Embed Size (px)
Citation preview

1
A Finite-State Approach to Machine Translation
Srinivas Bangalore Giuseppe Riccardi
AT&T Labs-Research
{srini,dsp3}@research.att.com
NAACL 2001, Pittsburgh, June 6, 2001

2
Overview
• Motivation• Stochastic Finite State Machines• Learning Machine Translation Models• Case study
– MT for Human-Machine Spoken Dialog
• Experiments and Results

3
Motivation• Finite State Transducers (FST)
– Unified formalism to represent symbolic transductions– Calculus for combining FSTs
• Learnability– Automatically train transductions from (parallel) corpora
• Speech-to-Speech Machine Translation chain– Combining speech and language constraints
• Previous Approaches to FST-MT: Knight and Al-Onaizan 1998, Vilar et.al. 1999, Ney 2000, Nederhof 2001

4
Stochastic Machine Translation
• Noisy-channel paradigm (IBM)
• Stochastic Finite State Transducer Model
)()|(maxargˆTTS
WT WPWWPW
T
Problem Reordering Lexical )|(maxargˆ
Problem Choice Lexical ),(maxargˆ
)ˆ(TT
WRWT
TSW
ST
WPW
WWPW
STT
T
MT SW TW

5
Pairing and Aligning• Input: Source-Target language sentence pairs• Sentence Alignment (Alshawi, Bangalore and Douglas,
1998)
• Output: – Alignment between source-target substrings– Dependency trees for source and target strings
Spanish : ajá quiero usar mi tarjeta de crédito
English : yeah I wanna use my credit card

6
Learning SFST from Bi-language
• Bi-language: each token consists of a source language word with its target language word.
• Ordering of tokens: source language order or target language order
• ajá quiero usar mi tarjeta de crédito• yeah I wanna use my credit card
• (ajá,yeah) (I) (quiero,wanna) (usar,use) (mi,my) (tarjeta,card) (de,
(crédito,credit)
SW
TW
)W,F(W TS

7
Learning Bilingual Phrases• Effective translation of text chunks (e.g.
collocations)• Learn bilingual phrases
– Joint entropy minimization on bi-language corpus
• Phrase-segmented bi-language corpus– (ajá,yeah) (quiero,I wanna) (usar,use) (mi,my) (tarjeta de crédito, card credit)
• Local Reordering of phrases tarjeta de crédito
card credit credit card
Lexical Choice
LocalReordering

8
Local Reordering• Locally reordered phrase=min(S TLM)
S is the “sausage” FSM
TLM is an n-gram target language model– “credit card” is the more likely phrase

9
Lexical Choice Model• Train variable N-gram language model (Riccardi
1995) on bi-language corpus.– simple N-gram models– phrase-based N-gram models

10
Lexical Reordering• Output of the lexical choice transducer:
sequence of target language phrases.– I’d this to my home phone to charge like
• Words in phrases are in target language word order.
• However, phrases need to be reordered in target language word order.
• Reordered: – I'd like to charge this to my home phone

11
Lexical Reordering Models• Alignment of JEnglish-English sentence
pairs.JEnglish: I’d this to my home phone to charge
like
English: I’d like to charge this to my home phone
I’d
this
like
charge
home
my phone
to to
I’d
this
like
charge
home
my phone
toto

12
Lexical Reordering Models (contd)
• Dependency tree represented as a bracketed string with reordering instructions.
….. :[ :[ to:to :] :-1 charge:charge :] :+1 like:like
• Train variable N-gram language model on the bracketed corpus
• Output of FST: strings with reordering instructions.[ [ to ] -1 charge ] +1 like

13
Lexical Reordering Models (contd)
• Instructions are composed with “interpreter” FST to form target language sentence.
• Finite-state approximation:– Well-formedness of brackets checked for a
bounded depth with a weighted FSM– Weights are estimated from the bracketed
training corpus
• Alternate approach: Approximation of a CFG (Nederhof 2001)

14
ASR-based Speech Translation
Alignment
Lexical Choice
Phrase Learning
Lexical Reordering
)W,F(W TS
)W,(W TS
a
b
Acoustic Model Training
)Speech,(WS
Lexicon FSM
)(Lexicon
A
L
c Speech Recognizerc b a L A

15
MT Evaluation
• Application-independent evaluation– Translation Accuracy – Based on string alignment
• Application-driven evaluation– “How May I Help You?”– Spoken dialog for call routing (14 call
types)– Classification based on salient phrase
detection

16
Examples
• Yes I like to make this long distance call area code x x x x x x x x x x
• Yeah I need the area code for rockmart georgia
• Yeah I’m wondering if you could place this call for me I can’t seem to dial it it don’t seem to want to go through for me

17
Evaluation Metric• Evaluation metric for MT is a complex issue.• String edit distance between reference string
and result string (length in words: R)– Insertions (I)– Deletions (D)– Moves = pairs of Deletions and Insertions (M)– Remaining Insertions (I') and Deletions (D')
• Translation Accuracy = 1 – (M + I' + D' + S) / R

18
Experiments and Evaluation
• Data Collection: – The customer side of operator-customer
conversations transcribed– Transcriptions were then manually
translated into Japanese• Training Set: 12226 English-Japanese
sentence pairs• Test Set: 3253 sentences.• Different translation models
– Word n-gram and Phrase n-gram

19
Translation Accuracy(English-Japanese on Text)
• After reordering is better than before reordering• Phrase n-grams better than simple n-grams
00.10.20.30.40.50.60.70.8
1gra
m
2gra
m
3gra
m
1phr
gram
2phr
gram
3phr
gram
before reordering
after reordering

20
Translation Accuracy(English-Japanese on Text and Speech)
• Speech recognition accuracy 60%• Drop of about 10% between text translation and
speech translation
00.10.20.30.40.50.60.70.8
1gra
m
2gra
m
3gra
m
1phr
gram
2phr
gram
3phr
gram
Text
Speech

22
Call-Classification Performance
• False Rejection Rate: Probability of rejecting a call, given that the call-type is one of the 14 call-types.
• Probability Correct: Probability of correctly classifying a call, given that the call is not rejected.

23
MT evaluation on HMIHYClassification accuracy on original English text and Japanese-English translated text.
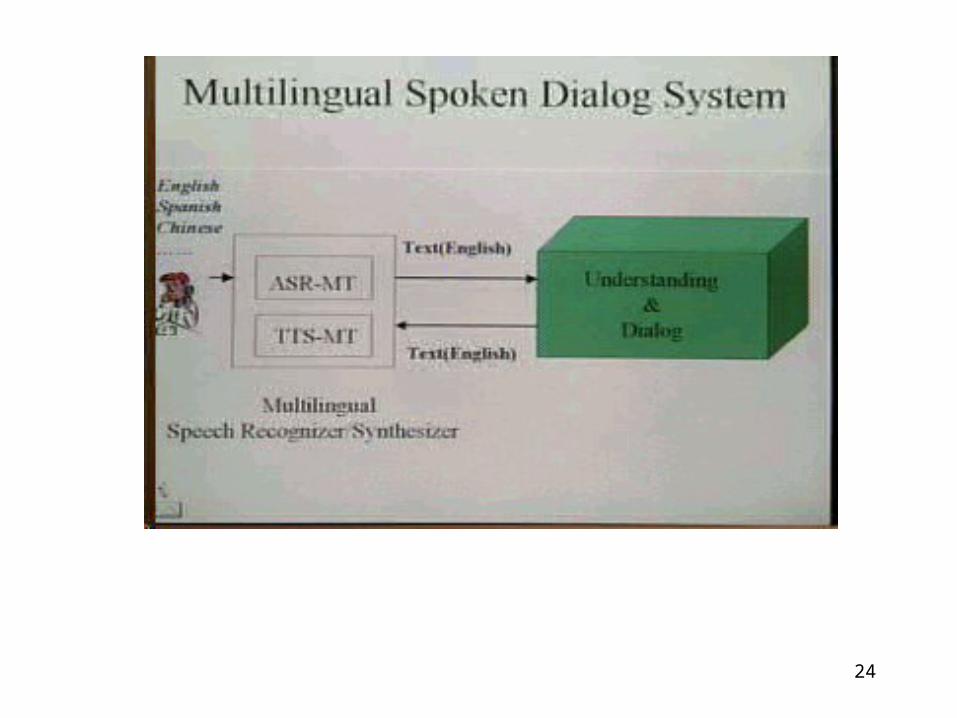
24
DEMO

25
Conclusion• Stochastic Finite State based approach is
viable and effective for limited domain MT.
• Finite-state model chain allows integration of speech and language constraints.
• Multilingual speech application enabled by MThttp://www.research.att.com/~srini/Projects/Anuvaad/home.html

26
Translation using stochastic FSTs• Sequence of finite-state transductions
Japanese: 私は これを 私の 家の 電話に チャージ したいのですJEnglish: I’d this to my home phone to charge
like
English: I’d like to charge this to my home phone
I’d
this
like
charge
home
my phone
to to
I’d
this
like
charge
home
my phone
toto
27
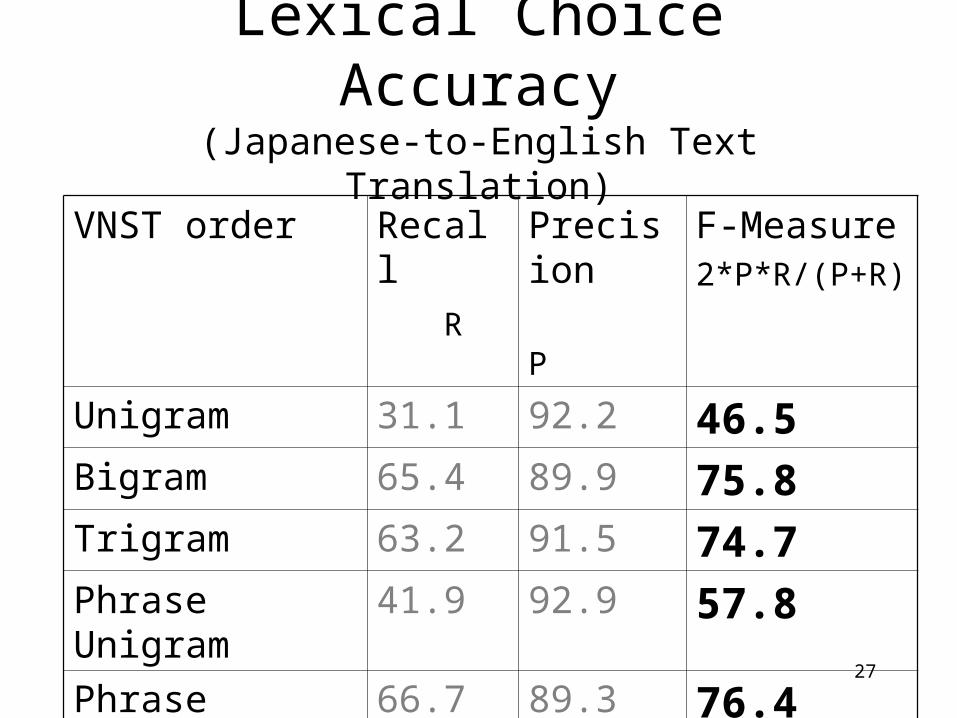
Lexical Choice Accuracy(Japanese-to-English Text Translation)
VNST order Recall R
Precision P
F-Measure2*P*R/(P+R)
Unigram 31.1 92.2 46.5Bigram 65.4 89.9 75.8Trigram 63.2 91.5 74.7Phrase Unigram
41.9 92.9 57.8
Phrase Bigram 66.7 89.3 76.4Phrase Trigram
65.3 89.9 75.7
28
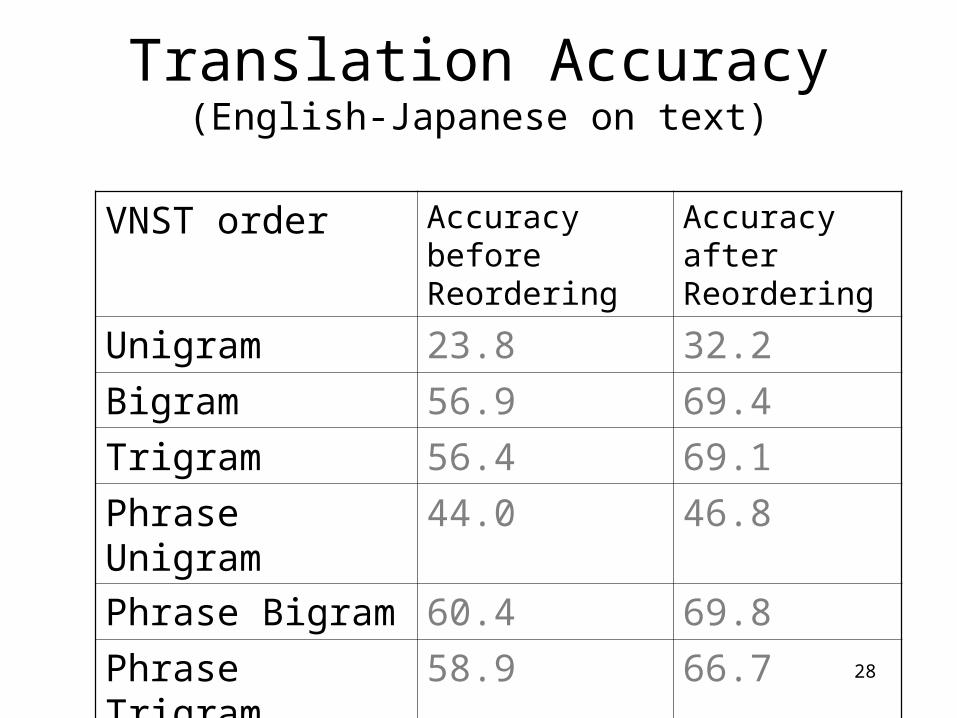
Translation Accuracy(English-Japanese on text)
VNST order Accuracy before Reordering
Accuracy after Reordering
Unigram 23.8 32.2
Bigram 56.9 69.4
Trigram 56.4 69.1
Phrase Unigram 44.0 46.8
Phrase Bigram 60.4 69.8
Phrase Trigram 58.9 66.7
29
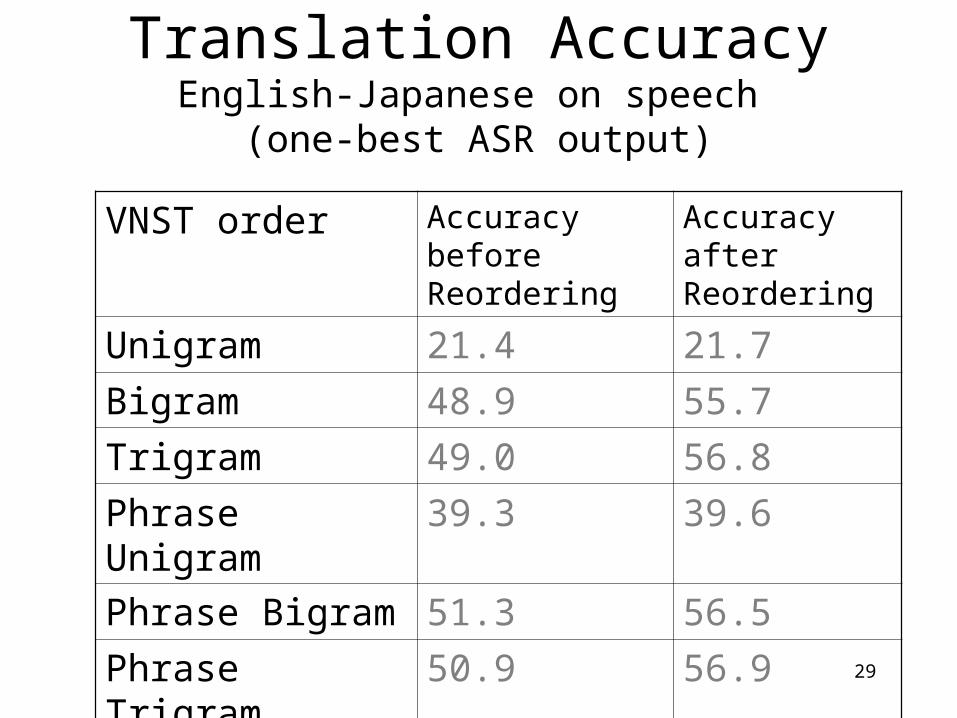
Translation AccuracyEnglish-Japanese on speech
(one-best ASR output)
VNST order Accuracy before Reordering
Accuracy after Reordering
Unigram 21.4 21.7
Bigram 48.9 55.7
Trigram 49.0 56.8
Phrase Unigram 39.3 39.6
Phrase Bigram 51.3 56.5
Phrase Trigram 50.9 56.9

30
Biblio-J. Berstel “Transductions and Context Free Languages” Teubner Studienbüchner-G. Riccardi, R. Pieraccini and E. Bocchieri, "Stochastic Automata for Language Modeling", Computer Speech and Language, 10, pp. 265-293, 1996.-Fernando C. N. Pereira and Michael Riley. Speech Recognition by Composition of Weighted Finite Automata . Finite-State Language Processing. MIT Press, Cambridge, Massachusetts. 1997-S. Bangalore and G. Riccardi, "Stochastic Finite-State Models for Spoken Language Machine Translation", Workshop on Embedded Machine Translation Systems, NAACL, pp. 52-59, Seattle, May 2000.
More references on http://www.research.att.com/info/dsp3
http://research.att.com/info/dsp3





























