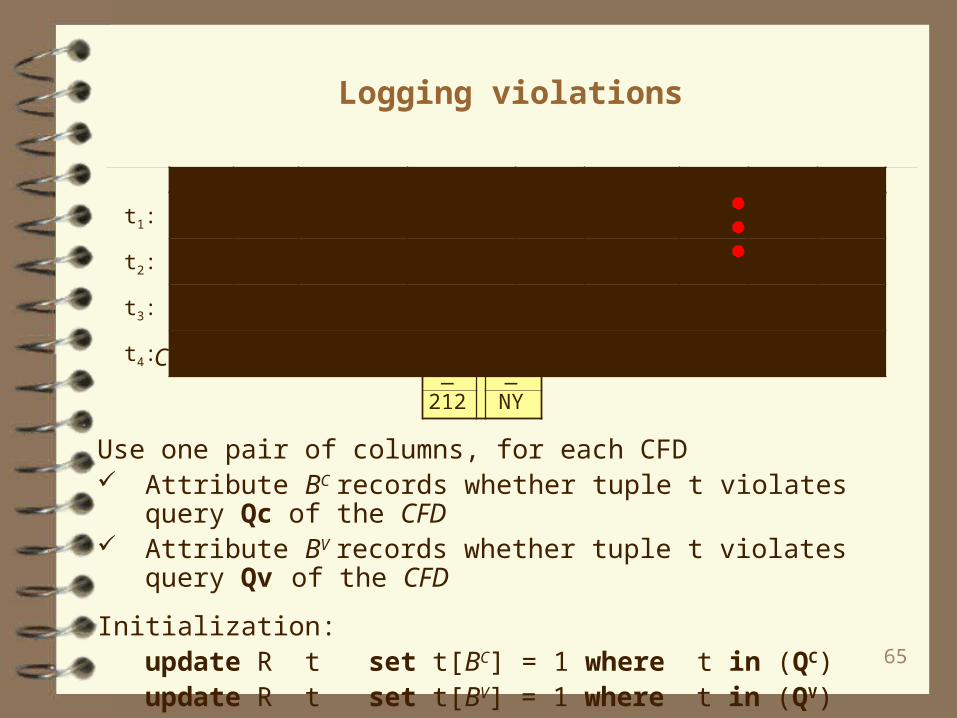
Logging violations
area state
_ _
212 NY
CFD: (areastate, T)
cc area phone addr city zip state BC BV
t1: +1 908 111-1111 Elm Str. MH 07974 NJ 0 1t2: +1 908 222-2222 Pine Str. MH 07974 NY 0 1t3: +1 212 333-3333 Oak Str. NYC 01202 NJ 1 0t4: +1 310 444-4444 Main Str. LA 90291 CA 0 0
Use one pair of columns, for each CFD Attribute BC records whether tuple t violates query Qc of the CFD Attribute BV records whether tuple t violates query Qv of the CFD
Initialization:update R t set t[BC] = 1 where t in (QC)update R t set t[BV] = 1 where t in (QV)

66
Handling deletions
Let tdel be the tuple we want to delete from R
Step 1: delete from R t where t = tdel
Step 2: update R t set t[BV] = 0
where t[BV] = 1 AND t[area] = tdel[area] AND 1 = (select count(distinct state) from R t’
where t’[area] = tdel[area])
cc area phone addr city zip state BC BV
t1: +1 908 111-1111 Elm Str. MH 07974 NY 0 1t2: +1 908 222-2222 Pine Str. MH 07974 NJ 0 1t3: +1 212 333-3333 Oak Str. NYC 01202 NJ 1 0t4: +1 310 444-4444 Main Str. LA 90291 CA 0 0
area state
_ _
212 NY
CFD: (areastate, T) How about
batch deletions?How about
batch deletions?
67
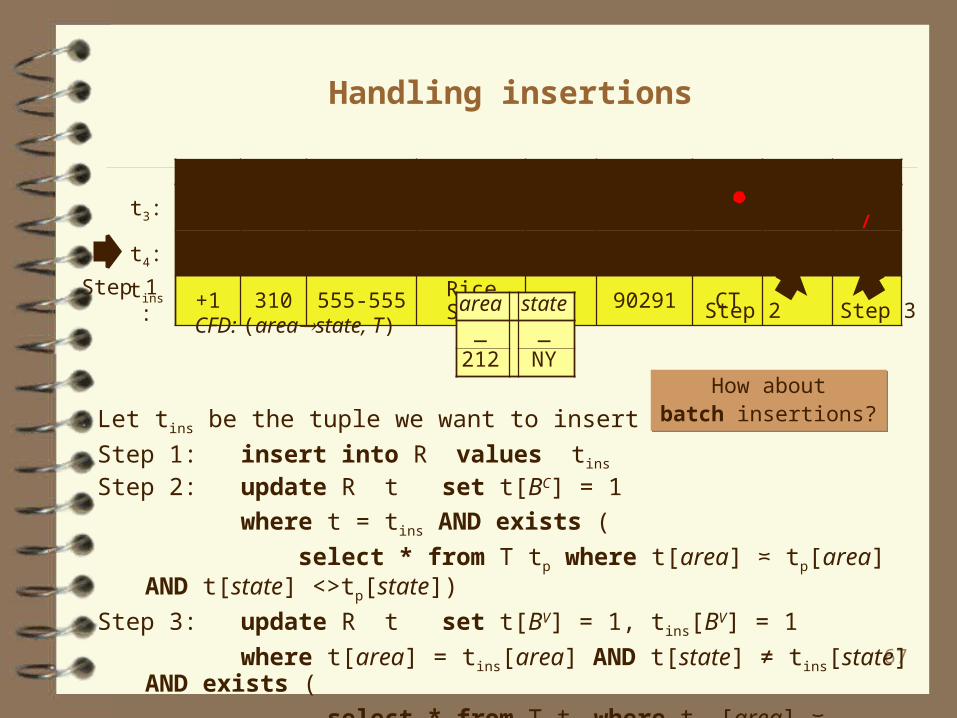
Handling insertions
cc area phone addr city zip state BC BV
t3: +1 212 333-3333 Oak Str. NYC 01202 NJ 1 0t4: +1 310 444-4444 Main Str. LA 90291 CA 0 0tins: +1 310 555-555 Rice Str. LA 90291 CT
area state
_ _
212 NY
CFD: (areastate, T)
Let tins be the tuple we want to insert into R
Step 1: insert into R values tins
Step 2: update R t set t[BC] = 1
where t = tins AND exists (
select * from T tp where t[area] t≍ p[area] AND t[state] <>tp[state])
Step 3: update R t set t[BV] = 1, tins[BV] = 1
where t[area] = tins[area] AND t[state] ≠ tins[state] AND exists (
select * from T tp where tins[area] t≍ p[area] AND tp[state] = _)
Step 2 Step 3
0 1
/ 1
Step 1
How aboutbatch insertions?
How aboutbatch insertions?

68
Handling batch insertions
Step 1
Let Rins be the tuples we want to insert into R
Step 1: Find tuples in Rins which violate Qc
Step 2: Find clean tuples in R that become
dirty, due to some tuple(s) in Rins
Step 3: Find tuples in Rins that become dirty
due to some dirty tuple(s) in R
Step 4: Find clean tuples in Rins that violate the CFD
Step 5: Insert Rins in R
Step 2
Step 3
Step 4
Rins:
R:

69
The source code
Let Rins be the tuples we want to insert into R
Step 1: update Rins tins set tins[BC] = 1 where tins in (QC)
Step 2: update R t set t[BV] = 1 where t[BC] = 0 AND t[BV] = 0 AND
exists (select * from T where t[area] t≍ p[area] AND tp[state] = _) AND
exists (select * from Rins tins where tins[area] = t[area] AND
tins[state] ≠ t[state])
Step 3: update Rins tins set tins[BV] = 1 where
exists (select * from R t where tins[area] = t[area] AND t[BV] = 1)
Step 4: update Rins tins set tins[BV] = 1 where tins[BC] = 0 AND tins[BV] = 0 AND
tins[area] IN (select area from Rins t’ins, Tp tp where
t’ins[BC] = 0 AND t’ins[BV] = 0 AND t’ins[area] t≍ p[area] AND
tp[state] = _
group by area having count(distinct state) > 1)
Step 5: insert into R values (select * from Rins)
70
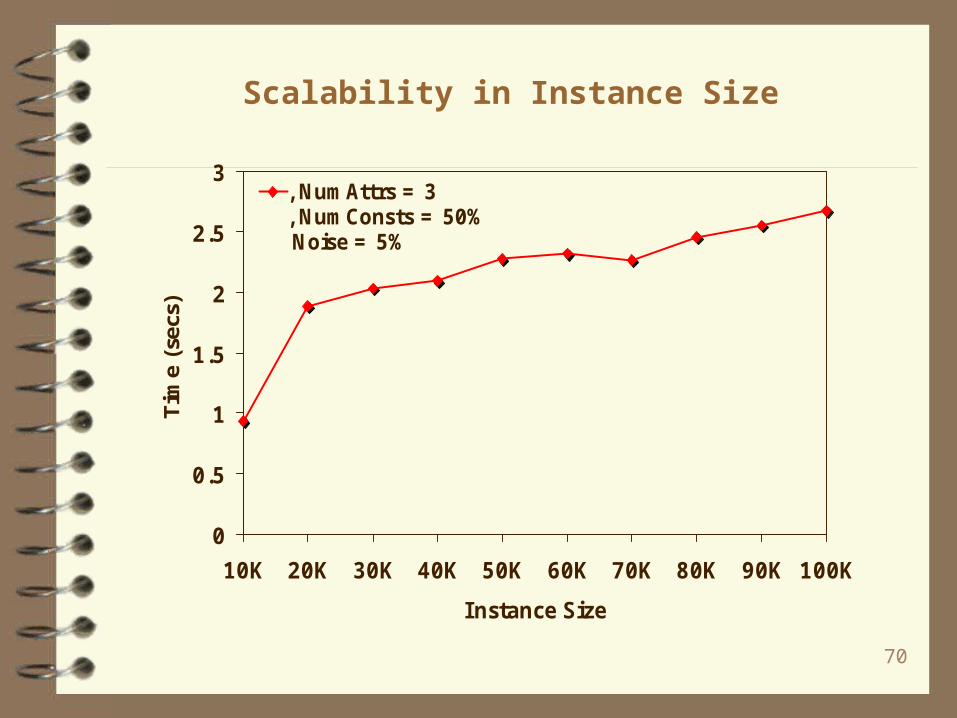
Scalability in Instance Size
0
0.5
1
1.5
2
2.5
3
10K 20K 30K 40K 50K 60K 70K 80K 90K 100K
Instance Size
Tim
e (s
ecs)
, NumAttrs =3, NumConsts =50% Noise =5%
71
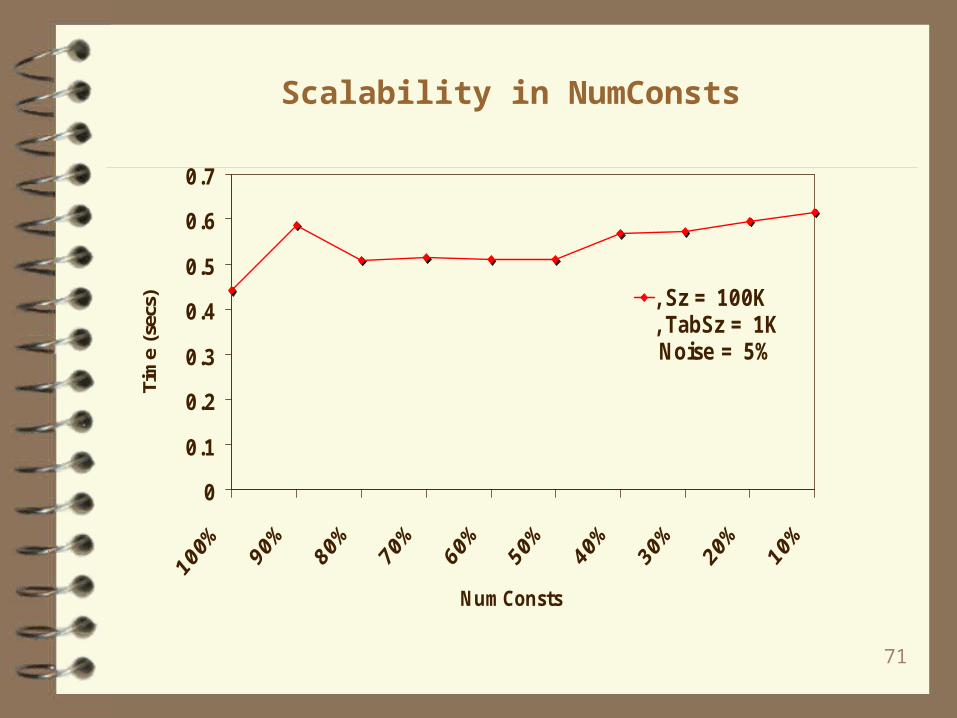
Scalability in NumConsts
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
NumConsts
Tim
e (s
ecs) , Sz =100K
, TabSz =1K Noise =5%
72
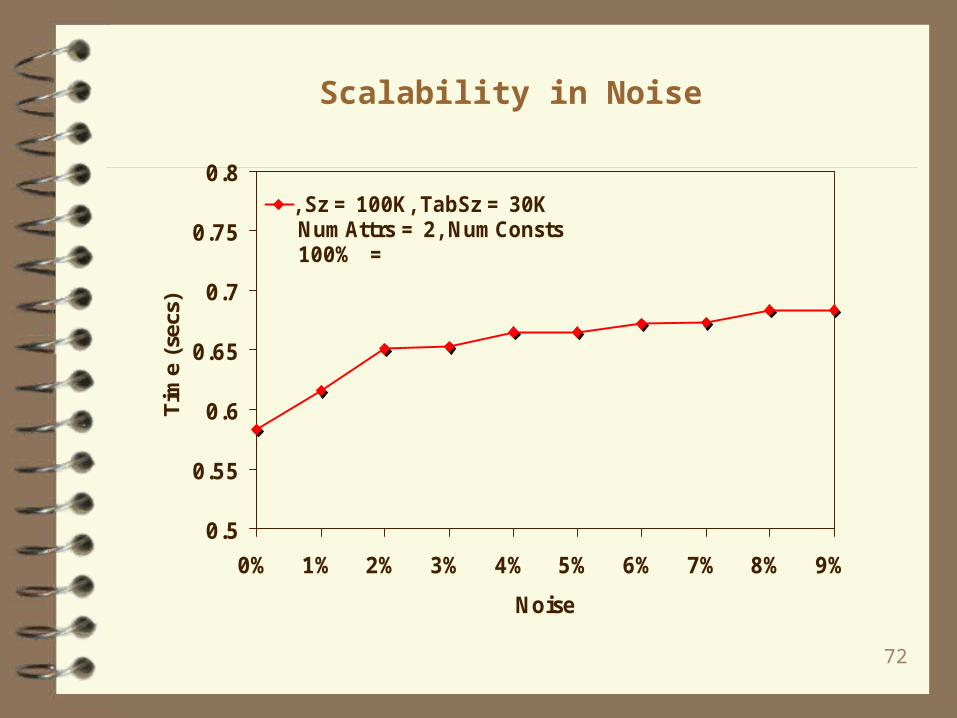
Scalability in Noise
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0% 1% 2% 3% 4% 5% 6% 7% 8% 9%
Noise
Tim
e (s
ecs)
, Sz =100K , TabSz =30K NumAttrs =2 ,NumConsts100% =
73
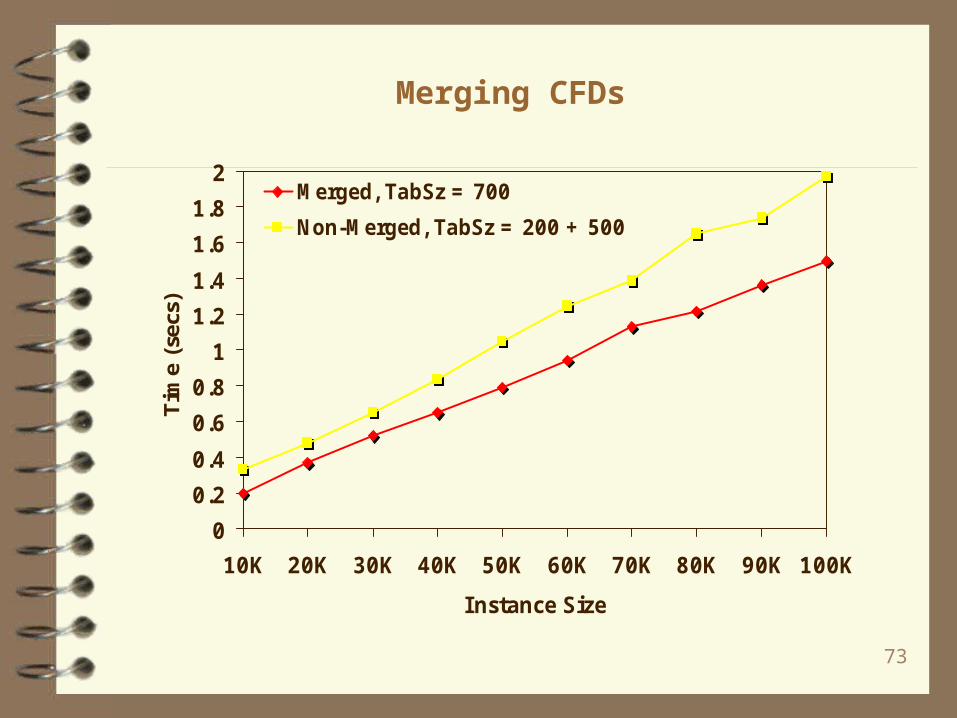
Merging CFDs
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
10K 20K 30K 40K 50K 60K 70K 80K 90K 100K
Instance Size
Tim
e (s
ecs)
Merged, TabSz = 700
Non-Merged, TabSz = 200 + 500
74
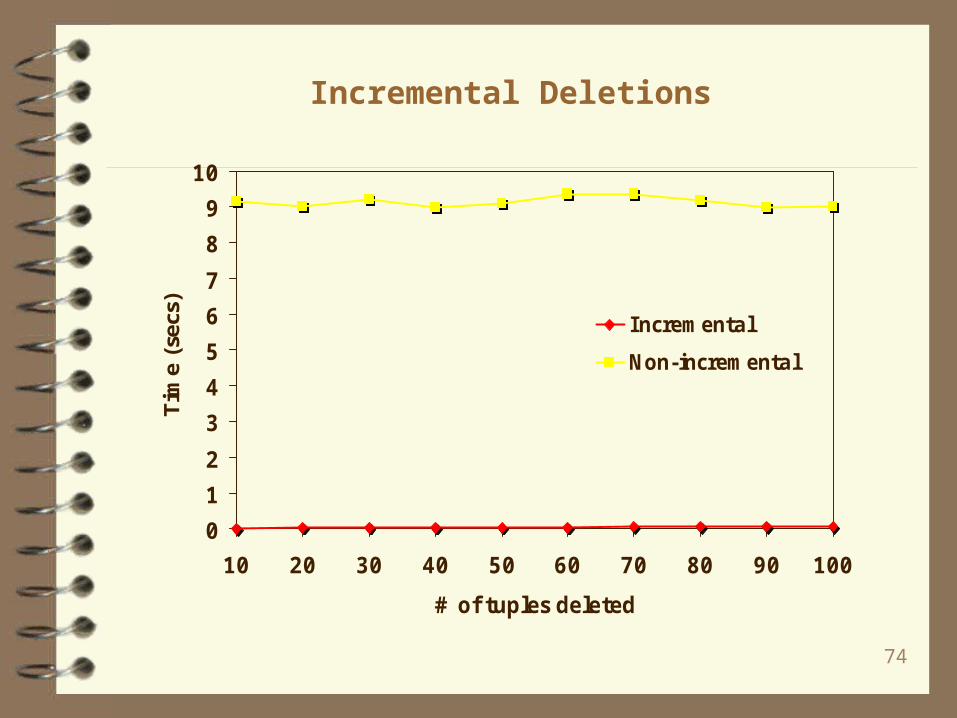
Incremental Deletions
0
1
2
3
4
5
6
7
8
9
10
10 20 30 40 50 60 70 80 90 100
# of tuples deleted
Tim
e (s
ecs)
Incremental
Non-incremental
75
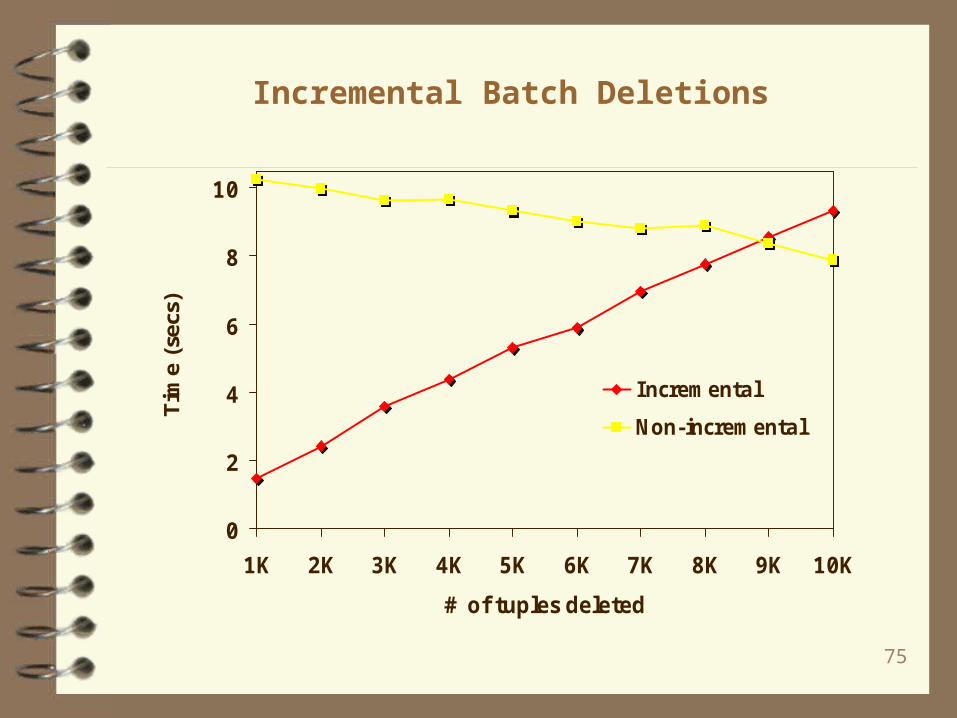
Incremental Batch Deletions
0
2
4
6
8
10
1K 2K 3K 4K 5K 6K 7K 8K 9K 10K
# of tuples deleted
Tim
e (s
ecs)
Incremental
Non-incremental
76
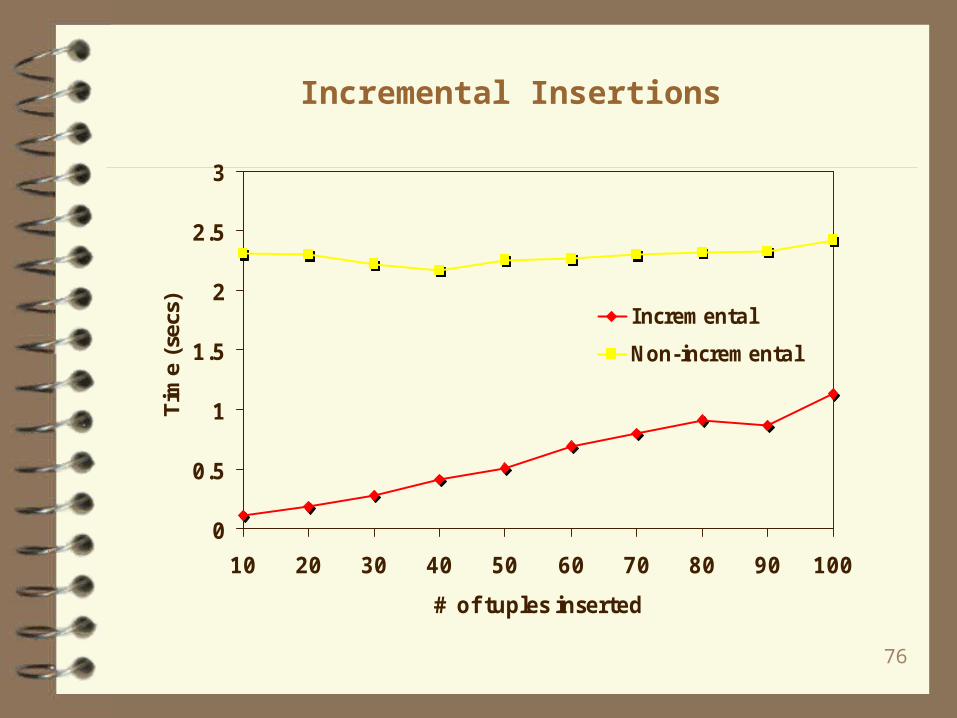
Incremental Insertions
0
0.5
1
1.5
2
2.5
3
10 20 30 40 50 60 70 80 90 100
# of tuples inserted
Tim
e (s
ecs) Incremental
Non-incremental
77
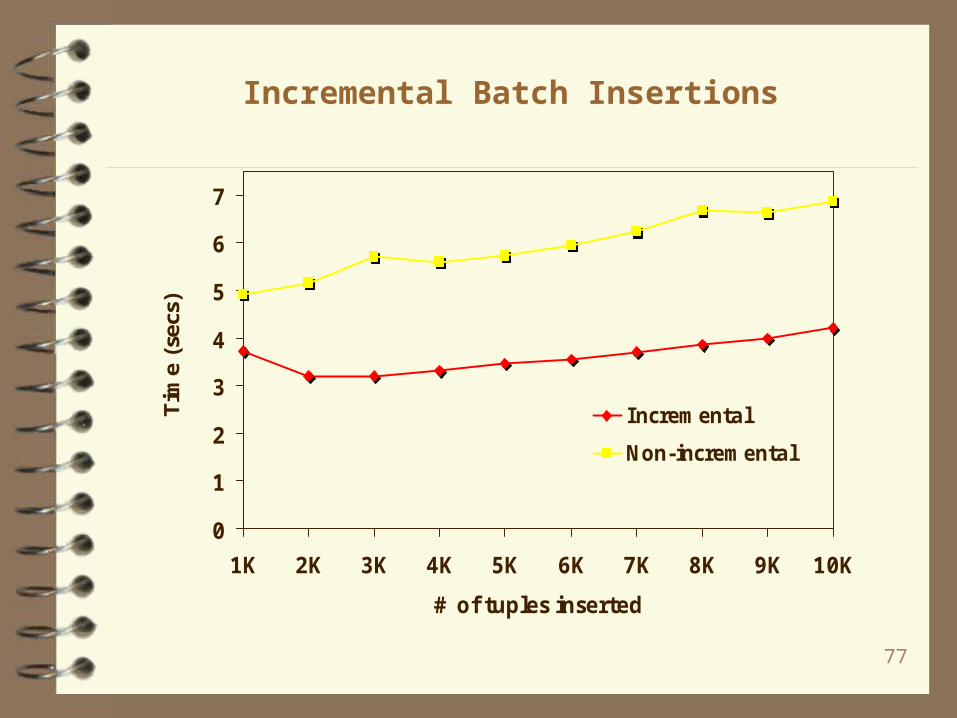
Incremental Batch Insertions
0
1
2
3
4
5
6
7
1K 2K 3K 4K 5K 6K 7K 8K 9K 10K
# of tuples inserted
Tim
e (s
ecs)
Incremental
Non-incremental

78
Checking the satisfiability of CFDs
Input: a set of CFDs
MAXSC: find a maximum subset of that is consistent
Complexity: the MAXSC problem for CFDs is NP-complete
Theorem: there is an -approximation algorithm for MAXSC there exist constant such that for the subset m found by the
algorithm has a bound: card(m) > card(OPT())
Proof idea: approximation factor preserving reduction to
MAXGSAT
Open questions: effective heuristic algorithms for checking the satisfiability of CFDs + CINDs (undecidable) for determining implication of CFDs, CINDs, and CFDs + CINDs for finding minimum cover of CFDs, CINDs, and CFDs + CINDs

79
Automated methods for finding a repair
Input: a relational database DB, and a set of CFDs
Output: a repair DB’ of DB such that cost(DB’, DB) is minimal repair: DB’ satisfies “good”: cost(DB’, DB)
– DB’ is “close” to the original data in DB– Minimizing changes to “accurate” attributes
Complexity: Finding an optimal repair is NP-complete (data complexity) for traditional FDs, for a fixed
set of FDs (or INDs) and fixed schema PSPACE-complete for CFDs + CINDs (combined complexity)
Open questions: effective heuristic for repairing databases based
on CFDs, CINDs, and CFDs + CINDs

80
Incremental repair
Input: a clean database DB, changes DB to DB, and a set of
CFDs
Output: a repair DB’ of DB + DB
Complexity. The local data cleaning problem is NP-hard, even if
DB consists of a single tuple.
Open questions: find effective heuristic algorithms for incrementally
repairing databases based on CFDs CINDs CFDs + CINDs

81
Discovering CFDs and CINDs
Input: Sample databases of a schema R
Output: CFDs and CINDs that hold on all (or most) database
instances of R
Difficulty. A naïve approach may find non-representative CFDs and
CINDs as large as the sample data
Open questions: find effective method for discovering CFDs CINDs CFDs + CINDs

82
Summary
Conditional functional dependencies– for data cleaning rather than schema design – complexity bounds of satisfiability and implication analyses– a sound and complete inference system
Conditional inclusion dependencies– for data cleaning and schema matching in practice– complexity bounds of satisfiability and implication analyses– a sound and complete inference system
Complexity bounds for CFDs and CINDs taken together SQL techniques for automatic detection of CFD violations
– a pair of SQL queries for validating multiple CFDs– incremental techniques for validating CFDs
A practical method for data cleaning and schema matching

83
References
Conditional Functional Dependencies for Data Cleaning
The 23rd International Conference on Database Engineering
(ICDE), 2007.Philip Bohannon, Wenfei Fan, Floris Geerts, Xibei Jia, Anastasios
Kementsietsidis
Extending Dependencies with Conditions Loreto Bravo, Wenfei Fan, Shuai Ma
Improving Data Quality: Consistency and Accuracy Gao Cong, Wenfei Fan, Floris Geerts, Xibei Jia, Shuai Ma
Conditional Functional Dependencies for Capturing Data
Inconsistencies Wenfei Fan, Floris Geerts, Xibei Jia, Anastasios Kementsietsidis





























