Embed Size (px)
Citation preview

Research Papers Recommender based on Digital Repositories Metadata
Ruben Boada, Ricard de la Vega & Ángel CarreñoBig Data Management & Analytics Postgraduate Course (UPC-BarcelonaTech)September 18, 2015

1. Big Picture2. Technical validation 3. Results obtained & demo

1. Big Picture2. Technical validation 3. Results obtained & demo

The objective is to create a research paper recommender based on metadata of all the open access digital repositories

The objective is to create a research paper recommender based on metadata of all the open access digital repositories
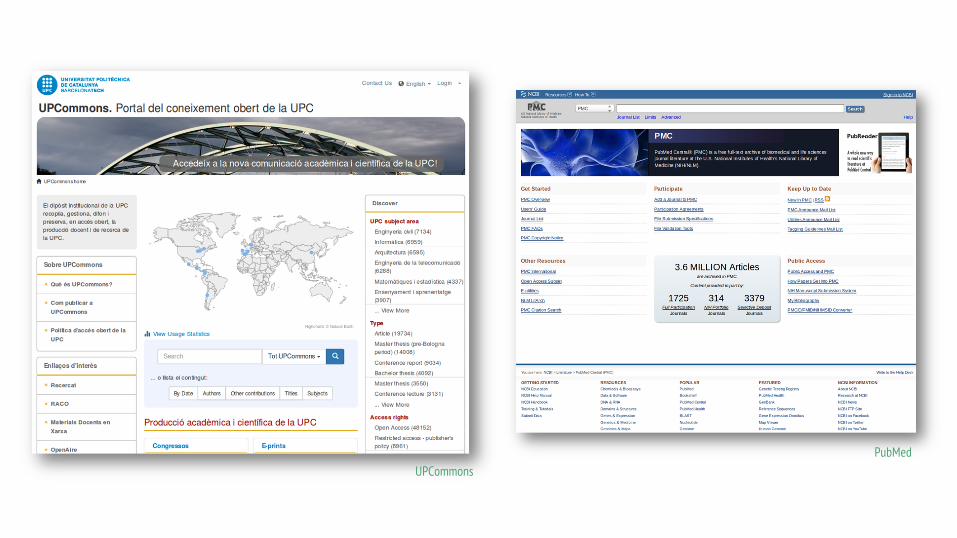
PubMedUPCommons

The objective is to create a research paper recommender based on metadata of all the open access digital repositories

Open Data Sources, how big is it?○ Structured (XML based)
○ OAI-PMH harvester protocol
○ 15 metadata
■ dc.title■ dc.abstract■ dc.creator■ ...
+3K
+114M
Research Papers &Theses
DigitalRepositories
PubMed

Our Approach● Content recommendation● All Open Access repositories ● Based on logical distance between
“representative” keywords (extracted from subject, abstract & title metadata)
● Multi-thesaurus approach, no “subject based”
● Amazon, Netflix, Facebook...● Types: collaborative, content &
híbrid filtering● Research Papers
○ Repository itself○ POC vs Production○ Collaborative and hybrids
(ex. Citations, tags)○ Subject based (ex. ACM)
Related work
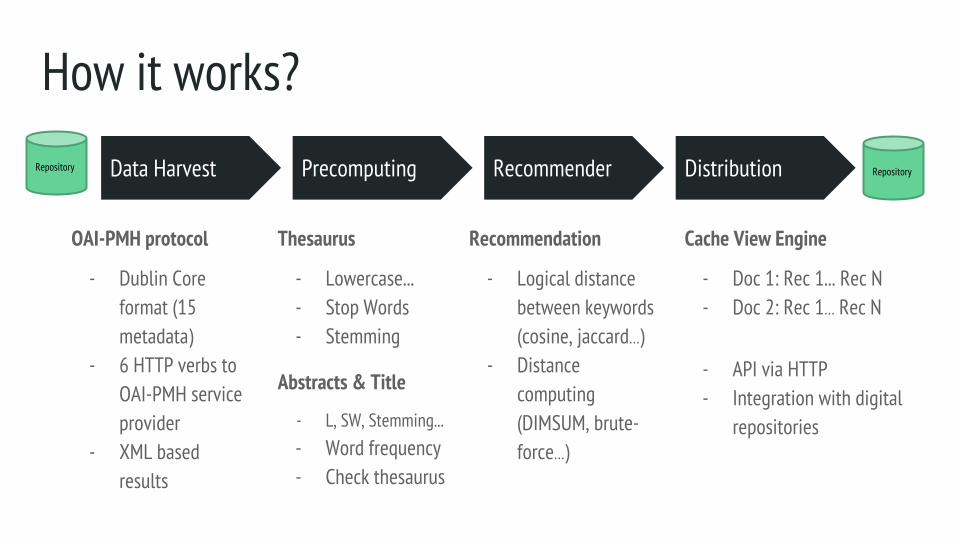
How it works?
Data Harvest
OAI-PMH protocol
- Dublin Core format (15 metadata)
- 6 HTTP verbs to OAI-PMH service provider
- XML based results
Step 2 Step 3Precomputing Recommender Distribution
Thesaurus
- Lowercase...- Stop Words- Stemming
Recommendation
- Logical distance between keywords (cosine, jaccard…)
- Distance computing (DIMSUM, brute-force…)
Cache View Engine
- Doc 1: Rec 1... Rec N- Doc 2: Rec 1… Rec N
- API via HTTP- Integration with digital
repositories
Repository Repository
Abstracts & Title
- L, SW, Stemming...- Word frequency- Check thesaurus

The prototype objective (with 2 repositories) is analyze the feasibility of multi-repository recommendations and obtaining performance metrics to estimate scalability

The prototype objective (with 2 repositories) is analyze the feasibility of multi-repository recommendations and obtaining performance metrics to estimate scalability

The prototype objective (with 2 repositories) is analyze the feasibility of multi-repository recommendations and obtaining performance metrics to estimate scalability

1. Big Picture2. Technical validation 3. Results obtained & demo


Harvest data
- Family to save entire XML responses of this requests (one XML for each register)
- All metadata saved for future use- URL as key (dc.identifier.uri)- Probably versioning of content

Precomputing
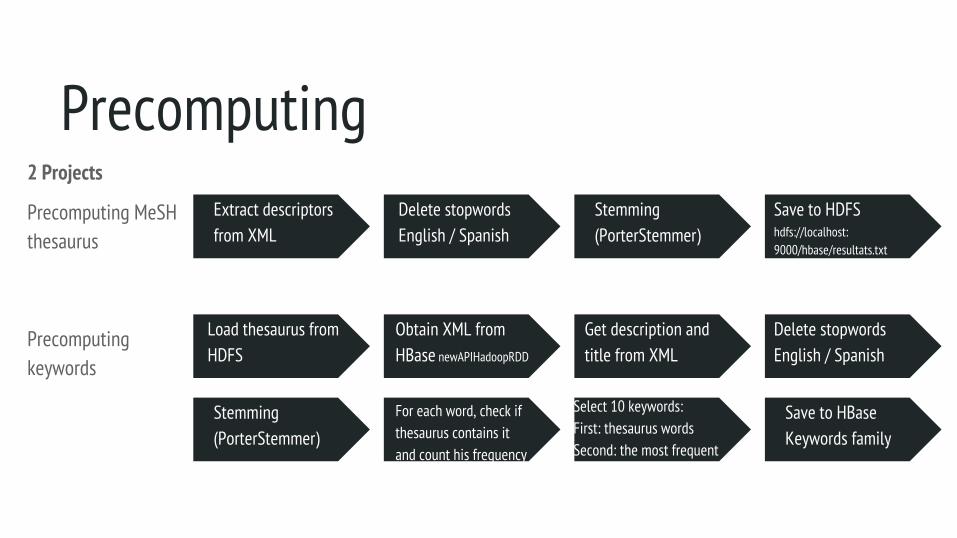
Precomputing2 Projects
Precomputing MeSH thesaurus
Precomputing keywords
Extract descriptors from XML
Delete stopwordsEnglish / Spanish
Stemming (PorterStemmer)
Save to HDFShdfs://localhost:9000/hbase/resultats.txt
Load thesaurus from HDFS
Obtain XML from HBase newAPIHadoopRDD
Get description and title from XML
For each word, check if thesaurus contains it and count his frequency
Delete stopwordsEnglish / Spanish
Stemming (PorterStemmer)
Select 10 keywords:First: thesaurus wordsSecond: the most frequent
Save to HBaseKeywords family

Precomputing - Reduce loops to only the necessary
- Define objects outside principal iterator
- Use foreachPartition function to instantiate one connection for each partition
- Pre-split HBase to exploit parallelization
- Redefine computing stopwords (concatenate no stopwords vs replace stopwords from original text)
- BufferedMutator vs HTableInterface
- Many loops- Too many instances inside
loops- Many connections to HBase
(one per register)- Algoritmic problems
(e.g. replaceAll vs concatenate)

Precomputing
Check if thesaurus contains each word is hard !!!

Recommender
VS
DIMSUM (MLlib) Brute force approach
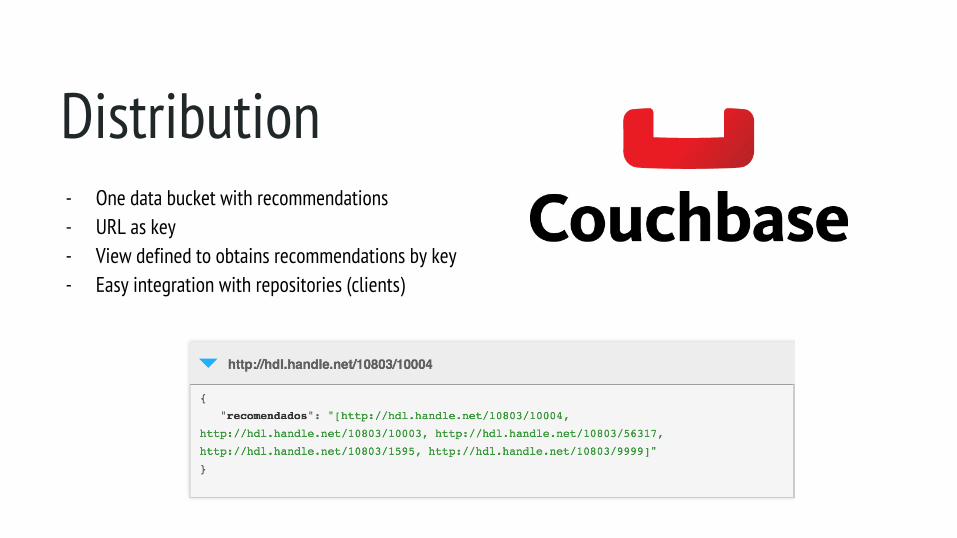
Distribution- One data bucket with recommendations- URL as key- View defined to obtains recommendations by key- Easy integration with repositories (clients)

1. Big Picture2. Technical validation 3. Results obtained & demo
Repository
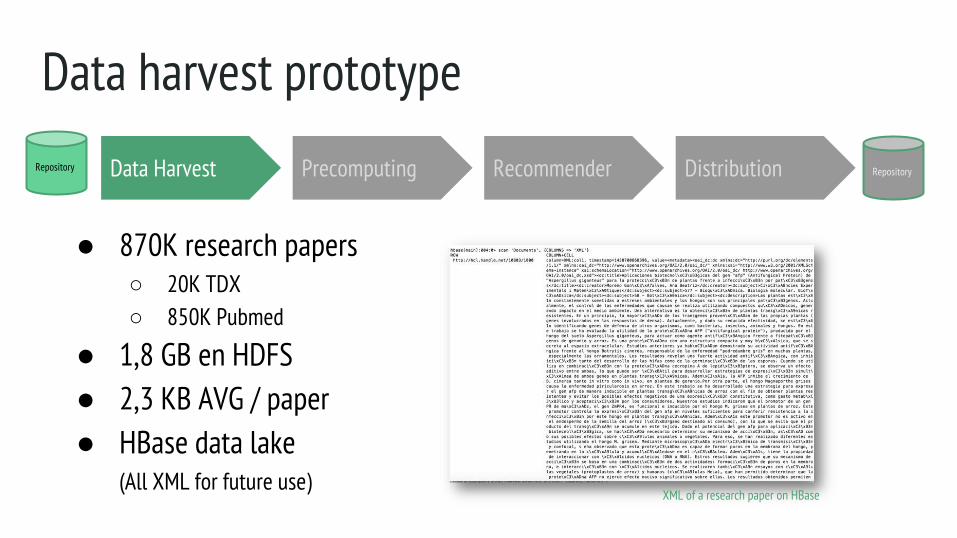
Data harvest prototype
Data Harvest
● 870K research papers○ 20K TDX○ 850K Pubmed
● 1,8 GB en HDFS● 2,3 KB AVG / paper● HBase data lake
(All XML for future use)
Precomputing RecommenderRepository Distribution
XML of a research paper on HBase
Repository
Data harvest prototype
Data Harvest
● First, XML on FS. Second approach, insert on HBase.● Fetch XML + insert on HBase
○ Adapt (an existing) harvester module○ To do a new harvester
● New harvester implementation, effective but not efficient○ Connection management problems○ [prototype] manual intervention vs improve connection management
Precomputing RecommenderRepository Distribution

Repository
Precomputing prototype
Data Harvest
● Medical Subject Headings Thesaurus (MeSH) loading on HDFS○ 27.450 items, 0,5 MB○ 25 minutes
● Keyword extraction from abstract & title metadata ○ 870K research papers○ 100 words AVG / research paper on title+abstract○ 28K comparisons on thesaurus / word (worst case, but often)
Precomputing RecommenderRepository Distribution

Repository
Precomputing prototype
Data Harvest Precomputing RecommenderRepository Distribution
Research Papers Computing time (on hours)
Initial approach 23K 12
Approach without thesaurus comparisons
870K 0,5
Final approach 870K 1,6

Repository
Recommender prototype
Data Harvest Precomputing RecommenderRepository Distribution

Future Work● 2n prototype with
○ DIMSUM or similar recommender approach
○ Cloud infrastructure○ User validation tests with different
configurations
● And beyond…○ Full research papers text○ New products, ex. duplicator
detection
ConclusionsWith the prototype, we want to check the feasibility of:
● Multi-repository research paper recommendations○ Ex. TDX with Pubmed
recommendations
● Performance metrics to estimate scalability○ harvest & precomputing: reasonable○ recommender approach: not

1. Big Picture2. Technical validation 3. Results obtained & demo






























