Embed Size (px)
Citation preview

© 2010 IBM Corporation
Code Alignment for Architectures with Pipeline Group Dispatching
Helena Kosachevsky, Gadi Haber, Omer Boehm
Code Optimization Technologies IBM Research – Haifa

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Agenda
Background
Code alignment algorithm–General concepts, code chains–Genetic algorithm
Code alignment for Power 6–Architecture specifics–Evaluation strategies
Results

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Background
Proper code placement strongly impacts –instruction cache performance–branch prediction–instruction fetch mechanism
Previous works– not many sees code alignment as a code chains placement without
reordering, using padding of a certain size– used as a complementary optimization, producing mixed results
We propose a profile-guided generic optimization algorithm, producing stable performance gain

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Code Alignment Algorithm – general concepts
Code chain - is a code sequence which is executed more or less continuously with no significant differences in its instructions frequency
Satisfies one of the following properties:–Terminates with unconditional jump or branch via register–Terminates with a conditional branch whose fallthru is taken
infrequently

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Code Alignment Algorithm – working on chains
Aligns each chain by inserting non-executable padding between the chains
Working on chains, not basic blocks, – limits code inflation
Profile allows to focus on frequently executed chains – avoid long run time and code inflation
Tries to determine the best position for each given chain
© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
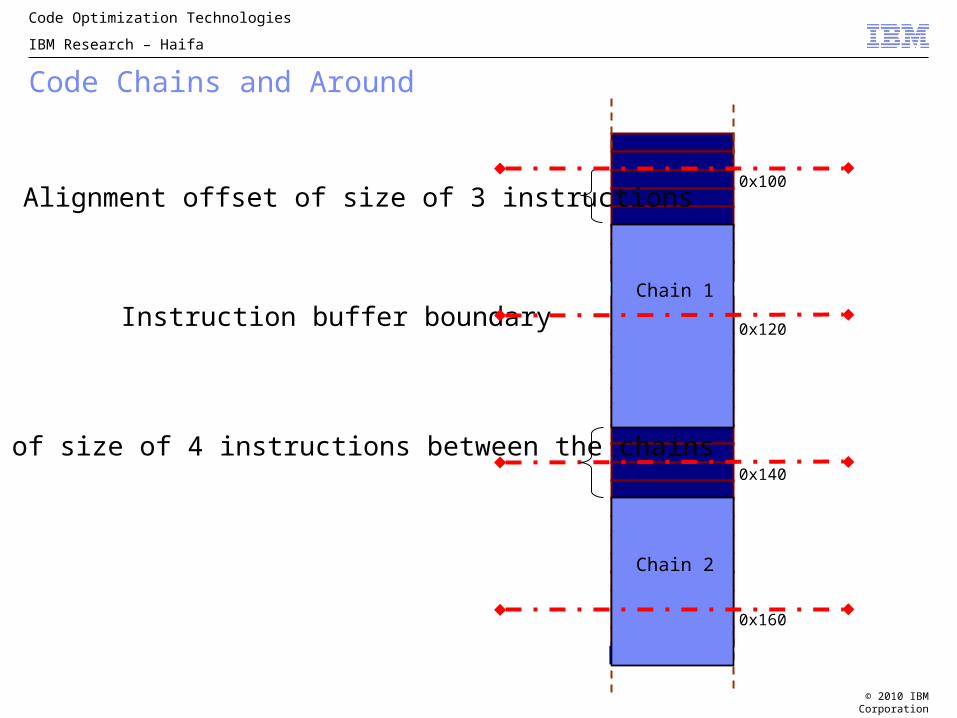
Code Chains and Around
0x100
0x120
0x140
0x160
Alignment offset of size of 3 instructions
Instruction buffer boundary
Chain 2
Chain 1
Gap of size of 4 instructions between the chains

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Code Alignment Algorithm – filtering alignment options
The algorithm works in phases, in each phase a different measure determines the best alignment alternatives
The initial set of alignment options is defined
This set is filtered in several steps with different filter at each step
These filters, or evaluation strategies, are specific to the architecture and model the performance dependency on the code placement
The strategies are applied based on predefined priorities. The next filter will apply only to results which survived previous filters. The next filter results doesn’t override the previous one’s, but refines it

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Power 6 Pipeline
The generic pipeline stages of instruction processing:
Fetch : Instructions are copied from the instruction cache or memory into the fetch buffer.
Decode : Instructions in the fetch buffer are interpreted.
Dispatch : Instructions are sent to the appropriate execution units.
Execute : The operations indicated by the instructions are carried out in the execution units.
Complete :At the end of execution, the result of instructions can be forwarded to other pending instructions while the result awaits write back.
Write Back : The results of execution are written to the architected register, cache or memory in program order, and any exceptions are recognized.

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment for Power 6
In-order architecture, static dispatch grouping
Very sensitive to code alignment

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment for Power 6 – architecture specifics
Fetch buffer contains 8 instructions
Instructions which are not to be executed are discarded
“Good” instructions are delivered for dispatch
Dispatch groups are formed, each cycle one group is executed
A new dispatch group starts on the instruction buffer boundary

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment for Power 6 – evaluation strategies
Start from 8 possible alignment options. Filter them by:
1. dispatch groups
- minimize the number of dispatch groups formed within the chain, normalized by their execution frequency

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment Evaluation Using Grouping Analysis
0x00
0x20
0x40
0x60
offset=0 groups=8
offset=1 groups=8
offset=2 groups=7
offset=3 groups=6
offset=4 groups=7
offset=5 groups=7
offset=6 groups=7
offset=7 groups=6
performing grouping analysis
Penalty for offset is the sum of execution
counters of each created group

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment for Power 6 – evaluation strategies
2. hot targets
- Aligns targets of frequently executed branch instructions, that have high incoming control flow
- Best case – hot targets are placed on the beginning of the instruction buffer
- Worst case – the first instruction of the hot target is the last instruction of the ibuff
- a dispatch group with 1 instruction - this is the only executed instruction of the ibuff

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment Evaluation by Aligned Hot Targets
0x100
0x120
0x140
0x160
Frequently taken target
Chain 1
Chain 2
Inserting a gap between the chains toplace the hot target on the ibuff boundary

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Alignment for Power 6 – evaluation strategies
Other possible strategies:
Branch instructions alignment
Reduce dispatch stalls

© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Results
The algorithm was implemented into IBM FDPR-Pro, a profile-based post-link optimizer
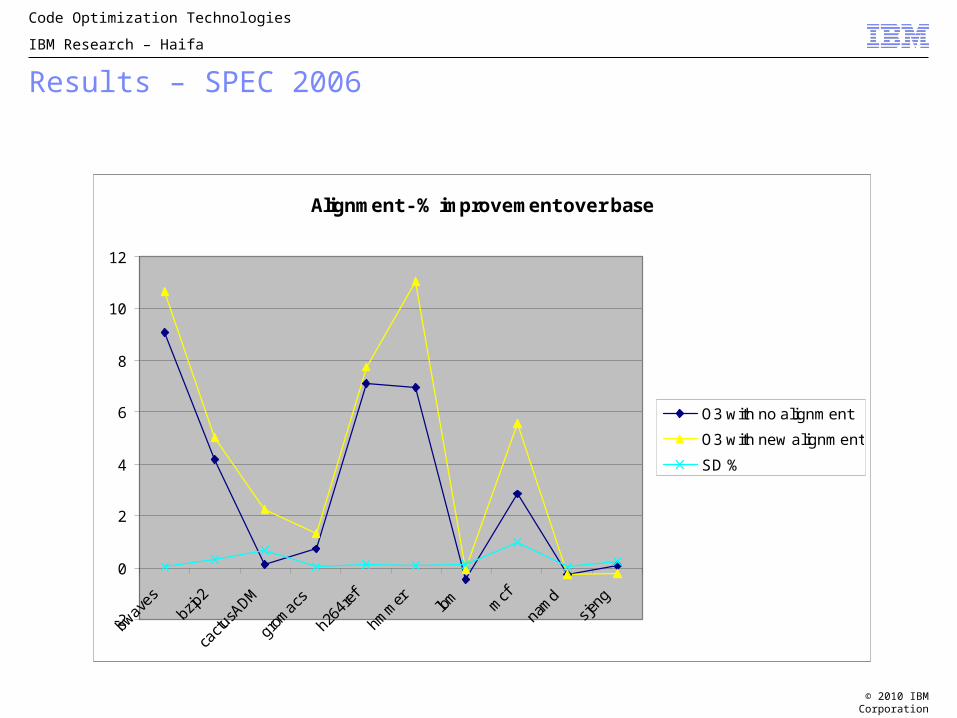
In some cases of extremely bad code alignment up to 40% improvement is achieved
Stable performance gain on SPEC 2006 INT64 benchmarks, running on AIX 6.1 on Power 6. Applied on top of standard O3 FDPR-Pro optimization set and showed up to 5% improvement.
© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Results – SPEC 2006
Alignment - % improvement over base
-2
0
2
4
6
8
10
12
bwav
esbz
ip2
cactu
sADM
grom
acs
h264
ref
hmm
er lbm mcf
nam
dsje
ng
O3 with no alignment
O3 with new alignment
SD %
© 2010 IBM Corporation
Code Optimization Technologies
IBM Research – Haifa
Thanks!





























