Embed Size (px)
Citation preview

Reproducibility (and automation) ofMachine Learning process
Dzianis Dus
Data Scientist at InData Labs

What this speech is about?
1. Data mining / Machine learning process
2. Workflow automation
3. Basic design concepts
4. Data pipelines
5. Available instruments
6. About my own experience

Process overview
1. Data Engineering – 80%– Data extraction
– Data cleaning
– Data transformation
– Data normalization
– Feature extraction
2. Machine Learning – 20%– Model fitting
– Hyperparameters tuning
– Model evaluationCRISP-DM

Why automation?
1. You want to update models on regular basis
2. Make your data workflows more trustable
3. You can perform a data freeze (possibly)
4. A step to (more) reproducible experiments
5. Write once and enjoy every day

How: Conceptual requirements1. Reuse code between training and evaluation
phases (as much as possible)
2. Its easier to log features then to extract them from data in retrospective way (if you can)
3. Solid environment is more important for the first iteration then the quality of your model
4. Better to use the same language everywhere (integration becomes much easier)
5. Every model requires support after deployment
6. You’d better know the rules of the game…

Feel free to download from author’s personal web page:http://martin.zinkevich.org/rules_of_ml/

A taste of

How: Technical requirements
1. Simple way to define DAGs of batch tasks
2. Tasks parameterization
3. Ability to store intermediate results(checkpointing)
4. Tasks dependencies resolution
5. Automatic failures processing
6. Logging, notifications
7. Execution state monitoring
8. Python-based solution (we are on PyCon)

https://github.com/pinterest/pinball
Pinball (Pinterest)
1. Nice UI2. Dynamic pipelines
generation3. Pipelines configuration in
Python code (?)4. Parameterization through
shipping python dicts (?)5. In fact, not documented6. Seems like no other big
players use this

https://github.com/apache/incubator-airflow
Airflow (AirBnB, Apache Incubator)
1. Very nice UI2. Dynamic pipelines
generation3. Orchestration through
message queue4. Code shipping5. Scheduler spawns workers6. Pipelines configuration in
Python code7. Parameterization through
tasks templates using Jinja(Hmm…)
8. As for me, not so elegant as written in documentation

https://github.com/spotify/luigi
Luigi (Spotify, Foursquare)
1. Simple UI2. Dynamic pipelines
generation3. Orchestration through
central scheduling (no external components)
4. No code shipping5. No scheduler6. Pipelines configuration in
Python code (very elegant!)7. Parameterization through
Parameters ()8. Simple, well-tested9. Good documentation

About … Luigi!

Luigi … … is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoopsupport built in.
… helps you stitch many tasks together, where each task can be a Hive query, a Hadoop job in Java, a Spark job in Scala or Python, a Python snippet, dumping a table from a database, or anything else…

Luigi facts
1. Inspired by GNU Make
2. Everything in Luigi is in Python
3. Extremely simple (has only three main classes: Target, Task, Parameter)
4. Each task must consume some input data and may produce some output
5. Based on assumption of atomic writes

Luigi facts
1. Has no built-in scheduler (use crontab / run manually from CLI)
2. You can not trigger any tasks from UI (its only for monitoring purposes)
3. Master takes only orchestration role
4. Master does not ship your code to workers

Luigi fundamentalsTarget corresponds to:• file on local FS• file on HDFS• entry in DB• any other kind of a checkpoint
Task:• this is where execution takes place• consume Targets that where created by other Tasks• usually also outputs Target• could depend on one or more other Tasks• could have Parameters

Luigi Targets
• Have to implement exists method
• Write must be atomic
• Luigi comes with a toolbox of useful Targets:luigi.LocalTarget(‘/home/path/to/some/file/’)
luigi.contrib.hdfs.HdfsTarget(‘/reports/%Y-%m-%d’)
luigi.postgres.PostgresTarget(…)
luigi.contrib.mysqldb.MySqlTarget(…)
luigi.contib.ftp.RemoteTarget(…)
… and many others …
• Built-in formats (GzipFormat is useful)

Luigi Tasks• Main methods: run(), output(), requires()
• Write your code in run()
• Define your Target in output()
• Define dependencies using requires()
• Task is complete() if output Target exists()

Luigi Parameters• Task that runs a Hadoop job every night?
• Luigi provides a lot of them:luigi.parameter.Parameterluigi.parameter.DateParameterluigi.parameter.IntParameterluigi.parameter.EnumParameterluigi.parameter.ListParameterluigi.parameter.DictParameter… and etc …
• And automatically parses from CLI!

Execute from CLI: $ luigi MyTask --module your.cool.module --param 999

Central scheduling• Luigi central scheduler (luigid)
– Doesn’t do any data processing– Doesn’t execute any tasks– Workers synchronization– Tasks dependencies resolution– Prevents same task run multiple times– Provides administrative web interface– Retries in case of failures– Sends notifications (emails only)
• Luigi worker (luigi)– Starts via cron / by hand– Connects to central scheduler– Defines tasks for execution– Waits for permission to execute Task.run() – Processes data, populates Targets

Web interface

Execution model
Simplified process:1. Some workers started2. Each submits DAG of Tasks3. Recursive check of Tasks completion4. Worker receives Task to execute5. Data processing!6. Repeat
Client-server API:1. add_task(task_id, worker_id, status)2. get_work(worker_id)3. ping(worker_id)
http://www.arashrouhani.com/luigid-basics-jun-2015/

Tasks dependencies
• Using requires() method
• yielding at runtime!

Easy parallelization recipe
1. Do not use multiprocessing inside Task
2. Split huge Task into smaller ones and yieldthem inside run() method
3. Run luigi with --workers N parameter
4. Make a separate job to combine all the Targets (if you want)
5. Also it helps to minimize your possible data loss in case of failures (atomic writes)

Luigi notifications
• luigi.notifications
• Built-in support for email notifications:
– SMTP
– Sendgrid
– Amazon SES / Amazon SNS
• Side projects for other channels:
– Slack (https://github.com/bonzanini/luigi-slack)
– …

About … Flo!

Flo is the first period & ovulation tracker that uses neural networks*.
* OWHEALTH, INC. is the first company to publicly announce using neural networks formenstrual cycle analysis and prediction.
• Top-level App in Apple Store and Google Play
• More than 6.5 million registered users
• More than 17.5 million tracked cycles
• Integration with wearable devices
• A lot of (partially) structured information
• Quite a lot work with data & machine learning
• And even more!

• About 450 GB of useful information:– Cycles lengths history
– Ovulation and pregnancy tests results
– User profile data (Age, Height, Weight, …)
– Manual tracked events (Symptoms, Mood, …)
– Lifestyle statistics (Sleep, Activity, Nutrition, …)
– Biometrics data (Heart rate, Basal temperature, …)
– Textual data
– …
• Periodic model updates

Key points
• Base class for all models (sklearn-like interface)• Shared code base for data and features extraction
during training and prediction phases• Currently 450+ features extracted for each cycle• Using individual-level submodels predictions (weak
predictors) as features for network input (strong predictor)
• Semi-automatic model updates• Model unit testing before deployment• In practice heuristics combined with machine
learning

Model update in Flo =
• (Me) Trigger pipeline execution from CLI
• (Luigi) Executes ETL tasks (on live Postgres replica)
• (Luigi) Persists raw data on disk (data freeze)
• (Luigi) Executes features extraction tasks
• (Luigi) Persists dataset on disk
• (Luigi) Executes Neural Network fitting task
• (Tensorflow) A lot of operations with tensors
• (Me) Monitoring with TensorBoard and Luigi Web Interface
• (Me) Working on other tasks, reading Slack notifications
• (Me) Deploying model by hand (after unit testing)
• (Luigi, Me) Looking after model accuracy in production

Triggering pipeline
1. Class of model:• Provides basic architecture of network• Has predefined set of hyperparameters
2. Model build parameters:• Sizes of some named layers• Weights decay amount (L2 regularization technique)• Dropout regularization amount• Or what ever needed to compile Tensorflow / Theano computation graph
3. Model fit parameters:• Number of fitting epochs• Mini-batch size• Learning rate• Specific paths to store intermediate results
4. Data extraction parameters:• Date of data freeze (raw data on disk)• Segment of users for which we want to fit model• Many other (used default values)

Model update in Flo: DAG Fit network → Extract features → Fit submodels → Extract Raw → Data Train / Test split

Model update in Flo: Dashboard Track DAG execution status in Luigi scheduler web interface:
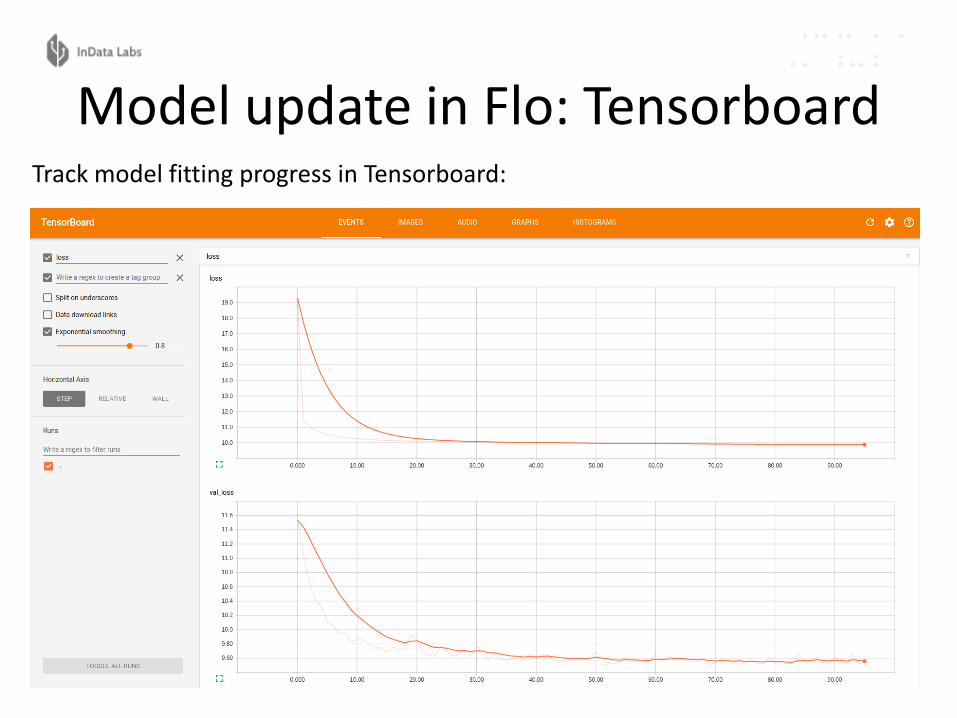
Model update in Flo: TensorboardTrack model fitting progress in Tensorboard:

Model update in Flo: Notifications • Everything is OK:
• Some trouble with connection:
• Do I need to update the model?

Conclusion
Reproducibility and automation is about:1. Process design (conceptual aspect)
– Think not only about experiments, but about further integration too
– Known best practices
2. Process realization (technical aspect) – Build solid data science environment– Search for convenient instruments (Luigi seems like a
good starting point)– Make your pipelines simple and easily extensible– Make everything you can to make your pipelines trustful– Monitoring is important aspect

I hope you’ve enjoyed it!Questions, please.





























