Embed Size (px)
Citation preview

1
Code Optimization

2
Outline
• Machine-Independent Optimization– Code motion– Memory optimization
• Suggested reading
– 5.2 ~ 5.6

3
Motivation
• Constant factors matter too!
– easily see 10:1 performance range depending on
how code is written
– must optimize at multiple levels
• algorithm, data representations, procedures, and loops

4
Motivation
• Must understand system to optimize
performance
– how programs are compiled and executed
– how to measure program performance and
identify bottlenecks
– how to improve performance without destroying
code modularity and generality

5
5.2 Expressing Program Performance

6
Time Scales P382
• Absolute Time
– Typically use nanoseconds
• 10–9 seconds
– Time scale of computer instructions

7
Time Scales
• Clock Cycles– Most computers controlled by high frequency
clock signal
– Typical Range• 100 MHz
– 108 cycles per second
– Clock period = 10ns
• 2 GHz
– 2 X 109 cycles per second
– Clock period = 0.5ns

8
CPE P383
1 void vsum1(int n)
2 {
3 int i;
4
5 for (i = 0; i < n; i++)
6 c[i] = a[i] + b[i];
7 }
8

9
CPE P383
9 /* Sum vector of n elements (n must be even) */10 void vsum2(int n)11 {12 int i;1314 for (i = 0; i < n; i+=2) {15 /* Compute two elements per iteration */16 c[i] = a[i] + b[i];17 c[i+1] = a[i+1] + b[i+1];18 }19 }

10
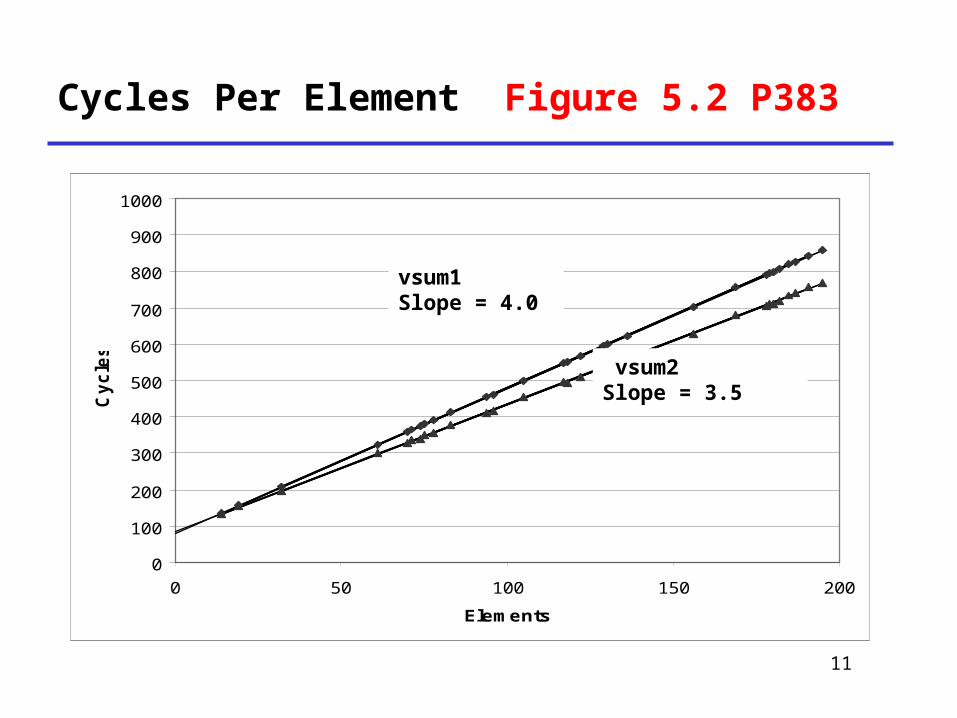
Cycles Per Element
• Convenient way to express performance of
program that operators on vectors or lists
• Length = n
• T = CPE*n + Overhead
11
Cycles Per Element Figure 5.2 P383
0
100
200
300
400
500
600
700
800
900
1000
0 50 100 150 200
Elements
Cy
cle
s
vsum1Slope = 4.0
vsum2Slope = 3.5

12
5.3 Program Example5.4 Eliminating Loop Inefficiencies5.5 Reducing Procedure Calls5.6 Eliminating Unneeded Memory References

13
5.3 Program Example
14
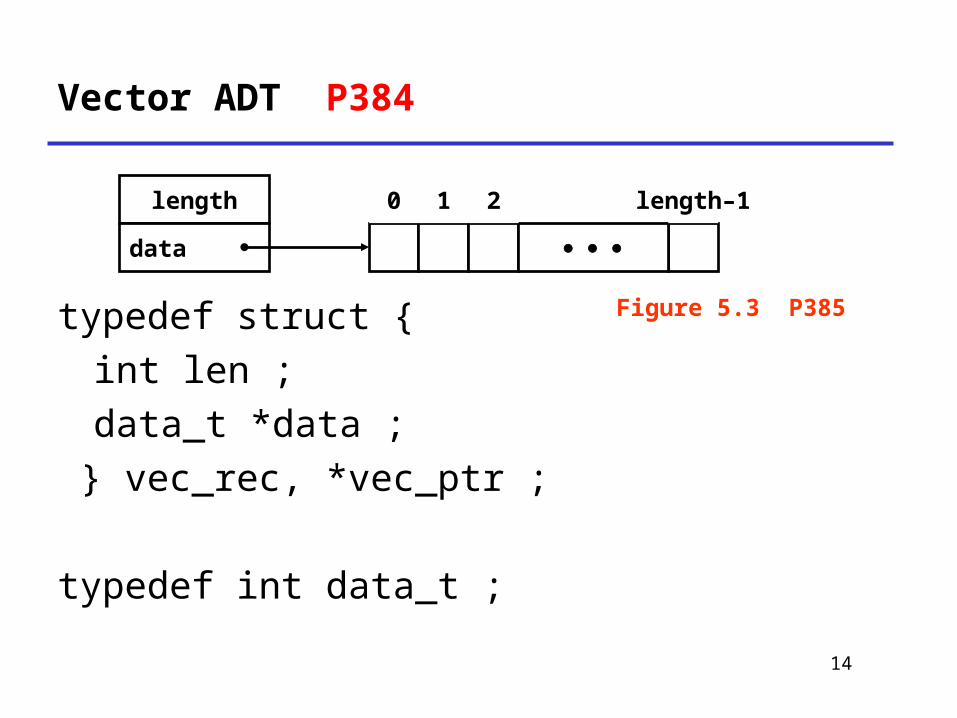
Vector ADT P384
typedef struct { int len ;
data_t *data ; } vec_rec, *vec_ptr ; typedef int data_t ;
length
data
0 1 2 length–1
Figure 5.3 P385

15
Procedures P386
• vec_ptr new_vec(int len)
– Create vector of specified length
• data_t *get_vec_start(vec_ptr v)
– Return pointer to start of vector data
P392
P386

16
Procedures
• int get_vec_element(vec_ptr v, int index, int
*dest)
– Retrieve vector element, store at *dest
– Return 0 if out of bounds, 1 if successful
• Similar to array implementations in Pascal,
Java
– E.g., always do bounds checking
P386

17
Vector ADT
vec_ptr new_vec(int len)
{
/* allocate header structure */
vec_ptr result = (vec_ptr) malloc(sizeof(vec_rec)) ;
if ( !result )
return NULL ;

18
Vector ADT
/* allocate array */if ( len > 0 ) {
data_t *data = (data_t *)calloc(len, sizeof(data_t)) ;
if ( !data ) { free( (void *)result ) ; return NULL ; /* couldn’t allocte stroage
*/}result->data = data
} else result->data = NULL
return result ;}

19
Vector ADT
/** Retrieve vector element and store at dest.* Return 0 (out of bounds) or 1 (successful)*/ int get_vec_element(vec_ptr v, int index, data_t *dest)
{ if ( index < 0 || index >= v->len)
return 0 ;*dest = v->data[index] ;return 1;
}

20
Vector ADT
/* Return length of vector */ int vec_length(vec_ptr) {return v->len ;
}
/* Return pointer to start of vector data */
data_t *get_vec_start(vec_ptr v){return v->data ;
}
P392

21
Optimization Example P385
#ifdef ADD
#define IDENT 0
#define OPER +
#else
#define IDENT 1
#define OPER *
#endif

22
Optimization Example P387
void combine1(vec_ptr v, data_t *dest)
{
int i;
*dest = IDENT;
for (i = 0; i < vec_length(v); i++) {
int val;
get_vec_element(v, i, &val);
*dest = *dest OPER val;
}
}

23
Optimization Example
• Procedure
– Compute sum (product) of all elements of
vector
– Store result at destination location

24
Time Scales P387
void combine1(vec_ptr v, int *dest)
{
int i;
*dest = 0;
for (i = 0; i < vec_length(v); i++) {
int val;
get_vec_element(v, i, &val);
*dest += val;
}
}
5.3 Program Example

25
Time Scales P385
• Procedure– Compute sum of all elements of integer vector
– Store result at destination location
– Vector data structure and operations defined via abstract data type
• Pentium II/III Performance: CPE– 42.06 (Compiled -g) 31.25 (Compiled -O2)

26
Understanding Loop
void combine1-goto(vec_ptr v, int *dest){ int i = 0; int val; *dest = 0; if (i >= vec_length(v)) goto done; loop: get_vec_element(v, i, &val); *dest += val; i++; if (i < vec_length(v)) goto loop done:}
1 iteration

27
Inefficiency
• Procedure vec_length called every iteration
• Even though result always the same
5.4 Eliminating Loop Inefficiencies

28
Code Motion P388
void combine2(vec_ptr v, int *dest){ int i; int length = vec_length(v); *dest = 0; for (i = 0; i < length; i++) { int val; get_vec_element(v, i, &val); *dest += val; }}

29
Code Motion P388
• Optimization
– Move call to vec_length out of inner loop
• Value does not change from one iteration to next
• Code motion
– CPE: 22.61 (Compiled -O2)
• vec_length requires only constant time, but
significant overhead

30
Reduction in Strength P392
void combine3(vec_ptr v, int *dest){ int i; int length = vec_length(v); int *data = get_vec_start(v); *dest = 0; for (i = 0; i < length; i++) { *dest += data[i];}
5.5 Reducing Procedure Calls

31
Reduction in Strength
• Optimization– Avoid procedure call to retrieve each vector
element• Get pointer to start of array before loop
• Within loop just do pointer reference
• Not as clean in terms of data abstraction
– CPE: 6.00 (Compiled -O2)• Procedure calls are expensive!
• Bounds checking is expensive

32
Eliminate Unneeded Memory References P394
void combine4(vec_ptr v, int *dest)
{
int i;
int length = vec_length(v);
int *data = get_vec_start(v);
int sum = 0;
for (i = 0; i < length; i++)
sum += data[i];
*dest = sum;
}
5.6 Eliminating Unneeded Memory References

33
Eliminate Unneeded Memory References
• Optimization
– Don’t need to store in destination until end
– Local variable sum held in register
– Avoids 1 memory read, 1 memory write per
cycle
– CPE: 2.00 (Compiled -O2)
• Memory references are expensive!

34
Detecting Unneeded Memory References
.L18:movl (%ecx,%edx,4),%eaxaddl %eax,(%edi)
incl %edxcmpl %esi,%edxjl .L18
.L24:addl (%eax,%edx,4),%ecx
incl %edxcmpl %esi,%edxjl .L24
Combine3 Combine4

35
Detecting Unneeded Memory References
• Performance
– Combine3
• 5 instructions in 6 clock cycles
• addl must read and write memory
– Combine4
• 4 instructions in 2 clock cyles


![Lecture 22: Code Optimization Introduction to Code ...cs164/fa11/lectures/lecture22-2x2.pdf · Lecture 22: Code Optimization [AdaptedfromnotesbyR.BodikandG.Necula] Administrivia •](https://img.pdfslide.us/doc/110x75/61495b0e080bfa6260148e8f/lecture-22-code-optimization-introduction-to-code-cs164fa11lectureslecture22-2x2pdf.jpg)


























