Embed Size (px)
Citation preview

Scalable Streaming Data Pipelines with
RedisAvram Lyon
@ajlyon / github.com/avramredisconf / May 10, 2016

MOBILE GAMES - PUBLISHER AND DEVELOPER

What kind of data?• App opened• Killed a walker• Bought something• Heartbeat• Memory usage
report• App error
• Declined a review prompt
• Finished the tutorial• Clicked on that button• Lost a battle• Found a treasure chest• Received a push
message
• Finished a turn• Sent an invite• Scored a Yahtzee• Spent 100 silver coins• Anything else any
game designer or developer wants to learn about
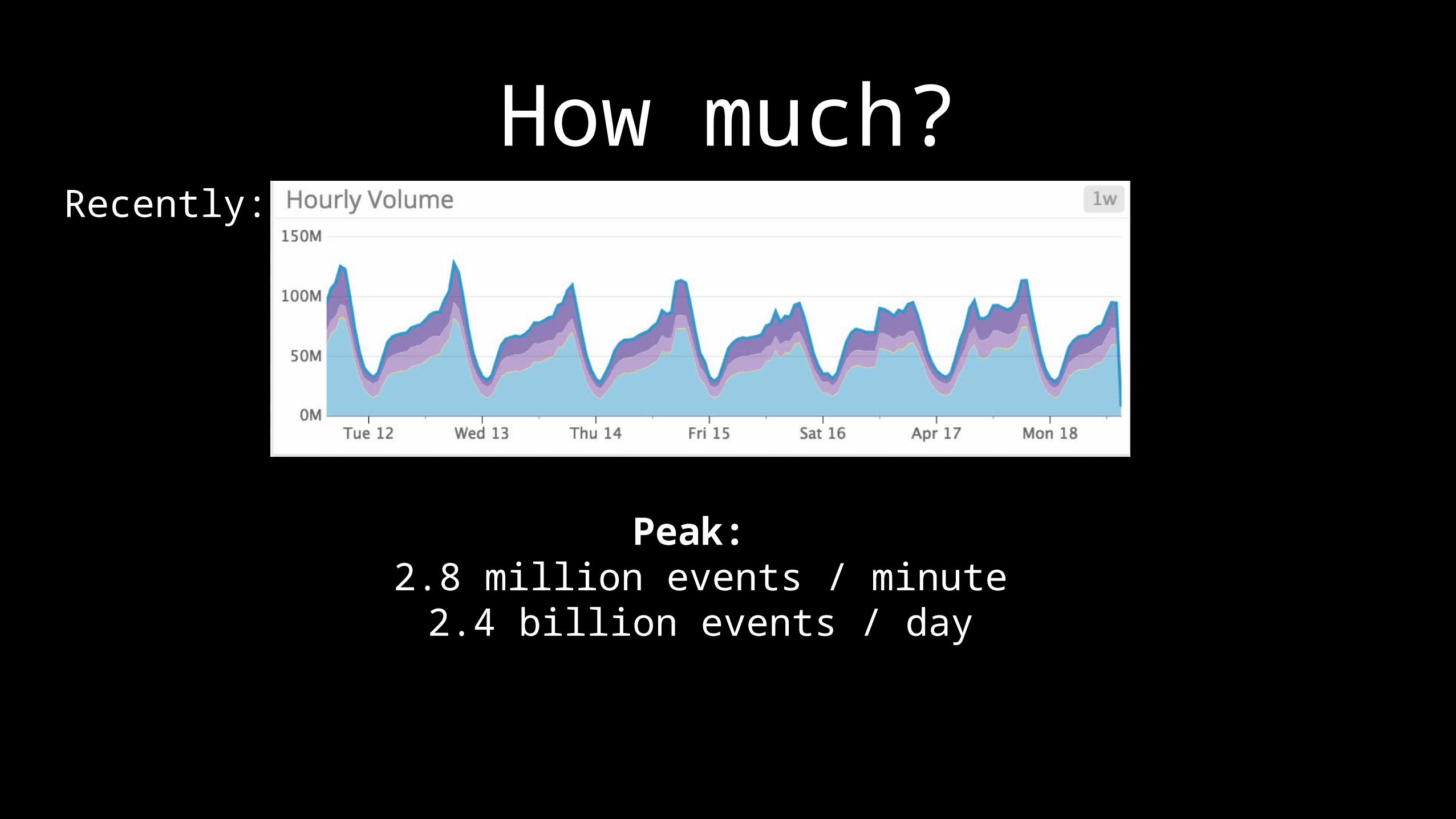
How much?Recently:
Peak: 2.8 million events / minute
2.4 billion events / day

Primary Data Stream
Collection Kinesis
WarehousingEnrichment Realtime MonitoringKinesisPublic API
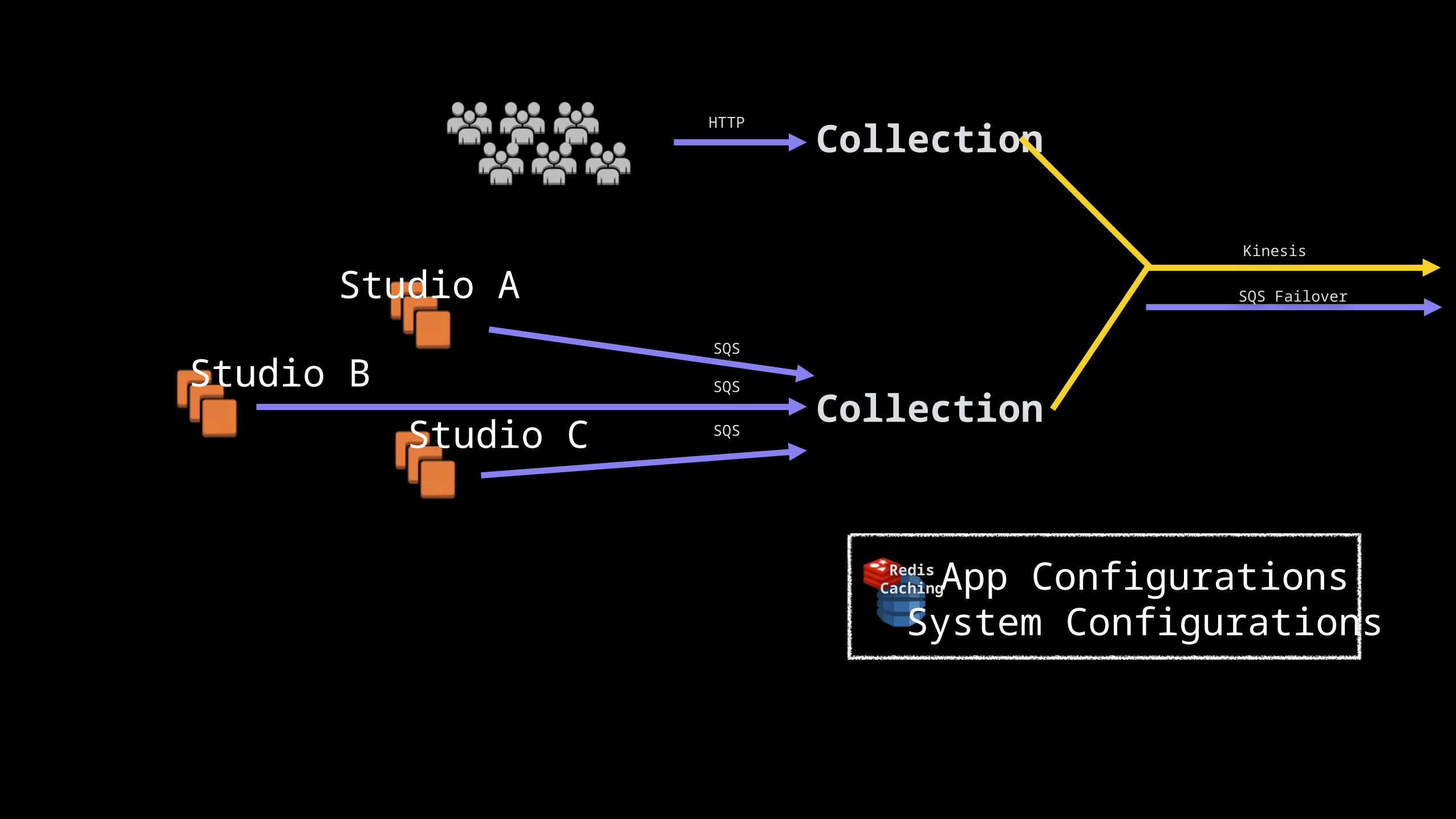
CollectionHTTP
Collection
SQS
SQS
SQS
Studio A
Studio BStudio C
Kinesis
SQS Failover
Redis Caching App Configurations
System Configurations
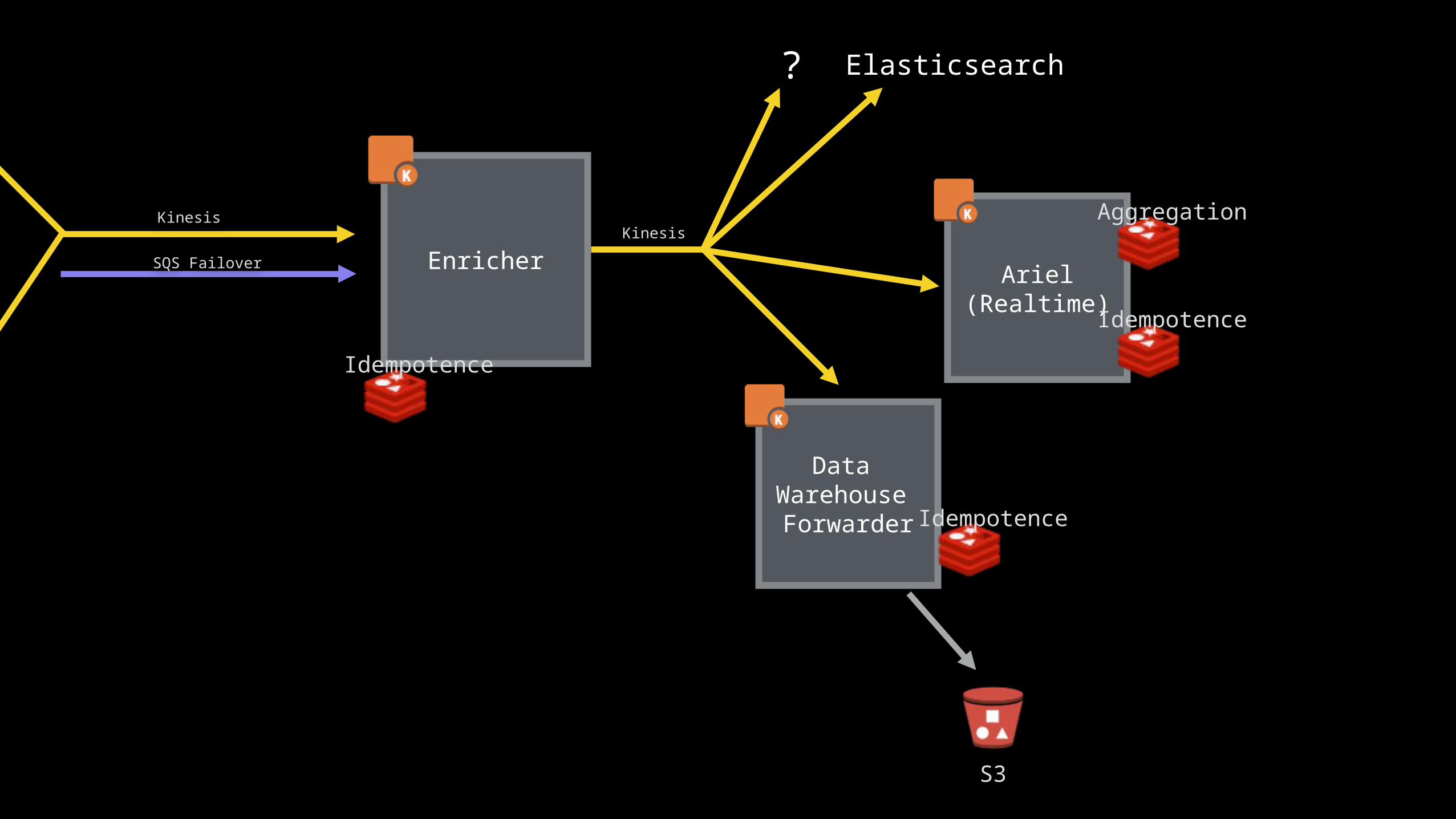
Kinesis
SQS Failover
S3
Kinesis
Elasticsearch?
Enricher
Data Warehouse Forwarder
Ariel(Realtime)
Idempotence
Aggregation
Idempotence
Idempotence

What’s in the box?
=
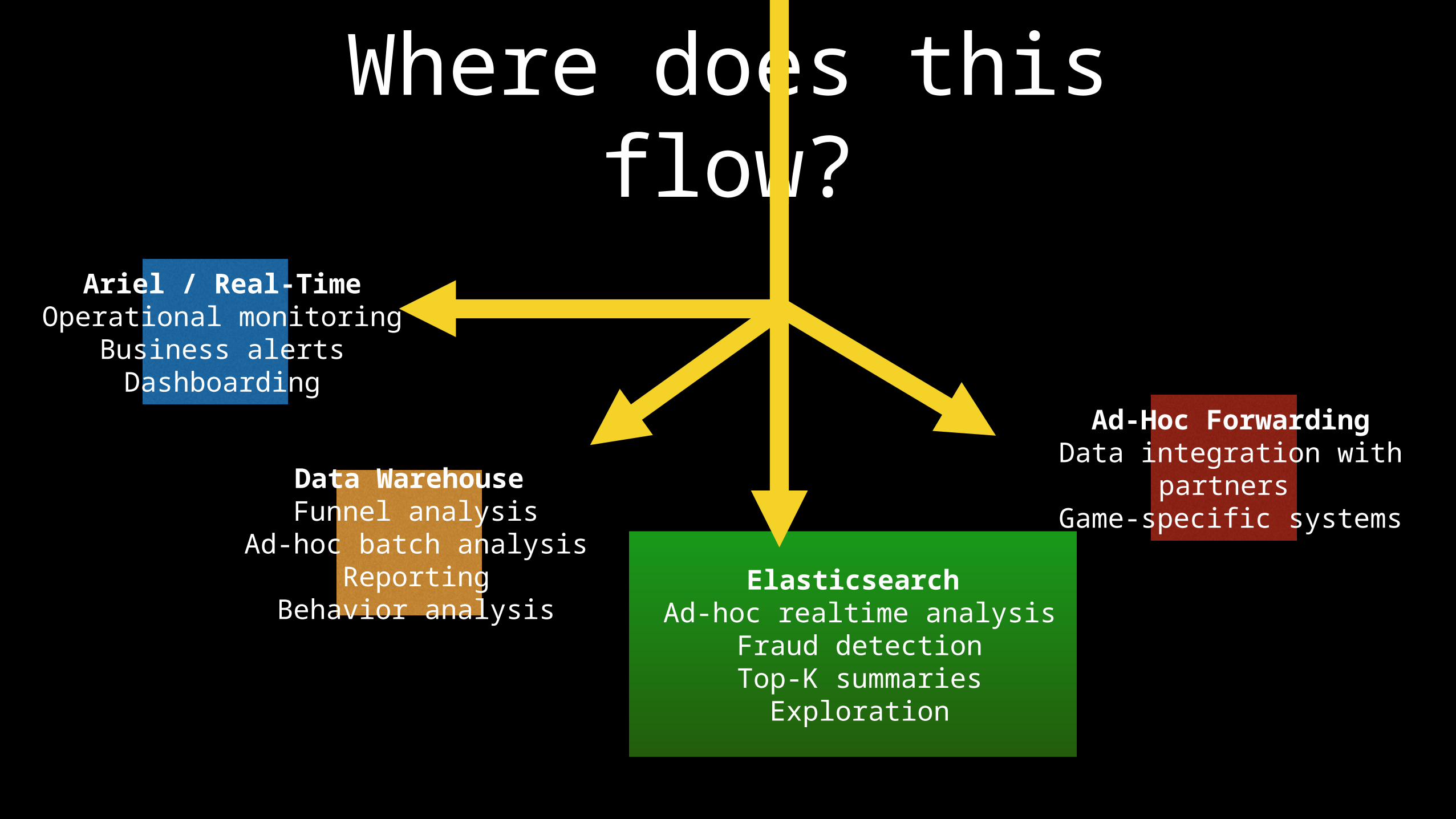
Where does this flow?
Ariel / Real-TimeOperational monitoring
Business alertsDashboarding
Data WarehouseFunnel analysis
Ad-hoc batch analysisReporting
Behavior analysisElasticsearch
Ad-hoc realtime analysisFraud detection
Top-K summariesExploration
Ad-Hoc ForwardingData integration with partners
Game-specific systems
Kinesis
a short aside

Kinesis
• Distributed, sharded streams. Akin to Kafka.• Get an iterator over the stream— and checkpoint with
current stream pointer occasionally.• Workers coordinate shard leases and checkpoints in
DynamoDB (via KCL)
Shard 0Shard 1Shard 2
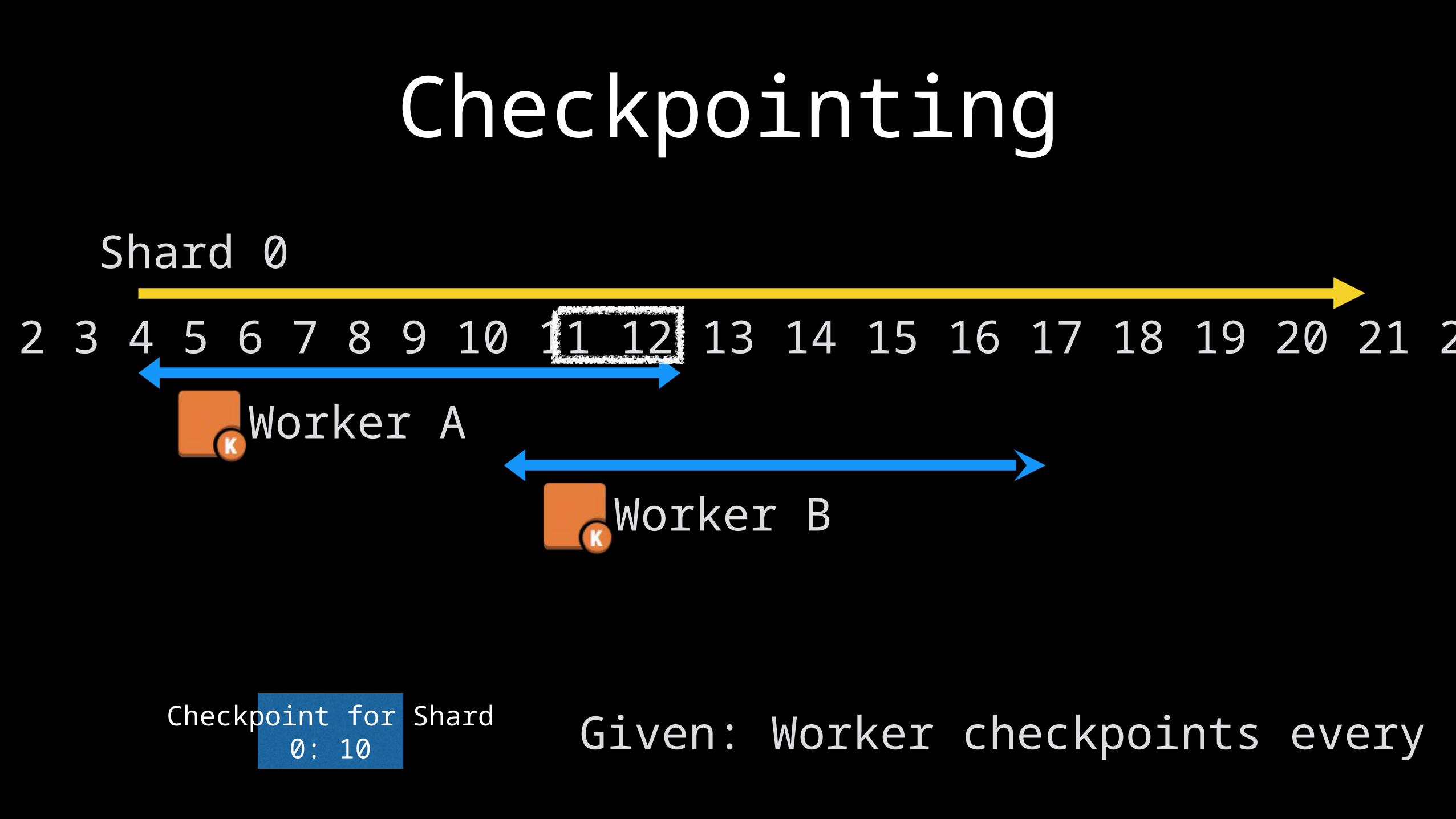
Shard 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
Checkpointing
Checkpoint for Shard 0: 10 Given: Worker checkpoints every 5
Worker A 🔥
Worker B

Auxiliary Idempotence
• Idempotence keys at each stage• Redis sets of idempotence keys by time window• Gives resilience against various types of failures

Auxiliary Idempotence
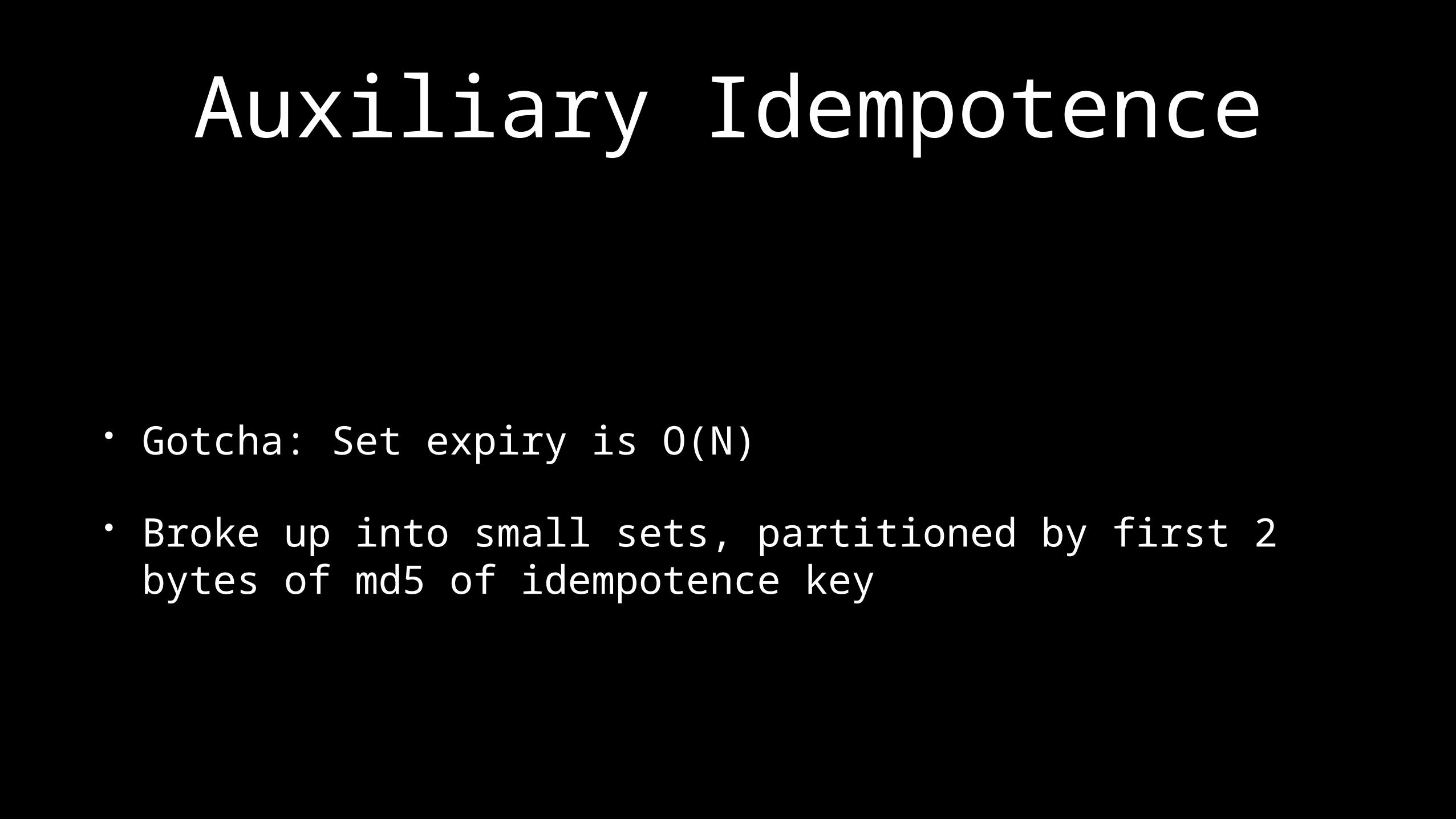
Auxiliary Idempotence
• Gotcha: Set expiry is O(N)• Broke up into small sets, partitioned by first 2 bytes of md5
of idempotence key
Collection Kinesis
WarehousingEnrichment Realtime MonitoringKinesisPublic API

1. Deserialize event batch
2. Apply changes to application properties
3. Get current device and application properties
4. Get known facts about sending device
5. Emit to each enriched event to Kinesis
Collection Kinesis
Enrichment
Kinesis
SQS Failover
Kinesis
S3
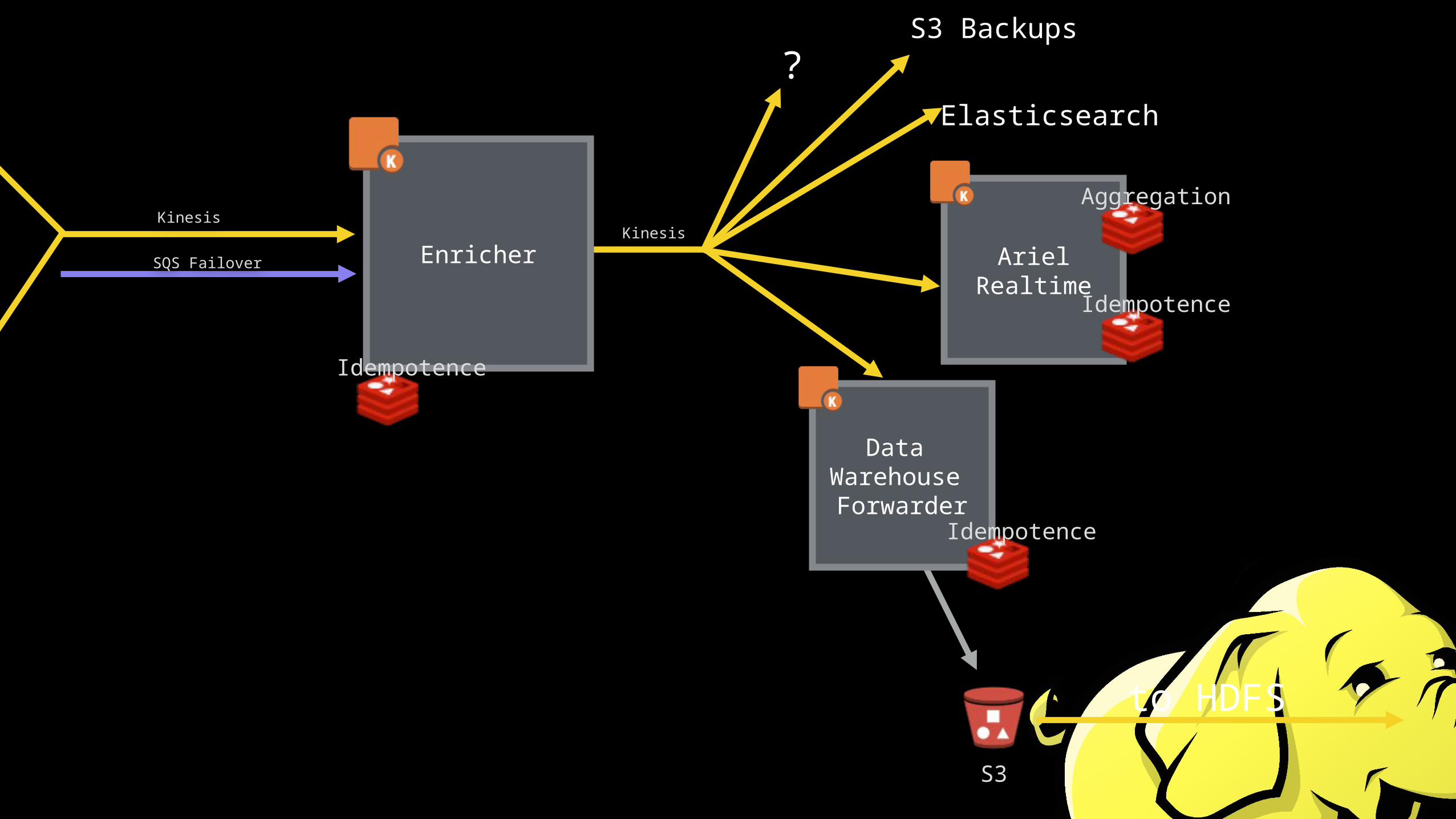
Elasticsearch?
S3 Backups
to HDFS
Enricher
Data Warehouse Forwarder
Idempotence
ArielRealtime
Idempotence
Aggregation
Idempotence

Now we have a stream of well-described, denormalized event
facts.

Pipeline to HDFS
• Partitioned by event name and game, buffered in-memory and written to S3
• Picked up every hour by Spark job• Converts to Parquet, loaded to HDFS

A closer look at Ariel
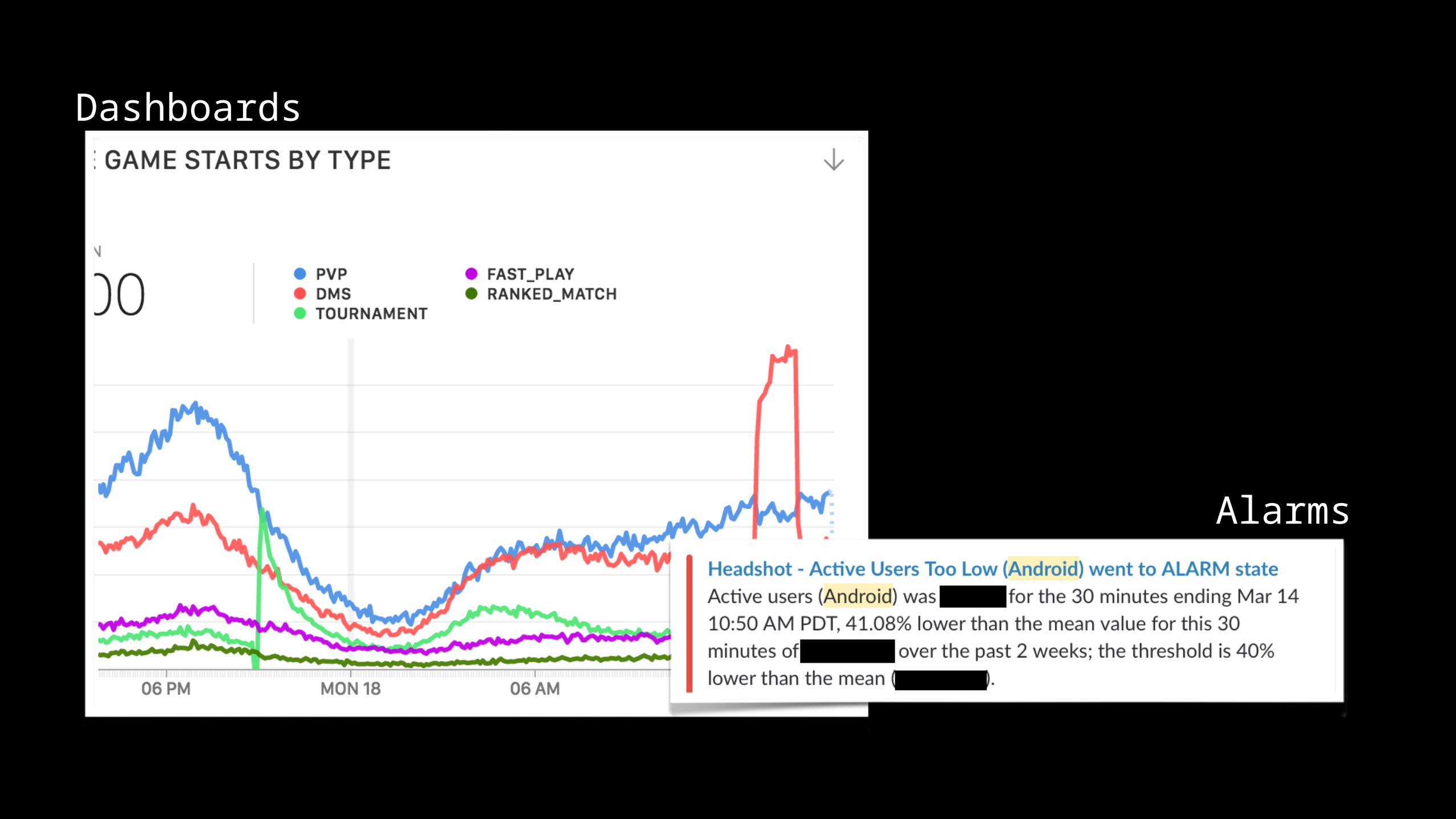
Dashboards
Alarms

Ariel Goals
• Low time-to-visibility• Easy configuration• Low cost per configured metric
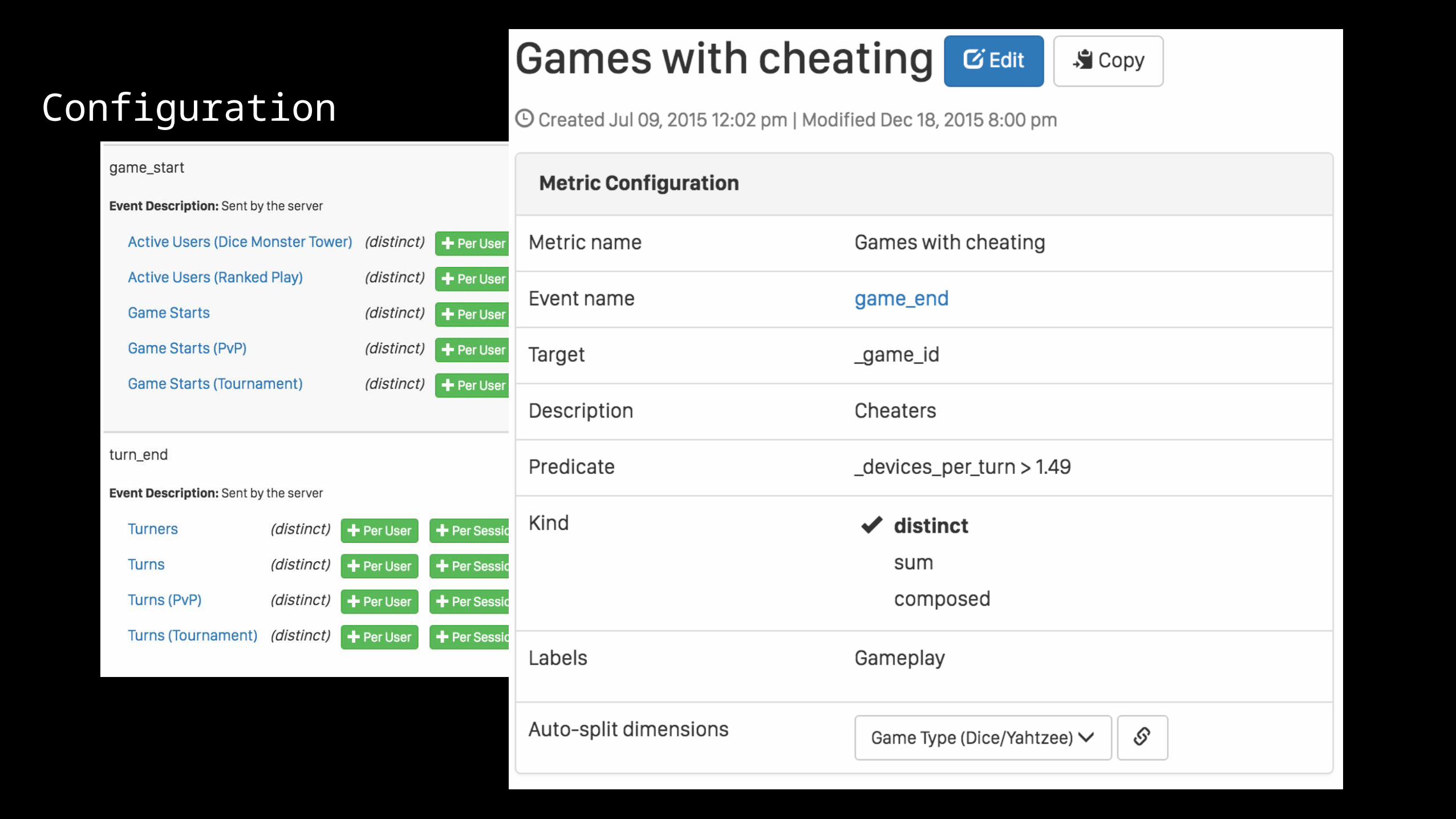
Configuration
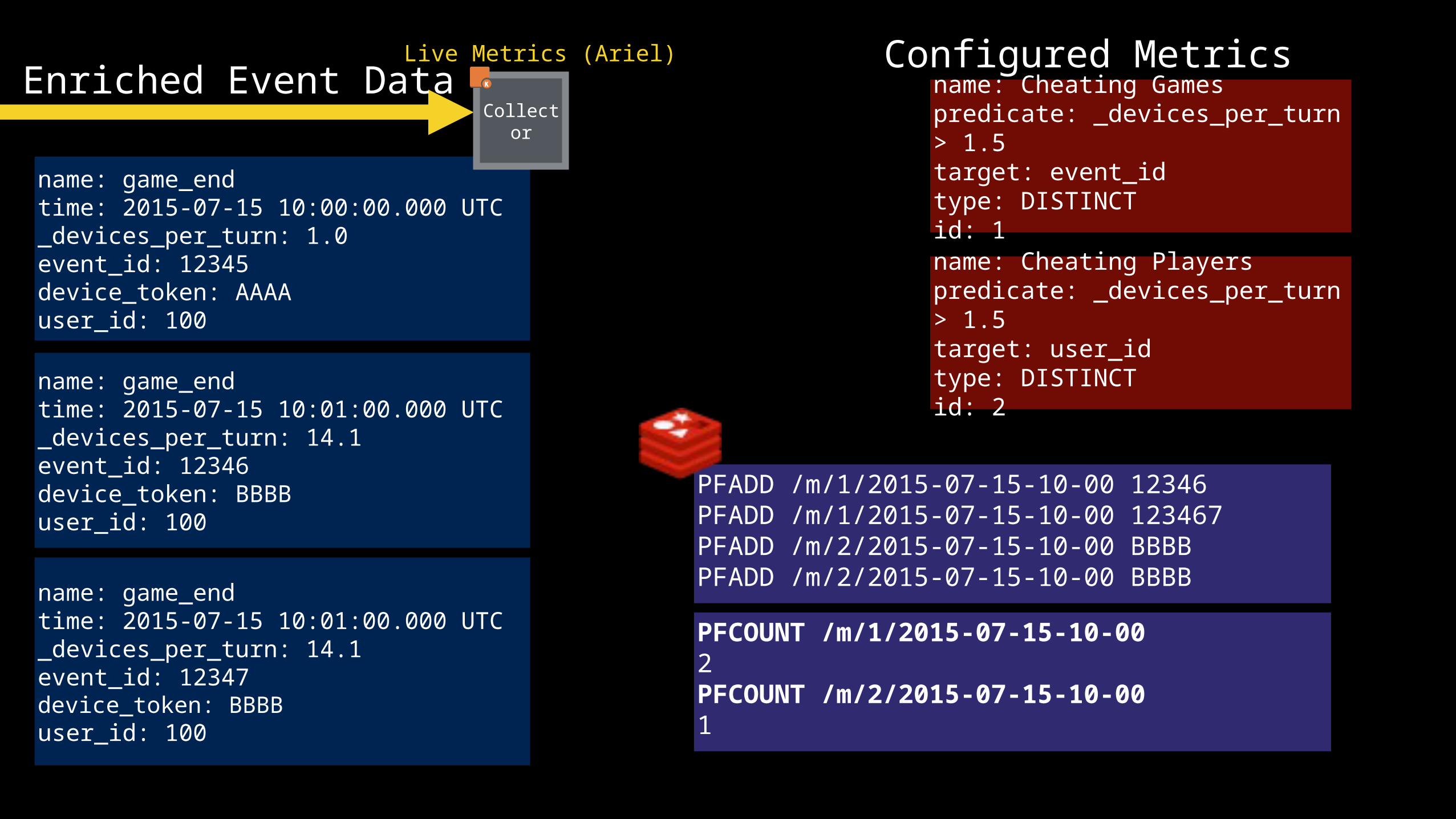
Live Metrics (Ariel)Enriched Event Data
name: game_endtime: 2015-07-15 10:00:00.000 UTC_devices_per_turn: 1.0event_id: 12345device_token: AAAAuser_id: 100
name: game_endtime: 2015-07-15 10:01:00.000 UTC_devices_per_turn: 14.1event_id: 12346device_token: BBBBuser_id: 100
name: Cheating Gamespredicate: _devices_per_turn > 1.5target: event_idtype: DISTINCTid: 1name: Cheating Playerspredicate: _devices_per_turn > 1.5target: user_idtype: DISTINCTid: 2
name: game_endtime: 2015-07-15 10:01:00.000 UTC_devices_per_turn: 14.1event_id: 12347device_token: BBBBuser_id: 100
PFADD /m/1/2015-07-15-10-00 12346 PFADD /m/1/2015-07-15-10-00 123467PFADD /m/2/2015-07-15-10-00 BBBBPFADD /m/2/2015-07-15-10-00 BBBB
PFCOUNT /m/1/2015-07-15-10-002PFCOUNT /m/2/2015-07-15-10-001
Configured MetricsCollector

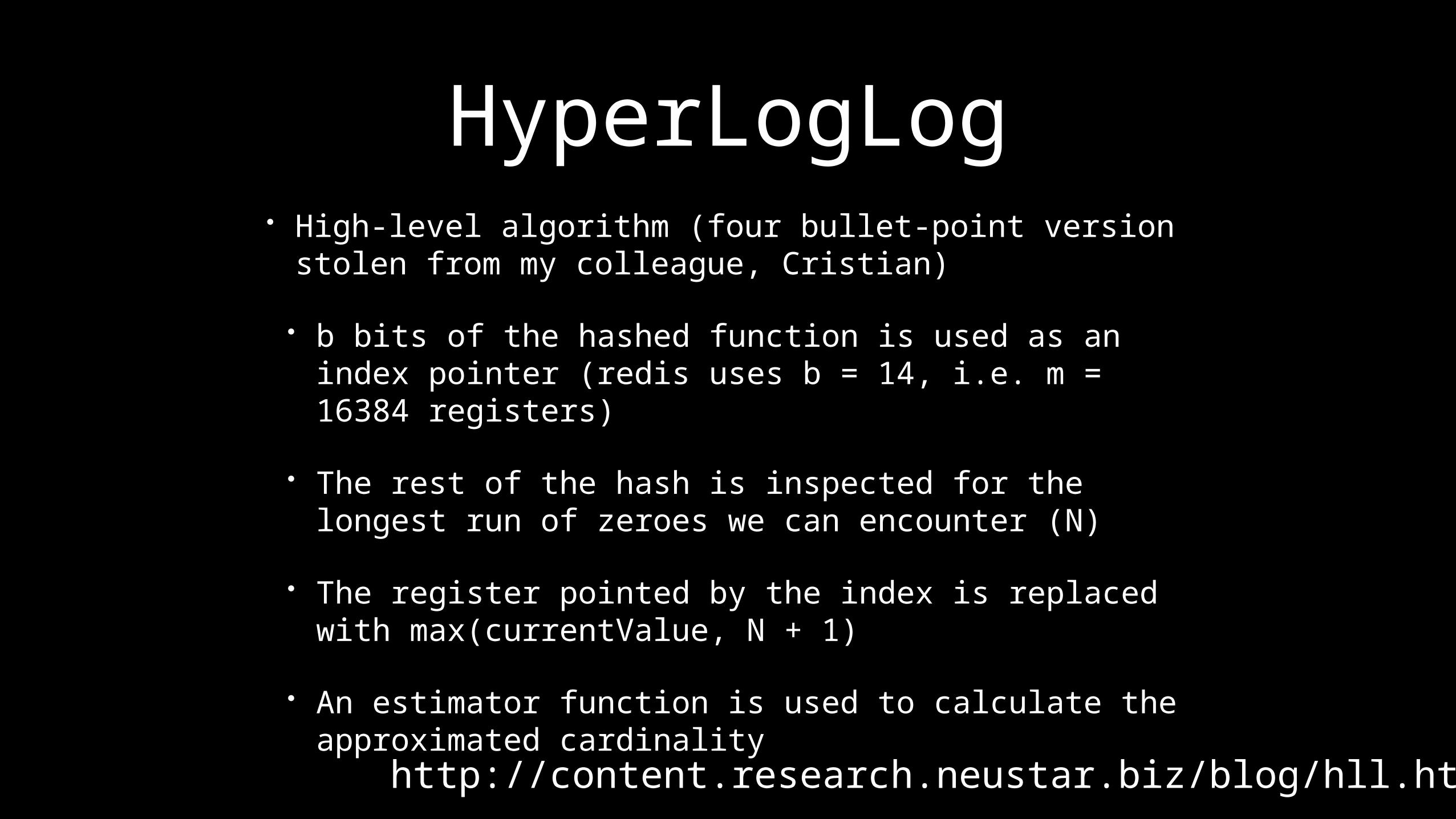
HyperLogLog• High-level algorithm (four bullet-point version stolen
from my colleague, Cristian)• b bits of the hashed function is used as an index
pointer (redis uses b = 14, i.e. m = 16384 registers)• The rest of the hash is inspected for the longest run of
zeroes we can encounter (N)• The register pointed by the index is replaced with
max(currentValue, N + 1)• An estimator function is used to calculate the
approximated cardinalityhttp://content.research.neustar.biz/blog/hll.html
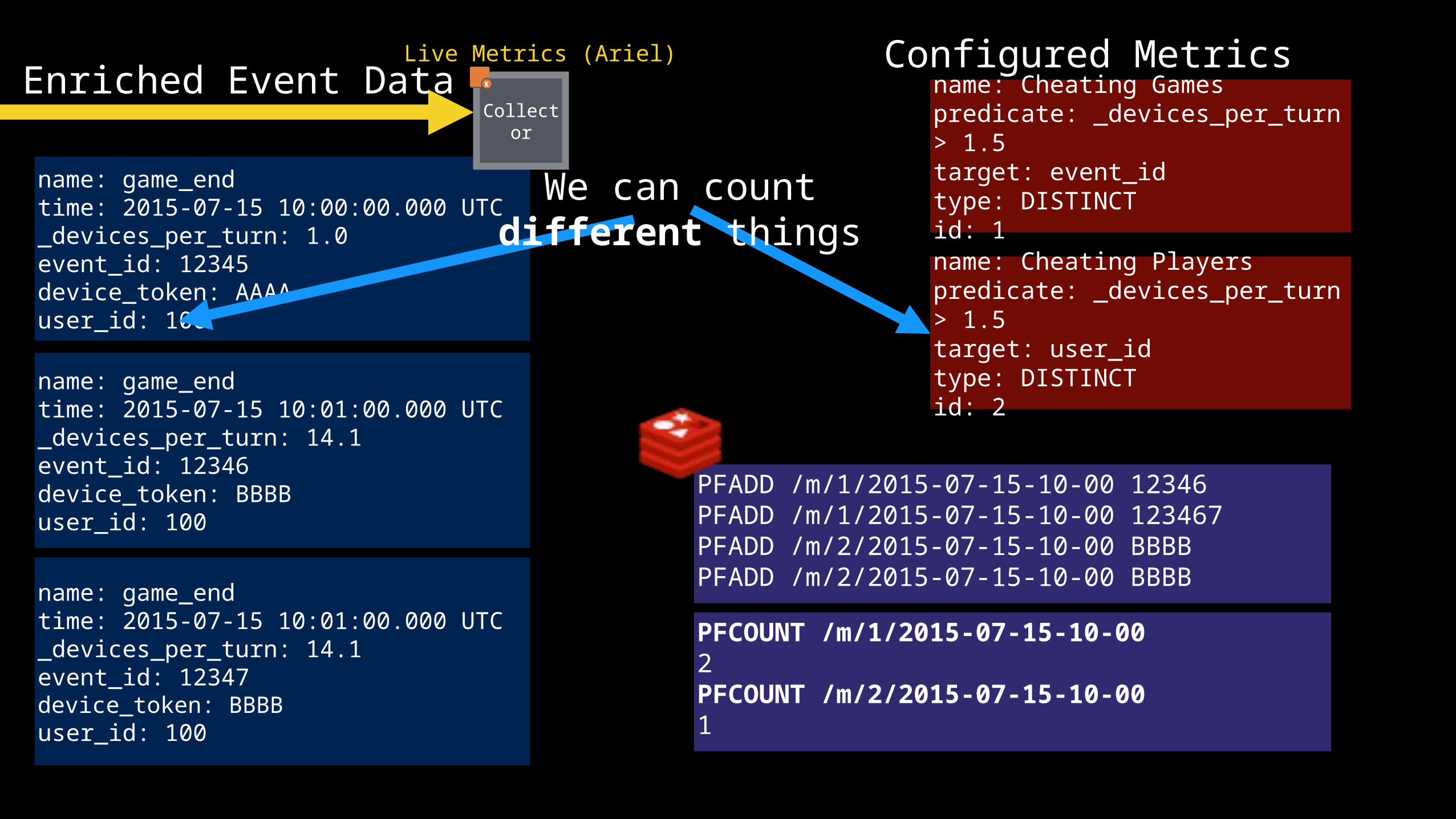
Live Metrics (Ariel)Enriched Event Data
name: game_endtime: 2015-07-15 10:00:00.000 UTC_devices_per_turn: 1.0event_id: 12345device_token: AAAAuser_id: 100
name: game_endtime: 2015-07-15 10:01:00.000 UTC_devices_per_turn: 14.1event_id: 12346device_token: BBBBuser_id: 100
name: Cheating Gamespredicate: _devices_per_turn > 1.5target: event_idtype: DISTINCTid: 1name: Cheating Playerspredicate: _devices_per_turn > 1.5target: user_idtype: DISTINCTid: 2
name: game_endtime: 2015-07-15 10:01:00.000 UTC_devices_per_turn: 14.1event_id: 12347device_token: BBBBuser_id: 100
PFADD /m/1/2015-07-15-10-00 12346 PFADD /m/1/2015-07-15-10-00 123467PFADD /m/2/2015-07-15-10-00 BBBBPFADD /m/2/2015-07-15-10-00 BBBB
PFCOUNT /m/1/2015-07-15-10-002PFCOUNT /m/2/2015-07-15-10-001
Configured Metrics
We can countdifferent things
Collector
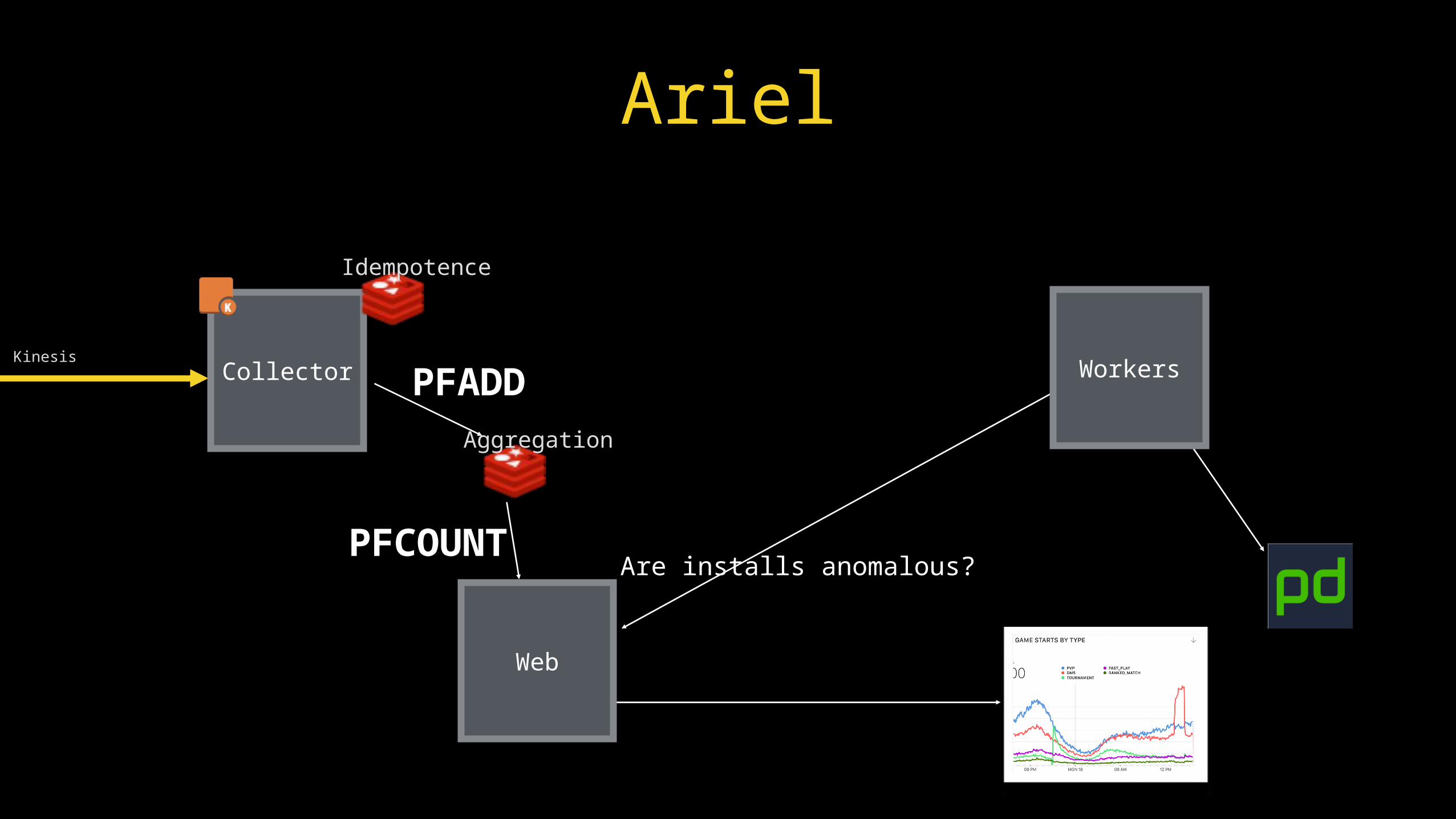
Kinesis
Aggregation
Ariel
PFCOUNT Are installs anomalous?
Collector
Idempotence
PFADD
Web
Workers
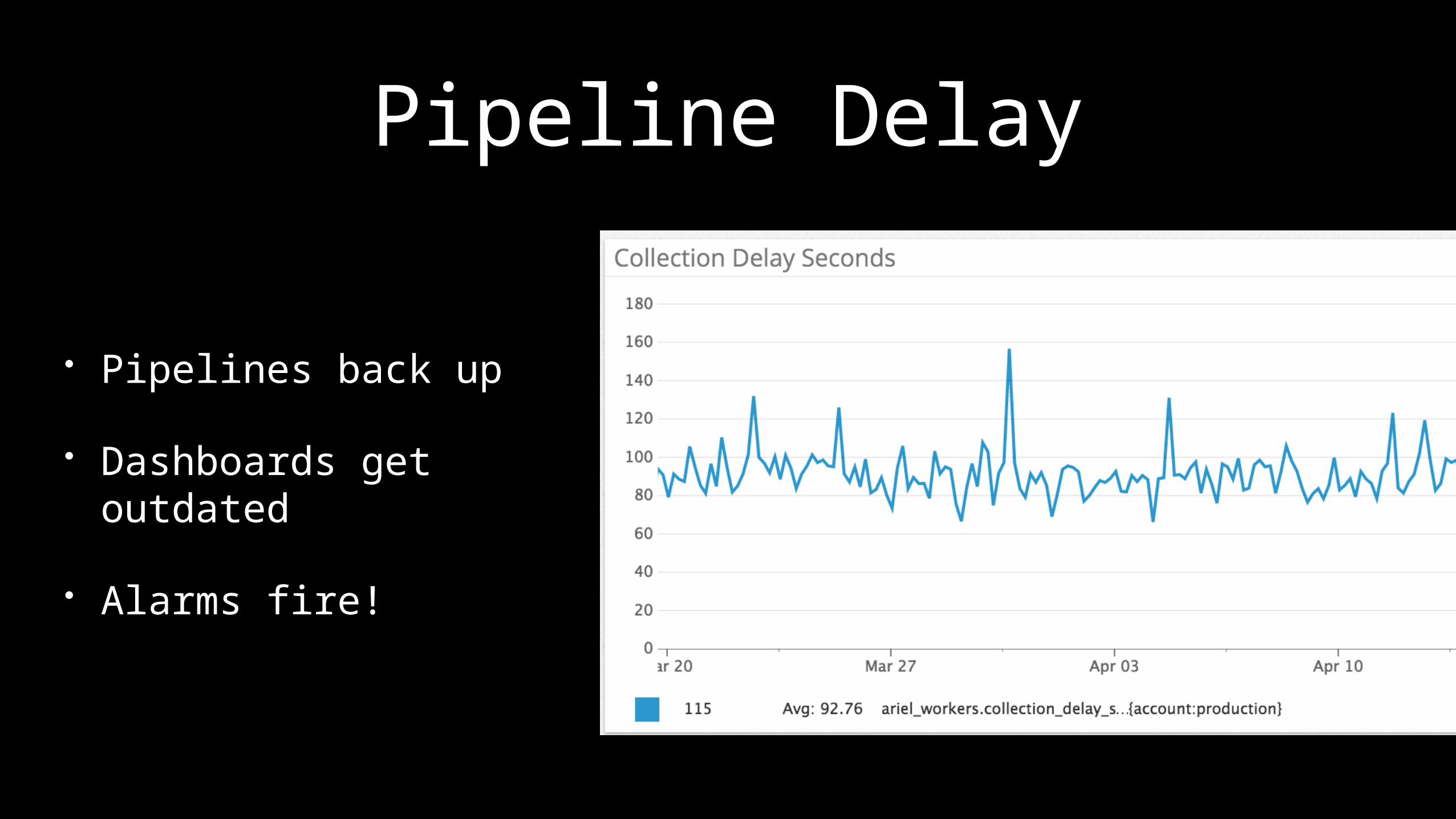
Pipeline Delay
• Pipelines back up• Dashboards get outdated• Alarms fire!

Alarm Clocks• Push timestamp of current events to per-
game pub/sub channel• Worker takes 99th percentile age of last N
events per title as delay• Use that time for alarm calculations• Overlay delays on dashboards
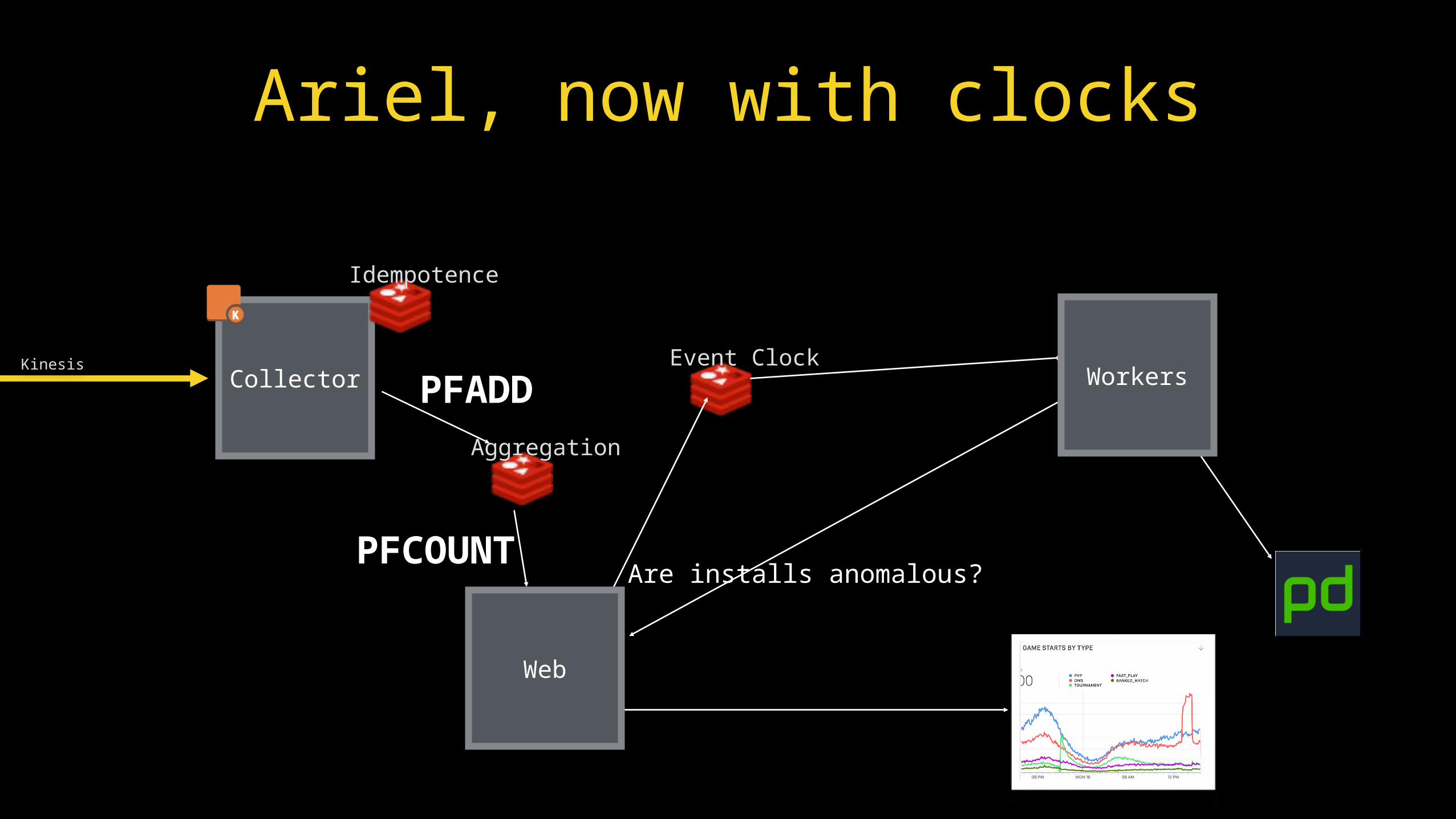
Ariel, now with clocks
Event ClockKinesis
Aggregation
PFCOUNT Are installs anomalous?
Collector
Idempotence
PFADD
Web
Workers

Ariel 1.0• ~30K metrics configured• Aggregation into 30-
minute buckets• 12 kilobytes per HLL set
(plus overhead)
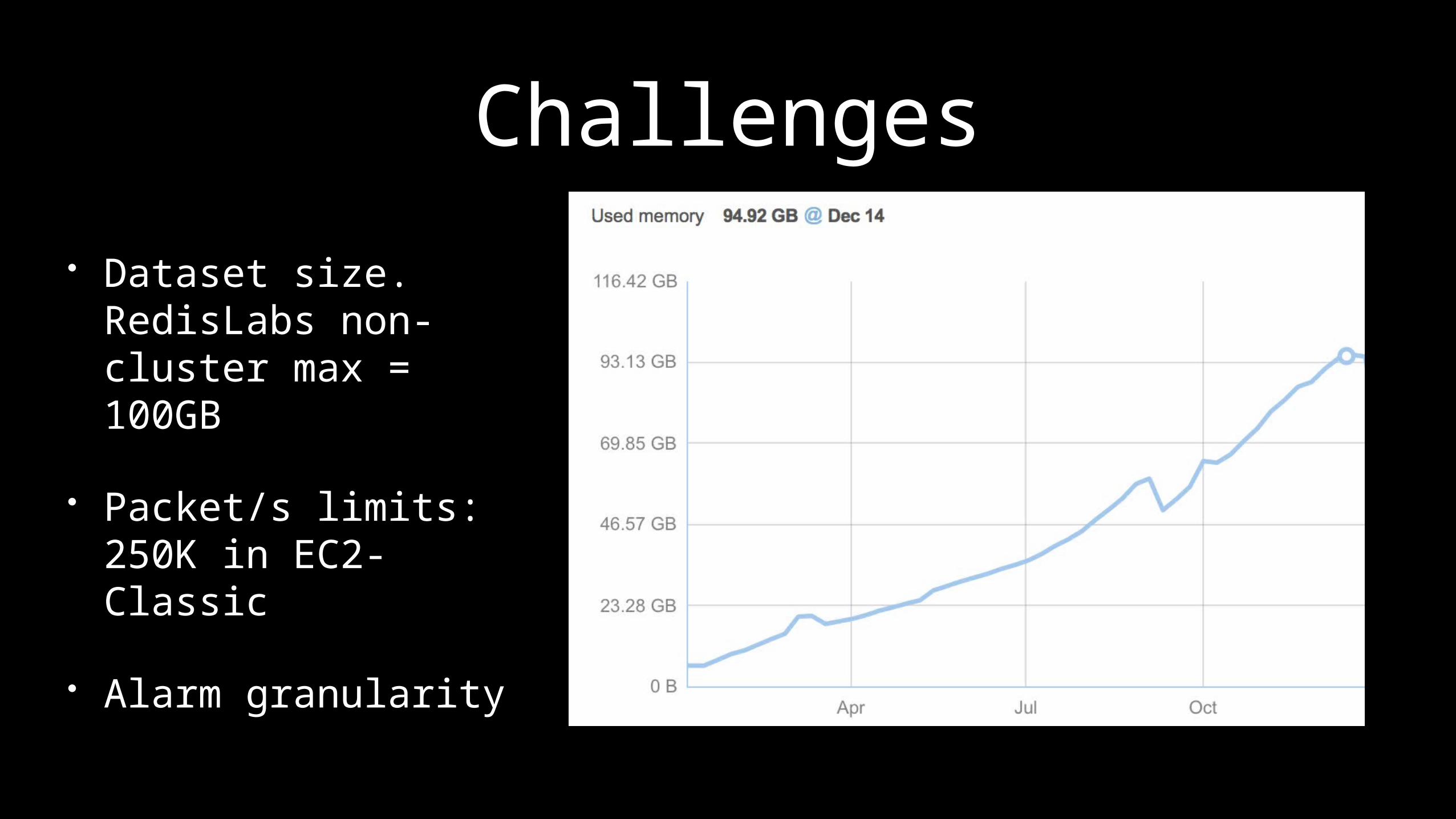
Challenges• Dataset size.
RedisLabs non-cluster max = 100GB
• Packet/s limits: 250K in EC2-Classic
• Alarm granularity

Hybrid Datastore: Requirements
• Need to keep HLL sets to count distinct• Redis is relatively finite• HLL outside of Redis is messy

Hybrid Datastore: Plan
• Move older HLL sets to DynamoDB• They’re just strings!
• Cache reports aggressively• Fetch backing HLL data from DynamoDB as
needed on web layer, merge using on-instance Redis
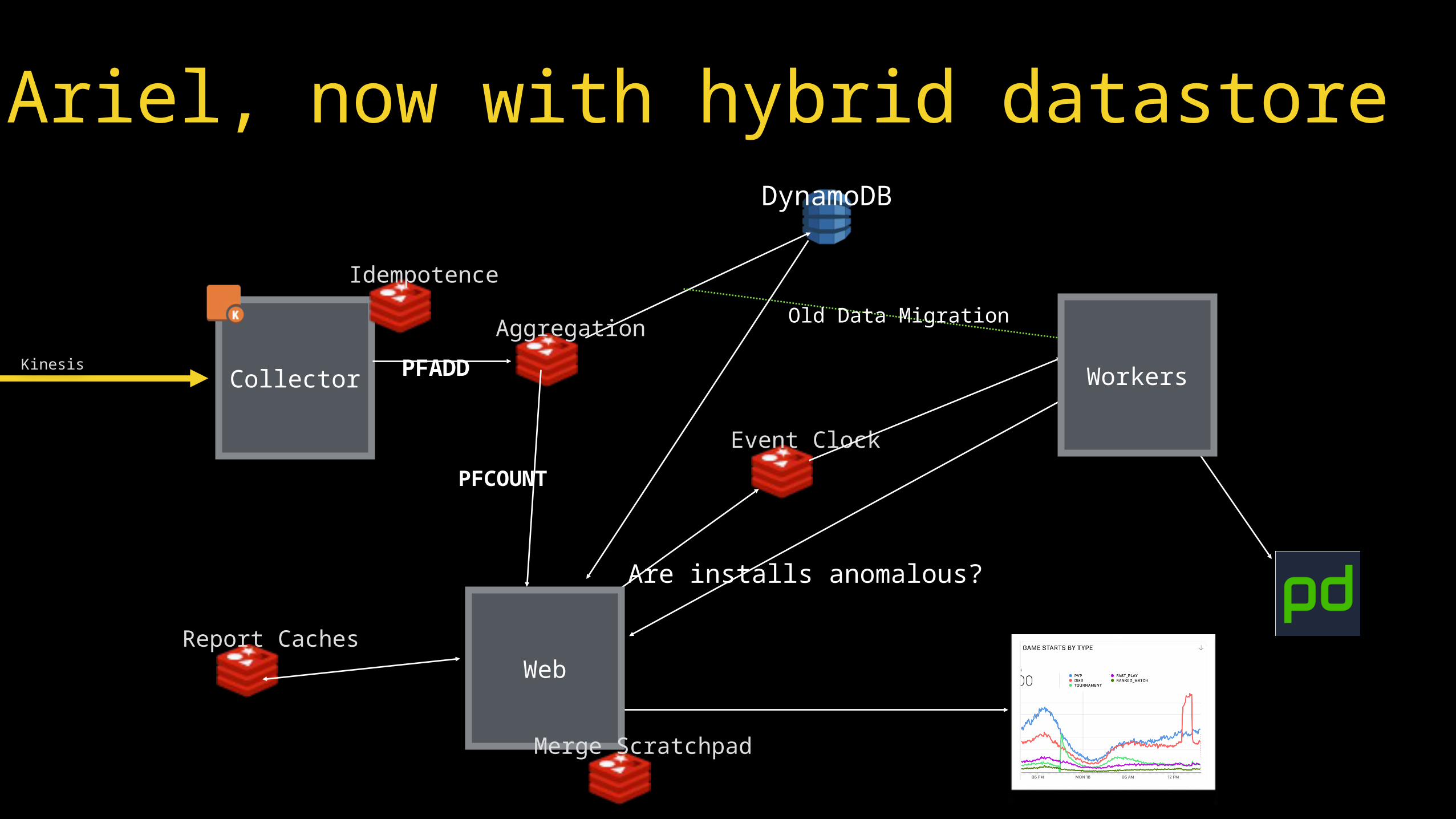
Ariel, now with hybrid datastoreDynamoDB
Report Caches
Old Data Migration
Event Clock
Kinesis
Aggregation
PFCOUNT
Are installs anomalous?
Collector
Idempotence
PFADD
Web
Workers
Merge Scratchpad
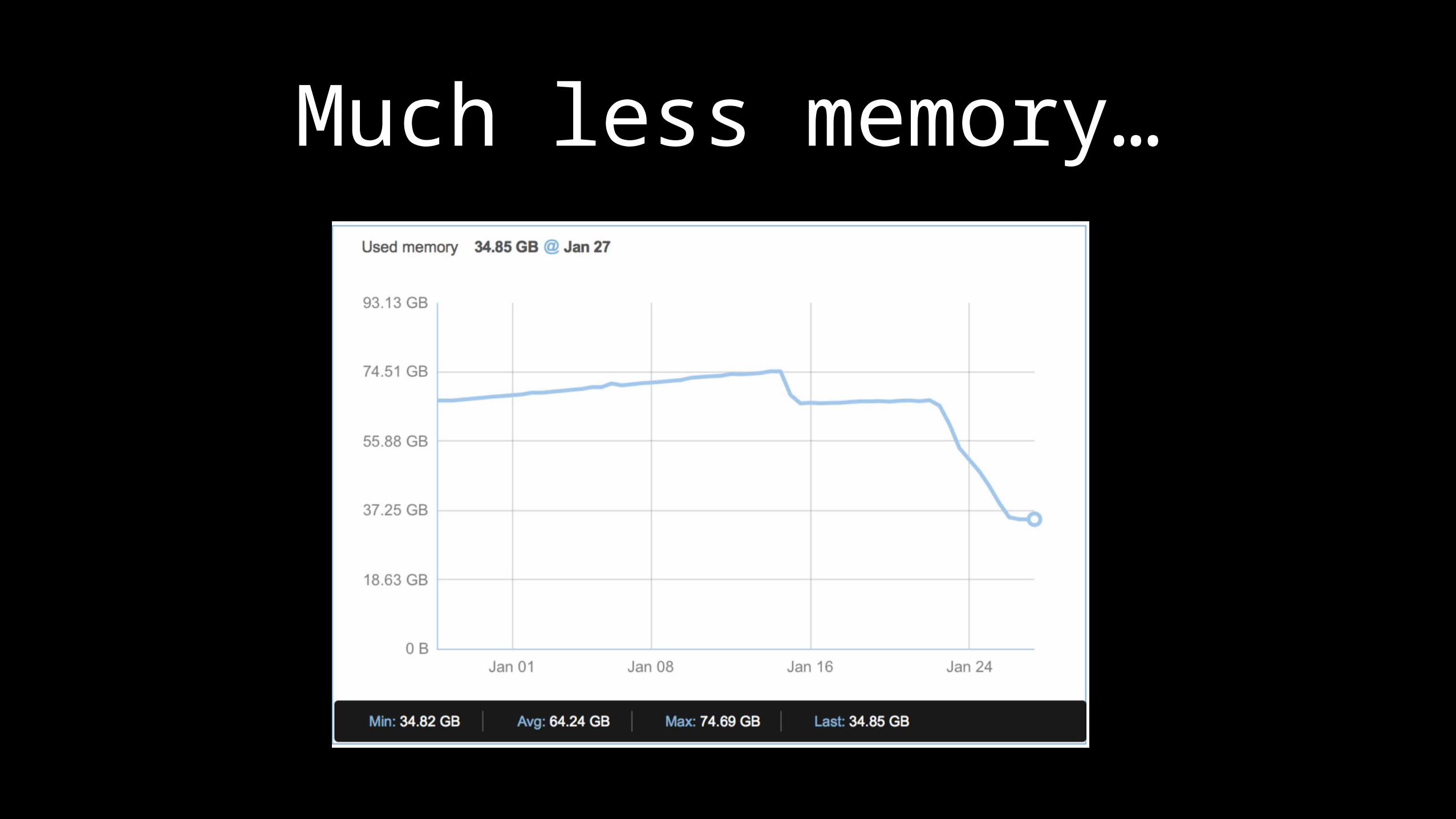
Much less memory…

Redis Roles• Idempotence• Configuration Caching• Aggregation• Clock• Scratchpad for merges• Cache of reports• Staging of DWH extracts

Other Considerations
• Multitenancy. We run parallel stacks and give games an assigned affinity, to insulate from pipeline delays
• Backfill. System is forward-looking only; can replay Kinesis backups to backfill, or backfill from warehouse

Why Not _____?
• Druid• Flink• InfluxDB• RethinkDB






























