Embed Size (px)
Citation preview

Studies of HPCC Systems® from Machine Learning Perspectives
Ying Xie, Pooja Chenna, Ken Hoganson Department of Computer Science
Kennesaw State University

Outline • Leverage and Enhance Deep Learning Capability of HPCC
Systems®
• Comparative Studies of HPCC Systems® and Hadoop Systems

Leverage and Enhance Deep Learning Capability of HPCC Systems®
• Deep learning has been emerged as a recent breakthrough in the area of Machine Learning and revitalized research activities in Artificial Intelligence (AI).
• The development of deep learning techniques has been primarily driven by big data analytics.
• Since HPCC Systems is a well established big data platform, it is very important to leverage and enhance the deep learning capability of the HPCC Systems platform.

Images are copied from neuralnetworksanddeeplearning.com
• From Neural Network to Deep Learning
A typical multilayer perceptron

A deep neural architecture

Stacked Autoencoder

Images are copied from ufldl.stanford.edu
• Stacked Autoencoder

This code was implemented by Maryam Mousaarab Najafabadi from F

Deep Belief Network

Restricted Boltzmann Machine
Images are copied from http://deeplearning4j.org/

Deep Belief Network

Visualize High Dimensional Data

• Iris Data

Use DBN to conduct dimension reduction



• Breast Cancer Wisconsin (Original) Data Set

Use DBN to conduct dimension reduction



• Glass Data

Use stacked auto-encoder to conduct dimension reduction

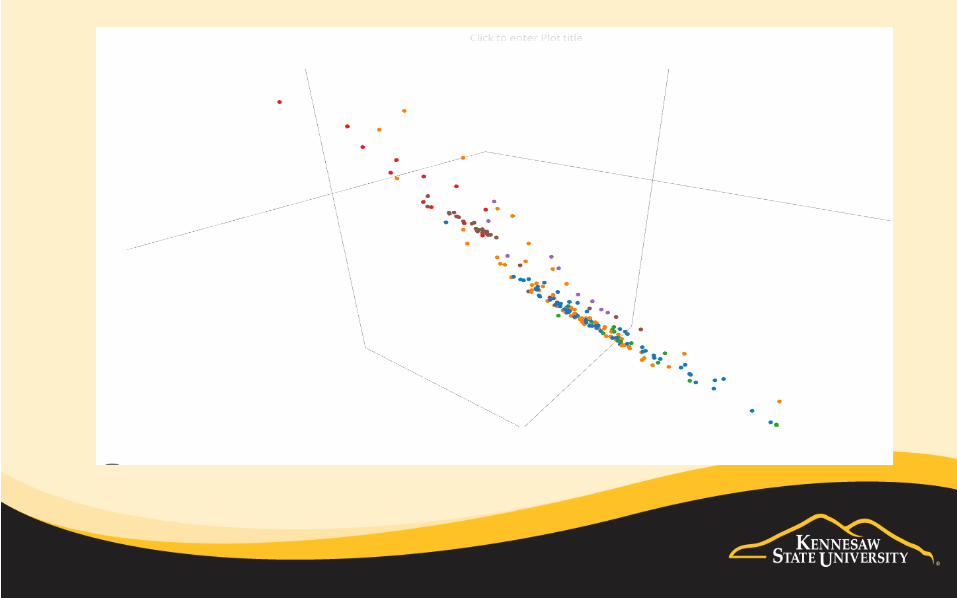
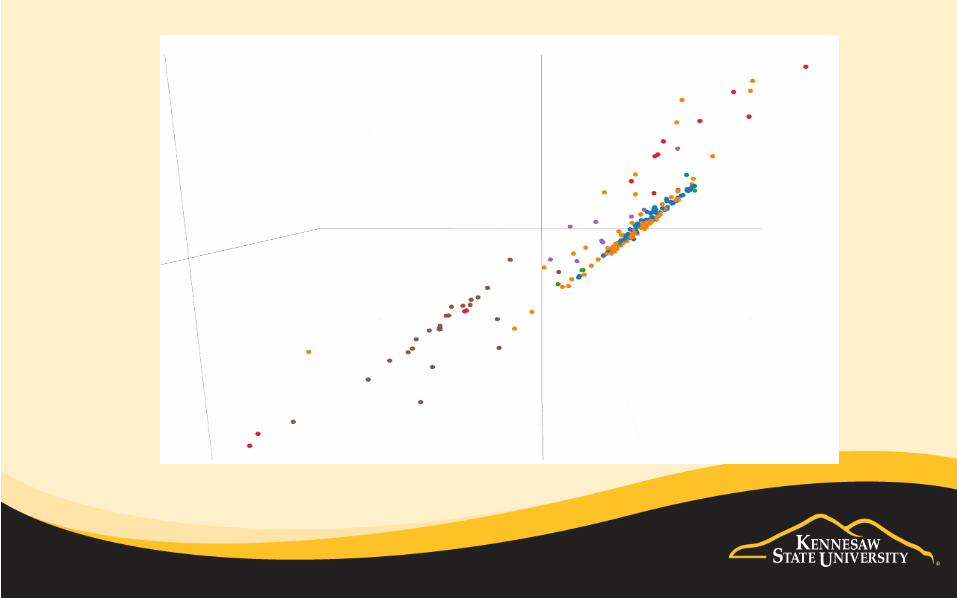


• Based on the visualization, we may even gain some good ideas what classification algorithm may work well

Classification Algorithm #Miss-classified Instances
Logistic 72
MLP 66
Simple Logistic 70
7NN 76
5NN 70
3NN 64

Mapping Data to Higher Dimensional Spaces

• Blood Transfusion Data


• Classification performance on higher dimensional space
Original Space (4 Dim) (#Miss-classified Instances)
Higher Dim (10 Dim) (#Miss-classified Instances)
Logistic 171 157 MLP 160 166
Mapped to higher dimensional space by Stacked Auto-Encoder
Mapped to higher dimensional space DBN

• Wine Data

• Classification performance on higher dimensional space
Original Space (13 Dim) (#Miss-classified Instances)
Higher Dim (15 Dim) (#Miss-classified Instances)
Logistic 10 6 MLP 4 4
Original Space (13 Dim) (#Miss-classified Instances)
Higher Dim (15 Dim) (#Miss-classified Instances)
Logistic 10 7 MLP 4 2
Mapped to higher dimensional space by Stacked Auto-Encoder

• For a given data set, we can explore which combination of deep learning mapping techniques, dimensional space, and supervised learning model may yield best classification result

• For instance – Breast Cancer Data
3 Dim. Space (#Miss-classified
Instances)
6 Dim. Space (#Miss-classified
Instances)
9 Dim. Space (#Miss-classified
Instances)
12 Dim. Space (#Miss-classified
Instances)
Logistic 22 21 24 25 MLP 21 22 30 21
3 Dim. Space (#Miss-classified
Instances)
6 Dim. Space (#Miss-classified
Instances)
9 Dim. Space (#Miss-classified
Instances)
12 Dim. Space (#Miss-classified
Instances)
Logistic 22 23 24 25 MLP 20 21 30 22
Mapped to different dimensional spaces by Stacked Auto-Encoder
Mapped to different dimensional spaces by DBN

• Our next step: try to implement a meta supervised learning algorithm on HPCC – This algorithm will automatically map the given data
to different dimensional spaces by using both stacked auto-encoder and DBN
– Then classification models will be trained on all dimensional spaces in a distributed manner
– Cross-validation will be used to select the best performed model as the final output.

Implementation of Deep Belief Network on
HPCC

Our Implementations of Deep Learning on HPCC
• Restricted Boltzmann Machine (RBM) with Contrastive Divergence learning algorithm
• Deep Belief Network by stacking RBMs • Supervised Deep Belief Network

Machine Learning Routines • Utility Module • Matrix Library • Dense Matrix Library • PBblas

Restricted Boltzmann Machine - RBM
v
h
v’
h’

w(t+1) = w(t) + α(vhT – v’h’T)

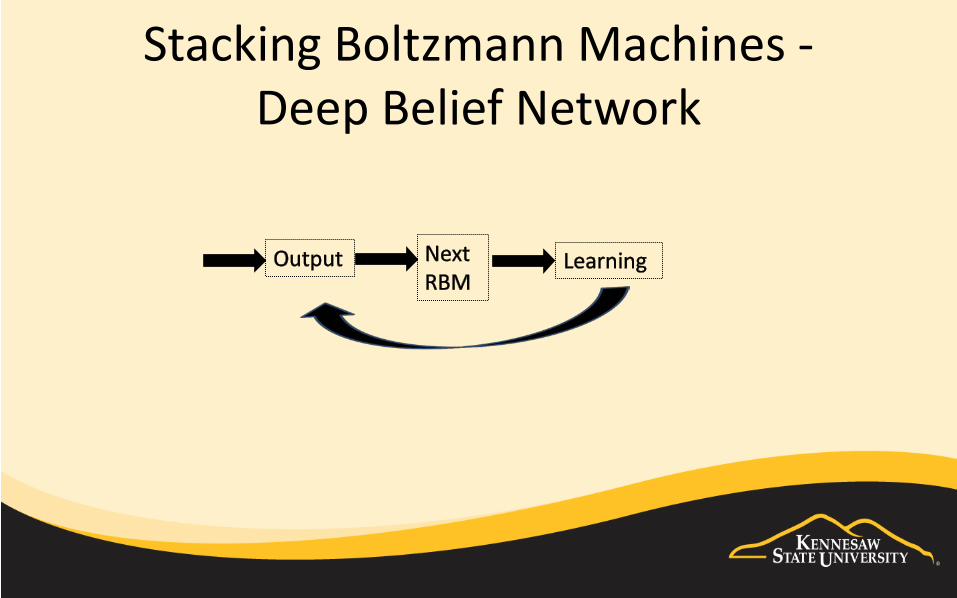
Stacking Boltzmann Machines - Deep Belief Network

Final Output
Input Parameters
• Iris Data Sample

Supervised Boltzmann Machine – Deep Belief Network
y – actual output h – hidden samples v – visible samples

Supervised Deep Belief Network

• Our ultimate goal is to implement a full-stack of deep learning techniques on HPCC and conduct a wide range of experiences to show how powerful the deep learning engine on HPCC will be.

Comparative Studies of HPCC and Hadoop

• HPCC and Hadoop clusters on CSCloud – HPCC cluster :
• 5 thor nodes • 5 roxie nodes • 2 middle-ware nodes • 1 landing zone node for uploading files
– Hadoop cluster
• 1 job-tracker / name-node • 1 support system (Web UI, hadoop ecosystem, etc) • 4 worker nodes: task-tracker / data-node

• Algorithms for comparison – Text Processing Algorithms:
• Word Count • Inverted Index
– Machine Learning Algorithms: • Supervised Learning Algorithm - Random Forests • Unsupervised Learning Algorithm - KMeans
– Graph Algorithm: • Page Rank

Text Processing Algorithms Data: Authorized version of Bible downloaded from http://av1611.com/ HPCC Implementation of Inverted Index: http://www.dabhand.org/ECL/construct_a_simple_bible_search.htm (implemented by David Bayliss, Chief Data Scientist and VP of LexisNexis Risk Solutions) Hadoop Implementation of Inverted Index: Victor Guana and Joshua Davidson. On Comparing Inverted Index Parallel Implementations Using Map/Reduce Technical Report. May 09, 2012.
Algorithm HPCC Hadoop
Word Count 1.003 seconds 23.466 seconds
Inverted Index 34.205 seconds 27.047 seconds

Machine Learning Algorithms Data: KDD Network Intrusion Dataset Reference: C. Blake and C. J. Merz. UCI Repository of machine learning databases. Irvine, CA: University of California, Department of Information and Computer Science. [http://www.ics.uci.edu/~mlearn/MLRepository.html] Description:
– Total number of Instances : 4000000 – Used instances : 20394 randomly picked – Number of Attributes : 42
Hadoop Libraries – Apache Mahout:
– Version : CDH-5.4.2-1 (Cloudera)
HPCC Machine Learning Library

Efficiency:
Algorithm HPCC Hadoop
Random Forests 1 minutes 50 seconds 18 seconds
KMeans 36.675 seconds 1 min 45 seconds

Graph Algorithm Data Sets: Randomly generated graph with 25 nodes with maximum degree 5. HPCC Implementation of Pageranking – Our team’s implementation Hadoop Implementation Pageranking - http://blog.xebia.com/2011/09/wiki-pagerank-with-hadoop/
Algorithm HPCC Hadoop
Page Rank 29.817 seconds 36 minutes

THANK YOU





























