Embed Size (px)
Citation preview

Lessons Learned Optimizing NoSQL for
Apache SparkJohnMusser@johnmusser /Basho@basho
SparkSummitEurope,2016
NoSQL
NoSQLKey-Value
DocumentColumnar
Graph
NoSQLKey-Value
DocumentColumnar
Graph
+NoSQL
+NoSQL = ?
+ =NoSQL
+ =NoSQL
How do we turn this…
+ =NoSQL
into this?

+ =We built this.

+ =We built this.
Here are our lessons…

ParallelizeMap smart
Optimize all the levelsBe flexible
Simplify

Riak
• Distributed,key-valueNoSQLdatabase• Knownforscalability,reliability,opssimplicity• Launched2009,usedby1/3ofFortune50• Opensource(Apache),onGitHubhttps://github.com/basho/riak/• EnterpriseEdition,seemulti-clusterreplication

We started to see in our customer base…

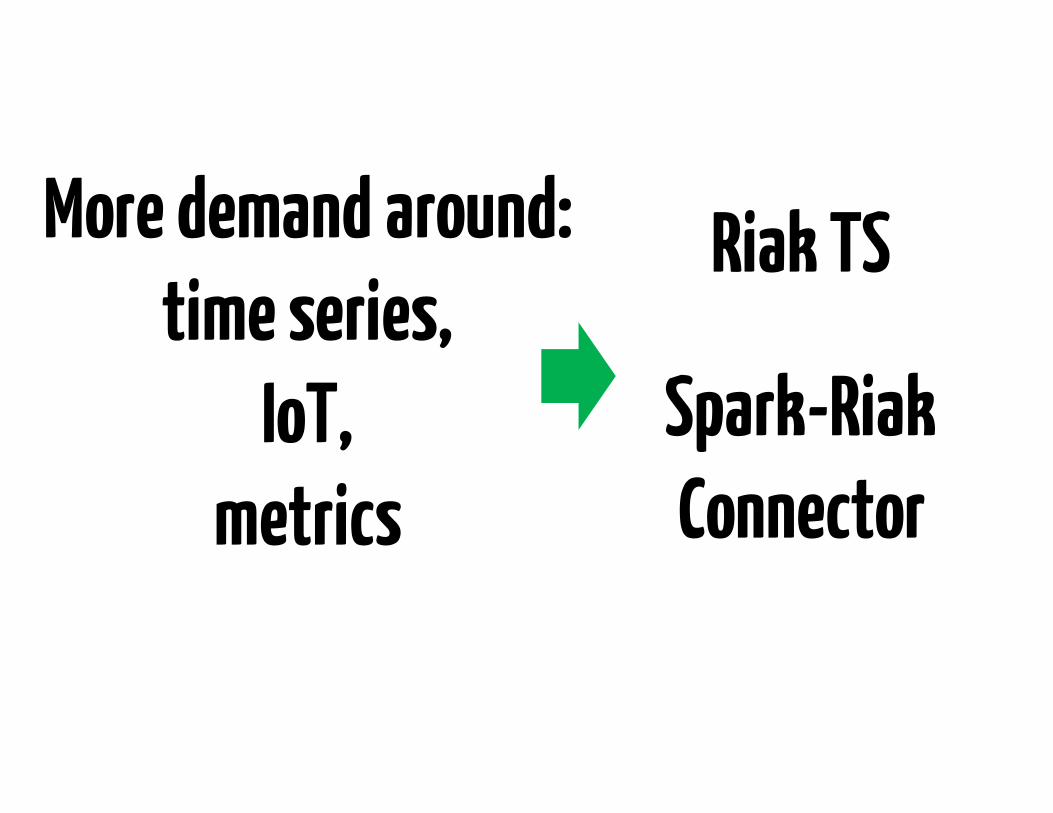
More demand around:time series,
IoT, metrics
More demand around:time series,
IoT, metrics
Riak TS
Spark-Riak Connector
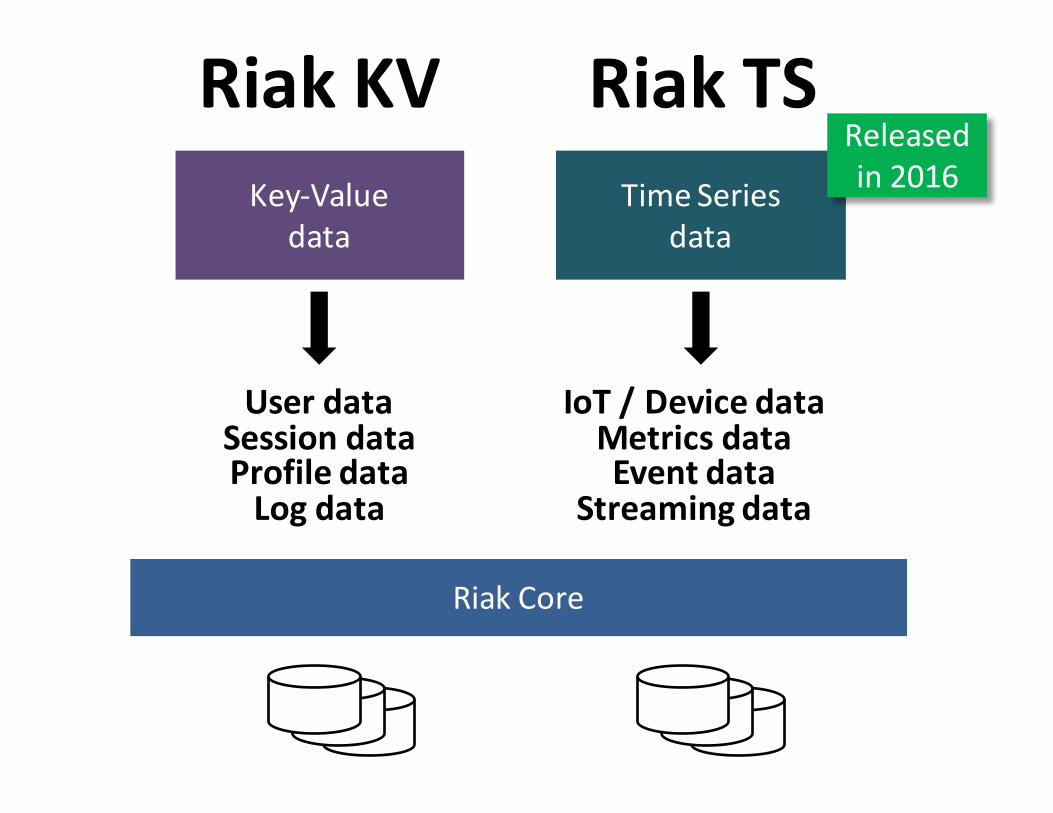
Key-Valuedata
TimeSeriesdata
RiakKV RiakTS
UserdataSessiondataProfiledataLogdata
IoT/DevicedataMetricsdataEventdata
Streamingdata
RiakCore
Releasedin2016
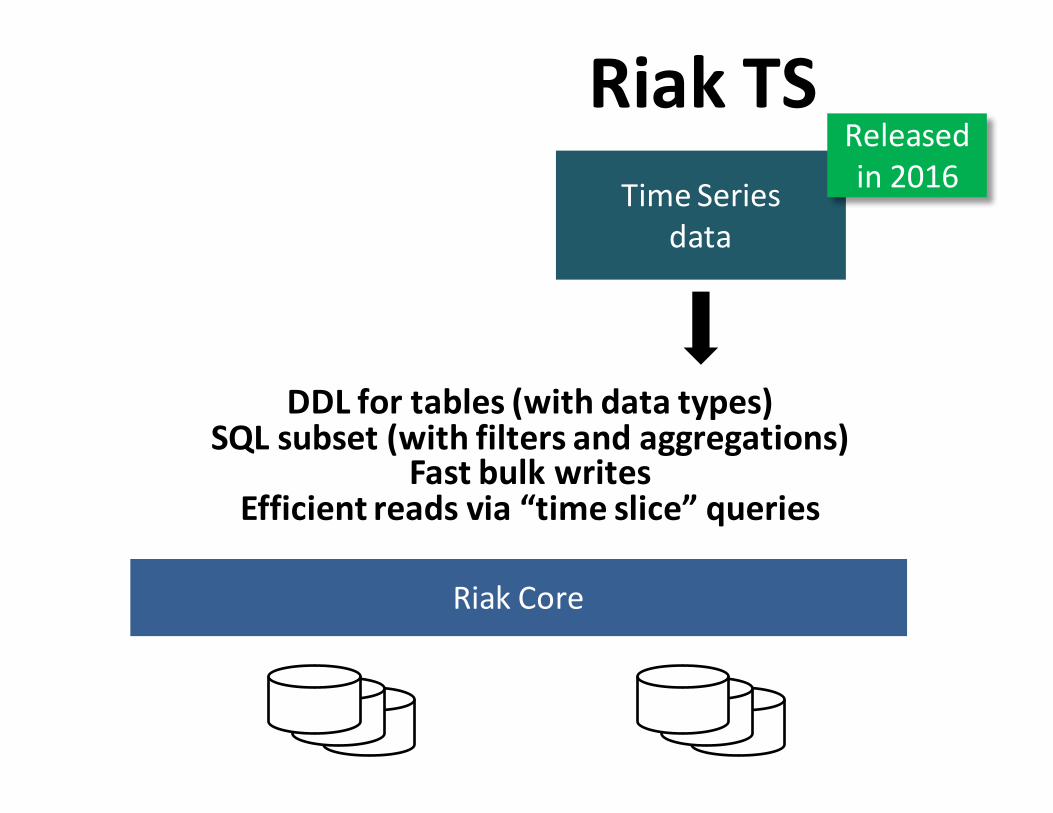
TimeSeriesdata
RiakTS
DDLfortables(withdatatypes)SQLsubset(withfiltersandaggregations)
FastbulkwritesEfficientreadsvia“timeslice”queries
RiakCore
Releasedin2016

Intellicore SportsDataPlatform• 1GBtelemetryperdriver• 400packets/second• 1.2Mpackets/race• Platformsetupfor40,000TPS

Spark-RiakConnector
• Version1.0:publishedSept.2015• Currentversion:1.6,publishedSept.2016• Scala/JVMbased• SupportforJava,Scala,Python• SupportsSpark1.6.x• Opensource(Apache),onGitHubhttps://github.com/basho/spark-riak-connector/
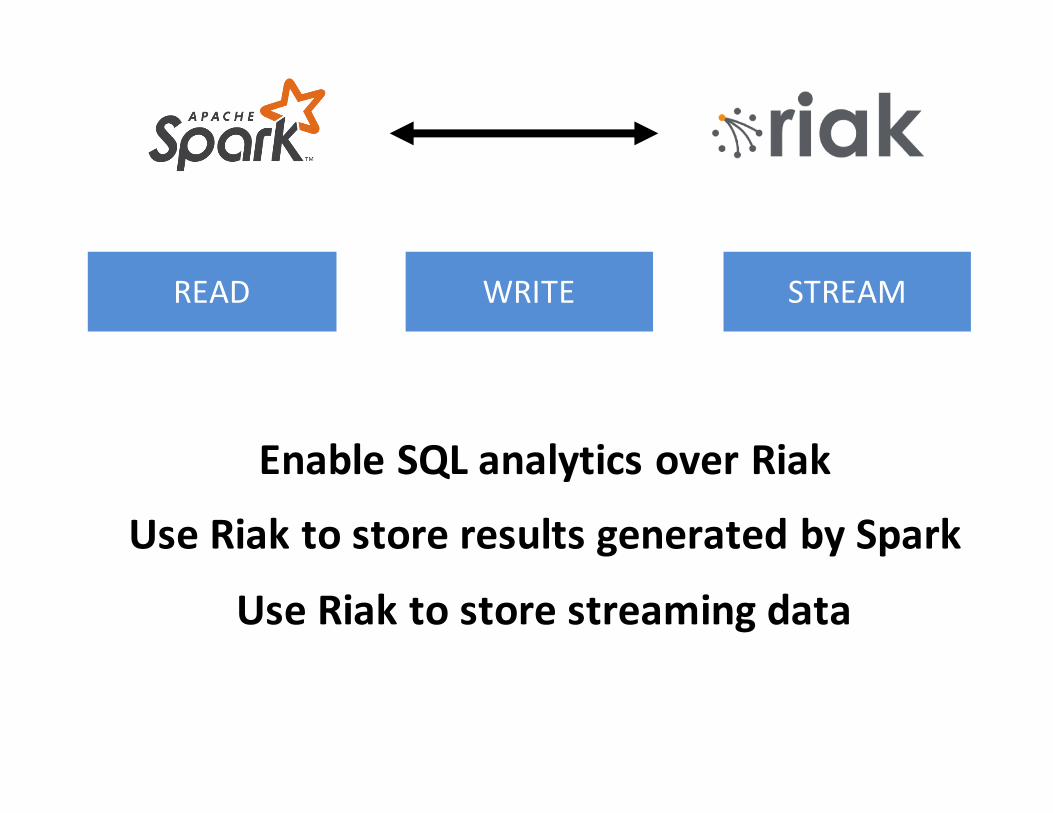
EnableSQLanalyticsoverRiak
UseRiaktostoreresultsgeneratedbySpark
UseRiaktostorestreamingdata
READ WRITE STREAM

(this in turn uses learnings from other connectors we’ve built...)

Parallelize whenever possible
?

?Howtomovelotsofdataquicklyandefficiently?
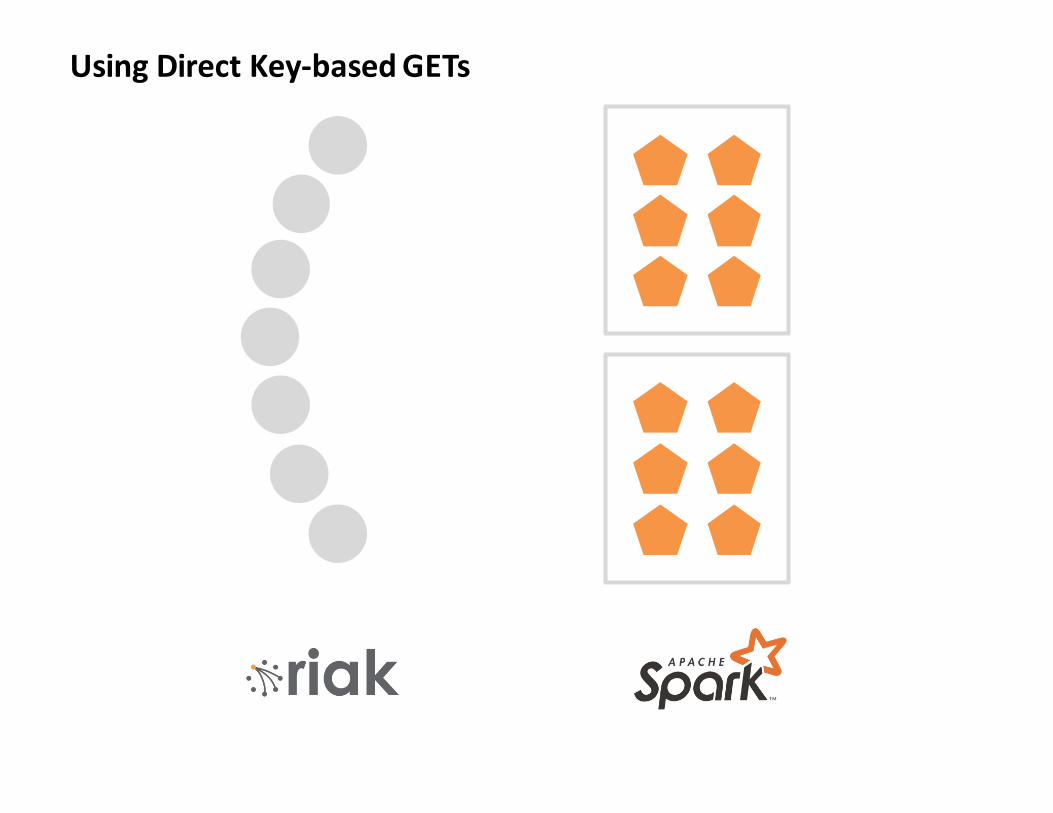
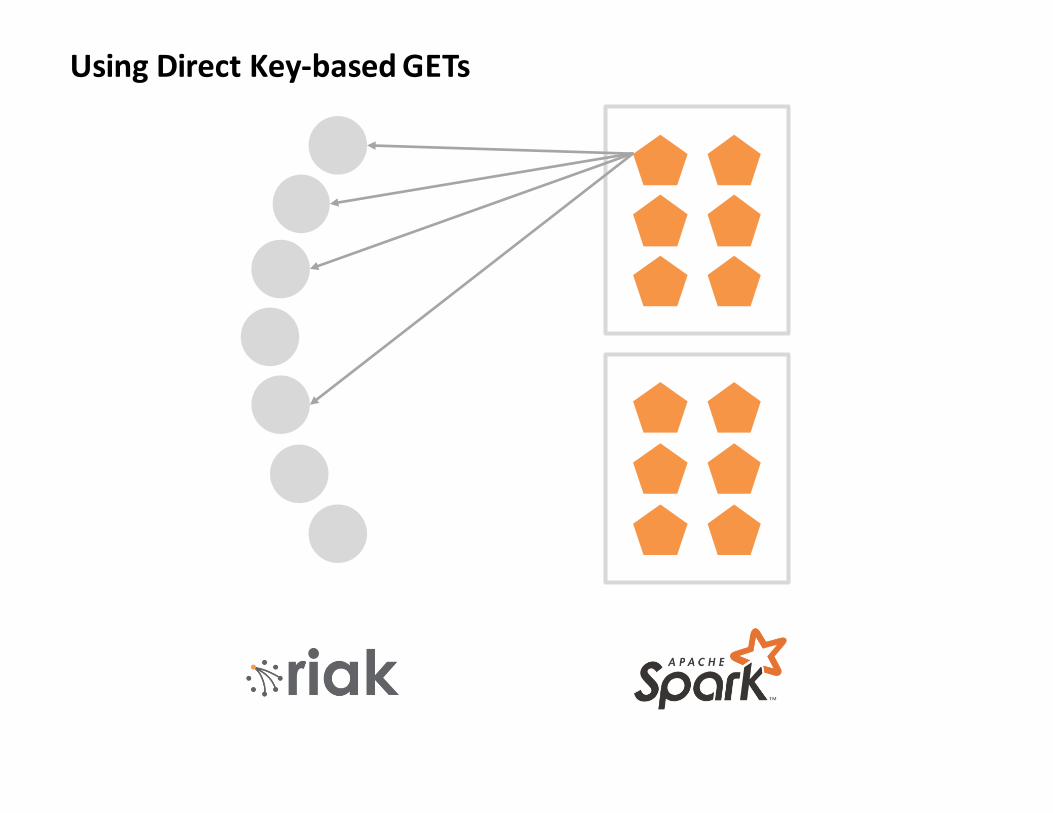
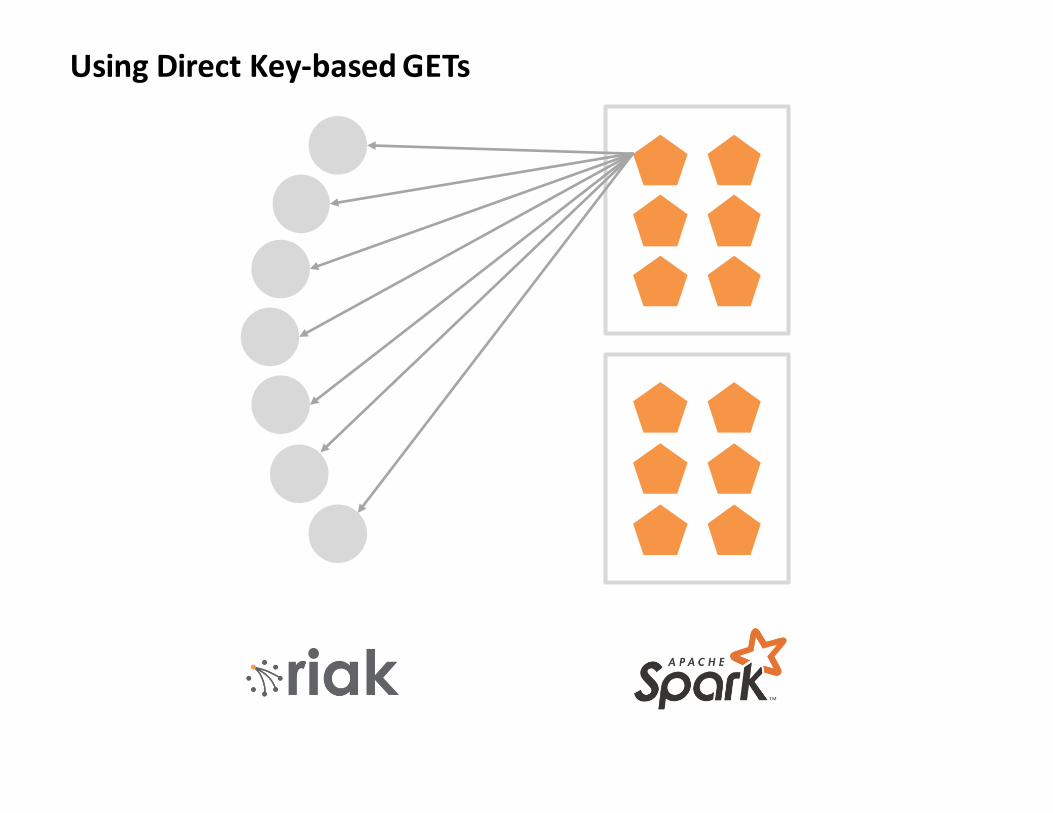
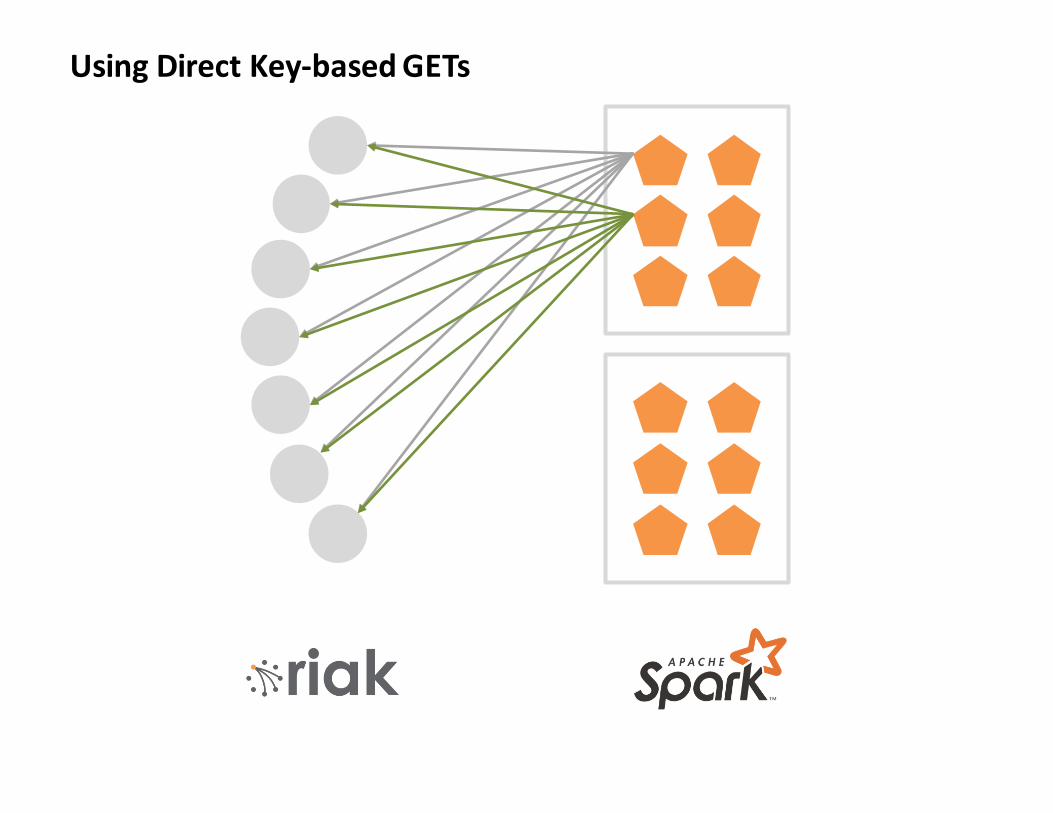
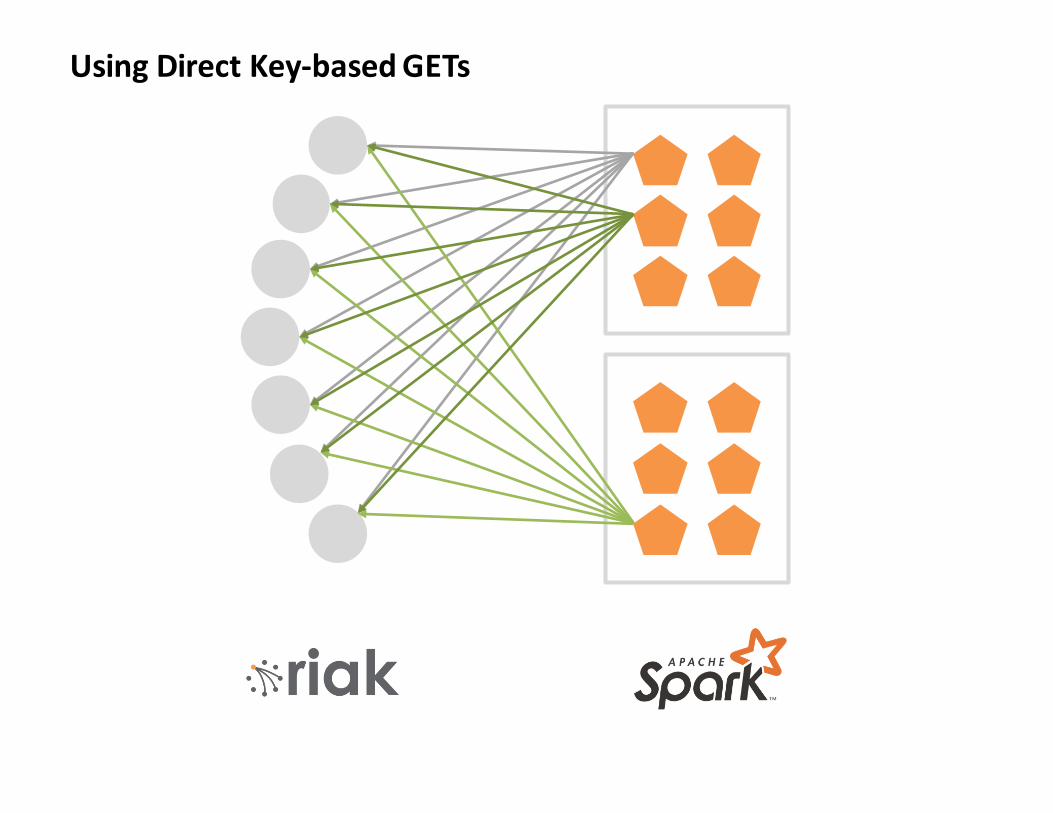
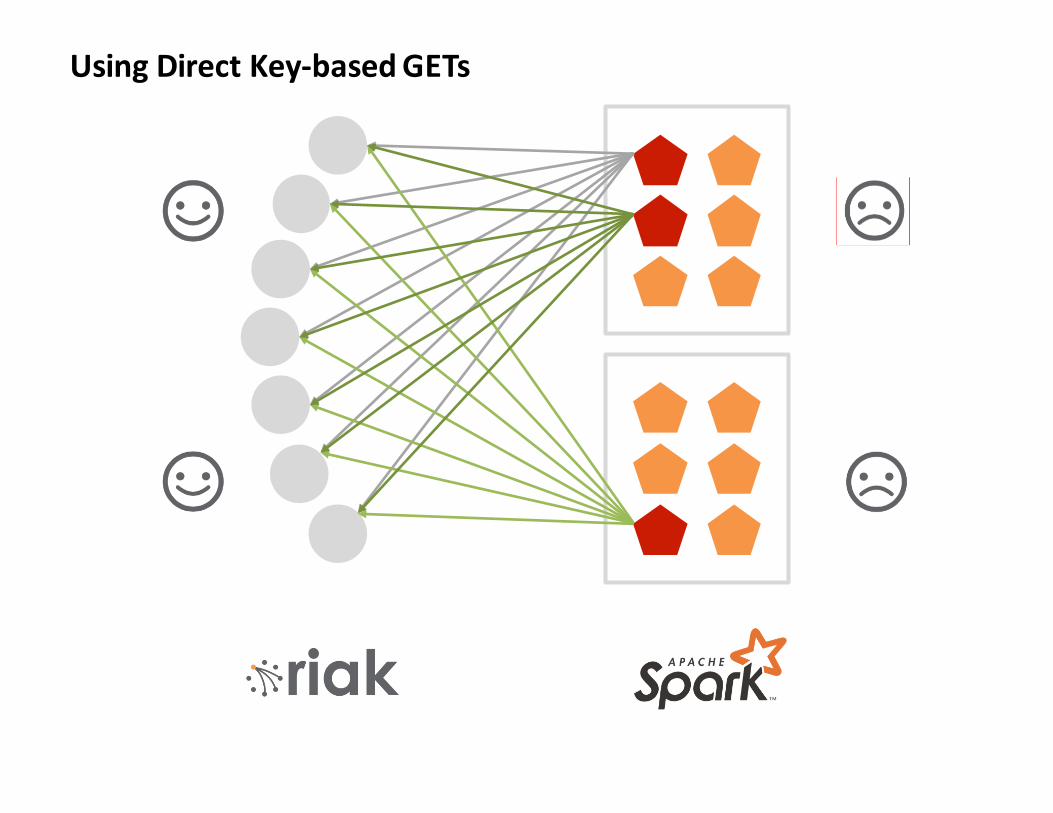
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
UsingDirectKey-basedGETs
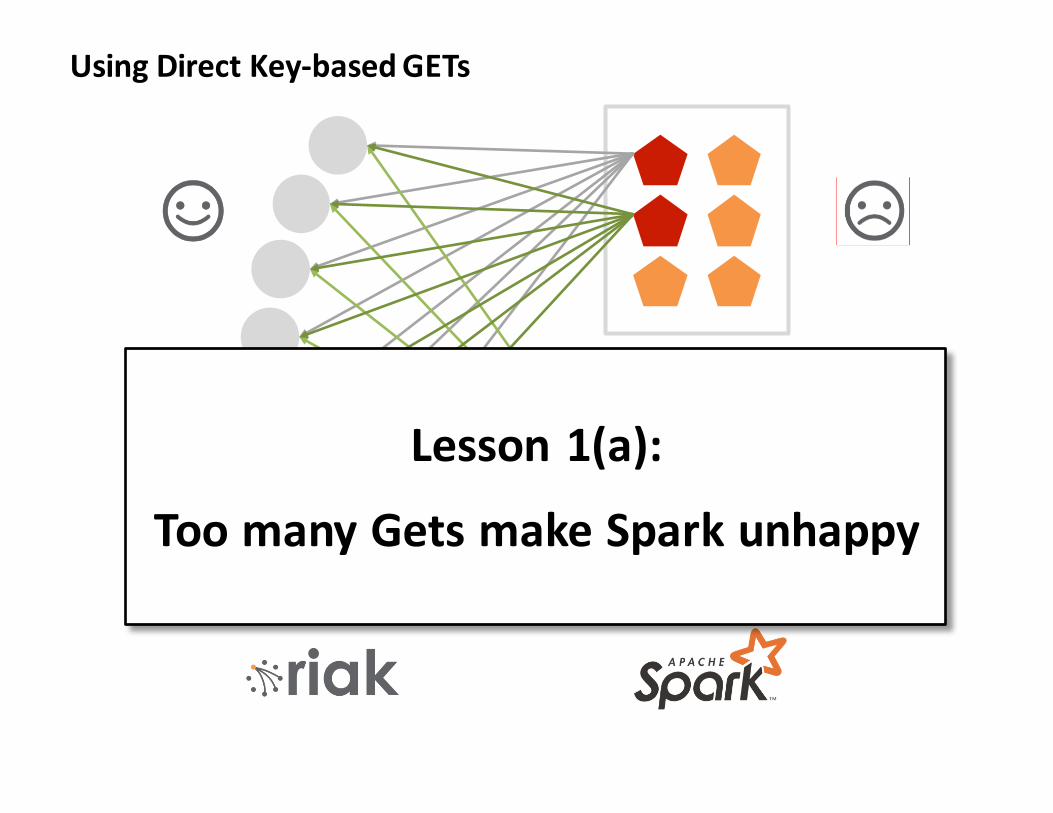
Lesson1(a):
ToomanyGetsmakeSparkunhappy
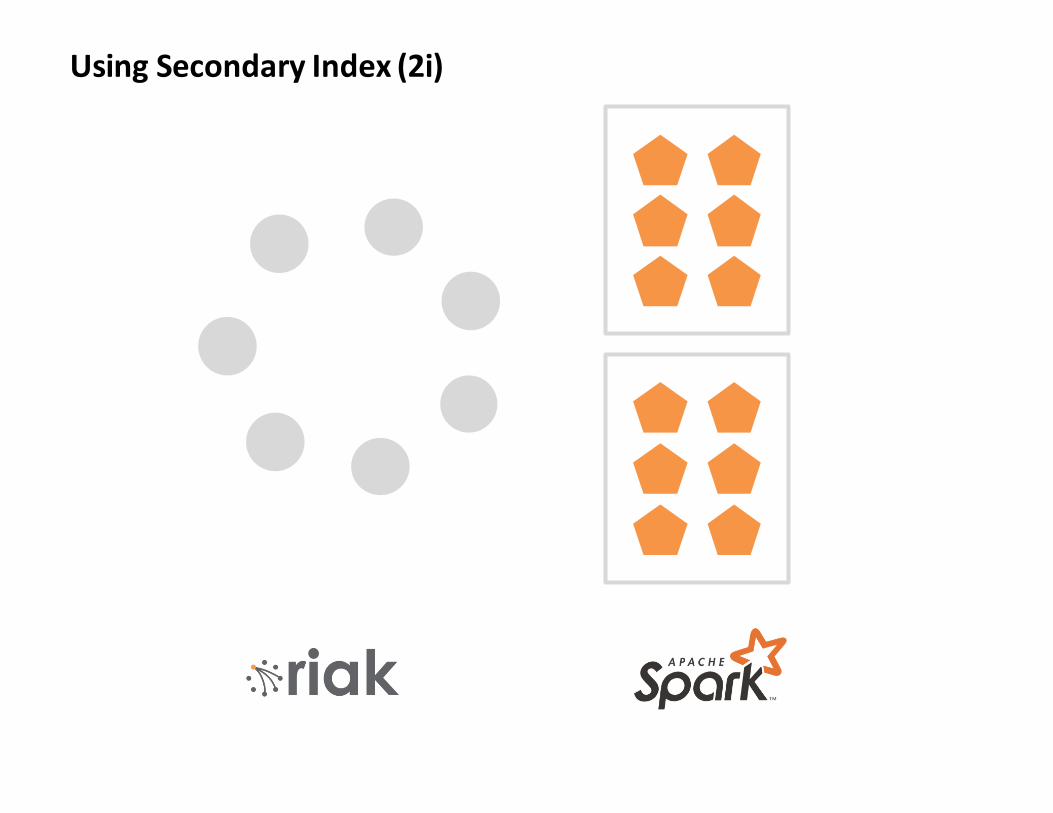
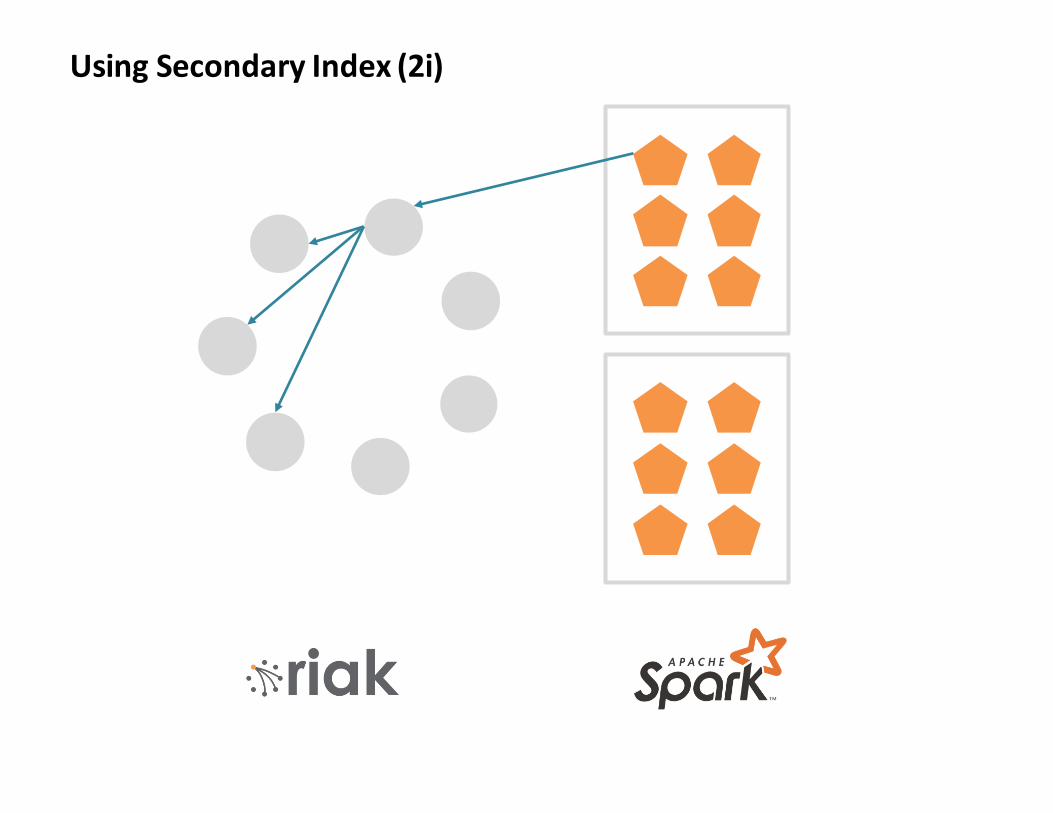
UsingSecondaryIndex(2i)
UsingSecondaryIndex(2i)
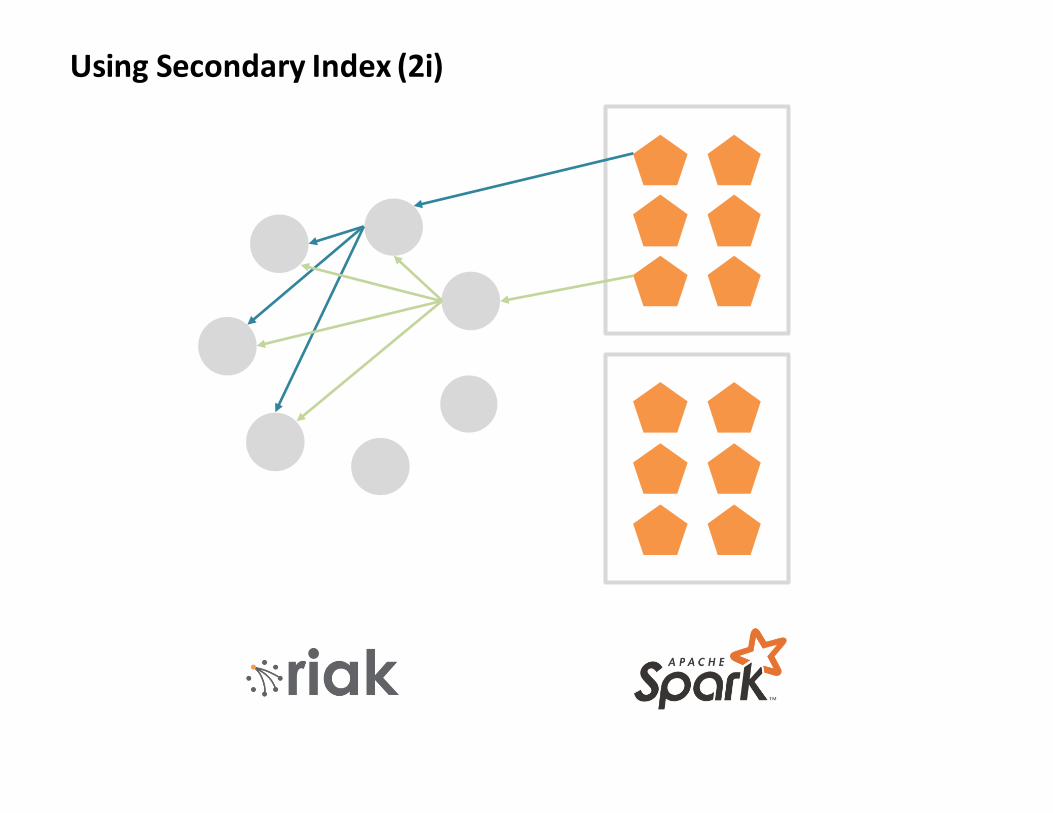
UsingSecondaryIndex(2i)
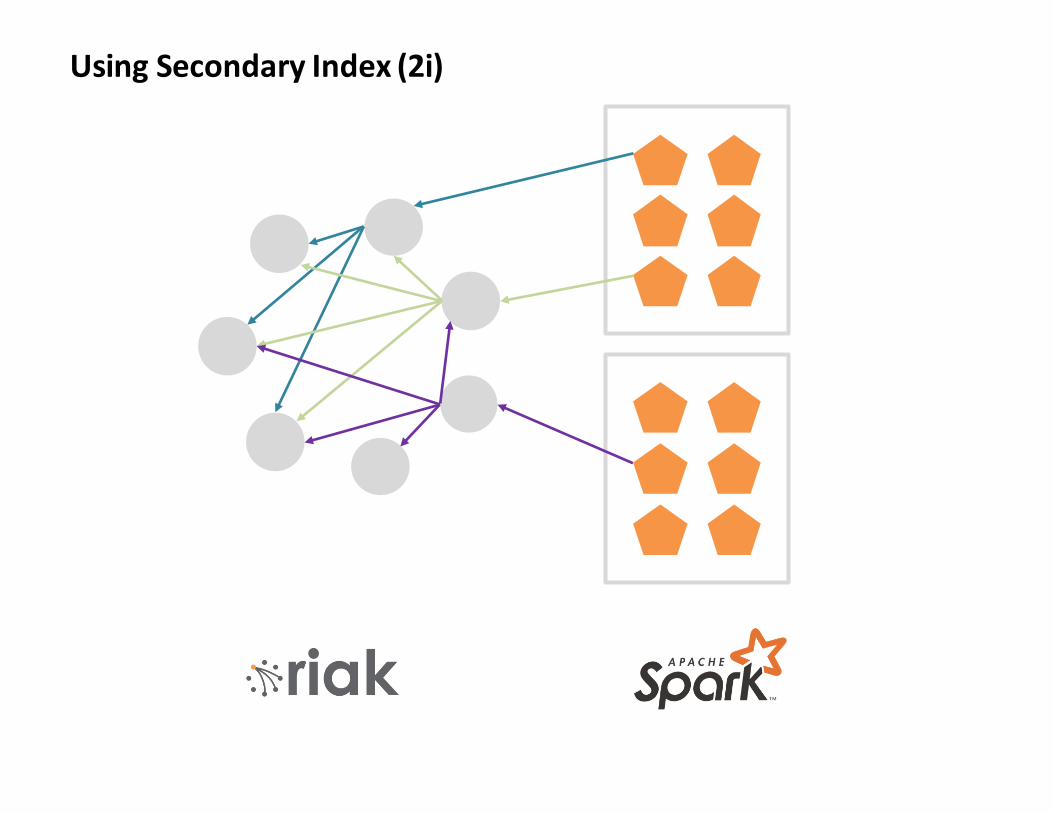
UsingSecondaryIndex(2i)
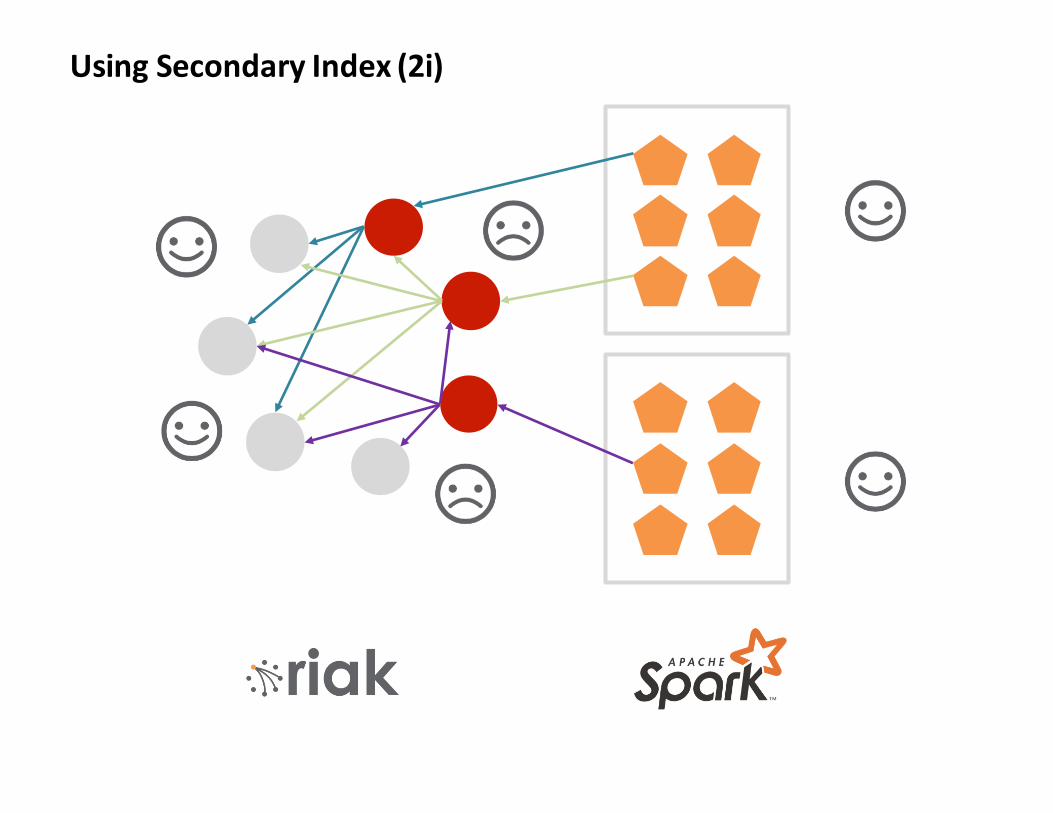
UsingSecondaryIndex(2i)
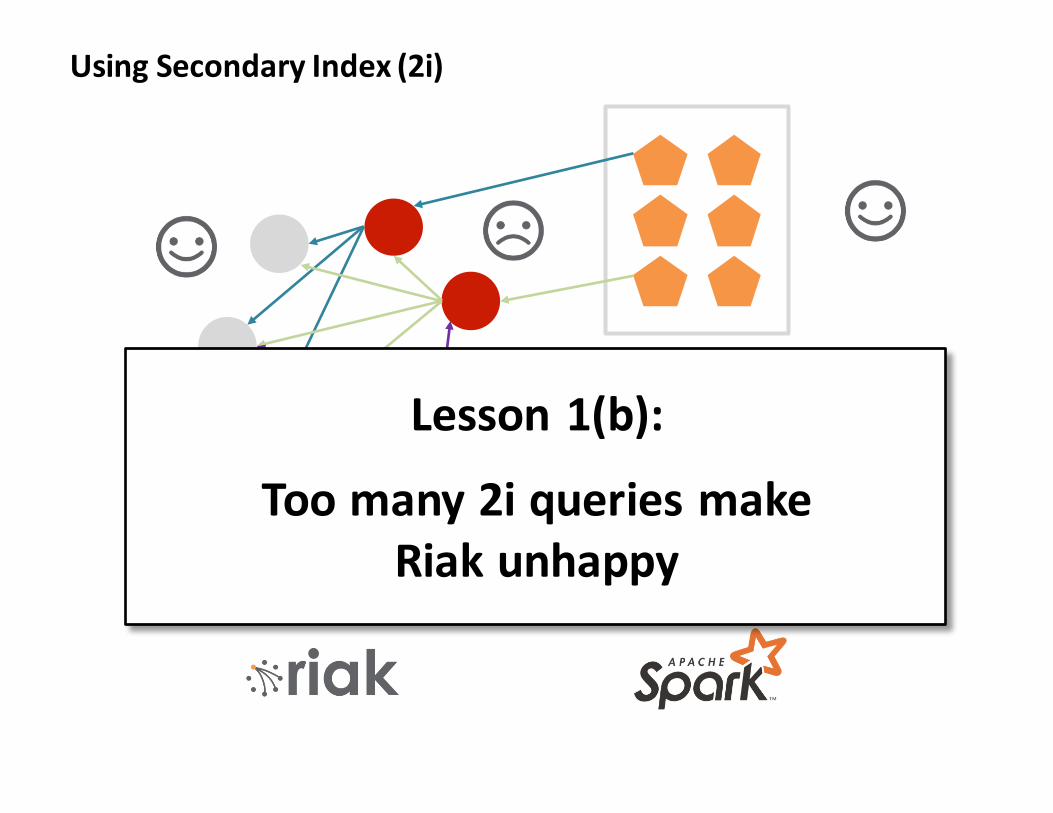
Lesson1(b):
Toomany2iqueriesmakeRiakunhappy
UsingSecondaryIndex(2i)
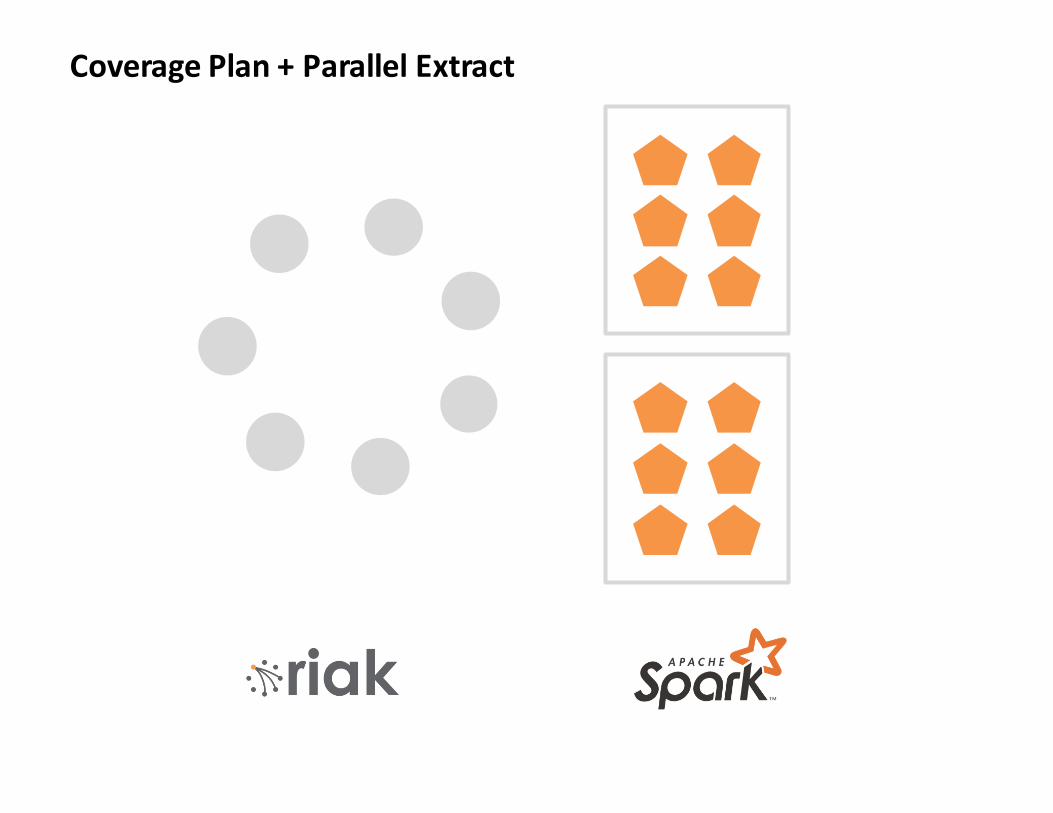
CoveragePlan+ParallelExtract
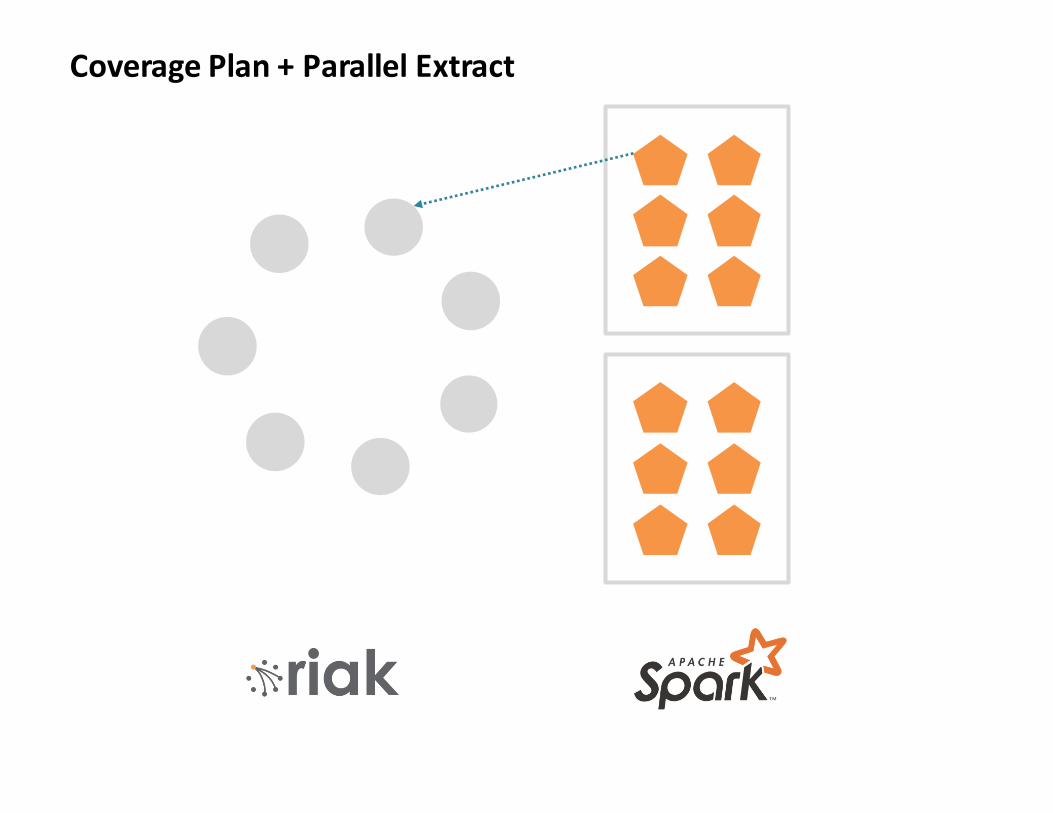
CoveragePlan+ParallelExtract
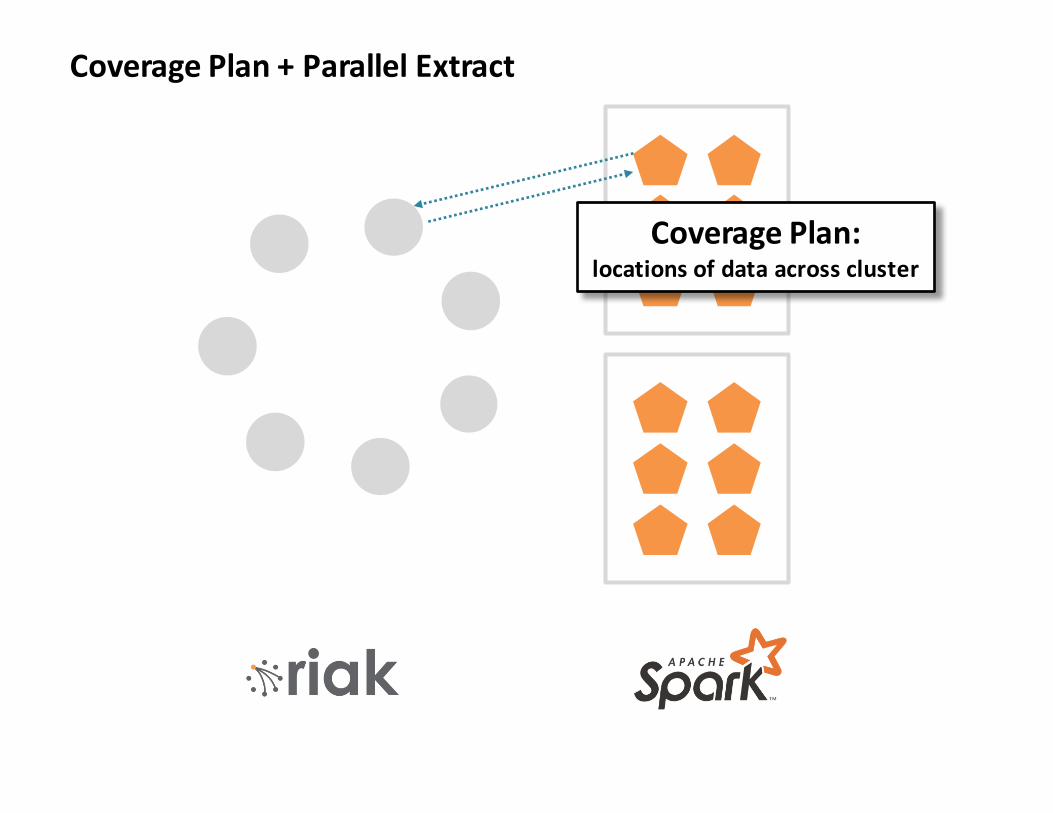
CoveragePlan:locationsofdataacrosscluster
CoveragePlan+ParallelExtract
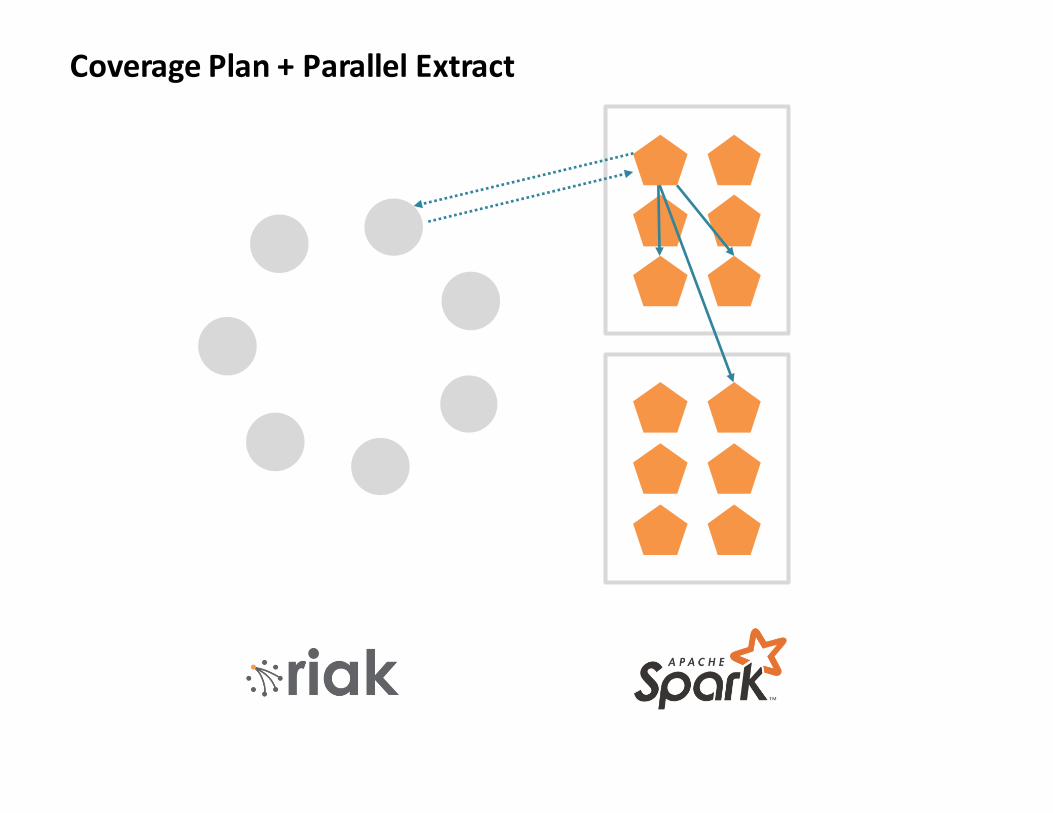
CoveragePlan+ParallelExtract
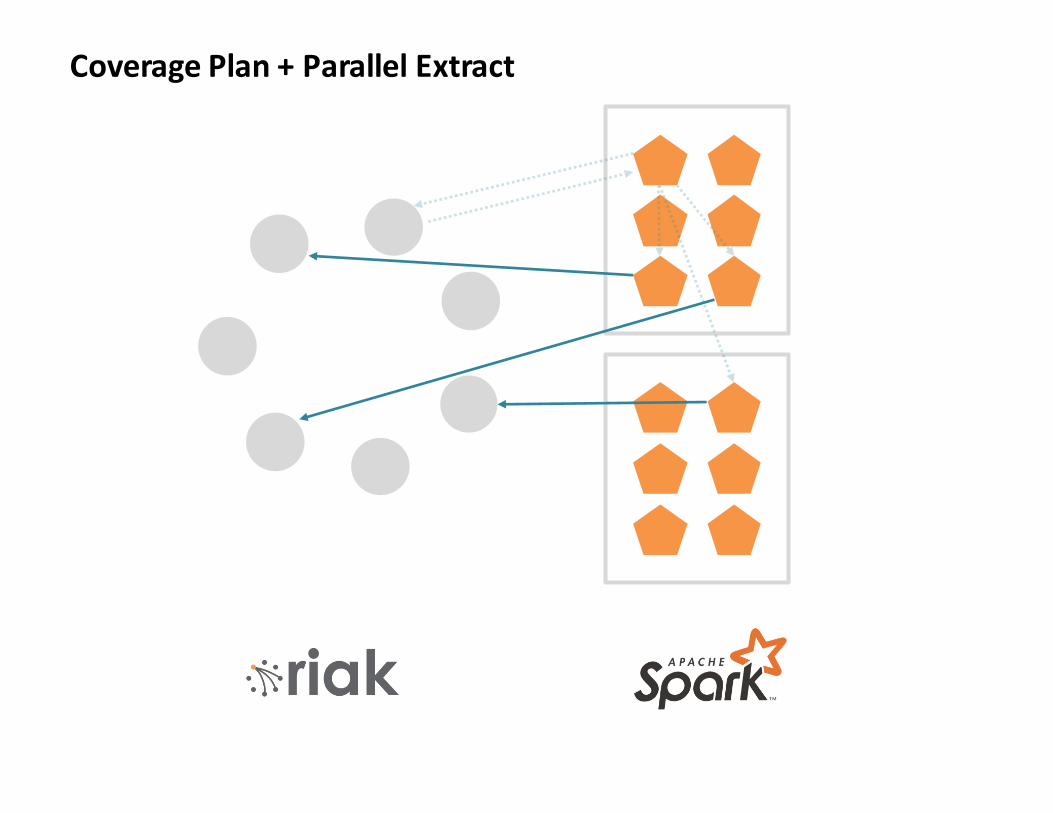
CoveragePlan+ParallelExtract
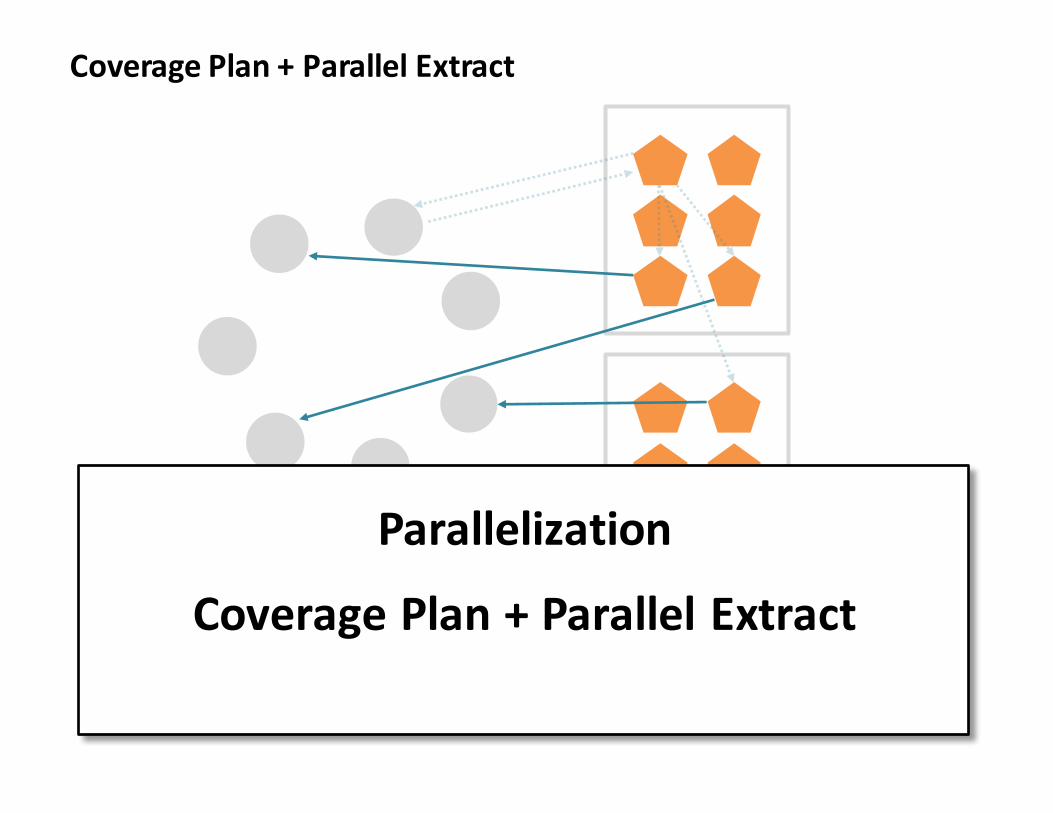
CoveragePlan+ParallelExtract
Parallelization
CoveragePlan+ParallelExtract
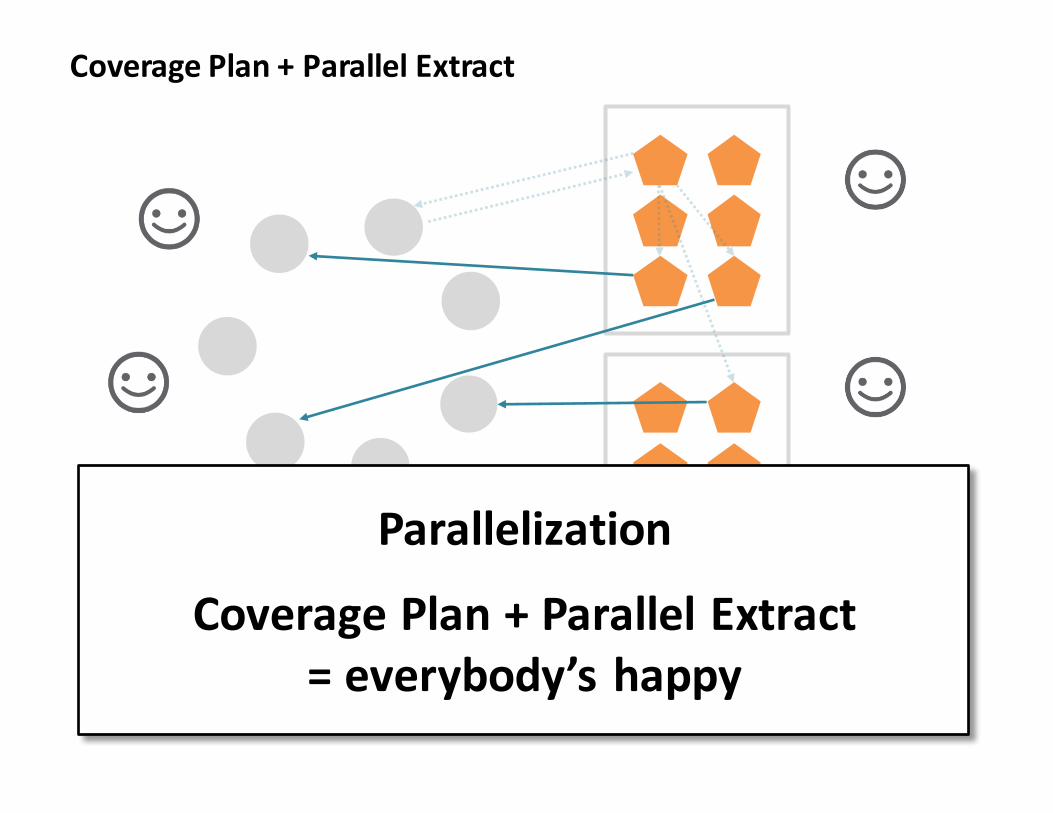
CoveragePlan+ParallelExtract
Parallelization
CoveragePlan+ParallelExtract=everybody’shappy

Be smartabout
data mapping
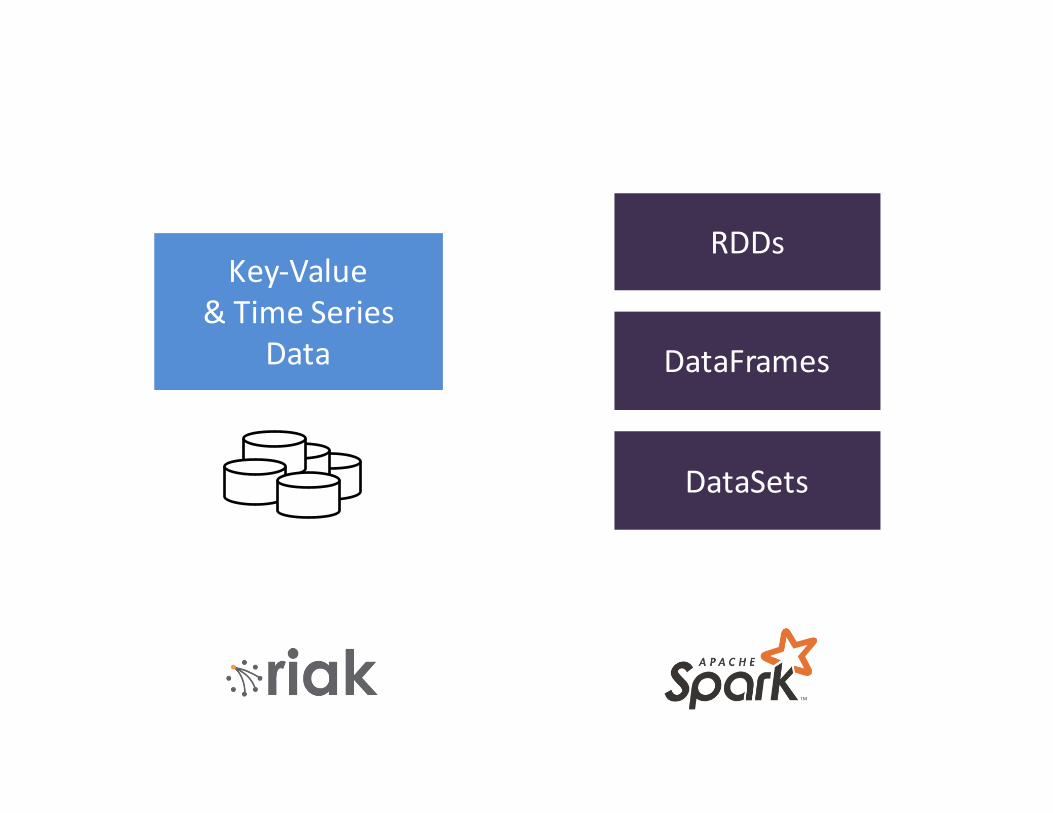
Key-Value&TimeSeries
Data DataFrames
RDDs
DataSets
Key-Value&TimeSeries
Data DataFrames
RDDs
DataSets
PlainText
XML
JSON
Binary
Key-Value&TimeSeries
Data DataFrames
RDDs
DataSets
?

Key-Value&TimeSeries
Data DataFrames
RDDs
DataSets
?Howtomapthedataasefficientlyandseamlessly
aspossible?
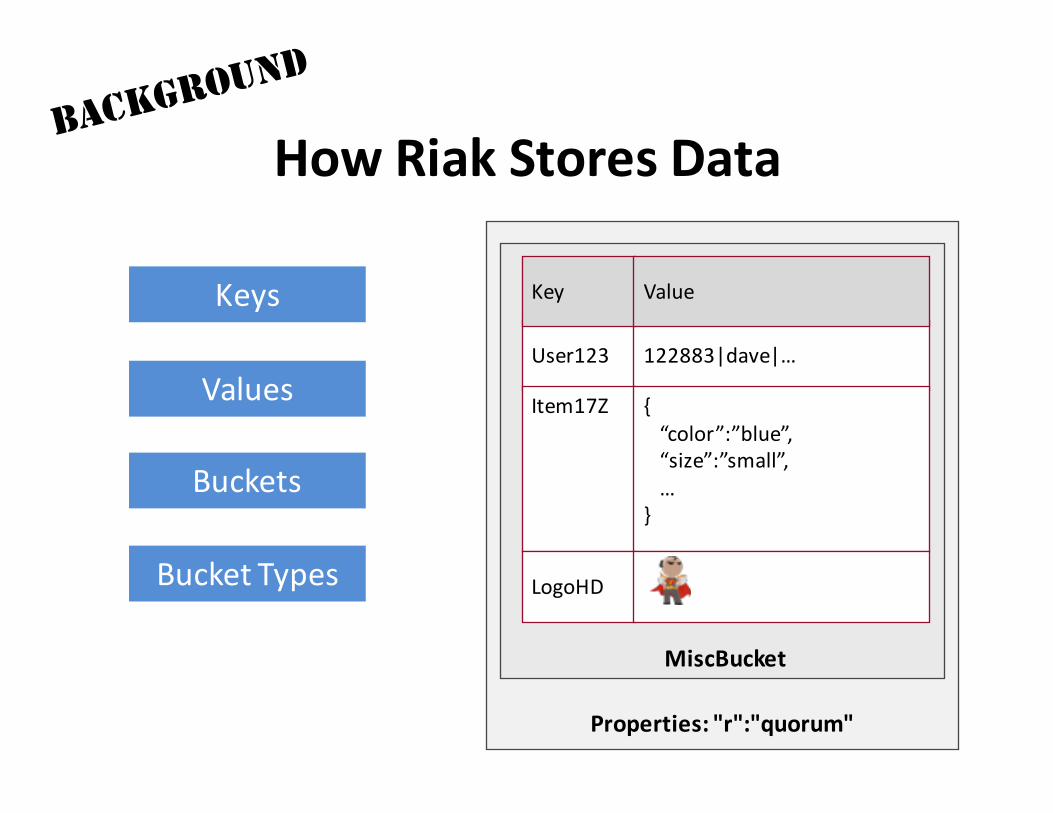
Properties:"r":"quorum"
HowRiakStoresData
MiscBucket
User123 122883|dave|…
Item17Z {“color”:”blue”,“size”:”small”,…
}
LogoHD
Key ValueKeys
Values
Buckets
BucketTypes
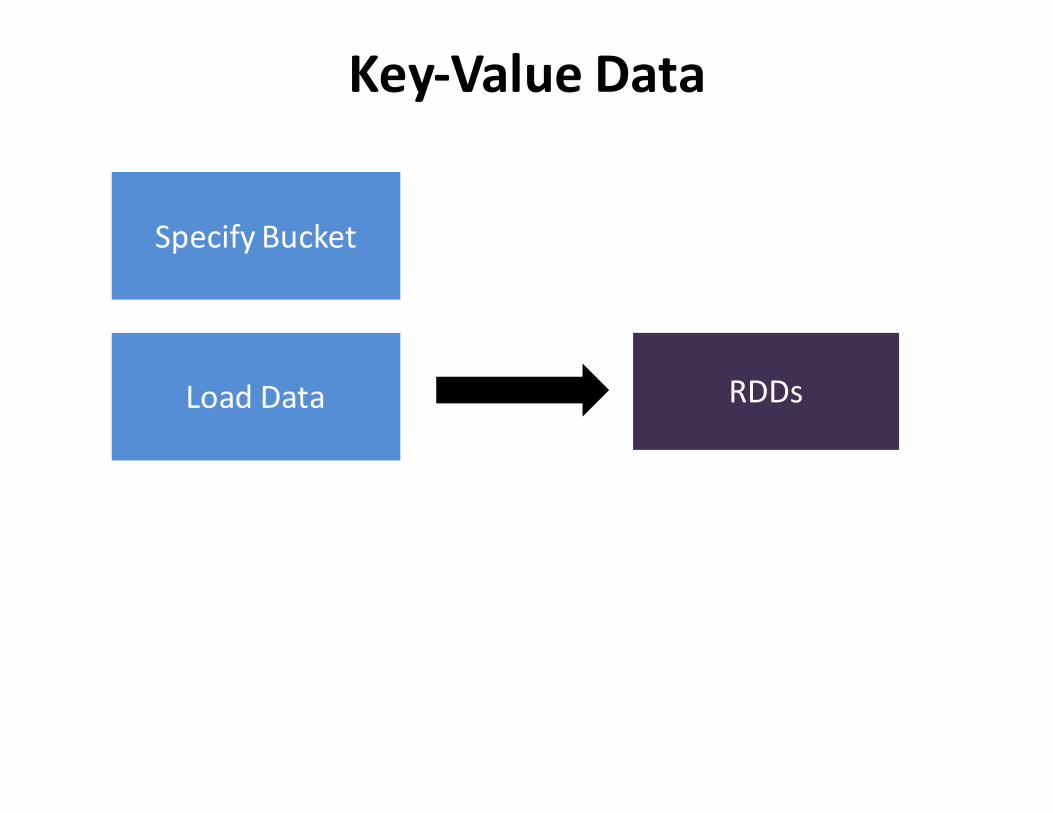
SpecifyBucket
RDDsLoadData
Key-ValueData

SpecifyBucket
LoadData
val kv_bucket = new Namespace(”MiscBucket")
val riakRdd = sc.riakBucket[String](kv_bucket).queryAll()
Code: Key/Value Query

QuerybyKeys
Queryby2iRange
val rdd =sc.riakBucket[String](kv_bucket_name).queryBucketKeys("Alice", "Bob", "Charlie")
val rdd = sc.riakBucket[String](kv_bucket_name).query2iRange("myIndex", 1L, 5000L)
Code: Key/Value Query
Queryby2iStringsval rdd =
sc.riakBucket[String](kv_bucket_name).query2iKeys("dailyDataIndx", ”Jan", ”Feb”)
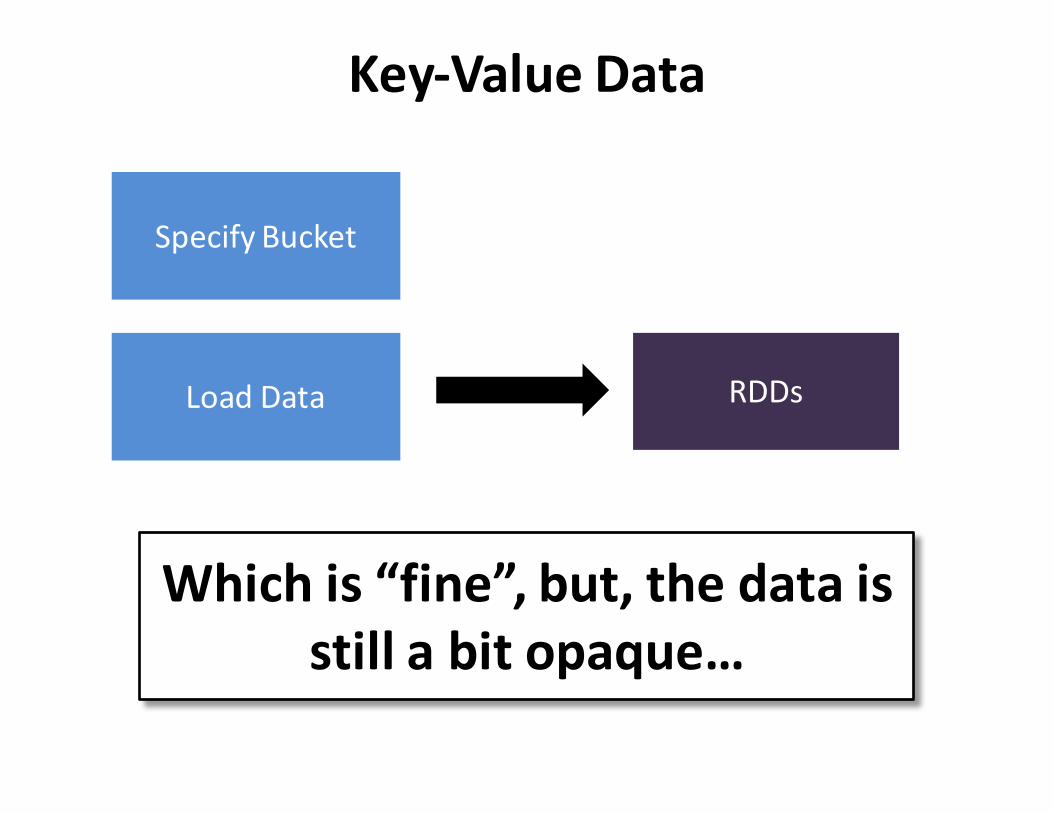
SpecifyBucket
RDDsLoadData
Key-ValueData
Whichis“fine”,but,thedataisstillabitopaque…
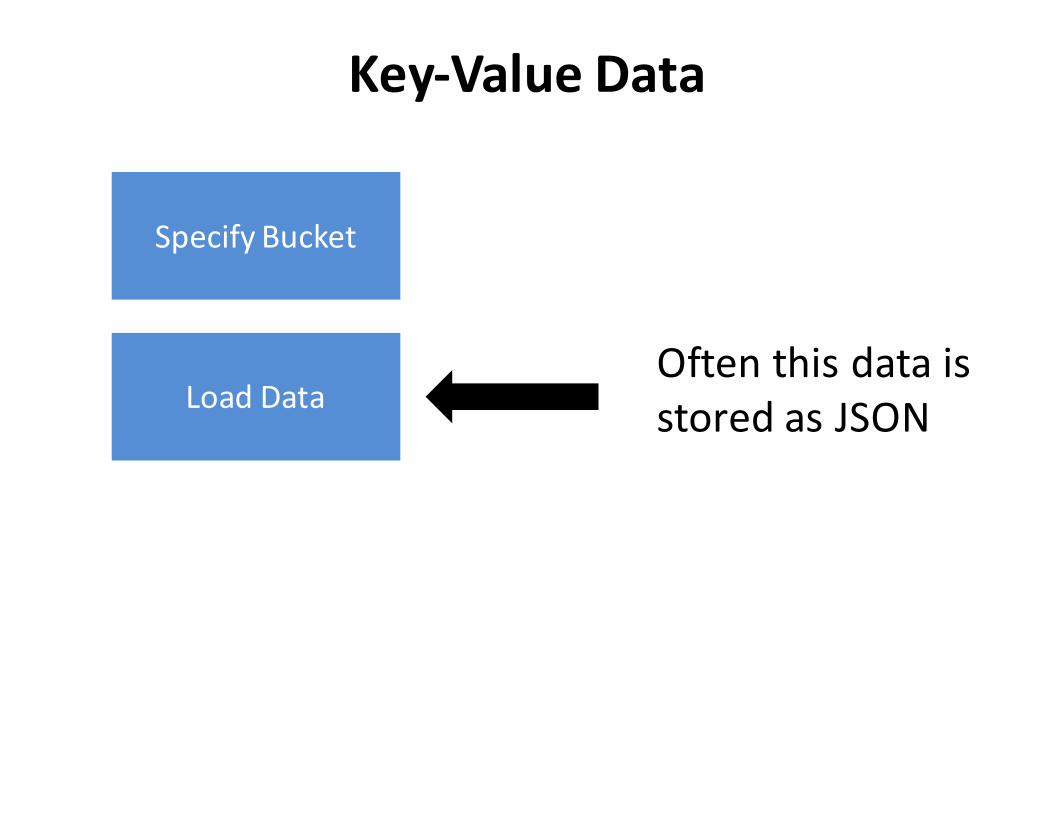
SpecifyBucket
LoadData
Key-ValueData
OftenthisdataisstoredasJSON
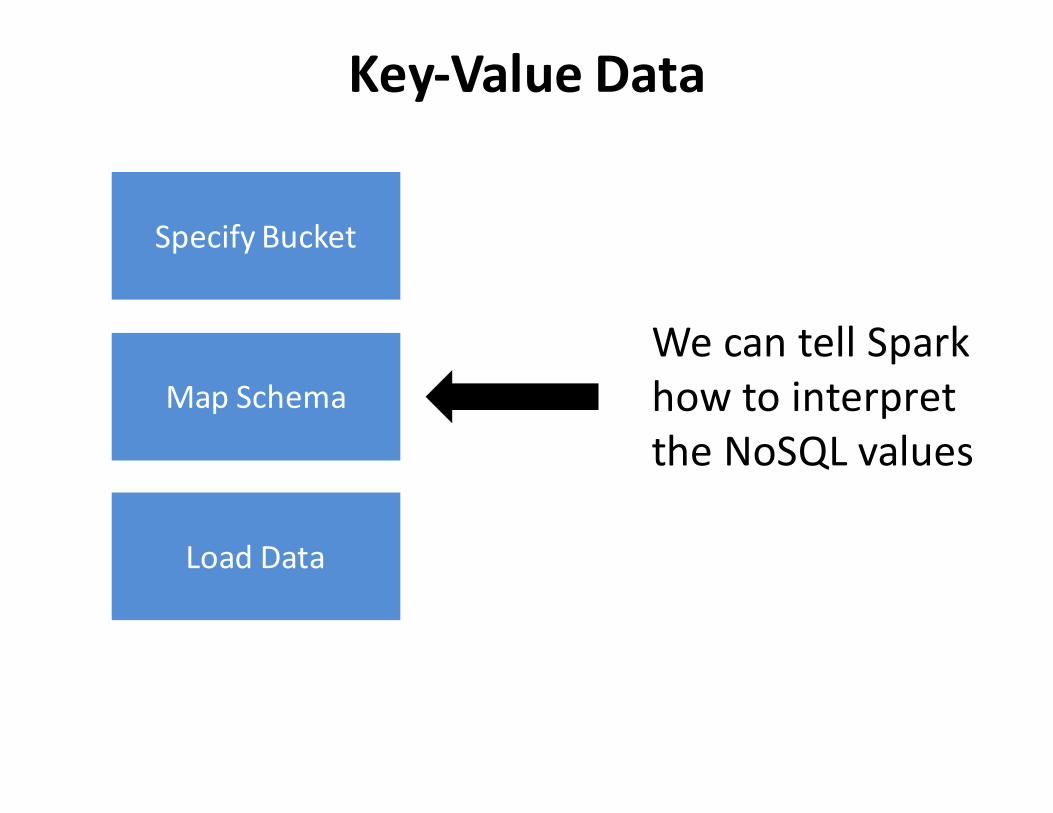
SpecifyBucket
MapSchema
Key-ValueData
LoadData
WecantellSparkhowtointerprettheNoSQLvalues
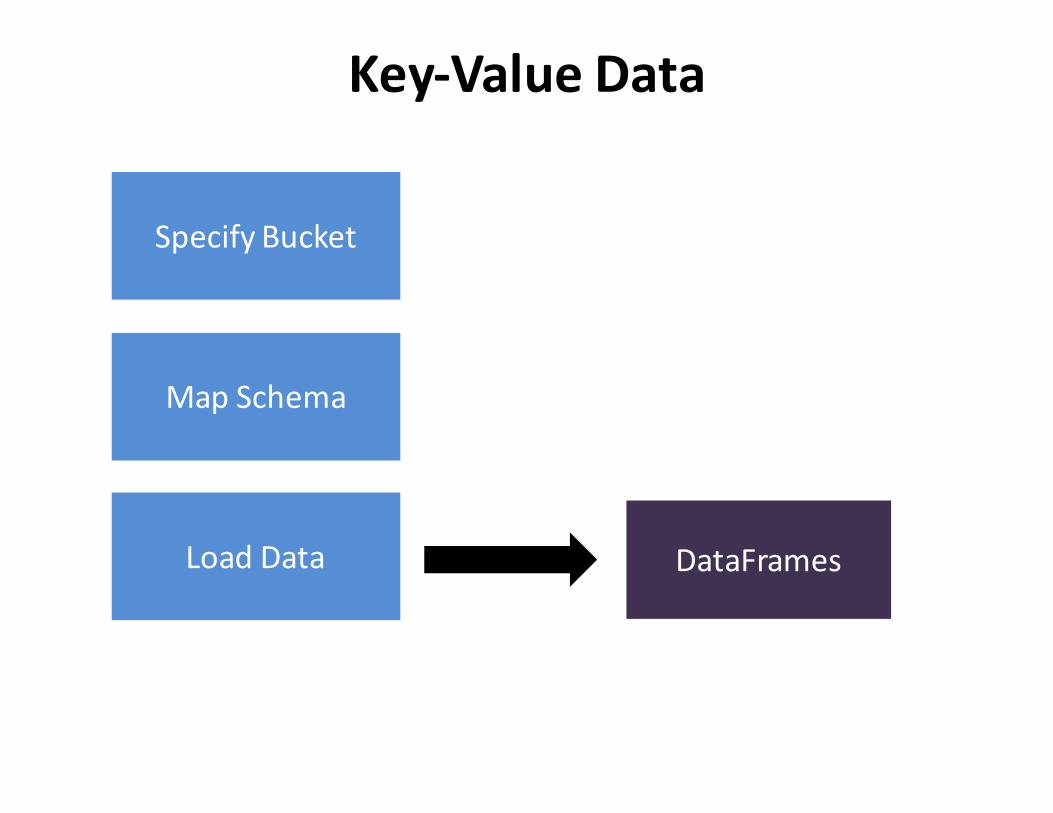
SpecifyBucket
MapSchema
Key-ValueData
LoadData DataFrames
SpecifyBucket
MapSchema
Key-ValueData
LoadData DataFramesNowwehavefull-fledgedDataFrames

SpecifyBucket
MapSchema
LoadData
val kv_bucket = new Namespace(”MiscBucket")
case class UserData(user_id: String, name: String, age: Int)
val riakRdd = sc.riakBucket[UserData](kv_bucket).queryAll()
val df = riakRdd.toDF()
Code
SpecifyBucket
MapSchema
Key-ValueData
LoadData
SpecifyBucket
MapSchema
TimeSeriesData
LoadData
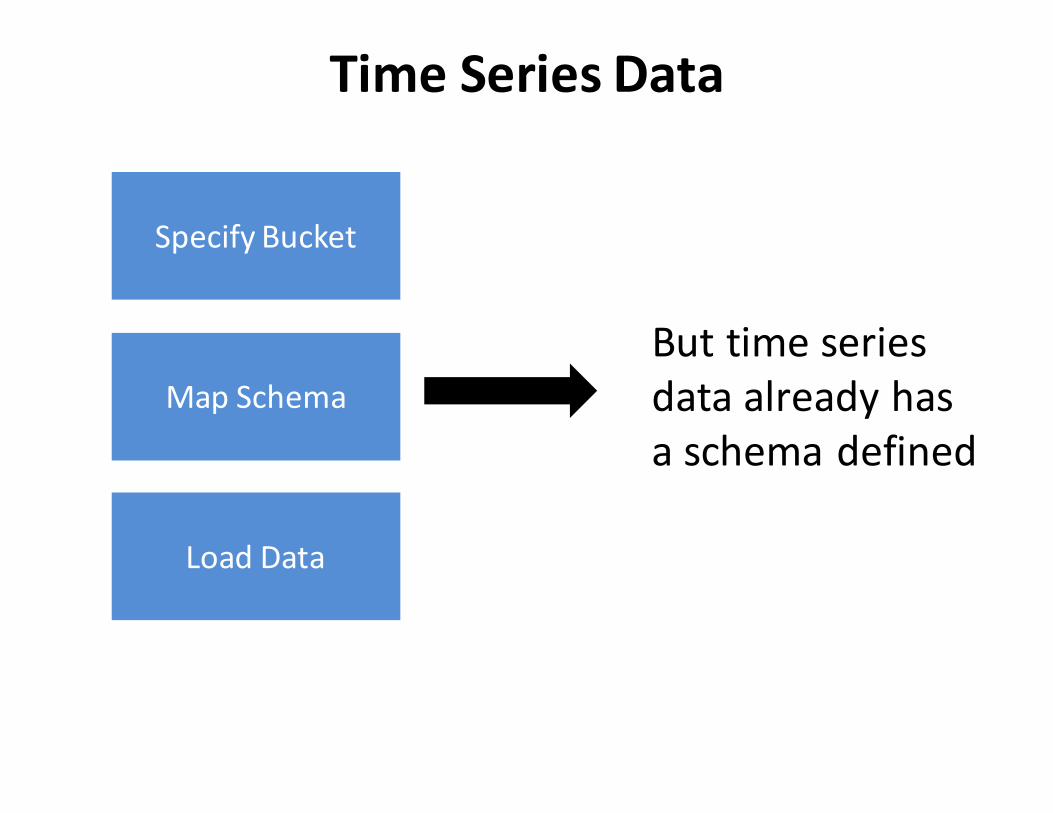
SpecifyBucket
MapSchema
TimeSeriesData
LoadData
Buttimeseriesdataalreadyhasaschemadefined
SpecifyBucket
MapSchema
TimeSeriesData
LoadData
Solet’suseautomaticschemadiscovery instead
SpecifyBucket
LoadData
TimeSeriesData
DataFrames

SpecifyTable
LoadData
val ts_table_name = "test-table"
df = sqlContext.re.option("spark.riak.connection.hosts","riak_host_ip:10017")
.format("org.apache.spark.sql.riak")
.load(ts_table_name)
.select(“time”, “col1”, “col2”)
.filter(s"time >= CAST($from AS TIMESTAMP)")
Time Series Code

SpecifyTable
LoadData
val ts_table_name = "test-table"
df = sqlContext.re.option("spark.riak.connection.hosts","riak_host_ip:10017")
.format("org.apache.spark.sql.riak")
.load(ts_table_name)
.select(“time”, “col1”, “col2”)
.filter(s"time >= CAST($from AS TIMESTAMP)")
Time Series Code
UseDatadf.where(df("age") >= 50).select("id", "name")
df.groupBy(”age").count

SpecifyTable
LoadData
val ts_table_name = "test-table"
df = sqlContext.re.option("spark.riak.connection.hosts","riak_host_ip:10017")
.format("org.apache.spark.sql.riak")
.load(ts_table_name)
.select(“time”, “col1”, “col2”)
.filter(s"time >= CAST($from AS TIMESTAMP)")
Time Series Code
UseDatadf.where(df("age") >= 50).select("id", "name")
df.groupBy(”age").count
UsestheSparkDataSourceAPI

Optimize all the levels

Optimize all the layers

HTTP ProtocolBuffers
2 primary interfaces to Riak
HTTP ProtocolBuffers
2 primary interfaces to Riak
Flexibility Performance

ProtocolBuffers
• Dataserializationandinterchange• DevelopedbyGoogle• IDL+RPC• Messagesserializedtobinarywireformat• Librarysupportfor20+languages

ProtocolBuffers
• Fordataserializationandinterchange• OriginallydevelopedbyGoogle• IDL+RPC• Messagesserializedtobinarywireformat• Librarysupportfor20+languages
Note:InRiak,youtypicallydon’thavetoknowthedetails,theclient
SDKstakecareofitforyou

HTTP ProtocolBuffers
How much faster?
150-300% faster
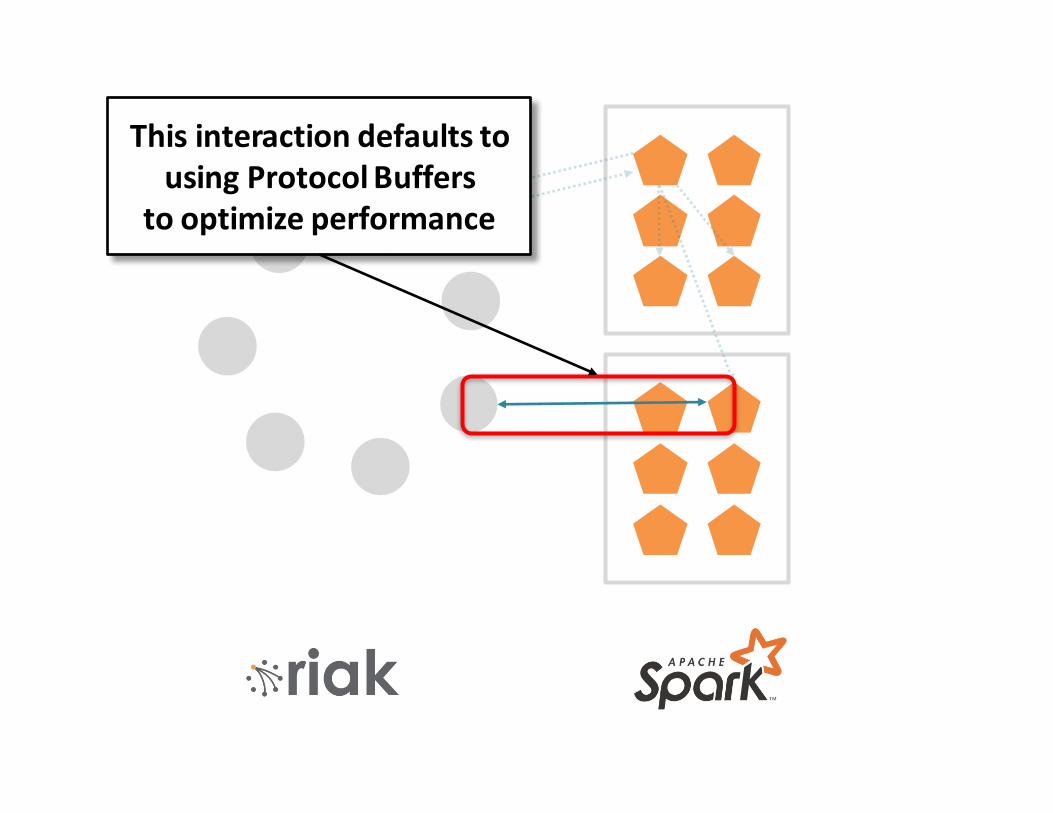
ThisinteractiondefaultstousingProtocolBuffers
tooptimizeperformance

HTTP ProtocolBuffers
What if we can make this faster?
?

HTTP ProtocolBuffers OptimizedBinary
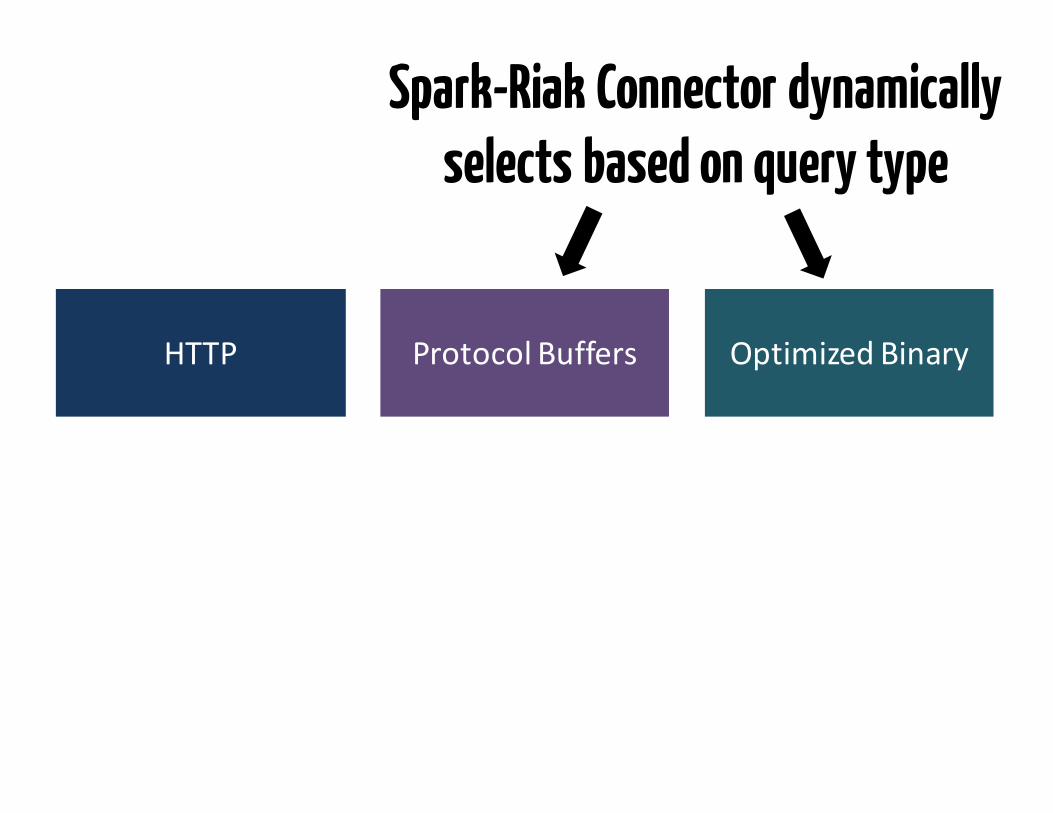
HTTP ProtocolBuffers
Spark-Riak Connector dynamically selects based on query type
OptimizedBinary
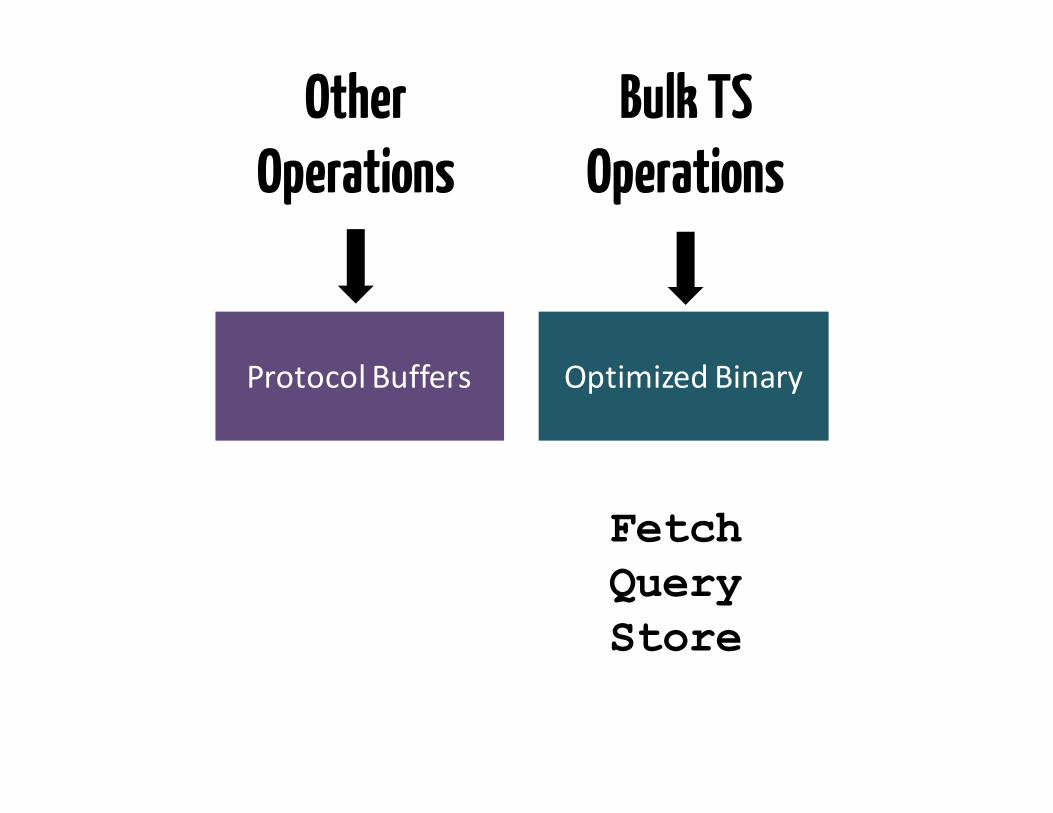
ProtocolBuffers
Bulk TS Operations
OptimizedBinary
Other Operations
FetchQueryStore
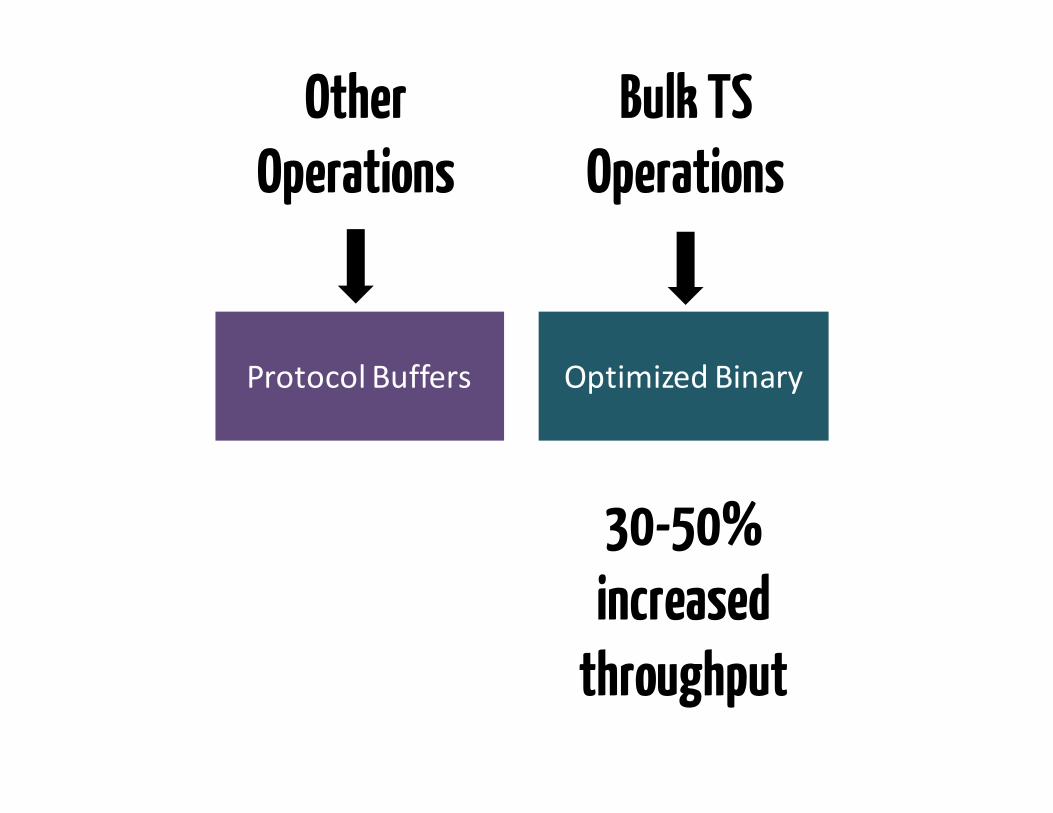
ProtocolBuffers
Bulk TS Operations
OptimizedBinary
Other Operations
30-50% increased
throughput

2 use case-specific optimizations
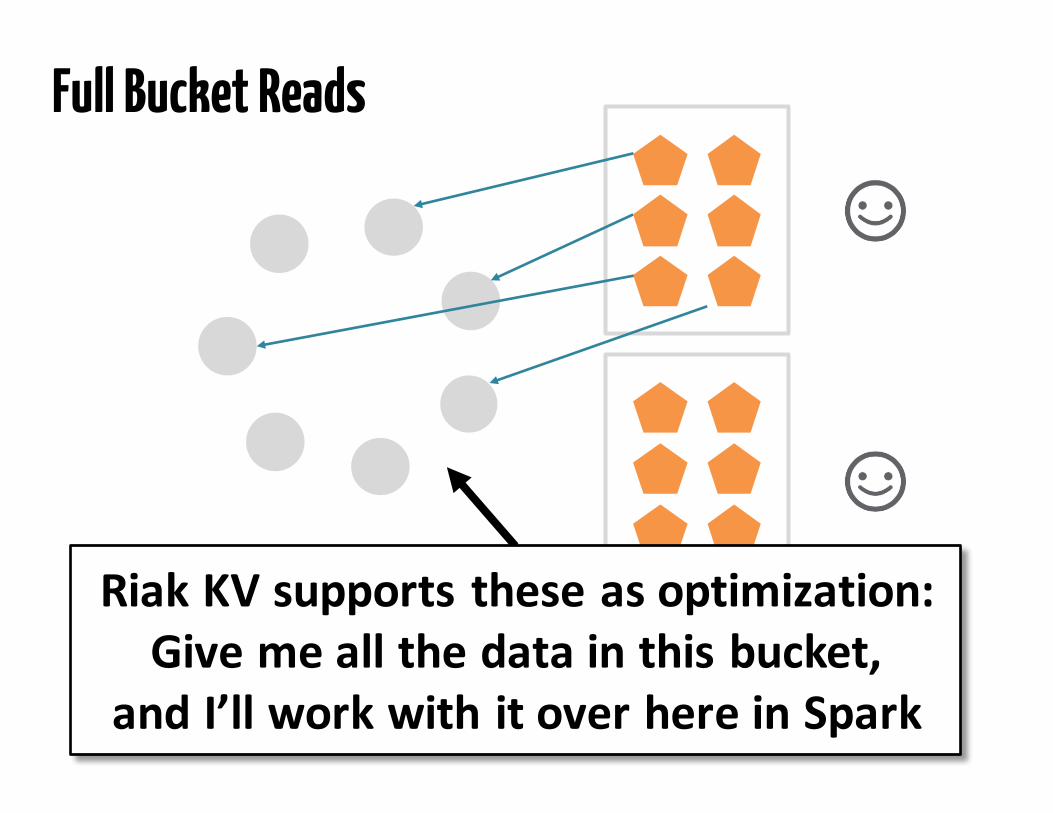
Full Bucket Reads
RiakKVsupportstheseasoptimization:Givemeallthedatainthisbucket,
andI’llworkwithitoverhereinSpark
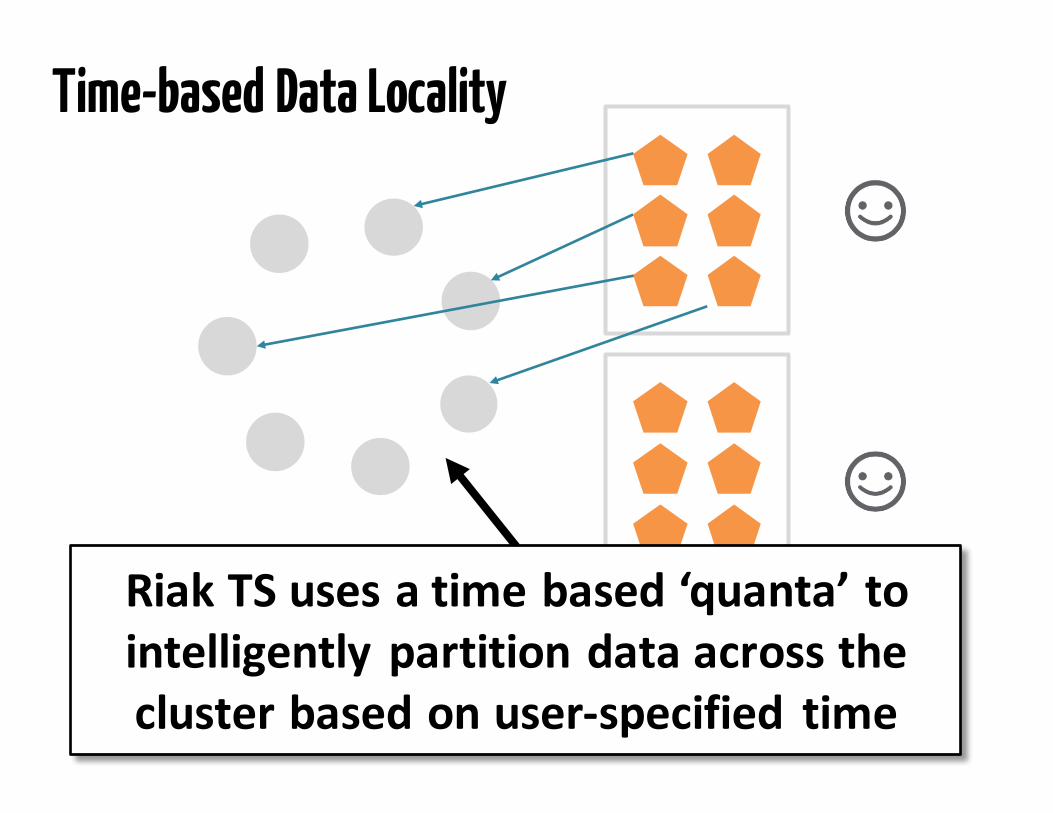
Time-based Data Locality
RiakTSusesatimebased‘quanta’tointelligentlypartitiondataacrosstheclusterbasedonuser-specified time
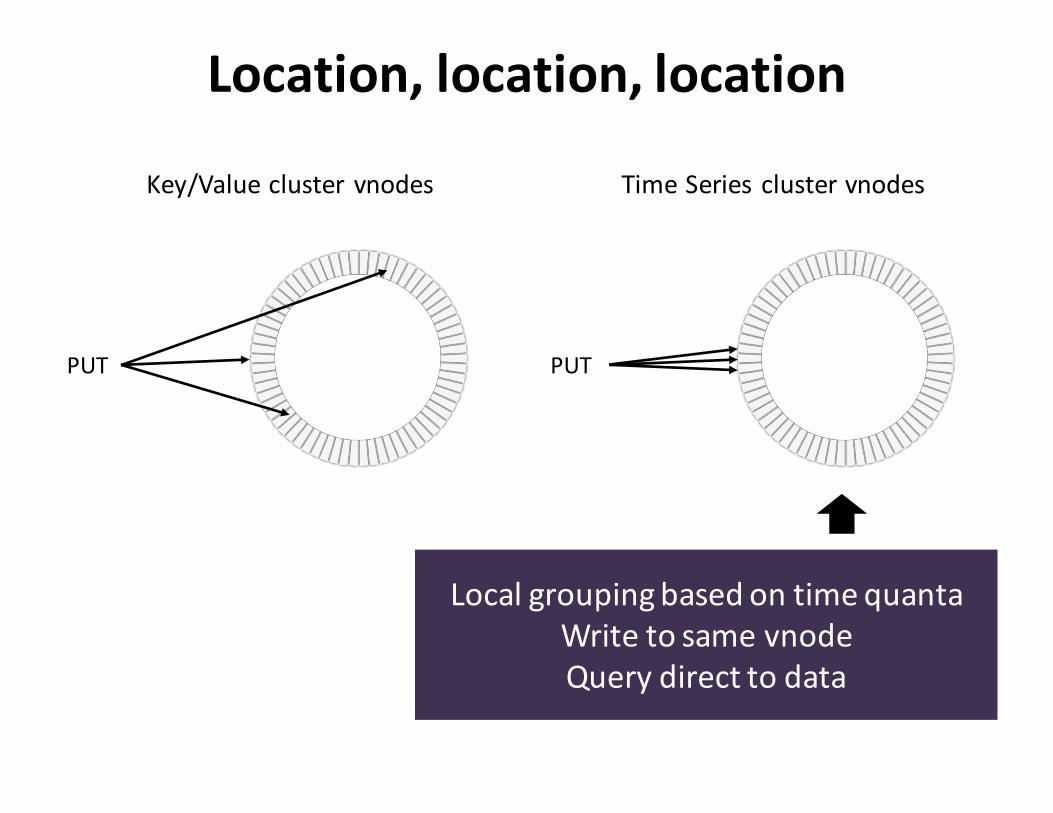
Location,location,location
Key/Valueclustervnodes
PUT PUT
TimeSeriesclustervnodes
LocalgroupingbasedontimequantaWritetosamevnodeQuerydirecttodata
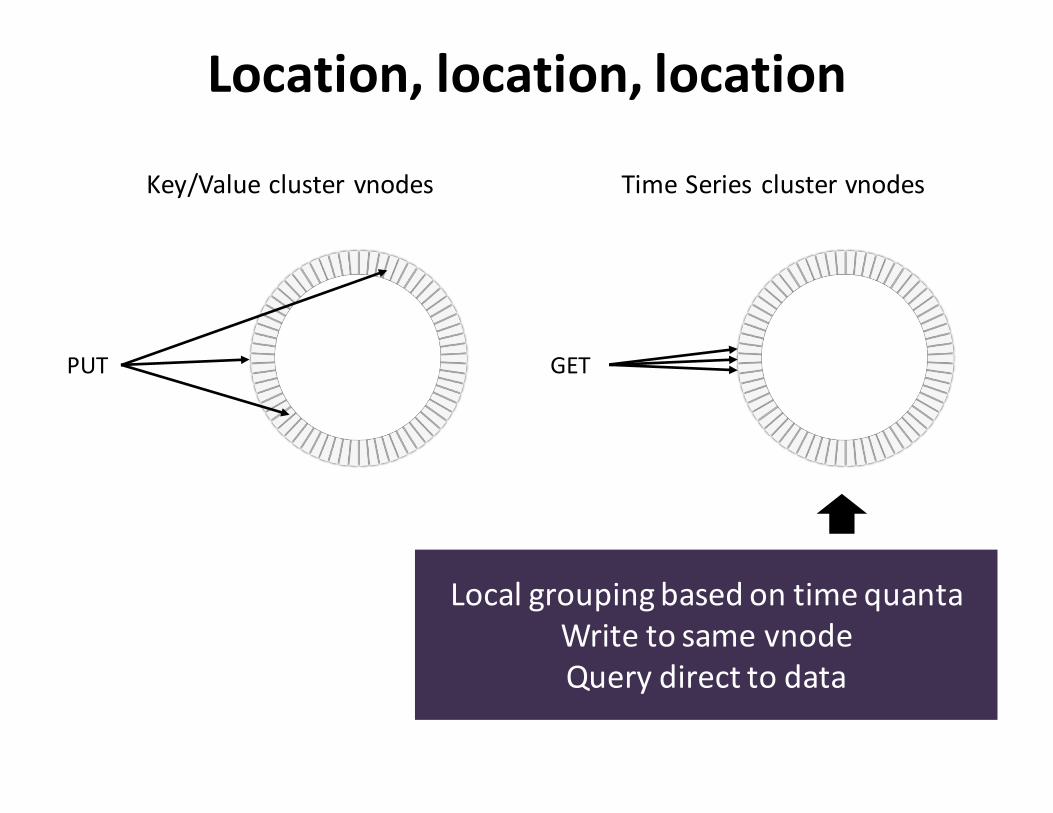
Location,location,location
Key/Valueclustervnodes
PUT GET
TimeSeriesclustervnodes
LocalgroupingbasedontimequantaWritetosamevnodeQuerydirecttodata

RiakTimeSeriesSQL
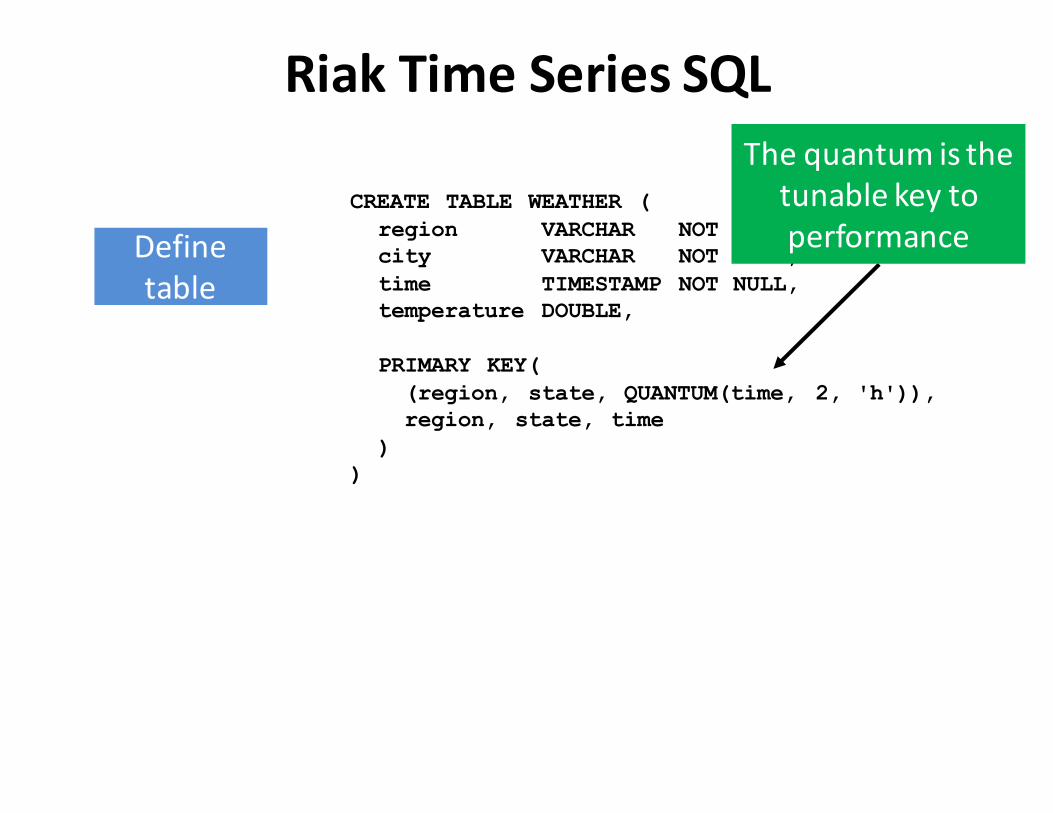
Definetable
CREATE TABLE WEATHER (region VARCHAR NOT NULL,city VARCHAR NOT NULL,time TIMESTAMP NOT NULL,temperature DOUBLE,
PRIMARY KEY((region, state, QUANTUM(time, 2, 'h')), region, state, time
))
RiakTimeSeriesSQL
Definetable
CREATE TABLE WEATHER (region VARCHAR NOT NULL,city VARCHAR NOT NULL,time TIMESTAMP NOT NULL,temperature DOUBLE,
PRIMARY KEY((region, state, QUANTUM(time, 2, 'h')), region, state, time
))
Thequantumisthetunablekeytoperformance

RiakTimeSeriesSQL
SELECT * FROM WEATHERWHERE city = ’Brussels'
time >= ‘2016-01-01’ ANDtime <= ‘2016-02-01 00:00:00’
Definetable
Query
CREATE TABLE WEATHER (region VARCHAR NOT NULL,city VARCHAR NOT NULL,time TIMESTAMP NOT NULL,temperature DOUBLE,
PRIMARY KEY((region, state, QUANTUM(time, 2, 'h')), region, state, time
))

Beflexible

Bepolyglot

Support multiple languages

Pythonimport pyspark_riak
conf = pyspark.SparkConf().setAppName("My Spark Riak App") conf.set("spark.riak.connection.host", "127.0.0.1:8087")
sc = pyspark.SparkContext(conf) pyspark_riak.riak_context(sc)
Setup

Pythonimport pyspark_riak
conf = pyspark.SparkConf().setAppName("My Spark Riak App") conf.set("spark.riak.connection.host", "127.0.0.1:8087")
sc = pyspark.SparkContext(conf) pyspark_riak.riak_context(sc)
my_data = [{'key0':{'data': 0}}, {'key1':{'data': 1}}] kv_write_rdd = sc.parallelize(my_data)kv_write_rdd.saveToRiak(‘kv_sample_bucket’)
Setup
Write

Pythonimport pyspark_riak
conf = pyspark.SparkConf().setAppName("My Spark Riak App") conf.set("spark.riak.connection.host", "127.0.0.1:8087")
sc = pyspark.SparkContext(conf) pyspark_riak.riak_context(sc)
my_data = [{'key0':{'data': 0}}, {'key1':{'data': 1}}] kv_write_rdd = sc.parallelize(my_data)kv_write_rdd.saveToRiak(‘kv_sample_bucket’)
Setup
Write
Read kv_read_rdd = sc.riakBucket(‘kv_sample_bucket’).queryAll()print(kv_read_rdd.collect())
SparkStreaming
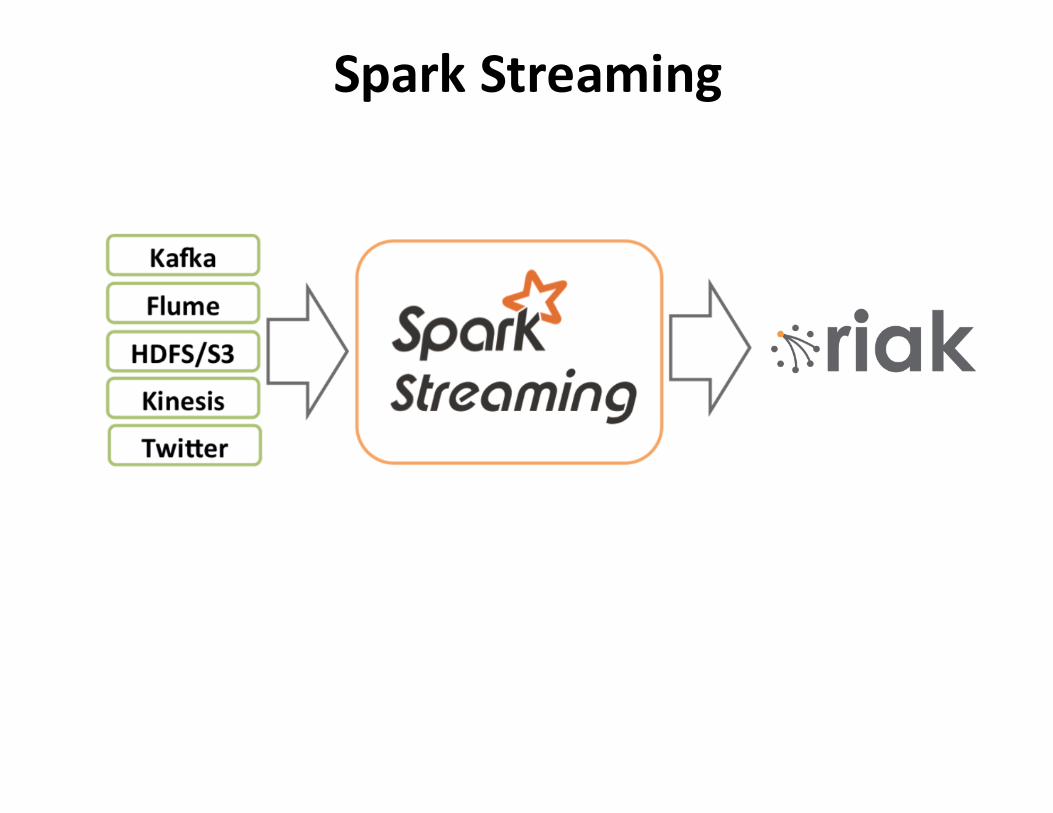
SparkStreaming

Setup
Stream
import com.basho.riak.spark.streaming._
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(serverIP, serverPort)
val errs = lines.filter(lines => lines contains "ERROR")
Spark-Riak Streaming
Save errs.saveToRiak("test-bucket-4store")

Deployment
On premiseCloud
HybridGeo-distributed
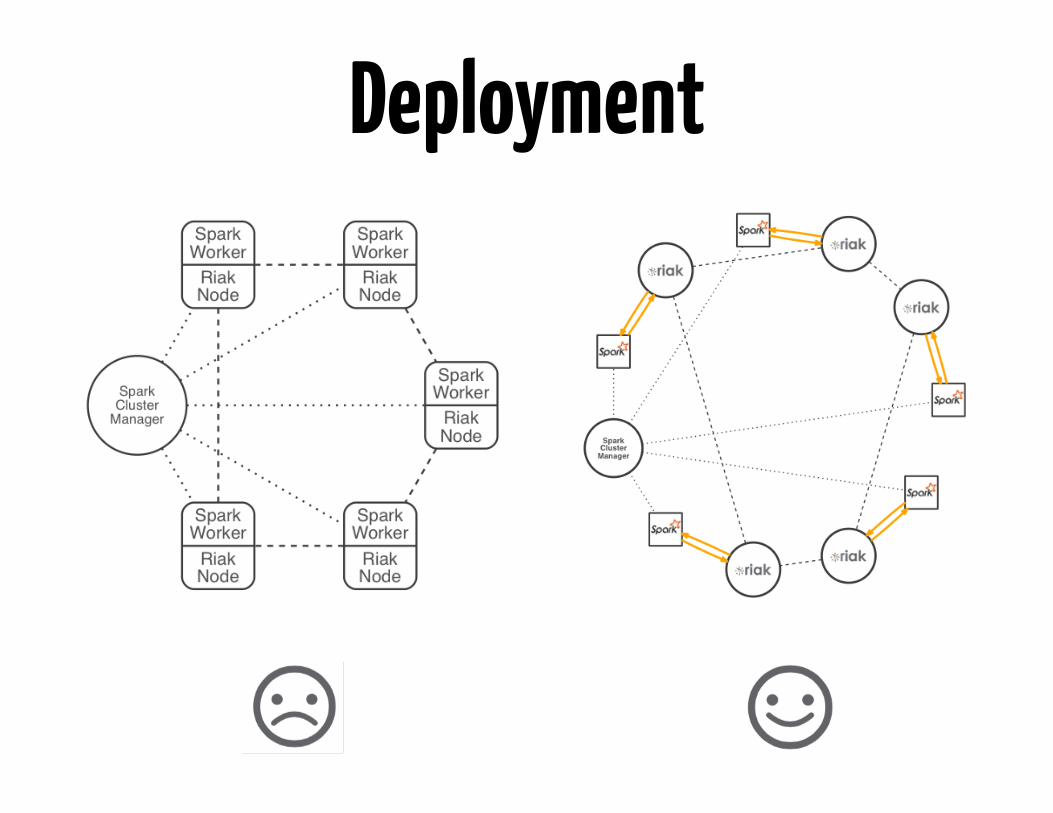
Deployment
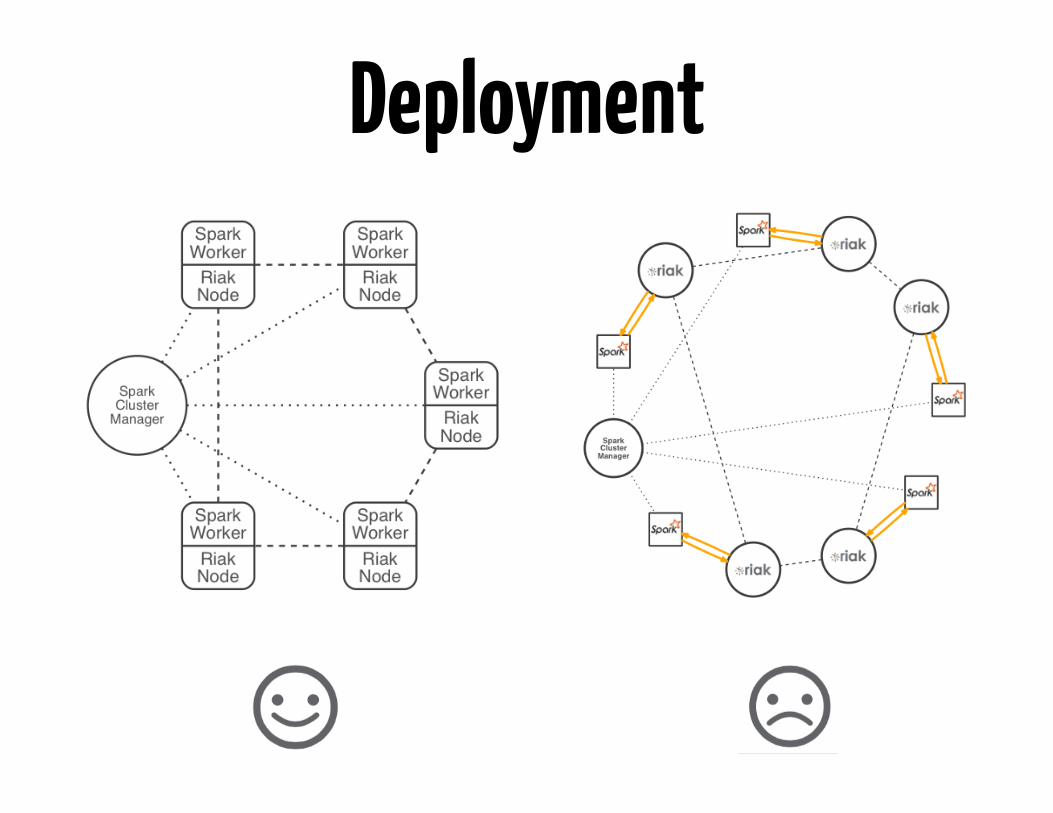
Deployment

Deployment
https://github.com/basho-labs/riak-mesos
+

Simplify

How to reducefriction?
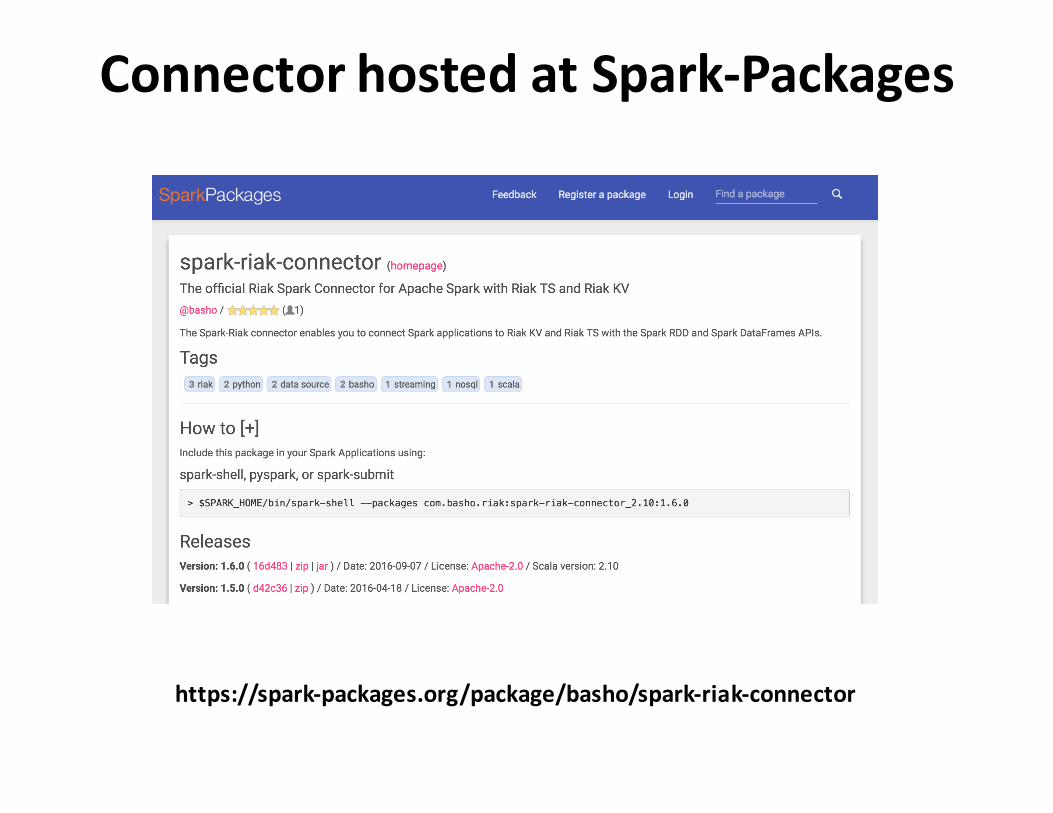
ConnectorhostedatSpark-Packages
https://spark-packages.org/package/basho/spark-riak-connector
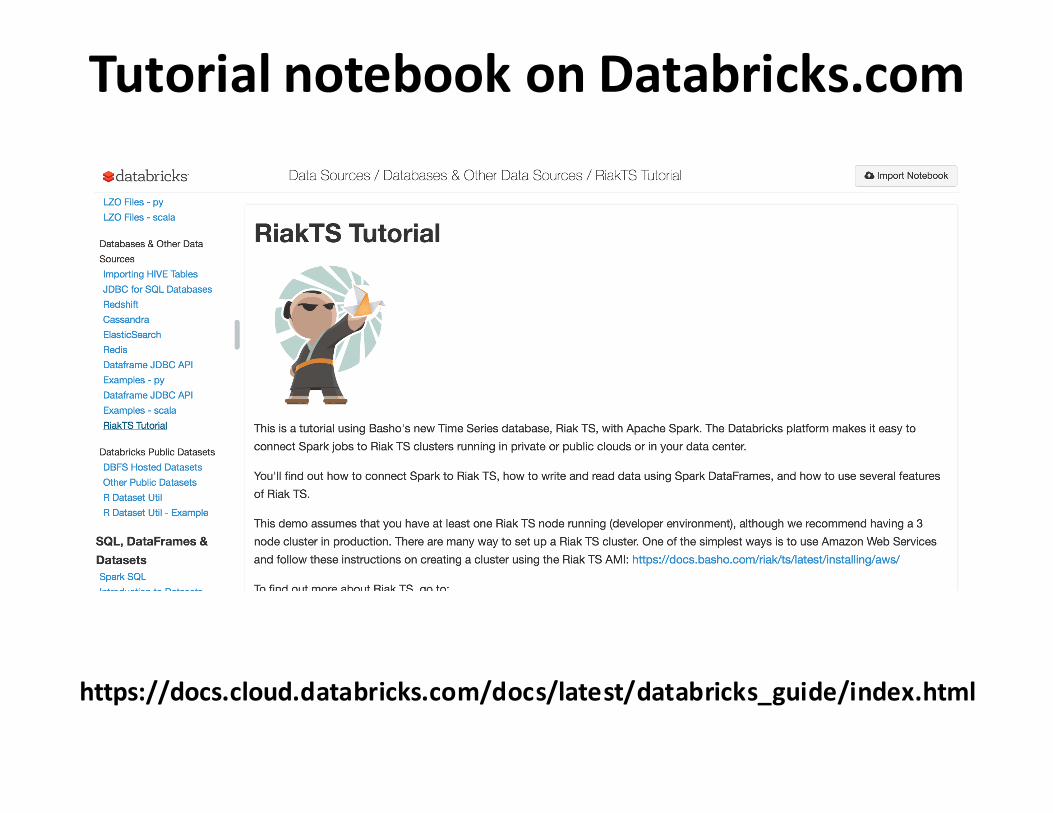
https://docs.cloud.databricks.com/docs/latest/databricks_guide/index.html
TutorialnotebookonDatabricks.com

Don’t die
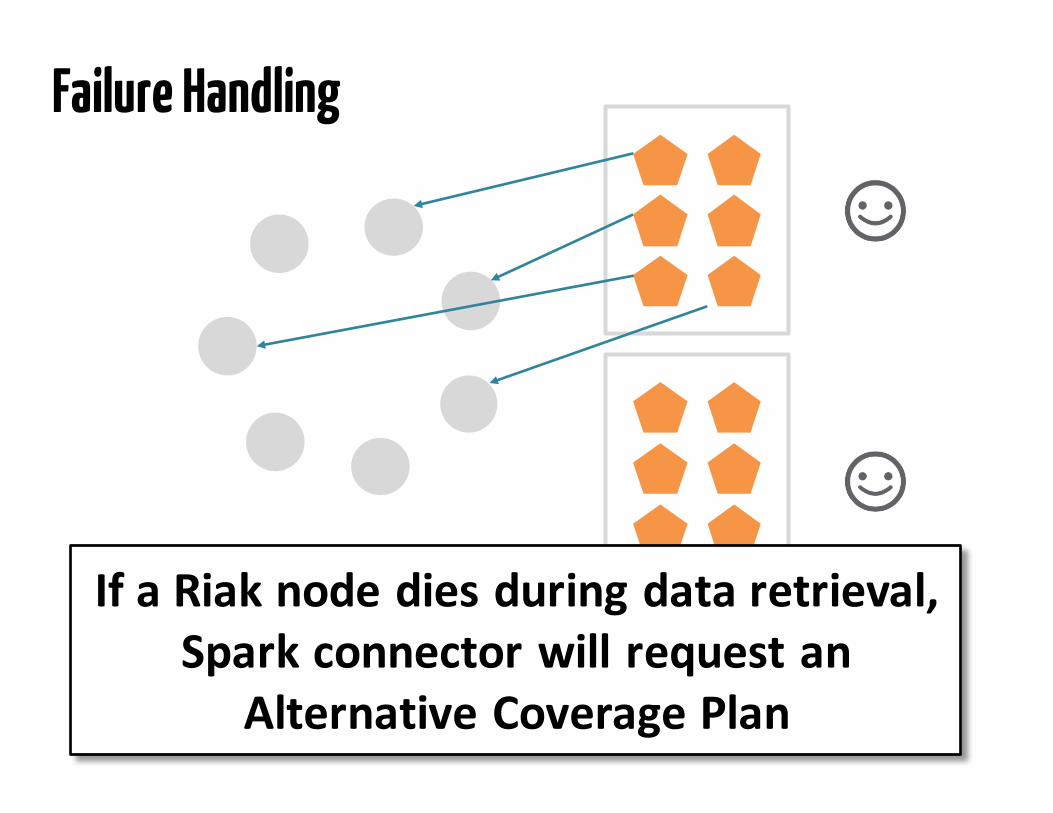
Failure Handling
IfaRiaknodediesduringdataretrieval,Sparkconnectorwillrequestan
AlternativeCoveragePlan

Next steps for Riak-Spark?
Spark 2.0DataSets
Structured Streaming

So, back to the question…
+NoSQL = ?
+ =NoSQL
+ =NoSQL

ParallelizeMap smart
Optimize all the levelsBe flexible
Simplify

Thank You
@johnmusser@basho

PhotoCredits
Racecar:SpacesuitMediaIntellicore applicationscreenshots: Intellicore, http://www.intellicore.tv/





























