Embed Size (px)
Citation preview

+
Protein and gene model inference based on statistical modeling in k-partite graphsSarah Gester, Ermir Qeli, Christian H. Ahrens, and Peter Buhlmann

+Problem Description
Given peptides and scores/probabilities, infer the set of proteins present in the sample.
PERFGKLMQK
MLLTDFSSAWCR
FFRDESQINNR
TGYIPPPLJMGKR
Protein A
Protein B
Protein C

+Previous Approaches
N-peptides rule
ProteinProphet (Nesvizhskii et al. 2003. Anal Chem) Assumes peptide scores are correct.
Nested mixture model (Li et al. 2010. Ann Appl Statist) Rescores peptides while doing the protein inference Does not allow shared peptides Peptide scores are independent
Hierarchical statistical model (Shen et al. 2008. Bioinformatics) Allows for shared peptides Assume PSM scores for the same peptide are independent Impractical on normal datasets
MSBayesPro (Li et al. 2009. J Comput Biol) Uses peptide detectabilities to determine peptide priors.

+Markovian Inference of Proteins and Gene Models (MIPGEM)
Inclusion of shared/degenerate peptides in the model.
Treats peptide scores/probabilities as random values
Model allows dependence of peptide scores.
Inference of gene models

+Why scores as random values?
PERFGKLMQK
MLLTDFSSAWCR
FFRDESQINNR
TGYIPPPLJMGKR
Protein A
Protein B
Protein C

+Building the bipartite graph

+Shared peptides

+Definitions
Let pi be the score/probabilitiy of peptide i. I is the set of all peptides.
Let Zj be the indicator variable for protein j. J is the set of all proteins.
€
P[Z j =1 |{pi;i ∈ I}]

+Simple Probability Rules
€
P(A | B) =P(A,B)
P(B)=
P(B | A)P(A)
P(B)
€
P(A,B) = P(A | B)P(B) = P(B | A)P(A)
€
P(A) = P(A,B = b)b
∑
€
P(A = a | B)a
∑ =1

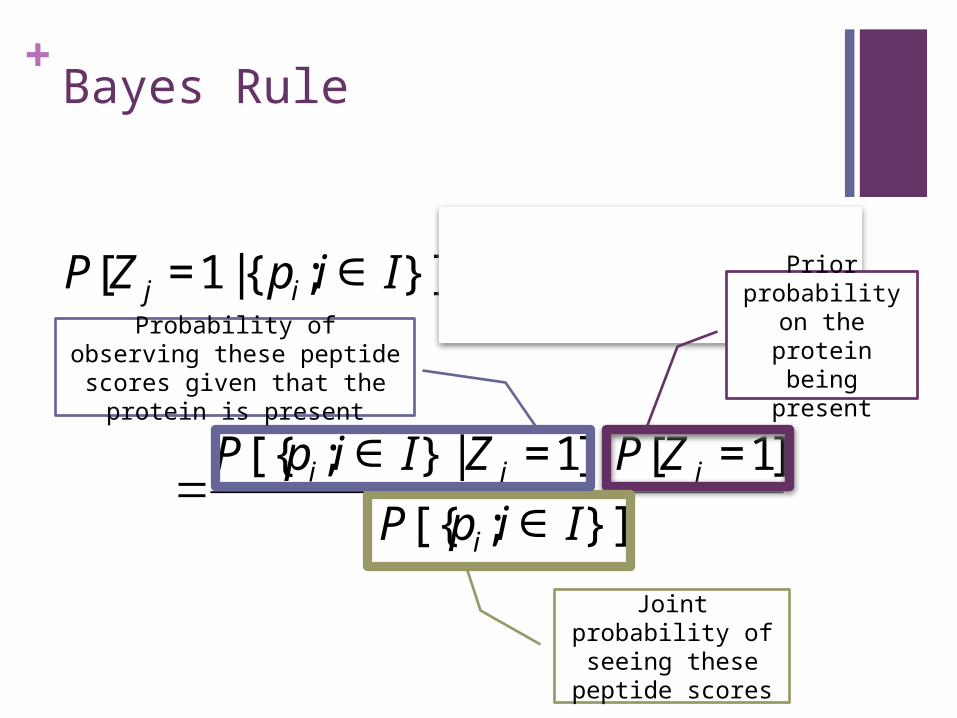
+Bayes Rule
€
P[Z j =1 |{pi;i ∈ I}] =P[Z j =1,{pi;i ∈ I}]
P[{pi;i ∈ I}]
€
=P[{pi;i ∈ I} | Z j =1]⋅P[Z j =1]
P[{pi;i ∈ I}]
Prior probability on
the protein being present
Joint probability of seeing these peptide scores
Probability of observing these peptide scores given that the protein is present

+Assumptions
Prior probabilities of proteins are independent
Dependencies can be included with a little more effort.
This does not mean that proteins are independent.€
P[{Z j ; j ∈ J}] = P(Z j )j∈J
∏

+Assumptions
Connected components are independent

+Assumptions
Peptide scores are independent given their neighboring proteins. Ne(i) is the set of proteins connected to peptide i in the
graph. Ir is the set of peptides belonging to the rth connected
component R(Ir) is the set of proteins connected to peptides in Ir
€
P[{pi;i ∈ I} |{Z j; j ∈ R(Ir )}] = P[ pi |{Z j ; j ∈ Ne(i)}]i∈I r
∏

+Assumptions
Conditional peptide probabilities are modeled by a mixture model. The specific mixture model they use is based on the
peptide scores used (from PeptideProphet).
+Bayes Rule
€
P[Z j =1 |{pi;i ∈ I}] =P[Z j =1,{pi;i ∈ I}]
P[{pi;i ∈ I}]
€
=P[{pi;i ∈ I} | Z j =1]⋅P[Z j =1]
P[{pi;i ∈ I}]
Prior probability on
the protein being present
Joint probability of seeing these peptide scores
Probability of observing these peptide scores given that the protein is present

+Joint peptide score distribution
Assumption: peptides in different components are independent
Ir is the set of peptides in component r
R(Ir) is the set of proteins connected to peptides in Ir
€
P({pi;i ∈ I}) = P({pi;i ∈ Ir})r=1
R
∏
€
P({pi;i ∈ Ir}) = P({pi;i ∈ Ir} |{Z j; j ∈ R(Ir )})P({Z j; j ∈ R(Ir )})Z j ∈{0,1}j∈R (I r )
∑

+Conditional Probability
Mixture model
€
P( pi |{Z j ; j ∈ Ne(i)}) ≈
1
u − lif Z j = 0
j∈Ne( i)
∑
f1(pi) if Z j > 0j∈Ne( i)
∑
⎧
⎨ ⎪ ⎪
⎩ ⎪ ⎪
l =i
min(pi)
m =i
median (pi)
u =i
max(pi)

+Conditional Probability
Mixture model
€
f1(x) =b1(x − l) l ≤ x ≤ m
(b1 + b2)(x − m) + b1(m − l) m < x ≤ u
⎧ ⎨ ⎩
l =i
min(pi)
m =i
median (pi)
u =i
max(pi)
€
f1(x)dx =1l
u
∫
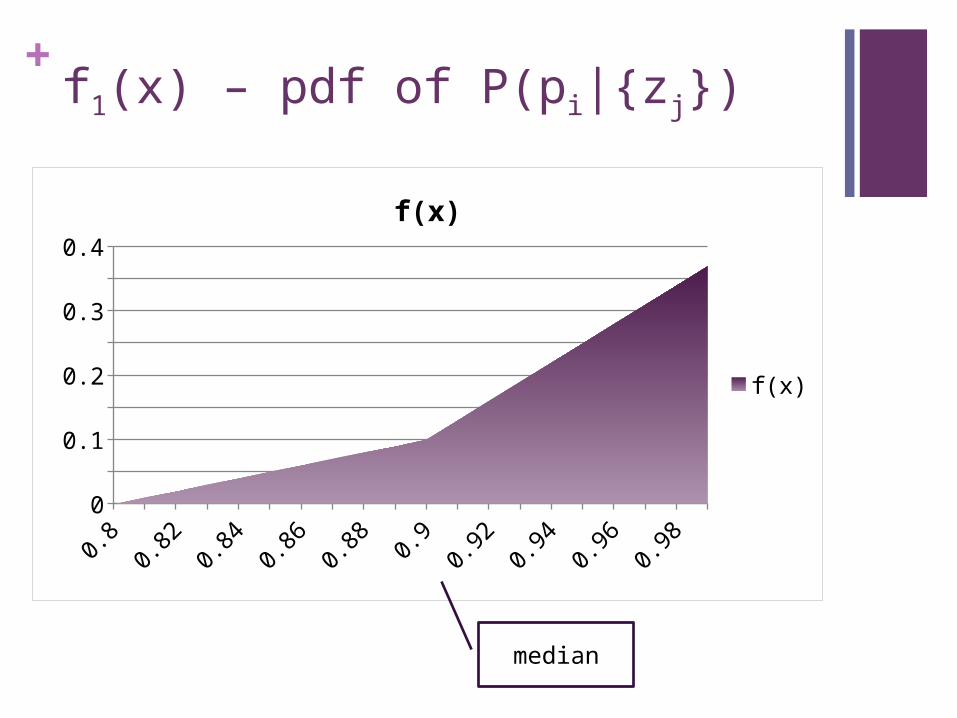
+f1(x) – pdf of P(pi|{zj})
0.8
0.82
0.84
0.86
0.88 0.
90.
920.
940.
960.
980
0.050.1
0.150.2
0.250.3
0.350.4
f(x)
f(x)
median

+Choosing b1 and b2
Seek to maximize the log likelihood of observing the peptide scores.
€
l = log(P({pi;i ∈ I})) = log P({pi;i ∈ Ir
r=1
R
∏ }) ⎛
⎝ ⎜
⎞
⎠ ⎟
€
l = log(P({pi;i ∈ Ir}))r=1
R
∑
€
l = log P( pi |{Z j = z; j ∈ Ne(i)}i∈I r
∏z∈{0,1}j∈R (I r )
∑ ) ⋅ P(Z j = z)j∈R (I r )
∏ ⎛
⎝
⎜ ⎜ ⎜
⎞
⎠
⎟ ⎟ ⎟r=1
R
∑

+Choosing b1 and b2
It turns out:
€
ˆ b 1 =b1
argmin − l (b1)
ˆ b 2 =2 − ˆ b 1(u − l)2
(u − m)2

+Conditional Protein Probabilities
€
P[Z j =1 |{pi;i ∈ I}] =P[Z j =1,{pi;i ∈ I}]
P[{pi;i ∈ I}]
€
=P[{pi;i ∈ I} | Z j =1]⋅P[Z j =1]
P[{pi;i ∈ I}]

+Conditional Protein Probabilities
€
P(Z j =1 |{pi;i ∈ I}) =P[{pi;i ∈ I} | Z j =1]⋅P[Z j =1]
P[{pi;i ∈ I}]
€
=
P[{pi;i ∈ I} | Z j =1,Zk = z]⋅P[Z j =1,Zk = z]k∈R(I d ( j ) )
∑
P[{pi;i ∈ I}]
€
=A(1)
P[{pi;i ∈ I}]

+Conditional Protein Probabilities(NEC Correction)
€
P(Z j =1 |{pi;i ∈ I}) =P[{pi;i ∈ I} | Z j =1]⋅P[Z j =1]
P[{pi;i ∈ I}]
€
=
P[{pi;i ∈ I} | Z j =1,{Zk;k ≠ j}) ⋅P[Z j =1,{Zk;k ≠ j}]zk ∈{0,1}
∑
P[{pi;i ∈ I}]
€
=A(1)
P[{pi;i ∈ I}]

+Conditional Protein Probabilities
€
P(Z j =1 |{pi;i ∈ I}) =A(1)
P[{pi;i ∈ I}]
€
P(Z j = 0 |{pi;i ∈ I}) =A(0)
P[{pi;i ∈ I}]

+Conditional Protein Probabilities
€
P(Z j =1 |{pi;i ∈ I}) + P(Z j = 0 |{pi;i ∈ I}) =1
€
A(0)
P({pi;i ∈ I})+
A(1)
P({pi;i ∈ I})=
A(1) + A(0)
P({pi;i ∈ I})=1
€
A(1) + A(0) = P({pi;i ∈ I})

+Conditional Protein Probabilities
€
P(Z j =1 |{pi;i ∈ I}) =A(1)
P[{pi;i ∈ I}]=
A(1)
A(0) + A(1)
€
P(Z j = 0 |{pi;i ∈ I}) =A(0)
P[{pi;i ∈ I}]=
A(0)
A(0) + A(1)

+Shared Peptides
€
Aunshared (1) = P[{pi;i ∈ IA} | Z1 =1,Zk = z]⋅P[Z1 =1,Zk = z]k∈R (I A )
∑
€
Aunshared (1) = P[{pi;i ∈ IA} | Z1 =1]⋅P[Z1 =1]

+
€
Ashared (1) = P[{pi;i ∈ IB} | Z1 =1,Zk = z]⋅P[Z1 =1,Zk = z]k∈R (I B )
∑
€
Ashared (1) = P[{pi;i ∈ IB} | Z1 =1,Z2 =1]⋅P[Z1 =1]⋅P[Z2 =1] +
P[{pi;i ∈ IB} | Z1 =1,Z2 = 0]⋅P[Z1 =1]⋅P[Z2 = 0]
Shared Peptides

+Shared Peptides
If the shared peptide has pi ≥ median
€
Punshared[Z1 =1 |{pi;i ∈ I}] ≥ Pshared[Z1 =1 |{pi;i ∈ I}]
€
Punshared[Z1 = 0 |{pi;i ∈ I}] ≤ Pshared[Z1 = 0 |{pi;i ∈ I}]

+Shared Peptides
If the shared peptide has pi < median
€
Punshared[Z1 =1 |{pi;i ∈ I}] < Pshared[Z1 =1 |{pi;i ∈ I}]
€
Punshared[Z1 = 0 |{pi;i ∈ I}] > Pshared[Z1 = 0 |{pi;i ∈ I}]

+Gene Model Inference

+Gene Model Inference
Assume a gene model, X, has only protein sequences which belong to the same connected component.
Peptide 1
Peptide 2
Peptide 3
Peptide 4
Protein A
Protein B
Gene X

+Gene Model Inference
Assume a gene model, X, has only protein sequences which belong to the same connected component.
R(X) is the set of proteins with edges to X.
Ir(X) is the set of peptides with edges to proteins with edges to X
€
P[X =1 |{pi;i ∈ I}] =1− P {Z j = 0} |{pi;i ∈ Ir(X )}j∈R (X )I
⎡
⎣ ⎢
⎤
⎦ ⎥

+Gene Model Inference
Gene model, X, has proteins from different connected components of the peptide-protein graph.
Peptide 1
Peptide 2
Peptide 3
Peptide 4
Protein A
Protein B
Gene X

+Gene Model Inference
Gene model, X, has proteins from different connected components of the peptide-protein graph.
Rl(X) is the set of proteins with edges to X in component l.
Il(X) is the set of peptides with edges to proteins with edges to X in component l.
€
P {Z j = 0} |{pi;i ∈ Ir(X )}j∈R(X )I
⎡
⎣ ⎢
⎤
⎦ ⎥= P {Z j = 0} |{pi;i ∈ Il (X )}
j∈R l (X )I
⎡
⎣ ⎢
⎤
⎦ ⎥
l =1
m
∏

+Datasets
Mixture of 18 purified proteins
Mixture of 49 proteins (Sigma49)
Drosophila melanogaster
Saccharomyces cerevisiae (~4200 proteins)
Arabidopis thaliana (~4580 gene models)

+Comparisons with other tools
Small datasets with a known answerMix of 18 proteins
Sigma49

+
Sigma49
Comparisons with other tools
One hit wonders
Sigma49 no one hit wonders

+Comparison with other tools
Arabidopsis thaliana dataset has many proteins with high sequence similarity.

+Splice isoforms

+Conclusion +Criticism
Developed a model for protein and gene model inference.
Comparisons with other tools do not justify complexity: Value of a small FP rate at the expense of many FN is not
shared for all applications.
Discard some useful information such as #spectra/peptide
Assumptions of parsimony from pruning may be too aggressive.






















