Embed Size (px)
Citation preview

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 1
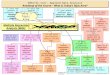
S052/§I.1(a): Applied Data AnalysisRoadmap of the Course – What Is Today’s Topic?
S052/§I.1(a): Applied Data AnalysisRoadmap of the Course – What Is Today’s Topic?
More details can be found in the “Course Objectives and Content” handout on the course webpage.More details can be found in the “Course Objectives and Content” handout on the course webpage.
Multiple RegressionAnalysis (MRA)
Multiple RegressionAnalysis (MRA) iiii XXY 22110
Do your residuals meet the required assumptions?
Test for residual
normality
Use influence statistics to
detect atypical datapoints
If your residuals are not independent,
replace OLS by GLS regression analysis
Use Individual
growth modeling
Specify a Multi-level
Model
If your sole predictor is continuous, MRA is
identical to correlational analysis
If your sole predictor is dichotomous, MRA is identical to a t-test
If your several predictors are
categorical, MRA is identical to ANOVA
If time is a predictor, you need discrete-
time survival analysis…
If your outcome is categorical, you need to
use…
Binomial logistic
regression analysis
(dichotomous outcome)
Multinomial logistic
regression analysis
(polytomous outcome)
If you have more predictors than you
can deal with,
Create taxonomies of fitted models and compare
them.Form composites of the indicators of any common
construct.
Conduct a Principal Components Analysis
Use Cluster Analysis
Use non-linear regression analysis.
Transform the outcome or predictor
If your outcome vs. predictor relationship
is non-linear,
How do you deal with missing
data?
Today’s Topic Area

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 2
S052/§I.1(a): Applied Data AnalysisWhere Does Today’s Topic Appear in the Printed Syllabus?
S052/§I.1(a): Applied Data AnalysisWhere Does Today’s Topic Appear in the Printed Syllabus?
In the future, I ask you to keep automatically tabs on the inter-connections among the Roadmap, the Daily Topic Area, the Printed Syllabus, and the content of the day’s class, when you first download and pre-read the required day’s class materials.
In the future, I ask you to keep automatically tabs on the inter-connections among the Roadmap, the Daily Topic Area, the Printed Syllabus, and the content of the day’s class, when you first download and pre-read the required day’s class materials.
Today’s topic, Deciding Which Regression Models to Fit, is from Syllabus Section I.1(a) and includes: Slides 3-4: Introducing the ILLCAUSE data-example. Slides 5-6: Imagining a “Universe Of All Possible
Models”. Slides 7-8: Two Strategies For Choosing Sensible
Subsets of Regression Models To Fit. Slides 9-14: Exploratory Univariate & Bivariate
Analyses in the ILLCAUSE Dataset. Slide 15: Establishing Priorities Among the Predictors. Slides 16-18: Fitting a Taxonomy of Regression Models
in the ILLCAUSE Dataset. Slide 19: Decoding Standard Regression Output. Slide 20: APA-Style Table Displaying a Taxonomy Of
Fitted Regression Models. Slides 21-22: Appendix 1. Slide 23: Appendix 2.
Today’s topic, Deciding Which Regression Models to Fit, is from Syllabus Section I.1(a) and includes: Slides 3-4: Introducing the ILLCAUSE data-example. Slides 5-6: Imagining a “Universe Of All Possible
Models”. Slides 7-8: Two Strategies For Choosing Sensible
Subsets of Regression Models To Fit. Slides 9-14: Exploratory Univariate & Bivariate
Analyses in the ILLCAUSE Dataset. Slide 15: Establishing Priorities Among the Predictors. Slides 16-18: Fitting a Taxonomy of Regression Models
in the ILLCAUSE Dataset. Slide 19: Decoding Standard Regression Output. Slide 20: APA-Style Table Displaying a Taxonomy Of
Fitted Regression Models. Slides 21-22: Appendix 1. Slide 23: Appendix 2.

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 3
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Question, and Dataset, Will Drive Our Presentation Today?S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Question, and Dataset, Will Drive Our Presentation Today?
As an introductory example of this part of the syllabus -- “Deciding Which Multiple Regression Models To Fit” -- here’s a multiple regression analysis to address the following broad question:
Do Chronically-ill Children Understand The Causes Do Chronically-ill Children Understand The Causes Of Illness Differently From Healthy Children?Of Illness Differently From Healthy Children?
As an introductory example of this part of the syllabus -- “Deciding Which Multiple Regression Models To Fit” -- here’s a multiple regression analysis to address the following broad question:
Do Chronically-ill Children Understand The Causes Do Chronically-ill Children Understand The Causes Of Illness Differently From Healthy Children?Of Illness Differently From Healthy Children?
Dataset on the website: ILLCAUSE.txtCodebook on the website: ILLCAUSE_info
Dataset on the website: ILLCAUSE.txtCodebook on the website: ILLCAUSE_info
Dataset ILLCAUSE.txt
Overview Data for investigating differences in children’s understanding of the causes of illness, by their health status.
Source Perrin E.C., Sayer A.G., and Willett J.B. (1991). Sticks And Stones May Break My Bones: Reasoning About Illness Causality And Body Functioning In Children Who Have A Chronic Illness, Pediatrics, 88(3), 608-19.
Sample size 301 children, including a sub-sample of 205 who were described as asthmatic, diabetic, or healthy. After further reductions due to the list-wise deletion of cases with missing data on one or more variables, the analytic sub-sample used in class ends up containing 33 diabetic children, 68 asthmatic children and 93 healthy children.
More info Chronically-ill children were recruited into the study through their pediatricians; healthy children were a matched random sample drawn from the same schools as the ill children.
Updated September 16, 2005

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 4
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Variables Will We Focus On In Our Analyses?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Variables Will We Focus On In Our Analyses?
Col Variable Variable Description Variable Metric/Labels 1 ID Child identification code Integers
2 ILLCAUSE Child’s score on a measure of the understanding of illness causality.
Ordinal score obtained by averaging child responses to 7 interview questions on the causes of illness, with responses rated on a “developmental” scale: 1 = No response. 2 = Phenomenistic or circular response. 3 = External agency cited as sole cause. 4 = Internalization in understanding illness, once agent
internalized, illness is inevitable. 5 = Interaction of host and agent described. 6 = Mechanisms of illness causation described, including notions
of treatment and bodily response.
3 SES
Family socio-economic status, rated using the education and employment levels of the primary bread-winner with Hollingshead Two-Factor Index of Social Position. (Hollingshead & Frederick. Social Class and Mental Illness. NY: Wiley, 1958)
Ordinal rating of social class: 1 = upper 2 = upper middle 3 = middle 4 = lower middle 5 = low (Notice the ordering of the numerical values is counterintuitive).
4 PPVT Child’s normed score on the Peabody Picture Vocabulary Test.
Continuous score, mean of 100 & standard deviation of 15 in population.
5 AGE Child age Continuous variable, months since birth.
6 GENREAS Child’s score on a measure of general reasoning.
Ordinal score, from 1 through 6. Similar to ILLCAUSE, but requires general reasoning, rather than reasoning about illness.
7 HEALTH Child Health Status Indicator
Categorical variable with multiple categories, of which we are interested in:
3 = Diabetic 5 = Asthmatic 6 = Healthy
Col Variable Variable Description Variable Metric/Labels 1 ID Child identification code Integers
2 ILLCAUSE Child’s score on a measure of the understanding of illness causality.
Ordinal score obtained by averaging child responses to 7 interview questions on the causes of illness, with responses rated on a “developmental” scale: 1 = No response. 2 = Phenomenistic or circular response. 3 = External agency cited as sole cause. 4 = Internalization in understanding illness, once agent
internalized, illness is inevitable. 5 = Interaction of host and agent described. 6 = Mechanisms of illness causation described, including notions
of treatment and bodily response.
3 SES
Family socio-economic status, rated using the education and employment levels of the primary bread-winner with Hollingshead Two-Factor Index of Social Position. (Hollingshead & Frederick. Social Class and Mental Illness. NY: Wiley, 1958)
Ordinal rating of social class: 1 = upper 2 = upper middle 3 = middle 4 = lower middle 5 = low (Notice the ordering of the numerical values is counterintuitive).
4 PPVT Child’s normed score on the Peabody Picture Vocabulary Test.
Continuous score, mean of 100 & standard deviation of 15 in population.
5 AGE Child age Continuous variable, months since birth.
6 GENREAS Child’s score on a measure of general reasoning.
Ordinal score, from 1 through 6. Similar to ILLCAUSE, but requires general reasoning, rather than reasoning about illness.
7 HEALTH Child Health Status Indicator
Categorical variable with multiple categories, of which we are interested in:
3 = Diabetic 5 = Asthmatic 6 = Healthy

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 5
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Even With A Few Predictors, There Are So Many Models You Can Possibly Fit!
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Even With A Few Predictors, There Are So Many Models You Can Possibly Fit!
To address a RQ about children’s understanding of illness, you can: Identify ILLCAUSE as the outcomeoutcome. Identify “HEALTH,” AGE, and SES as predictorspredictors.
And proceed with regression analysis …
To address a RQ about children’s understanding of illness, you can: Identify ILLCAUSE as the outcomeoutcome. Identify “HEALTH,” AGE, and SES as predictorspredictors.
And proceed with regression analysis …
Now. what happens if we include non-linear expressions of the continuous predictors, or break them up into categories, or add another predictor like gender or race, or … How Many Potential Models Would Exist Then?
Now. what happens if we include non-linear expressions of the continuous predictors, or break them up into categories, or add another predictor like gender or race, or … How Many Potential Models Would Exist Then?
The task appears reasonable until you until you begin to enumerate how many possible begin to enumerate how many possible models you can actually specify using models you can actually specify using just these few predictors …just these few predictors …
The task appears reasonable until you until you begin to enumerate how many possible begin to enumerate how many possible models you can actually specify using models you can actually specify using just these few predictors …just these few predictors …
Three models with a 1 main effectThree models with a 1 main effect
ii
ii
ii
SESILLCAUSEAGEILLCAUSEHEALTHILLCAUSE
10
10
10 ""
ii
ii
ii
SESILLCAUSEAGEILLCAUSEHEALTHILLCAUSE
10
10
10 ""
Three models with 2 main effects and 1 two-way interaction
Three models with 2 main effects and 1 two-way interaction
ii
ii
ii
SESAGESESAGEILLCAUSEAGEHEALTHSESHEALTHILLCAUSEAGEHEALTHAGEHEALTHILLCAUSE
3210
3210
3210
""""""""
ii
ii
ii
SESAGESESAGEILLCAUSEAGEHEALTHSESHEALTHILLCAUSEAGEHEALTHAGEHEALTHILLCAUSE
3210
3210
3210
""""""""
One model with 3 main effectsOne model with 3 main effects
ii SESAGEHEALTHILLCAUSE 3210 "" ii SESAGEHEALTHILLCAUSE 3210 ""
Three models with 2 main effectsThree models with 2 main effects
ii
ii
ii
SESAGEILLCAUSESESHEALTHILLCAUSEAGEHEALTHILLCAUSE
210
210
210
""""
ii
ii
ii
SESAGEILLCAUSESESHEALTHILLCAUSEAGEHEALTHILLCAUSE
210
210
210
""""
Three models with 3 main effects and 1 two-way interaction
Three models with 3 main effects and 1 two-way interaction
ii
ii
ii
SESAGESESAGEHEALTHILLCAUSESESHEALTHSESAGEHEALTHILLCAUSEAGEHEALTHSESAGEHEALTHILLCAUSE
43210
43210
43210
""""""""""
ii
ii
ii
SESAGESESAGEHEALTHILLCAUSESESHEALTHSESAGEHEALTHILLCAUSEAGEHEALTHSESAGEHEALTHILLCAUSE
43210
43210
43210
""""""""""
Three models with 3 main effects and 2 two-way interactions
Three models with 3 main effects and 2 two-way interactions
One model with 3 main effects and 3 two-way interactions
One model with 3 main effects and 3 two-way interactions
and so on ...and so on ...

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 6
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Really, How Big Is the Problem and How Can We Deal With It?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Really, How Big Is the Problem and How Can We Deal With It?
Number of feasible regression models that can possibly be specified
increases exponentially as the number of potential predictors rises.*
Number of feasible regression models that can possibly be specified
increases exponentially as the number of potential predictors rises.*
predictors of 5.141* numbere predictors of 5.141* numbere
“Initial” model contains main effect of the question
predictor HEALTH?
**
Second model adds the main effect of control
predictor AGE?
**Third model adds two-
way interaction of HEALTH and AGE?
**
Fourth model adds the main effect of control
predictor, SES? **
next?
You are here!
With one outcome and thirteen predictors …With one outcome and thirteen predictors …
The “universe of all possible models” contains 73,566,892 specifications.
The “universe of all possible models” contains 73,566,892 specifications.
It seems plausible to ask, then …What strategy can we use to identify a
subset of “essential” models”?
It seems plausible to ask, then …What strategy can we use to identify a
subset of “essential” models”?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 7
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Two Broad Strategies For Deciding Which Models To Specify And Fit
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Two Broad Strategies For Deciding Which Models To Specify And Fit
Two Broad Classes of Model-Specification StrategyTwo Broad Classes of Model-Specification Strategy
More Thoughtful Methods:More Thoughtful Methods: Use your knowledge of the research
question, the supporting substantive theory and logic to specify and fit a systematic taxonomy of regression models.
Make sure your decisions are driven by your need to answer specific research questions, to test reasonable hypotheses, and to tell a good story.
More Thoughtful Methods:More Thoughtful Methods: Use your knowledge of the research
question, the supporting substantive theory and logic to specify and fit a systematic taxonomy of regression models.
Make sure your decisions are driven by your need to answer specific research questions, to test reasonable hypotheses, and to tell a good story.
Example follows, using ILLCAUSE data:• Subsequently, we’ll use the same example to
refine our ability to conduct regression analyses by adding new tools:General linear hypothesis (GLH) test, Influence statistics, Innovations in residual analysis,Strategies for improving interpretation of fitted
models.
Example follows, using ILLCAUSE data:• Subsequently, we’ll use the same example to
refine our ability to conduct regression analyses by adding new tools:General linear hypothesis (GLH) test, Influence statistics, Innovations in residual analysis,Strategies for improving interpretation of fitted
models.
Well-known “Automated” Methods:Well-known “Automated” Methods:• Forward selection.• Backward elimination.• Stepwise regression.• All-possible-subsets regression.
I don’t recommend these methods at all:• Choice of models is abdicated to a computer.• Choice of each subsequent model can be strongly
impacted by inter-relationships among the predictors currently in the model and any potential additional predictors.
Please don’t ever use these methods, but do read about them in the post-class readings so that you can
recognize what to avoid!

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 8
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Example of Specifying a Sensible Taxonomy of Regression Models to Data
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Example of Specifying a Sensible Taxonomy of Regression Models to Data
Do children suffering from different types of chronic illness understand the causes of illness differently from
each other, and from healthy children?
Here starts the data-example – my illustrative data-analyses are contained in ...
Do children suffering from different types of chronic illness understand the causes of illness differently from
each other, and from healthy children?
Here starts the data-example – my illustrative data-analyses are contained in ...
Data-Analytic Handout I.1(a).1Data-Analytic Handout I.1(a).1 Available on class website. Features exploratory univariate and
bivariate analyses of the ILLCAUSE data.
Data-Analytic Handout I.1(a).1Data-Analytic Handout I.1(a).1 Available on class website. Features exploratory univariate and
bivariate analyses of the ILLCAUSE data.
Data-Analytic Handout I.1(a).2Data-Analytic Handout I.1(a).2 Available on class website. Features the fitting of a sensible taxonomy of
regression models to the ILLCAUSE data.
Data-Analytic Handout I.1(a).2Data-Analytic Handout I.1(a).2 Available on class website. Features the fitting of a sensible taxonomy of
regression models to the ILLCAUSE data.
A “Do it Yourself” PC-SAS Manual is available on the course website: Full_PCSAS_Manual.pdf. Trimmed_PCSAS_Manual.pdf.
A “Do it Yourself” PC-SAS Manual is available on the course website: Full_PCSAS_Manual.pdf. Trimmed_PCSAS_Manual.pdf.
All S052 Data-Analytic HandoutsAll S052 Data-Analytic Handoutscontain “model” PC-SAS Code and Statistical Outputcontain “model” PC-SAS Code and Statistical Output
I asked you to print these handouts out, and include them in your package of course materials for today’s class.
They will serve as “models” for your own future data-analyses, including our regular Data-Analytic Memos (DAMs), and your future research.
You should consult them carefully as you work on the DAM assignments.
A few programming comments follow …
All S052 Data-Analytic HandoutsAll S052 Data-Analytic Handoutscontain “model” PC-SAS Code and Statistical Outputcontain “model” PC-SAS Code and Statistical Output
I asked you to print these handouts out, and include them in your package of course materials for today’s class.
They will serve as “models” for your own future data-analyses, including our regular Data-Analytic Memos (DAMs), and your future research.
You should consult them carefully as you work on the DAM assignments.
A few programming comments follow …

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 9
S052/§I.1(a): Deciding Which Multiple Regression Models To FitAnnotated PC-SAS Code From The Exploratory Analysis
S052/§I.1(a): Deciding Which Multiple Regression Models To FitAnnotated PC-SAS Code From The Exploratory Analysis
OPTIONS Nodate Pageno=1; TITLE1 'S-052: APPLIED DATA ANALYSIS'; TITLE2 'I: Conducting Sensible Multiple Regression Analyses'; TITLE3 'I.1(a): Fitting Taxonomies of Multiple Regression Models'; TITLE4 'Handout #1: Introducing the Data'; TITLE5 'Understanding of Illness Causality and Chronic Illness in Children'; *-------------------------------------------------------------------------* Input data, name and label variables in dataset *-------------------------------------------------------------------------*; DATA ILLCAUSE; INFILE 'C:\DATA\S052\ILLCAUSE.txt'; INPUT ID ILLCAUSE SES PPVT AGE GENREAS HEALTH; IF HEALTH=3 OR HEALTH=5 OR HEALTH=6; LABEL ID = 'Subject Identification Code' ILLCAUSE = 'Understanding of Illness Causality' SES = 'Hollingshead SES' PPVT = 'Score on Peabody Picture Vocabulary Test' AGE = 'Chronological Age (Months)' GENREAS = 'General Reasoning Ability' HEALTH = 'Health Status'; PROC FORMAT; VALUE HFMT 3 = 'Diabetic' 5 = 'Asthmatic' 6 = 'Healthy';
OPTIONS Nodate Pageno=1; TITLE1 'S-052: APPLIED DATA ANALYSIS'; TITLE2 'I: Conducting Sensible Multiple Regression Analyses'; TITLE3 'I.1(a): Fitting Taxonomies of Multiple Regression Models'; TITLE4 'Handout #1: Introducing the Data'; TITLE5 'Understanding of Illness Causality and Chronic Illness in Children'; *-------------------------------------------------------------------------* Input data, name and label variables in dataset *-------------------------------------------------------------------------*; DATA ILLCAUSE; INFILE 'C:\DATA\S052\ILLCAUSE.txt'; INPUT ID ILLCAUSE SES PPVT AGE GENREAS HEALTH; IF HEALTH=3 OR HEALTH=5 OR HEALTH=6; LABEL ID = 'Subject Identification Code' ILLCAUSE = 'Understanding of Illness Causality' SES = 'Hollingshead SES' PPVT = 'Score on Peabody Picture Vocabulary Test' AGE = 'Chronological Age (Months)' GENREAS = 'General Reasoning Ability' HEALTH = 'Health Status'; PROC FORMAT; VALUE HFMT 3 = 'Diabetic' 5 = 'Asthmatic' 6 = 'Healthy';
Data-Analytic Handout I.1(a).1 …Data-Analytic Handout I.1(a).1 …
As many TITLEs as you like – the title text is in single quotes,
and ends in a semicolon
As many TITLEs as you like – the title text is in single quotes,
and ends in a semicolon
Comments can run over several lines – they start with an asterisk
and end with a semicolon
Comments can run over several lines – they start with an asterisk
and end with a semicolon
In the DATA step, raw data is read from an external file into a
temporary SAS dataset, here called ILLCAUSE
In the DATA step, raw data is read from an external file into a
temporary SAS dataset, here called ILLCAUSE
In this PROCedure, labels are created for the values of the
categorical HEALTH variable.
In this PROCedure, labels are created for the values of the
categorical HEALTH variable.
In the INPUT command,
variables are listed in the order they
appear in the dataset.
In the INPUT command,
variables are listed in the order they
appear in the dataset.
This IF statement selects out the
diabetic, asthmatic and healthy children.
This IF statement selects out the
diabetic, asthmatic and healthy children.
In the INFILE command, you specify the location of the raw data.
In the INFILE command, you specify the location of the raw data.

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 10
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting Exploratory Analysis S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting Exploratory Analysis
*-------------------------------------------------------------------------* List data for subsample of 30 cases *-------------------------------------------------------------------------*; PROC PRINT LABEL DATA=ILLCAUSE(obs=35); TITLE6 'Outcome and Predictor Values For the First 35 Children'; FORMAT HEALTH HFMT.; VAR ID ILLCAUSE AGE HEALTH SES;
*-------------------------------------------------------------------------* Display selected univariate and bivariate summary information *-------------------------------------------------------------------------*; PROC TABULATE DATA=ILLCAUSE; TITLE6 'Selected Univariate Summaries of ILLCAUSE, AGE and SES'; CLASS HEALTH; FORMAT HEALTH HFMT.; VAR ILLCAUSE AGE SES; TABLE (ILLCAUSE AGE SES)*(HEALTH ALL), N MEAN STD MIN MAX; PROC PLOT DATA=ILLCAUSE; TITLE6 'Bivariate Scatterplots for ILLCAUSE by AGE and SES'; PLOT ILLCAUSE*(AGE SES); PROC CORR NOSIMPLE DATA=ILLCAUSE; TITLE6 'Estimated Bivariate Correlations ...'; VAR ILLCAUSE AGE SES; RUN;
*-------------------------------------------------------------------------* List data for subsample of 30 cases *-------------------------------------------------------------------------*; PROC PRINT LABEL DATA=ILLCAUSE(obs=35); TITLE6 'Outcome and Predictor Values For the First 35 Children'; FORMAT HEALTH HFMT.; VAR ID ILLCAUSE AGE HEALTH SES;
*-------------------------------------------------------------------------* Display selected univariate and bivariate summary information *-------------------------------------------------------------------------*; PROC TABULATE DATA=ILLCAUSE; TITLE6 'Selected Univariate Summaries of ILLCAUSE, AGE and SES'; CLASS HEALTH; FORMAT HEALTH HFMT.; VAR ILLCAUSE AGE SES; TABLE (ILLCAUSE AGE SES)*(HEALTH ALL), N MEAN STD MIN MAX; PROC PLOT DATA=ILLCAUSE; TITLE6 'Bivariate Scatterplots for ILLCAUSE by AGE and SES'; PLOT ILLCAUSE*(AGE SES); PROC CORR NOSIMPLE DATA=ILLCAUSE; TITLE6 'Estimated Bivariate Correlations ...'; VAR ILLCAUSE AGE SES; RUN;
Print the first 35 cases for inspection and review
Print the first 35 cases for inspection and review
Add a sixth title to the output for this procedure
Add a sixth title to the output for this procedure
Format the values of the HEALTH variable, just for this procedure
Format the values of the HEALTH variable, just for this procedure
List the variables in the order you want them printing
List the variables in the order you want them printing
Inspect the bivariate relationships between outcome, ILLCAUSE,
and the two continuous controls, AGE & SES, by plotting the
values of the outcome against each predictor, in scatter-plots
Inspect the bivariate relationships between outcome, ILLCAUSE,
and the two continuous controls, AGE & SES, by plotting the
values of the outcome against each predictor, in scatter-plots
Create a tabulation of summary statistics (mean, standard deviation, minimum and maximum) for the
three continuous variables in the analysis -- ILLCAUSE (outcome), AGE and SES (control
predictors) – separately by the values of categorical (“CLASSification”) variable HEALTH.
Create a tabulation of summary statistics (mean, standard deviation, minimum and maximum) for the
three continuous variables in the analysis -- ILLCAUSE (outcome), AGE and SES (control
predictors) – separately by the values of categorical (“CLASSification”) variable HEALTH.
Estimate bivariate correlation coefficients to summarize the bivariate relationships between the outcome, ILLCAUSE, and the continuous
controls, AGE & SES
Estimate bivariate correlation coefficients to summarize the bivariate relationships between the outcome, ILLCAUSE, and the continuous
controls, AGE & SES
Don’t forget to “RUN”Don’t forget to “RUN”
Data-Analytic Handout I.1(a).1 …Data-Analytic Handout I.1(a).1 …

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 11
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Listing a Few Cases from the ILLCAUSE Datasest
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Listing a Few Cases from the ILLCAUSE Datasest
Subject Understanding Identification of Illness Chronological Health Hollingshead Obs Code Causality Age (Months) Status SES 1 301 . 128 Diabetic 2 2 302 2.857 79 Diabetic 2 3 303 3.429 151 Diabetic 3 4 304 4.286 178 Diabetic 3 5 305 4.286 113 Diabetic 4 6 306 3.286 81 Diabetic 2 7 307 2.857 194 Diabetic 4 ...
Subject Understanding Identification of Illness Chronological Health Hollingshead Obs Code Causality Age (Months) Status SES 1 301 . 128 Diabetic 2 2 302 2.857 79 Diabetic 2 3 303 3.429 151 Diabetic 3 4 304 4.286 178 Diabetic 3 5 305 4.286 113 Diabetic 4 6 306 3.286 81 Diabetic 2 7 307 2.857 194 Diabetic 4 ...
Notice that a period (.) is used in PC-SAS as the default
missing value code.
Notice that a period (.) is used in PC-SAS as the default
missing value code.
Notice that the children's values of SES are
heterogeneous and remember that higher
values mean lower SES!!!
Notice that the children's values of SES are
heterogeneous and remember that higher
values mean lower SES!!!
Notice the heterogeneous ages of the sampled children
(in months)
Notice the heterogeneous ages of the sampled children
(in months)
“Obs” represents the values of a SAS “system” variable, which counts and identifies the
observations in the order in which they appear in the temporary SAS dataset
“Obs” represents the values of a SAS “system” variable, which counts and identifies the
observations in the order in which they appear in the temporary SAS dataset
Selected output from Data-Analytic Handout I.1(a).1 … data for a few early casesSelected output from Data-Analytic Handout I.1(a).1 … data for a few early cases
The values of the outcome, ILLCAUSE, are listed here for each
child
The values of the outcome, ILLCAUSE, are listed here for each
child
Notice that the health status of the children has been reformatted by my PC-SAS program from a
numerical to an alphabetic label
Notice that the health status of the children has been reformatted by my PC-SAS program from a
numerical to an alphabetic label

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 12
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Tabulations of the ILLCAUSE Data
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Tabulations of the ILLCAUSE Data
Selected output from Data-Analytic Handout I.1(a).1 …
What four things do you What four things do you notice that may usefully notice that may usefully inform the subsequent inform the subsequent
regression analysis?regression analysis?
Selected output from Data-Analytic Handout I.1(a).1 …
What four things do you What four things do you notice that may usefully notice that may usefully inform the subsequent inform the subsequent
regression analysis?regression analysis?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 13
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Scatterplot of the ILLCAUSE/AGE Relationship
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Scatterplot of the ILLCAUSE/AGE Relationship
Scatterplot of the bivariate relationship between outcome ILLCAUSE and control predictor AGE:
What conclusions do you draw What conclusions do you draw from this plot that may usefully from this plot that may usefully inform subsequent regression inform subsequent regression
analysis?analysis?
Scatterplot of the bivariate relationship between outcome ILLCAUSE and control predictor AGE:
What conclusions do you draw What conclusions do you draw from this plot that may usefully from this plot that may usefully inform subsequent regression inform subsequent regression
analysis?analysis?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 14
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Scatterplot of the ILLCAUSE/SES Relationship
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Exploratory Bivariate Scatterplot of the ILLCAUSE/SES Relationship
Scatterplot of the bivariate relationship between outcome ILLCAUSE and control predictor SES:
What conclusions do you draw What conclusions do you draw from this plot that may usefully from this plot that may usefully inform subsequent regression inform subsequent regression
analysis?analysis?
Scatterplot of the bivariate relationship between outcome ILLCAUSE and control predictor SES:
What conclusions do you draw What conclusions do you draw from this plot that may usefully from this plot that may usefully inform subsequent regression inform subsequent regression
analysis?analysis?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 15
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit How To Create A Thoughtful Taxonomy Of Fitted Regression Models?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit How To Create A Thoughtful Taxonomy Of Fitted Regression Models?
Identify the outcome variable (here, ILLCAUSE) – this is usually not difficult.
Determine the “best” path through the universe of all possible regression models by deciding on an order that predictors must be added to the regression model.
Do this by establishing priorities among classes of predictors based on substance (the research questions and the theoretical framework), the research design, … etc.
For example, here’s one way of parsing out the problem … others appear in the appendices.
Identify the outcome variable (here, ILLCAUSE) – this is usually not difficult.
Determine the “best” path through the universe of all possible regression models by deciding on an order that predictors must be added to the regression model.
Do this by establishing priorities among classes of predictors based on substance (the research questions and the theoretical framework), the research design, … etc.
For example, here’s one way of parsing out the problem … others appear in the appendices.
Priority Predictor Comment
High HEALTH is the key question predictor.Without health status in the final model, we cannot address the research questions!
MediumAGE is a key control predictor because it represents the multi-cohort nature of the research design:
The sample contains multiple sub-samples of children of different ages. By controlling for AGE, we can include all children in the same analysis, regardless of their age, rather than doing an “age-slice by age-slice” analysis, as was suggested by one ill-informed reviewer!!!
LowSES is a subsidiary control predictor. It is often worth including because some twit will always ask you if it had an effect.
In these data, descriptive analyses suggest that ill children have lower SES. So, if understanding illness also depends on home resources, the effect of SES could masquerade as an effect of HEALTH.

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 16
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
Read the data into a temporary SAS dataset called ILLCAUSERead the data into a temporary SAS dataset called ILLCAUSE
Access the temporary SAS dataset, ILLCAUSE, a second time to manipulate the data prior to regression analysis
Access the temporary SAS dataset, ILLCAUSE, a second time to manipulate the data prior to regression analysis
Convert the categorical HEALTH status variable into a system of dummy
variables
Convert the categorical HEALTH status variable into a system of dummy
variables
Create a set of two-way HEALTH by AGE
interactions
Create a set of two-way HEALTH by AGE
interactions
Create a set of two-way HEALTH by SES
interactions
Create a set of two-way HEALTH by SES
interactions
Create an AGE by SES interactions
Create an AGE by SES interactions
Now, fit a taxonomy of regression models that takes into account the priorities you’ve established …here’s the DATA step from Data-Analytic Handout I.1(a).2 in which we first recode/create the variables we need …Now, fit a taxonomy of regression models that takes into account the priorities you’ve established …here’s the DATA step from Data-Analytic Handout I.1(a).2 in which we first recode/create the variables we need …

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 17
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
PROC REG is the PC-SAS
procedure for conducting
multiple regression analysis
PROC REG is the PC-SAS
procedure for conducting
multiple regression analysis
Begin by listing all variables that will be used in any regression model in order to ensure listwise deletion of cases with missing values
Begin by listing all variables that will be used in any regression model in order to ensure listwise deletion of cases with missing values
Optionally label each model so that you can
refer to it later
Optionally label each model so that you can
refer to it later
You can specify many regression models in one PROC REG “paragraph.”
You can specify many regression models in one PROC REG “paragraph.”
And here’s the PROC REG step …And here’s the PROC REG step …
Indicate that you are about to specify a regression model
Indicate that you are about to specify a regression model
Identify the variable that is the hypothesized outcomeIdentify the variable that is the hypothesized outcome
Specify the predictors you want included in each hypothesized model
Specify the predictors you want included in each hypothesized model
The categorical question predictor, HEALTH, is represented by only two of
the health status dummies: D (for diabetics) and A (for asthmatics). For a
discussion of this, see Appendix 1.
The categorical question predictor, HEALTH, is represented by only two of
the health status dummies: D (for diabetics) and A (for asthmatics). For a
discussion of this, see Appendix 1.

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 18
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Annotated PC-SAS Code For Conducting the Multiple Regression Analyses
What logic What logic drove the drove the specification of specification of the sequence of the sequence of models in the models in the taxonomy?taxonomy?
What logic What logic drove the drove the specification of specification of the sequence of the sequence of models in the models in the taxonomy?taxonomy?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 19
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Does Regular Multiple Regression Output Look Like?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit What Does Regular Multiple Regression Output Look Like?
Question …Can you navigate, and interpret, the contents of typical regression output?Question …Can you navigate, and interpret, the contents of typical regression output?
What hypothesis does this pair of statistics test?What hypothesis does this pair of statistics test?
Interpret the estimated intercept?
Interpret the estimated intercept?
What hypothesis does each of these pairs of statistics test?What hypothesis does each of these pairs of statistics test?
Conceptually, what is standard error?Conceptually, what is standard error?
Interpret the “Sum of Squares Error” or SSError statistic?Interpret the “Sum of Squares Error” or SSError statistic?
Interpret the R2 statistic?Interpret the R2 statistic?
Interpret the estimated coefficient associated with predictor D?
Interpret the estimated coefficient associated with predictor D?
Interpret the estimated coefficient associated with predictor A?
Interpret the estimated coefficient associated with predictor A?
Interpret the “Root MSE” statistic?Interpret the “Root MSE” statistic?
Interpret the “Sum of Squares Model” or SSModel statistic?Interpret the “Sum of Squares Model” or SSModel statistic?
Interpret the “Sum of Squares Total” or SSTotal statistic?Interpret the “Sum of Squares Total” or SSTotal statistic?

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 20
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Finally, Assemble The Taxonomy of Fitted Models Into An APA-Style Table
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Finally, Assemble The Taxonomy of Fitted Models Into An APA-Style Table
What are the critical What are the critical features of APA features of APA formatting for formatting for
tables?tables?
What are the critical What are the critical features of APA features of APA formatting for formatting for
tables?tables?
Consult the style Consult the style manuals manuals and
exemplars on the course website
Consult the style Consult the style manuals manuals and
exemplars on the course website
We’ll dissect this taxonomy, and interpret its substantive story, in subsequent classes ...We’ll dissect this taxonomy, and interpret its substantive story, in subsequent classes ...

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 21
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 1: Why Can Two Dummy Predictors Distinguish Among Three Groups?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 1: Why Can Two Dummy Predictors Distinguish Among Three Groups?
The first fitted regression model (M1) from Data-Analytic Handout I.1(a).1 (Slide #19) is:
From it, you can estimate the predicted value of ILLCAUSE in each health status group by substituting numerical values of the health status predictors that represent prototypical individuals in the dataset:
Notice that the predicted outcome values corresponding to one of the groups – the reference, omitted or comparison group (here, healthy children) – are obtained when the two dichotomous predictors that distinguish the chronically-ill children are both set to zero. This means that, if you have an intercept in the model, you need one less dummy predictor in the model than there are groups compared, as the fitted value for the “reference (or omitted) group” is provided by the estimated intercept.
Another way of thinking about this is to understand that, although there are three distinct health status groups present, only two independent pieces of information are needed to indicate the health status of a child because if a child is neither diabetic nor asthmatic then s/he must be healthy, by default.
Of course, you get to choose which of the health status groups serves as the reference, because you are the one who picks which dummy predictor is omitted from the regression model. Typically, you make this choice for substantive, not statistical, reasons.
iii ADUSEAILLC 94.084.060.4ˆ
76.394.060.4194.0084.060.4ˆ:
66.384.060.4094.0184.060.4ˆ:60.4094.0084.060.4ˆ:
i
i
i
USEAILLC1A0;D AsthmaticUSEAILLC0A1;D DiabeticUSEAILLC0A0;DHealthy

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 22
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 1: Why Can Two Dummy Predictors Distinguish Among Three Groups?
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 1: Why Can Two Dummy Predictors Distinguish Among Three Groups?
Inspection of the fitted values computed on the previous slide indicate that the fitted regression parameters that we obtained in the analysis – that is, the estimated intercept parameter and the two estimated slope parameters associated with the dummy predictors representing health status, can be interpreted as follows:
iii ADUSEAILLC 210ˆˆˆˆ
The fitted slope parameter associated with dummy
predictor A represents the difference in the predicted
value of ILLCAUSE between the asthmatic and
“reference” healthy children – it is our best estimate of
the difference between asthmatic and healthy
children, on average, in the population (-0.94).
The fitted slope parameter associated with dummy
predictor A represents the difference in the predicted
value of ILLCAUSE between the asthmatic and
“reference” healthy children – it is our best estimate of
the difference between asthmatic and healthy
children, on average, in the population (-0.94).
The fitted slope parameter associated with dummy
predictor D represents the difference in the predicted
value of ILLCAUSE between diabetic and “reference” healthy
children – it is our best estimate of the difference
between diabetic and healthy children, on
average, in the population (-0.84).
The fitted slope parameter associated with dummy
predictor D represents the difference in the predicted
value of ILLCAUSE between diabetic and “reference” healthy
children – it is our best estimate of the difference
between diabetic and healthy children, on
average, in the population (-0.84).
The fitted intercept represents the predicted
value of ILLCAUSE (4.60) for those in the reference
(or omitted) category –it is our best estimate of the
understanding of healthy children, on average, in the
population.
The fitted intercept represents the predicted
value of ILLCAUSE (4.60) for those in the reference
(or omitted) category –it is our best estimate of the
understanding of healthy children, on average, in the
population.

© Willett, Harvard University Graduate School of Education S052/I.1(a) – Slide 23
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 2: Other Strategies For Specifying Taxonomies Of Regression Models
S052/§I.1(a): Deciding Which Multiple Regression Models To Fit Appendix 2: Other Strategies For Specifying Taxonomies Of Regression Models
“Baseline Control Model” Approach:• Form a baseline control model, by sequentially adding
control predictors, highest priority first, and testing for appropriate interactions as you go along.
• Then, add the main effects of the question predictors to the new baseline control model.
• Then, add interactions between the question predictors and the control predictors in the baseline control model, sequentially.
• Finally, add interactions between the question predictors.
Here, the objective is to obtain a parsimonious model that controls away all extraneous variation first, and then focus attention on the impact of the question predictors. While this approach refines your view of the impact of the question predictors, removing that part of their effect that may depend on the inter-relationships with the controls, it never reveals the “total” impact of the question predictors on the outcome for a person who has been randomly selected from the population without regard to any of their other characteristics.
“Work Back From The End” Approach:• Include all possible predictors in the model, both their
main effects and interactions.• The, remove statistically unimportant predictors
sequentially to achieve a more parsimonious model, starting with those of lowest declared priority that do not appear to have statistically significant effects (i.e., remove question predictors last).
• Make sure that you remove any statistically unimportant ahead of any of the main effects from which they are constituted.
Here, the objective is to obtain a final parsimonious model by sequentially removing predictors that appear unimportant. The idea is that you get to see the impact of “everything” to start with, and then you can “slim down” the fitted model to a final model. However, the impact of main effects is always masked when interactions are present in the model, and you still may remove an important predictor whose correlation with another predictor makes it look unimportant.
Devise Your Own Strategy?• It’s acceptable to devise your own strategy, in fact it’s
probably the best approach as you know the field the best!.
It’s perfectly acceptable to devise your own strategy providing that it is systematic, sensible and that you explain it explicitly to your reader, describing the logic that underpins its construction.