Embed Size (px)
Citation preview

Fabrikatyr AnalyticsUncover tangible truths amidst the noise of modern media

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
2
Agenda
@conr#[email protected]
Explanation of Topic Modelling
Application using Gensim
Sample Results
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
3
Explanation of Topic ModellingA BRIEF INTRODUCTION TO THE SEMANTIC WEB
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
4
Why is it Important?
• Discover topics in large groups of documents
• Use these labels to understand the body of text and documents more effectively
What is Semantic Analysis?
Some use cases:
•Consumer Insight
• Recommender
• Social Media Monitoring
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
5
What is Topic Modelling?
Grouping documents based on the probability of words occurring in each document
http://people.cs.umass.edu/~wallach/talks/priors.pdf08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
608 Apr 2015
Transforming raw data to insight for a particular audience is not about algorithms alone
DataInsight
The Gap
Good Data Science makes ‘The Gap’ as small as possible

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
7
Finding the most suitable application of Topic modelling for ‘discussion’ is critical
08 Apr 2015
Topic modelling
Semantic
Subject matter corpus
General Corpus
Statistical
Word probability
Paragraph structure
Word distance
Mixture of all?
Analysing political debate discourse has the following issues• Few / little ‘training’ texts• Highly variable sentence
length• Distinct word distributions
• Statistical word probability has readily available implementations and can resolve these challenges
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
8
What is Gensim?
08 Apr 2015
Gensim is a free Python library designed to automatically extract semantic topics from documents, as efficiently (computer-wise) and painlessly (human-wise) as possible. Gensim aims at processing raw, unstructured digital texts (“plain text”).
• Offers more precise modelling options than ‘topicModels’ in R or MALLET
• Wider function set
• Somewhat complex to optimise
• Dependencies: numpy and scipy
Radim Rehurek

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
9
Application using GensimHOW TO USE GENSIM TO UNDERSTAND LARGE VOLUMES OF TEXT EFFECTIVELY
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
10
Preparing the data• No data set is
ever ready to operate on ‘out-of-the-box’
• Challenges included:• Character
encoding• Multiple fields in a
column• Timestamps
DATA
08 Apr 2015
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
11
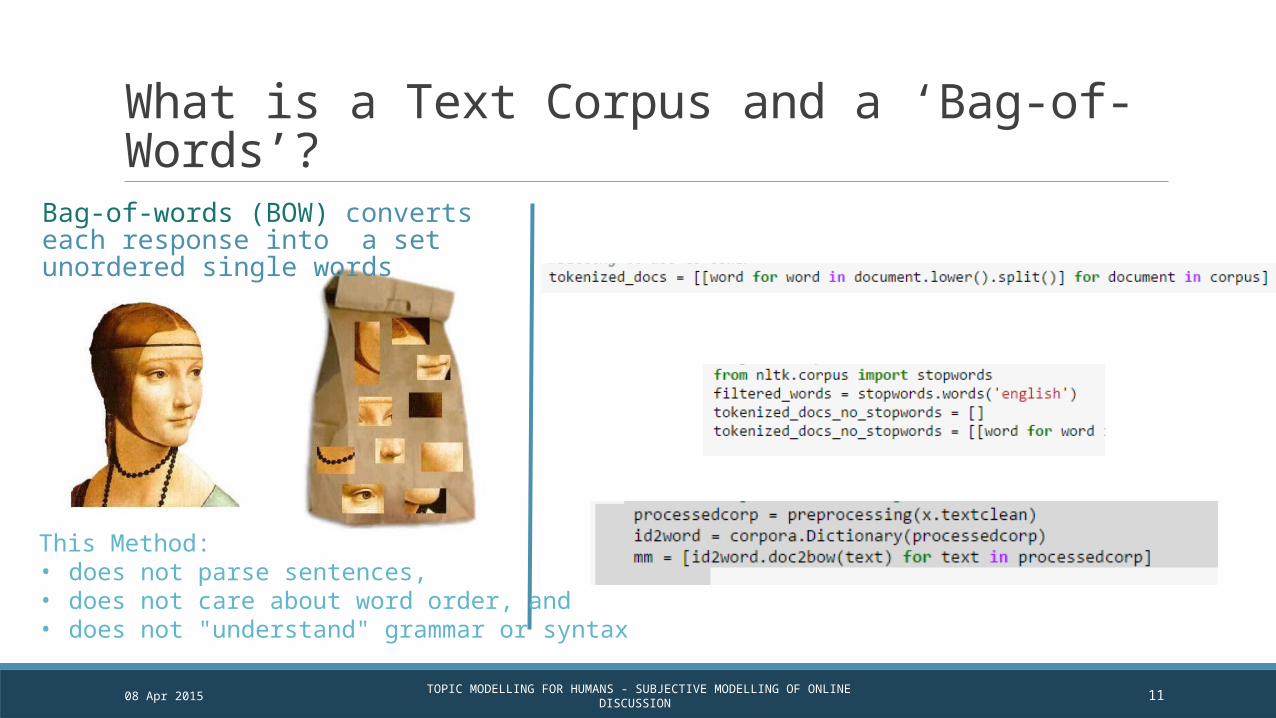
What is a Text Corpus and a ‘Bag-of-Words’?
08 Apr 2015
Bag-of-words (BOW) converts each response into a set unordered single words
This Method:• does not parse sentences,• does not care about word order, and• does not "understand" grammar or syntax

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
1208 Apr 2015
The optimum number of topics can be selected by calculating the model with the smallest measure of Chaos / Entropy
Least amount of disorder in the topics
Harmonic Mean
AIC
Entropy
“Sum of Lowest average probability” for each topic distribution
Balance of “Harmonic mean “ against model complexity
Least amount of disorder in the topics
Using Kullback–Leibler divergence we can spot local minimum and pick the optimum number based on how many topics we want to ‘name’
Local minimums provide a chance to explore the Trade-off between granularity and consistency
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
13
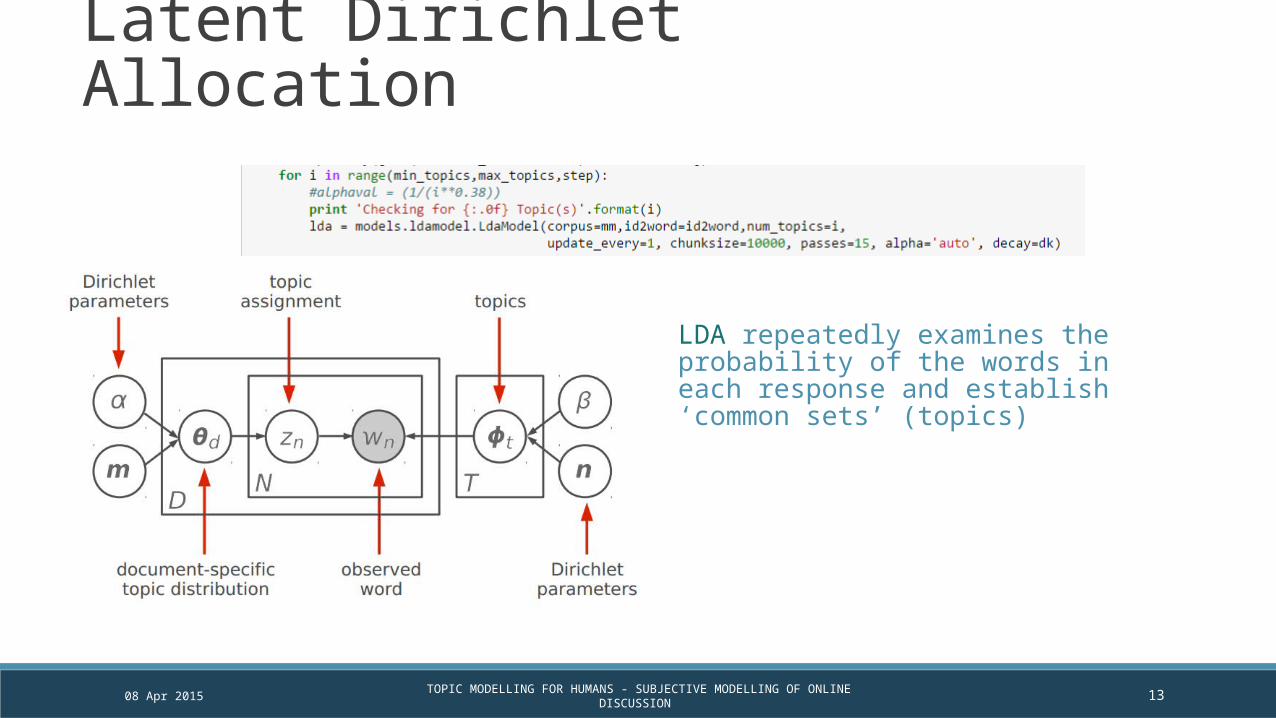
Latent Dirichlet Allocation
LDA repeatedly examines the probability of the words in each response and establish ‘common sets’ (topics)
08 Apr 2015
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
14
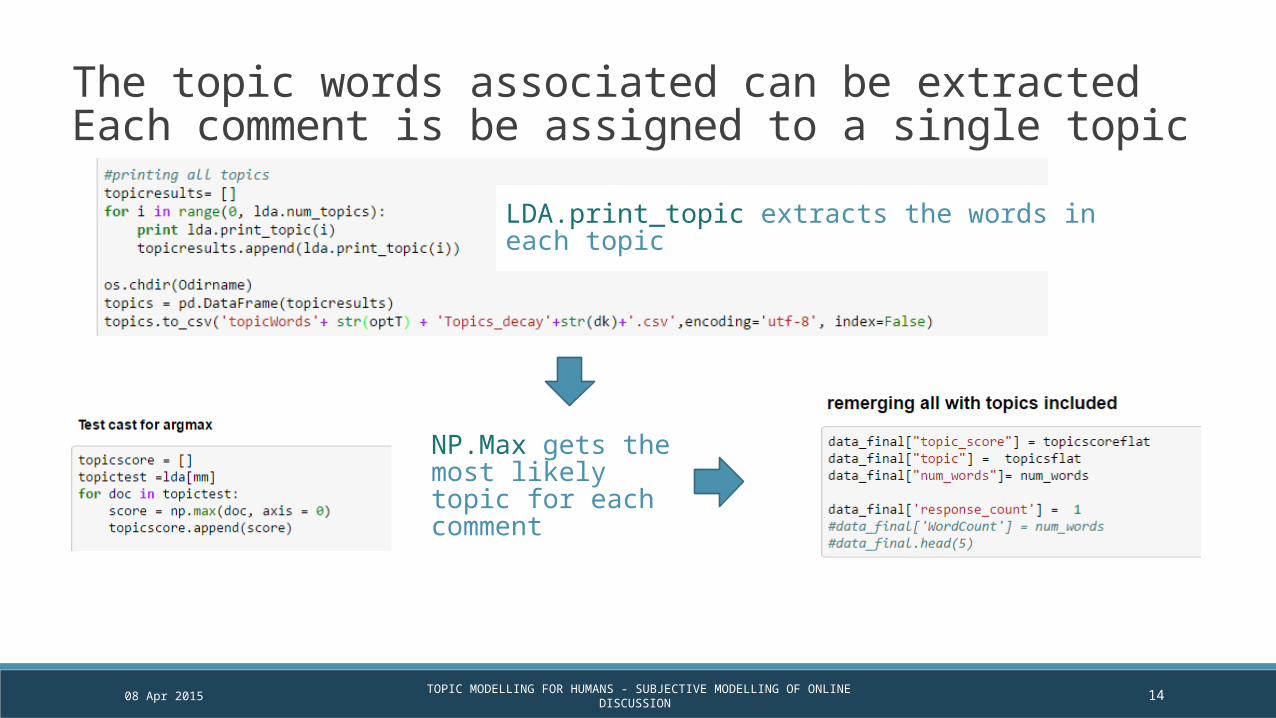
The topic words associated can be extractedEach comment is be assigned to a single topic
08 Apr 2015
LDA.print_topic extracts the words in each topic
NP.Max gets the most likely topic for each comment

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
15
Sample ResultsINTERROGATING A COMMUNITY FORUM DISCUSSION
08 Apr 2015
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
16
How to use it?There are 7 key stages to model topics effectively
1• Colla
te text
2• Creat
e Corpus
3• Creat
e ‘bag of words’
4• Opti
mum topics
5• Esta
blish keyword groupings
6• Nam
e Topics
7• Visu
alise
1Get Data
2Create Corpus
3Feature review
4Optimum
topics
5Review
6Name & Visualise
7Deliver insight
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
17
Sample set : 11.3K posts to a Teleco help forum
08 Apr 2015
Corpus 5,000
Questions3,000 Users
3 years of data
Kudos
Device
Thread size
User Age
Views
Maximum user posts
Data Features
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
18
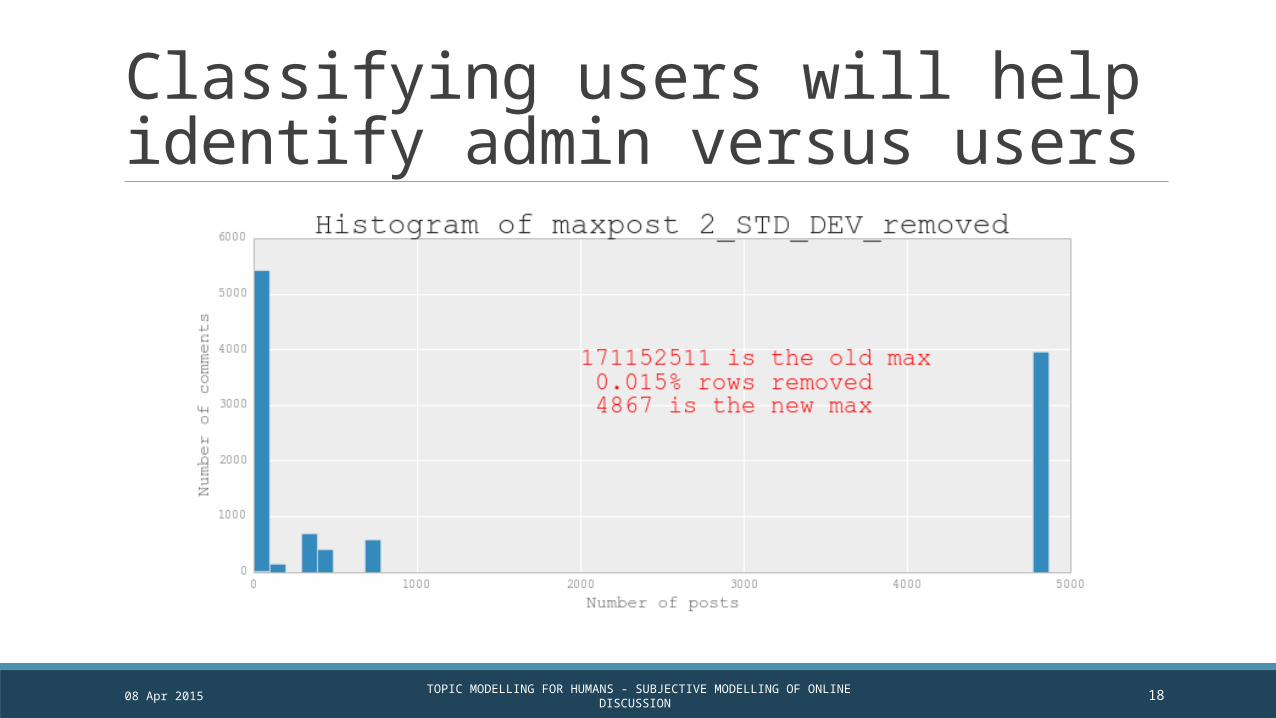
Classifying users will help identify admin versus users
08 Apr 2015
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
19
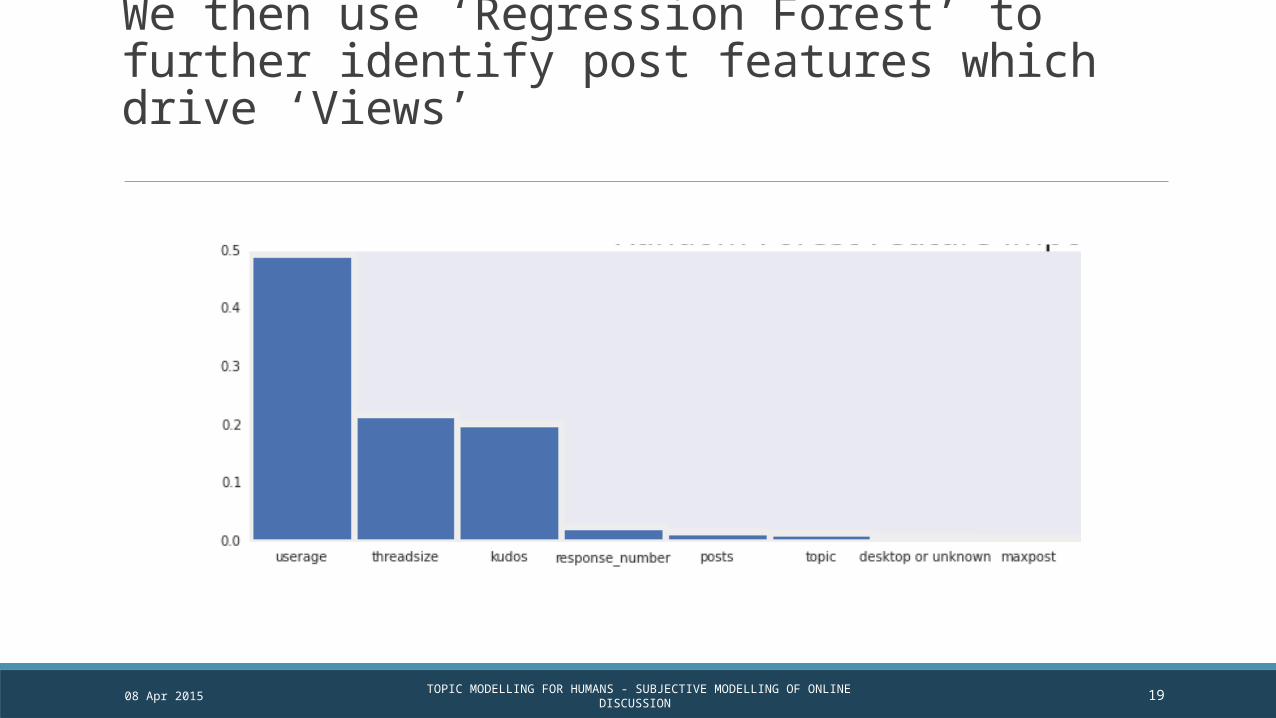
We then use ‘Regression Forest’ to further identify post features which drive ‘Views’
08 Apr 2015
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
20
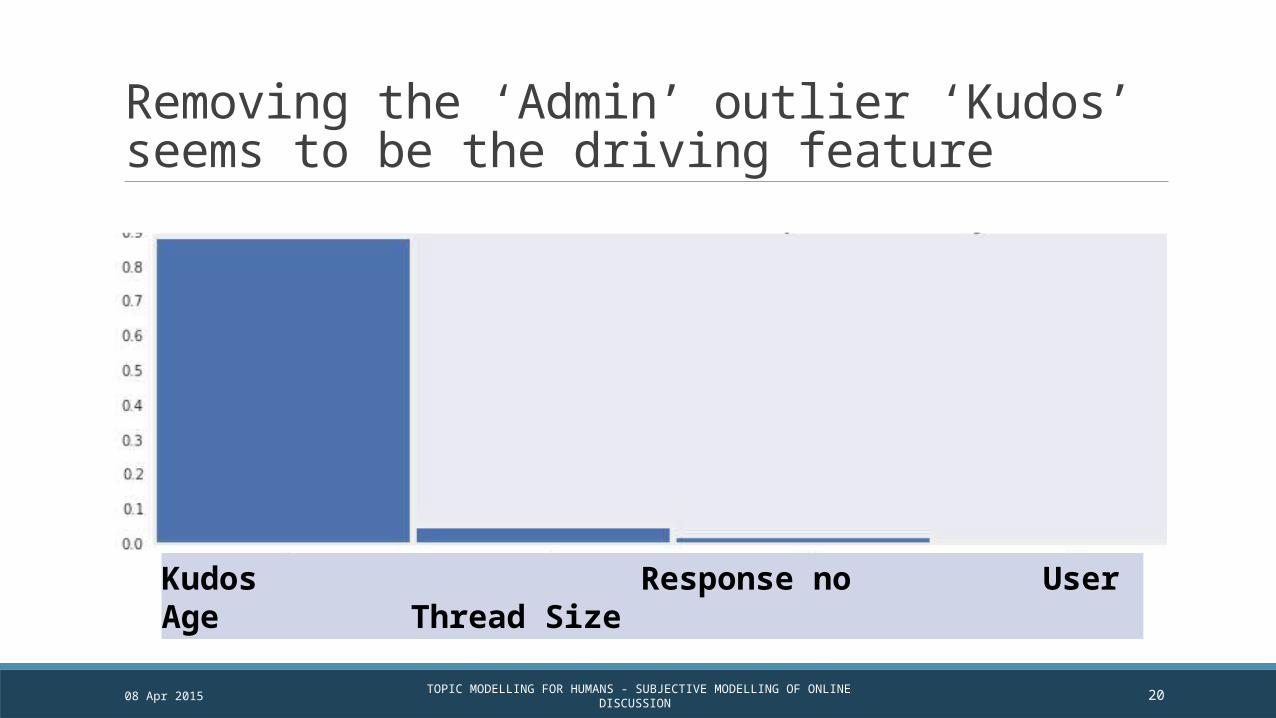
Removing the ‘Admin’ outlier ‘Kudos’ seems to be the driving feature
08 Apr 2015
Kudos Response no User Age Thread Size
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
2108 Apr 2015
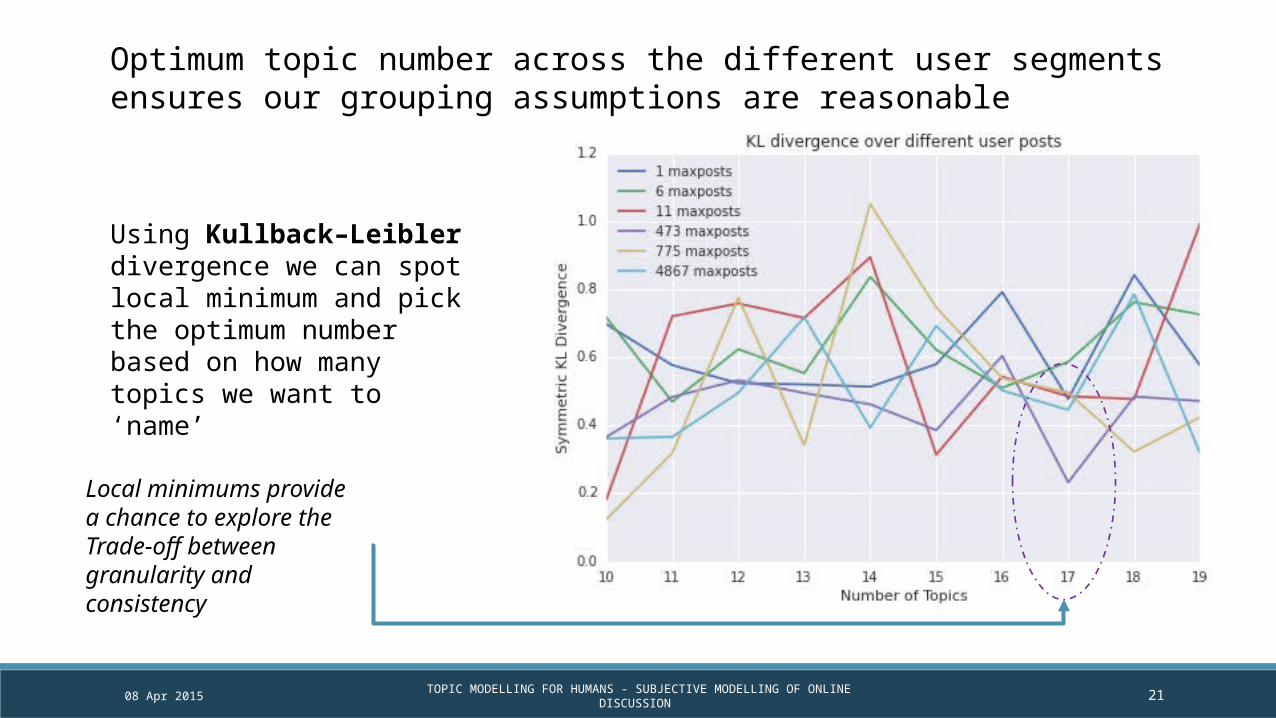
Optimum topic number across the different user segments ensures our grouping assumptions are reasonable
Using Kullback–Leibler divergence we can spot local minimum and pick the optimum number based on how many topics we want to ‘name’
Local minimums provide a chance to explore the Trade-off between granularity and consistency
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
22
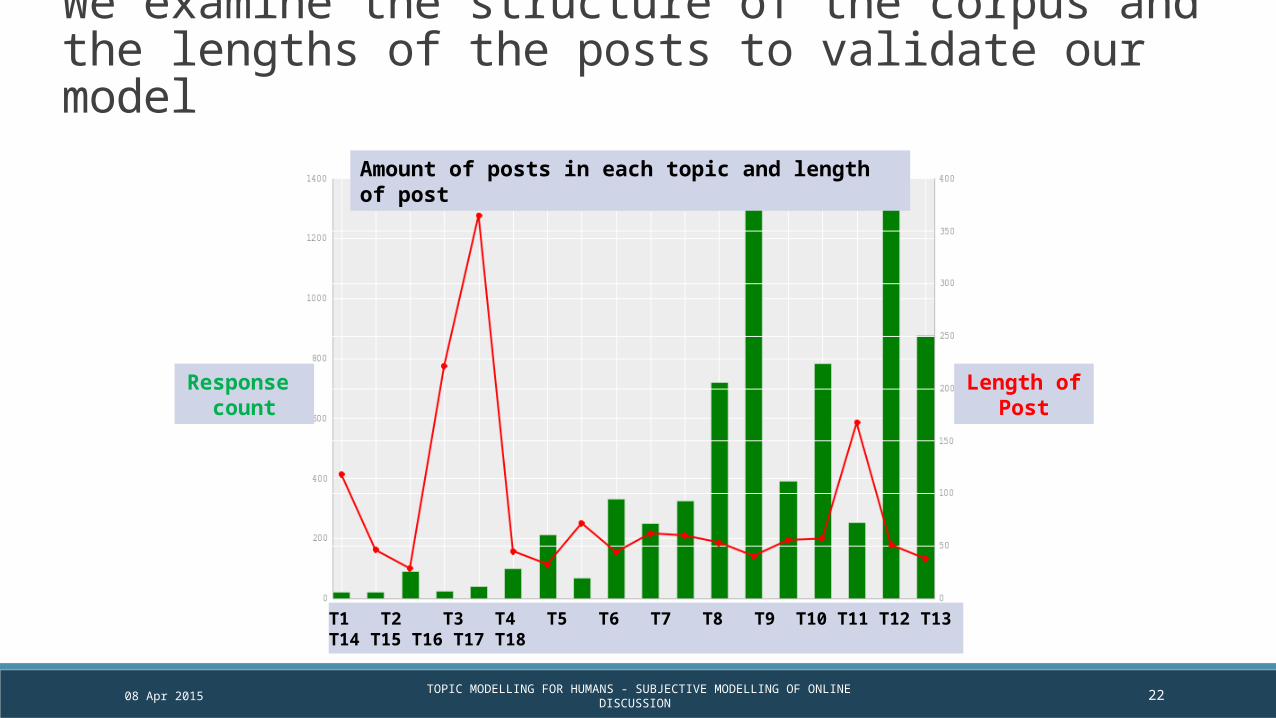
Amount of posts in each topic and length of post
T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 T12 T13 T14 T15 T16 T17 T18
08 Apr 2015
We examine the structure of the corpus and the lengths of the posts to validate our model
Response count
Length of Post

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
2308 Apr 2015
Word probability distributions, corpus and domain knowledge allow for topics to be named
Topic Topic Name Word tokens and probability11 Internet setting internet setting data phone work
30% 27% 31% 12% 5%
12 Number Transfer number 48 sim support old 36% 35% 14% 6% 3%
13 General new account query
phone sim go solution solved
26% 29% 24% 9% 6%
14 Roaming text roaming call send eu 23% 25% 22% 8% 5%
15 General chat im like think good dont 13% 12% 10% 4% 2%
16 Referral Bonus press key navi highlight select 27% 32% 31% 15% 9%
17 Network Issues network phone problem im internet 12% 11% 13% 5% 3%
18 Blackberry Problems problem blackberry mine get thanks 11% 11% 13% 5% 2%
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
24
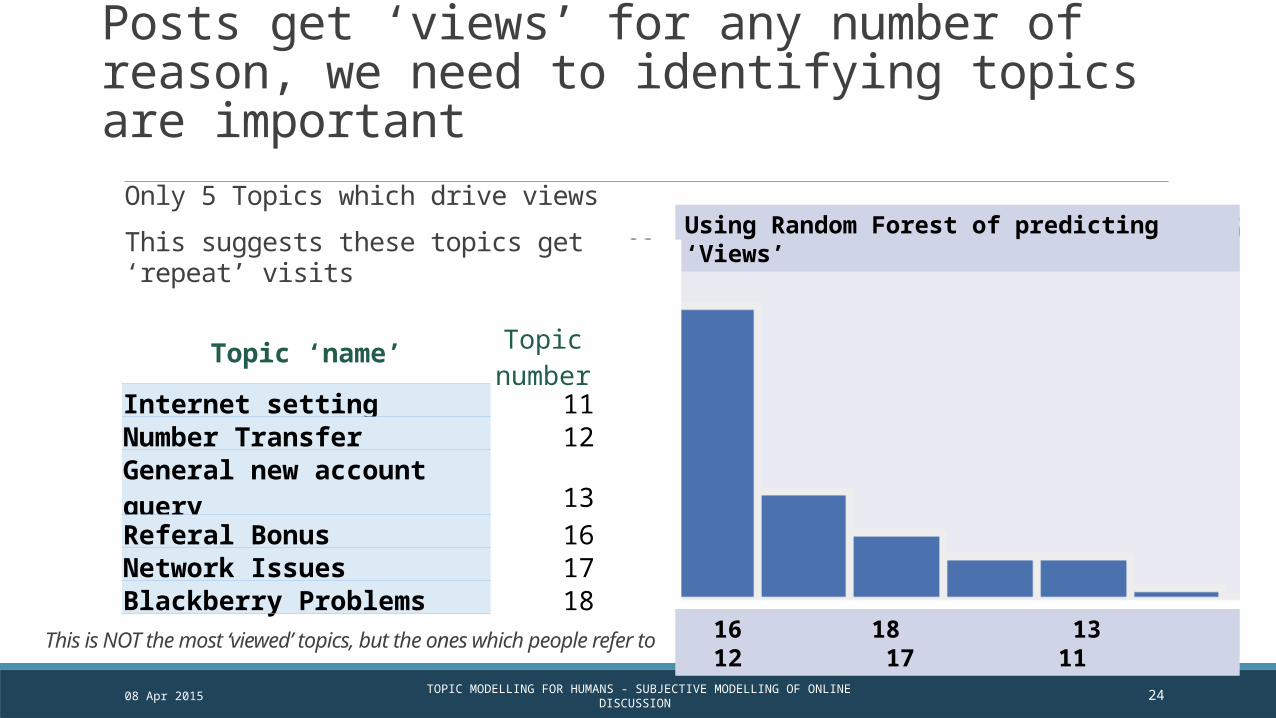
Posts get ‘views’ for any number of reason, we need to identifying topics are important
08 Apr 2015
Using Random Forest of predicting ‘Views’
Topic ‘name’ Topic number
Internet setting 11Number Transfer 12General new account query 13Referal Bonus 16Network Issues 17Blackberry Problems 18
Only 5 Topics which drive views
This suggests these topics get ‘repeat’ visits
This is NOT the most ‘viewed’ topics, but the ones which people refer to 16 18 13 12 17 11
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
2508 Apr 2015
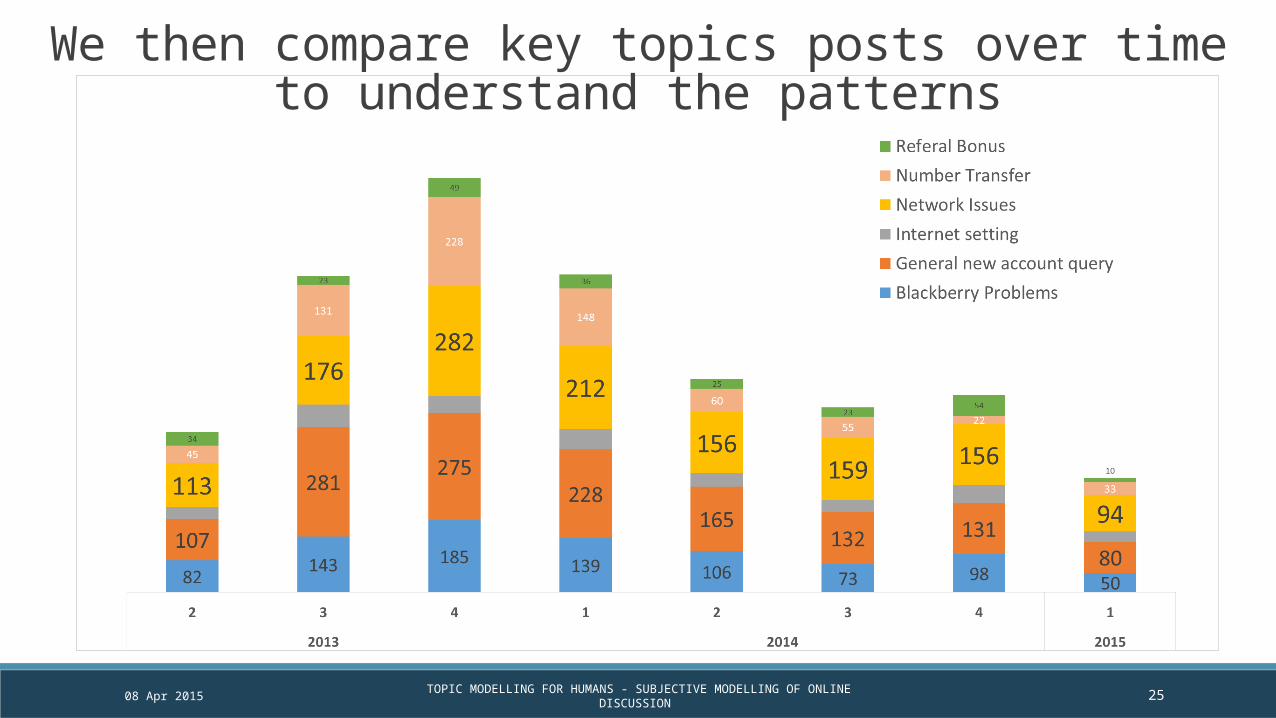
We then compare key topics posts over time to understand the patterns

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
26
Using ‘Named Entity Recognition’(NER), Topic Modelling can be used to understand how consumers are interacting with brands
08 Apr 2015
Brands mentions only occur in 2% of the entire corpus, making any assignment of topics trivial
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
27
ConclusionTHINGS TO THINK ABOUT
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
28
2nd Generation of ‘Listening’ tools will be less metric and more Qualitative
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
29
Context is KeyBlind application of complex modelling will yield results which deliver incorrect classification
The final deliverable and key features must be defined before embarking on the analysis08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
30
There is an infinite amount of data, harvesting it is the key
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
31
AppendixGENSIM
08 Apr 2015

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
32
Comparison of LDA implementations
08 Apr 2015
Learning rate – (decay)To ‘bootstrap’ small bodies of text
‘Passes’ of the Bayesian sampling function can also effect the model
•Gensim in Python currently has the most extensive set of parameters however topicmodels in R has some good visualisation examples
•‘Online’ LDA implementations are crucial for ‘social listening’ for evolving political commentary
The ‘Number of Topics’ is the key parameter however there are a few other parameters which are important.
Priors MatterFunction of document count and length
‘Honourable mention’ implementations• Vowpal Wabbit – machine learning• Mallet – Focus on text modelling• Stanford - great resource
TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
33
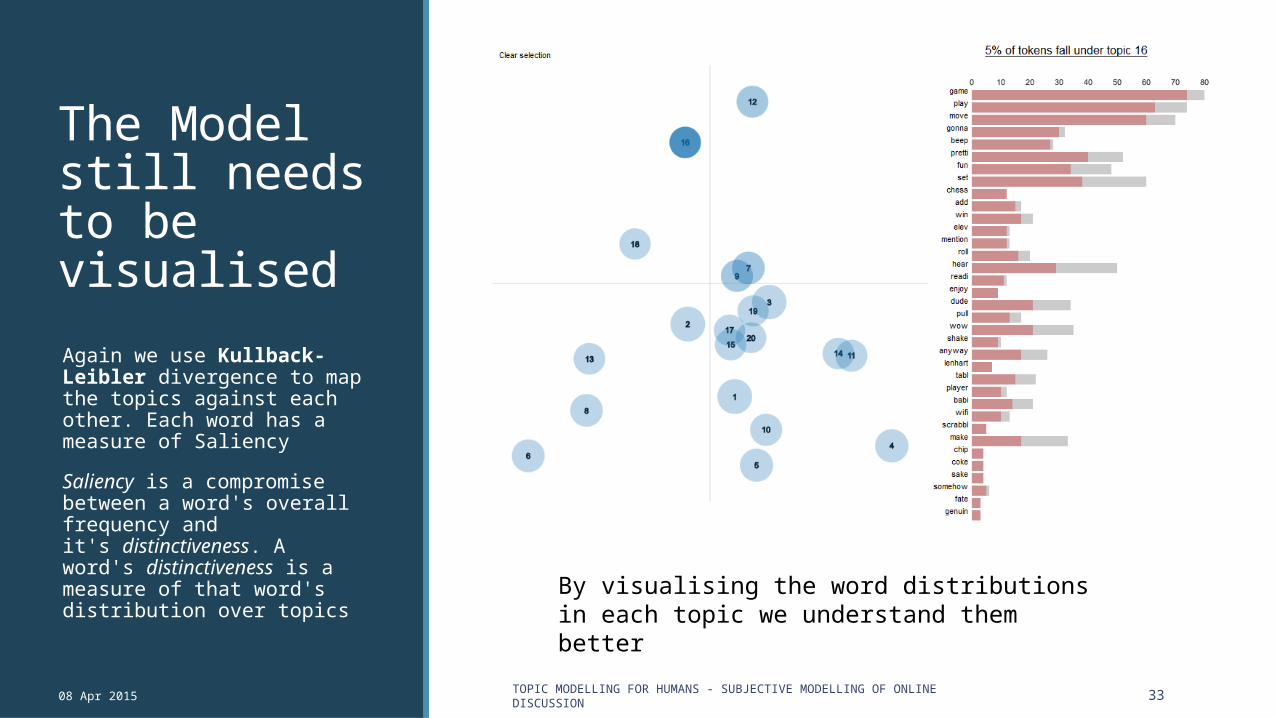
The Model still needs to be visualised
Again we use Kullback-Leibler divergence to map the topics against each other. Each word has a measure of Saliency
Saliency is a compromise between a word's overall frequency and it's distinctiveness. A word's distinctiveness is a measure of that word's distribution over topics
08 Apr 2015
By visualising the word distributions in each topic we understand them better

TOPIC MODELLING FOR HUMANS - SUBJECTIVE MODELLING OF ONLINE DISCUSSION
34
Why Priors Matter!
Careful thinking about priors can yield new insights
– e.g., priors and STOPWORD handling are related
For LDA the choice of prior is surprisingly important:
– Asymmetric prior for document-specific topic distributions
– Symmetric prior for topic-specific word distributions
Almost all work on LDA uses symmetric Dirichlet priors– Two scalar concentration parameters: α and β● Concentration parameters are usually set heuristically● Some recent work on inferring optimal concentration parameter values from data (Asuncion et al., 2009)
08 Apr 2015





























