Embed Size (px)
Citation preview

09_25_Chromosome22.jpg

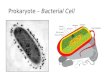
Fig. 27.8. The single chromosome (DNA + proteins) of a prokaryote contains all the directions for making a living cell. The chromosome of a prokaryopte is not organized into a nucleus, although it is generally located in one part of the cell).
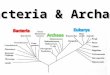
Prokaryotes (Ch. 27)
characteristics
genome organization
reproduction
metabolism
representative groups
importance
All the strands are part of the one chromosome, making a loop.

Prokaryote genomes
● Example: E. coli● 89% coding● 4,285 genes● 122 structural RNA genes● Prophage remains● Insertion sequence elements● Horizontal transfers

Prokaryotic genome organization:
• Haploid circular genomes (0.5-10 MB, 500-10000 genes)• Operons: polycistronic transcription units• Environment-specific genes on plasmids and other types of
mobile genetic elements• Usually asexual reproduction, great variety of
recombination mechanisms• Transcription and translation take place in the same
compartment
EPFL Bioinformatics I – 09 Jan 2006

Some important concepts from Chapter 1 that you should review from your high school biology course
1. Fig. 1.2 - properties of life
2. Fig. 1.3 - levels of biological organization
3. A closer look at cells - eukaryotic and prokaryotic (Fig. 1.8). Prokaryotes often also have a cell wall around the membrane.

Eukaryotic genome
● Example: C. elegans● 10 chromosomes● 19,099 genes● Coding region – 27%● Average of 5 introns/gene● Both long and short duplications

Eukaryotic genome organization
More about the nuclear genome:
• Multiple linear chromosomes, total size 5-10’000 MB, 5000 to 50000 genes
• Monocistronic transcription units• Discontinuous coding regions (introns and exons)• Large amounts of non-coding DNA • Transcription and translation take place in different compartments• Variety of RNA genes: rRNA, tRNA, snRNA (small nuclear), sno (small
nucleolar), microRNAs, etc. • Often diploid genomes and obligatory sexual reproduction• Standard mechanism of recombination: meiosis
• Multiple genomes: nuclear, plastid genomes: mitochondria, chloroplasts• Plastid genomes resemble prokaryotic genomes
EPFL Bioinformatics I – 09 Jan 2006

Complete genomes
>1387 projects
261 published
(01-03-05)
• 654 prokaryotes
• 472 eukaryotes
207 21
33
http://www.genomesonline.org/

● Using all of the available information, we can reconstruct relationships between organisms back to the earliest forms of life
Reconstructing Life’s Tree

Hierarchy of gene organization
Gene – single unit of genetic function
Operon – genes transcribed in single transcript
Regulon – genes controlled by same regulator
Modulon – genes modulated by same stimilus
Element – plasmid, chrom-osome,phage
Genome
** order of ascending complexity

Number of available completely sequenced genomes
95 03-0596 97 98 99 00 01 02 03 04
2 512
19 24
42
71
116
165
224
261
0
30
60
90
120
150
180
210
240
270
300
1 2 3 4 5 6 7 8 9 10 11

Huge amount of data
with exponential increase

Genomes to date

Polymorphic repeats
● Can be found anywhere in the genome● The longer the repeat, the more polymorphic it is● Are the basis for DNA fingerprinting & paternity
testing● In silico estimation of potentially polymorphic
repeats suggest > 100,000 in the human genome

Polymorphic repeats in genes
● Are found in genes less frequently● Have been implicated in several inherited genetic
disorders● Mutations at a rate of up to 100,000x that of SNPs● Have also been linked to roles in development,
cancer & morphology


First microbial genome was completely sequenced in 1995 by The Institute for Genomic Research (TIGR)
Fleishmann, R.D. et al. 1995. Science 269:496-512.
Genome of Haemophilus influenzae Rd
single circular chromosome 1,860,137 bp
Outer circle – coding sequences with database matches
40% of genes at the time had no match in the databases

E. coli K12
Blattner et al. 1995. Science 277:1453-74
Orange squares-forward genes
Yellow squares-complement genes
Red arrows-rRNA
Green arrows-tRNA
White ring-REP sequences
Blue ring-bacteriophage protein similarity
Sunburst-CAI (codon adaptation index)

Microorganism
Chromosome (kbp)
Plasmid (kbp)
Genome (kbp)
rRNA
Escherichia coli K12 MG1655* 4640 - 4640 7 Haemophilus influenzae Rd* 1830 - 1830 6 Burkholderia cepacia ATCC 25416 3650 +3170 +
1070 200 8090 4+1+1
Agrobacterium tumefaciens 3000 + 2100
(L) 200, 450 5750 1+1
Rhizobium meliloti 3400 1340, 1700 6440 3 Rhodobacter sphaeroides 3045 + 915 31, 42, 63, 97,
105, 110 4408 1+2
Thiobacillus cuprinus 3800 50 (L) 3850 1 Myxococcus xanthus 9455 - 9455 4 Bacillus subtilis* 4215 - 4215 10 Mycoplasma genitalium* 580 - 580 1 Bacillus cereus Fo837/76 2400 40, 230, 260,
360, 760, 960 5010 3
Streptomyces coelicolor 8000 (L) 350 (L) 8350 6 Synechocystis sp. strain PCC 6803* 3820 2.2, 5.2, 50,
100 3977 2
Borrelia burgdorferi B31* 910 (L) 9-53 (L and C) >1250 2 Methanococcus jannaschii* 1660 16, 58 1734 2 Haloferax volcanii 2920 6.4, 86, 442,
690 4144 2
Comparative genomics
Multipartite genomes
Circular and linear DNA elements
Huge degree of variation


Some important concepts from Chapter 1 that you should review from your high school biology course
1. Fig. 1.2 - properties of life
2. Fig. 1.3 - levels of biological organization
3. A closer look at cells - eukaryotic and prokaryotic (Fig. 1.8). Prokaryotes often also have a cell wall around the membrane.

Human Genome Organization
HUMAN GENOME
Genes and gene-related sequences
Extragenic DNA
Nuclear genome3000 Mb
65-80000 genes
Mitochondrial genome16.6 kb
37 genes
Coding DNA
Noncoding DNA
Unique or low copy number
Moderate to highly
repetitive
Pseudogenes Gene fragments
Introns,untranslated
sequences, etc.
Tandemly repeated
or clustered repeats
Interspersedrepeats
Unique or moderately repetitive
Two rRNAgenes
22 tRNAgenes
13 polypeptide-encoding genes
30% 70%
10% 90%
80% 20%
From: Dr Finbarr Hayes lec

HUMAN NUCLEAR GENOME24 chromosomes (haploid)3200 Mbp30,000 genes
Mitochondrial genome16569 bp37 genes
Human genome = nuclear genome + mitochondrial genome

H strand enriched in G
L strand enriched in C

Organization of the human genome
Limited autonomy of mt genomesmt encoded nuclear
NADH dehydrog 7 subunits >41 subunits
Succinate CoQ red 0 subunits 4 subunits
Cytochrome b-c1 comp 1 subunit 10 subunits
Cytochrome C oxidase 3 subunits 10 subunits
ATP synthase complex 2 subunits 14 subunits
tRNA components 22 tRNAs none
rRNA components 2 components none
Ribosomal proteins none ~80
Other mt proteins none mtDNA pol, RNA pol etc.

Human Mitochondrial Genome
Small (16.5 kb) circular DNA
rRNA, tRNA and protein encoding genes (37)
1 gene/0.45 kb
Very few repeats
No introns
93% coding;
Genes are transcribed as multimeric transcripts
Recombination not evident
Maternal inheritance

What are the mitochondrial genes?
● 24 of 37genes are RNA coding– 22 mt tRNA– 2 mit ribosomal RNA (23S, 16S)
● 13 of 37 genes are protein coding
(synthethized on ribosomes inside mitochondria)
some subunits of respiratory complexes
and oxidative phosphorylation enzymes

Two overlapping genes encoded by same strand of mt DNA
(unique example)
Two independent AUG located in Frame-shift to each other, second stop codon is derived from TA + A (from poly-A)

Mitochondrial codon table
22 tRNA cover for
60 positions via
third base wobble

Human Nuclear Genome3200 Mb
23 (XX) or 24 (XY) linear chromosomes
30-35,000 genes
1 gene/100kb
Introns in the most of the genes
1,5 % of DNA is coding
Genes are transcribed individually
Repetitive DNA sequences (45%)
Recombination at least once for each chrom.
Mendelian inheritance (X + auto, paternal Y)

Human Genome Organization
HUMAN GENOME
Genes and gene-related sequences
Extragenic DNA
Nuclear genome3000 Mb
65-80000 genes
Mitochondrial genome16.6 kb
37 genes
Coding DNA
Noncoding DNA
Unique or low copy number
Moderate to highly
repetitive
Pseudogenes Gene fragments
Introns,untranslated
sequences, etc.
Tandemly repeated
or clustered repeats
Interspersedrepeats
Unique or moderately repetitive
Two rRNAgenes
22 tRNAgenes
13 polypeptide-encoding genes
30% 70%
10% 90%
80% 20%
From: Dr Finbarr Hayes lec

Human nuclear genome
Euchromatic portion 3000Mb
Constitutive heterochromatine
200 Mb
Heterochromatin is distributed
between chromosomesunevenly
chr Total DNA Hetero DNA
1 279 30
2 251 3
16 104 15
17 88 3
21 45 11

Gene-poor chromosomes (With extra heterochromatin)
Short arms of acrocentric chromosomes –13,–14,–15, –21, –22
Part of long arms of chr 1,9,16Long arm of chromosome Y

Human genome base content● 41% CG in average
38% CG for chromosomes 4 and 13
49% for chromosome 19
● Regions with wide swings in GC content
(e.g. from 33,1% to 59,3%)
GC content is correlated with Giemsa staining;
Genes correlated too.
Gene density correlates with higher GC content

Location of CpG islands in the gene
CpG islands do NOT have a deficit of CpG dinucelotides


REPEATS!!!!

3 Main Components in Eukaryotic Genomes
DNA purified from a human, do not self-anneal
as a simple sigmoidal curve. Instead we see a curve
which is the sum of the reannealings of many different components
C0 = the initial concentration of nucleotides, T – time in seconds
CoT curve is a measure of
sequence complexity
REPEATS
NO REPEATS

Satellite DNA is repetitive DNA that could be separated by buoyant density
Equilibrium density gradient
centrifugation
Sheared DNA in Cesium Chloride
gradient

Satellite DNA
Alpha –satellite(Centromere DNA)
Microsatellites Minisatellites
Are you still remember what it is?
If not please refer to previous lectures and to the book


Repetitive DNA● Moderately repeated DNA
– Tandemly repeated rRNA, tRNA and histone genes (gene products needed in high amounts)
– Large duplicated gene families
– Mobile DNA (transposons)
● Simple-sequence DNA– Tandemly repeated short sequences
– Found in centromeres and telomeres (and others)
= (MINI and MICROSATELLITES)

Genetic maps
● Variable number tandem repeats (VNTRs – minisatellites), 10-100 bp, are a sort of genetic fingerprint
● Short tandem repeat polymorphisms (STRPs – microsatellites), 2-5 bp, are another kind of marker
● A sequence tagged site (STS), 200-600 bp, is a known unique location in the genome

Human Mobile DNA (transposons)● Moves within genome● LINE (Long interspersed nuclear elements)
– L1, L2, L3 LINE is ~21% of human DNA (~1,00,000 copies)
● SINE (Short interspersed nuclear elements)– Alu is ~10,7% of human DNA (1,200, 000 copies)
– MIR, MIR3 is 3% of hum DNA (500,000 copies)
● LTR elements (Long Terminal Repeats)– ERV and MalR are 8% of human DNA (500,000 copies)
● Transposons – MER1 (Charlie), MER2 (Tigger), others
(350, 000 copies), 2,8% of human DNA
TOTAL: approx; 45% of human DNA

RNA or DNA intermediate
• Transposon moves using DNA intermediate
• Retrotransposon moves using RNA intermediate
http://www.hos.ufl.edu/mooreweb/
LINEs and ERVs

Long interspersed nuclear elements (LINEs ) 20% of genome
● LINE1 – active
(Also many truncated inactive sequences)
● Line2 – inactive
● Line 3 – inactive
RNA binding also endonuclease
LINEs prefer AT-rich euchromatic bands
Internal promoter
IN everyone’s genome 60-100 copies of LINE1 are still capable of transposing,
and may occasionally cause the disease by gene disruption

Mechanism of LINE repeat jumps
Full length LINE transcript is generated from 5’-UTR-based promoter
ORF1 and ORF2 translated into proteins that stay bound to LINE mRNA
ORF1/ORF2/mRNA complex moves back into the nucleus
5’ 3’
5’ 3’orf1
orf2
5’ 3’orf1orf2
5’ 3’3’ 5’
3’ 5’
Product of ORF2 cut ds DNA
Freed 3’ serves as a primer for LINE reverse transcription from 3’ UTR

ORF2 and ORF1 function● ORF1 keeps ORF2 and LINE mRNA bound together and
retracted into nucleus
● ORF2 (endonuclease) cut dsDNA to provide free 3’ end as a primer to LINE 3’UTR
● ORF2 (reverse transcriptase)
makes cDNA copy of LINE mRNA, which becomes integrated into chromosomal DNA
(as it bound to it by former 3’ freed end)
TTTT A is ORF1 cleavage site, that is why integration prefers AT rich regions

LINE replication is not very efficient process
Reverse transcriptase of LINE elements is a “weak” enzyme (have a low processivity)
Many insertions are truncational
(copies are not able to copy itself further)
Most insertions are only 900 bp
(instead of 6.1 kb),
only 1 of 100 insertions is successful

Illustration to full-size LINEs and their fossil derivates

Short interspersed nuclear elements (SINE) 13% of genome
● Non-autonomous (no revertase)● 100-400 bp long;● No open reading frames● Derived from tRNA (transcribed with
RNA pol III, leaving internal promoter) ● Share sequences with 3’ ends of LINEs● Depend on LINE machinery for its movement

AluI - elements
● Derived from signal recognition particle 7SL● Does not share its 3’ end with a LINE● Internal promoter is active, but require appropriate
flanking sequence for activation – so it’s active only if lucky with it’s integration site
● Integrates in GC rich sequences
● Only active SINE in the human genome

As ALU repeats do not have
open reading frames,
ALUs have to useRT enzyme
and endonuclease provided by LINE repeats
or other transposons
Mark A. Batzer and Prescott L.Deininger

After integration Alu copies rapidly mutate at sites of their 24 CpGs
Alignment of Alu-subfamily consensus sequences.Mark A. Batzer and Prescott L.Deininger

The expansion of Alu-elements in primate lineage
Mark A. Batzer and Prescott L.Deininger


Potential Alu-mediated damage to human genome
Insertional mutagenesis
ALU-mediated uneven recombination

Diseases that sometimes caused by de novo Alu-integration
● Neurofibromatosis (Shwann cell tumors), ● haemophilia,● breast cancer, ● Apert syndrome (distortions of the head and face and
webbing of the hands and feet), ● cholinesterase deficiency
(congenital myasthenic syndrome) ● complement deficiency
(hereditary angioedema)

Disease that sometimes caused by Alu-mediated uneven recombination
● insulin-resistant diabetes type II (InsReceptor) ● Lesch–Nyhan syndrome (overproduction of uric acid
leading to neurologic syndrome),● Tay–Sachs disease,● complement component C3 deficiency, ● Familial hypercholesterolaemia ● α-thalassaemia● Several types of cancer, including Ewing sarcoma, breast
cancer, acute myelogenous leukaemia

Positive role of Alu repeats in evolution
Alu
Alu
Alu
Insertions of the repeat near gene may change
its expression pattern,
gene structure,
or leads to alternatively spliced
mRNA isoforms
LTRs contain promoters, ALUs repeats contain TF binding sites

Human repeat distribution depends on GC content of integration sites

Alu paradox● Alu repeats are found in GC-rich (gene rich) regions more
often than in AT rich;
● De novo integration of ALU-repeats happens
in AT-rich areas
(as they hijacked ORF2 product of LINE)
ALUs are subject of positive selection (as they CREATE new genes)
by supplying genome segments ready to become geneswith promoter like elements and exonic-like boundaries.
Also they are GC rich themselves, so they transform AT-rich regions into GC rich

LTR transposons
● Any trasposon flanked by Long Terminal Repeats; ● DNA bases transposons and Retrotransposons;
Contain Transposase;
Already silent in the human genome
Fossils (Charlie and Tigger types)
Endogenous Retroviral Sequences(ERVs)
Contain Gag and Pol genes
Only HERV-K look still OK for moving

DNA transposons and retrotransposons
Kazazian, Science, Vol 303, Issue 5664
LINE SINE

Human RNA genes (non-coding RNA transcripts)
3000 RNA genes in human genome (rough)● rRNA ● tRNA● Small nuclear RNA● Small nucleolar RNA● SRP RNA● MicroRNA● Antisense RNA● Non-coding gene mRNA isoforms;● RNAs form transcribed pseudogenes

miRNA and antisense RNA are underestimated;
“other non-coding RNA”are not represented

rRNA genes (1200 genes)
18S, 5.8S and 28Sare encoded
by single transcription units;
Located in 5 clusters:Chr. 13,14,15, 21,22
5S is in tandem arrays,largest is on Chr. 1q41-42
All this is to increase a gene dosage

tRNA genes (497 nuclear genes + 324 putative pseudogenes)
● Humans have fewer tRNA genes that the worm (584), but more than the fly (284);
● Frog X.laevis have thousands of tRNA genes;
● Number of tRNA genes correlates with size of the oocytes;
In large oocytes lots of protein needs to be sythethized simultaneously….

● 49 families according to codon recognition;
(Should by 61 for every coding triplet)
Paradox is eliminated by codon wobbling
● Very rough correlation between tRNA gene number and amino acid frequency in the protein
● 280 out of 497 genes are on Chr.6, most are clustered in the same 4 Mb region; other are also more or less clustered (Chr. 1 and 7)
● All chromosomes still carry at least one tRNA gene – chr.22 and Y are exclusions
tRNA genes (497 nuclear genes + 324 putative pseudogenes)

Representation of aminoacids by human tRNA (examples)
Amino Acid Frequency Number of tRNAs
Alanine 7,06% 40
Leucine 9,95% 35
Tryptophan 1,30% 7
Valine 6,12% 44
Aspartate 4,78% 10
Cysteine 2,25% 30
Histidine 2,56% 12
Selenocysteine <0,01% 1

Small nuclear RNA (snRNA)● Uridine rich; ● Numbered U1, U2, U3 etc● Include spliceosomal RNAs U6 and U1
U6 (44 genes) and U1 (16 genes)
● Sometimes clustered as very irregular or almost perfect groups,
e.g. RNU1 locus at 1p36 and RNU2 at 17q21; ● For U6 snRNA 1135 fragmental/pseudogenic sequences
are identified

● Employed in nucleolus to guide
site-specific base modifications in rRNA; ● Also can modify U6 RNA;
● snoRNA genes often found in other gene’ introns● Generally not clustered except SNURF-SNRPN unit on 15 q which
possibly involved in Prader-Willi sydrome● C/D box snoRNA and H/ACA snoRNA
Small nucleolar RNA (snoRNA)
Site-specific 2’-O-ribose methylation of rRNA (105-107 sites)
Site-specific Pseudouridylation
(95 sites)

SRP RNA (7SL RNA)
Protein export machinery of the endoplasmic reticulum binds a protein RNA complex
(Signal Recongnition Particle) that contains 7SL RNA
four 7SL genes, 500 7SL pseudogenesand all the Alu repeats that are derived form 7SL gene

Micro RNA (miRNA)● a family of 21–25-nucleotide small RNAs that negatively
regulate gene expression at the post-transcriptional level;● primary transcripts of miRNAs are processed sequentially
by two RNase-III enzymes, Drosha and Dicer, into a small, imperfect dsRNA duplex (miRNA:miRNA*)
mature miRNA strand plus its complementary strand (miRNA*).
● RNA-induced silencing complex (RISC) is operated by miRNA;miRNA* and Ago-proteins

Exonuclease III Drosha
Dicer cleaves microRNAs into their mature form
This form is exported from the nucleus
By Exportin-5
miRNA incorporated into effector complexes Elizabeth P Murchison and Gregory J Hannon

miRNA is recognized by the PAZ domain of an Ago protein,
and incorporated into RISC
facilitates transfer of miRNAs into RISC.
Depending on RISC components, RISC may target homologous mRNA
for cleavage, or stall mRNA translation
ss miRNA

Non-coding mRNA with poly(A )tail transcribed by RNA pol II
● Mid-to-large size mRNA● For most of them function is unknown● Often overexpressed in tumors● 7SK RNA decreases rate of RNA pol II
elongation and inhibits the activity of CDK9/cyclin T complexes;
● SRA RNA co-activator of steroid receptors● XIST RNA – X-chromosome incativation in
female cells

Antisense RNA● TSIX regulates XIST gene● Antisense regulation of imprinted genes● aHIF: regulates hypoxia-inducible factor (HIF)-1alpha and
HIF-2alpha; ● Makorin-2 gene as an antisense to the RAF1 oncogen● RFP2 CLL candidate gene and RFP2OS transcript● antisense beta myosin heavy chain RNA switches myosin
heavy chain gene expression from myosin beta to myosin alpha in heart musc

Some more statistics
● Gene density 1/100 kb (vary widely); ● Averagely 9 exons per gene● 363 exons in titin gene● Many genes are intronsless● Largest intron is 800 kb (WWOX gene)● Smallest introns – 10 bp● Average 5’ UTR 0,2-0,3 kb● Average 3’ UTR 0,77 kb but underestimated…● Largest protein: titin: 38,138 aa

INTRONLESS GENES
● Interferon genes● Histone genes● Many ribonuclease genes● Heat shock protein genes● Many G-protein coupled receptors● Some genes with HMG boxes● Various neurotransmitters receptors and hormone receptors

Smallest human genes
Percentages describe
exon content to the length of the gene

Typical human genes

Extra Large human genes
IG genes are shown as germline genes, before rearrangements

Presumable functions of human genes

HUMAN genes and their homology
to genes from other organisms

Why so small amount of genes we, humans, kings of nature, have?
Human 30,000 genesDrosophila – 13,000Nematode – 19,000
Potential of proteome and transcriptome diversity is so great that it is no need for increase of amount of genes

Gene families● Functionally identical genes
-- Recently duplicated genes (Alpha-globins);
-- Histone genes (86 members, some are identical)
-- Ubiquitin-encoding genes (some are in polycistronc transcription units)
● Functionally similar genes
usually arise by duplications also, than diverge ● Functionally related genes
belong to the same pathway or to encode subunits of protein complex (usually non-related)

Chromosomal distribution of human histone genes

Bidirectional and partially overlapping genes
● Not very common in human genome as 1 gene/100 kb density allow genes to be loose…
● Provides possibility for common regulation of a gene pair.● Partially overlapping genes are usually encoded by opposite DNA
strands.
Found in dense gene areas,
as HLA class III complex on 6p21.3
Could represent sense-antisense pair
with one gene is coding mRNA, another is non-coding

HLA class III complex on 6p21.3: an example of tightly packed genes
MHC Class III genesEncoding complement proteins C4A and C4B, C2 and FACTOR B
TUMOUR NECROSIS FACTORS AND
Plus some Immunologically irrelevant genesGenes encoding 21-hydroxylase, RNA Helicase, Casein kinase
Heat shock protein 70, Sialidase

An example of complex human gene locus INK4a-ARF
From: Prof. Gordon Peters website

Genes within genes
Neurofibromatosis gene (NF1) intron 26 encode :
OGMP (oligodendrocyte myelin glycoprotein)EVI2A and EVO2B (homologues of ecotropic viral intergration sites in mouse)

Gene families
● Classical gene families
(overall conservativeness)
Histones, alpha and beta-globines
● Gene families with large conservative domains
(other parts could be low conservative)
HLH/bZIP box transcription factors
● Gene families with short conservative motifs
e.g. DEAD box (Asp-Glu-Ala-Asp), WD repeat

Example of human gene familiesclustered together
alpha-albumin serum albumin vitamin D-binding protein
four placenta-specific genes, primates only
CS = chorionic somatomammotropin

Example of human protein motifs
DEAD box proteins are involved in mRNA splicing and translation initiation; 8 conservative boxes, DEAD is the most evident
WD proteins take part in a variety of regulatory functions, GH (Gly-His should be at 23-41 aa distance from WD (Trp-Aps)

Gene superfamilies● Proteins that are functionally related in a general sense, but
show only weak homology
● Immunoglobulin superfamily (IG genes, T- cell receptor genes, HLA-genes….)
● Globin superfamily (myoglobin, alpha and beta-globins, neuroglobin etc….)
● G-protein coupled receptor superfamily (seven transmembrane domains, but low homology)
And so on….

Illustration to gene superfamily

Major mechanisms of gene family spreading
● Ancient gene or chromosomal segment duplications– Tandem duplications– Duplications with gene transfer to another chromosome
● Retrotransposition events
(processed copies with no introns only)

Some regions of genome are more prone to rearrangements than others
Chromosome 22q

Human pseudogenes
Non-processed pseudogenes Processed
pseudogenesContain introns;
Arise by duplications;
Frequency of transfer depend on chromosomal context
(pericentromeral fragment are transferred more often)
Do not contain introns;
Arise by retrotransposition;
Frequency of transfer depends on initial level of
gene expression
(Highly expressed genes are transferred more often) Complete Partial
Both types of pseudogenes are raw material for evolution

HLA type I cluster
Domain structure of a typical HLA type I gene
Complete pseudogenes
Partial pseudogenes and their structure

NF1 gene and its pseudogenes on different chromosomes
All NF1 pseudogenes are partial; 11 of them are found in the genome

Mechanism of processed pseudogene transfer into new location
Could be very prolific: there are 95 functional ribosomal genes and 2090 pseudogenes

Transcription from pseudogenes
Master gene
Chr 1
Chr 7
Partial duplication with preservation of the promoter; Expression is preserved in evolution, If transcript encode partial protein (regulatory),or if rare transcription factors sites present in both promoters
Chr 15
LINE-mediated inclusion of cDNA copy of master gene;
Brought under heterologous promoter by chance, could be antisense


Genetic maps
● Variable number tandem repeats (VNTRs – minisatellites), 10-100 bp, are a sort of genetic fingerprint
● Short tandem repeat polymorphisms (STRPs – microsatellites), 2-5 bp, are another kind of marker
● A sequence tagged site (STS), 200-600 bp, is a known unique location in the genome




























{kind=link}