Embed Size (px)
Citation preview

1
Chapter 17 Disk Storage, Basic File Structures,
and Hashing
Chapter 18Index Structures for Files

3
Storage
• Primary storage (main memory)– Can be operated on directly by computer CPU
small, fast
• Secondary storage– http://en.wikipedia.org/wiki/Hard_disk– Can not be operated on directly by computer CPU
– Magnetic disks, optical disks, tapes, etc.
– Larger capacities, inexpensive, slower than main memory

4
Storage capacity units
• Kilobytes – 1000 bytes
• Megabytes – 1 million bytes
• Gigabytes (Gbytes) – 1 billion bytes
• Terabytes – 1000 gigabytes

5
Memory Hierarchies and Storage Devices
• Primary storage– Cache (static RAM)– most expensive, fast, used
by CPU to speed up execution programshttp://wombat.doc.ic.ac.uk/foldoc/foldoc.cgi?query=cache
- Main memory (dynamic RAM) – work area for CPU

6
Secondary storage (Mass storage)
– CD-ROM– Tapes– Disks
Main memory database: entire database is stored in main memory

7
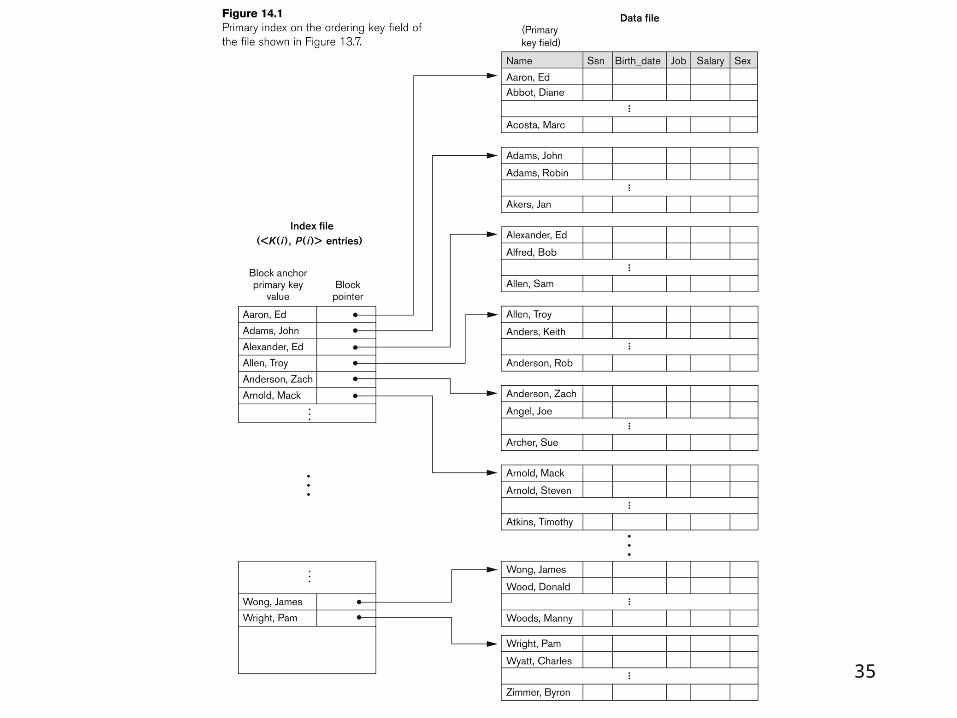
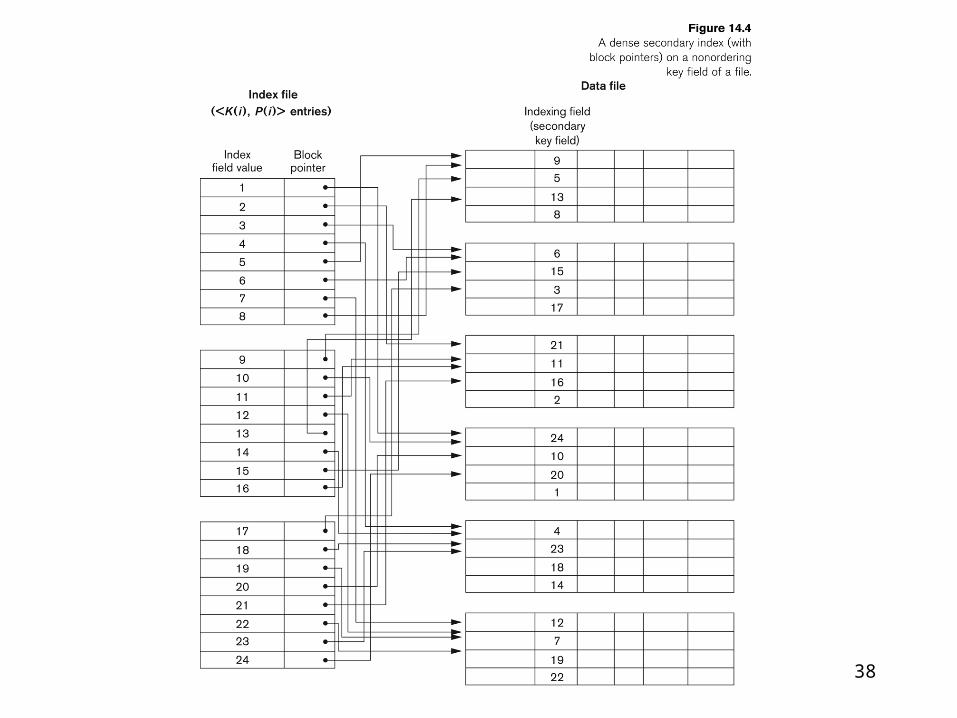
File organization• Heap file (unordered file)
place new records in no order at the end of the file
• Sorted file ( sequential file) keeps the records ordered by the value of a particular
file
• Hashed fileUses hash function applied to a field (hash key) to
determine a record’s placement on disk
• B-trees, B+ trees – use tree structure
8

9
Binary codes

10
11
12

13
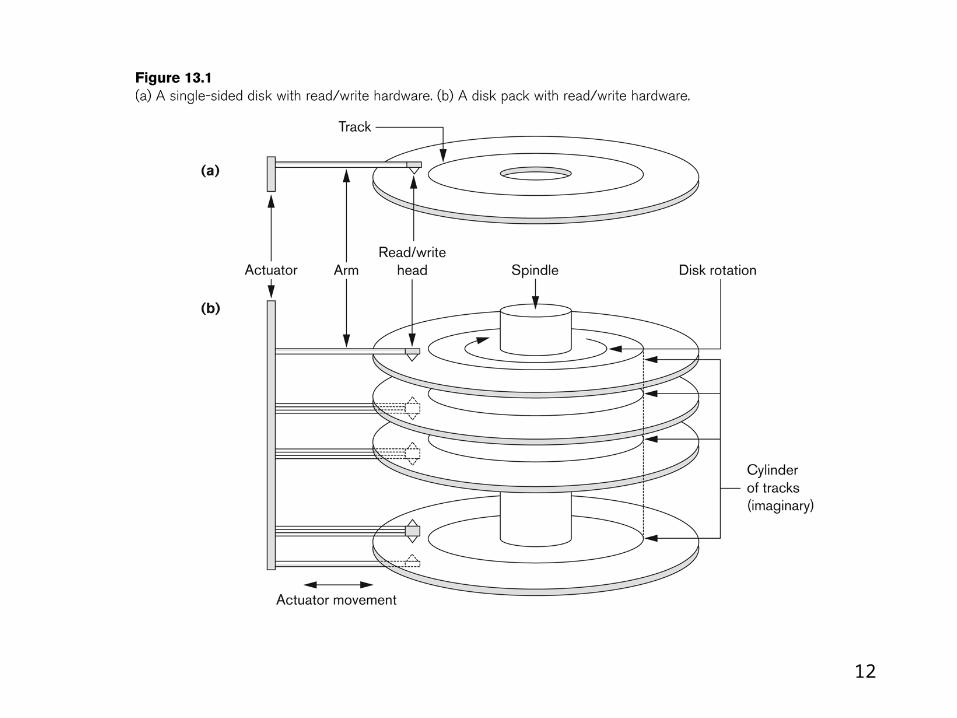
Tracks
The part of a disk which passes under one read/write head while the head is stationary. The number of tracks on a disk surface therefore corresponds to the number of different radial positions of the head(s). The collection of all tracks on all surfaces at a given radial position is known
a cylinder and each track is divided into sectors.

14
Cylinder
• The set of tracks on a multi-headed disk that may be accessed without head movement. That is, the collection of disk tracks which are the same distance from the spindle about which the disks rotate.

15
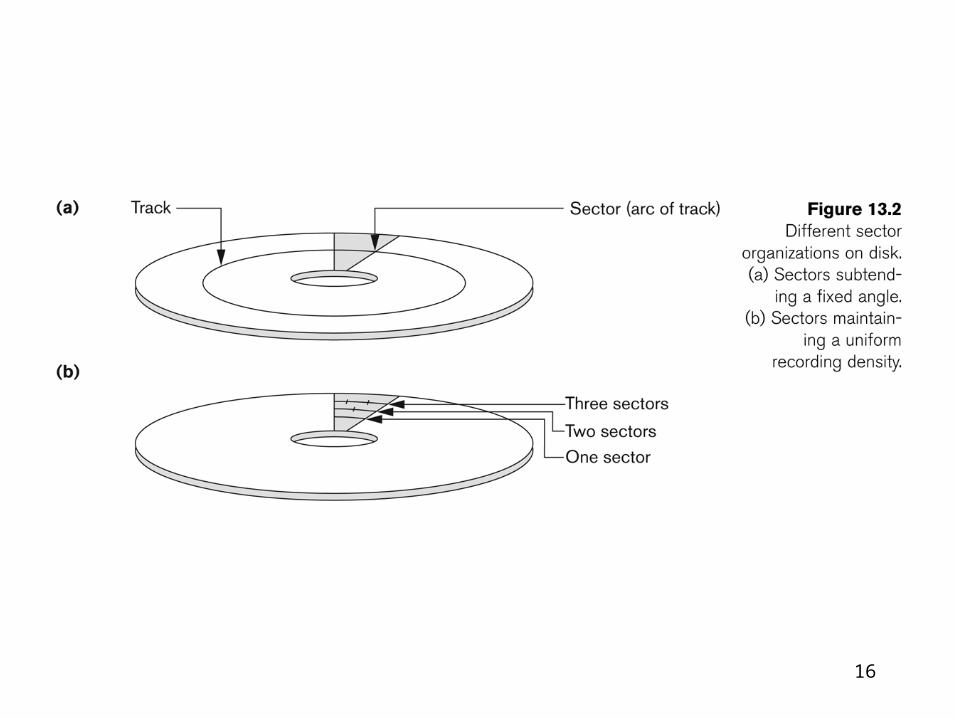
Sector
• one sector lies within a continuous range of rotational angle of the disk
16

17
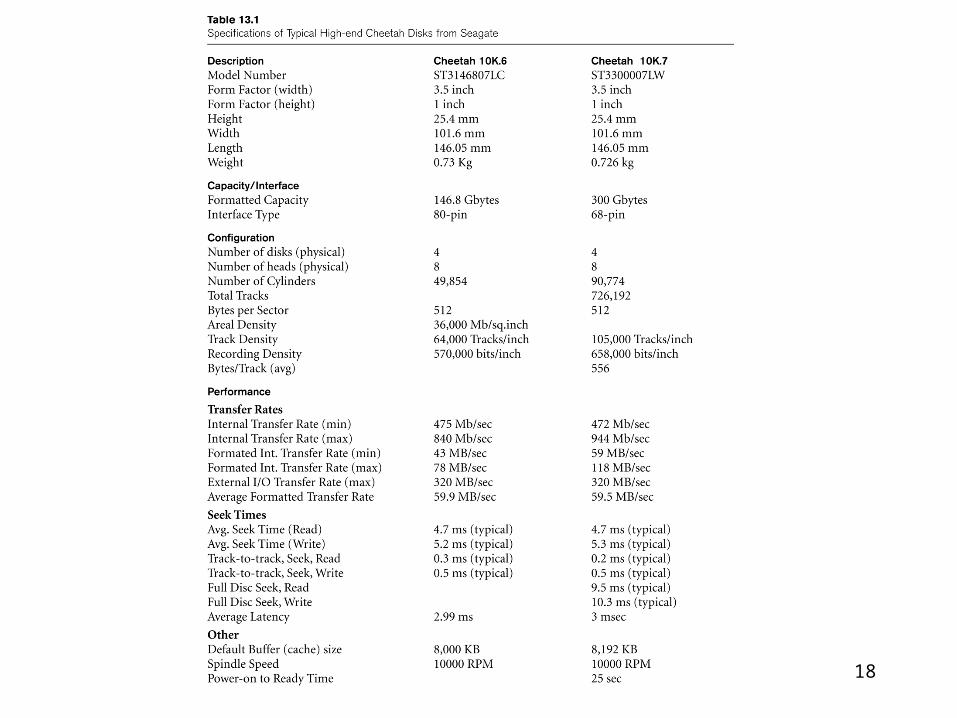
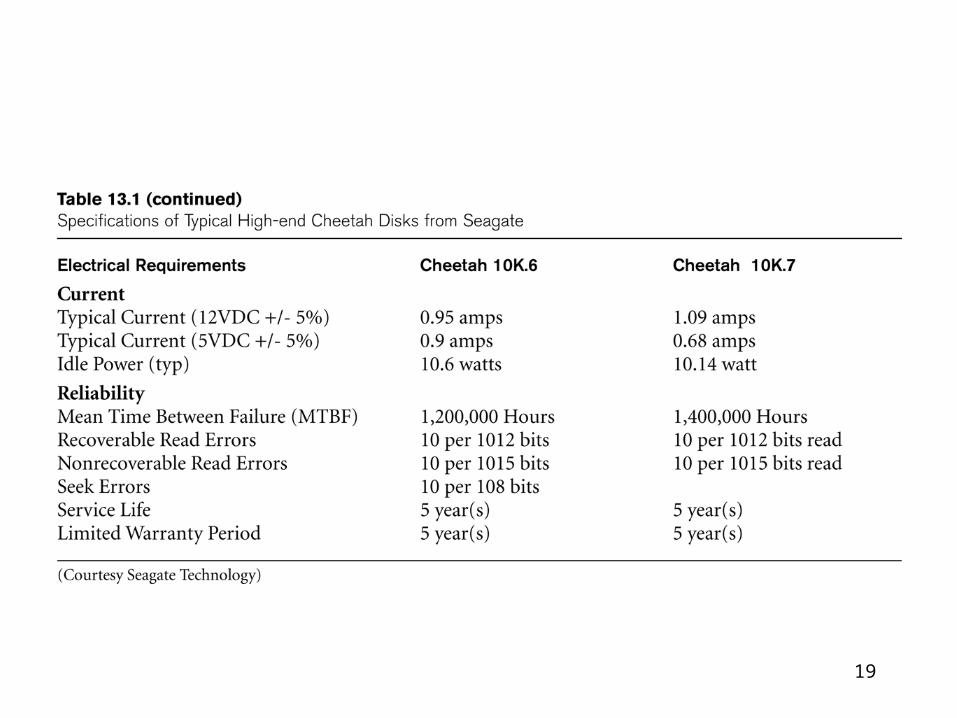
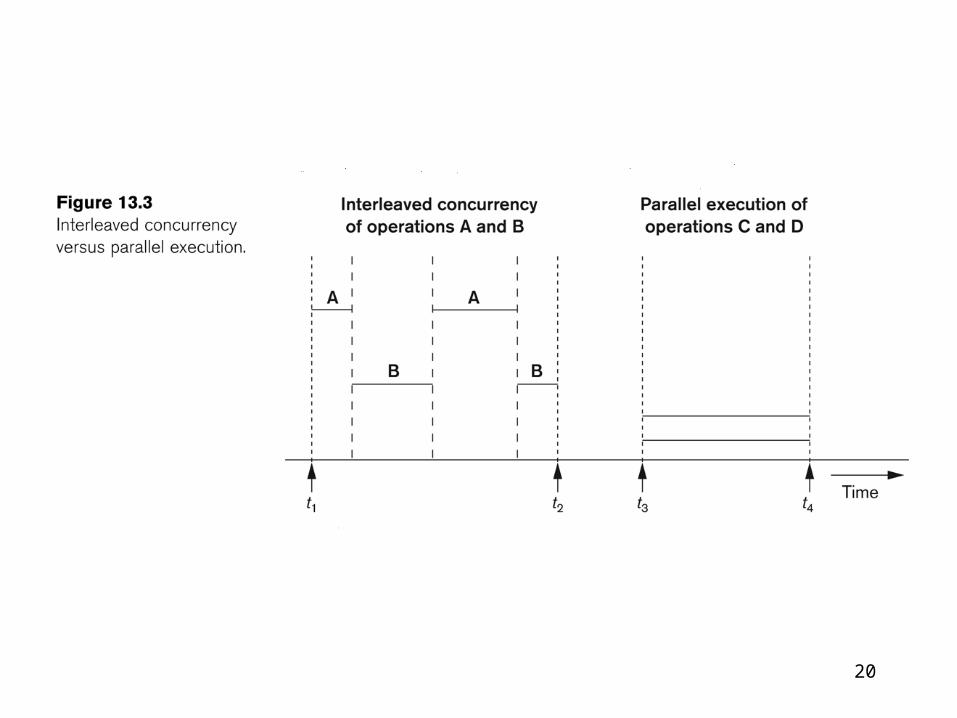
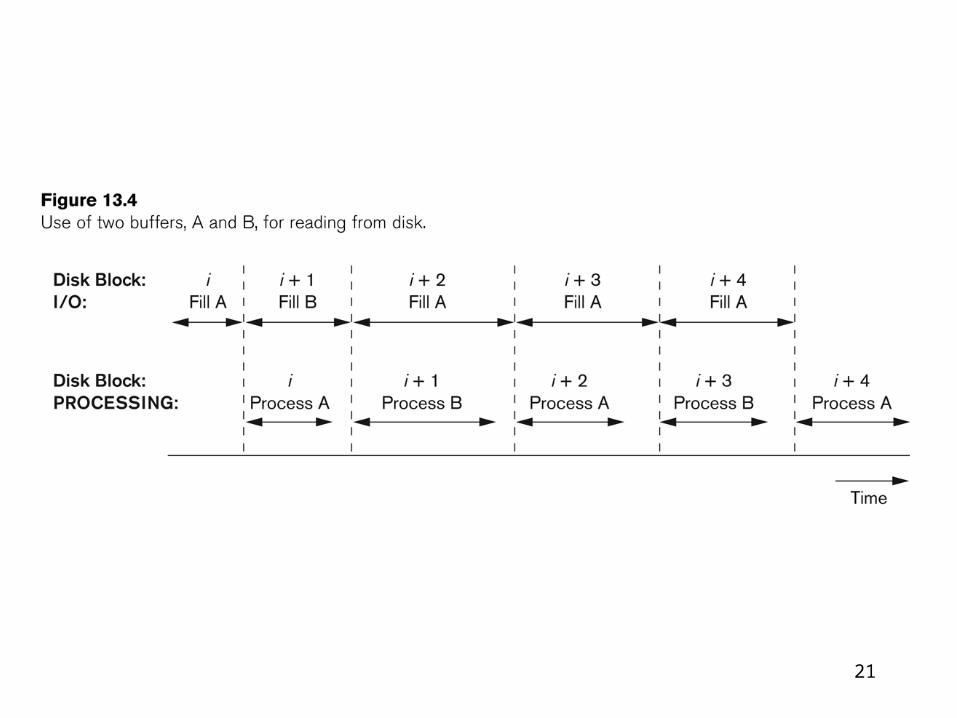
Data transfer between main memory and disks
(in blocks)
Hardware Address of a block– Surface number– Track number– Block number
• Time requires– Seek time– Rotational delay time (latency)– Block transfer time
18
19
20
21
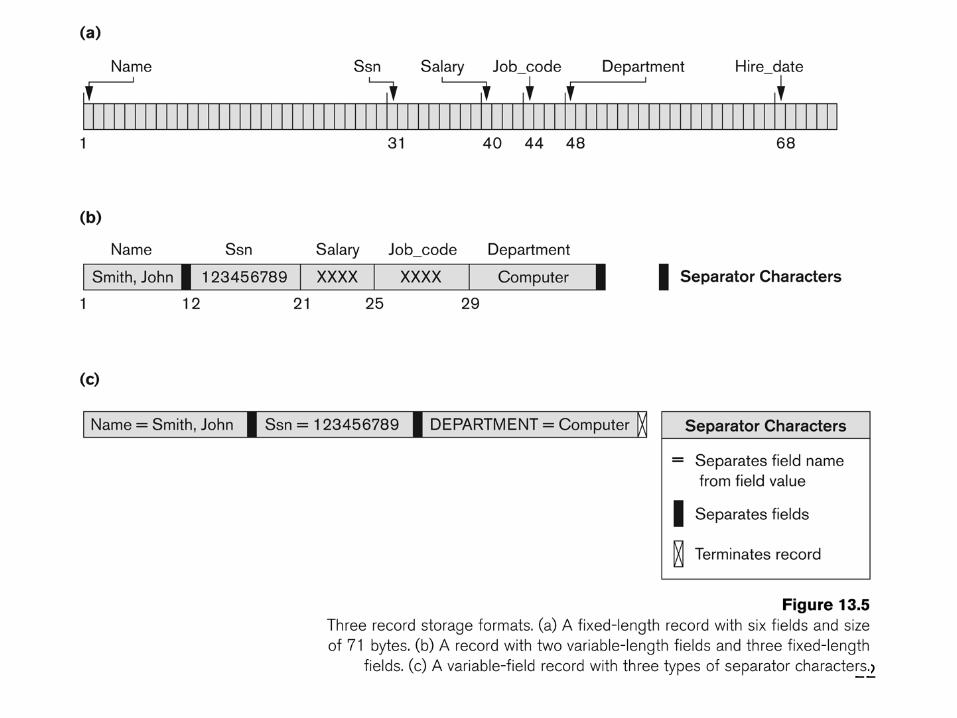
22
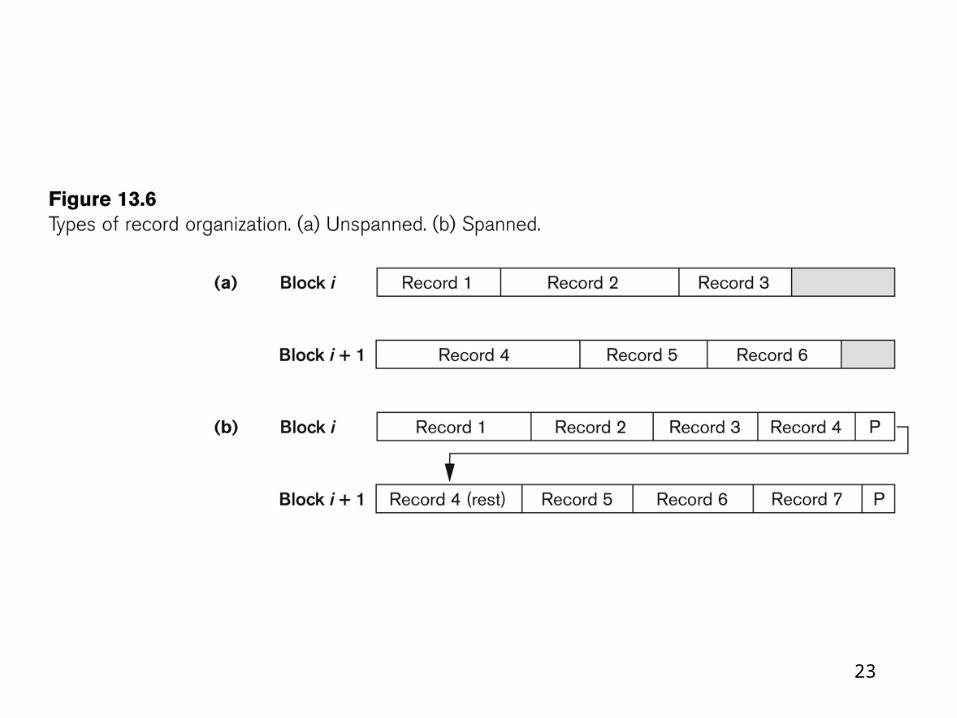
23
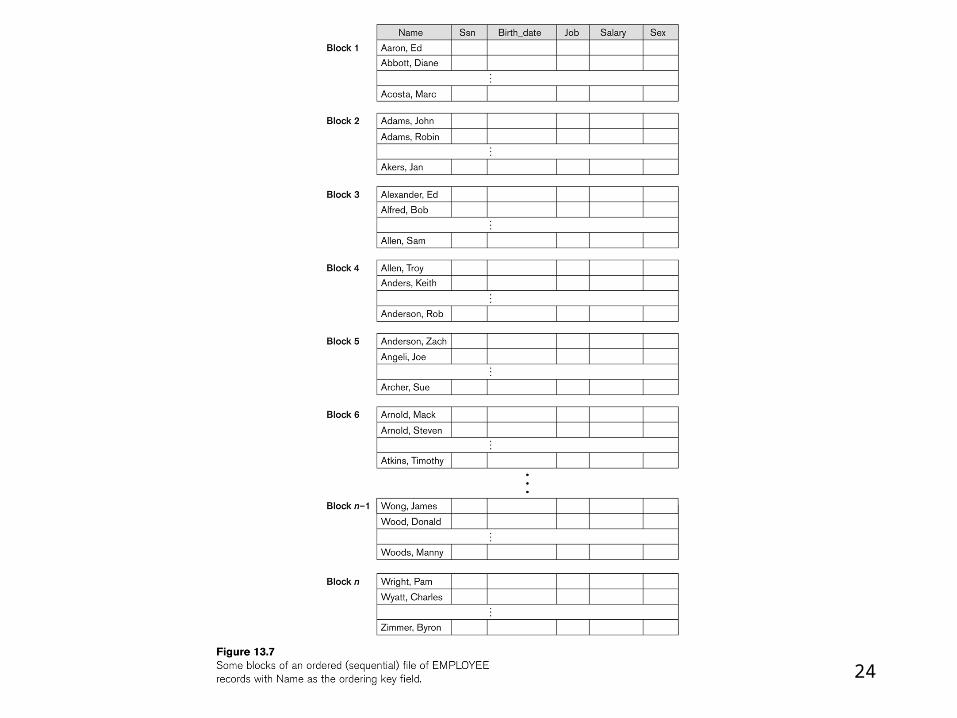
24
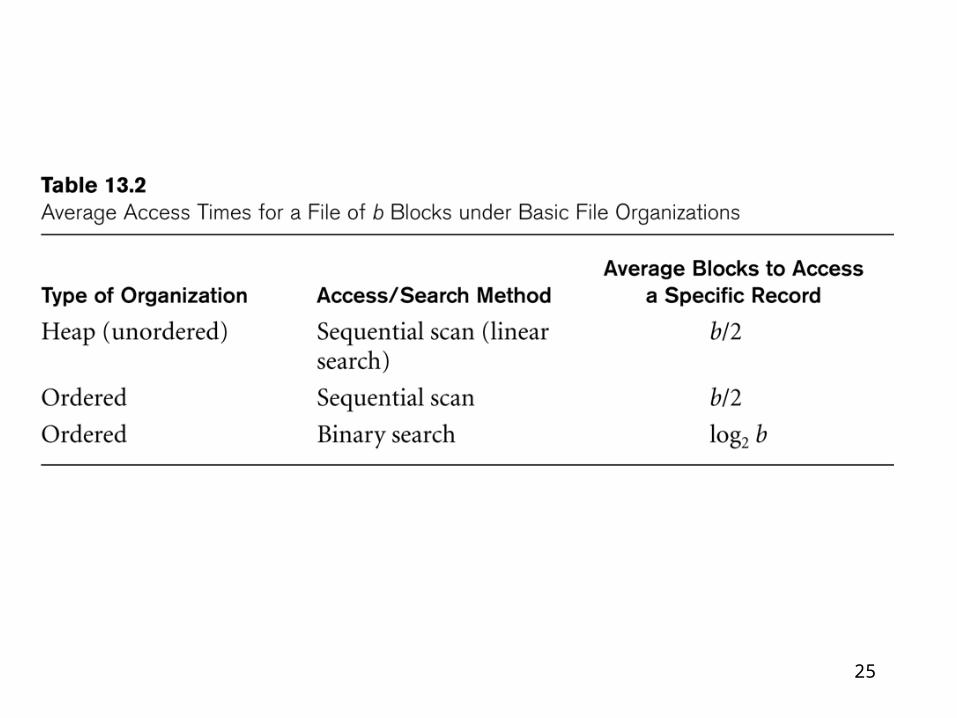
25

26

27
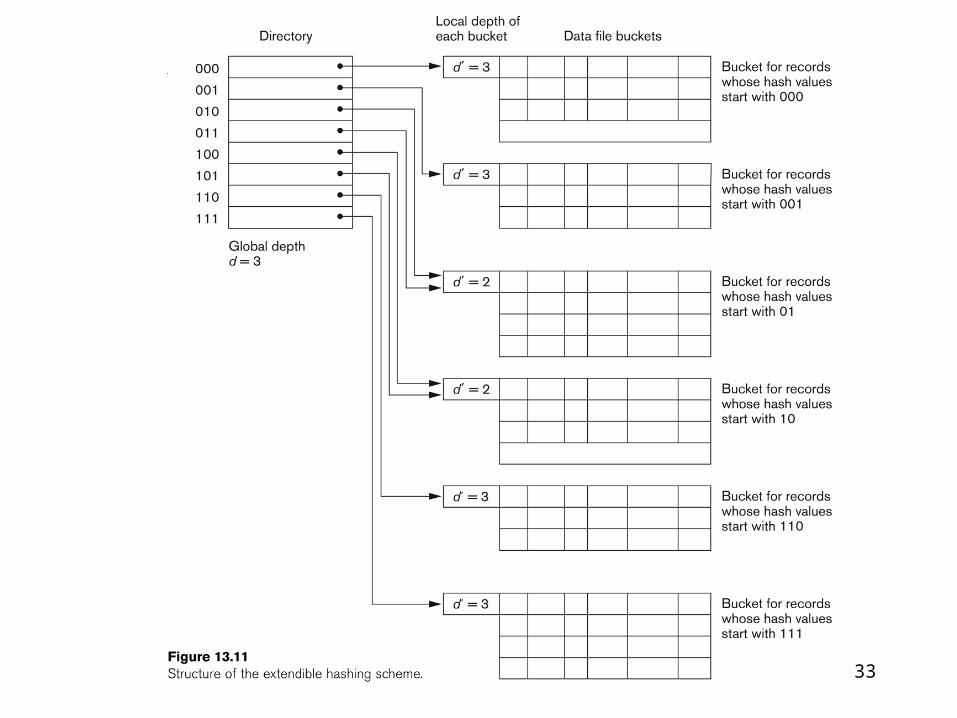
Hashing techniques
Static hashing – hash address space is fixed
Extendible hashing
Linear hashing

28
Hashing algorithm
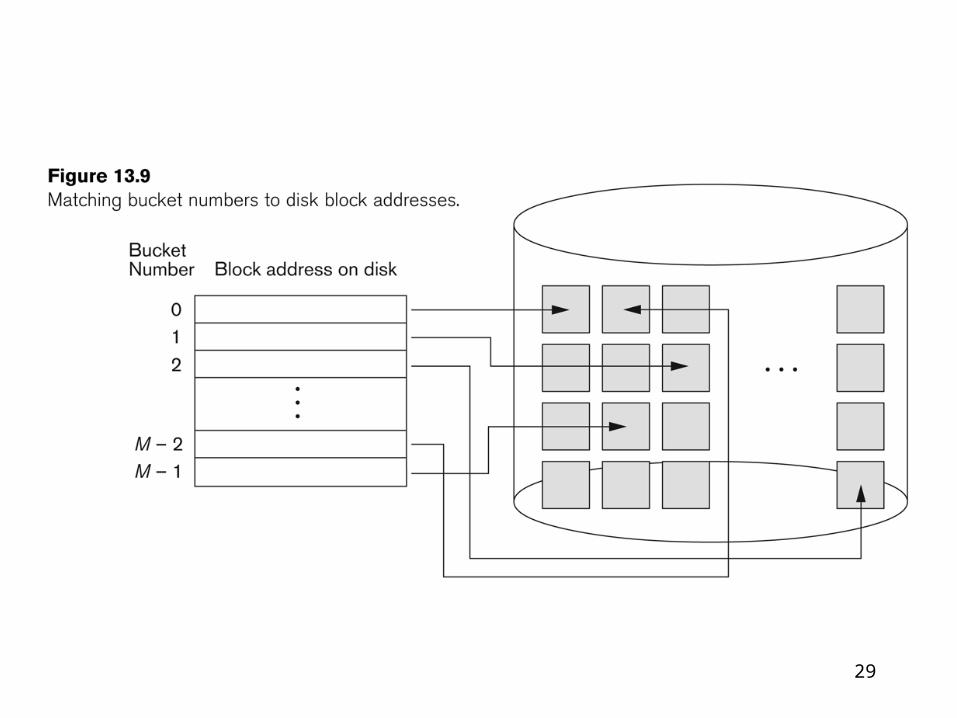
29
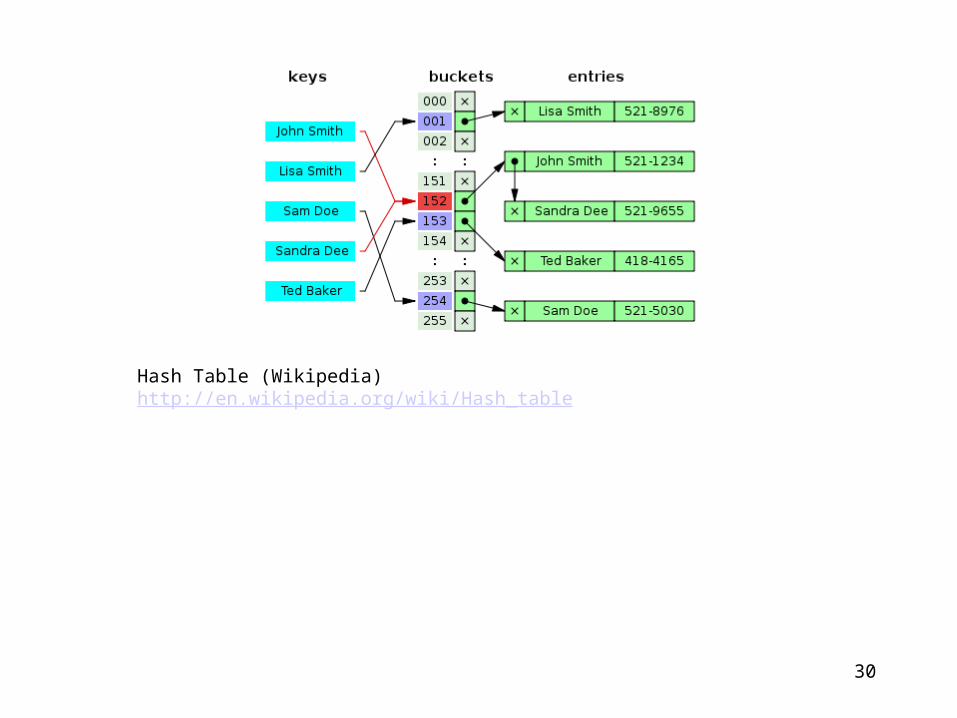
30
Hash Table (Wikipedia) http://en.wikipedia.org/wiki/Hash_table
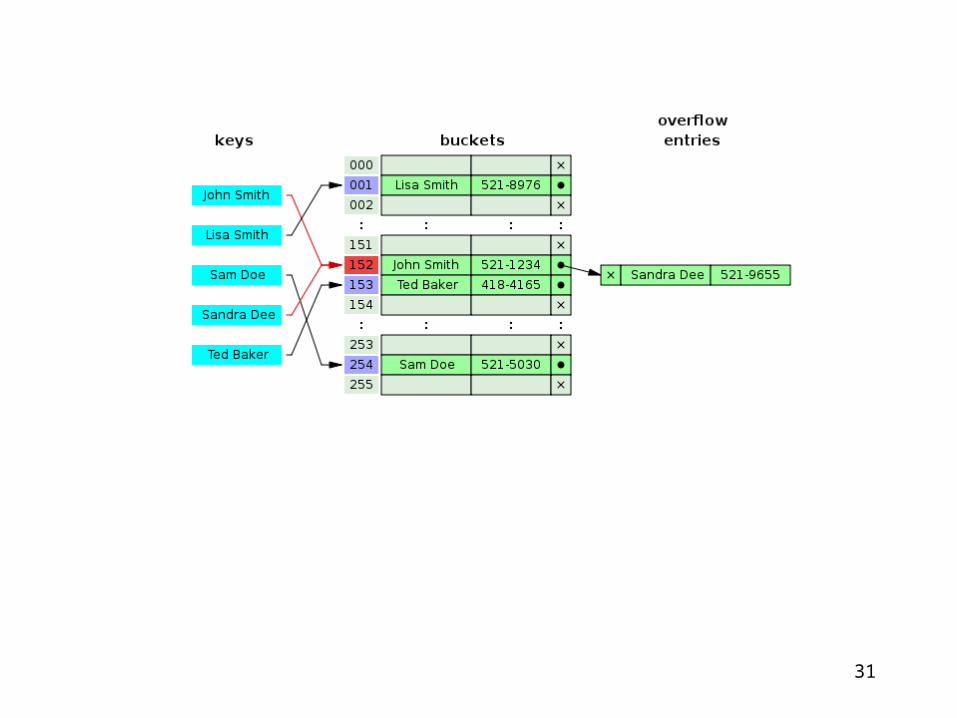
31
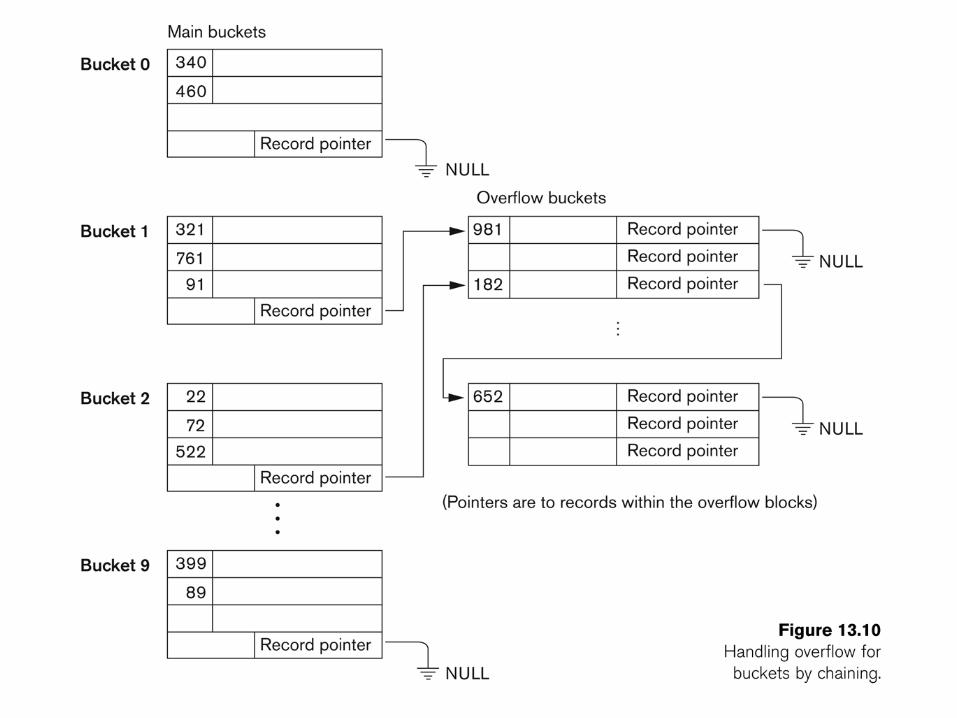
32
33

34
35

36

37
38

39

40
41
42
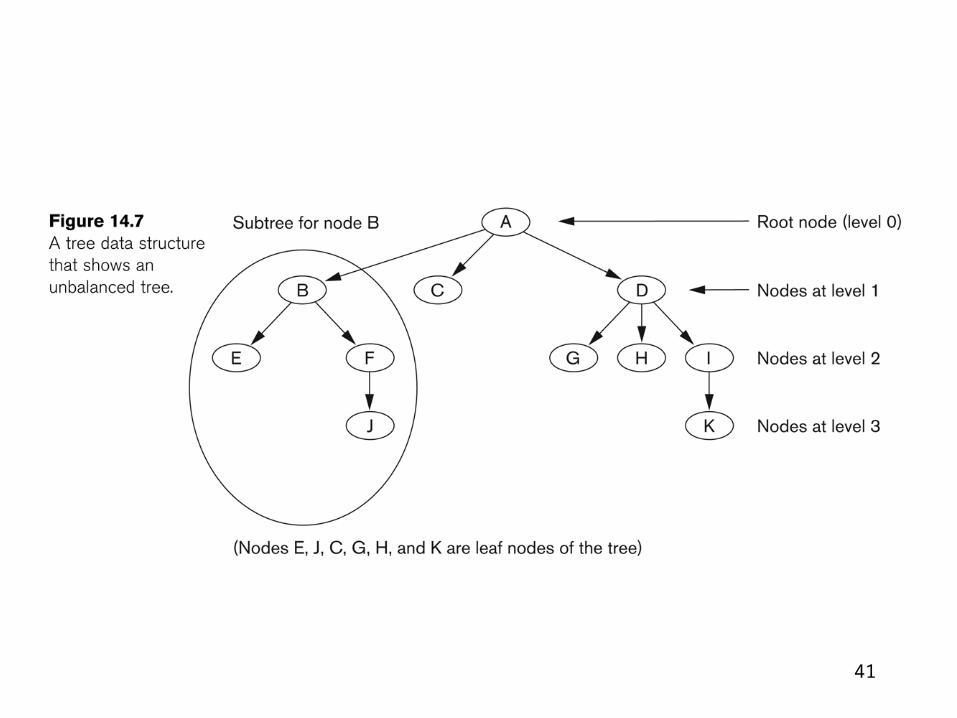
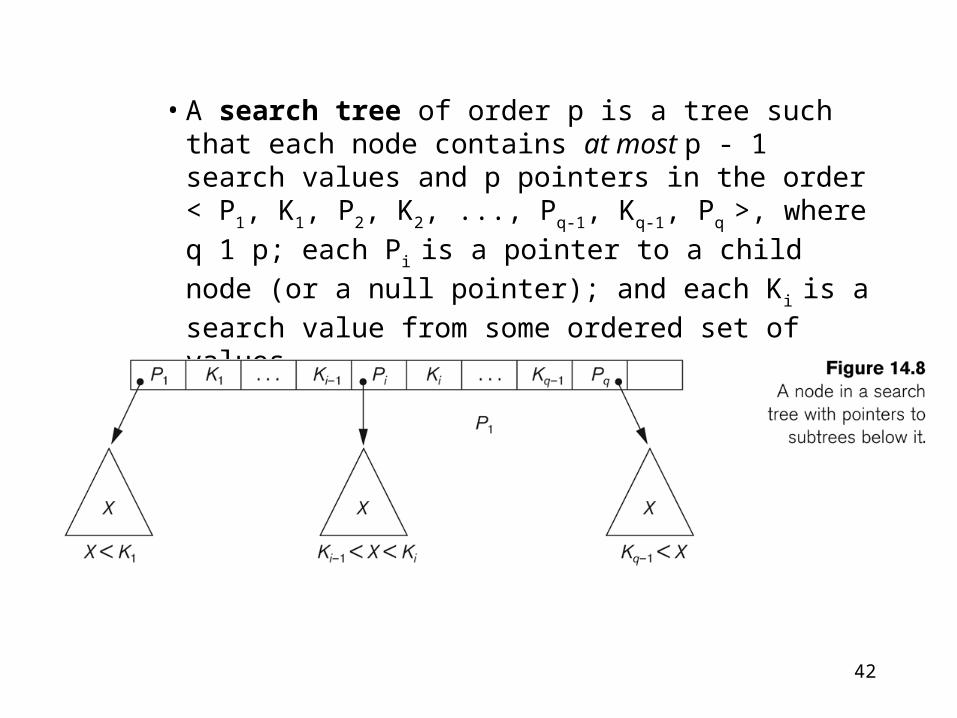
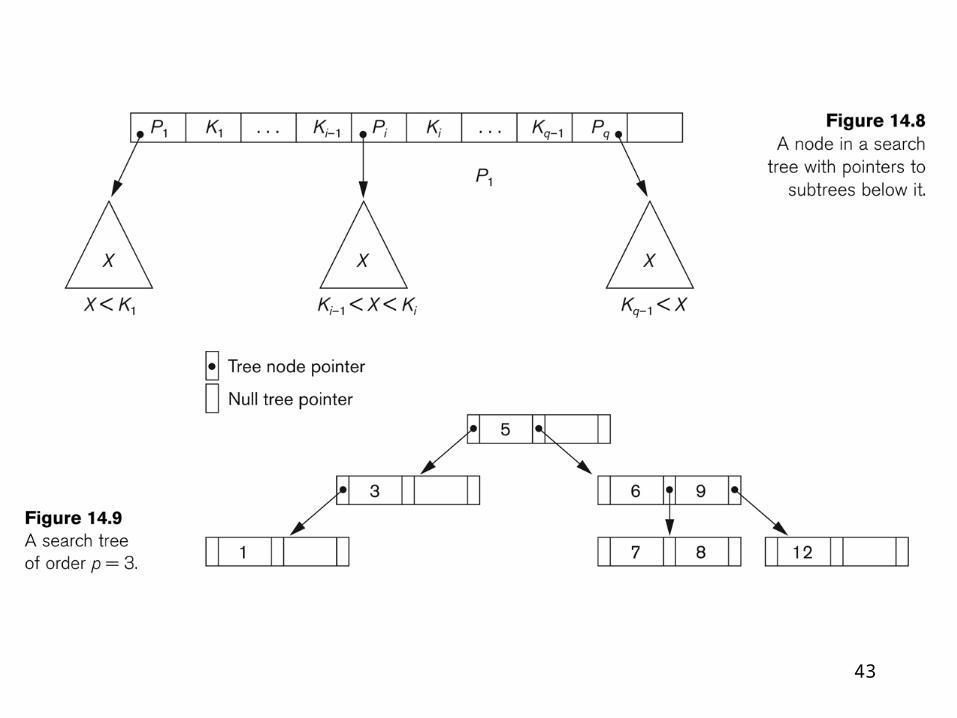
• A search tree of order p is a tree such that each node contains at most p - 1 search values and p pointers in the order < P1, K1, P2, K2, ..., Pq-1, Kq-1, Pq
>, where q 1 p; each Pi is a pointer to a child node
(or a null pointer); and each Ki is a search value
from some ordered set of values.
43
44

45
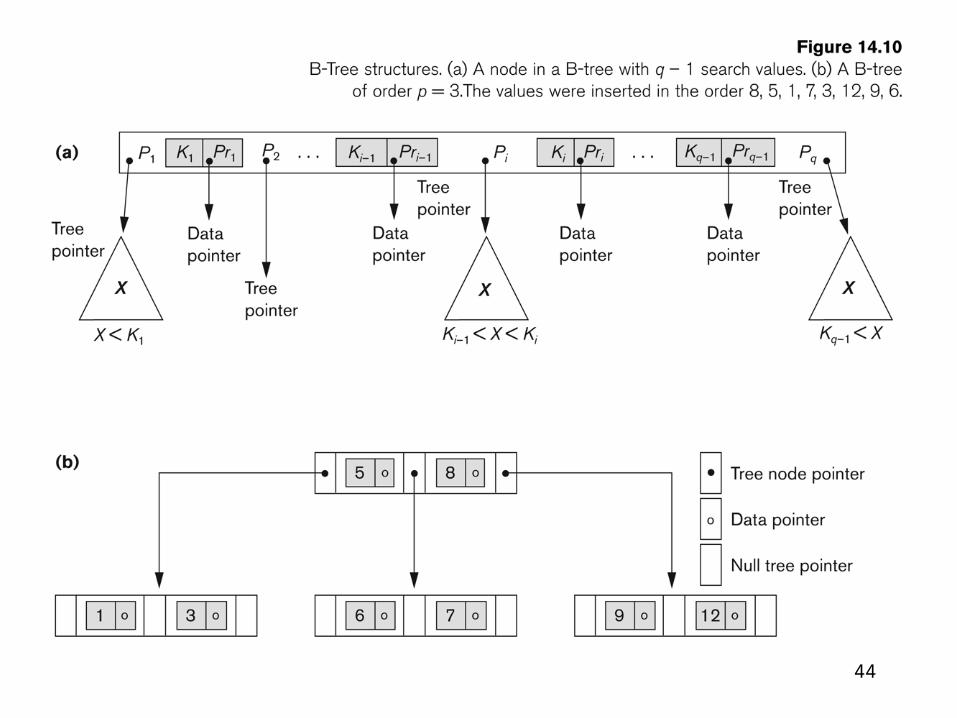
B tree of order p
1. Each internal node in the B-tree is of the form
<P1, <K1, Pr1> , P2, <K2, Pr2> , ..., <Kq-1,Prq-1> , Pq> where q 1 p. Each Pi is a tree pointer—a pointer to another node in the B-tree. Each Pri is a data pointer —a pointer to the record whose search key field value is equal to Ki (or to the data file block containing that record).
2. Within each node, K1 <K2 < ... < Kq-1.
3. For all search key field values X in the subtree pointed at by P i (the ith subtree, see Figure 06.10a), we have:
Ki-1 < X < Ki for 1 < i < q; X < Ki for i = 1; and Ki-1 < X for i = q. 4. Each node has at most p tree pointers. 5. Each node, except the root and leaf nodes, has at least (p/2) tree pointers. The root
node has at least two tree pointers unless it is the only node in the tree. 6. A node with q tree pointers, q 1 p, has q - 1 search key field values (and hence has q -
1 data pointers). 7. All leaf nodes are at the same level. Leaf nodes have the same structure as internal
nodes except that all of their tree pointers Pi are null.

46
EXAMPLE 5: Suppose that the search field of Example 4 is a nonordering key field, and we construct a B-tree on this field. Assume that each node of the B-tree is 69 percent full. Each node, on the average, will have p * 0.69 = 23 * 0.69 or approximately 16 pointers and, hence, 15 search key field values. The average fan-out fo =16. We can start at the root and see how many values and pointers can exist, on the average, at each subsequent level:
Root: 1 node 15 entries 16 pointers
Level 1: 16 nodes 240 entries 256 pointers
Level 2: 256 nodes 3840 entries 4096 pointers
Level 3: 4096 nodes 61,440 entries 65536 pointers
Level 4: 65536 nodes 983,040 entries

47
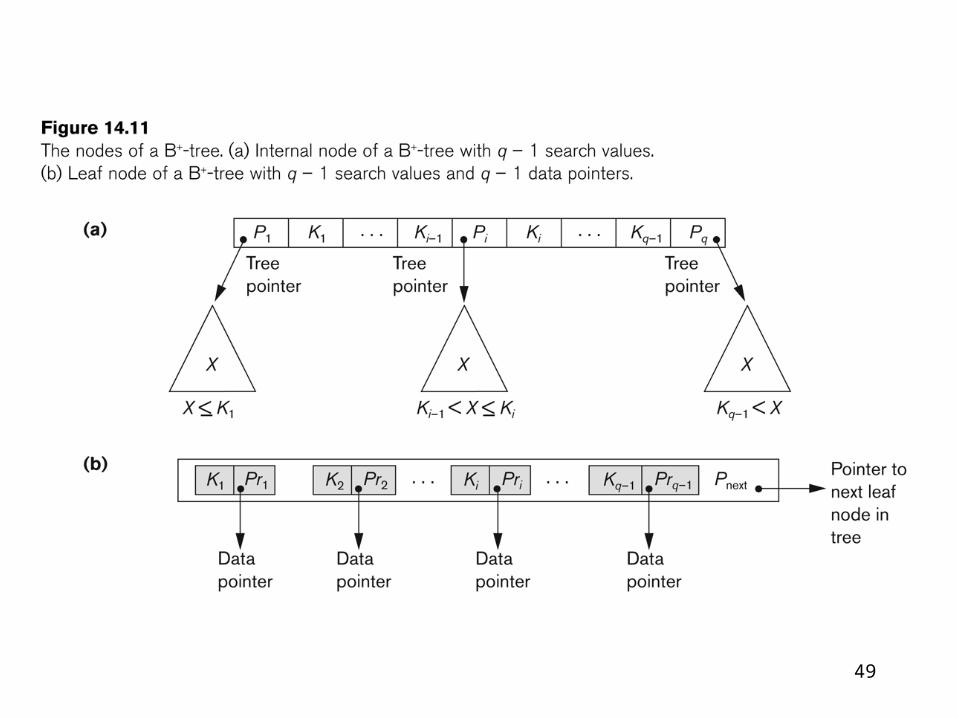
B+ TreesThe structure of the internal nodes of a B+-
tree of order p is as follows: 1. Each internal node is of the form <P1, K1, P2, K2, ..., Pq-1, Kq-1, Pq>
where q 1 p and each Pi is a tree pointer.
2. Within each internal node, K1 < K2 < ... <Kq-1.
3. For all search field values X in the subtree pointed at by Pi, we have
Ki-1 < X 1 Ki for 1 < i < q; X 1 Ki for i = 1; and Ki-1 < X for i = q.
4. Each internal node has at most p tree pointers.
5. Each internal node, except the root, has at least (p/2) tree pointers. The root node has at least two tree pointers if it is an internal node.
6. An internal node with q pointers, q 1 p, has q - 1 search field values.

48
The structure of the leaf nodes of a B+-tree of order p (Figure 14.11b) is as follows:
1. Each leaf node is of the form <<K1, Pr1> , <K2, Pr2>, ..., <Kq-1, Prq-1>, Pnext>
Where q 1 p, each Pri is a data pointer, and Pnext points to the next leaf
node of the B+-tree.
2. Within each leaf node, K1 < K2 < ... < Kq-1, q 1 p.
3. Each Pri is a data pointer that points to the record whose search field
value is Ki or to a file block containing the record (or to a block of
record pointers that point to records whose search field value is Ki if
the search field is not a key).
4. Each leaf node has at least (p/2) values.
5. All leaf nodes are at the same level.
49

50

51
EXAMPLE 7: Suppose that we construct a B+-tree on the field of Example 6. To calculate the approximate number of entries of the B+-tree, we assume that each node is 69 percent full. On the average, each internal node will have 34 * 0.69 or approximately 23 pointers, and hence 22 values. Each leaf node, on the average, will hold 0.69 * pleaf = 0.69 * 31 or
approximately 21 data record pointers. A B+-tree will have the following average number of entries at each level:
Root: 1 node 22 entries 23 pointers
Level 1: 23 nodes 506 entries 529 pointers
Level 2: 529 nodes 11,638 entries 12,167 pointers
Level 3: 12,167nodes 255,507entries 279,841 pointers
Level 4: 279,841 nodes 5,876,661entries

52
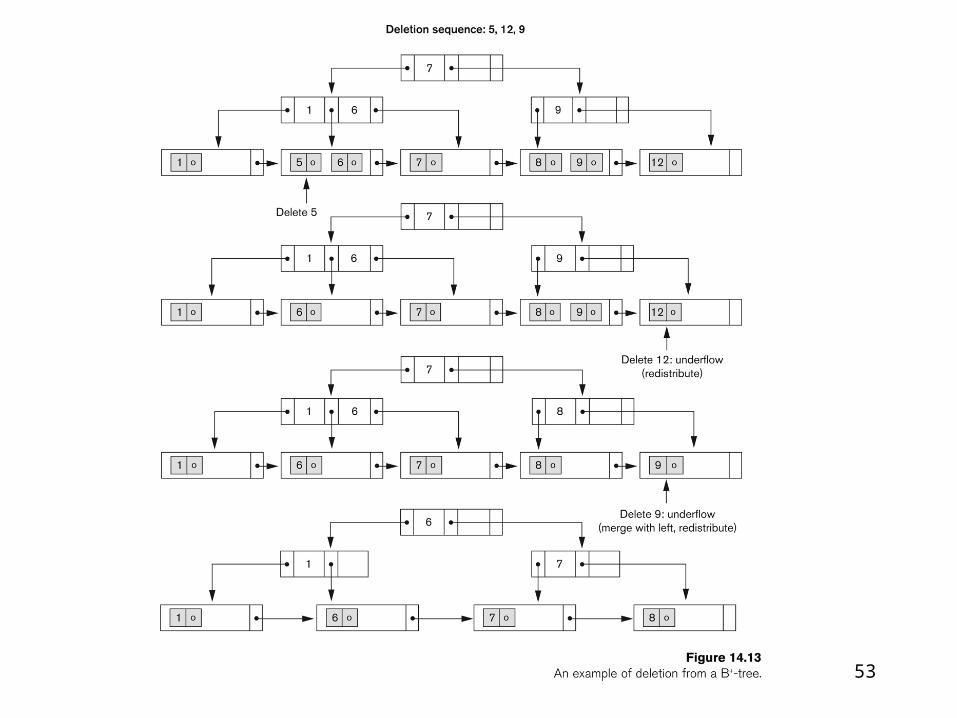
53
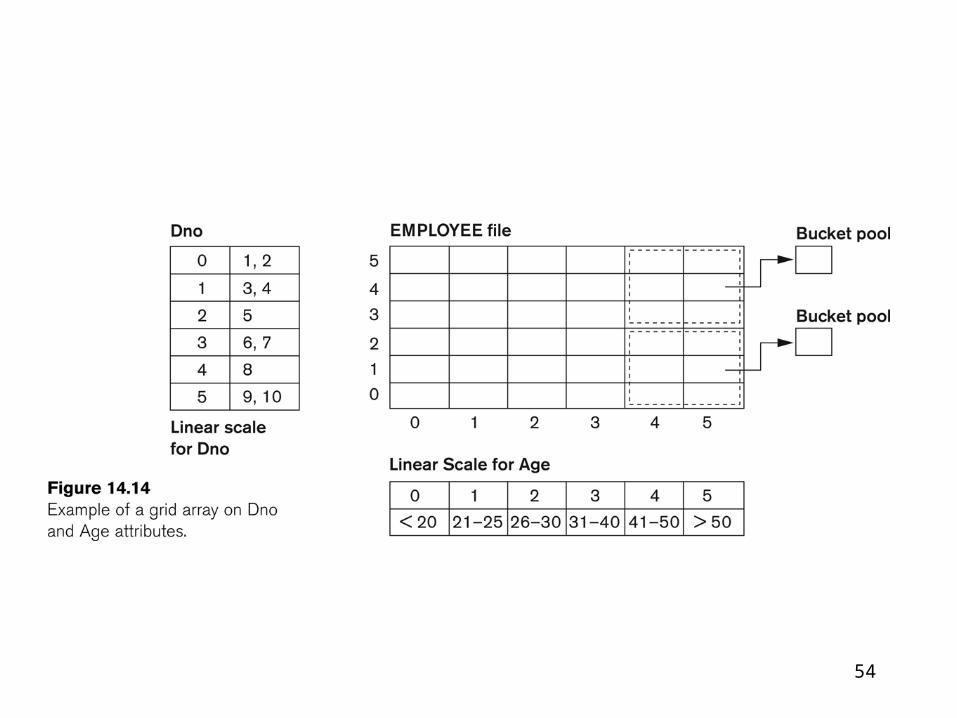
54
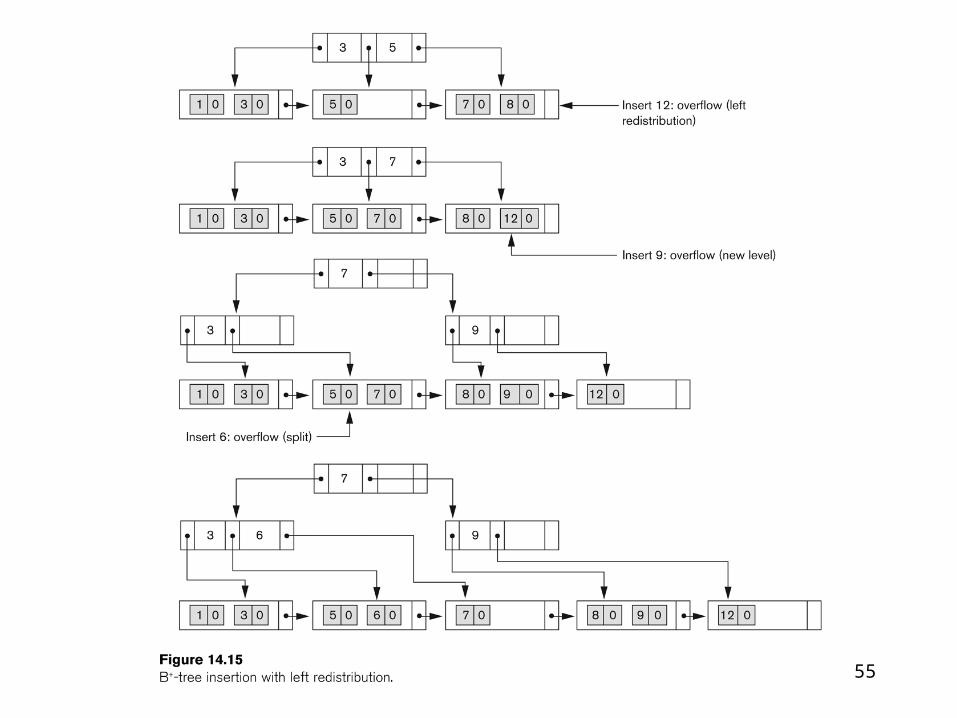
55






























