Embed Size (px)
Citation preview

Proprietary & Confidential
Proliferation of New Database Technologies and Implications for Data Science Workflows November 2017
Manny Bernabe | James Lamb

Section 1Intro to Uptake

3Copyright © 2017 Uptake – CONFIDENTIAL13-Nov-17Collaboration Portfolio
Uptake at a glance
AVIATION CONSTRUCTION ENERGY MANUFACTURING
4MM+Predictions/week
2014founded in Chicago
75%across Data Science & Engineering
800+ Employees
Uptake has developed partnerships in:
MINING OIL & GAS RAIL RETAIL
Ranked #5 on CNBC’s 2017 Disruptor 50 list – May 2017
Uptake’s Industry Thought Leaders featured in:
Recognized as World Economic Forum 2017 Technology Pioneer – June 2017

4Copyright © 2017 Uptake – CONFIDENTIAL13-Nov-17Collaboration Portfolio
Rail Uptime: Predictive events & conditions – actual screenshot
Real time alerts are too late. In this case we are predicting 2 weeks into the future.

5Copyright © 2017 Uptake – CONFIDENTIAL13-Nov-17Collaboration Portfolio
Our strength lies in data science.
1 2 3 4 5
Cutting edge tech
Top tier talent Fast deployment Industry knowledge Applied experience
Built from scratch for quality
Over 60 data scientists
Core platform built to scale out
Our data scientists train in your field
We work in many industries
Failure Prediction
Event/Alert Filtering
Anomaly Detection
Image Analytics Suggestion
Our core machine learning engines can be deployed in any industry.
Label Correction

Section 2Emergence of NoSQL Databases

7Copyright © 2017 Uptake
To be clear: Relational DBs are awesome and they’re here to stay

8Copyright © 2017 Uptake
Relational databases are popular because they’re intuitive to reason about, easy to query, and come with some nice guarantees
● Normalized data model○ Entities, relationships that
look like the real world
● Declarative code○ “I want this”
● Query Planning ○ “I know how to get this for
you”
● Strong correctness guarantees○ ACID principles (see next
slide)

9Copyright © 2017 Uptake
What if a node writes data to disk and then dies before it tells you it’s done?
Are you willing to wait for every node in your cluster to respond to a write?
Are you willing to forgo some forms of parallelization?
If you lose a block of data, are you ok with your application being down until it’s all restored?
When your data are big and/or coming in fast, the guarantees made by relational DBs can be very difficult to maintain
Atomicity → transactions cannot “partially succeed”
Consistency → transactions cannot produce an invalid state (all reads see the same data)
Isolation → executing transactions concurrently results in the same state as executing them sequentially
Durability → once a transaction happens, the only way to reverse its effect is with another transaction

10Copyright © 2017 Uptake
NoSQL DBs exist to give your business the flexibility to make tradeoffs between accuracy, speed, and reliability
Once you distribute your data, you have to pick one of these strategies:
Consistent & Available
“I’d rather my app be down than wrong”
Examples:● mobile payments● ticketing
Tech: Oracle, Postgres, MySQL
Consistent & Partition-Tolerant
“whatever data is up needs to be right”
Examples: ● sports apps● Slack
Tech: MongoDB, Memcache
Available & Partition-Tolerant
“all data is available even if nodes fail”
Examples: ● social media● news aggregators
Tech: Cassandra, CouchDB

11Copyright © 2017 Uptake
Relational DBs are (rightfully) still king, but NoSQL alternatives have been on the rise in recent years
Image credit: db-engines

12Copyright © 2017 Uptake
NoSQL (“not only SQL”) DBs come in many shapes and sizesDocument Stores Key-Value Stores Column Stores

Section 3NoSQL Case Study: Elasticsearch

14Copyright © 2017 Uptake
To make this concrete, we’ll cover a document database called Elasticsearch

15Copyright © 2017 Uptake
Elasticsearch is a document-based, non-relational, schema-optional, distributed, highly-available data store
● Document-based → Single “record” is a JSON object which follows some schema (called a “mapping”) but is extensible and whose content varies within an index
● Non-relational → Documents are stored in indices and keyed by unique IDs, but explicit definition of relationships between fields is not required
● Schema-optional → You can enforce schema-on-write restrictions on incoming data but don’t have to
● Distributed → data in ES are distributed across multiple shards stored on multiple physical nodes (at least in production ES clusters)
● Available → Query load is distributed across the cluster without the need for a master node. No single point of failure
Let’s go through each of these points...

16Copyright © 2017 Uptake
Document stores are databases that store unstructured or semi-structured textEach “record” in Elasticsearch is a JSON document.
Information on how the cluster responded. In this case, 4 shards participated in responded to the request.
This tells you how many documents matched your query.
The “hits.hits” portion of the response contains an array of documents. Each document in this array is equivalent to one “record” (think 1 row in a relational DB)
The fields starting with “_” are default ES fields, not data we indexed into the cluster

17Copyright © 2017 Uptake
Schemas are optional but strongly encouraged in ElasticsearchElasticsearch is “schema-optional” because you can enforce type restrictions on certain fields, but the databases will not reject documents that have additional fields not present in your mapping
Example mapping for a field called firstContactDate
store: true = tells Elasticsearch to store the raw values of this field, not just references in an index
fields: {} = additional alternative fields to create from raw values passed to this one. In this case, a field called firstContactDate.search will exist that users can query with the “dateOptionalTime” format
This block tells ES to index a timestamp with every new document passed to this index. Can be user-generated or auto-generated by ES
This applies to the customer index. For now, just think of:index in ES = table in RDBMS

18Copyright © 2017 Uptake
Non-relational = No Joins!
Elasticsearch has no support for query-time joins. Data that need to be used together by applications must be stored together. This is called “denormalization”.
Image credit: Contactually

19Copyright © 2017 Uptake
Elasticsearch presents as a single logical data store, but it stores data distributed across multiple physical machines
This is not specific to ES. Lots of distributed databases do this. Commit this image to memory:
Image credit: LIIP

20Copyright © 2017 Uptake
A cool trick called “consistent hashing” allows ES to tolerate node failures, stay available, distribute load evenly, and scale up and down smoothly (if done correctly)Each document has a unique id that gets hashed to a physical location in the cluster. Because you only need the id to identify where a document lives, and all nodes know the hashing scheme, there is no need for a “master” or “namenode” and any node can respond to any request
Image credit: Parse.ly

Section 4Data Science Workflows with NoSQL Databases

22Copyright © 2017 Uptake
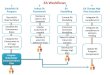
NoSQL involves “denormalizing” your data. This makes these databases very efficient for serving certain queries, but inefficient for arbitrary questions
Execute Query(DB handles joins) Train Model
Execute several queries
(join results) (Make a rectangle) Train Model
RDBMS Workflow
NoSQL Workflow

Section 5Introducing: uptasticsearch

24Copyright © 2017 Uptake
We wrote an R package called “uptasticsearch” to reduce friction between data scientists and data in Elasticsearch. We wanted data scientists to say “give me data” and get it

25Copyright © 2017 Uptake
uptasticsearch ropensci/elastic:
uptasticsearch’s API is intentionally less expressive than the Elasticsearch HTTP API. We wanted to narrow the focus to make it easy to use for people who are not sys admins or engineers

26Copyright © 2017 Uptake
We open-sourced uptasticsearch to give back to the R community and to hopefully get bright developers like you to help us make it better!
How you can get involved:
● Submit a PR addressing one of the open issues (https://github.com/UptakeOpenSource/uptasticsearch/issues)
● Download from CRAN and report any issues you encounter!
● Open issues on GitHub with feature requests and proposals

Appendix: Notes on Eventual Consistency

29Copyright © 2017 Uptake
Eventual Consistency
Some databases (like
Cassandra) implement
“tunable” consistency
Consistency strategies involve setting two parameters dictating how your cluster responds to actions:
R = “min number of nodes that have to ack a successful read”
W = “min number of nodes that have to ack a successful write”
To determine appropriate values for these, you need to also know how big your cluster is:
N = “total number of available nodes in your cluster”

30Copyright © 2017 Uptake
Eventual Consistency
“Go fast”:
R + W < N
- This strategy will give you a fast response because less nodes are involved in the decision to acknowledge a new action
- However, it is possible to get some incorrect responses...writes good go to one group of nodes and reads could hit a totally separate set of nodes (none of which have the correct value)
- Example with R = 1, W = 1, N = 3:
box1 box2
box3R
W

31Copyright © 2017 Uptake
Eventual Consistency
“Majority Rules”:
R + W > N
- This strategy is faster than total consistency but can still give good guarantees about correctness
- With this strategy, you are guaranteed to have at least one node that has the most recent write and acknowledges the new read
- Example with R = 2, W = 2, N = 3:
box1
box3
box2W
R
R
W

32Copyright © 2017 Uptake
Eventual Consistency
“Total Certainty”:
R + W = 2N
- This strategy is equivalent to consistency in an RDMBS- Every node has to participate in every read / write- Response latency will be controlled by the slowest node
box1 box2
box3
W
W R
RWR

33Copyright © 2017 Uptake
Eventual Consistency
Try this demo to get a
hands-on look at different
consistency strategies
Demo + awesome resource to learn more: http://pbs.cs.berkeley.edu/#demo