Embed Size (px)
Citation preview

1
9/28/2009
Network Applications and Network Programming:
Web and P2P

Admin.
Submit programming assignment 0 using class server if you want, you can also send email
attachment to TA
2

Recap: FTP, HTTP
FTP: file transfer ASCII (human-readable
format) requests and responses stateful server one data channel and one control channel
HTTP Extensibility: ASCII requests, header lines,
entity body, and responses line Scalability/robustness
• stateless server (each request should contain the full information); DNS load balancing
• Client caching Web caches one data channel
3

Recap: WebServer Flow
TCP socket space
state: listeningaddress: {*.6789, *.*}completed connection queue: sendbuf:recvbuf:
128.36.232.5128.36.230.2
state: listeningaddress: {*.25, *.*}completed connection queue:sendbuf:recvbuf:
state: establishedaddress: {128.36.232.5:6789, 198.69.10.10.1500}sendbuf:recvbuf:
connSocket = accept()
Create ServerSocket(6789)
read request from connSocket
read local file
write file to connSocket
close connSocket

Recap: Writing High Performance Servers:
Major Issues: Many socket/IO operations can cause processing to block, e.g., accept: waiting for new connection; read a socket waiting for data or close; write a socket waiting for buffer space; I/O read/write for disk to finish
Thus a crucial perspective of network server design is the concurrency design (non-blocking) for high performance to avoid denial of service
A technique to avoidblocking: Thread
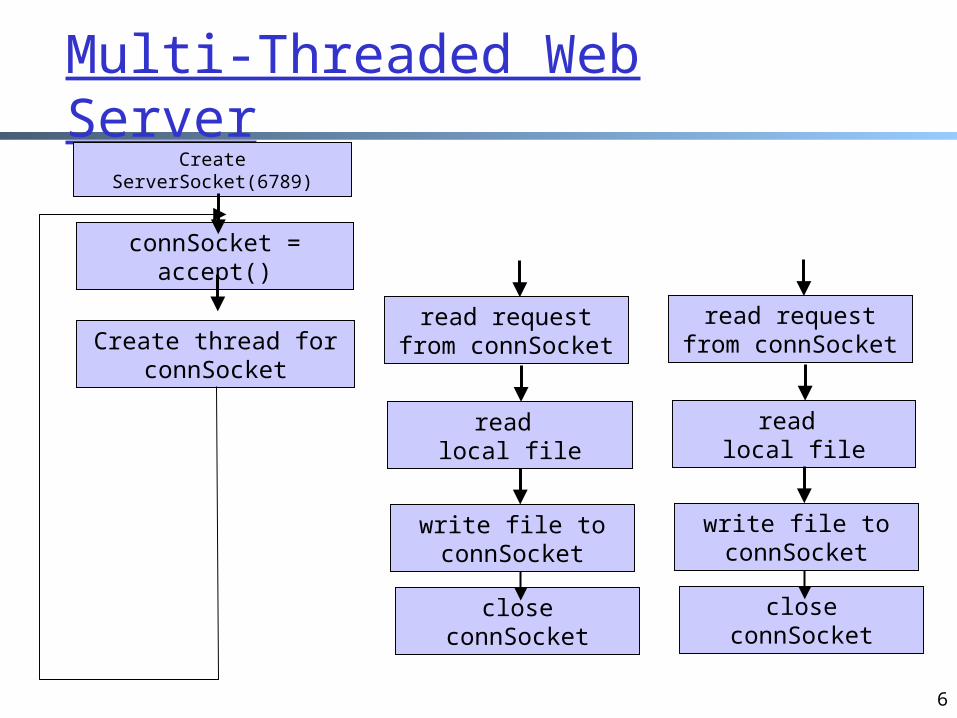
Multi-Threaded Web Server
6
connSocket = accept()
Create ServerSocket(6789)
Create thread for connSocket
read request from connSocket
read local file
write file to connSocket
close connSocket
read request from connSocket
read local file
write file to connSocket
close connSocket
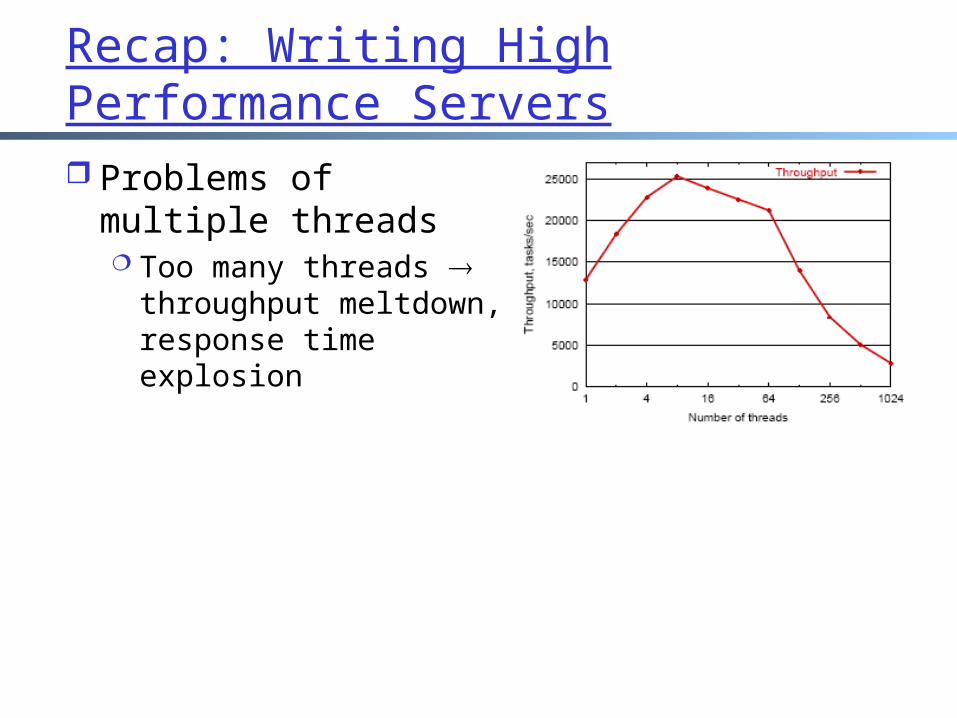
Recap: Writing High Performance Servers Problems of multiple
threads Too many threads
throughput meltdown, response time explosion

Event-Driven Programming
Event-driven programming, also called asynchronous i/o Tell the OS to not block when accepting/reading/writing on sockets Java: asynchronous i/o
for an example see: http://www.cafeaulait.org/books/jnp3/examples/12/
Yields efficient and scalable concurrency Many examples: Click router, Flash web server, TP Monitors, etc.
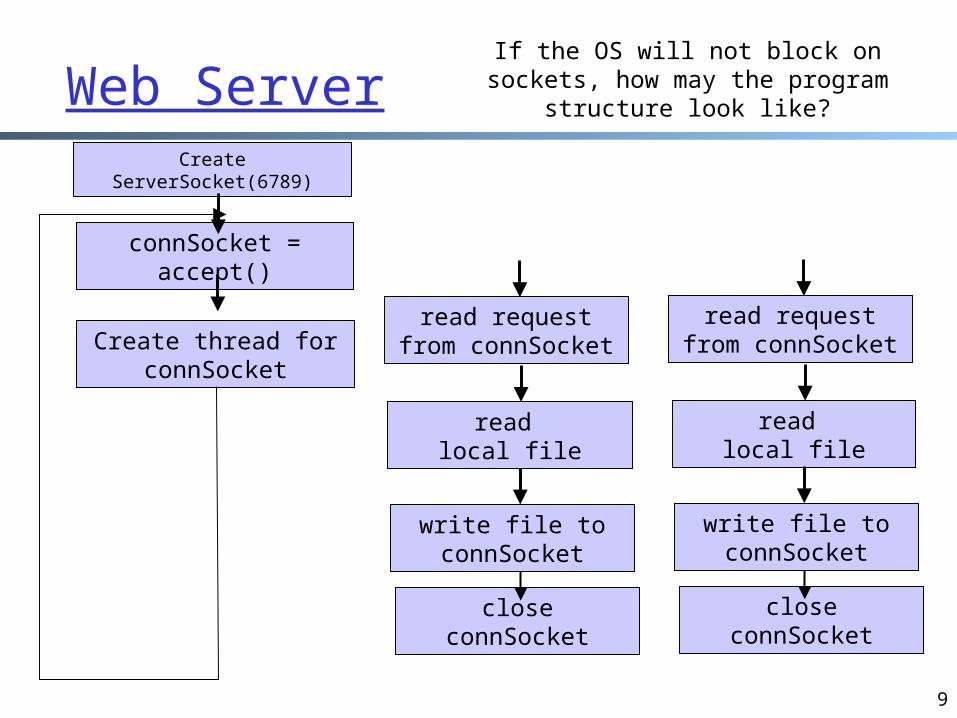
Web Server
9
connSocket = accept()
Create ServerSocket(6789)
Create thread for connSocket
read request from connSocket
read local file
write file to connSocket
close connSocket
read request from connSocket
read local file
write file to connSocket
close connSocket
If the OS will not block on sockets, how may the program structure look
like?

Typical Structure of Async i/o
Typically, async i/o programs use Finite State Machines (FSM) to monitor the progress of requests The state info keeps track of the execution
stage of processing each request, e.g., reading request, writing reply, …
The program has a loop to check potential events at each state
10

Async I/O in Java
An important class is the class Selector, to support event loop
A Selector is a multiplexer of selectable channel objects example channels: DatagramChannel, ServerSocketChannel, SocketChannel
use configureBlocking(false) to make a channel non-blocking
A selector may be created by invoking the open method of this class
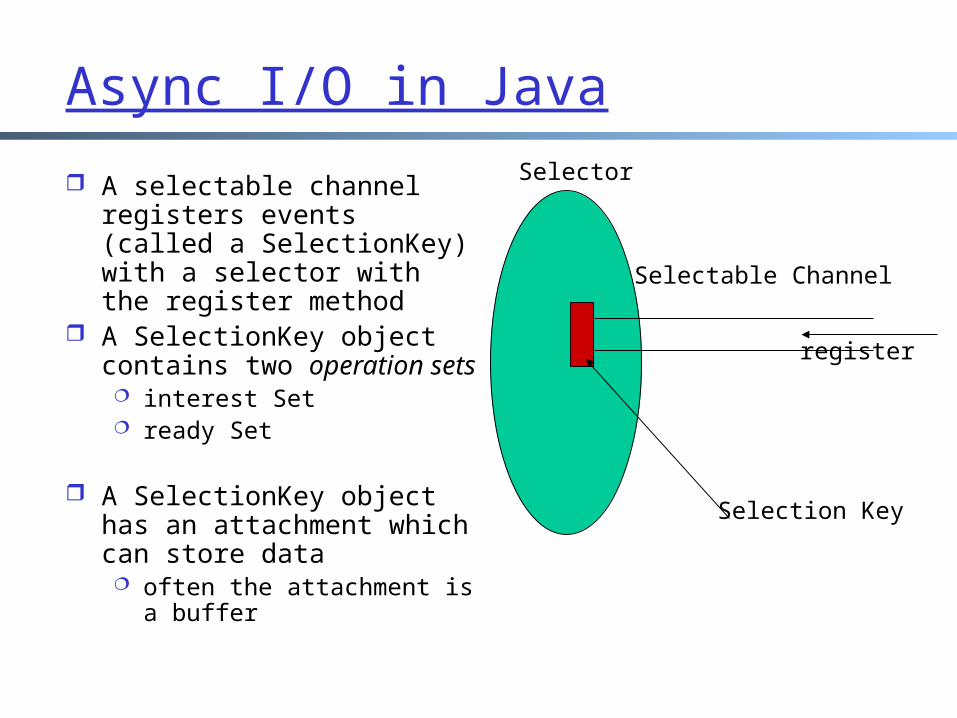
Async I/O in Java
A selectable channel registers events (called a SelectionKey) with a selector with the register method
A SelectionKey object contains two operation sets interest Set ready Set
A SelectionKey object has an attachment which can store data often the attachment is a
buffer
Selector
Selection Key
Selectable Channel
register

Async I/O in Java
Call select (or selectNow(), or select(int timeout)) to check for ready events, called the selected key set
Iterate over the set to process all ready events

Problems of Event-Driven Server
Difficult to engineer, modularize, and tune
No performance/failure isolation between Finite-State-Machines (FSMs)
FSM code can never block (but page faults, i/o, garbage collection may still force a block) thus still need multiple threads
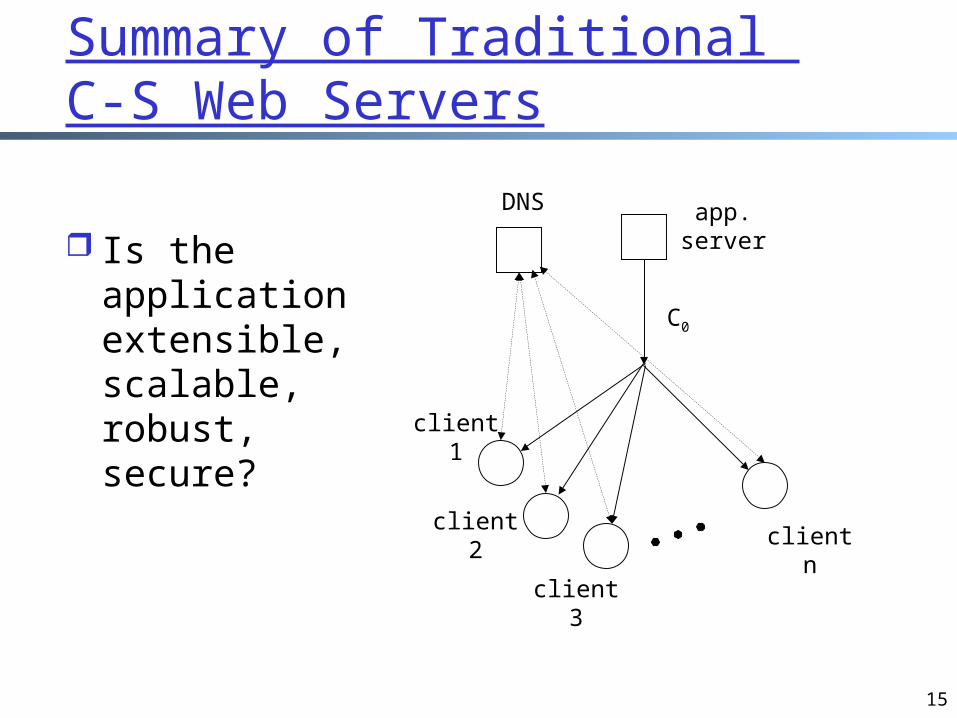
Summary of Traditional C-S Web Servers
Is the application extensible, scalable, robust, secure?
15
app. server
C0
client 1
client 2
client 3
client n
DNS

Content Distribution History...
“With 25 years of Internet experience, we’ve learned exactly one way to deal with the exponential growth: Caching”.
(1997, Van Jacobson)
16
17
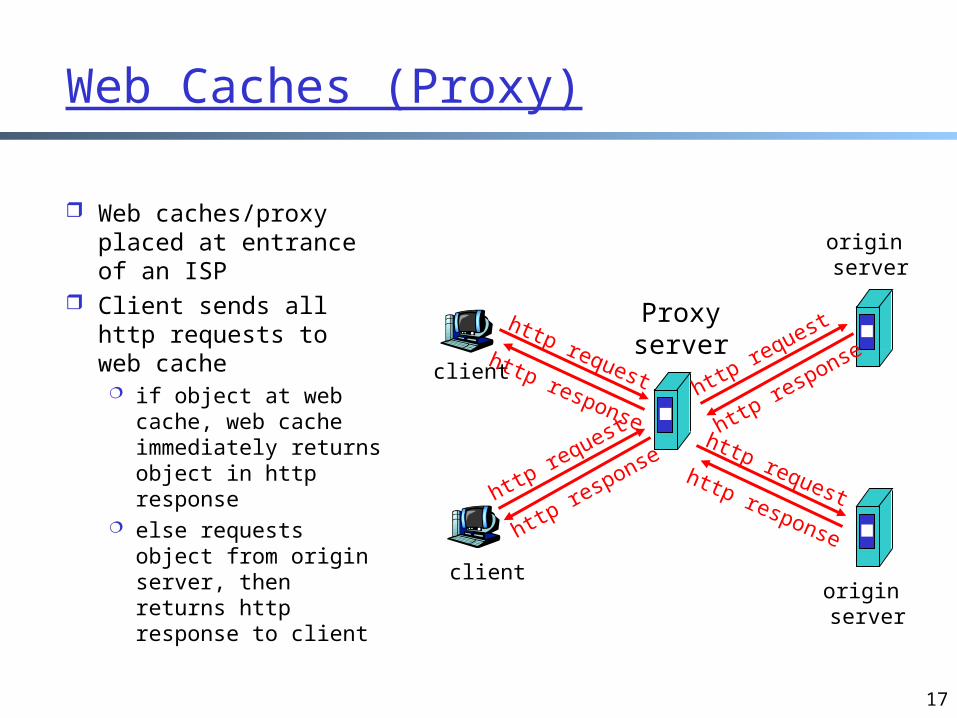
Web Caches (Proxy)
Web caches/proxy placed at entrance of an ISP
Client sends all http requests to web cache if object at web
cache, web cache immediately returns object in http response
else requests object from origin server, then returns http response to client
client
Proxyserver
client
http request
http re
quest
http response
http re
sponse
http re
quest
http re
sponse
http requesthttp response
origin server
origin server
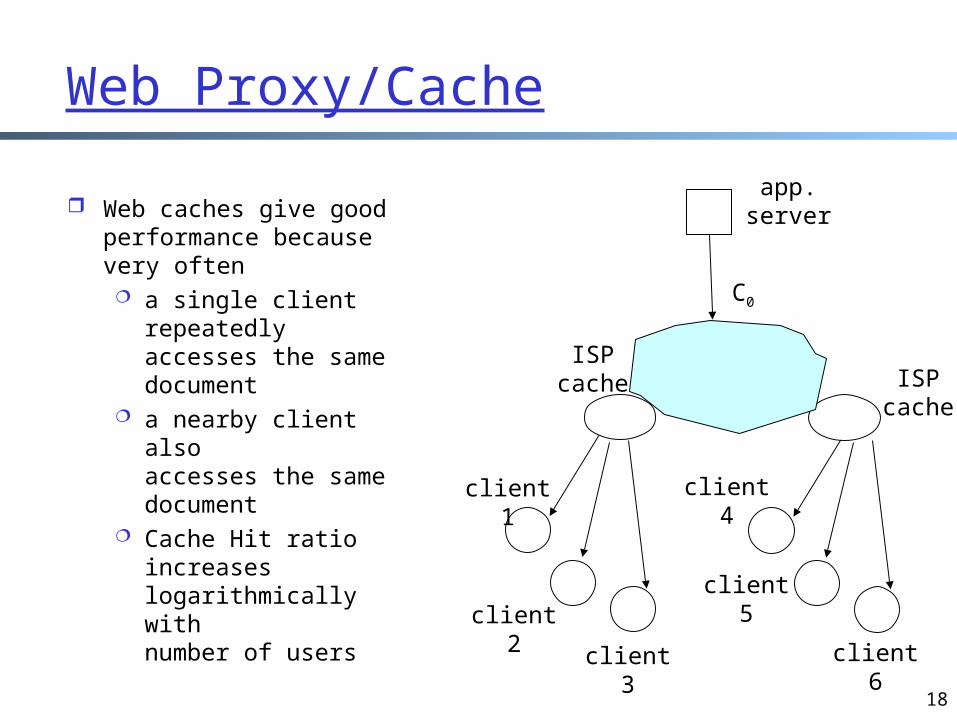
Web Proxy/Cache
Web caches give good performance because very often a single client
repeatedly accesses the same document
a nearby client also accesses the same document
Cache Hit ratio increases logarithmically with number of users
18
app. server
C0
client 1
client 2 client
3
ISP cache
client 4
client 5
client 6
ISP cache
19
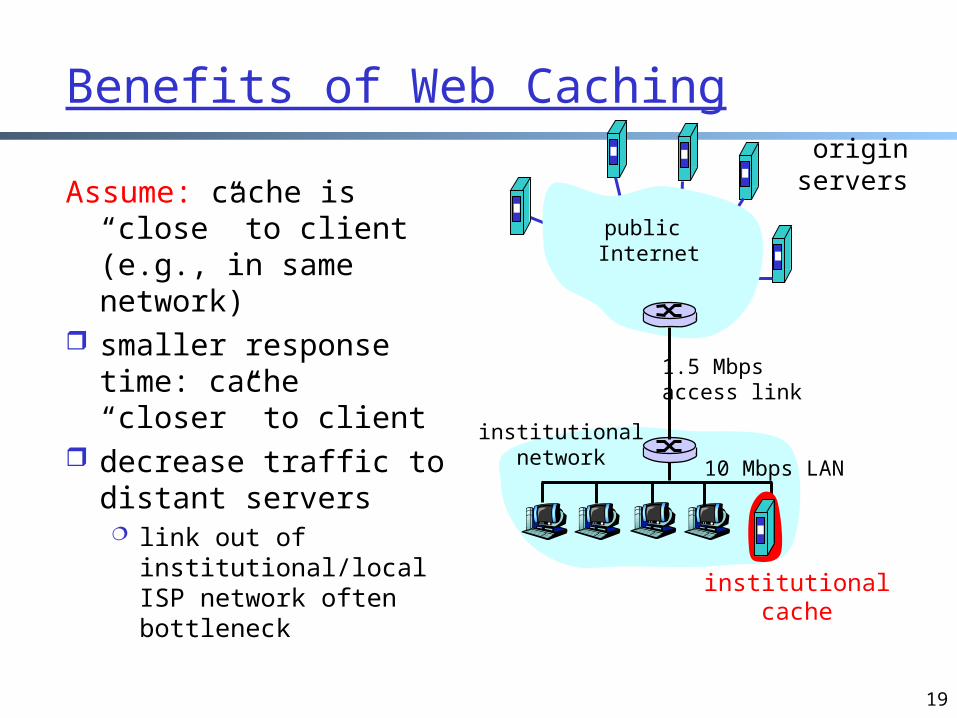
Benefits of Web Caching
Assume: cache is “close” to client (e.g., in same network)
smaller response time: cache “closer” to client
decrease traffic to distant servers link out of
institutional/local ISP network often bottleneck
originservers
public Internet
institutionalnetwork 10 Mbps LAN
1.5 Mbps access link
institutionalcache

What went wrong with Web Caches? Web protocols evolved extensively to
accommodate caching, e.g. HTTP 1.1 However, Web caching was developed with a
strong ISP perspective, leaving content providers out of the picture It is the ISP who places a cache and controls it ISPs only interest to use Web caches is to reduce
bandwidth
In the USA: Bandwidth relative cheap In Europe, there were many more Web caches
However, ISPs can arbitrarily tune Web caches to deliver stale content
20

Content Provider Perspective
Content providers care about User experience latency Content freshness Accurate access statistics Avoid flash crowds Minimize bandwidth usage in their access
link
21

Content Distribution Networks Content Distribution Networks (CDNs) build an
overlay networks of caches to provide fast, cost effective, and reliable content delivery, while working tightly with content providers.
Example: Akamai – original and largest commercial CDN
operates over 25,000 servers in over 1,000 networks
Akamai (AH kuh my) is Hawaiian for intelligent, clever and informally “cool”. Founded Apr 99, Boston MA by MIT students
22

Basic of Akamai Operation Content provider server
provides the base HTML document Akamai caches embedded objects at a set
of its cache servers (called edge servers) Akamaization of embedded content: e.g.,
<IMG SRC= http://www.provider.com/image.gif > changed to
<IMGSRC = http://a661. g.akamai.net/hash/image.gif>
Akamai customizes DNS to select serving edge servers based on closeness to client browser server load
23

More Akamai information
URL akamaization is becoming obsolete and only supported for legacy reasons Currently most content providers prefer to
use DNS CNAME techniques to get all their content served from the Akamai servers
still content providers need to run their origin servers
Akamai Evolution: Files/streaming Secure pages and whole pages Dynamic page assembly at the edge (ESI) Distributed applications
24
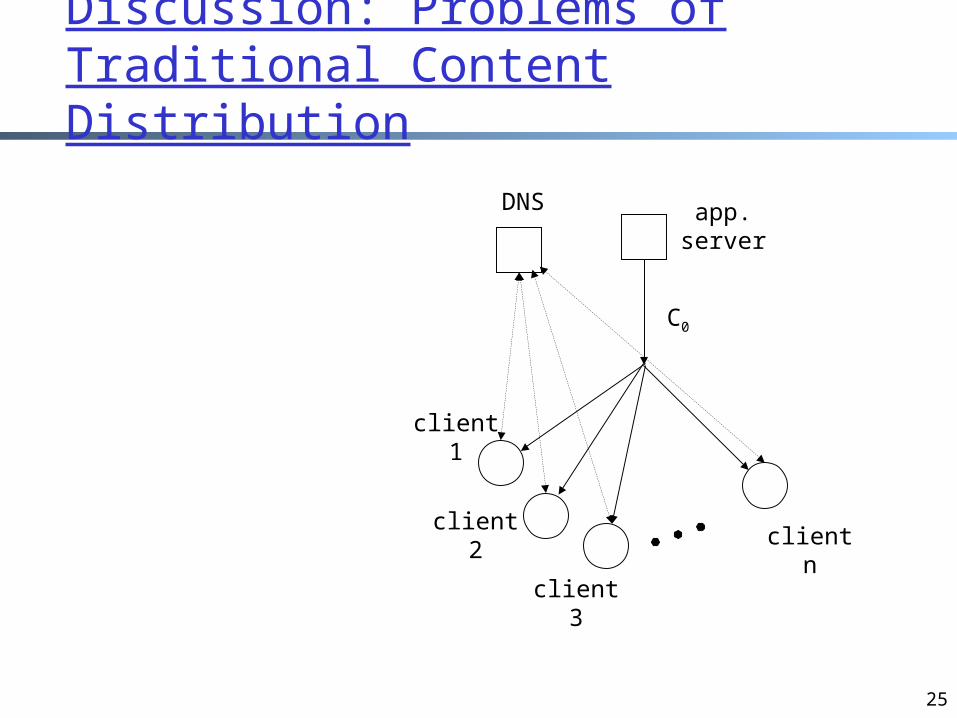
Discussion: Problems of Traditional Content Distribution
25
app. server
C0
client 1
client 2
client 3
client n
DNS
26
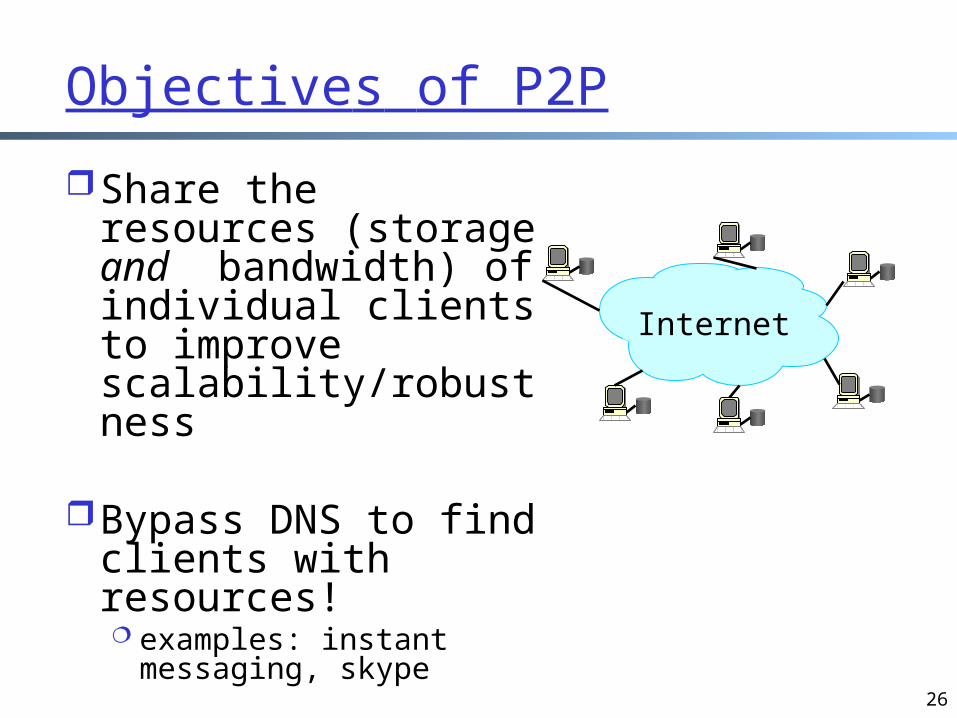
Objectives of P2P
Share the resources (storage and bandwidth) of individual clients to improve scalability/robustness
Bypass DNS to find clients with resources! examples: instant
messaging, skype
Internet

P2P
But P2P is not new
Original Internet was a p2p system: The original ARPANET connected UCLA,
Stanford Research Institute, UCSB, and Univ. of Utah
No DNS or routing infrastructure, just connected by phone lines
Computers also served as routers
P2P is simply an iteration of scalable distributed systems

P2P Systems
File Sharing: BitTorrent, LimeWireStreaming: PPLive, PPStream, Zatto,
…Research systems
Collaborative computing: SETI@Home project
• Human genome mapping• Intel NetBatch: 10,000 computers in 25
worldwide sites for simulations, saved about 500million
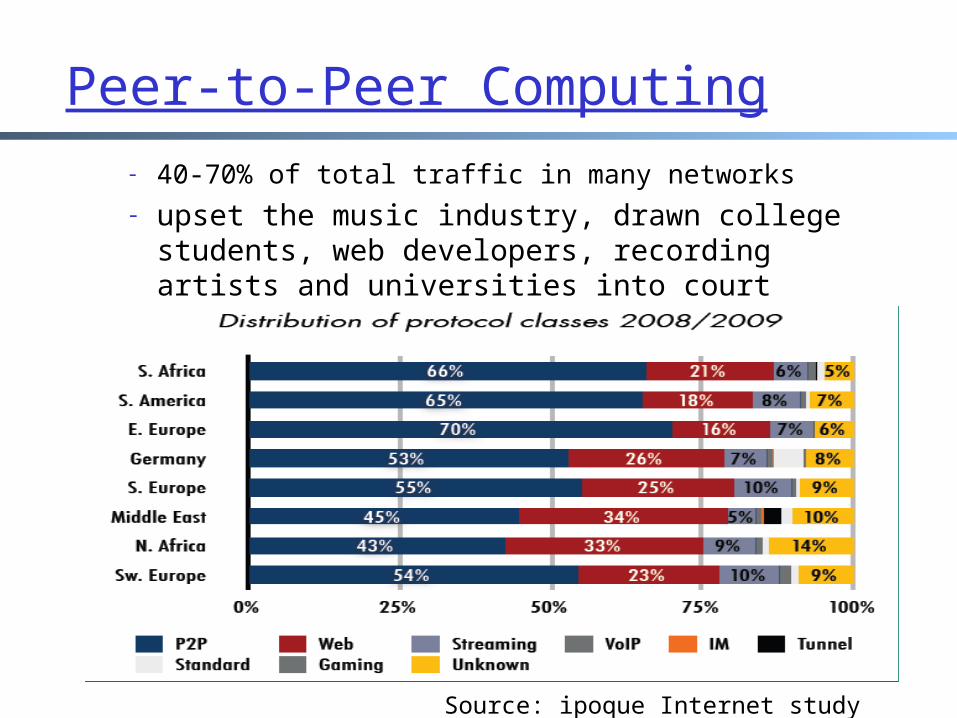
Peer-to-Peer Computing- 40-70% of total traffic in many networks- upset the music industry, drawn college
students, web developers, recording artists and universities into court
Source: ipoque Internet study 2008/2009
30
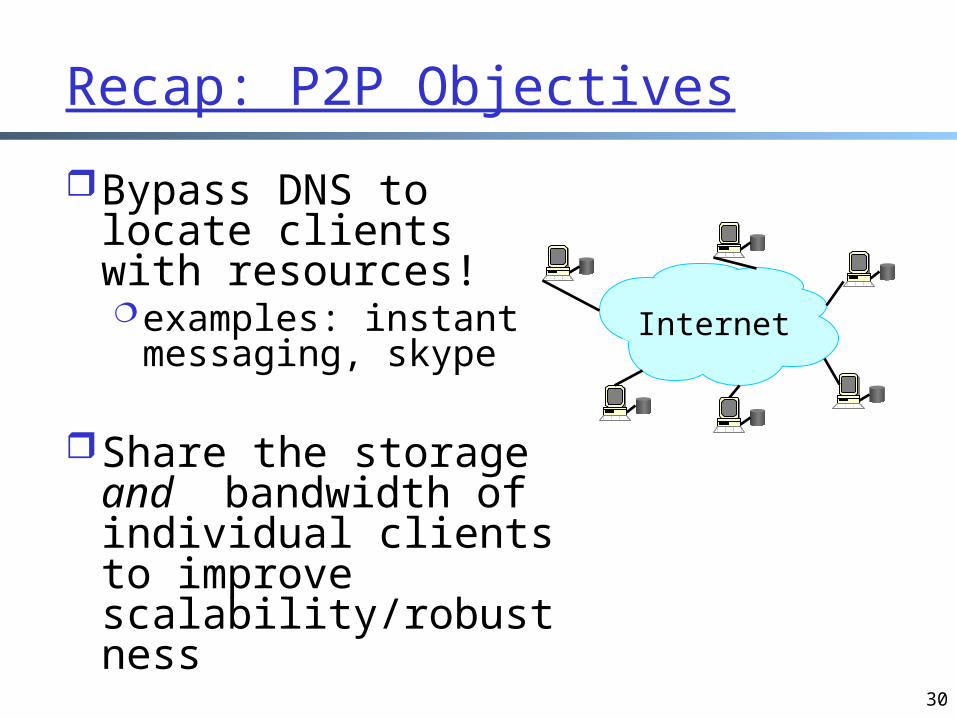
Recap: P2P Objectives
Bypass DNS to locate clients with resources!examples: instant
messaging, skype
Share the storage and bandwidth of individual clients to improve scalability/robustness
Internet
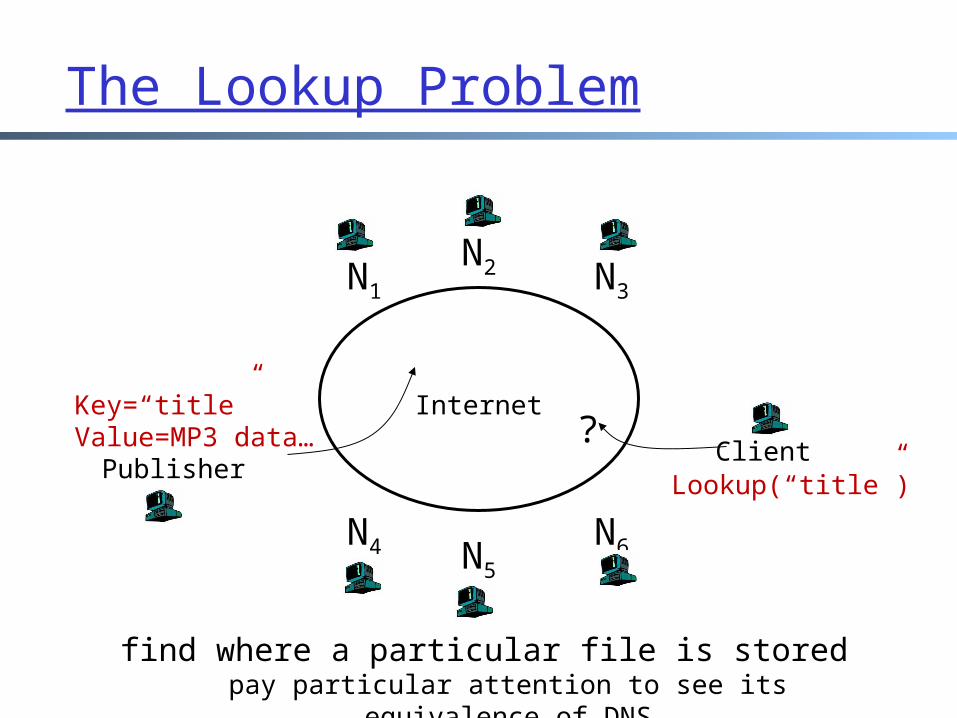
The Lookup Problem
Internet
N1
N2 N3
N6N5
N4
Publisher
Key=“title”Value=MP3 data… Client
Lookup(“title”)
?
find where a particular file is storedpay particular attention to see its equivalence of
DNS

32
Outline
RecapP2P
the lookup problem Napster
33
Centralized Database: Napster Program for sharing music over the Internet History:
5/99: Shawn Fanning (freshman, Northeasten U.) founded Napster Online music service, wrote the program in 60 hours
12/99: first lawsuit 3/00: 25% UWisc traffic Napster 2000: est. 60M users 2/01: US Circuit Court of
Appeals: Napster knew users violating copyright laws
7/01: # simultaneous online users:Napster 160K
9/02: bankruptcy
We are referring to the Napster before closure.03/2000
34
Napster: How Does it Work?
Application-level, client-server protocol over TCP
A centralized index system that maps files (songs) to machines that are alive and with files
Steps: Connect to Napster server Upload your list of files (push) to server Give server keywords to search the full list Select “best” of hosts with answers
35
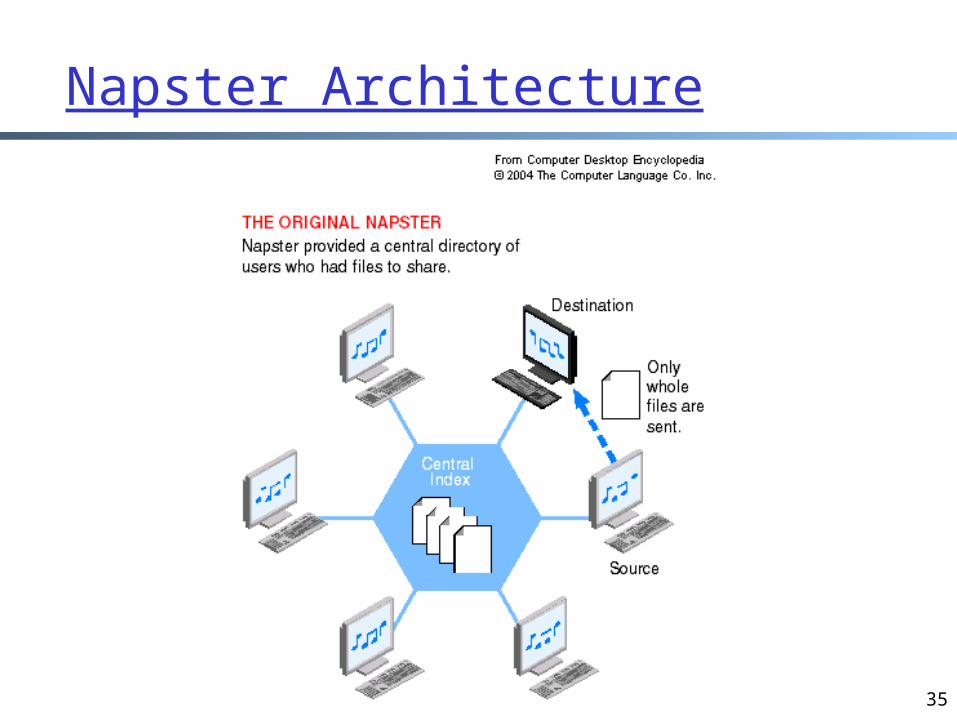
Napster Architecture
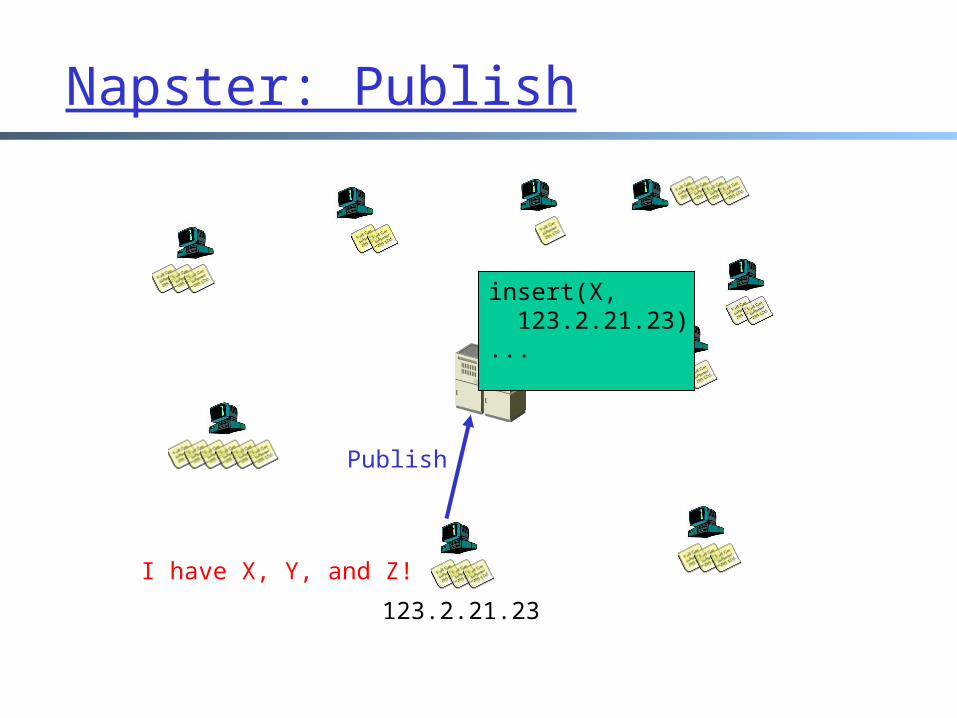
Napster: Publish
I have X, Y, and Z!
Publish
insert(X, 123.2.21.23)...
123.2.21.23
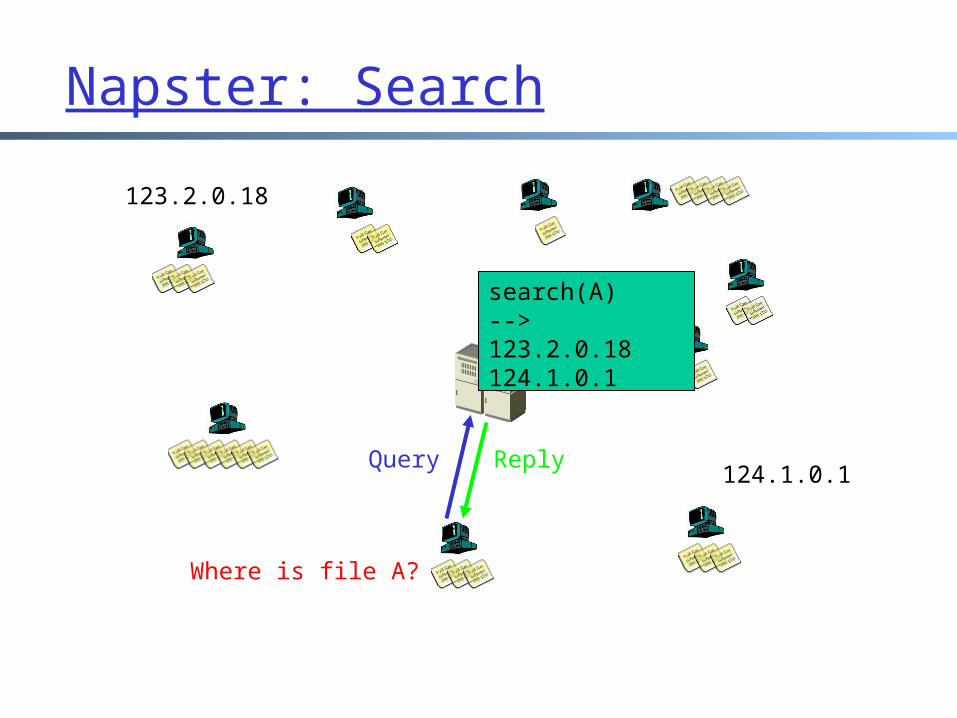
Napster: Search
Where is file A?
Query Reply
search(A)-->123.2.0.18124.1.0.1
123.2.0.18
124.1.0.1
Napster: Ping
ping
123.2.0.18
124.1.0.1ping
Napster: Fetch
123.2.0.18
124.1.0.1fetch
40
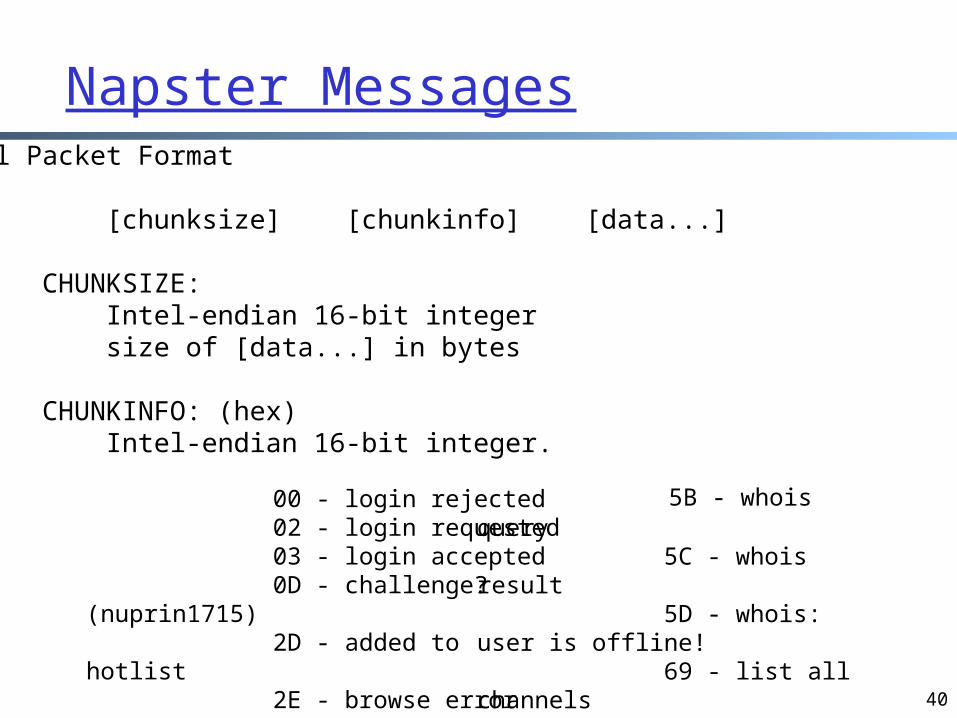
Napster MessagesGeneral Packet Format
[chunksize] [chunkinfo] [data...]
CHUNKSIZE: Intel-endian 16-bit integer size of [data...] in bytes
CHUNKINFO: (hex) Intel-endian 16-bit integer.
00 - login rejected 02 - login requested 03 - login accepted 0D - challenge? (nuprin1715) 2D - added to hotlist 2E - browse error (user isn't online!) 2F - user offline
5B - whois query 5C - whois result 5D - whois: user is offline! 69 - list all channels 6A - channel info 90 - join channel 91 - leave channel …..
41
Centralized Database: Napster Summary of features: a hybrid design
control: client-server (aka special DNS) for files data: peer to peer
Advantages simplicity, easy to implement sophisticated
search engines on top of the index system
Disadvantages application specific (compared with DNS) lack of robustness, scalability: central search
server single point of bottleneck/failure easy to sue !

42
Variation: BitTorrent
A global central index server is replaced by one tracker per file (called a swarm) reduces centralization; but needs other
means to locate trackers
The bandwidth scalability management technique is more interesting more later

43
Outline
Recap P2P
the lookup problem Napster (central query server; distributed
data servers) Gnutella

Gnutella
On March 14th 2000, J. Frankel and T. Pepper from AOL’s Nullsoft division (also the developers of the popular Winamp mp3 player) released Gnutella
Within hours, AOL pulled the plug on it
Quickly reverse-engineered and soon many other clients became available: Bearshare, Morpheus, LimeWire, etc.
44

45
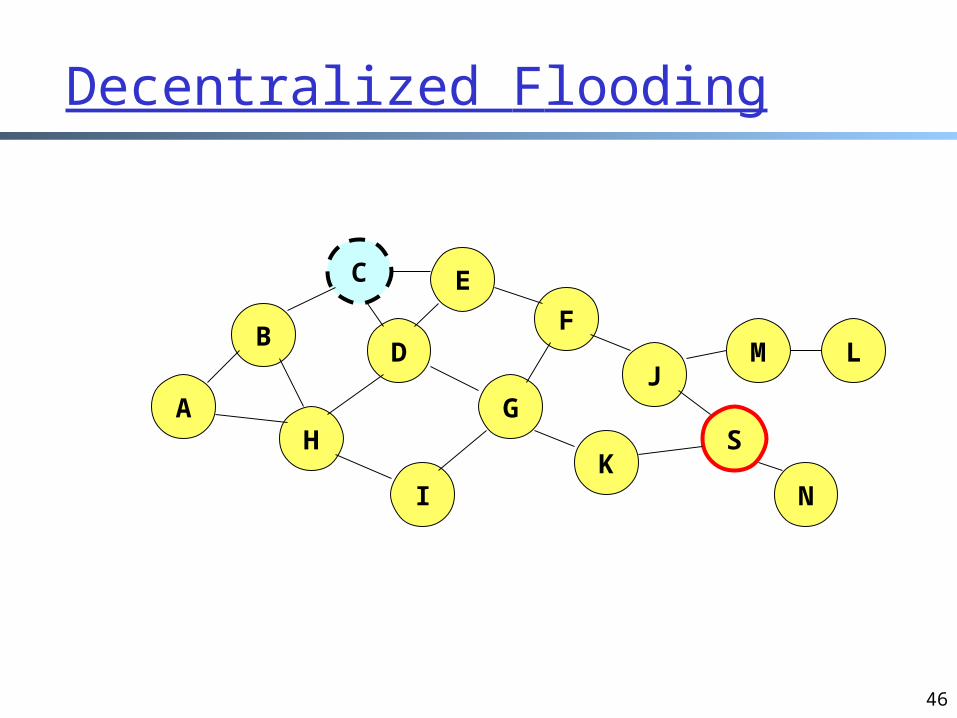
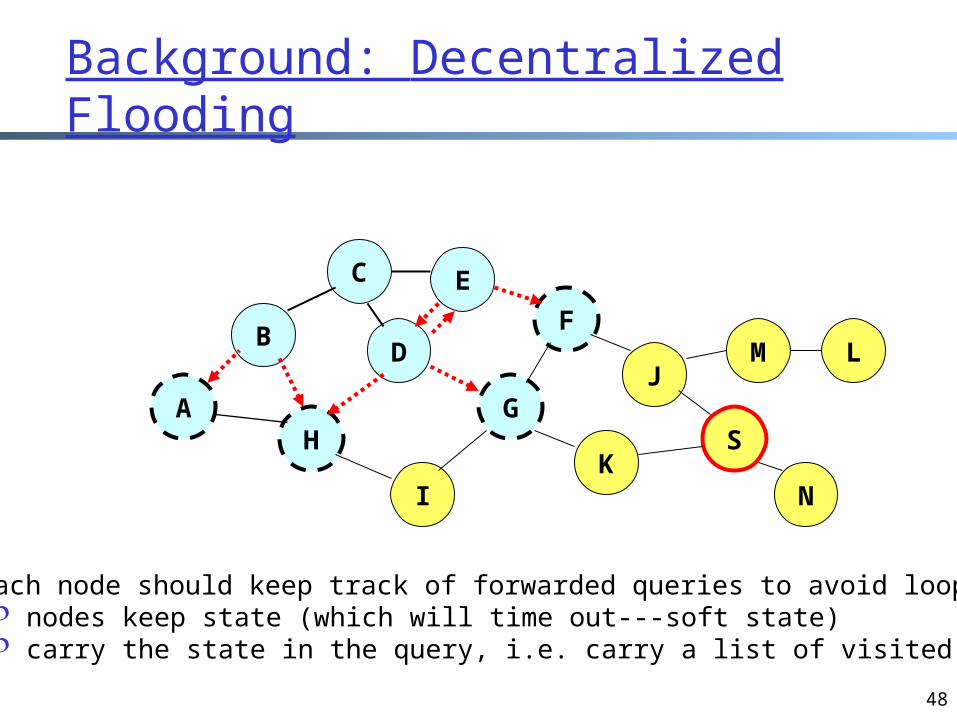
Decentralized Flooding: Gnutella
On startup, client contacts other servents (server + client) in network to form interconnection/peering relationships servent interconnection used to forward control (queries,
hits, etc) How to find a resource record: decentralized flooding
send requests to neighbors neighbors recursively forward the requests
46
Decentralized Flooding
B
A
C E
F
H
J
S
D
G
IK
M
N
L
47
Decentralized Flooding
B
A
C E
F
H
J
S
D
G
IK
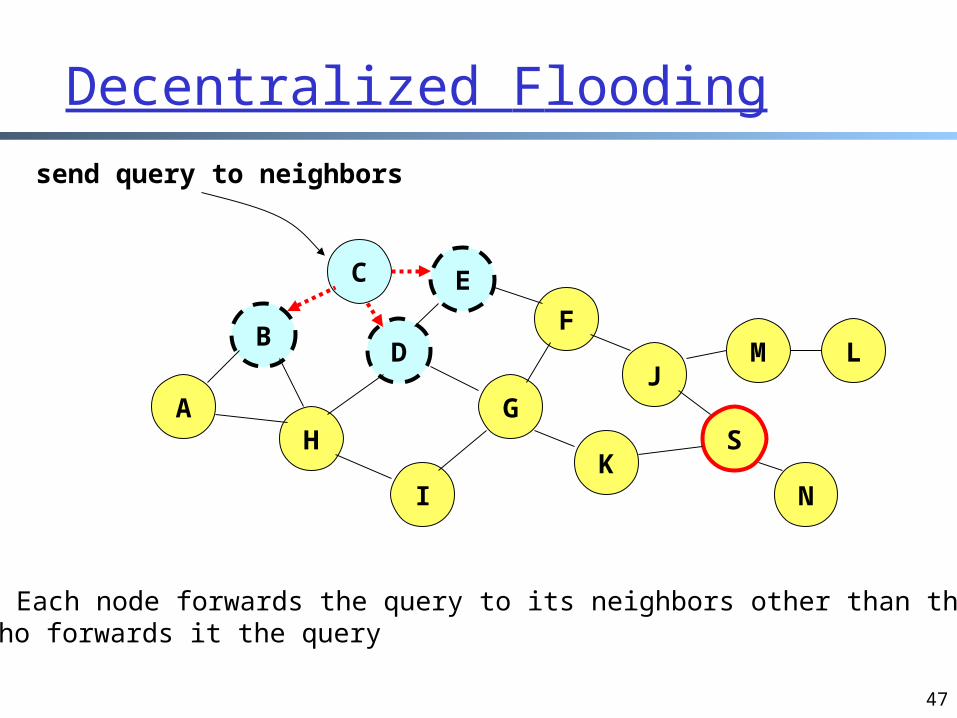
send query to neighbors
M
N
L
Each node forwards the query to its neighbors other than the onewho forwards it the query
48
Background: Decentralized Flooding
B
A
C E
F
H
J
S
D
G
IK
M
N
L
Each node should keep track of forwarded queries to avoid loop ! nodes keep state (which will time out---soft state) carry the state in the query, i.e. carry a list of visited nodes

49
Decentralized Flooding: Gnutella
Basic message header Unique ID, TTL, Hops
Message types Ping – probes network for other servents Pong – response to ping, contains IP addr, # of files, etc.
Query – search criteria + speed requirement of servent QueryHit – successful response to Query, contains addr
+ port to transfer from, speed of servent, etc.
Ping, Queries are flooded QueryHit, Pong: reverse path of previous message
50
Advantages and Disadvantages of Gnutella
Advantages: totally decentralized, highly robust
Disadvantages: not scalable; the entire network can be swamped
with flood requests• especially hard on slow clients; at some point broadcast
traffic on Gnutella exceeded 56 kbps to alleviate this problem, each request has a TTL to
limit the scope• each query has an initial TTL, and each node forwarding
it reduces it by one; if TTL reaches 0, the query is dropped (consequence?)

Flooding: FastTrack (aka Kazaa) Modifies the Gnutella protocol into two-level hierarchy Supernodes
Nodes that have better connection to Internet Act as temporary indexing servers for other nodes Help improve the stability of the network
Standard nodes Connect to supernodes and report list of files
Search Broadcast (Gnutella-style) search across
supernodes Disadvantages
Kept a centralized registration prone to law suits

52
Outline
Recap P2P
the lookup problem Napster (central query server; distributed
data server) Gnutella (decentralized, flooding) Freenet

53
Freenet History
final year project Ian Clarke , Edinburgh University, Scotland, June, 1999
Goals: totally distributed system without using centralized
index or broadcast (flooding) respond adaptively to usage patterns, transparently
moving, replicating files as necessary to provide efficient service
provide publisher anonymity, security free speech : resistant to attacks – a third party
shouldn’t be able to deny (e.g., deleting) the access to a particular file (data item, object)
54
Basic Structure of Freenet
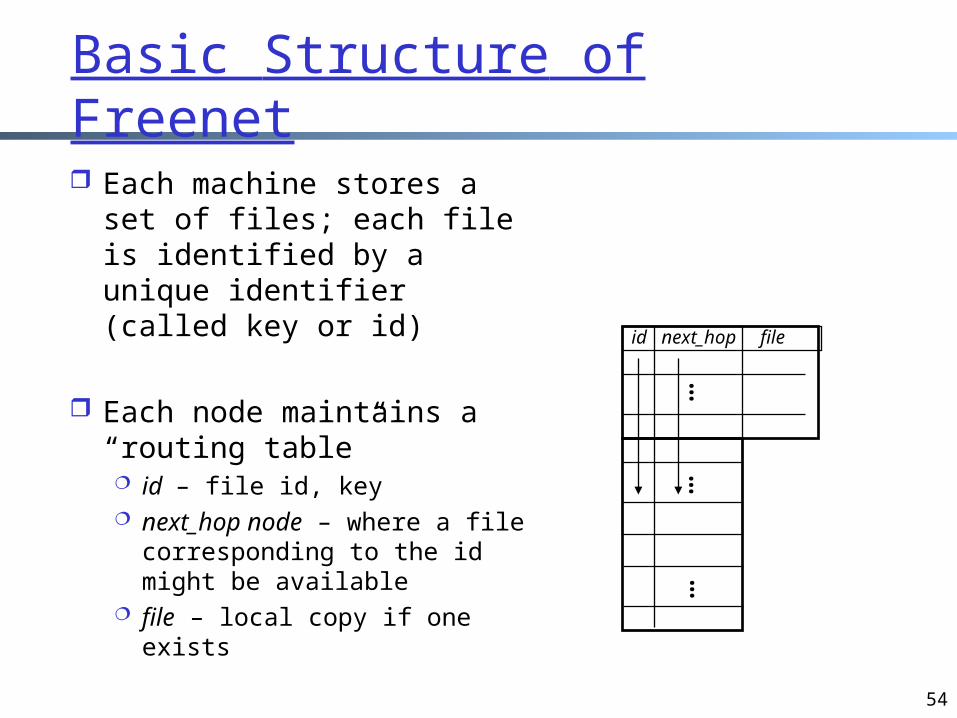
Each machine stores a set of files; each file is identified by a unique identifier (called key or id)
Each node maintains a “routing table” id – file id, key next_hop node – where a file
corresponding to the id might be available
file – local copy if one exists
id next_hop file
……
…

55
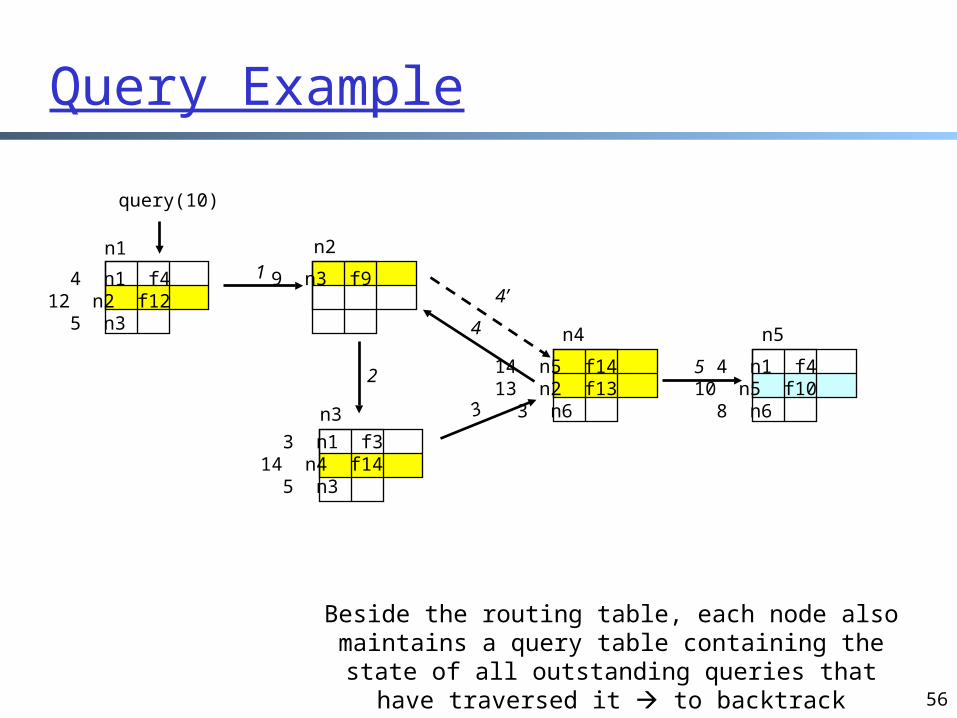
Freenet Query Search by routing API: file = query(id);
Upon receiving a query for file id check whether the queried file is stored locally check TTL to limit the search scope
• each query is associated a TTL that is decremented each time the query message is forwarded
• when TTL=1, the query is forwarded with a probability• TTL can be initiated to a random value within some bounds to obscure
distance to originator look for the “closest” id in the table with an unvisited next_hope
node• if found one, forward the query to the corresponding next_hop• otherwise, backtrack
– ends up performing a Depth First Search (DFS)-like traversal– search direction ordered by closeness to target
When file is returned it is cached along the reverse path (any advantage?)
id next_hop file
……
…
56
Query Example
4 n1 f412 n2 f12 5 n3
9 n3 f9
3 n1 f314 n4 f14 5 n3
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f410 n5 f10 8 n6
n5
query(10)
1
2
3
4
4’
5
Beside the routing table, each node also maintains a query table containing the state of all outstanding queries that have traversed it
to backtrack

57
Insert
API: insert(id, file); Two steps
first attempt a “search” for the file to be inserted
if found, report collision
if not found, insert the file by sending it along the query path
• thus inserted files are placed on nodes already possessing files with similar keys
• a node probabilistically replaces the originator with itself (why?)
58
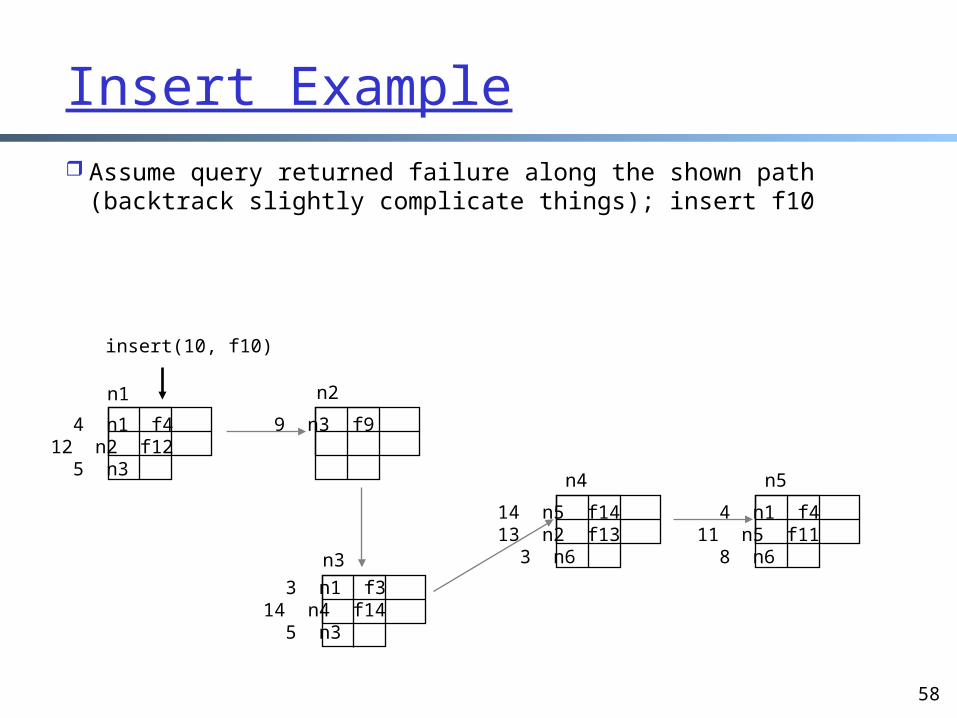
Insert Example Assume query returned failure along the shown path
(backtrack slightly complicate things); insert f10
4 n1 f412 n2 f12 5 n3
9 n3 f9
3 n1 f314 n4 f14 5 n3
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
59
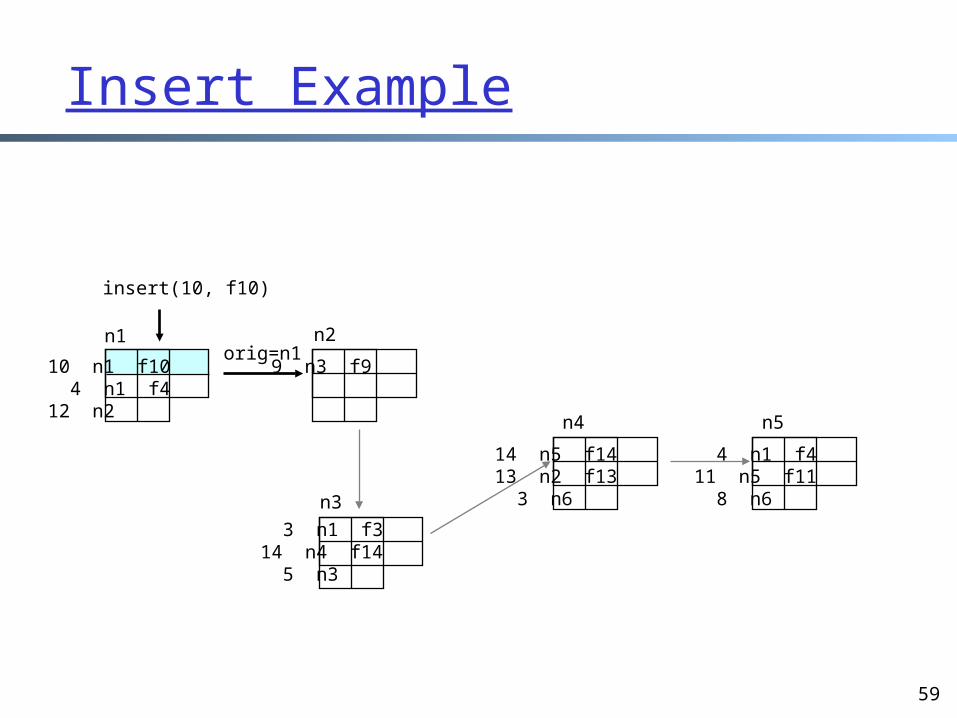
Insert Example
10 n1 f10 4 n1 f412 n2
14 n5 f1413 n2 f13 3 n6
n1
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
9 n3 f9
n2orig=n1
3 n1 f314 n4 f14 5 n3
n3
60
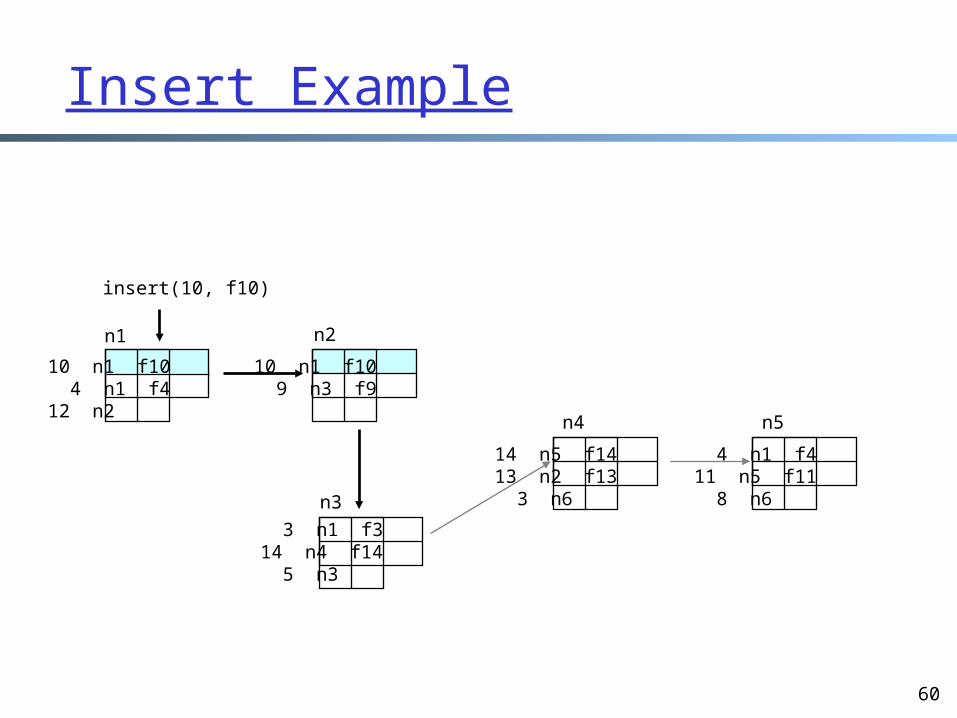
Insert Example
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
14 n5 f1413 n2 f13 3 n6
n1 n2
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
3 n1 f314 n4 f14 5 n3
n3
61
Insert Example
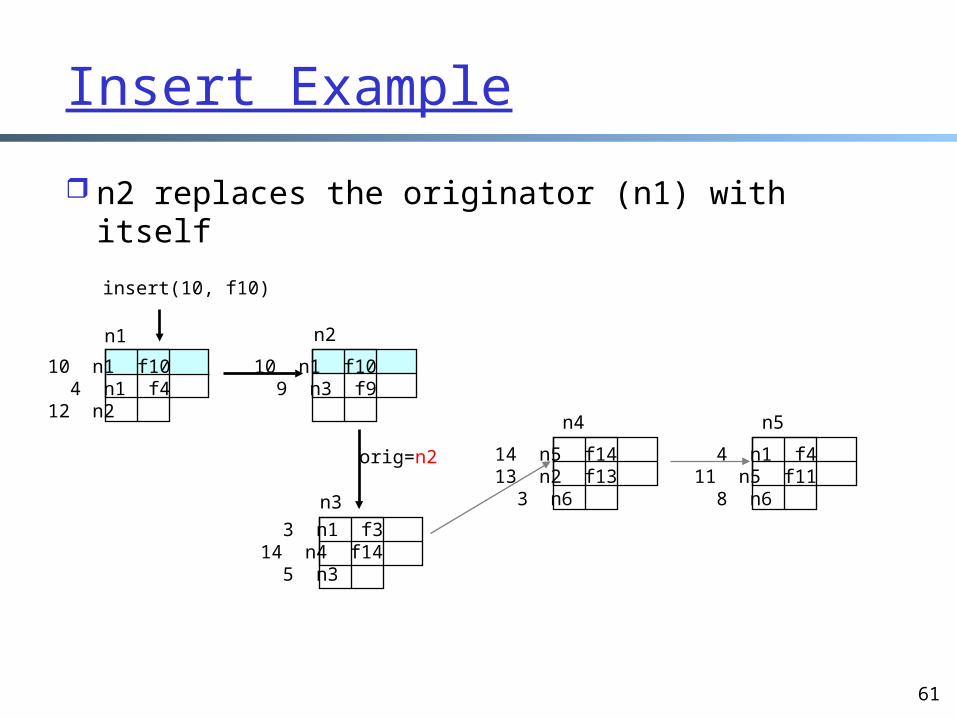
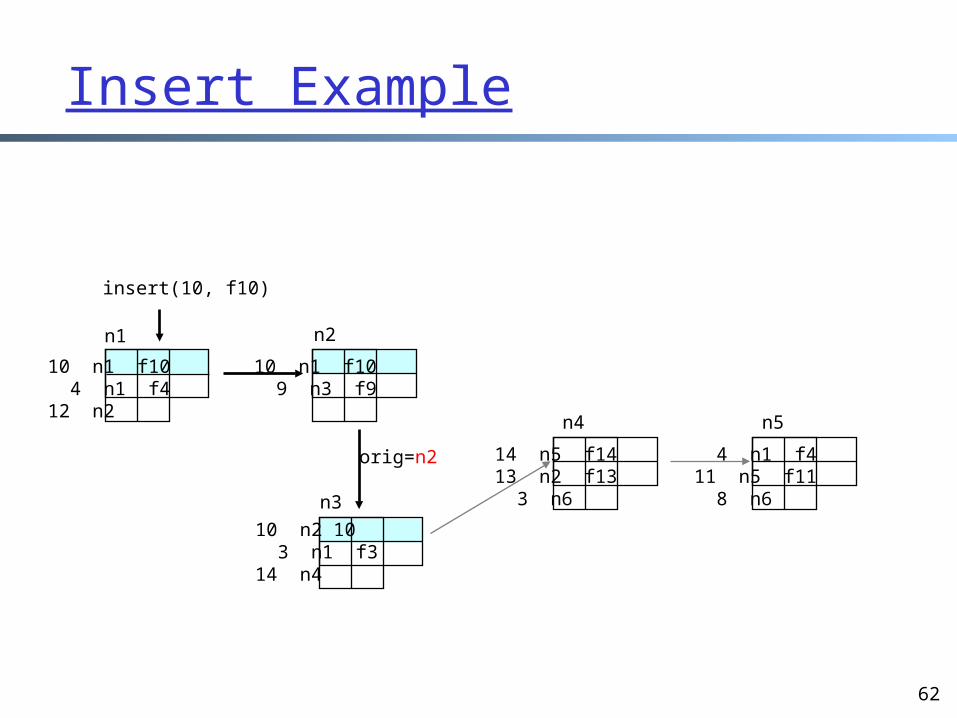
n2 replaces the originator (n1) with itself
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
14 n5 f1413 n2 f13 3 n6
n1 n2
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
orig=n2
3 n1 f314 n4 f14 5 n3
n3
62
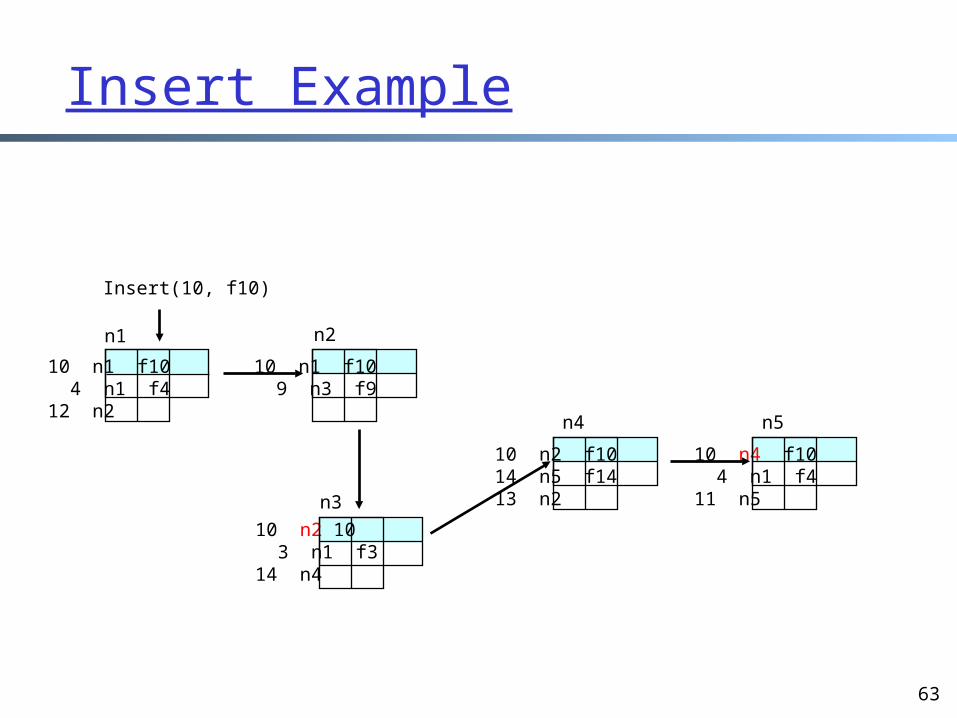
Insert Example
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
10 n2 10 3 n1 f314 n4
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
orig=n2
63
Insert Example
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
10 n2 10 3 n1 f314 n4
10 n2 f1014 n5 f1413 n2
n1 n2
n3
n4
10 n4 f10 4 n1 f411 n5
n5
Insert(10, f10)

64
Freenet Analysis
Authors claim the following effects: nodes eventually specialize in locating similar keys
• if a node is listed in a routing table, it will get queries for related keys
• thus will gain “experience” answering those queries popular data will be transparently replicated and will
exist closer to requestors as nodes process queries, connectivity increases
• nodes will discover other nodes in the network
Caveat: lexigraphic closeness of file names/keys may not imply content similarity

65
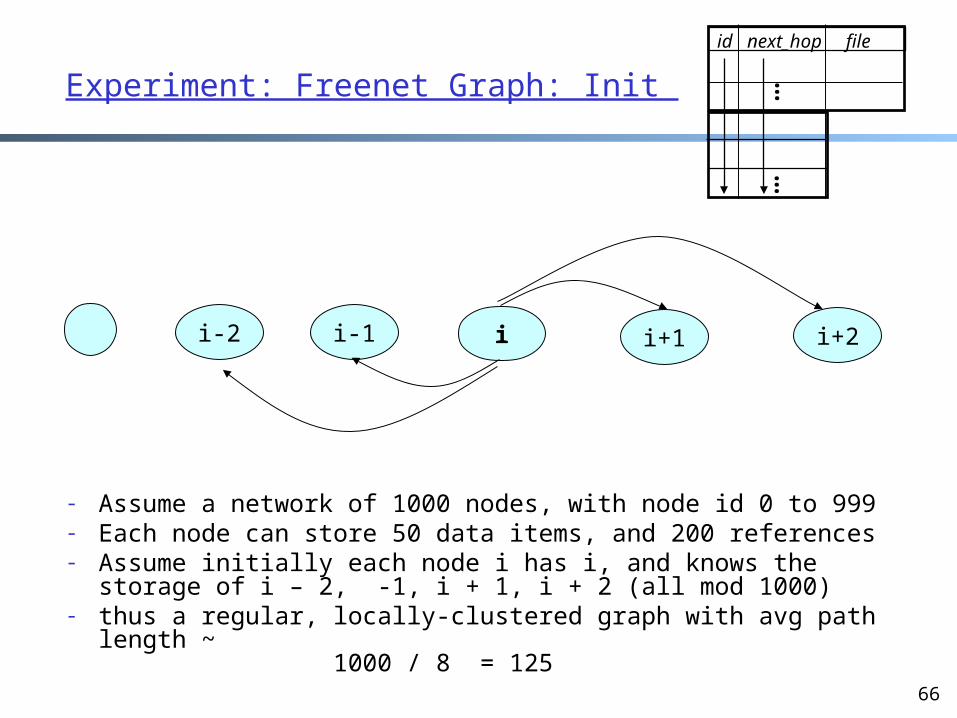
Understanding Freenet Self-Organization: Freenet Graph
We create a Freenet reference graph creating a vertex for each Freenet node adding a directed link from A to B if A refers
to an item stored at B
id next_hop file
……
66
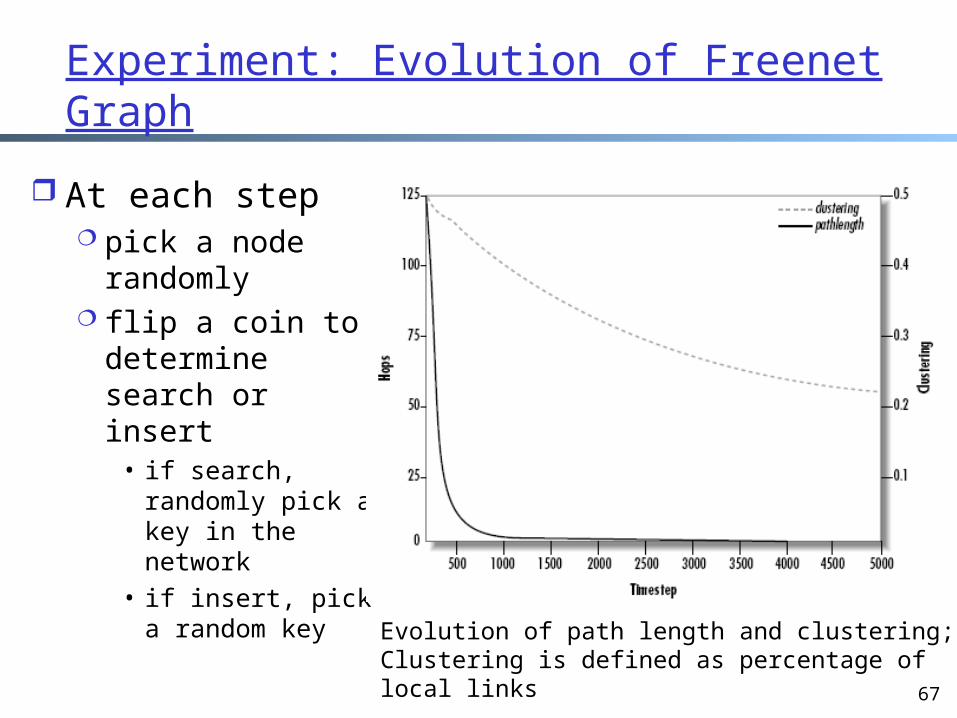
Experiment: Freenet Graph: Init
- Assume a network of 1000 nodes, with node id 0 to 999- Each node can store 50 data items, and 200 references- Assume initially each node i has i, and knows the storage of i
– 2, -1, i + 1, i + 2 (all mod 1000) - thus a regular, locally-clustered graph with avg path length
~ 1000 / 8 = 125
i-2 i-1 i i+1 i+2
id next_hop file
……
67
Experiment: Evolution of Freenet Graph
At each step pick a node
randomly flip a coin to
determine search or insert
• if search, randomly pick a key in the network
• if insert, pick a random key
Evolution of path length and clustering;Clustering is defined as percentage of local links
68
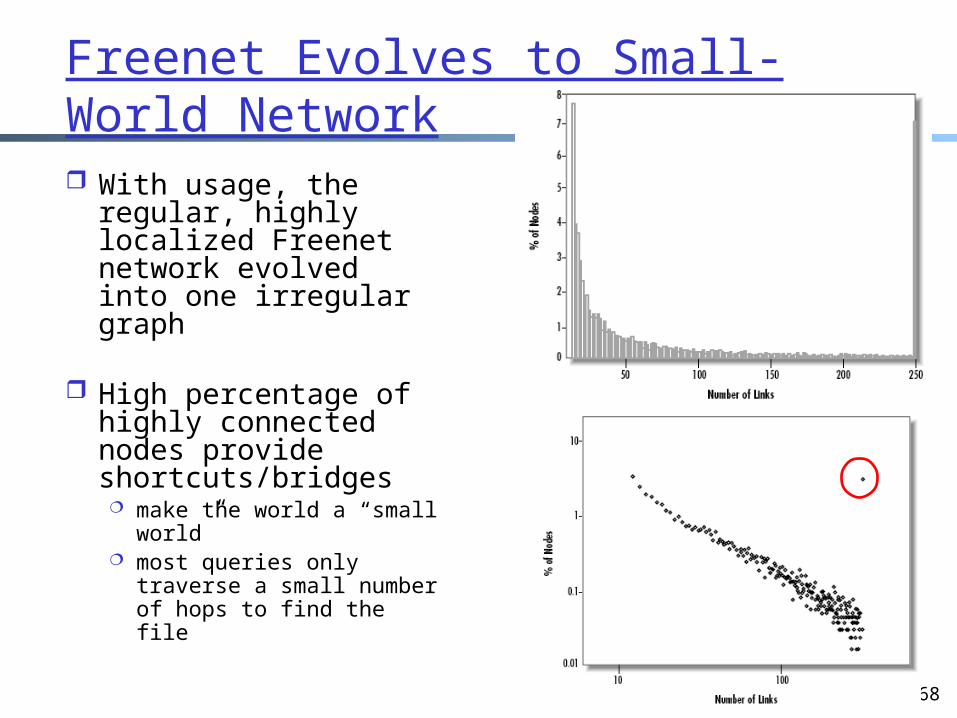
Freenet Evolves to Small-World Network With usage, the
regular, highly localized Freenet network evolved into one irregular graph
High percentage of highly connected nodes provide shortcuts/bridges make the world a “small
world” most queries only
traverse a small number of hops to find the file

69
Small-World
First discovered by Milgrom in 1967, Milgram mailed 160 letters to a set of
randomly chosen people in Omaha, Nebraska goal: pass the letters to a given person in Boston
• each person can only pass the letter to an intermediary known on a first-name basis
• pick the person who may make the best progress result: 42 letters made it through ! median intermediaries was 5.5---thus six degree of
separation
a potential explanation: highly connected people with non-local links in mostly locally connected communities improve search performance !

70
Kleinberg’s Result on Distributed Search
Question: how many long distance links to maintain so that distributed (greedy) search is effective?
Assume that the probability of a long link is some () inverse-power of the number of lattice steps
Kleinberg’s Law: Distributed algorithm exists only when probability is proportional to (lattice steps)-d, where d is the dimension of the space

71
Distributed Search
In other words, if double distance, increase number of neighbors by a constant -> see Chord
probability is proportional to (lattice steps)-d

72
Small World
Saul Steinberg; View of World from 9th Ave

73
Freenet: Properties Query using intelligent routing
decentralized architecture robust avoid flooding low overhead DFS search guided by closeness to target
Integration of query and caching makes it adaptive to usage patterns: reorganize network
reference structure free speech: attempts to discover/supplant existing
files will just spread the files !
Provide publisher anonymity, security each node probabilistically replaces originator with
itself

74
Freenet: Issues
Does not always guarantee that a file is found, even if the file is in the network
Good average-case performance, but a potentially long search path in a large network approaching small-world…

75
Summary
All of the previous p2p systems are called unstructured p2p systems
Advantages of unstructured p2p algorithms tend to be simple can optimize for properties such as locality
Disadvantages hard to make performance guarantee failure even when files exist

Optional Slides
76

Optional Slides
77
Aside: Search Time?
Aside: All Peers Equal?
56kbps Modem
10Mbps LAN
1.5Mbps DSL
56kbps Modem56kbps Modem
1.5Mbps DSL
1.5Mbps DSL
1.5Mbps DSL

Aside: Network Resilience
Partial Topology Random 30% die Targeted 4% die
from Saroiu et al., MMCN 2002

81
Asynchronous Network Programming
(C/C++)
82
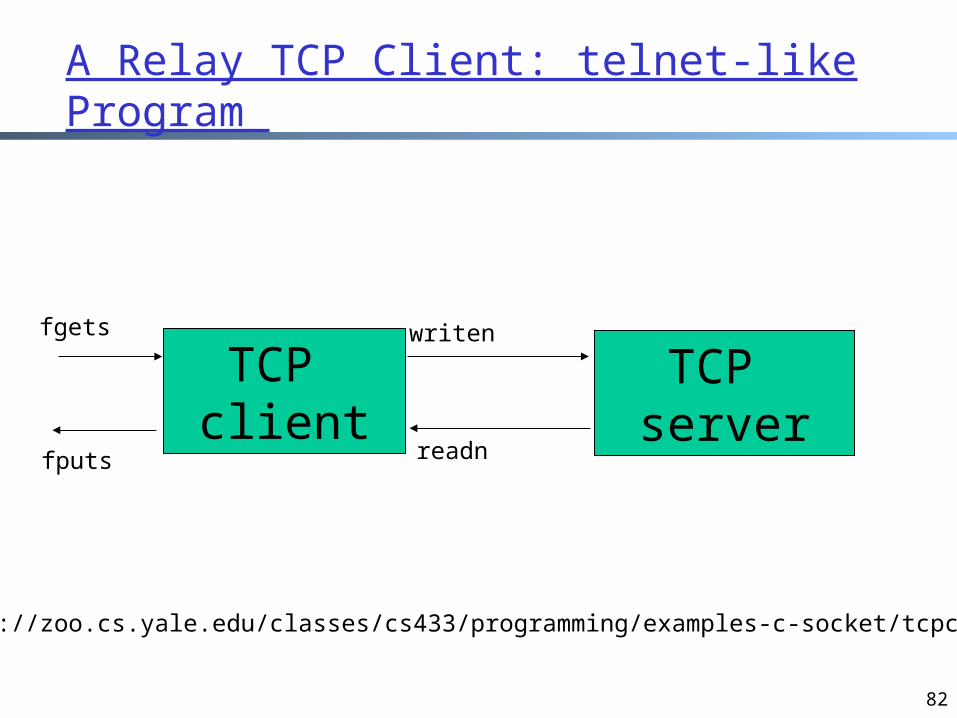
A Relay TCP Client: telnet-like Program
TCP client
TCP server
writen
readn
fgets
fputs
http://zoo.cs.yale.edu/classes/cs433/programming/examples-c-socket/tcpclient

83
Method 1: Process and Thread process
fork() waitpid()
Thread: light weight process pthread_create() pthread_exit()

84
pthread
Void main() { char recvline[MAXLINE + 1]; ss = new socketstream(sockfd);
pthread_t tid; if (pthread_create(&tid, NULL, copy_to, NULL)) { err_quit("pthread_creat()"); }
while (ss->read_line(recvline, MAXLINE) > 0) { fprintf(stdout, "%s\n", recvline); }}
void *copy_to(void *arg) { char sendline[MAXLINE];
if (debug) cout << "Thread create()!" << endl; while (fgets(sendline, sizeof(sendline), stdin)) ss->writen_socket(sendline, strlen(sendline));
shutdown(sockfd, SHUT_WR); if (debug) cout << "Thread done!" << endl;
pthread_exit(0);}

85
Method 2: Asynchronous I/O (Select)
select: deal with blocking system callint select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
FD_CLR(int fd, fd_set *set);FD_ZERO(fd_set *set);FD_ISSET(int fd, fd_set *set);FD_SET(int fd, fd_set *set);

86
Method 3: Signal and Select
signal: events such as timeout

87
Examples of Network Programming
Library to make life easier Four design examples
TCP Client TCP server using select TCP server using process and thread Reliable UDP
Warning: It will be hard to listen to me reading through the code. Read the code.
88
Example 2: A Concurrent TCP Server Using Process or Thread
Get a line, and echo it back Use select() For how to use process or thread, see
later Check the code at:
http://zoo.cs.yale.edu/classes/cs433/programming/examples-c-socket/tcpserver
Are there potential denial of service problems with the code?
89
Example 3: A Concurrent HTTP TCP Server Using Process/Thread
Use process-per-request or thread-per- request
Check the code at:http://zoo.cs.yale.edu/classes/cs433/programming/examples-c-socket/simple_httpd





























