Embed Size (px)
Citation preview

1
Compiler ConstructionParsing Part I
제 4 주 Parsing

2
What We Did Last Time
The cycle in lexical analysis RE → NFA NFA → DFA DFA → Minimal DFA DFA → RE
Engineering issues in building scanners

3
Today’s Goals
Parsing Part I Context-free grammars Sentence derivations Grammar ambiguity Left recursion problem with top-down parsing
and how to fix it Predictive top-down parsing
LL(1) condition Recursive descent parsing
4
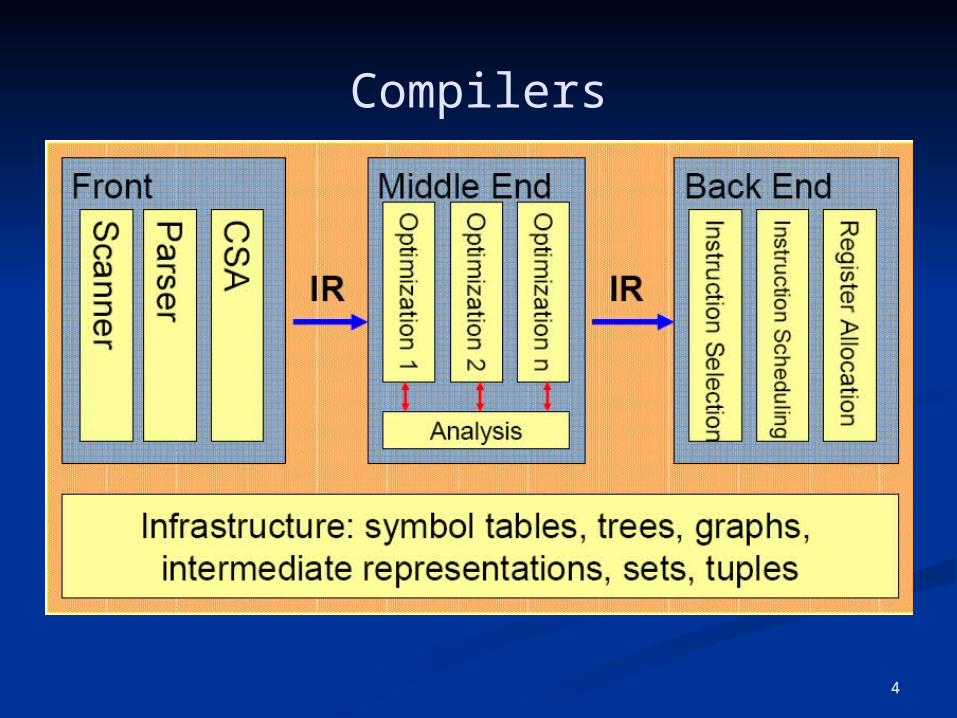
Compilers
5
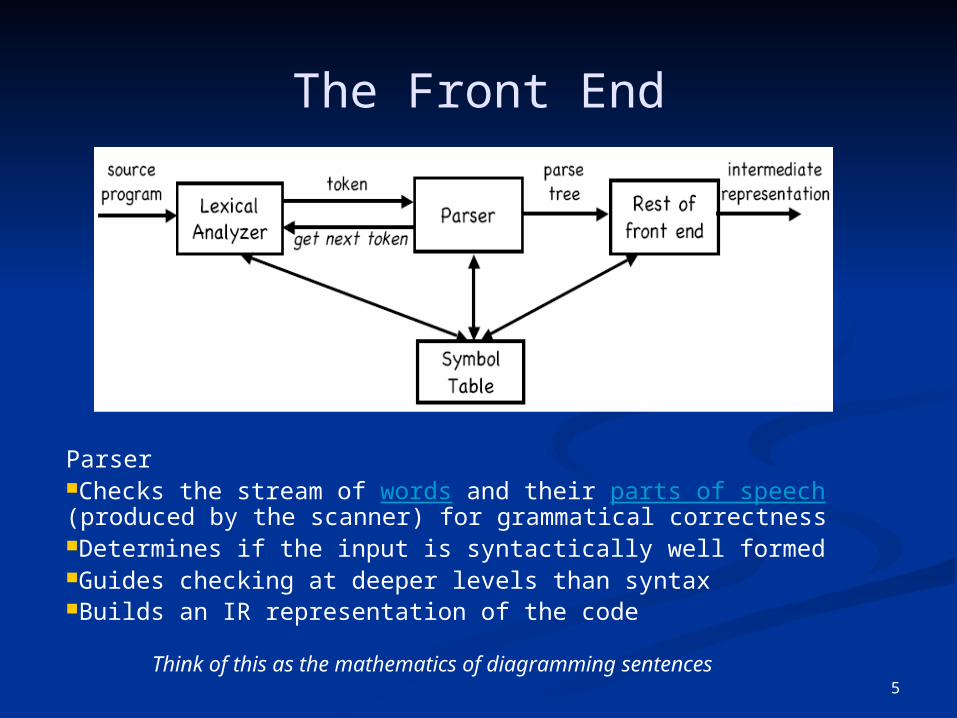
The Front End
ParserChecks the stream of words and their parts of speech(produced by the scanner) for grammatical correctnessDetermines if the input is syntactically well formedGuides checking at deeper levels than syntaxBuilds an IR representation of the code
Think of this as the mathematics of diagramming sentences

6
The Study of Parsing (syntax analysis)
The process of discovering a derivation for some sentence Need a mathematical model of syntax — a grammar G Need an algorithm for testing membership in L(G) Need to keep in mind that our goal is building parsers, not studying the math
ematics of arbitrary languages
Roadmap1. Context-free grammars and derivations2. Top-down parsing
Hand-coded recursive descent parsers LL(1) parsers
LL(1) parsed top-down, left to right scan, leftmost derivation, 1 symbol lookahead3. Bottom-up parsing
Operator precedence parsing LR(1) parsers
LR(1) parsed bottom-up, left to right scan, reverse rightmost derivation, 1 symbol lookahead

7
Syntax analysis
Every PL has rules for syntactic structure.
The rules are normally specified by a CFG (Context-Free Grammar) or BNF (Backus-Naur Form)
Usually, we can automatically construct an efficient parser from a CFG or BNF.
Grammars also allow SYNTAX-DIRECTED TRANSLATION.

8
Specifying Syntax with a Grammar
Context-free syntax is specified with a context-free grammarSheepNoise → SheepNoise baa
| baa
This CFG defines the set of noises sheep normally make
It is written in a variant of Backus–Naur form
Formally, a grammar is a four tuple, G = (S,N,T,P) S is the start symbol (set of strings in L(G)) N is a set of non-terminal symbols (syntactic variables) T is a set of terminal symbols (words) P is a set of productions or rewrite rules (P :N →(N ∪T)+)
9
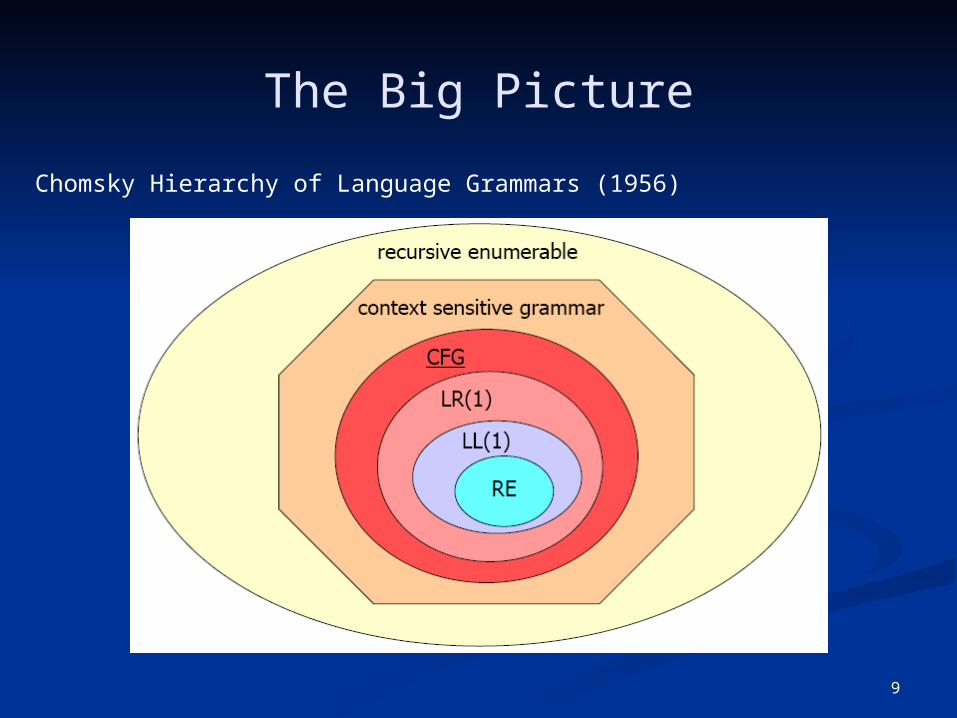
The Big Picture
Chomsky Hierarchy of Language Grammars (1956)

10
Deriving Syntax
We can use the SheepNoise grammar to create sentences use the productions as rewriting rules
While it is cute, this example quickly runs out of intellectual steam ...
11
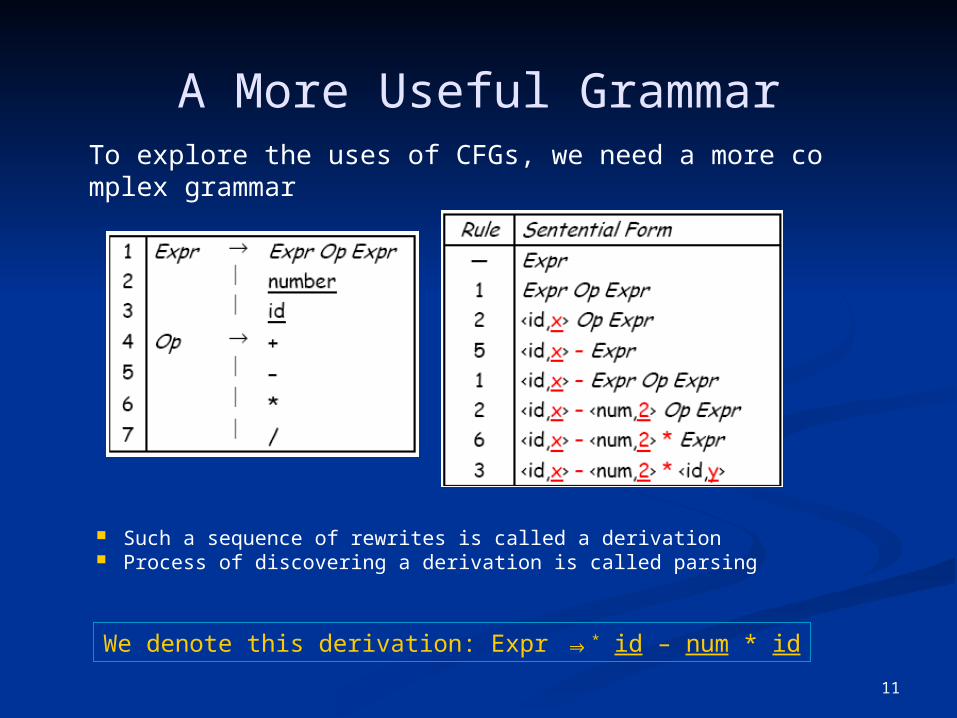
A More Useful Grammar
Such a sequence of rewrites is called a derivation Process of discovering a derivation is called parsing
To explore the uses of CFGs, we need a more complex grammar
We denote this derivation: Expr ⇒* id – num * id

12
Derivations
At each step, we choose a non-terminal to replace Different choices can lead to different derivations
Two derivations are of interest Leftmost derivation — replace leftmost NT at each step Rightmost derivation — replace rightmost NT at each step
These are the two systematic derivations(We don’t care about randomly-ordered derivations!)
The example on the preceding slide was a leftmost derivation Of course, there is also a rightmost derivation Interestingly, it turns out to be different

13
The Two Derivations for x – 2 * y
In both cases, Expr ⇒* id – num * id The two derivations produce different parse trees
Actually, each of two different derivations produces both parse trees as the grammar itself is ambiguous
The parse trees imply different evaluation orders!
Leftmost derivation Rightmost derivation

14
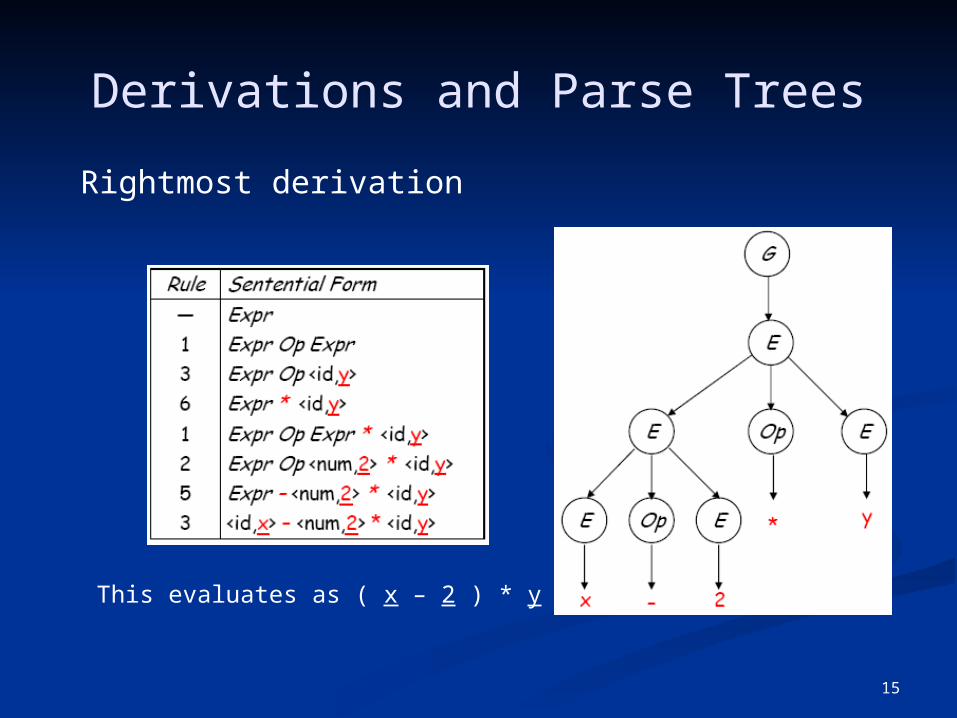
Derivations and Parse Trees
Leftmost derivation
This evaluates as x – ( 2 * y )
15
Derivations and Parse Trees
Rightmost derivation
This evaluates as ( x – 2 ) * y

16
Ambiguity Ambiguity
Definitions
If a grammar has more than one leftmost derivation for a single sentential form, the grammar is ambiguous
If a grammar has more than one rightmost derivation for a single sentential form, the grammar is ambiguous
The leftmost and rightmost derivations for a sentential form may differ, even in an unambiguous grammar
Examples Examples Associativity and precedenceAssociativity and precedence Dangling elseDangling else
17
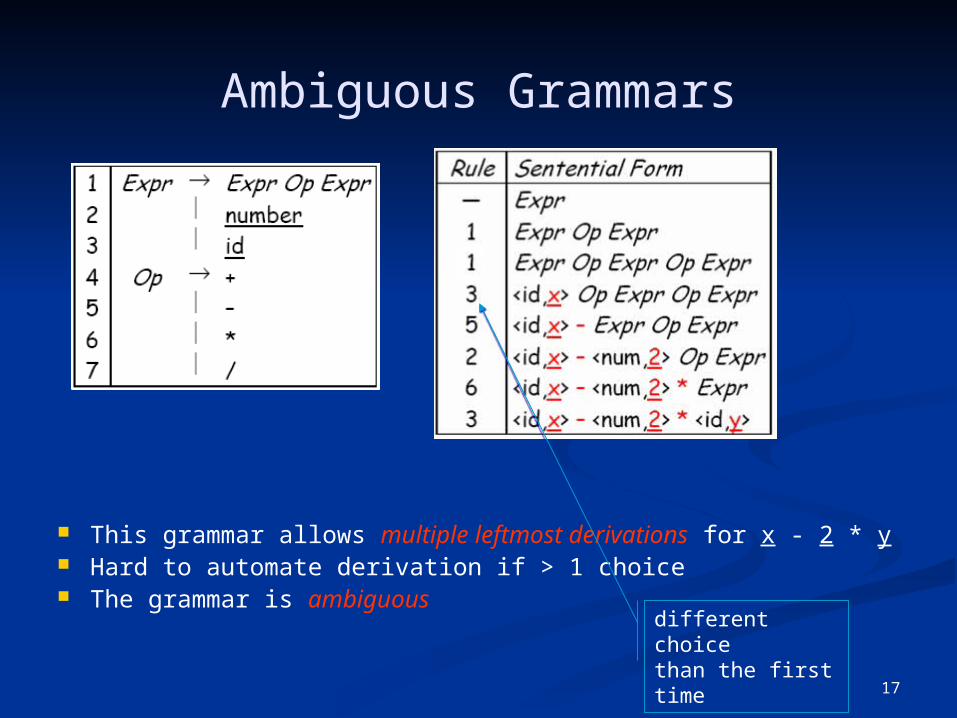
Ambiguous Grammars
This grammar allows multiple leftmost derivations for x - 2 * y Hard to automate derivation if > 1 choice The grammar is ambiguous
different choicethan the first time
18
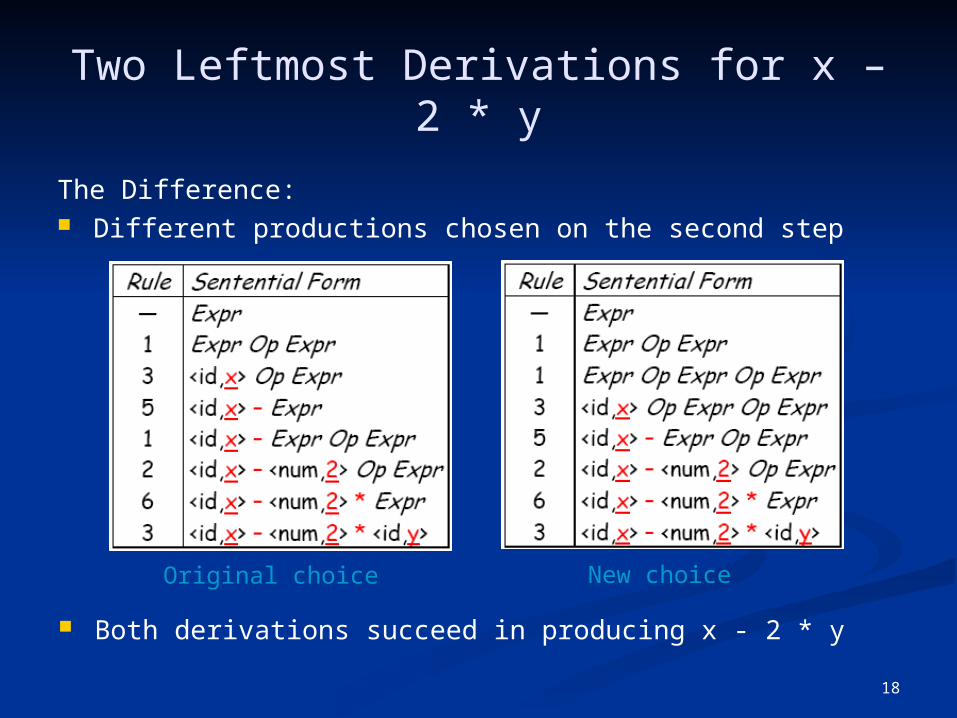
Two Leftmost Derivations for x – 2 * y
The Difference: Different productions chosen on the second step
Both derivations succeed in producing x - 2 * y
Original choice New choice

19
Derivations and Precedence/Association
These two derivations point out a problem with the grammar:It has no notion of precedence, or implied order of evaluation
To add precedence Create a non-terminal for each level of precedence Isolate the corresponding part of the grammar Force the parser to recognize high precedence subexpressions first
For algebraic expressions Multiplication and division, first (level one) Subtraction and addition, next (level two)
To add association On same precedenceOn same precedence Left-associative : The next-level (higher) nonterminal places at the last of a productionLeft-associative : The next-level (higher) nonterminal places at the last of a production

20
Derivations and PrecedenceAdding the standard algebraic precedence produces:

21
Derivations and Precedence
This produces x – ( 2 * y ), along with an appropriate parse tree.Both the leftmost and rightmost derivations give the same expression,because the grammar directly encodes the desired precedence.

22
Ambiguous Grammars by dangling else
Classic example — the if-then-else problem Stmt → if Expr then Stmt | if Expr then Stmt else Stmt | … other stmts …This ambiguity is entirely grammatical in nature
23
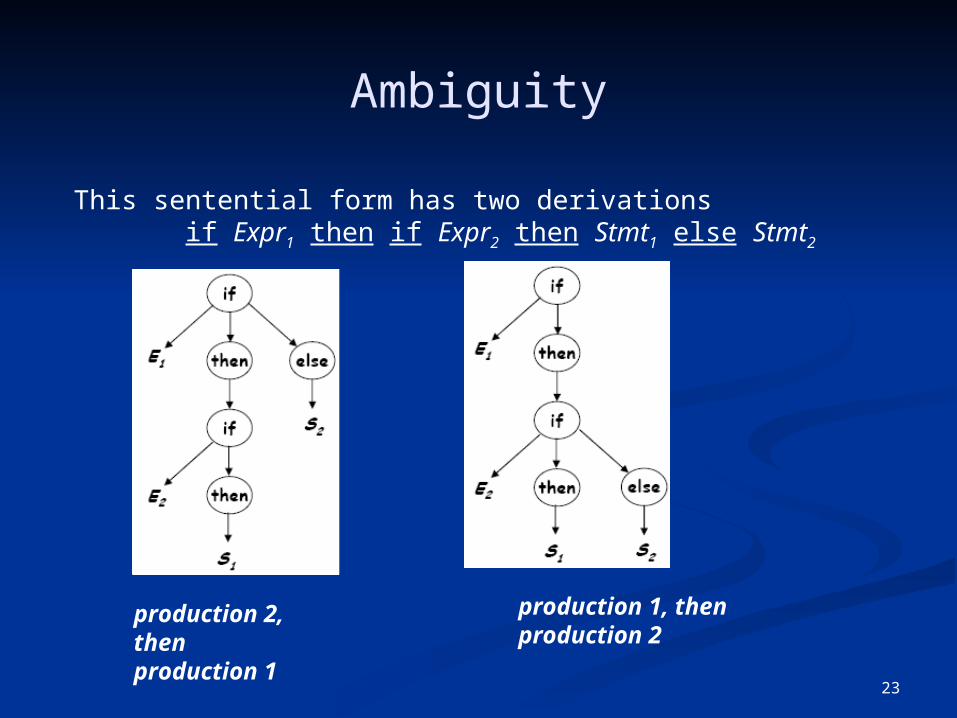
Ambiguity
This sentential form has two derivations if Expr1 then if Expr2 then Stmt1 else Stmt2
production 2, thenproduction 1
production 1, thenproduction 2

24
Ambiguity
Removing the ambiguity Must rewrite the grammar to avoid generating the problem Match each else to innermost unmatched if (common sense rule)
Intuition: a NoElse always has no else on its last cascaded else if statement
With this grammar, the example has only one derivation

25
Ambiguityif Expr1 then if Expr2 then Stmt1 else Stmt2
This binds the else controlling S2 to the inner if

26
Deeper Ambiguity
Ambiguity usually refers to confusion in the CFG
Overloading can create deeper ambiguitya = f(17)
In many Algol-like languages, f could be either a function or a subscripted variable
Disambiguating this one requires context Need values of declarations Really an issue of type, not context-free syntax Requires an extra-grammatical solution (not in CFG) Must handle these with a different mechanism
Step outside grammar rather than use a more complex grammar

27
Ambiguity - The Final Word
Ambiguity arises from two distinct sources Confusion in the context-free syntax (if-then-else) Confusion that requires context to resolve (overloading)Resolving ambiguity To remove context-free ambiguity, rewrite the grammar To handle context-sensitive ambiguity takes cooperation
Knowledge of declarations, types, … Accept a superset of L(G) & check it by other means†
This is a language design problemSometimes, the compiler writer accepts an ambiguous
grammar Parsing techniques that “do the right thing” i.e., always select the same derivation

28
Parsing Techniques
Top-down parsers (LL(1), recursive descent) Start at the root of the parse tree and grow toward leaves Pick a production & try to match the input Bad “pick” ⇒ may need to backtrack Some grammars are backtrack-free (predictive parsing)
Bottom-up parsers (LR(1), operator precedence) Start at the leaves and grow toward root As input is consumed, encode possibilities in an internal
state Start in a state valid for legal first tokens Bottom-up parsers handle a large class of grammars

29
Top-down Parsing
A top-down parser starts with the root of the parse tree The root node is labeled with the goal symbol of thegrammar
Top-down parsing algorithm:Construct the root node of the parse treeRepeat until the fringe of the parse tree matches the input string1. At a node labeled A, select a production with A on its lhs and, for each
symbol on its rhs, construct the appropriate child2. When a terminal symbol is added to the fringe and it doesn’t match the
fringe, backtrack3. Find the next node to be expanded (label ∈ NT)
The key is picking the right production in step 1 That choice should be guided by the input string

30
The Expression GrammarVersion with precedence derived last lecture
And the input x – 2 * y
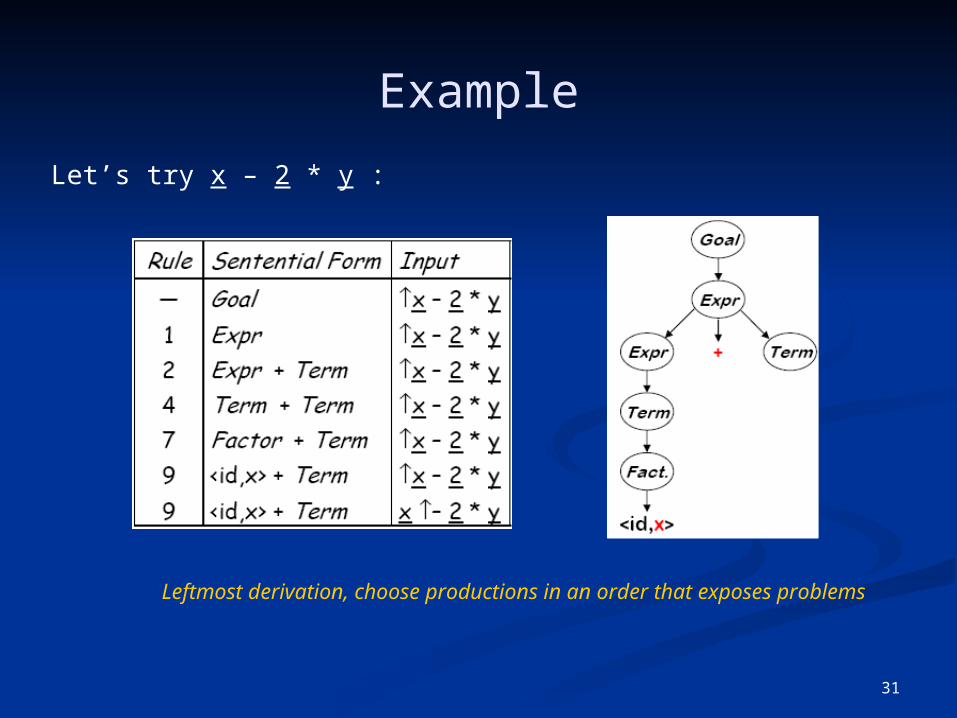
31
Example
Let’s try x – 2 * y :
Leftmost derivation, choose productions in an order that exposes problems

32
Example
Let’s try x – 2 * y :
This worked well, except that “–” doesn’t match “+”The parser must backtrack to here

33
ExampleContinuing with x – 2 * y :
⇒ Now, we need to expand Term - the last NT on the fringe
This time, “–”and “–” matched
We can advance past“–” to look at “2”
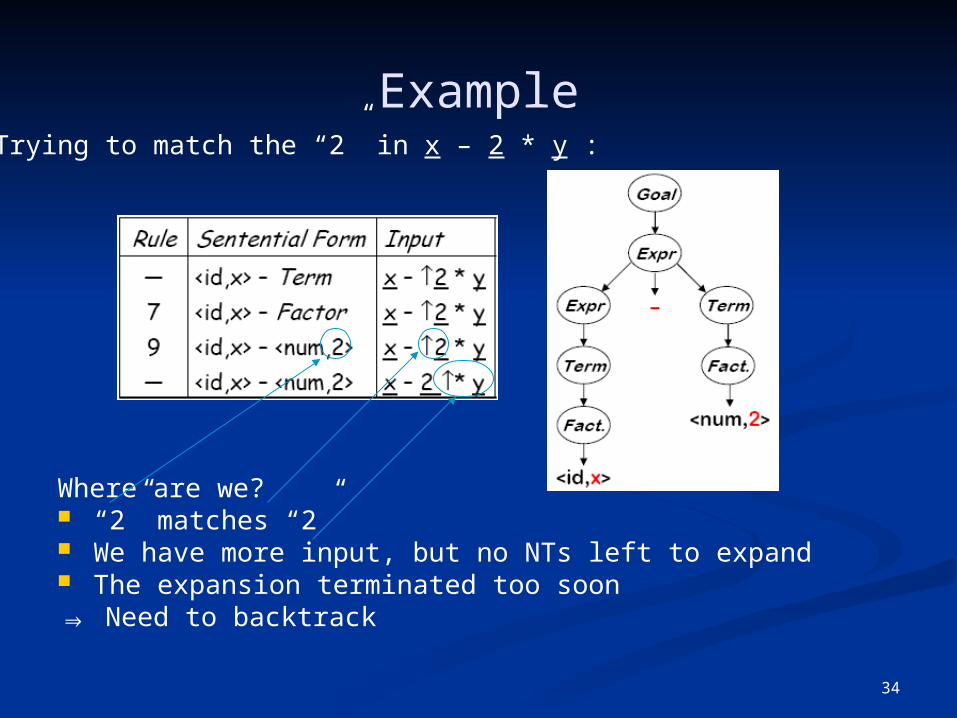
34
Example
Where are we? “2” matches “2” We have more input, but no NTs left to expand The expansion terminated too soon⇒ Need to backtrack
Trying to match the “2” in x – 2 * y :
35
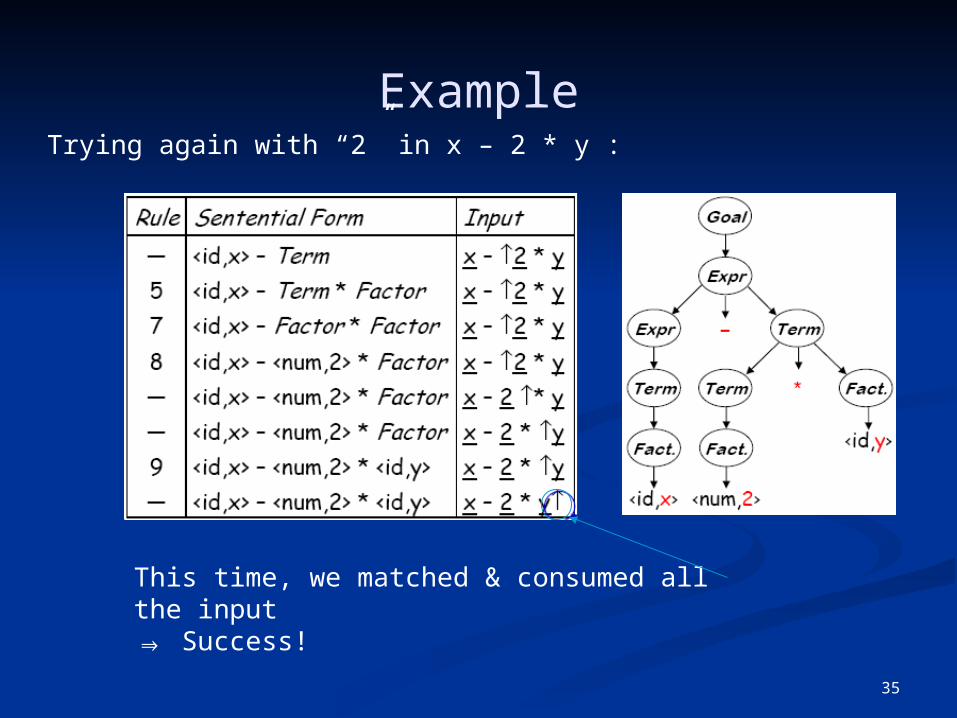
ExampleTrying again with “2” in x – 2 * y :
This time, we matched & consumed all the input⇒ Success!

36
Another Possible Parse
This doesn’t terminate (obviously) Wrong choice of expansion leads to non-termination Non-termination is a bad property for a parser to have Parser must make the right choice
Other choices for expansion are possible

37
Left Recursion
Top-down parsers cannot handle left-recursive grammars
Formally,A grammar is left recursive if ∃ A ∈ NT such that∃ a derivation A ⇒+ Aα, for some string α ∈ (NT ∪ T )+
Our expression grammar is left recursive This can lead to non-termination in a top-down parser For a top-down parser, any recursion must be right recursion We would like to convert the left recursion to right recursion
Non-termination is a bad property in any part of a compiler

38
Eliminating Left Recursion
To remove left recursion, we can transform the grammar
Consider a grammar fragment of the form Fee → Fee α | βwhere neither α nor β start with Fee
We can rewrite this as Fee → β Fie Fie → α Fie | εwhere Fie is a new non-terminal
This accepts the same language, but uses only right recursion

39
Eliminating Left Recursion
The expression grammar contains two cases of left recursion
Applying the transformation yields
These fragments use only right recursionThey retain the original left associativity
Expr → Expr + Term | Expr – Term | Term
Term → Term * Factor | Term / Factor | Factor
Expr → Term Expr′Expr′ | + Term Expr′ | – Term Expr′ | ε
Term → Factor Term′Term′ | * Factor Term′ | / Factor Term′ | ε

40
Eliminating Left RecursionSubstituting them back into the grammar yields
• This grammar is correct, if somewhat non-intuitive.
• It is left associative, as was the original
• A top-down parser will terminate using it.
• A top-down parser may need to backtrack with it.

41
Eliminating Left Recursion
The transformation eliminates immediate left recursionWhat about more general, indirect left recursion ?
The general algorithm: arrange the NTs into some order A1, A2, …, An
for i ← 1 to n for s ← 1 to i – 1 replace each production Ai → Asγ with Ai→ δ1γ |δ2γ|…|δkγ, where As→ δ1|δ2|…|δk are all the current productions for As
eliminate any immediate left recursion on Ai using the direct transformation
This assumes that the initial grammar has no cycles (Ai ⇒+ Ai ), and no epsilon productions
And back
Must start with 1 to ensure that A1 →A1 β is transformed

42
Eliminating Left Recursion
How does this algorithm work?1. Impose arbitrary order on the non-terminals2. Outer loop cycles through NT in order3. Inner loop ensures that a production expanding Ai has no non-termin
al As in its rhs, for s < i4. Last step in outer loop converts any direct recursion on Ai to right rec
ursion using the transformation showed earlier5. New non-terminals are added at the end of the order & have no left r
ecursion
At the start of the ith outer loop iterationFor all k < i, no production that expands Ak contains a non-terminalAs in its rhs, for s < k

43
Example
1. Ai = G 3. Ai = T, As = E
G →EE → T E'E' → + T E'E' → εT → T E' ~ TT → id
2. Ai = E
G →EE → T E'E' → + T E'E' → εT → E ~ TT → id
4. Ai = T
G →EE → T E'E' → + T E'E' → εT → id T'T' →E' ~ T T'T' → ε
Order of symbols: G, E, T
G →EE → E + TE → TT → E ~ TT → id
Go toAlgorith
m

44
Roadmap (Where are We?)
We set out to study parsing Specifying syntax
Context-free grammars Ambiguity
Top-down parsers Algorithm & its problem with left recursion Left-recursion removal
Predictive top-down parsing The LL(1) condition Simple recursive descent parsers

45
Picking the “Right” Production
If it picks the wrong production, a top-down parser may backtrackAlternative is to look ahead in input & use context to pick correctly
How much lookahead is needed? In general, an arbitrarily large amount Use the Cocke-Younger, Kasami algorithm or Earley’s algorithm
Fortunately, Large subclasses of CFGs can be parsed with limited lookahead Most programming language constructs fall in those subclasses
Among the interesting subclasses are LL(1) and LR(1) grammars

46
Predictive Parsing
Basic ideaGiven A → α | β, the parser should be able to choose between α & β
FIRST setsFor some rhs α∈G, define FIRST(α) as the set of tokens that appear as the fir
st symbol in some string that derives from αThat is, x ∈ FIRST(α) iff α ⇒* x γ, for some γ
We will defer the problem of how to compute FIRST sets until we look at the LR(1) table construction algorithm
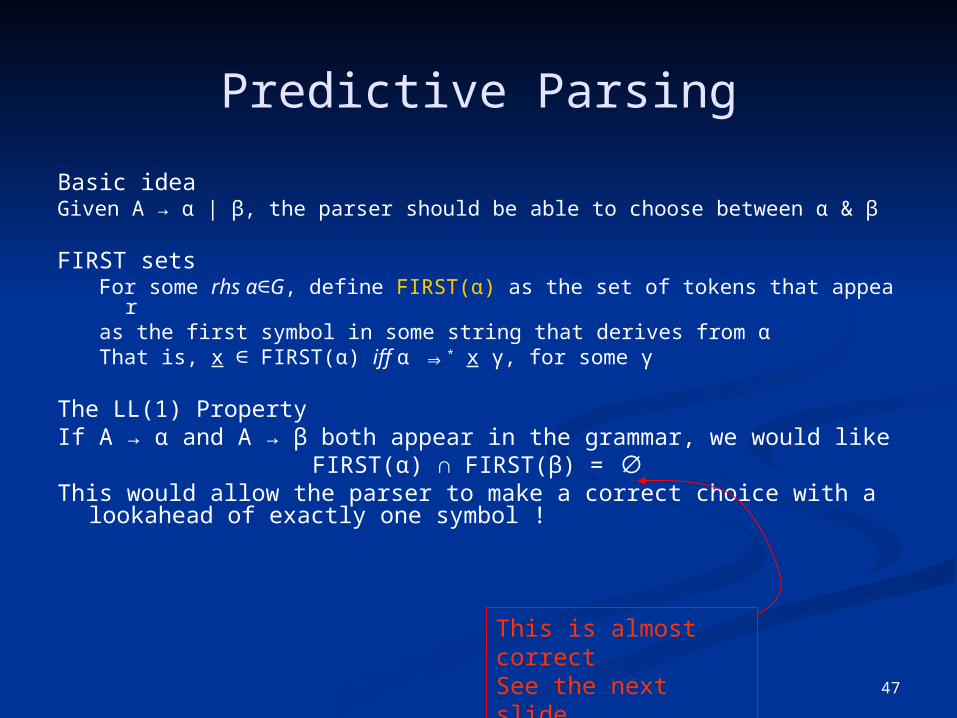
47
Predictive Parsing
Basic ideaGiven A → α | β, the parser should be able to choose between α & β
FIRST setsFor some rhs α∈G, define FIRST(α) as the set of tokens that appearas the first symbol in some string that derives from αThat is, x ∈ FIRST(α) iff α ⇒* x γ, for some γ
The LL(1) PropertyIf A → α and A → β both appear in the grammar, we would like
FIRST(α) ∩ FIRST(β) = ∅This would allow the parser to make a correct choice with a lookahead o
f exactly one symbol !
This is almost correctSee the next slide
48
Predictive Parsing
What about ε-productions?⇒ They complicate the definition of LL(1)
If A → α and A → β and ε ∈ FIRST(α), then we need to ensure that FIRST(β) is disjoint from FOLLOW(α), too
Define FIRST+(α) as FIRST(α) ∪ FOLLOW(α), if ε ∈ FIRST(α) FIRST(α), otherwise
Then, a grammar is LL(1) iff A → α and A → β implies
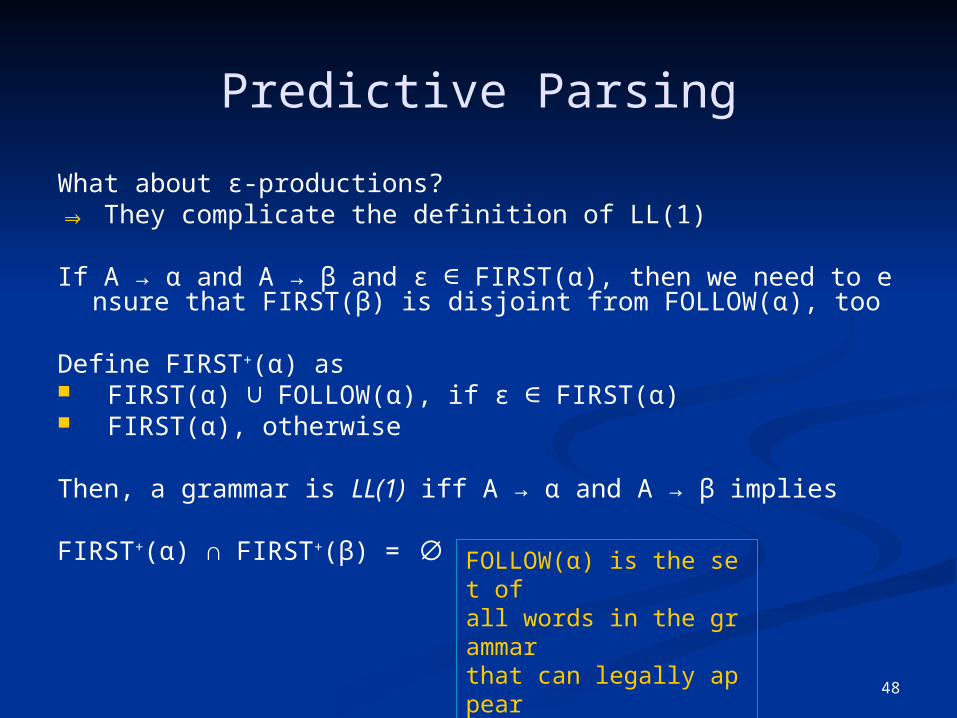
FIRST+(α) ∩ FIRST+(β) = ∅ FOLLOW(α) is the set ofall words in the grammarthat can legally appearimmediately after an α
49
Predictive Parsing
Given a grammar that has the LL(1) property Can write a simple routine to recognize each lhs Code is both simple & fastConsider A → β1 | β2 | β3, with
FIRST+(β1) ∩ FIRST+ (β2) ∩ FIRST+ (β3) = ∅
/* find an A */if (current_word ∈ FIRST(β1)) find a β1 and return trueelse if (current_word ∈ FIRST(β2)) find a β2 and return trueelse if (current_word ∈ FIRST(β3)) find a β3 and return trueelse report an error and return false
Grammars with the LL(1)property are called predictivegrammars because the parsercan “predict” the correctexpansion at each point in theparse.
Parsers that capitalize on theLL(1) property are calledpredictive parsers.
One kind of predictive parseris the recursive descentparser.
Of course, there is more detail to“find a βi” (§ 3.3.4 in EAC)

50
Recursive Descent ParsingRecall the expression grammar, after transformation
This produces a parser with sixmutually recursive routines: • Goal • Expr • EPrime • Term • TPrime • Factor
Each recognizes one NT or T
The term descent refers to thedirection in which the parse treeis built.
51
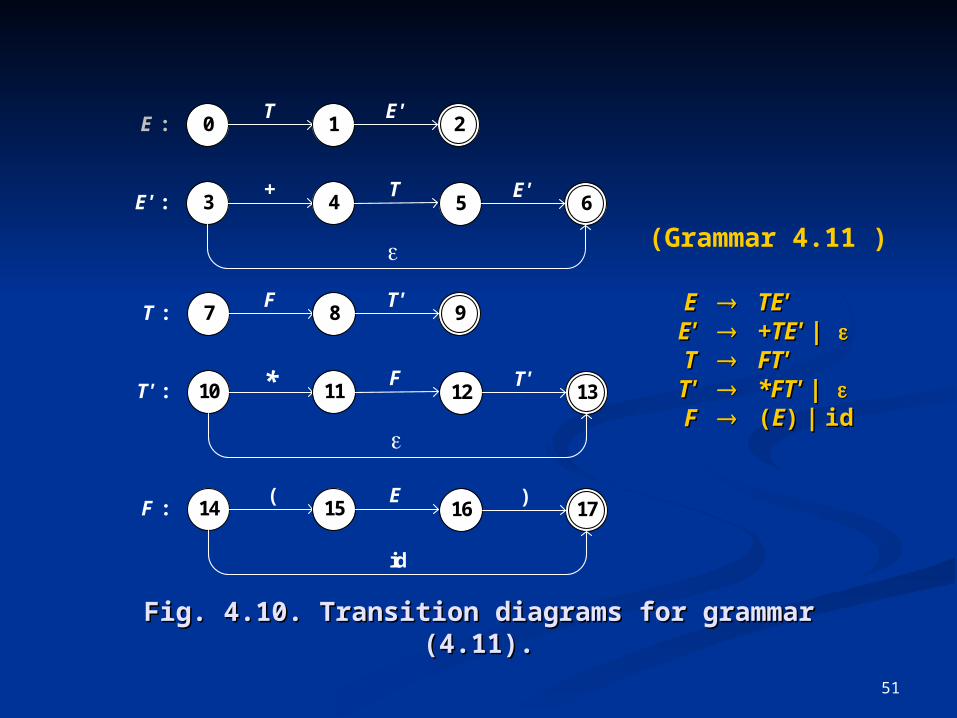
Fig. 4.10. Transition diagrams for grammar (4.11).Fig. 4.10. Transition diagrams for grammar (4.11).
0 102E :T
1E'
3E' :+
4T
1065E'
7 109T :F
8T'
10T' : * 11F
101312T'
14F :(
15E
101716)
id
EEEE''TTTT''FF
TETE''+TE+TE' ' | | FTFT''*FT*FT' ' | | ((EE)) | | idid
(Grammar 4.11 )
52
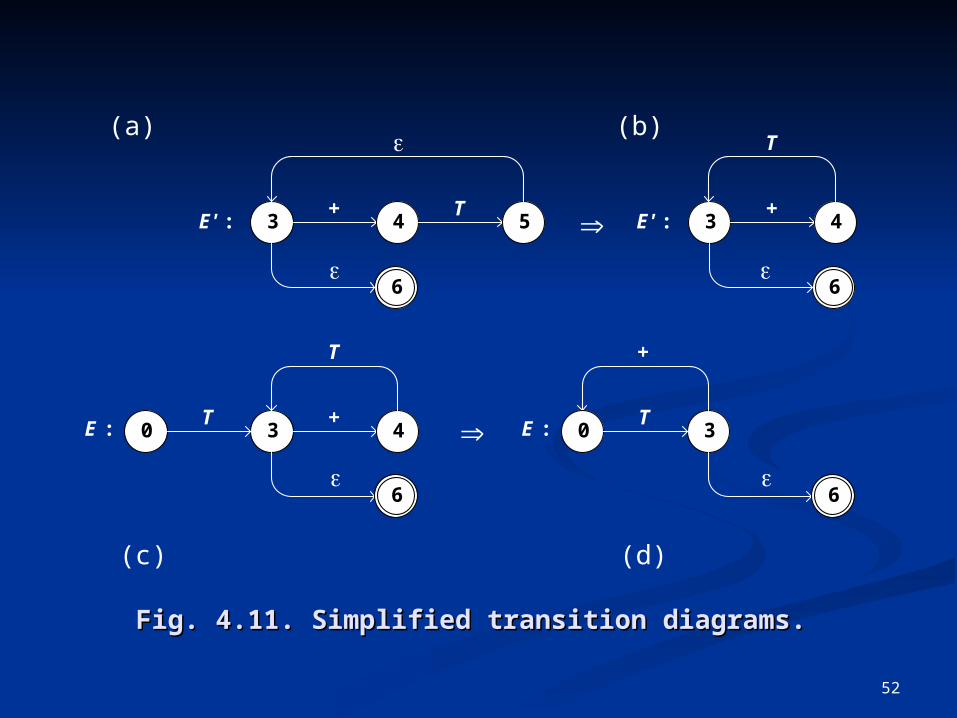
Fig. 4.11. Simplified transition diagrams.Fig. 4.11. Simplified transition diagrams.
3E' :+
4T
5
106
3E' :+
4
T
106
3E :+
4
T
106
0T
3E :
+
106
0T
(a) (b)
(c) (d)
53
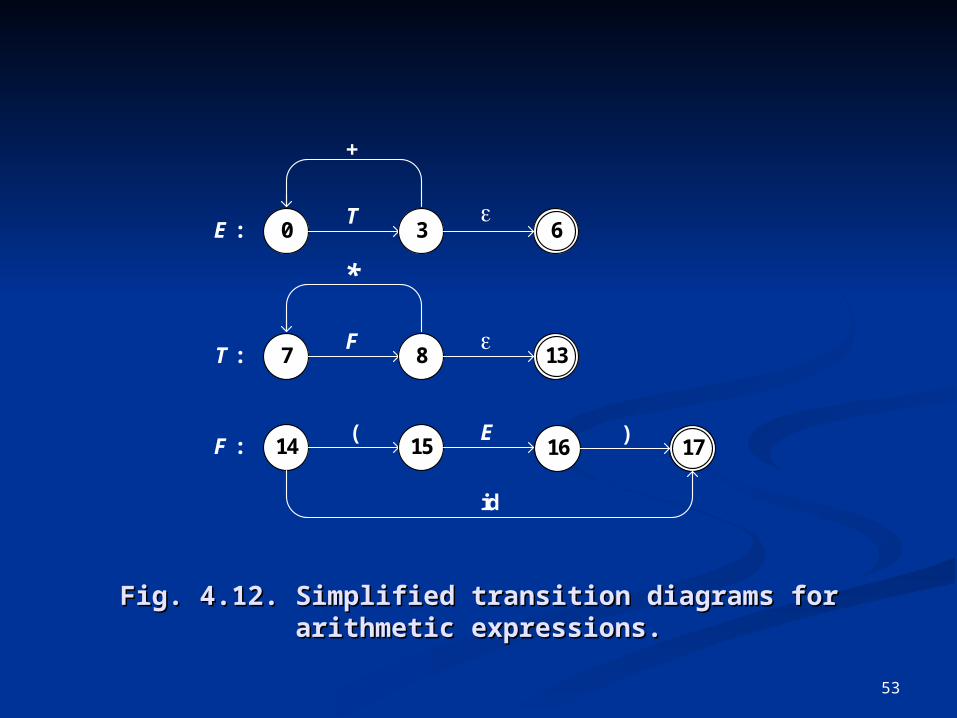
Fig. 4.12. Simplified transition diagrams for Fig. 4.12. Simplified transition diagrams for arithmetic expressions.arithmetic expressions.
*
7 1013T :F
8
14F :(
15E
101716)
id
+
0 106E :T
3

54
Recursive Descent ParsingA couple of routines from the expression parser

55
Recursive Descent Parsing
To build a parse tree: Augment parsing routines to build
nodes Pass nodes between routines usi
ng a stack Node for each symbol on rhs Action is to pop rhs nodes, make
them children of lhs node, and push this subtree
To build an abstract syntax tree Build fewer nodes Put them together in a different or
der
Expr( ) result ←true; if (Term( ) = false) then return false; else if (EPrime( ) = false) then result ←false; else build an Expr node pop EPrime node pop Term node make EPrime & Term children of Expr push Expr node return result;
Success ⇒ build a piece of the parse tree

56
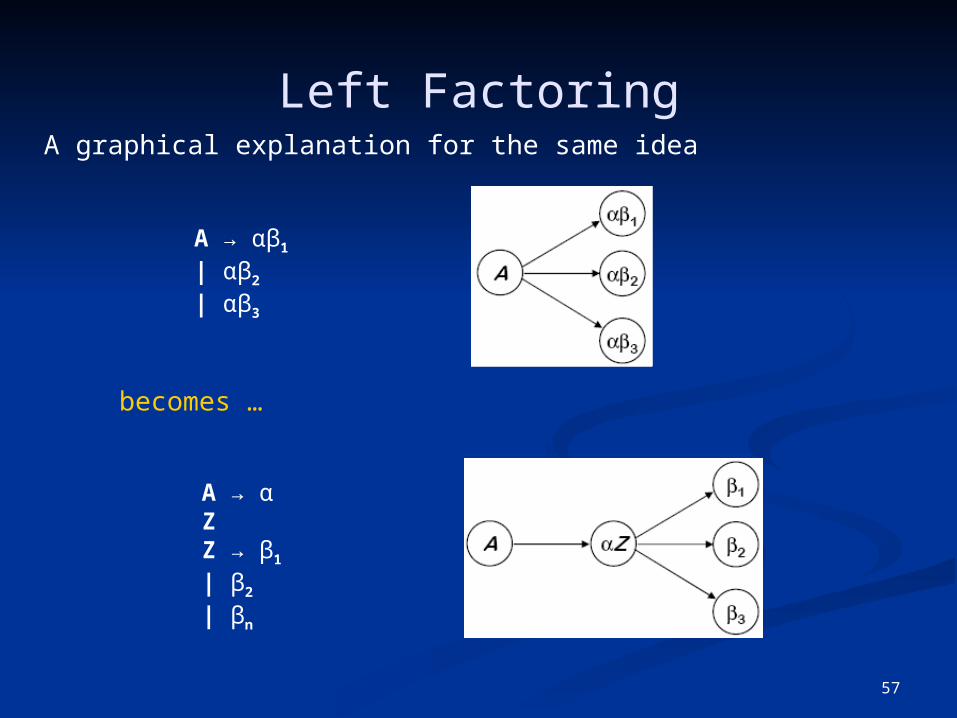
Left Factoring
What if my grammar does not have the LL(1) property?⇒ Sometimes, we can transform the grammar
The Algorithm
∀A ∈ NT, find the longest prefix α that occurs in two or more right-hand sides of A if α ≠ ε then replace all of the A productions, A → αβ1 | αβ2 | … | αβn | γ , with A → αZ | γ Z → β1 | β2 | … | βn
where Z is a new element of NT
Repeat until no common prefixes remain
57
Left FactoringA graphical explanation for the same idea
becomes …
A → αβ1
| αβ2
| αβ3
A → α ZZ → β1
| β2
| βn

58
Left Factoring: An ExampleConsider the following fragment of the expression grammar
After left factoring, it becomes
Factor → Identifier | Identifier [ ExprList ] | Identifier ( ExprList )
Factor → Identifier ArgumentsArguments → [ ExprList ] | ( ExprList ) | ε
FIRST(rhs1) = { Identifier }FIRST(rhs2) = { Identifier }FIRST(rhs3) = { Identifier }
FIRST(rhs1) = { Identifier }FIRST(rhs2) = { [ }FIRST(rhs3) = { ( }FIRST(rhs4) = FOLLOW(Factor)⇒ It has the LL(1) property
This form has the same syntax, with the LL(1) property
59
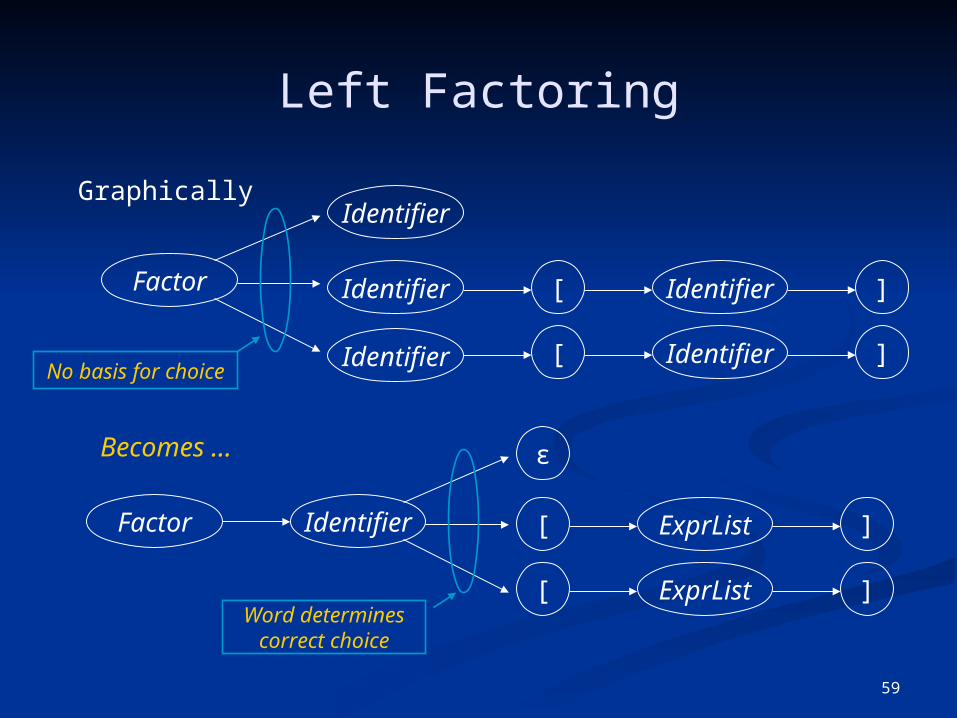
Left Factoring
Factor
ε
[ ExprList ]
[ ExprList ]Word determines
correct choice
Identifier
Becomes …
Factor Identifier
Identifier
Identifier
[ Identifier ]
[ Identifier ]No basis for choice
Graphically

60
Recursive Descent (Summary)
1. Build FIRST (and FOLLOW) sets2. Massage grammar to have LL(1) condition
a. Remove left recursionb. Left factor it
3. Define a procedure for each non-terminala. Implement a case for each right-hand sideb. Call procedures as needed for non-terminals
4. Add extra code, as neededa. Perform context-sensitive checkingb. Build an IR to record the code
Can we automate this process?

61
Summary
Parsing Part I Introduction to parsing
grammar, derivation, ambiguity, left recursion Predictive top-down parsing
LL(1) condition Recursive descent parsing
62
Next Class
Table-driven LL(1) parsing Bottom-up parsing





























