Embed Size (px)
Citation preview

+
Hbase: Hadoop DatabaseB. Ramamurthy

+Motivation-0
Think about the goal of a typical application today and the data characteristics
Application trend: Search Analytics
Simple get from a database provide the primary key get the row; traditional RDBMS is optimized for this normalized tables multiple indices etc. NULLs are expensive
Analytics huge number of rows accessed efficiently To supply analytic algorithms with big-data inherently denormalized multiple versions eg. time series NULLs are typical/norm…very common

+Motivation-1
HDFS itself is “big”
Why do we need “hbase” that is bigger and more complex?
Word count, web logs …are simple compared to web pages…consider what a web crawler encounters…
http://www.cse.buffalo.edu
http://www.math.buffalo.edu/index.shtml

+Introduction
Persistence is realized (implemented) in traditional applications using Relational Database Management System (RDBMS) Relations are expressed using tables and data is normalized Well-founded in relational algebra and functions Related data are located together
However social relationship data and network demand different kind of data representation Relationships are multi-dimensional Data is by choice not normalized (i.e, inherently redundant) Column-based tables rather than row-based (Consider Friends
relation in Facebook) Sparse table
Solution is Hbase: Hbase is database built on HDFS

+Motivation-2
Google: GFS Big Table Colossus
Facebook: HDFSHive Cassandra Hbase
Yahoo: HDFS Hbase
To source a MR workflow and to sink the output of MR workflow;
To organize data for large scale analytics
To organize data for querying
To organize data for warehousing; intelligence discovery
NO-SQL (see salesforce.com)
Compare storing a Bank Account details and a Facebook User Account details

+Hbase
Hbase reference : http://hbase.apache.org
Main concept: millions of rows and billions of columns on top of commodity infrastructure (say, HDFS)
Hbase is a data repository for big-data
It can be a source and sink to HDFS workflow
Hbase includes base classes for supporting and backing MR workflows, Pig and Hive as sink as well as source
HBASE
HDFS
HBASE

+When to use Hbase?
When you need high volume data to be stored
Un-structured data
Sparse data
Column-oriented data
Versioned data (same data template, captured at various time, time-elapse data)
When you need high scalability (you are generating data from an MR workflow: you need to store sink it somewhere…)
When you have long rows that a table needs to be split within a traditional row…shrading into horizontal partition.

+Hbase: A Definitive Guide
By George Lars
Online version available
Also look at http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html
+
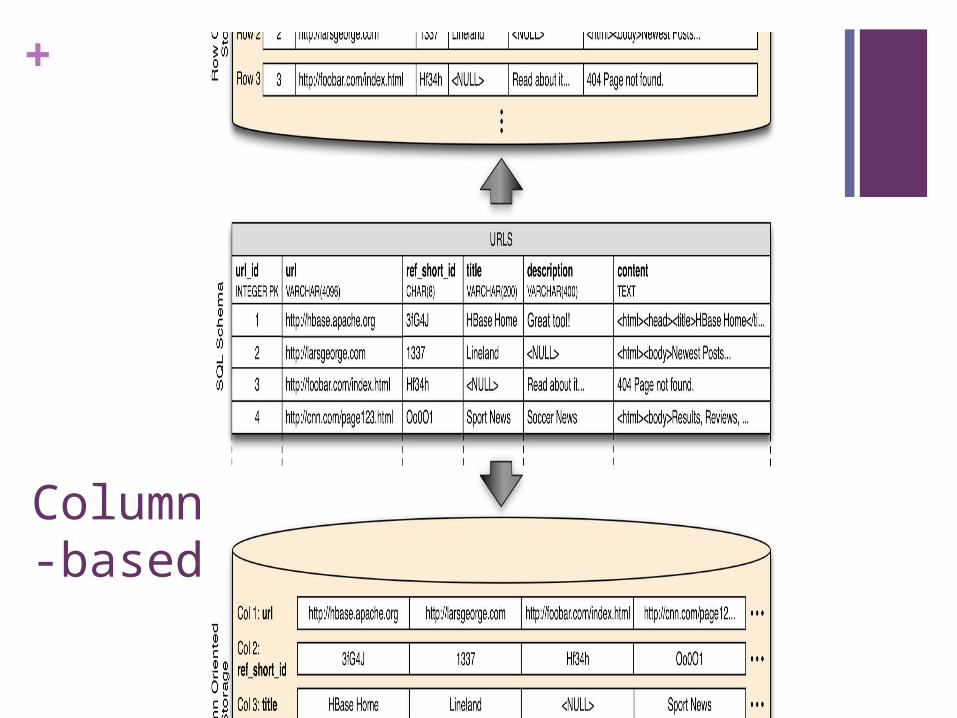
Column-based
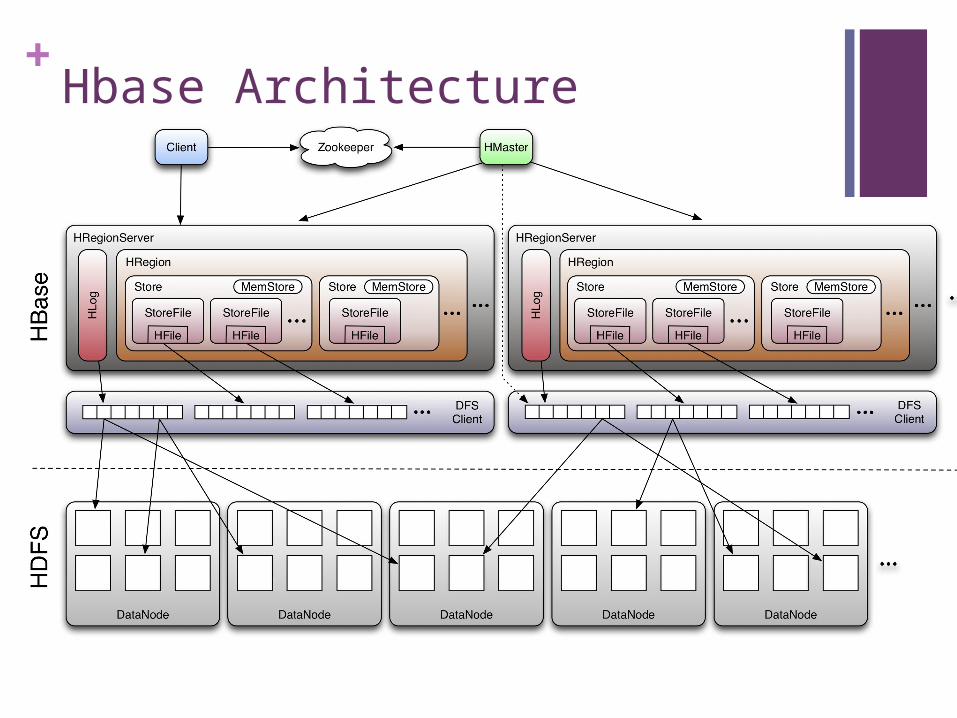
+Hbase Architecture

+Data Model
http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html
Table
Row# is some uninterrupted number
Column Families (courses: mth309, courses:cse241)
Region
Region File

Hardware
HDFS
HBASE
Operating Sys
Client Htable MR Client Htable
Applications: Google Earth
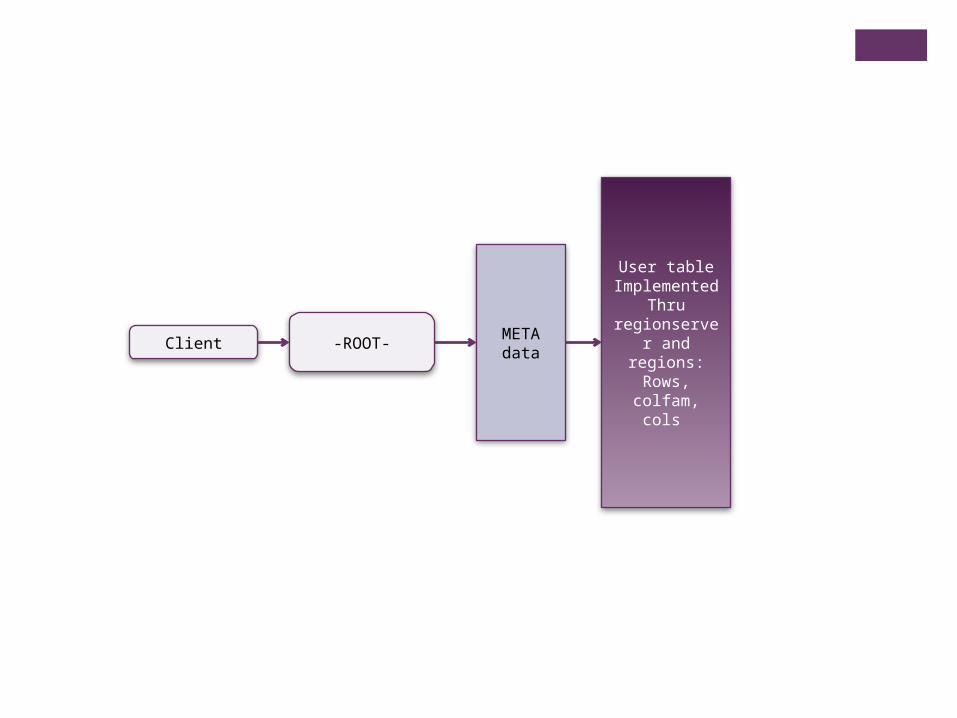
Client -ROOT-METAdata
User tableImplemented
Thru regionserver and regions:
Rows, colfam, cols
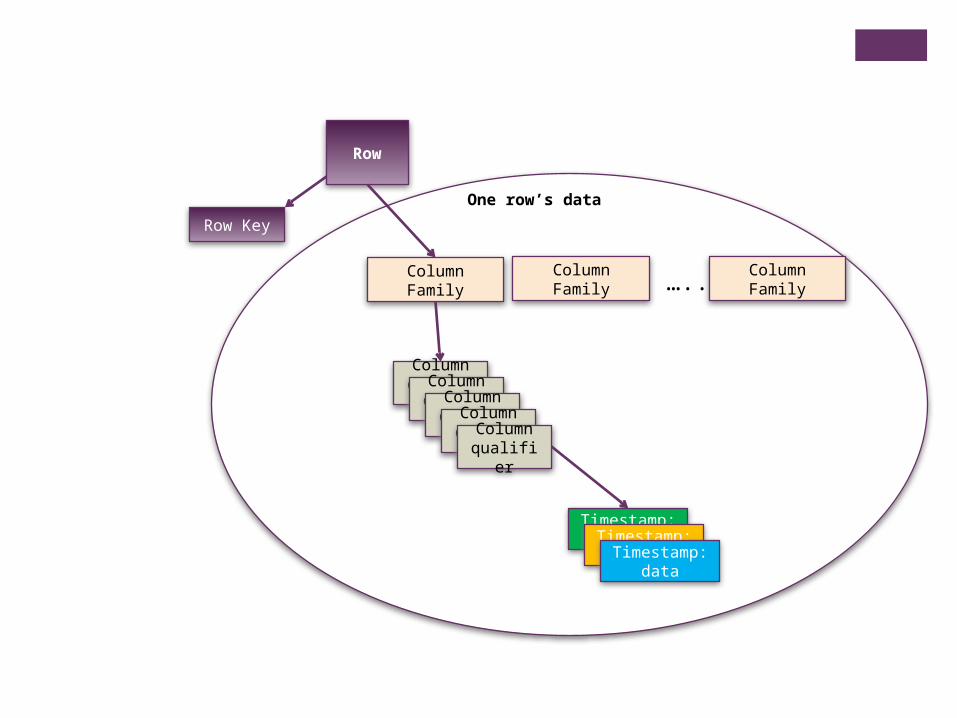
Row
Row Key
Column Family Column Family Column Family…..
ColumnqualifierColumn
qualifierColumnqualifierColumn
qualifier
Timestamp: data
Columnqualifier
Timestamp: dataTimestamp:
data
One row’s data
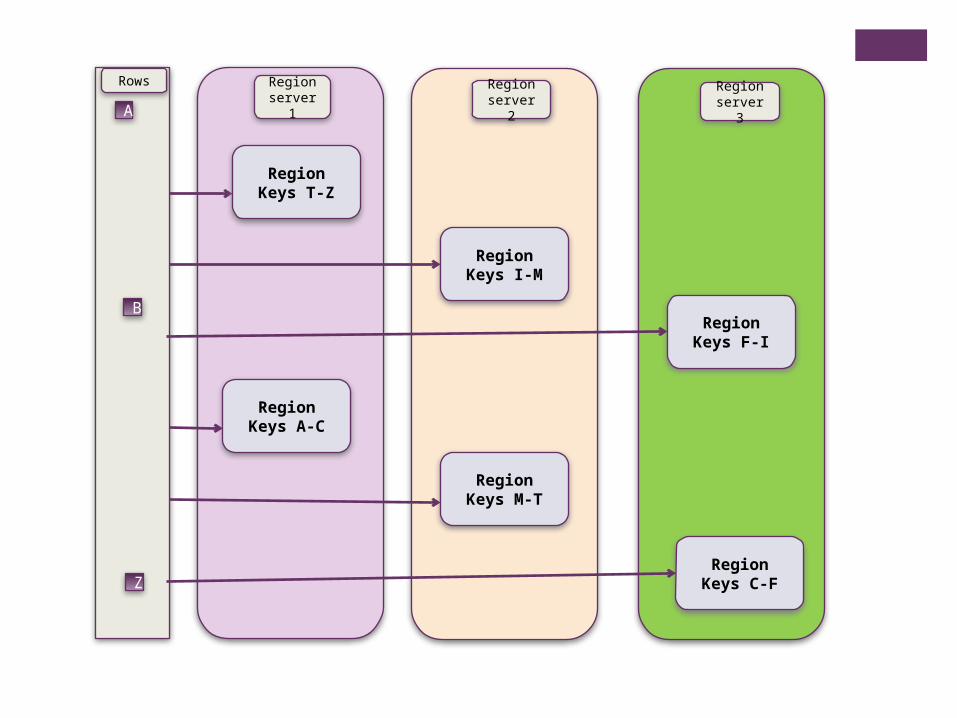
A
B
Z
Rows
RegionKeys T-Z
RegionKeys I-M
RegionKeys A-C
RegionKeys F-I
RegionKeys M-T
RegionKeys C-F
Region server1
Region server 2
Region server 3

HDFS Zookeeper
Hbase API
Master
RegionServer
HFile
Memstore
Write-ahead Log
Big-data application: EMR, healthcare, health exchanges





























