Embed Size (px)
Citation preview
1
CITS3401:Data Warehousingand Data Mining
Unit Coordinator: Wei Liu, email: [email protected]
Lecturer : Suprava Patnaik
email: [email protected]
Room 1.18 Computer Science & Software Engineering
Lecture hours: 9.00-11.00 am Thursday
Discussion slot: 1.30-2.30pm Thursday
Unit Web Page: http://undergraduate.csse.uwa.edu.au/units/CITS3401/
Lecture Slides, Project related information, Sample Question Patterns, Announcements and Help
1

2
CITS3401 Assessments
Two projects : 25% each An analysis of a business scenario through an OLAP tool.
We will be using an excel plug-in PALO for Data Warehousing Project.
An analysis of a data mining and exploration problem using WEKA.
Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java Code
Labs will start from the fourth week. Both OLAP and WEKA can be downloaded freely
Final Examination: 50% Updates will be available in the course website
2

CITS3401: Text Book
• Course Text Book: “Data Mining: Concepts and Techniques”, 2nd ed., Jiawei Han and Micheline Kamber- 2006
• .........., 3rd ed., Jiawei Han and Micheline Kamber, Jian Pei -2011
Jiawei Han‘s web page: http://web.engr.illinois.edu/~hanj/
References:• Data Mining: Methods and Techniques by, A.
Shawkat Ali and Saleh Wasimi Thomson, 2007
3

4

Text Book Screen Shut
5

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining? A Knowledge Discovery (KDD) Process
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
6

Why Data Mining?
The Explosive Growth of Data: from terabytes to petabytes Data Explosion
Our capability of generating , collecting, storing and managing data has grown tremendously in the last 50 years.
Data collection and data availability Automated data collection tools, database systems, Web, computerized
society Major sources of abundant data
Business: Web, e-commerce, transactions, stocks, … Science: Remote sensing, bioinformatics, scientific simulation, … Society and everyone: news, digital cameras, YouTube
We are drowning in data, but starving for knowledge! “Necessity is the mother of invention”—Data mining—Automated
and scalable analysis of massive data sets7

Why Data Mining?—Potential Applications
Data analysis and decision support Market analysis and management
Target marketing, customer relationship management (CRM), market basket analysis, cross selling, market segmentation
Risk analysis and management Forecasting, customer retention, improved underwriting,
quality control, competitive analysis Fraud detection and detection of unusual patterns (outliers)
Other Applications Text mining (news group, email, documents) and Web
mining Stream data mining
8

Ex. 1: Market Analysis and Management
Where does the data come from?—Credit card transactions, loyalty cards, discount coupons, customer complaint calls, plus (public) lifestyle studies,
Target marketing Find clusters of “model” customers who share the same characteristics:
interest, income level, spending habits, etc. Determine customer purchasing patterns over time
Cross-market analysis—Find associations/co-relations between product sales, & predict based on such association
Customer profiling—What types of customers buy what products (clustering or classification)
Customer requirement analysis Identify the best products for different groups of customers Predict what factors will attract new customers
Provision of summary Information: Multidimensional summary reports Statistical summary information (data central tendency and variation)
9

Ex. 2: Corporate Analysis & Risk Management
Finance planning and asset evaluation cash flow analysis and prediction contingent claim analysis to evaluate assets cross-sectional and time series analysis (financial-ratio,trend
analysis, etc.) Resource planning
summarize and compare the resources and spending Competition
monitor competitors and market directions group customers into classes and a class-based pricing
procedure set pricing strategy in a highly competitive market
10

Ex. 3: Fraud Detection & Mining Unusual Patterns
Approaches: Clustering & model construction for frauds, outlier analysis
Applications: Health care, retail, credit card service, telecomm. Money laundering: suspicious monetary transactions Medical insurance:
Professional patients, ring of doctors, and ring of references Unnecessary or correlated screening tests
Telecommunications: phone-call fraud Phone call model: destination of the call, duration, time of day
or week. Analyze patterns that deviate from an expected norm Retail industry:
Analysts estimate that 38% of retail shrink is due to dishonest employees
Anti-terrorism:
11

Evolution of Sciences
Before 1600, empirical science 1600-1950s, theoretical science
Each discipline has grown a theoretical component. Theoretical models often motivate experiments and generalize our understanding.
1950s-1990s, computational science Over the last 50 years, most disciplines have grown a third, computational branch (e.g.
empirical, theoretical, and computational ecology, or physics, or linguistics.) Computational Science traditionally meant simulation. It grew out of our inability to find
closed-form solutions for complex mathematical models. 1990-now, data science
The flood of data from new scientific instruments and simulations The ability to economically store and manage petabytes of data online The Internet and computing Grid that makes all these archives universally accessible Scientific info. management, acquisition, organization, query, and visualization tasks scale
almost linearly with data volumes. Data mining is a major new challenge!
12

Evolution of Database Technology
1960s: Data collection, database creation, IMS and network DBMS
1970s: Relational data model, relational DBMS implementation
1980s: RDBMS, advanced data models (extended-relational, OO, deductive, etc.) Application-oriented DBMS (spatial, scientific, engineering, etc.)
1990s: Data mining, data warehousing, multimedia databases, and Web databases
2000s Stream data management and mining Data mining and its applications Web technology (XML, data integration) and global information systems
13

Why Data Mining?
Summary: Abundance of data and data archives are seldom
visited. Far exceeded human ability for comprehension Intuitive decisions are prone to biases and errors, and
is extremely time-consuming and costly Data mining tools perform data analysis and uncover
important data patterns, contributing greatly to business strategies, knowledge bases, and scientific and medical research.
Data Tombs
Nuggets of knowledge 14

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining? A Knowledge Discovery from Data(KDD) Process
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
15

What Is Data Mining?
Data mining (knowledge discovery from data) Extraction of interesting (non-trivial, implicit, previously
unknown and potentially useful) patterns or knowledge from huge amount of data
Data mining: a misnomer? (Knowledge Mining from data) Alternative names
Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
Watch out: Is everything “data mining”? Simple search and query processing (Deductive) expert systems
16

What is Data Mining Tremendous amount of data (terabyte-petabyte)
High-dimensionality and high complexity of data Structured, un-structured, heterogeneous data
Scalable
Data mining involves integration of multiple disciplines: Machine learning Pattern recognition Statistics Databases Business Intelligence Big data
Efficient: Derived knowledge is new, interesting, informative and can be used for sophisticated application (decision making, process control, information management....)
17

Data Mining: Confluence of Multiple Disciplines
Data Mining
Database Technology Statistics
MachineLearning
PatternRecognition
AlgorithmOther
Disciplines
Visualization
18

Steps of Knowledge Discovery (KDD) Process
This is a view from typical database systems and data warehousing communities
Data mining plays an essential role in the knowledge discovery process
Data Cleaning
Data Integration
Databases
Data Warehouse
Task-relevant Data
Selection
Data Mining
Pattern Evaluation
19

Data Warehousing and Mining Framework
20

KDD Process: Several Key Steps Learning the application domain
relevant prior knowledge and goals of application Creating a target data set: data selection Data cleaning and preprocessing: (may take 60% of effort!) Data reduction and transformation
Find useful features, dimensionality/variable reduction, invariant representation
Choosing functions of data mining summarization, classification, regression, association,
clustering Choosing the mining algorithm(s) Data mining: search for patterns of interest Pattern evaluation and knowledge presentation
visualization, transformation, removing redundant patterns, etc.
Use of discovered knowledge21

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
22

Multi-Dimensional View of Data Mining
Data to be mined Database data (extended-relational, object-oriented, heterogeneous,
legacy), data warehouse, transactional data, stream, spatiotemporal, time-series, sequence, text and web, multi-media, graphs & social and information networks
Knowledge to be mined (or: Data mining functions) Characterization, discrimination, association, classification, clustering,
trend/deviation, outlier analysis, etc. Descriptive vs. predictive data mining Multiple/integrated functions and mining at multiple levels
Techniques utilized (methodologies) Data-intensive, data warehouse (OLAP), machine learning, statistics,
pattern recognition, visualization, high-performance, etc. Applications adapted
Retail, telecommunication, banking, fraud analysis, bio-data mining, stock market analysis, text mining, Web mining, etc. 23

Data Mining: On What Kinds of Data?
Structured and semi-structured data
Relational database/ Object-relational data
data warehouse,
transactional database
Unstructured data
Data streams and sensor data
Text data and web data
Time-series data, temporal data, sequence data (incl. bio-sequences)
Graphs, social networks and information networks
Spatial data, spatiotemporal data and multimedia data
24

Relational Database
A relational database is a collection of tables, each of which is assigned a unique name.
Each table consists of a set of attributes (columns or fields) and usually stores a large set of tuples (records or rows).
Each tuple in a relational table represents an object identified by unique key and described by a set of attribute values.
A semantic data model, such as the entity relationship data model, is often constructed for relational databases.
An ER data model represents the database as a set of entities and their relationships.
25

Relational Database
Relational data can be accessed by database queries written in a relational language such as SQL.
A given query is transformed into a set of relational operations such as join, selection and projection, and is then optimized for efficient processing.
Efficiency of retrieval, efficiency of update and integrity are the key requirements of a good relational database.
26

An Example The relational database of the AllElectronics company has four
relational tables: customer, item, employee and branch. The relation customer consists of a set of attributes, including a
unique customer_ID, name, address, age, occupation, income, etc. Similarly, the other three relations have their attributes.
27

Example of Queries
Show me a list of all items that were sold in the last quarter
Show me the total sales of the last month, grouped by branch
Which sales person has the highest amount of sales?
How many sales transactions occurred in the month of September?
28

Purpose of relationaldatabases
The main purpose of a relational database is to store data correctly and retrieve data on demand.
This type of data processing is sometime called Online Transaction Processing (OLTP).
Relational databases are passive data repositories in the sense that a query only shows you what is stored in the database, but cannot tell you much about the meaning or trend of the data.
29
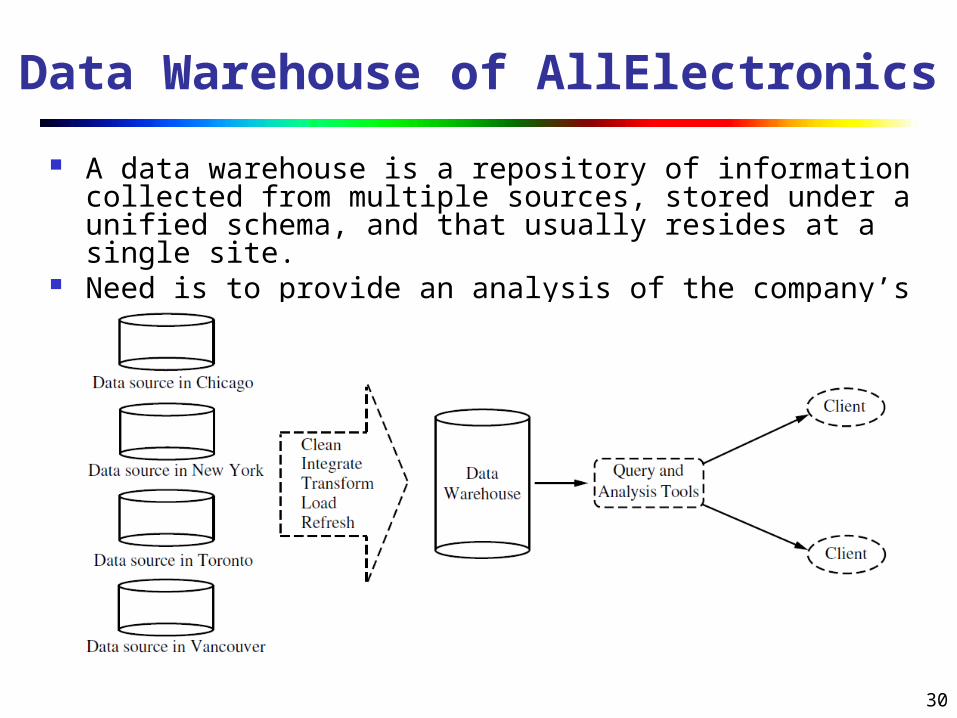
Data Warehouse of AllElectronics
A data warehouse is a repository of information collected from multiple sources, stored under a unified schema, and that usually resides at a single site.
Need is to provide an analysis of the company’s sales per item type per branch for the a specified period.
30

Data Warehouse the data warehouse may store a summary of the transactions per item type
for each store or, summarized to a higher level, for each sales region.
31

Transactional Database
A transactional database consists of a file where each record represents a transaction.
Supports nested relation
Transaction id: Items, Customer name, date…
Sample Queries: Show me all the items purchased by ‘X’ How many transactions include item number ‘Y’? market basket data analysis: Which items sold well
together? (Frequent item set)
32

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
33

Knowledge View: What Knowledge to be mined?
Data summary in multidimensional space Data cube and OLAP (On-Line Analytical Processing)
Pattern discovery Mining frequent patterns, association and correlation Applying pattern mining in many other tasks
Classification and predictive modelling Model construction based on some training examples Prediction of new data based on constructed models
Cluster analysis: How to group data to form new categories? Outlier analysis: Discovery of anomalies and rare events Trend and evolution analysis
34

Data Mining Function: (1) Characterization and Discrimination
Data can be associated with classes or concepts. ( e.g., classes of items: computer, printers concept of customers: bigSpender, budgetSpender.. are the descriptions )
Multidimensional concept description: Characterization: summarizing the class in general. (e.g. general
specification of products whose sales increased by 10% and , ….profile of customers who spend more than $1000 a year. )
Discrimination: comparison of target class with a contrast class.( compare the two groups of customers, such as who shop computer products regularly versus who rarely shop such products). Drilling down on dimensions such as occupation, age,etc.)
35

Data Mining Function: (2) Association and Correlation Analysis
Frequent patterns (or frequent item_sets) What items are frequently purchased together ?
Association, correlation vs. causality A typical association rule
Milk Bread [0.5%, 75%] (support, confidence) Are strongly associated items also strongly correlated?
How to mine such patterns and/or set rules efficiently in large datasets? ( single or multi-dimensional association, minimum support threshold)
How to use such patterns for classification, clustering, and other applications?
36

Data Mining Function: (3) Classification
Classification and label prediction Construct models (functions) based on some training examples or rules….
[example: kind of response (good, mild, no) in sales campaign: price, brand, category, place_made…]
Describe and distinguish classes or concepts for future prediction E.g., classify countries based on (climate), or classify cars based on (gas
mileage) Predict some unknown class labels
Typical methods Decision trees, naïve Bayesian classification, support vector machines,
neural networks, rule-based classification, pattern-based classification, logistic regression, …
Typical applications: Credit card fraud detection, direct marketing, classifying stars, diseases,
web-pages, …37

Data Mining Function: (4) Cluster Analysis
Unsupervised learning (i.e., Class label is unknown) Group data to form new categories (i.e., clusters), e.g., cluster
houses to find distribution patterns Principle: Maximizing intra-class similarity & minimizing
interclass similarity Example: homogeneous sub-population of AllElectronics
customers (customer attributes: city, age, income,..) Many methods and applications
38

Data Mining Function: (5) Outlier Analysis
Outlier analysis Outlier: A data object that does not comply with the general
behavior of the data Most data mining methods discard outliers as noise or
exceptions. Noise or exception? ― One person’s garbage could be
another person’s treasure Methods: by product of clustering or regression analysis,
distance analysis, statistical or probability model, Useful in fraud detection, rare events are more interesting Example: By detecting a purchase of extremely large amount
for a given account number.39

Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Sequence, trend and evolution analysis Trend, time-series, and deviation analysis: e.g., regression and
value prediction Sequential pattern mining
e.g., first buy digital camera, then buy large SD memory cards Periodicity analysis (e.g., overall stock market evolution
regularities or for particular companies) Motifs and biological sequence analysis
Approximate and consecutive motifs Similarity-based analysis
Mining data streams Ordered, time-varying, potentially infinite, data streams
40

Structure and Network Analysis
Graph mining Finding frequent subgraphs (e.g., chemical compounds), trees (XML),
substructures (web fragments) Information network analysis
Social networks: actors (objects, nodes) and relationships (edges) e.g., author networks in CS, terrorist networks
Multiple heterogeneous networks A person could be multiple information networks: friends, family,
classmates, … Links carry a lot of semantic information: Link mining
Web mining Web is a big information network: from PageRank to Google Analysis of Web information networks
Web community discovery, opinion mining, usage mining, …
41

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
42

Methodology View: Confluence of Multiple Disciplines
Data Mining
MachineLearning
Statistics
Applications
Algorithm
PatternRecognition
Distributed / cloud
computing
Visualization
Database Technology
43

Why Confluence of Multiple Disciplines?
Tremendous amount of data Algorithms must be scalable to handle big data
High-dimensionality of data Micro-array may have tens of thousands of dimensions
High complexity of data Data streams and sensor data Time-series data, temporal data, sequence data Structure data, graphs, social and information networks Spatial, spatiotemporal, multimedia, text and Web data Software programs, scientific simulations
New and sophisticated applications
44

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining/ classification What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
45

Application View: Diverse Applications
Mining text data and mining the Web Web page classification and ranking, Weblog analysis,
recommender systems, … Mining business data
Transaction data, market basket analysis, fraud detection, … Data mining and software/system engineering e.g., mining
software bugs , optimize system performance, help in computer vision
Mining biological and medical data Gene, protein, microarray data, biological networks
Mining social and information networks Community discovery, information propagation, …
Invisible data mining : web search, stock market analysis
46

Classification of Data Mining System
Classification according to the kinds of database mined: relational, transactional, ….spatial, text, stream data….or World Wide Web
Classification according to the kinds of knowledge mined: Based on mining functionalities, e.g. : characterization, discrimination, association, ….can be multiple and/or integrated data mining…., can be distinguished based on granularity…, regular or irregular patterns(outliers) mining
Classification according to the techniques utilized: degree of user interaction involved ( autonomous, interactive, query-driven), method of analysis (machine learning, pattern recognition, statistics, neural network….), combining merits of individual aspects..
Classification according to the applications adapted: Finance, Telecommunication, DNA, stock-market…all purpose data mining system may not fit for domain specific minig.
47

Summary (till this)
Data mining: Discovering interesting patterns and knowledge from massive amount of data
A natural evolution of science and information technology, in great demand, with wide applications
A KDD process includes data cleaning, data integration, data selection, transformation, data mining, pattern evaluation, and knowledge presentation
Mining can be performed in a variety of data Data mining functionalities: characterization, discrimination, association,
classification, clustering, trend and outlier analysis, etc. Data mining technologies and applications
48

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining What Kinds of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Kinds of Technologies Are Used?
What Kinds of Applications Are Targeted?
Are all the patterns interesting?
Integration of Data Mining System with Data Warehousing System
Major Issues in Data Mining
49

Evaluation of Knowledge
Are all mined knowledge interesting? One can mine tremendous amount of “patterns” Some may fit only certain dimension space (time, location,
…) Some may not be representative, may be transient, …
Evaluation of mined knowledge → directly mine only interesting knowledge? Descriptive vs. predictive Coverage Typicality vs. novelty Accuracy Timeliness …
50

Are All the “Discovered” Patterns Interesting?
Data mining may generate thousands of patterns: Not all of them are
interesting Suggested approach: Human-centered, query-based, focused mining
Interestingness measures A pattern is interesting if it is easily understood by humans, valid on new or
test data with some degree of certainty, potentially useful, novel, or validates
some hypothesis that a user seeks to confirm
Objective vs. subjective interestingness measures Objective: based on statistics and structures of patterns, e.g., support,
confidence, etc.
Subjective: based on user’s belief in the data, e.g., unexpectedness, novelty,
actionability, etc.
51

Find All and Only Interesting Patterns?
Find all the interesting patterns: Completeness Can a data mining system find all the interesting patterns? Do we need to
find all of the interesting patterns? Heuristic vs. exhaustive search Association vs. classification vs. clustering
Search for only interesting patterns: An optimization problem Can a data mining system find only the interesting patterns? Approaches
First general all the patterns and then filter out the uninteresting ones Generate only the interesting patterns—mining query optimization
52

Integration of Data Mining and Data Warehousing
Data mining systems, DBMS, Data warehouse systems coupling
No coupling, loose-coupling, semi-tight-coupling, tight-coupling
On-line analytical mining data
integration of mining and OLAP technologies
Interactive mining multi-level knowledge
Necessity of mining knowledge and patterns at different levels of
abstraction by drilling/rolling, pivoting, slicing/dicing, etc.
Integration of multiple mining functions
Characterized classification, first clustering and then association
53

Coupling Data Mining with DB/DW Systems
No coupling—flat file processing for developing efficient and effective algorithms,… is a poor design as may spend time in preprocessing.
Loose coupling- Fetching data from DB/DW. Mining does not explore data structure and optimization methods provided by DB & DW.Difficult for high scalability.
Semi-tight coupling—enhanced DM performance Provide efficient implement a few data mining primitives in a DB/DW
system, e.g., sorting, indexing, aggregation, histogram analysis, multiway join, precomputation of some statistical functions
Tight coupling—uniform processing environment DM is smoothly integrated into a DB/DW system, mining query is
optimized based on mining query, indexing, query processing methods, etc.
54

Major Issues in Data Mining (1)
Mining Methodology Mining various and new kinds of knowledge Mining knowledge in multi-dimensional space at multiple level of
abstraction. Data mining: An interdisciplinary effort Boosting the power of discovery in a networked environment Handling noise, uncertainty, and incompleteness of data Pattern evaluation and pattern- or constraint-guided mining
User Interaction Interactive mining Background knowledge (integrity constraints & deduction rules) Presentation and visualization of data mining results
55

Major Issues in Data Mining (2)
Efficiency and Scalability Efficiency and scalability of data mining algorithms Parallel, distributed, stream, and incremental mining methods
Diversity of data types Handling complex types of data Mining dynamic, networked, and global data repositories
Data mining and society Social impacts of data mining Privacy-preserving data mining Invisible data mining
56

A Brief History of Data Mining Society
1989 IJCAI Workshop on Knowledge Discovery in Databases Knowledge Discovery in Databases (G. Piatetsky-Shapiro and W. Frawley, 1991)
1991-1994 Workshops on Knowledge Discovery in Databases Advances in Knowledge Discovery and Data Mining (U. Fayyad, G. Piatetsky-
Shapiro, P. Smyth, and R. Uthurusamy, 1996) 1995-1998 International Conferences on Knowledge Discovery in Databases and Data
Mining (KDD’95-98) Journal of Data Mining and Knowledge Discovery (1997)
ACM SIGKDD conferences since 1998 and SIGKDD Explorations More conferences on data mining
PAKDD (1997), PKDD (1997), SIAM-Data Mining (2001), (IEEE) ICDM (2001), WSDM (2008), etc.
ACM Transactions on KDD (2007)
57

Where to Find References? DBLP, CiteSeer, Google
Data mining and KDD (SIGKDD: CDROM) Conferences: ACM-SIGKDD, IEEE-ICDM, SIAM-DM, PKDD, PAKDD, etc. Journal: Data Mining and Knowledge Discovery, KDD Explorations, ACM TKDD
Database systems (SIGMOD: ACM SIGMOD Anthology—CD ROM) Conferences: ACM-SIGMOD, ACM-PODS, VLDB, IEEE-ICDE, EDBT, ICDT, DASFAA Journals: IEEE-TKDE, ACM-TODS/TOIS, JIIS, J. ACM, VLDB J., Info. Sys., etc.
AI & Machine Learning Conferences: Machine learning (ML), AAAI, IJCAI, COLT (Learning Theory), CVPR, NIPS, etc. Journals: Machine Learning, Artificial Intelligence, Knowledge and Information Systems, IEEE-PAMI,
etc. Web and IR
Conferences: SIGIR, WWW, CIKM, etc. Journals: WWW: Internet and Web Information Systems,
Statistics Conferences: Joint Stat. Meeting, etc. Journals: Annals of statistics, etc.
Visualization Conference proceedings: CHI, ACM-SIGGraph, etc. Journals: IEEE Trans. visualization and computer graphics, etc.
58

Recommended Reference Books
E. Alpaydin. Introduction to Machine Learning, 2nd ed., MIT Press, 2011
S. Chakrabarti. Mining the Web: Statistical Analysis of Hypertex and Semi-Structured Data. Morgan Kaufmann, 2002
R. O. Duda, P. E. Hart, and D. G. Stork, Pattern Classification, 2ed., Wiley-Interscience, 2000
T. Dasu and T. Johnson. Exploratory Data Mining and Data Cleaning. John Wiley & Sons, 2003
U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy. Advances in Knowledge Discovery and Data Mining.
AAAI/MIT Press, 1996
U. Fayyad, G. Grinstein, and A. Wierse, Information Visualization in Data Mining and Knowledge Discovery, Morgan Kaufmann,
2001
J. Han, M. Kamber, and J. Pei, Data Mining: Concepts and Techniques. Morgan Kaufmann, 3 rd ed. , 2011
T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2 nd ed.,
Springer, 2009
B. Liu, Web Data Mining, Springer 2006
T. M. Mitchell, Machine Learning, McGraw Hill, 1997
Y. Sun and J. Han, Mining Heterogeneous Information Networks, Morgan & Claypool, 2012
P.-N. Tan, M. Steinbach and V. Kumar, Introduction to Data Mining, Wiley, 2005
S. M. Weiss and N. Indurkhya, Predictive Data Mining, Morgan Kaufmann, 1998
I. H. Witten and E. Frank, Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations, Morgan
Kaufmann, 2nd ed. 2005
59