Embed Size (px)
Citation preview

September 8-9, 2016

BigML, Inc 2
Ensembles
Poul Petersen CIO, BigML, Inc
Making trees unstoppable

BigML, Inc 3Supervised Learning
• Rather than build a single model… • Combine the output of several “weaker” models
into a powerful ensemble… • Q1: Why would this work? • Q2: How do we build “weaker” models? • Q3: How do we “combine” models?
Ensemble Idea

BigML, Inc 4Supervised Learning
1. Every “model” is an approximation of the “real” function and there may be several good approximations.
2. ML Algorithms use random processes to solve NP-hard problems and may arrive at different “models” depending on the starting conditions, local optima, etc.
3. A given ML algorithm may not be able to exactly “model” the real characteristics of a particular dataset.
4. Anomalies in the data may cause over-fitting, that is trying to model behavior that should be ignored. By using several models, the outliers may be averaged out.
Why Ensembles
In any case, if we find several accurate “models”, the combination may be closer to the real “model”

BigML, Inc 5Supervised Learning
Ensemble Demo #1

BigML, Inc 6Supervised Learning
Weaker Models
1. Bootstrap Aggregating - aka “Bagging” If there are “n” instances, each tree is trained with “n” instances, but they are sampled with replacement.
2. Random Decision Forest - In addition to sampling with replacement, the tree randomly selects a subset of features to consider when making each split. This introduces a new parameter, the random candidates which is the number of features to randomly select before making the split.
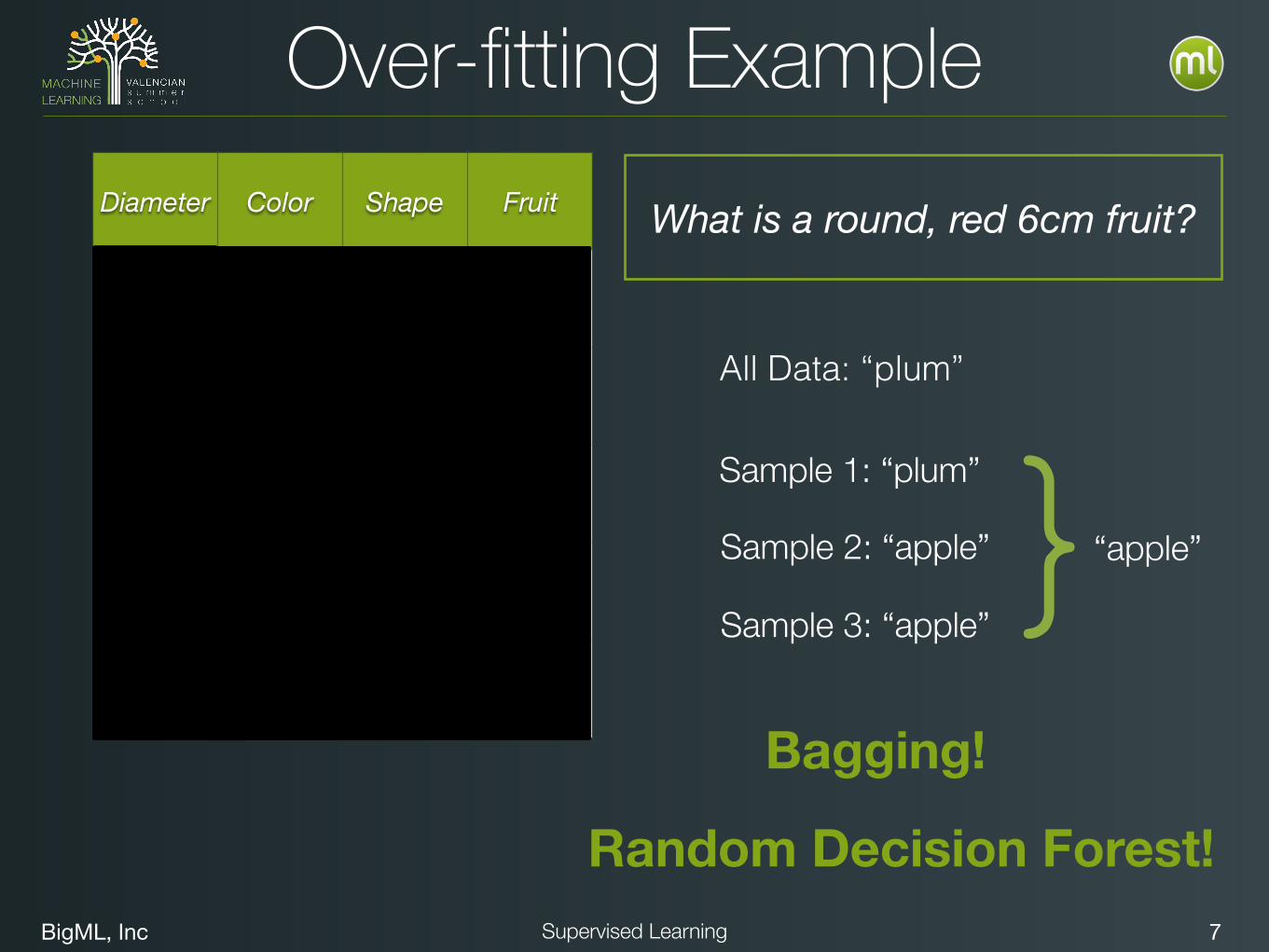
BigML, Inc 7Supervised Learning
Over-fitting ExampleDiameter Color Shape Fruit
4 red round plum
5 red round apple
5 red round apple
6 red round plum
7 red round appleBagging!
Random Decision Forest!
All Data: “plum”
Sample 2: “apple”
Sample 3: “apple”
Sample 1: “plum”}“apple”
What is a round, red 6cm fruit?

BigML, Inc 8Supervised Learning
1. Plurality - majority wins.
2. Confidence Weighted - majority wins but each vote is weighted by the confidence.
3. Probability Weighted - each tree votes the distribution at it’s leaf node.
4. K Threshold - only votes if the specified class and required number of trees is met. For example, allowing a “True” vote if and only if at least 9 out of 10 trees vote “True”.
5. Confidence Threshold - only votes the specified class if the minimum confidence is met.
Voting Methods
Linear and non-linear combinations of votes using stacking

BigML, Inc 9Supervised Learning
Ensemble Demo #2

BigML, Inc 10Supervised Learning
Model vs Bagging vs RF
Model Bagging Random Forest
Increasing Performance
Decreasing Interpretability
Increasing Stochasticity
Increasing Complexity

BigML, Inc 11Supervised Learning
Ensemble Demo #3

BigML, Inc 12Supervised Learning
• How many trees? • How many nodes? • Missing splits? • Random candidates? • Too many parameters?
SMACdown

BigML, Inc 2
Logistic Regression
Poul Petersen CIO, BigML, Inc
Modeling probabilities

BigML, Inc 3Supervised Learning
• Classification implies a discrete objective. How can this be a regression?
• Why do we need another classification algorithm?
• more questions….
Logistic RegressionLogistic Regression is a classification algorithm
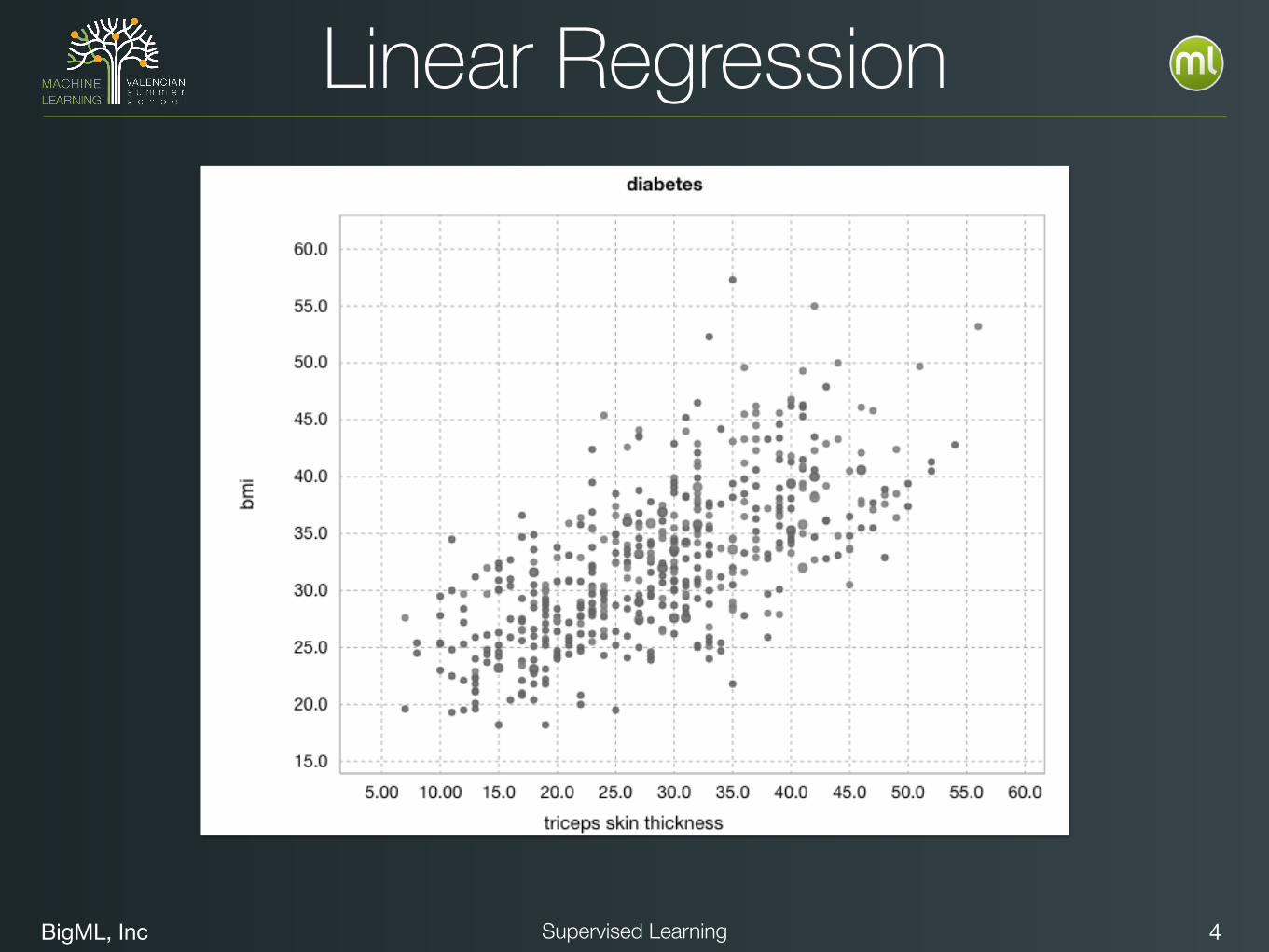
BigML, Inc 4Supervised Learning
Linear Regression

BigML, Inc 5Supervised Learning
Linear Regression
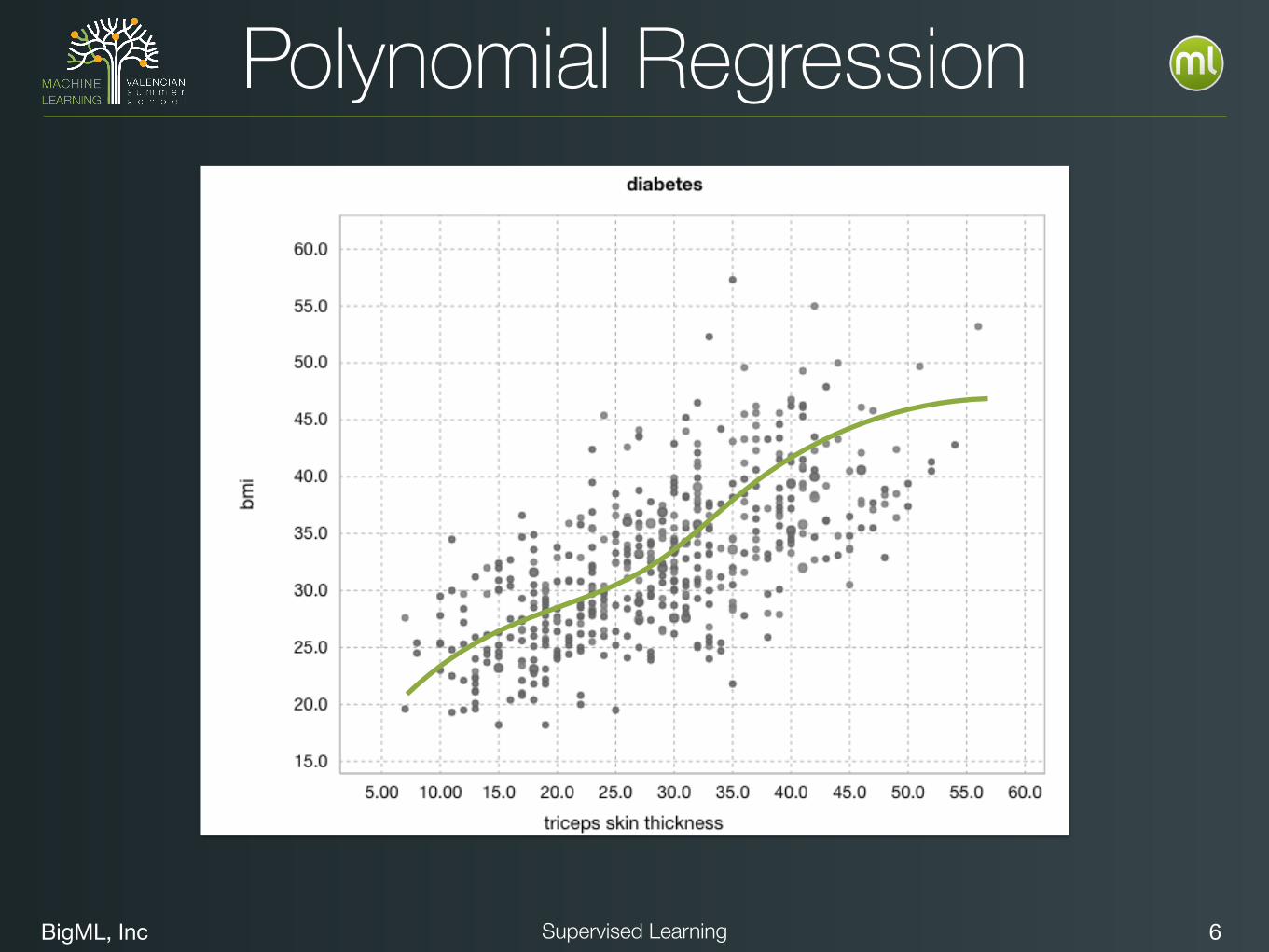
BigML, Inc 6Supervised Learning
Polynomial Regression

BigML, Inc 7Supervised Learning
• What function can we fit to discrete data?
Regression
Key Take-Away: Fitting a function to the data
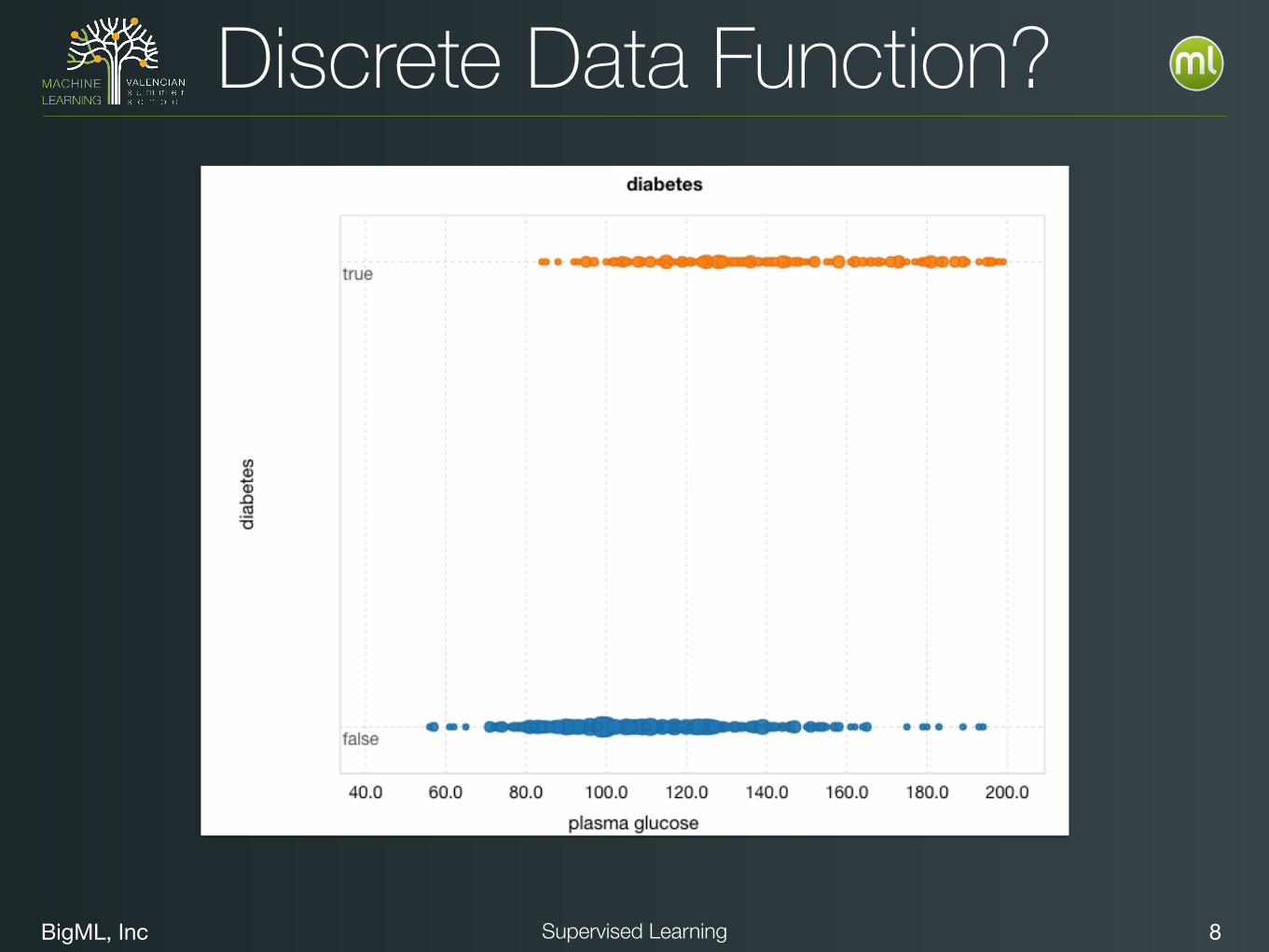
BigML, Inc 8Supervised Learning
Discrete Data Function?
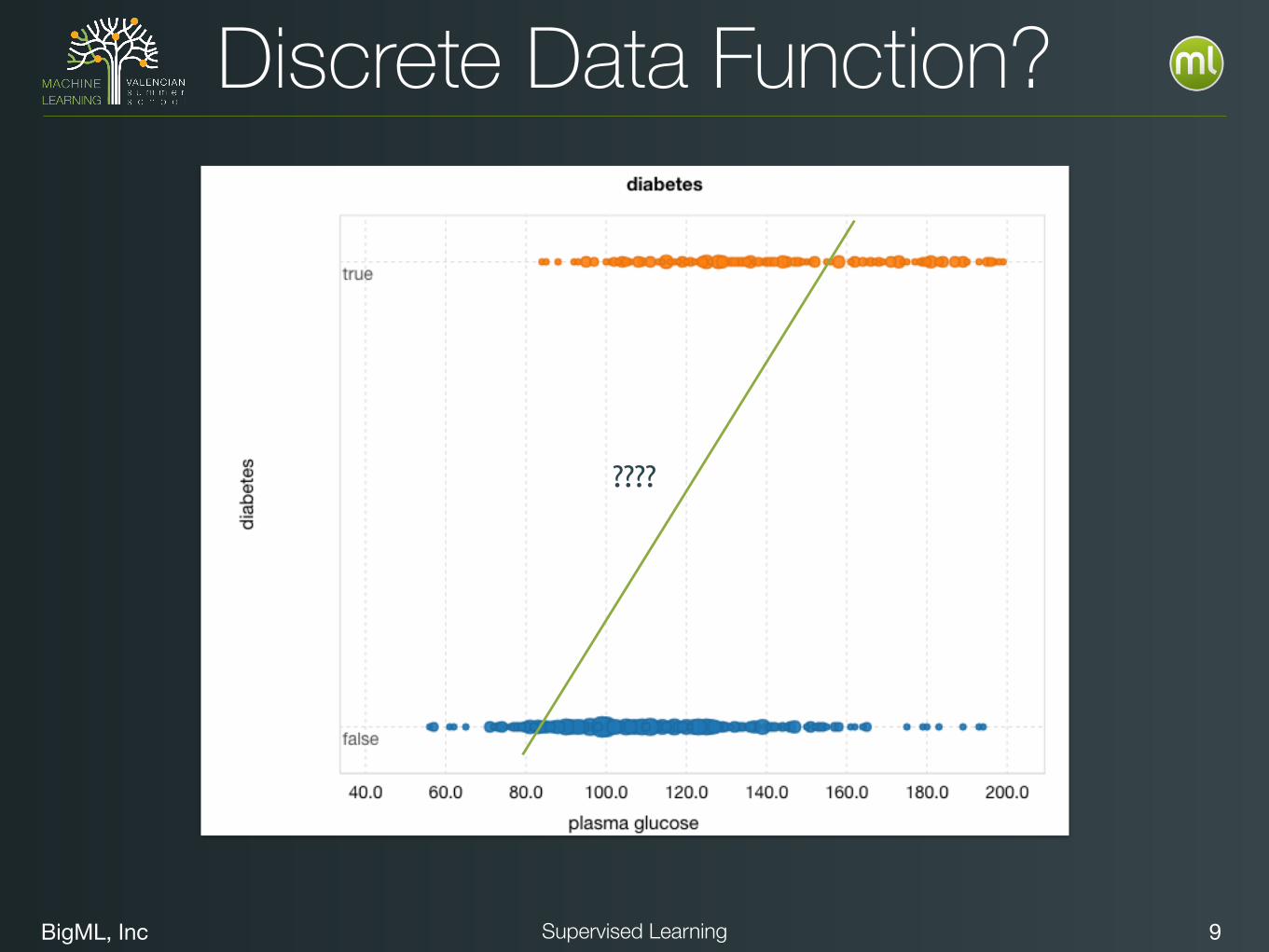
BigML, Inc 9Supervised Learning
Discrete Data Function?
????
BigML, Inc 10Supervised Learning
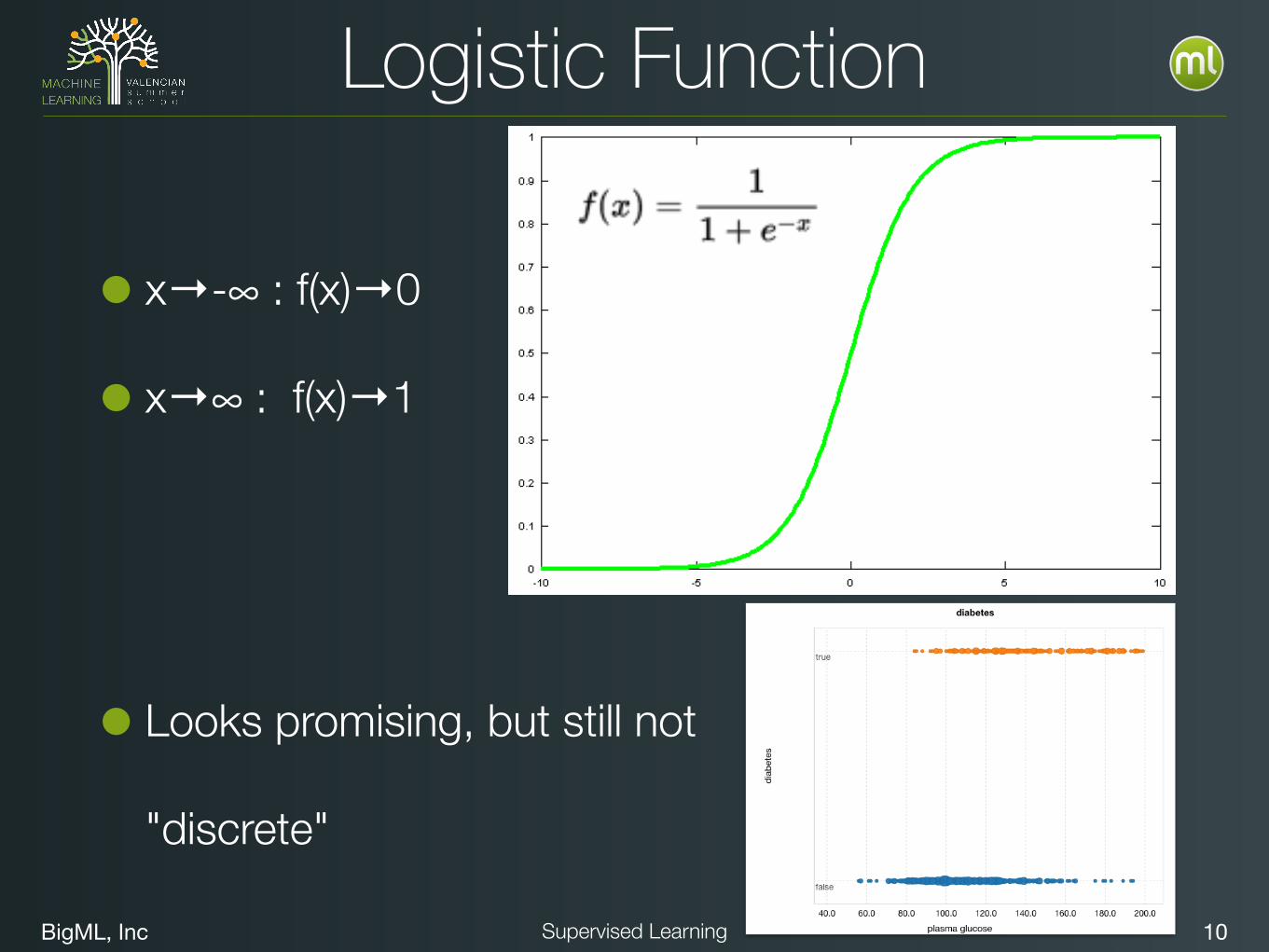
Logistic Function
• x→-∞ : f(x)→0
• x→∞ : f(x)→1
• Looks promising, but still not
"discrete"
BigML, Inc 11Supervised Learning
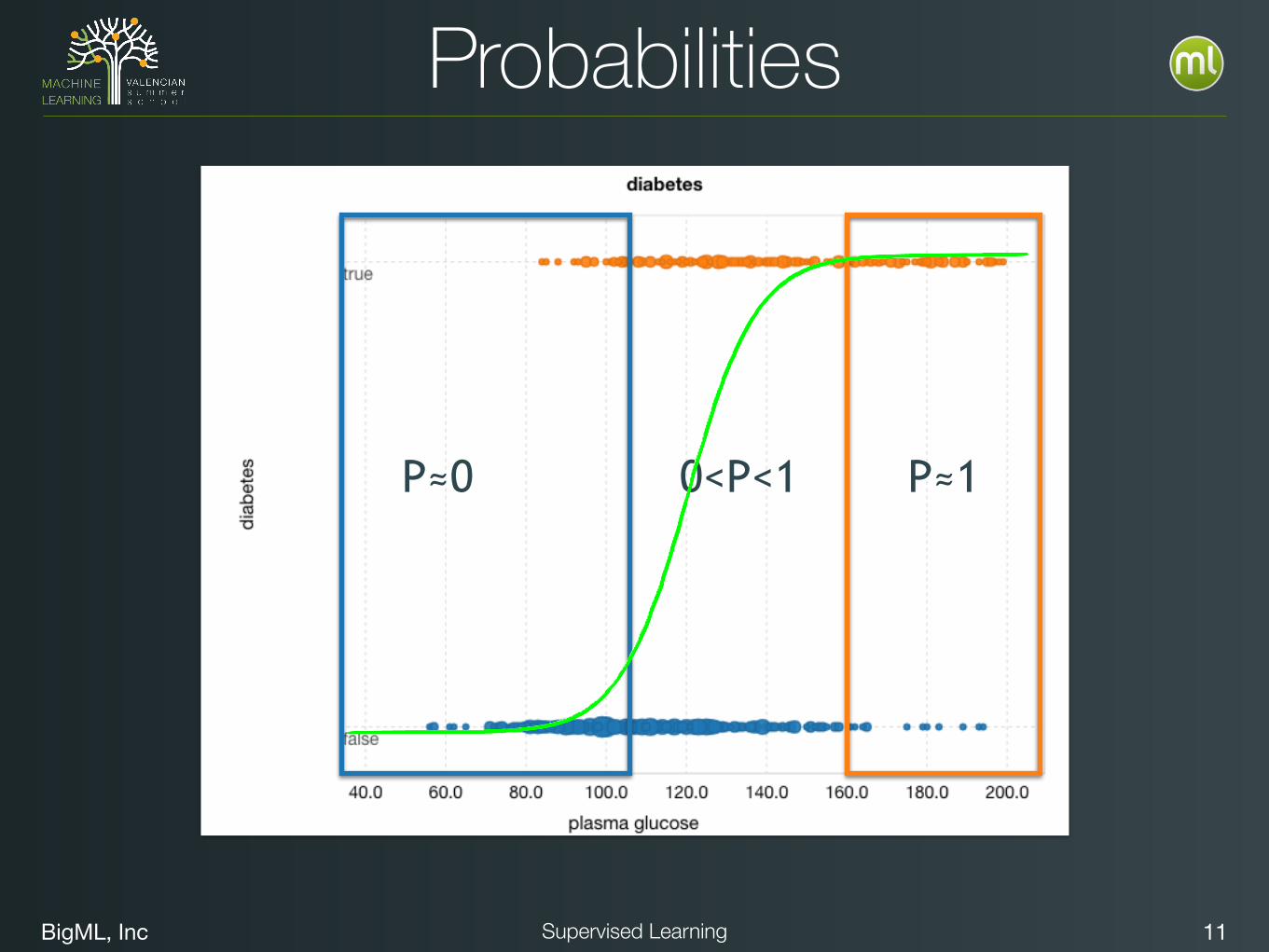
Probabilities
P≈0 P≈10<P<1

BigML, Inc 12Supervised Learning
• Assumes that output is linearly related to "predictors" … but we can "fix" this with feature engineering
• How do we "fit" the logistic function to real data?
Logistic RegressionLR is a classification algorithm … that models
the probability of the output class.

BigML, Inc 13Supervised Learning
Logistic Regressionβ₀ is the "intercept"
β₁ is the "coefficient"
The inverse of the logistic function is called the "logit":
In which case solving is now a linear regression

BigML, Inc 14Supervised Learning
Logistic RegressionIf we have multiple dimensions, add more coefficients:

BigML, Inc 15Supervised Learning
Logistic Regression Demo #1

BigML, Inc 16Supervised Learning
LR Parameters1. Bias: Allows an intercept term.
Important if P(x=0) != 0
2. Regularization:
• L1: prefers zeroing individual coefficients
• L2: prefers pushing all coefficients towards zero
3. EPS: The minimum error between steps to stop.
4. Auto-scaling: Ensures that all features contribute
equally.
• Unless there is a specific need to not auto-scale,
it is recommended.

BigML, Inc 17Supervised Learning
Logistic Regression
• How do we handle multiple classes?
• What about non-numeric inputs?

BigML, Inc 18Supervised Learning
LR - Multi-Class• Instead of a binary class ex: [ true, false ], we have multi-
class ex: [ red, green, blue, … ]
• k classes
• solve one-vs-rest LR • coefficients βᵢ for
each class

BigML, Inc 19Supervised Learning
LR - Field Codings• LR is expecting numeric values to perform regression. • How do we handle categorical values, or text?
Class color=red color=blue color=green color=NULL
red 1 0 0 0
blue 0 1 0 0
green 0 0 1 0
NULL 0 0 0 1
One-hot encoding
Only one feature is "hot" for each class

BigML, Inc 20Supervised Learning
LR - Field Codings
Dummy Encoding
Chooses a *reference class* requires one less degree of freedom
Class color_1 color_2 color_3
*red* 0 0 0
blue 1 0 0
green 0 1 0
NULL 0 0 1
BigML, Inc 21Supervised Learning
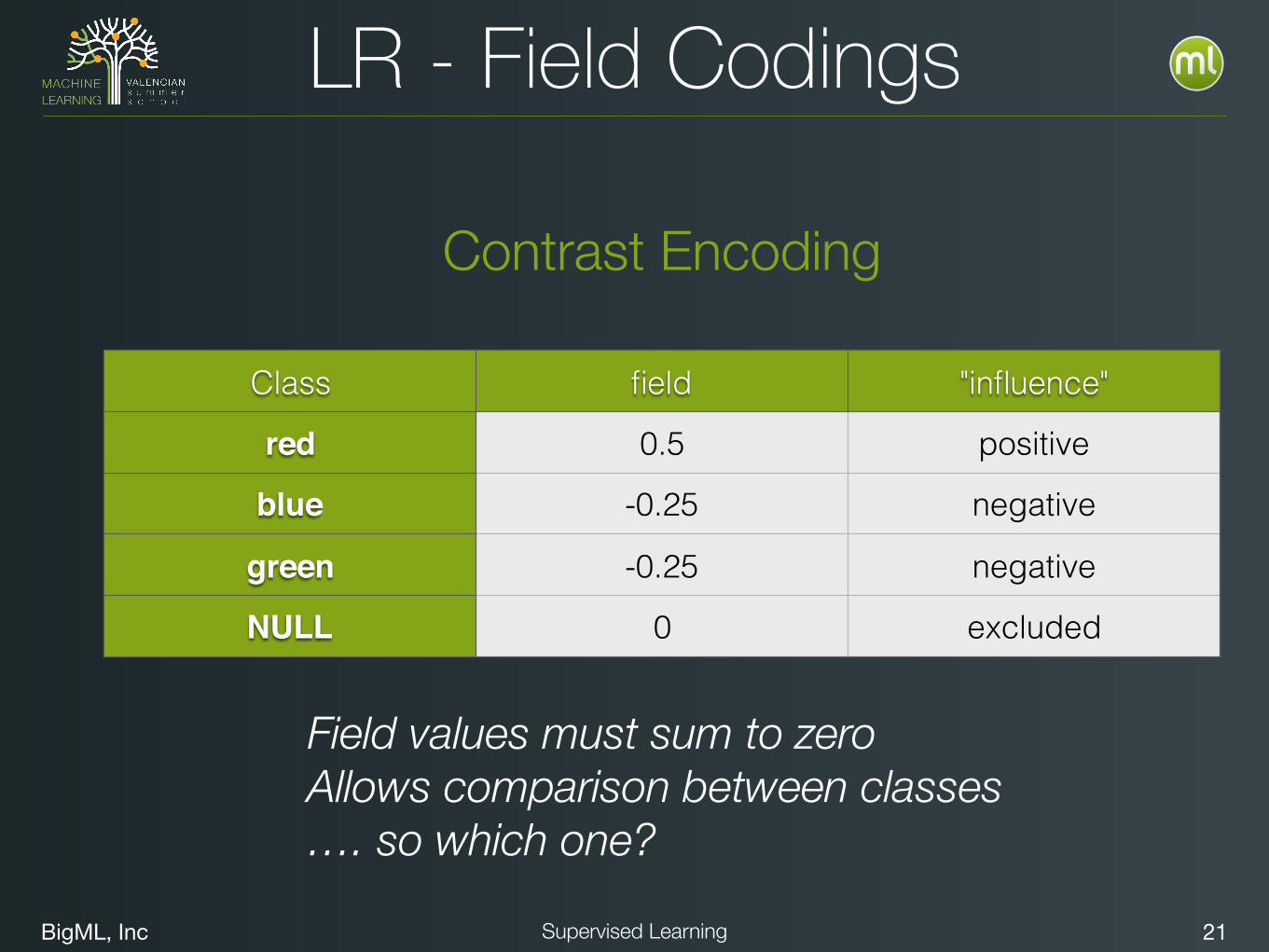
LR - Field Codings
Contrast Encoding
Field values must sum to zero Allows comparison between classes …. so which one?
Class field "influence"
red 0.5 positive
blue -0.25 negative
green -0.25 negative
NULL 0 excluded

BigML, Inc 22Supervised Learning
LR - Field Codings
• The "text" type gives us new features that have counts of the number of times each token occurs in the text field. "Items" can be treated the same way.
token "hippo" "safari" "zebra"
instance_1 3 0 1
instance_2 0 11 4
instance_3 0 0 0
instance_4 1 0 3
Text / Items ?

BigML, Inc 23Supervised Learning
Logistic Regression Demo #2
BigML, Inc 24Supervised Learning
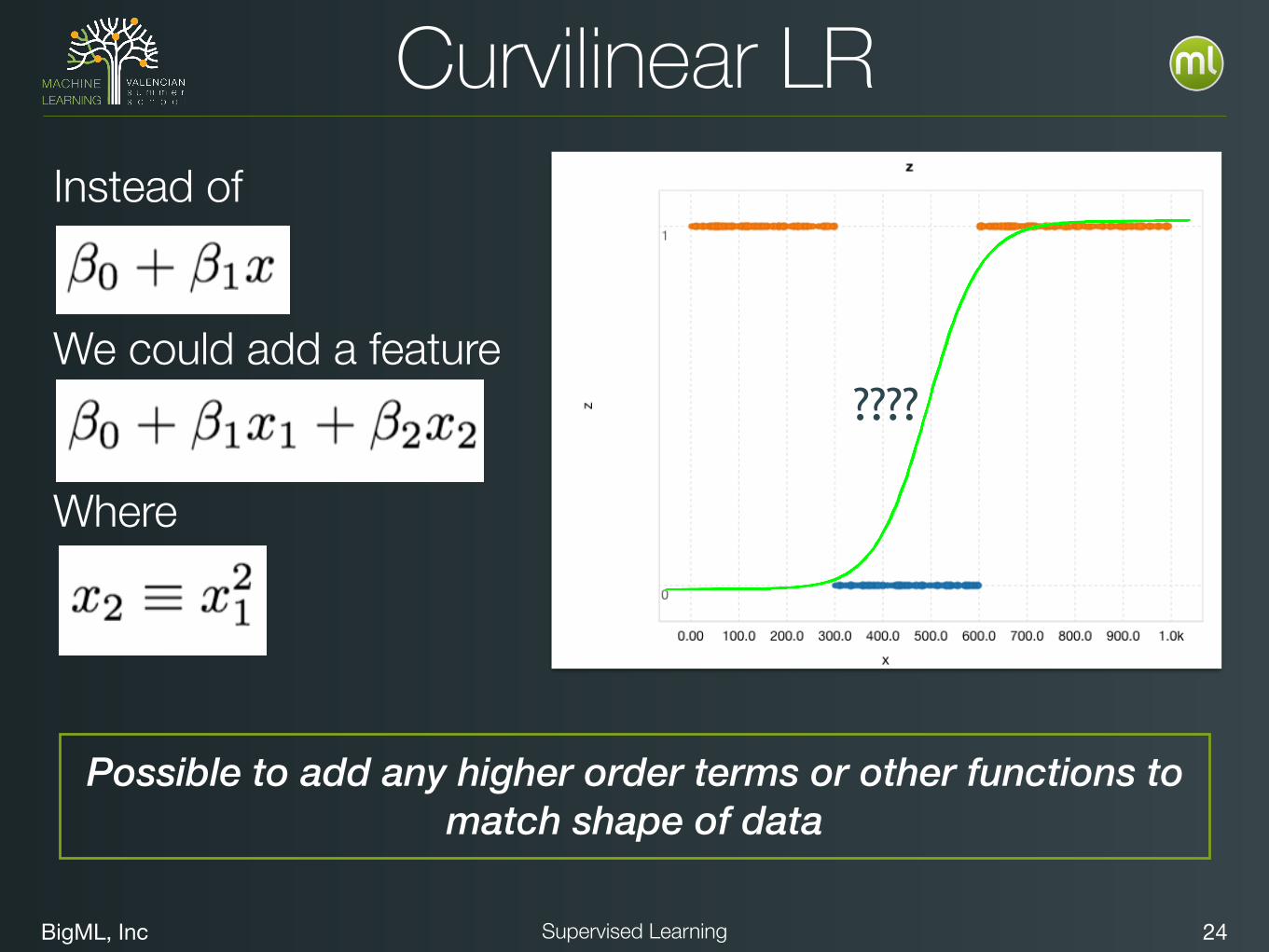
Curvilinear LRInstead of
We could add a feature
Where
????
Possible to add any higher order terms or other functions to match shape of data

BigML, Inc 25Supervised Learning
Logistic Regression Demo #3

BigML, Inc 26Supervised Learning
LR versus DT
• Expects a "smooth" linear relationship with predictors.
• LR is concerned with probability of a discrete outcome.
• Lots of parameters to get wrong: regularization, scaling, codings
• Slightly less prone to over-fitting
• Because fits a shape, might work
better when less data available.
• Adapts well to ragged non-linear relationships
• No concern: classification, regression, multi-class all fine.
• Virtually parameter free
• Slightly more prone to over-fitting
• Prefers surfaces parallel to
parameter axes, but given enough
data will discover any shape.
Logistic Regression Decision Tree

BigML, Inc 27Supervised Learning
Logistic Regression Demo #4





























