Embed Size (px)
Citation preview

INDEX- 善用索引

WHAT IS “INDEX”
EX: 圖書館的索書編號
索引的結構 LIKE Balance Tree
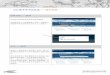
叢集索引 & 非叢集索引
Clustered v.s. Non-clustered Clustered
ID Product Price Manufacturer
1023 電冰箱 8700 日立1101 電暖器機 1900 日立1244 電腦 43000 愛買1300 除濕機 1500 大同1632 吹風機 350 鬼屋
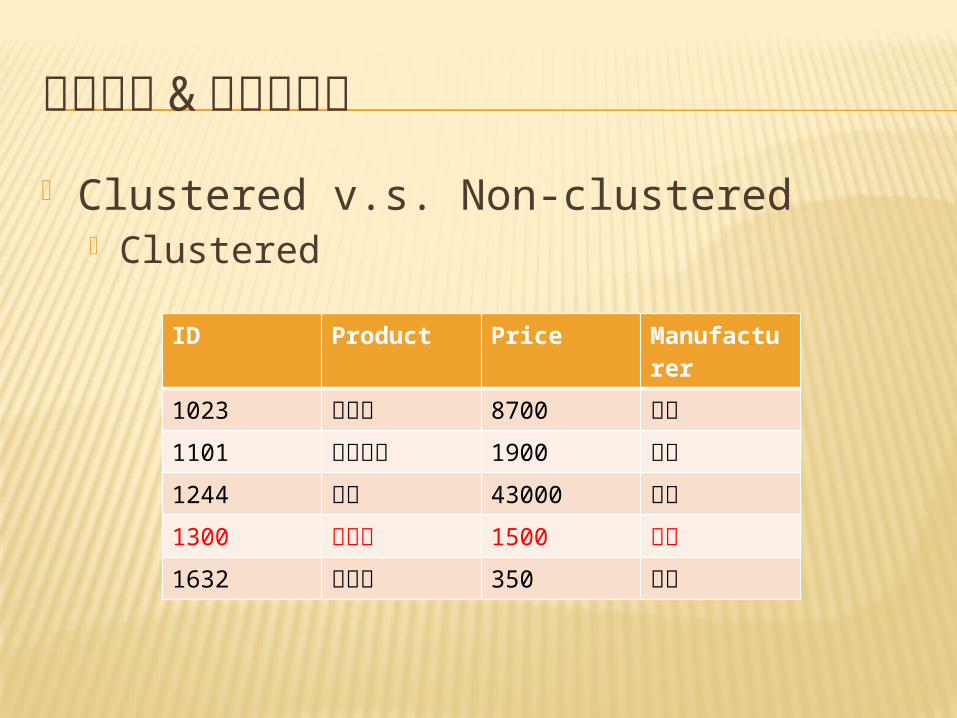
叢集索引 & 非叢集索引 CONT.
• Clustered v.s. Non-clustered– Non-Clustered
ID Product Price Manufacturer
1023 電冰箱 8700 日立1101 電暖器機 1900 日立1244 電腦 43000 愛買1632 吹風機 350 鬼屋1300 除濕機 1500 大同

UNIQUE
In Clustered &Non-clustered 唯一索引 (Unique index)
任何兩筆紀錄的索引值不可相同 最常用在 Primary Key 的欄位上 建議同時 NOT NULL

COMPOSITE
兩個或多個欄位組合成為索引(Composite index)
若同時是唯一索引,則不可重複的是 ?

自動設立非索引叢集的唯一索引
CREATE TABLE TABLE_1 ( ProductID smallint NOT NULL, ProductName char(30) UNIQUE, Price smallmoney, Manufacturer char(30) )

屬性表
包含的資料行 包含索引外的其他欄位
忽略重複的索引欄位 無論是否都拒絕重複值
重新計算統計資料 索引變動時是否自動更新
索引頁預留空間 填滿因數
末節點所使用的空間百分比

PRIMARY KEY DEMO
CREATE TABLE TABLE_2 ( ProductID smallint NOT NULL Primary
Key, ProductName char(30), Price smallmoney, Manufacturer char(30) )

建立索引的注意事項
一個資料表只能有 1 個叢集索引 可組合多個欄位
索引最多使用十六個欄位 總長度需在 900 byte 之內 一個資料表最多 249 個非叢集索引 內容少時不建議使用 primary key 以外的索引,
會浪費時間空間成本 同質性高的欄位不適合成為索引 EX: 性別

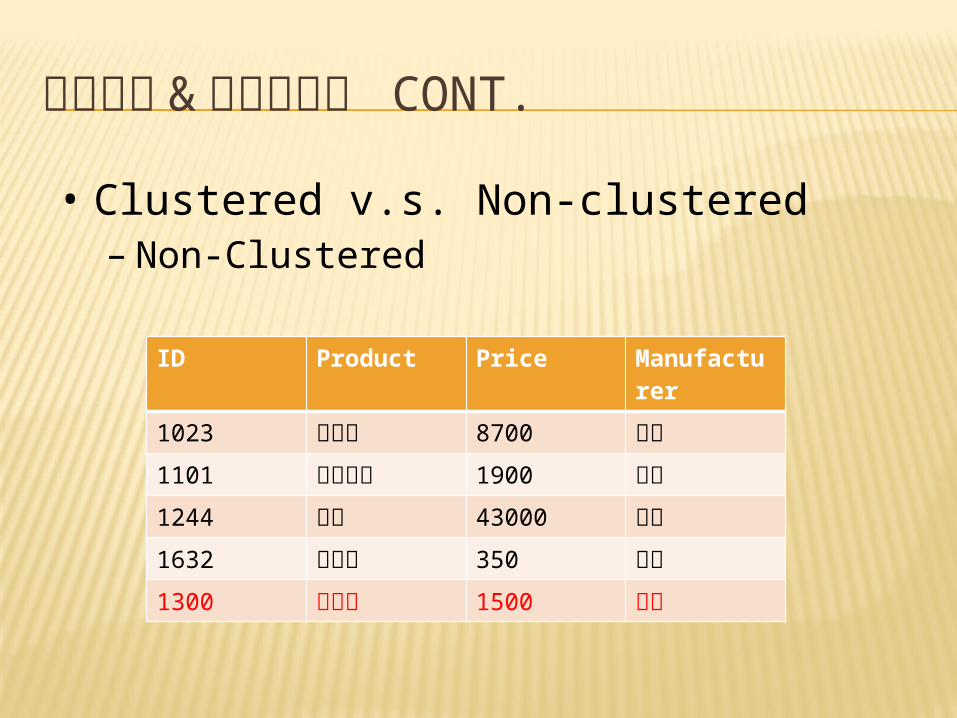
建立索引 語法
CREATE INDEX Index_name ON table_name (column1,…..)
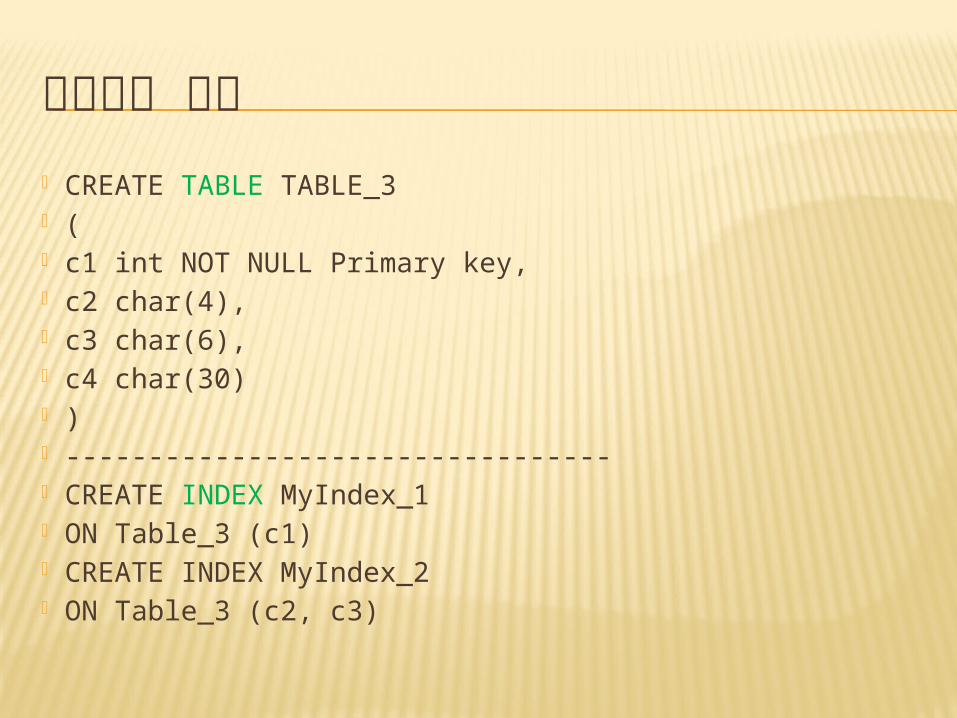
建立索引 語法 CREATE TABLE TABLE_3 ( c1 int NOT NULL Primary key, c2 char(4), c3 char(6), c4 char(30) ) --------------------------------- CREATE INDEX MyIndex_1 ON Table_3 (c1) CREATE INDEX MyIndex_2 ON Table_3 (c2, c3)

進階建立索引
CREATE [Unique] -- 指定唯一[CLUSTERED| NONCLUSTERED] -- 叢集與否INDEX Index_nameON table_name (column1[ASC|DESC][,….. n]) -- 指定升降冪[Include(column[…,n])] -- 將其他資料行包含於此索引內[WITH [PAD_INDEX] -- 索引頁面預留空間[,FillFactor = x] – 填滿因數[,Ignore_DUP_Key] – 忽略重複值[,Drop_Existing] – 忽略現成的索引[,Statistics_NoRecompute] -- 不重新計算統計值[ON FileGroup] – 儲存的檔案群組

進階建立索引
CREATE TABLE TABLE_4 ( ProductID smallint NOT NULL Primary Key, ProductName char(30), Price smallmoney, Manufacturer char(30) )
CREATE UNIQUE NONCLUSTERED INDEX index_3 ON TABLE_4 (ProductName) INCLUDE (price) WITH PAD_INDEX, FILLFACTOR=30, IGNORE_DUP_KEY
EXEC sp_helpindex table_4

刪除索引
DROP INDEX Table_Name.index_name
DROP INDEX Table_4.index_3

刪除索引 CONT.
CREATE TABLE MyTable ( ProductID smallint NOT NULL Primary key, ProductName char(30) UNIQUE, Price smallmoney, Manufacturer char(30) )
EXEC sp_helpindex MyTable
---A
DROP INDEX MyTable.PK__MyTable__7D439ABD DROP INDEX MyTable.UQ__MyTable__7E37BEF6
--- B
ALTER TABLE MyTable DROP CONSTRAINT PK__MyTable__7D439ABD ALTER TABLE MyTable DROP CONSTRAINT UQ__MyTable__7E37BEF6

修改或重建索引
DROP_EXISTING => 代替原來已存在的索引 ( 建議使用 )
維持原來索引的名稱,針對要改的細項做更改即可

重建索引 DBCC DBREINDEX
(‘DataBaseName.Schema.table_name’,Index_Name, FillFactor)
[WITH NO_INFOMSGS] -- 不顯示訊息
EX:DBCC DBREINDEX ( 客戶 , PK_ 客戶 ,70)

替檢視表建立索引 SET ARITHABORT, CONCAT_NULL_YIELDS_NULL, QUOTED_IDENTIFIER, ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS ON SET NUMERIC_ROUNDABORT OFF GO
CREATE VIEW dbo.產品日報 WITH SCHEMABINDING AS SELECT 下單日期 AS 日期, 書籍編號 AS 書號, SUM (數量) AS 每日銷售量, COUNT_BIG (*) AS 每日訂單數 FROM dbo.訂單 INNER JOIN dbo.訂購項目 ON 訂單.訂單編號 = 訂購項目.訂單編號 GROUP BY 下單日期, 書籍編號 GO
SELECT * FROM 產品日報

替檢視表建立唯一性叢集索引
CREATE UNIQUE CLUSTERED INDEX PK_產品日報
ON 產品日報 ( 日期 , 書號 )

建立非叢集索引
CREATE INDEX IX_ 書號 ON 產品日報 ( 書號 ) INCLUDE ( 日期 , 每日銷售量 )

索引查詢範例 ---使用主索引查詢SELECT 日期 , 書號 , 每日銷售量 , 每日訂單數 FROM 產品日報WHERE 日期 = '2005/9/11' ORDER BY 日期
---直接在VIEW以書號抓資料
SELECT 日期 , 書號 , 每日銷售量FROM 產品日報WHERE 書號 = 2
---直接在VIEW以PK去抓資料
SELECT 下單日期 , SUM(數量) AS 銷售量 FROM 訂單 INNER JOIN 訂購項目ON 訂單 .訂單編號 = 訂購項目 .訂單編號GROUP BY 下單日期 , 書籍編號ORDER BY 下單日期

刪除檢視表的索引
當刪除了檢視表中的主索引時,所有的非叢集索引會一併刪除 !