Embed Size (px)
Citation preview

1
Algorithms for Large Data Sets
Ziv Bar-YossefLecture 1
March 19, 2006
http://www.ee.technion.ac.il/courses/049011

2
Course overviewPart 1: Web Architecture of search engines Information retrieval
Index construction, Vector Space Model, evaluation criteria Ranking methods
Google’s PageRank, Kleinberg’s Hubs & Authorities Spectral methods
Latent Semantic Indexing Web structure
Power laws, small-world phenomenon Random graph models for the web
Preferential attachment, the copying model Web sampling
Sampling from the web, sampling from search engines Rank aggregation

3
Course overviewPart 2: Algorithms Random sampling
Mean, median, MST Data streams
Distinct elements, frequency moments, Lp distances Sketching
Shingling, Hamming distance, Bloom filters Dimension reduction
Low distortion embeddings, locality sensitive hash functions Lower bounds
Communication complexity, reductions

4
Prerequisites
Algorithms and data structures Complexity analysis Hashing
Probability theory Conditional probabilities, expectation, variance
Linear algebra Matrices, eigenvalues, vector spaces
Combinatorics Graph theory

5
Course requirements & grading
Papers review 90% of final grade Readings & participation 10% of final grade

6
Papers review Write a critical review of 2-3 papers on a
subject not studied in class.
Deliverables: Choice of papers to review (due: 4/6/06)5 page review report (due: 9/7/06)20 minute class presentation (9/7/06)

7
Textbooks
Mining the Web
by Soumen Chakrabarti
Modern Information Retrieval
by Ricardo Baeza-Yates and Berthier Ribeiro-Neto
Randomized Algorithms
by Rajeev Motwani and Prabhakar Raghavan

8
Instructor
Ziv Bar-Yossef Tel: 5737 Email: zivby@ee Office hours:
Mondays, 15:30-17:30 at 917 Meyer Mailing list: ee049011s-l

9
Large Data SetsExamples, Challenges, and Models

10
Examples of large data sets:Astronomy
• Astronomical sky surveys
• 120 Gigabytes/week
• 6.5 Terabytes/year
The Hubble Telescope
11
Examples of large data sets:Genomics
• 25,000 genes in human genome
• 3 billion bases
• 3 Gigabytes of genetic data

12
Examples of large data sets:Phone call billing records
• 250M calls/day
• 60G calls/year
• 40 bytes/call
• 2.5 Terabytes/year

13
Examples of large data sets:Credit card transactions
• 47.5 billion transactions in 2005 worldwide
• 115 Terabytes of data transmitted to VisaNet data processing center in 2004

14
Examples of large data sets:Internet traffic
Traffic in a typical router:
• 42 kB/second
• 3.5 Gigabytes/day
• 1.3 Terabytes/year

15
Examples of large data sets:The World-Wide Web
• 25 billion pages indexed
• 10kB/Page
• 250 Terabytes of indexed text data
• “Deep web” is supposedly 100 times as large

16
Reasons for the emergence of large data sets:Better technology
Storage & disksCheaperMore volumePhysically smallerMore efficient
Large data sets are affordable

17
Reasons for the emergence of large data sets:Better networking
High speed Internet Cellular phones Wireless LAN
More data consumers
More data producers

18
Reasons for the emergence of large data sets:Better IT More processes are automatic
E-commerce and V-commerce Online and telephone banking Online and telephone customer service E-learning Chats, news, blogs Online journals Digital libraries
More enterprises are computerized Companies Banks Governmental institutions Universities
More data is available in digital form
World’s yearly production of data:
5 billion Gigabyes
19
Reasons for the emergence of large data sets:Growing needs Science
Astronomy Earth and environmental studies Meteorology Genetics
Business Billing Mining customer data
More incentive to construct large data sets
Intelligence Emails Web sites Phone calls
Search Web pages Images Audio & Video

20
Characteristics of large data sets Huge Distributed
Dispersed over many servers
Dynamic Items add/deleted/modified continuously
Heterogeneous Many agents access/update data
Noisy Inherent Unintentional Malicious
Unstructured / semi-structured No database schema

21
New challengesRestricted access Large data sets are kept on magnetic and
optical storage devices
Access to data is sequential Random access is costly

22
New challengesStringent efficiency requirements
Traditionally, “efficient” algorithmsRun in (small) polynomial time.Use linear space.
For large data sets, efficient algorithmsMust run in linear or even sub-linear time.Must use up to poly-logarithmic space.

23
New challengesSearch the data
Traditionally, input data is:Either small and thus easily searchableModerately large, but organized in database
tables. In large data sets, input data is:
ImmenseDisorganized, unstructured, non-standardized
Hard to find what you want

24
New challengesMine the data
Association rules“Beers and diapers”
Patterns Clusters Statistical data Graph structure

25
New challengesClean the data Noise in data distorts
Computation results Search results Mining results
Need automatic methods for “cleaning” the data Spam filters Duplicate elimination Quality evaluation

26
Approximation of
Abstract model of computing
Data
(n is very large)
• Approximation of f(x) is sufficient
• Program can be randomized
Computer Program
ExamplesMean
Parity

27
Models for computing over large data sets
Random sampling Data Streams Sketching

28
Query a few data items
Random sampling
Data
(n is very large)
Computer Program
Examples
Mean
O(1) queries
Parity
n queries
Approximation of

29
Random sampling
AdvantagesUltra-efficient
Sub-linear running time & space (could even be independent of data set size)
DisadvantagesMay require random accessDoesn’t fit many problemsHard to sample from disorganized data sets
30
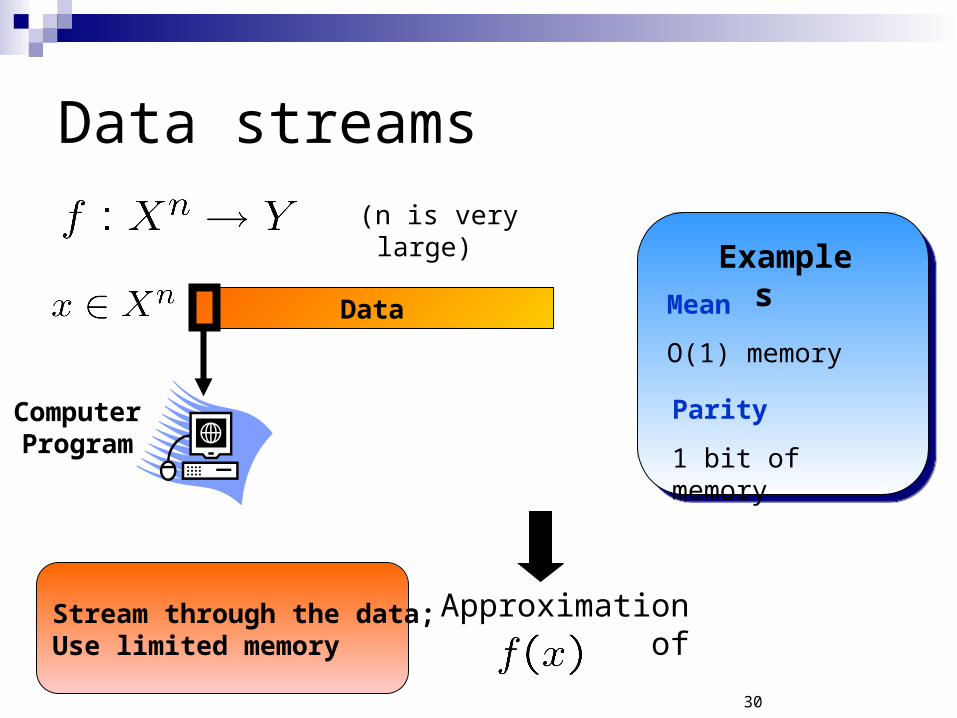
Data streams
Data
(n is very large)
Computer Program
Stream through the data;Use limited memory
Examples
Mean
O(1) memory
Parity
1 bit of memory
Approximation of

31
Data streams
AdvantagesSequential accessLimited memory
DisadvantagesRunning time is at least linearToo restricted for some problems

32
Sketching
Data1
(n is very large)
Data2Data1 Data2Sketch2Sketch1
Compress eachdata segment intoa small “sketch”
Compute overthe sketches
Examples
Equality
O(1) size sketch
Hamming distance
O(1) size sketch
Lp distance (p > 2)
n1-2/p) size sketch
Approximation of

33
Sketching
AdvantagesAppropriate for distributed data setsUseful for “dimension reduction”
DisadvantagesToo restricted for some problemsUsually, at least linear running time
34
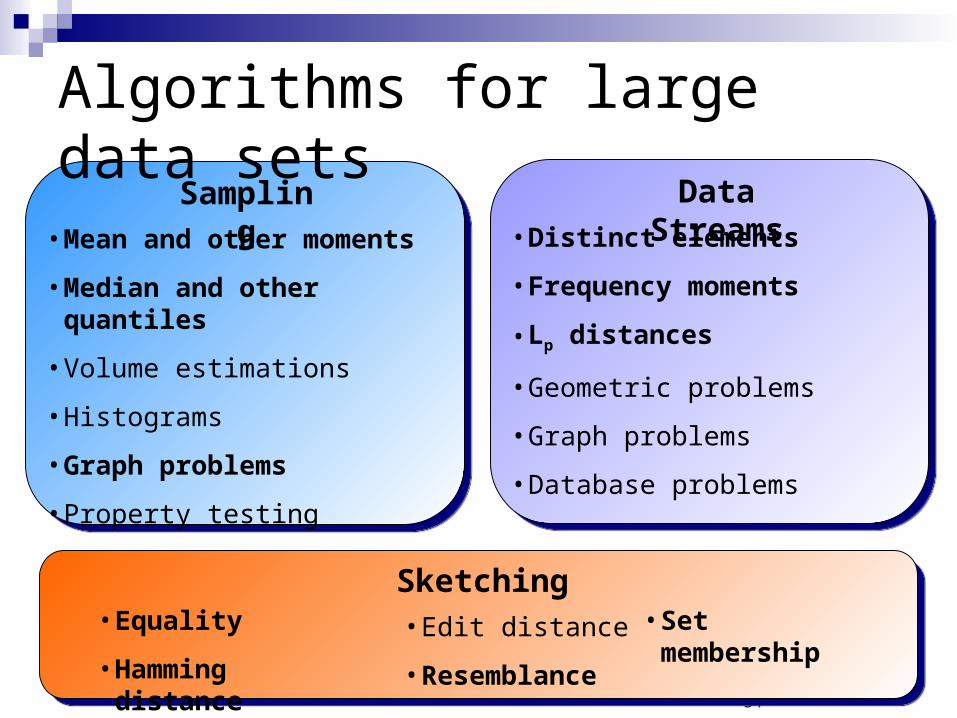
Algorithms for large data sets
• Mean and other moments
• Median and other quantiles
• Volume estimations
• Histograms
• Graph problems
• Property testing
Sampling• Distinct elements
• Frequency moments
• Lp distances
• Geometric problems
• Graph problems
• Database problems
Data Streams
• Equality
• Hamming distance
Sketching• Edit distance
• Resemblance
• Set membership

35
WebHistory and
Architecture of Search Engines

36
A brief history of the Internet 1961: First paper on packet switching (Kleinrock, MIT) 1966: ARPANET (first design of a wide area computer network) 1969: First packet sent from UCLA to SRI. 1971: First E-mail (Ray Tomlinson) 1974: Transmission Control Protocol (TCP) (Vint Cerf & Bob Kahn) 1978: TCP splits into TCP and IP (Internet Protocol) 1979: USENET (newsgroups) 1984: Domain Name System (DNS) 1988: First Internet worm 1990: The World-Wide Web (Tim Berners-Lee, CERN)

37
A brief history of the Web
1945: Hypertext (Vannevar Bush) 1980: Enquire (First hypertext browser) 1990: WorldWideWeb )First web browser) 1991: HTML and HTTP 1993: Mosaic (Mark Andressen) 1994: First WWW conference 1994: W3C 1994: Lycos (First commercial search engine) 1994: Yahoo! (First web directory, Jerry Yang and David
Filo) 1995: AltaVista (DEC) 1997: Google (First link-based search engine, Sergey
Brin and Larry Page)

38
End of Lecture 1

39
Basic terminology
Hypertext: document connected to other documents by links.
World-Wide Web: corpus of billions of hypertext documents (“pages”) that are stored on computers connected to the Internet. Documents are written in HTML Documents can be viewed using Web browsers

40
Information Retrieval (IR)
Information Retrieval System: a system that allows a user to retrieve documents that match her “information need” from a large corpus. Example: Get documents about Java, except for ones
that are about the Java coffee.
Data Retrieval System: a system that allows a user to retrieve all documents that match her query from a large corpus. Example: Get all documents containing the term
“Java” but not containing the term “coffee”.

41
Information Retrieval vs. Data Retrieval
Information RetrievalData Retrieval
DataFree text, unstructuredDatabase tables, structured
QueriesKeywords, free textSQL, relational algebras
ResultsApproximate matchesExact matches
ResultsOrdered by relevanceUnordered
AccessibilityNon-expert humansKnowledgeable users or automatic processes
42
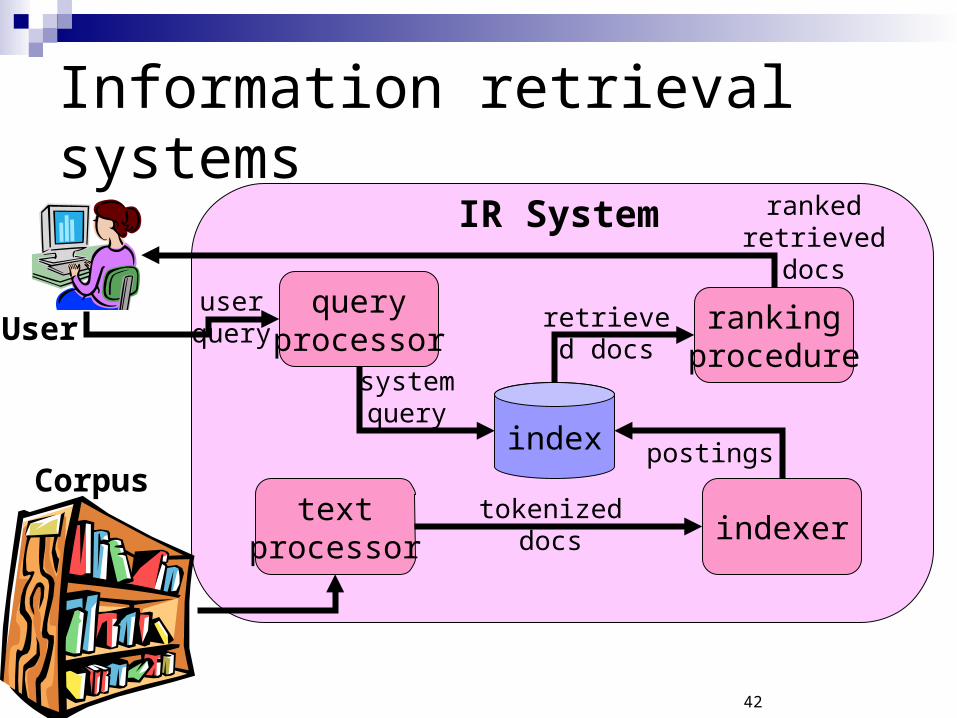
Information retrieval systems
IR System
queryprocessor
textprocessor
user query
ranked retrieved
docs
User
Corpus
rankingprocedure
system query
retrieved docs
index
indexertokenized
docs
postings

43
Search enginesSearch Engine
queryprocessor
textprocessor
user query
ranked retrieved
docs
User
Web
rankingprocedure
system query
retrieved docs
index
indexertokenized
docs
postings
crawlerglobal
analyzerrepository
44
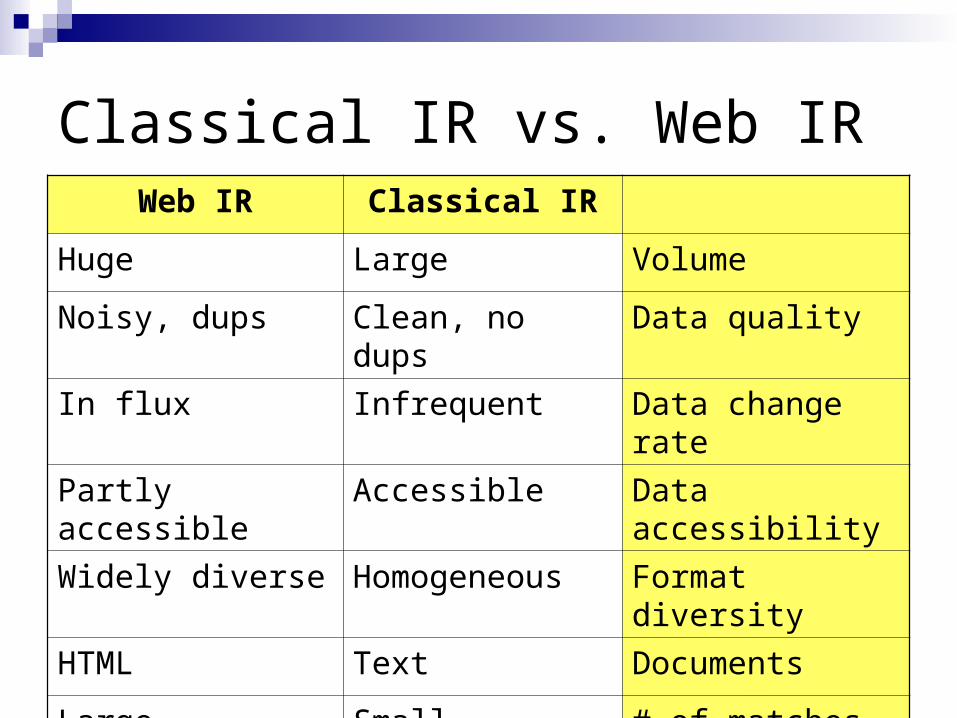
Classical IR vs. Web IRClassical IRWeb IR
VolumeLargeHuge
Data qualityClean, no dupsNoisy, dups
Data change rateInfrequentIn flux
Data accessibilityAccessiblePartly accessible
Format diversityHomogeneousWidely diverse
DocumentsTextHTML
# of matchesSmallLarge
IR techniquesContent-basedLink-based





























