Embed Size (px)
Citation preview

Python Scalability: A Convenient Truth
Travis Oliphant
Continuum Analytics

2
• A short tour through data science • Understanding Scale • The Zen of PyData
Overview• Abstract overview

DATA SCIENCE: A SHORT TOUR
3
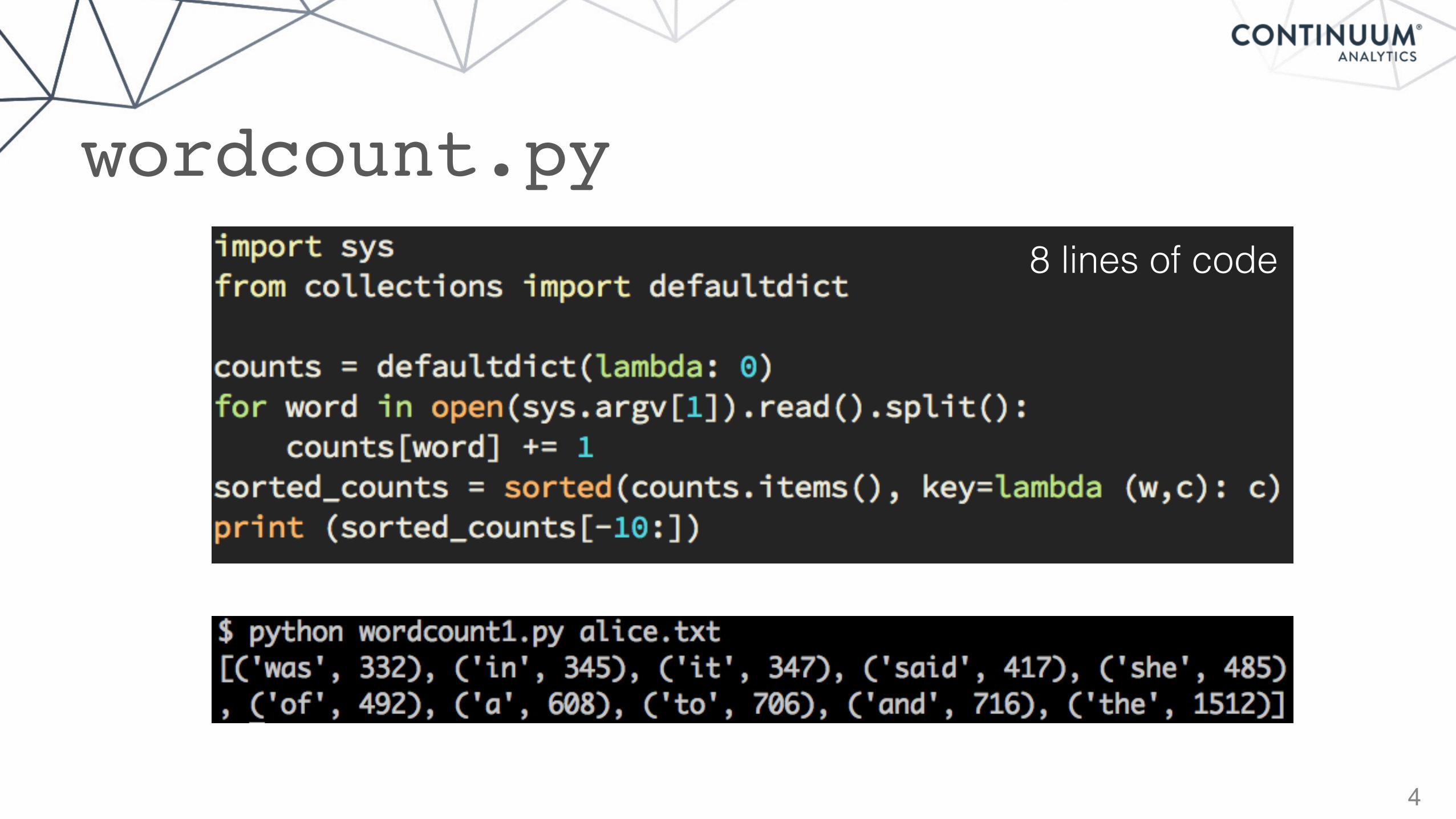
4
wordcount.py8 lines of code

5
Performance & Limitations• For 1 million rows (45MB CSV), takes ~3 sec on Macbook • … but CSVs are not where Python shines • For a billion rows…?
• Also, data has to fit in memory • For this problem, maybe we can be clever with itertools or
toolz and streaming for out-of-core • The lack of “easy” and “obvious” solutions to larger datasets is
why people tend to believe that “Python doesn’t scale”
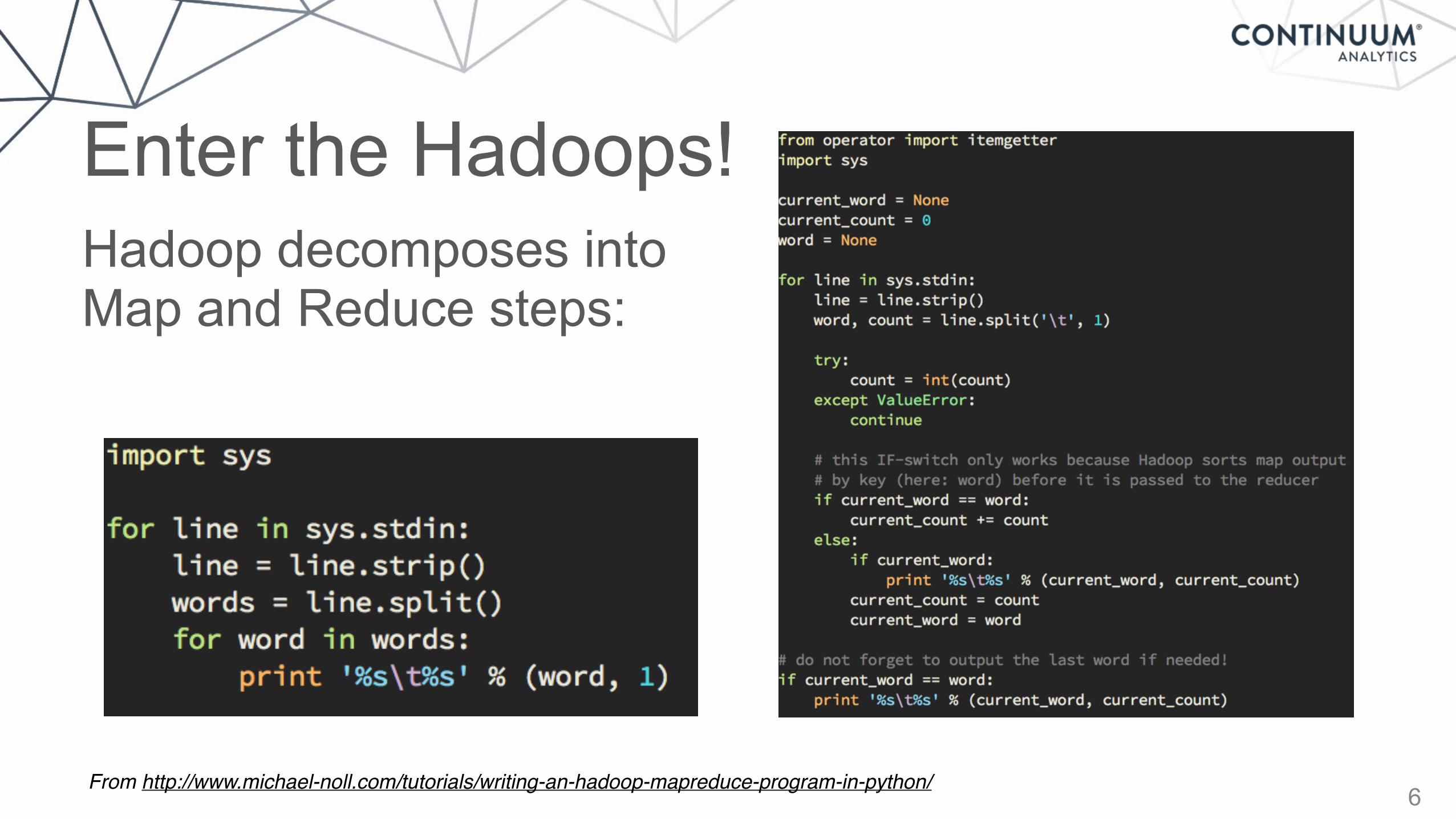
6
Enter the Hadoops!Hadoop decomposes intoMap and Reduce steps:
From http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/

Maybe Spark is an improvement?
7

An Inconvenient Truth
8
• “Python” libraries in the Hadoop ecosystem are lipstick.py on an elephant in the room: Python in Hadoop is a second class citizen, outside of the most straightforward use cases • Cognitive model is very different • Access to libraries is extremely limited

Query, Exploration, Modeling
9
• “Core” Hadoop is traditionally concerned with scalable, robust query performance
• Even though Spark and Hadoop enable scale-out, for many data scientists, the usability for ad hoc exploration is dramatically lower than with Python or R because of the reduced interactivity
• In essence, the usability factors around scale-out means that they explore on a single machine, sometimes on a subset of data, and then deploy onto not only a different machine (cluster), but have to recode into different language or APIs

UNDERSTANDING SCALE
10
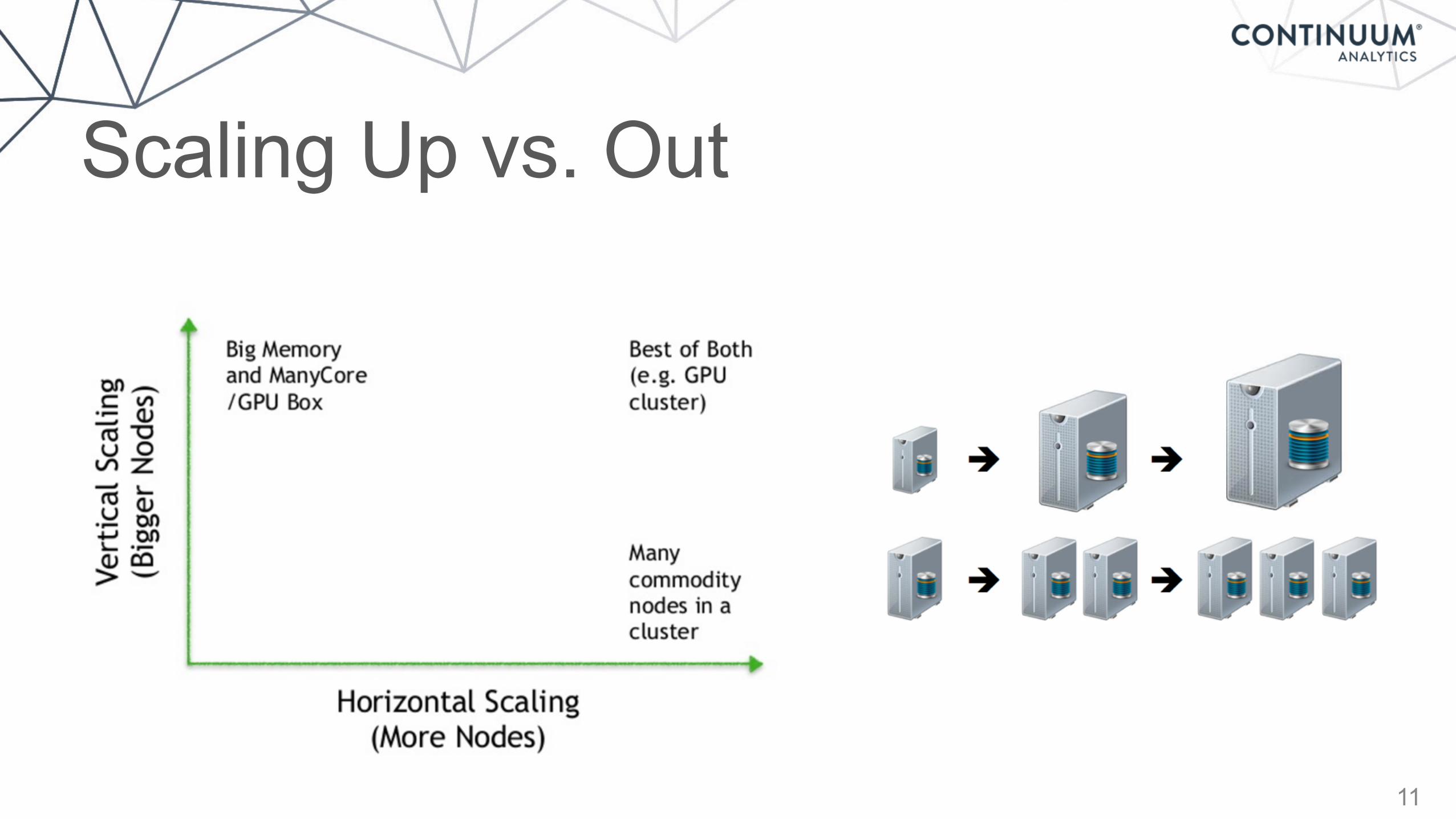
Scaling Up vs. Out
11
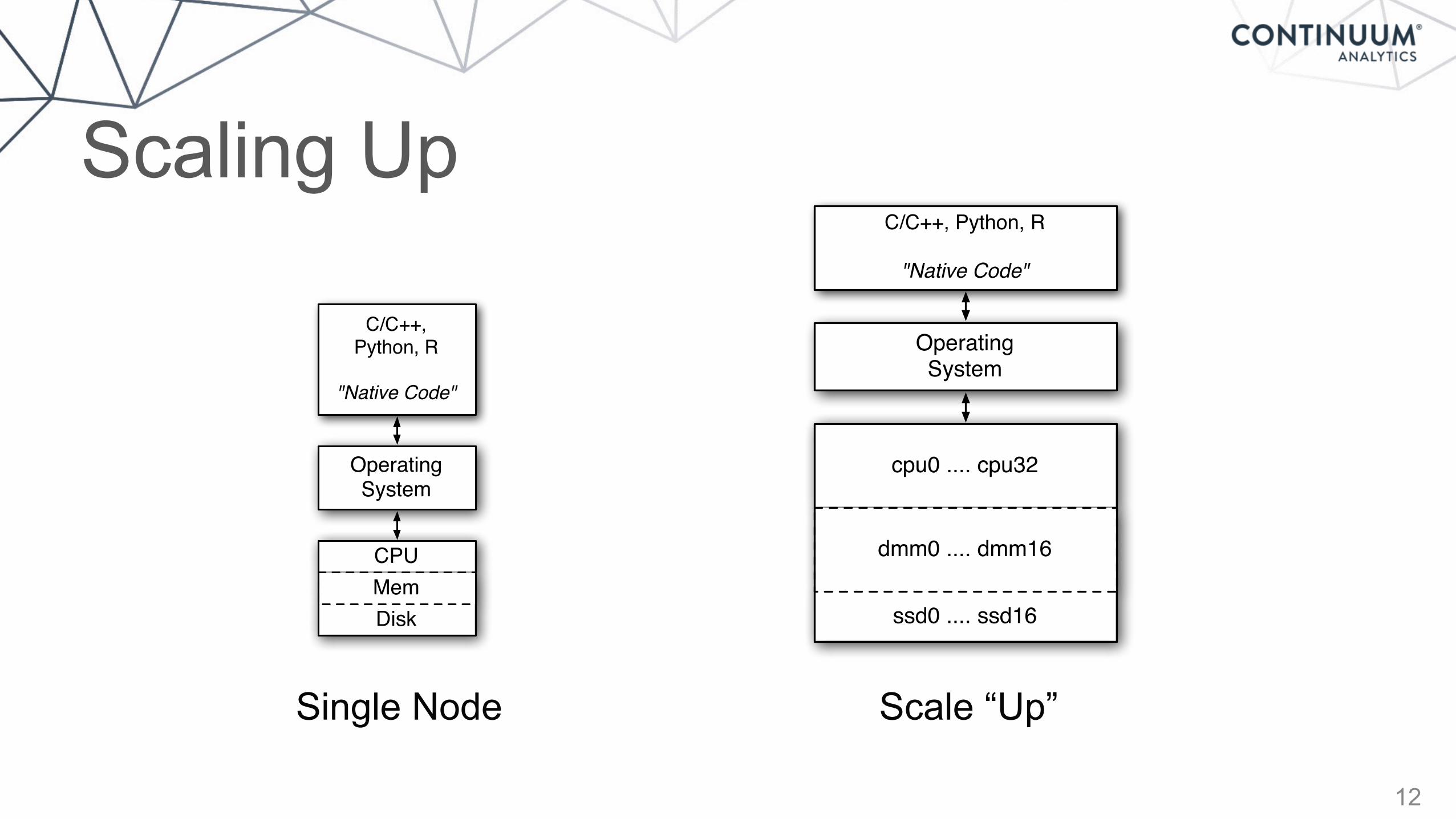
Scaling Up
12
Single Node
C/C++, Python, R
"Native Code"
OperatingSystem
CPU
DiskMem
Scale “Up”
cpu0 .... cpu32
ssd0 .... ssd16
dmm0 .... dmm16
C/C++, Python, R
"Native Code"
OperatingSystem
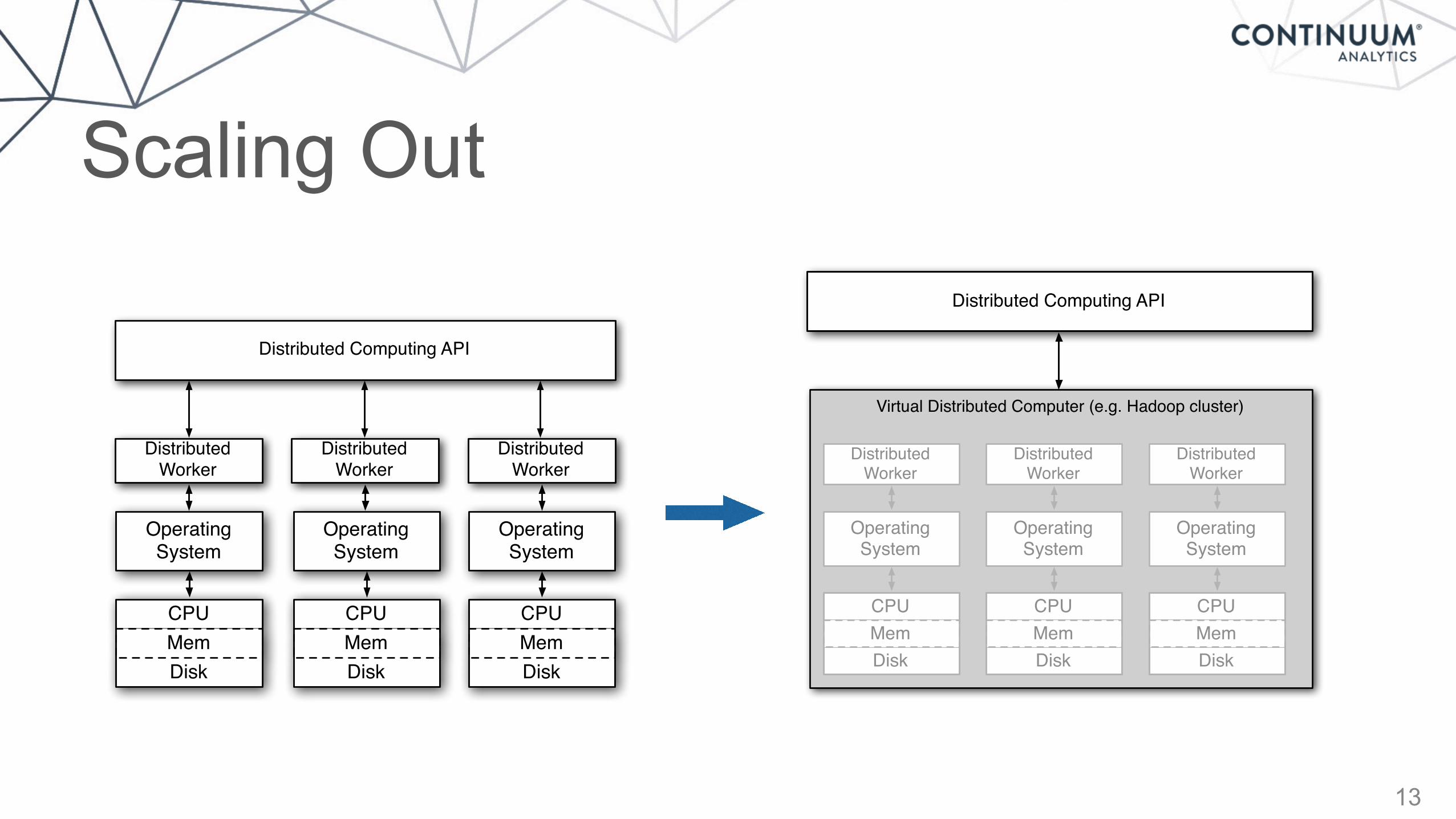
Scaling Out
13
OperatingSystem
CPU
DiskMem
OperatingSystem
OperatingSystem
CPU
DiskMem
CPU
DiskMem
DistributedWorker
Distributed Computing API
DistributedWorker
DistributedWorker
Virtual Distributed Computer (e.g. Hadoop cluster)
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
CPU
DiskMem
CPU
DiskMem
CPU
DiskMem
Distributed Computing API
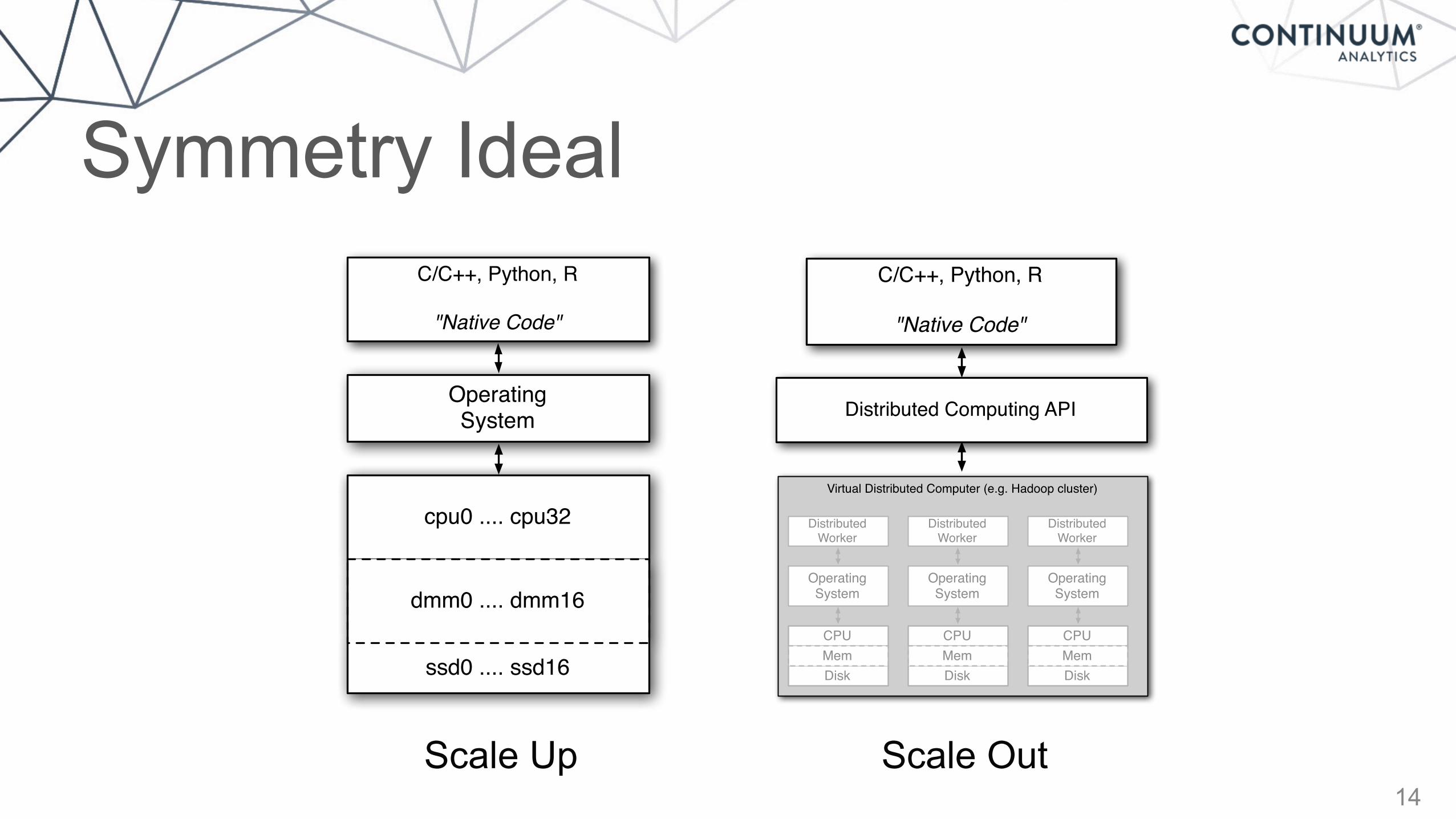
Symmetry Ideal
14
cpu0 .... cpu32
ssd0 .... ssd16
dmm0 .... dmm16
C/C++, Python, R
"Native Code"
OperatingSystem
Virtual Distributed Computer (e.g. Hadoop cluster)
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
CPU
DiskMem
CPU
DiskMem
CPU
DiskMem
Distributed Computing API
Scale Up Scale Out
C/C++, Python, R
"Native Code"
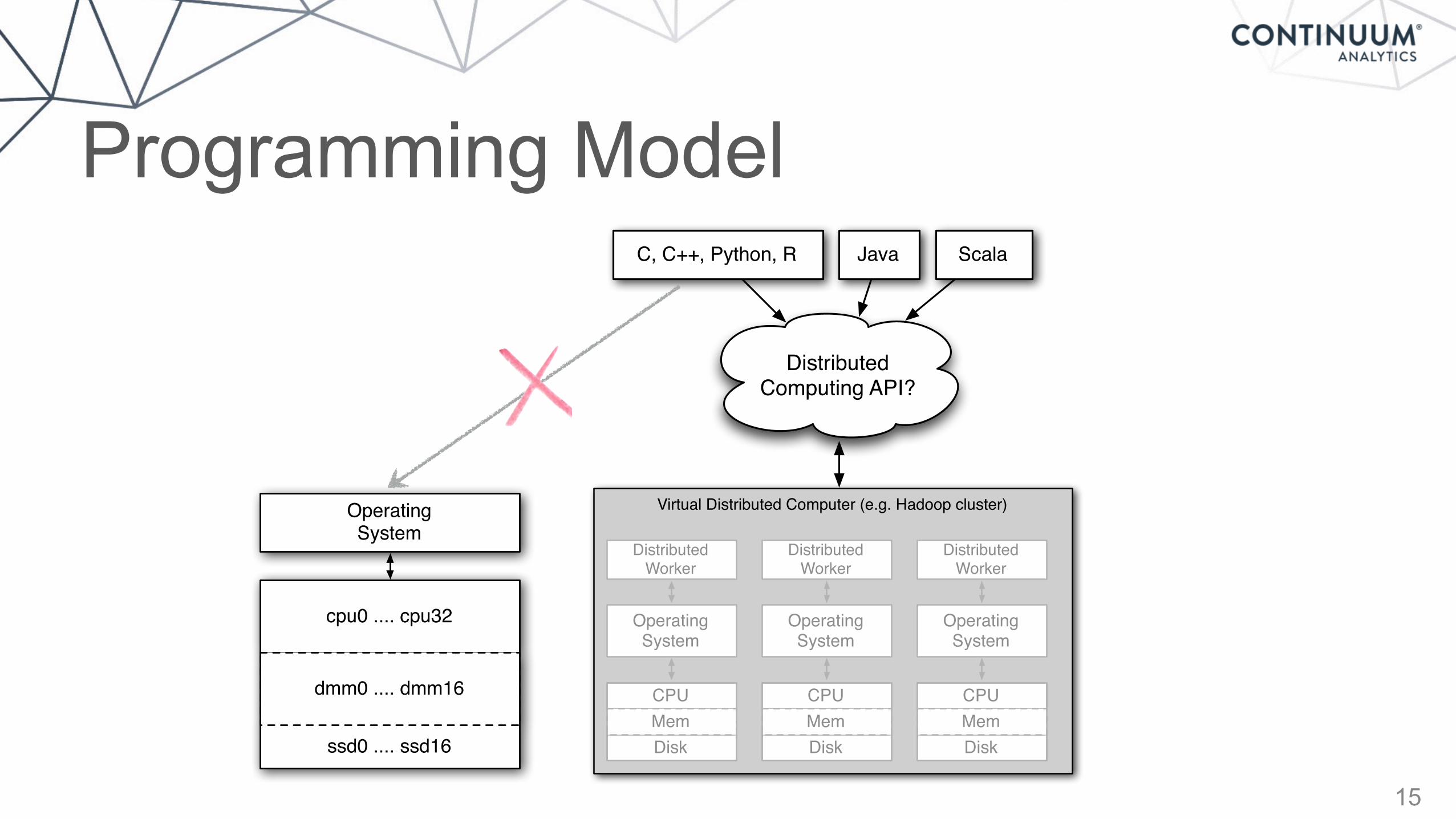
Programming Model
15
Virtual Distributed Computer (e.g. Hadoop cluster)
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
DistributedWorker
OperatingSystem
CPU
DiskMem
CPU
DiskMem
CPU
DiskMem
C, C++, Python, R Java Scala
Distributed Computing API?
cpu0 .... cpu32
ssd0 .... ssd16
dmm0 .... dmm16
OperatingSystem
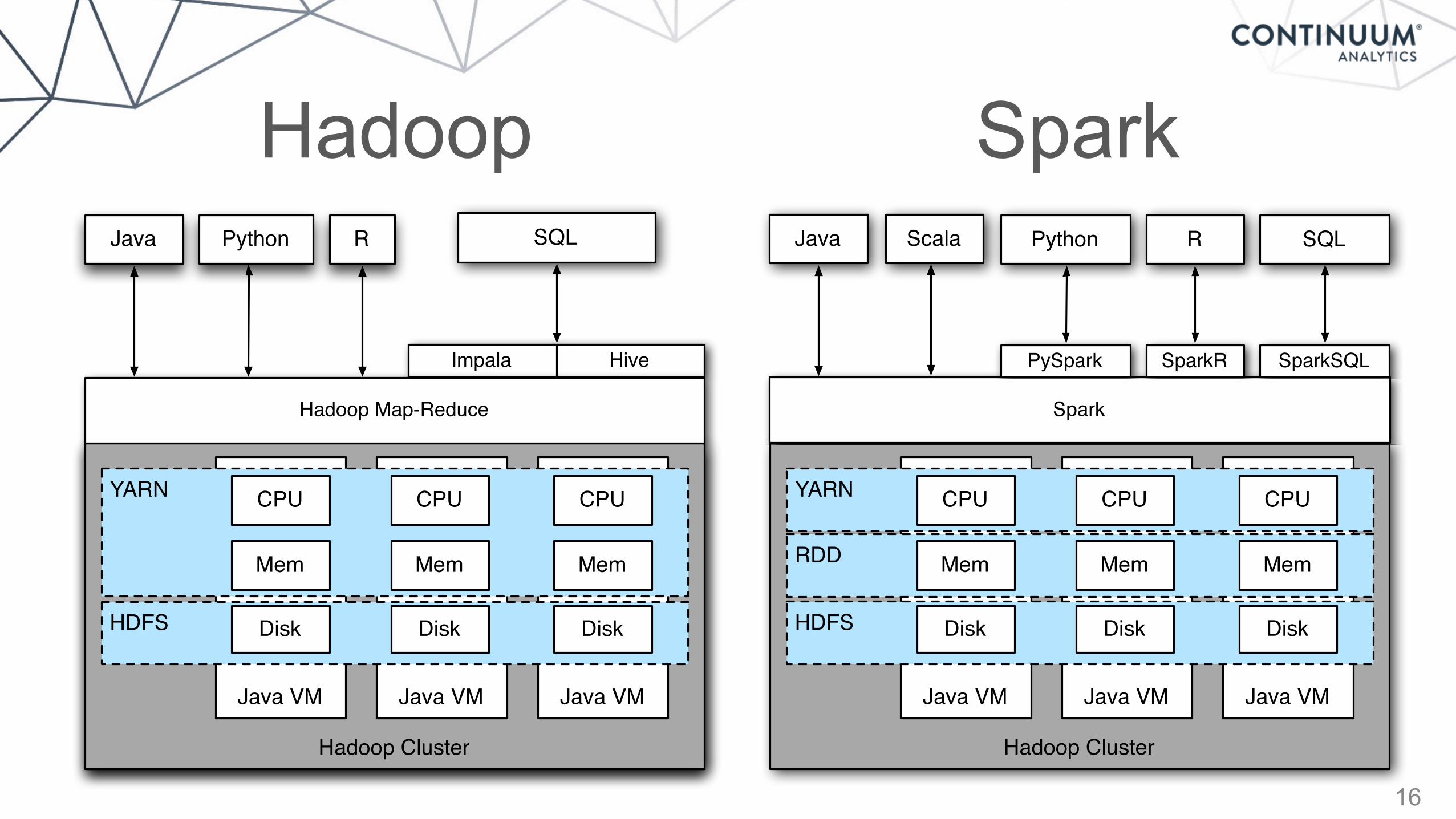
HiveImpala
SQL
Hadoop
16
Hadoop Cluster
Java VMJava VMJava VM
YARN
HDFS Disk Disk Disk
CPU
Mem
CPU
Mem
CPU
Mem
Hadoop Cluster
Java VMJava VMJava VM
YARN
HDFS Disk Disk Disk
CPU
Mem
CPU
Mem
CPU
Mem
Java Python R
Hadoop Map-Reduce
Hadoop Cluster
Java VMJava VMJava VM
RDD
YARN
HDFS Disk Disk Disk
CPUCPUCPU
MemMemMem
SparkJava
Spark
Scala Python R SQL
PySpark SparkR SparkSQL

Who’s Afraid of Distributed Computing?
17
• “What’s hard about distributed computing is not space, but time” • The difficulty of the problem scales with your temporal
exposure • The fewer nodes you have, the less complex distributed
computing is • So, optimizing per-node performance can be a lifesaver
• Additionally, the whole reason you use a distributed computer is because of performance. So, performance is an aspect of correctness.

Why Is Python Nice?
18
• Core data structures, with nice functions and spelling • Facilitate a wide variety of algorithms that interop • Open access to a huge variety of existing libraries and
algorithms • Very easy to get high performance when you need it…
• … on a single machine

Scaling Python
19
• Most Python data structures and supporting libraries (including C, C++, FORTRAN) were design for single-node use case
• “Automagically” scaling out single-node (“unified memory”) code to distributed machine is hard. • Making it robust is extremely hard to do w/ software. • “When software gets hard, we solve it with hardware”

Scalable Primitives
20
• What if…. We created a small set of distributed data structures for Python that have this property?
• Not everything from single-node case would work • But many things would • And spelling could at least be made congruent

ANACONDA + HADOOP
21
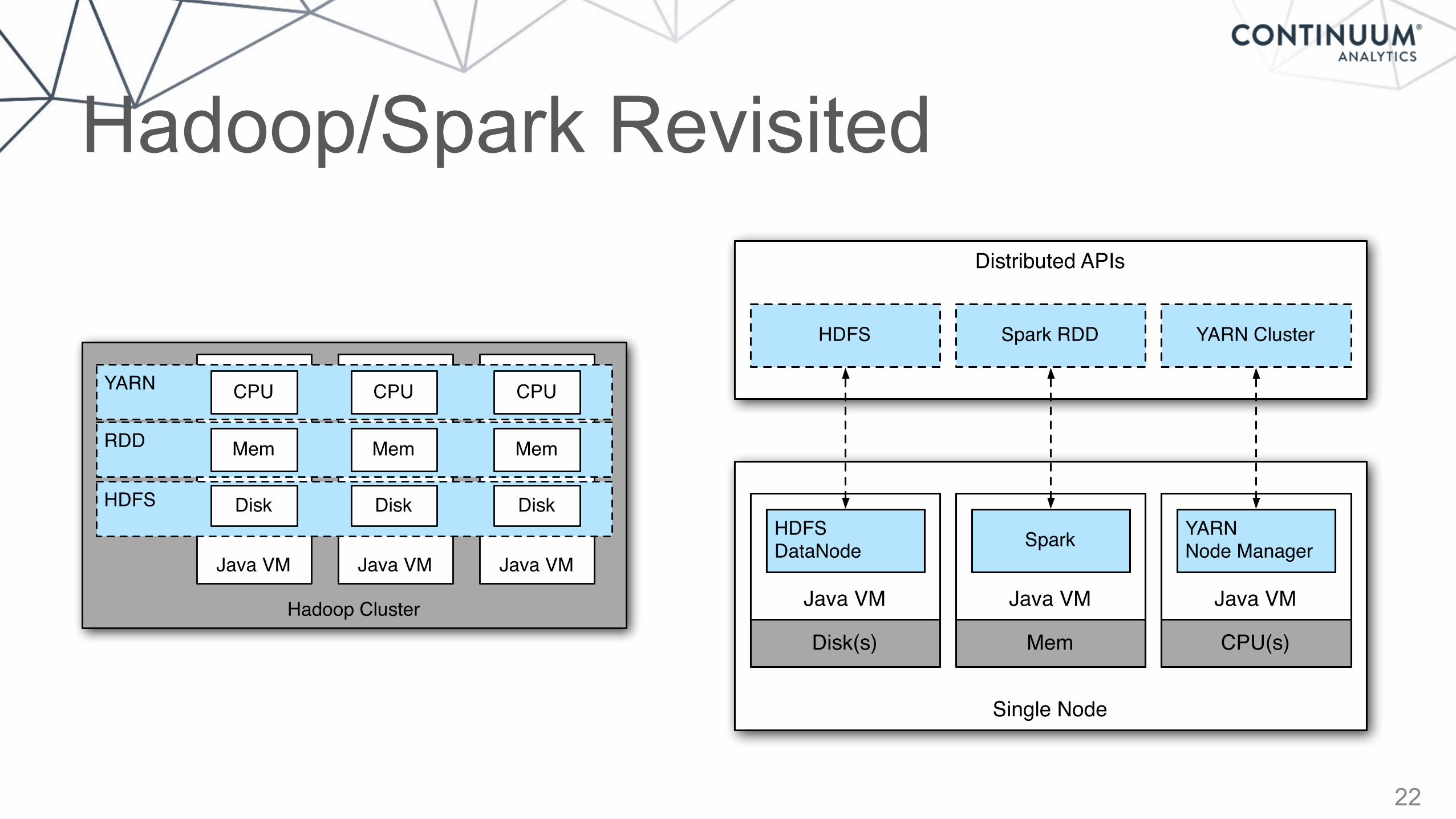
Hadoop/Spark Revisited
22
Hadoop Cluster
Java VMJava VMJava VM
RDD
YARN
HDFS Disk Disk Disk
CPUCPUCPU
MemMemMem
Single Node
CPU(s)Disk(s) Mem
Java VM
HDFSDataNode
Java VM
Spark
Java VM
YARNNode Manager
Distributed APIs
HDFS Spark RDD YARN Cluster
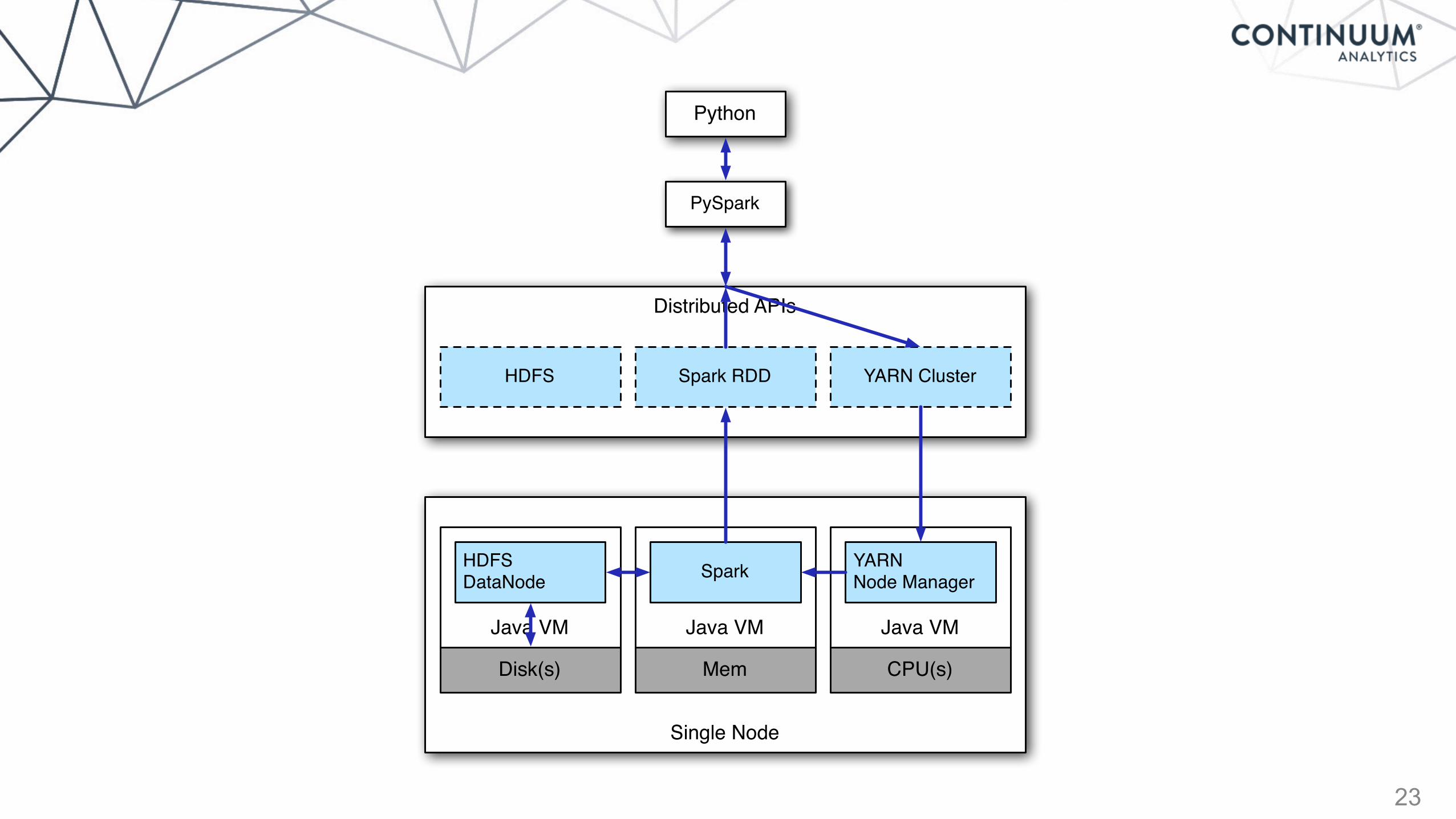
23
Single Node
CPU(s)Disk(s) Mem
Java VM
HDFSDataNode
Java VM
Spark
Java VM
YARNNode Manager
Distributed APIs
HDFS Spark RDD YARN Cluster
Python
PySpark
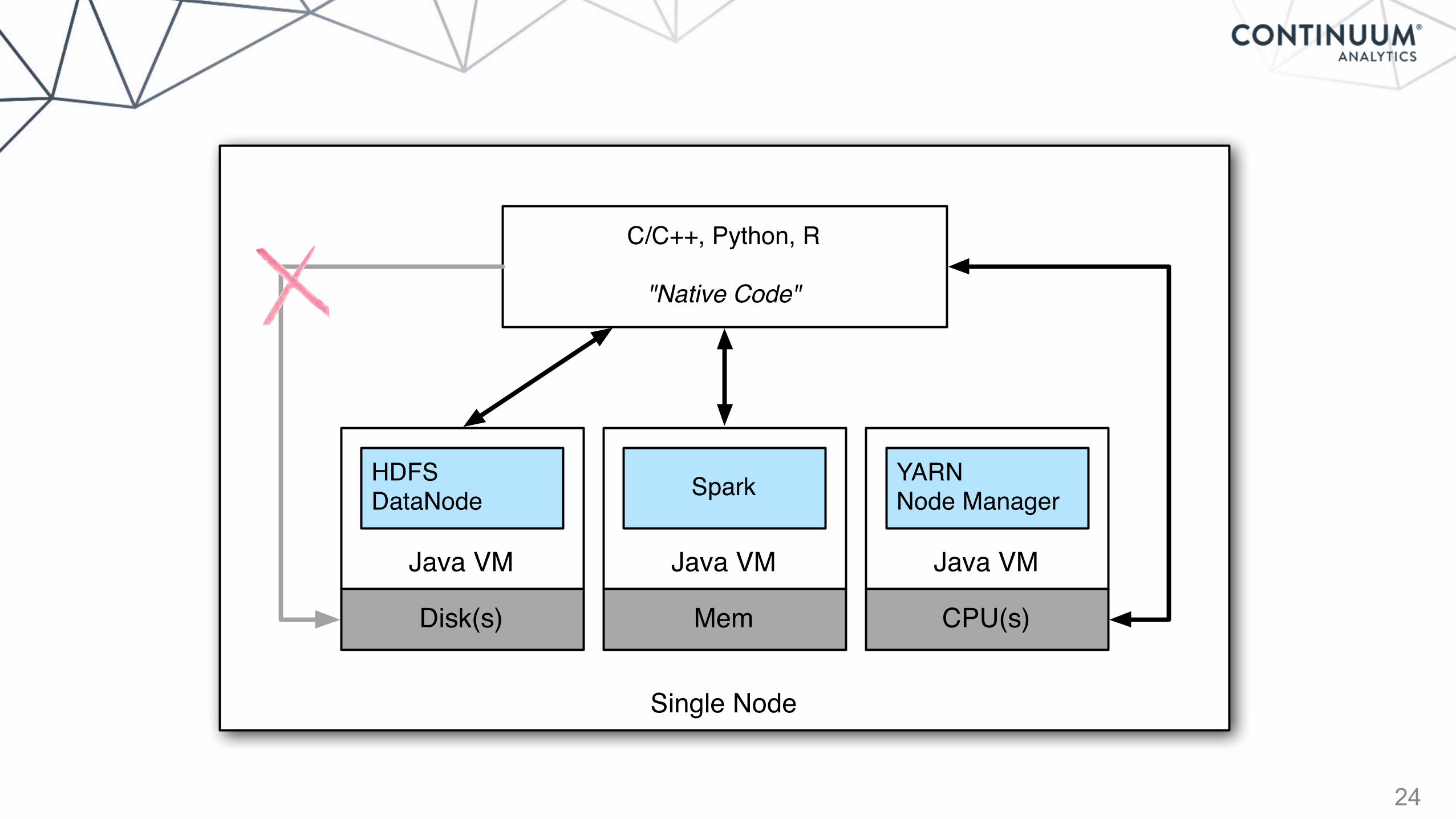
24
Single Node
CPU(s)Disk(s) Mem
Java VM
HDFSDataNode
Java VM
Spark
Java VM
YARNNode Manager
C/C++, Python, R
"Native Code"
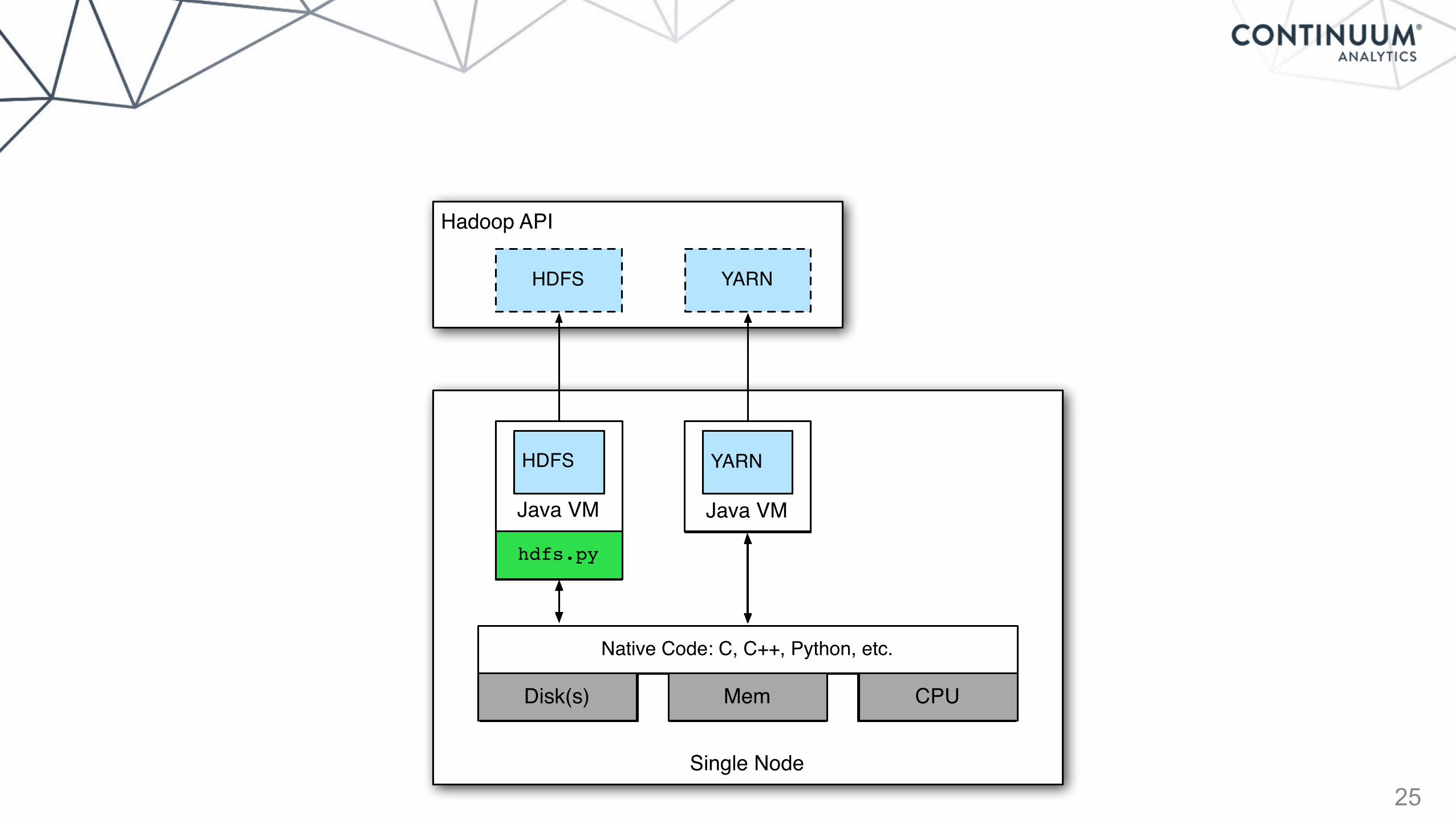
Hadoop API
Single Node
Disk(s)
Java VM
YARN
Native Code: C, C++, Python, etc.
Mem CPU
HDFS
hdfs.py
YARN
Java VM
HDFS
25
Disk(s)
Native Code: C, C++, Python, etc.
Mem CPU
hdfs.py
Java VM
HDFS
Java VM
YARN
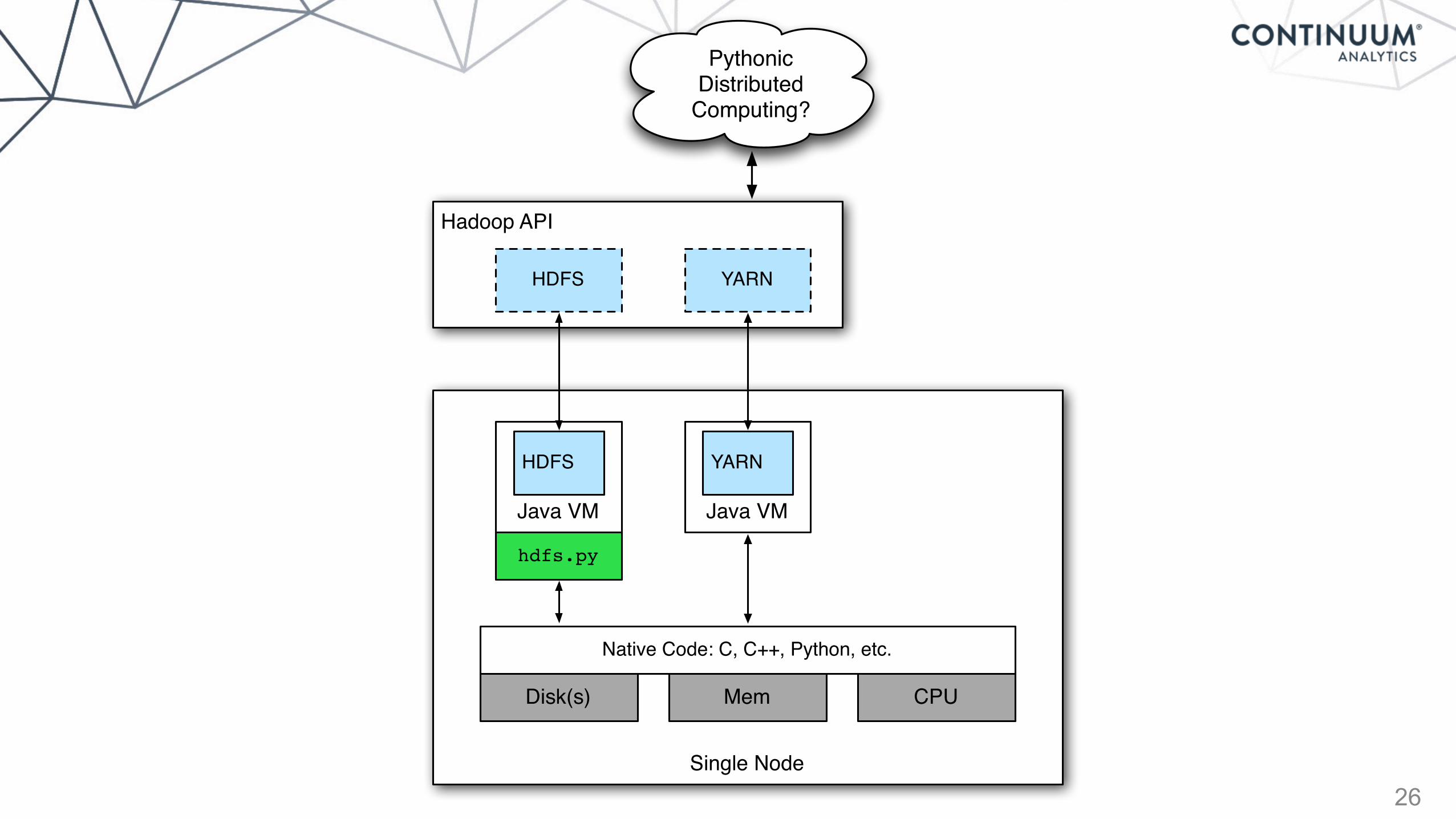
26
Hadoop API
Single Node
Disk(s)
Java VM
YARN
Native Code: C, C++, Python, etc.
Mem CPU
HDFS
hdfs.py
YARN
Java VM
HDFS
Pythonic Distributed
Computing?

27
Dask: Pythonic Parallelism• A parallel computing framework • That leverages the excellent Python ecosystem • Using blocked algorithms and task scheduling • Written in pure Python
Core Ideas • Dynamic task scheduling yields sane parallelism • Simple library to enable parallelism • Dask.array/dataframe to encapsulate the functionality
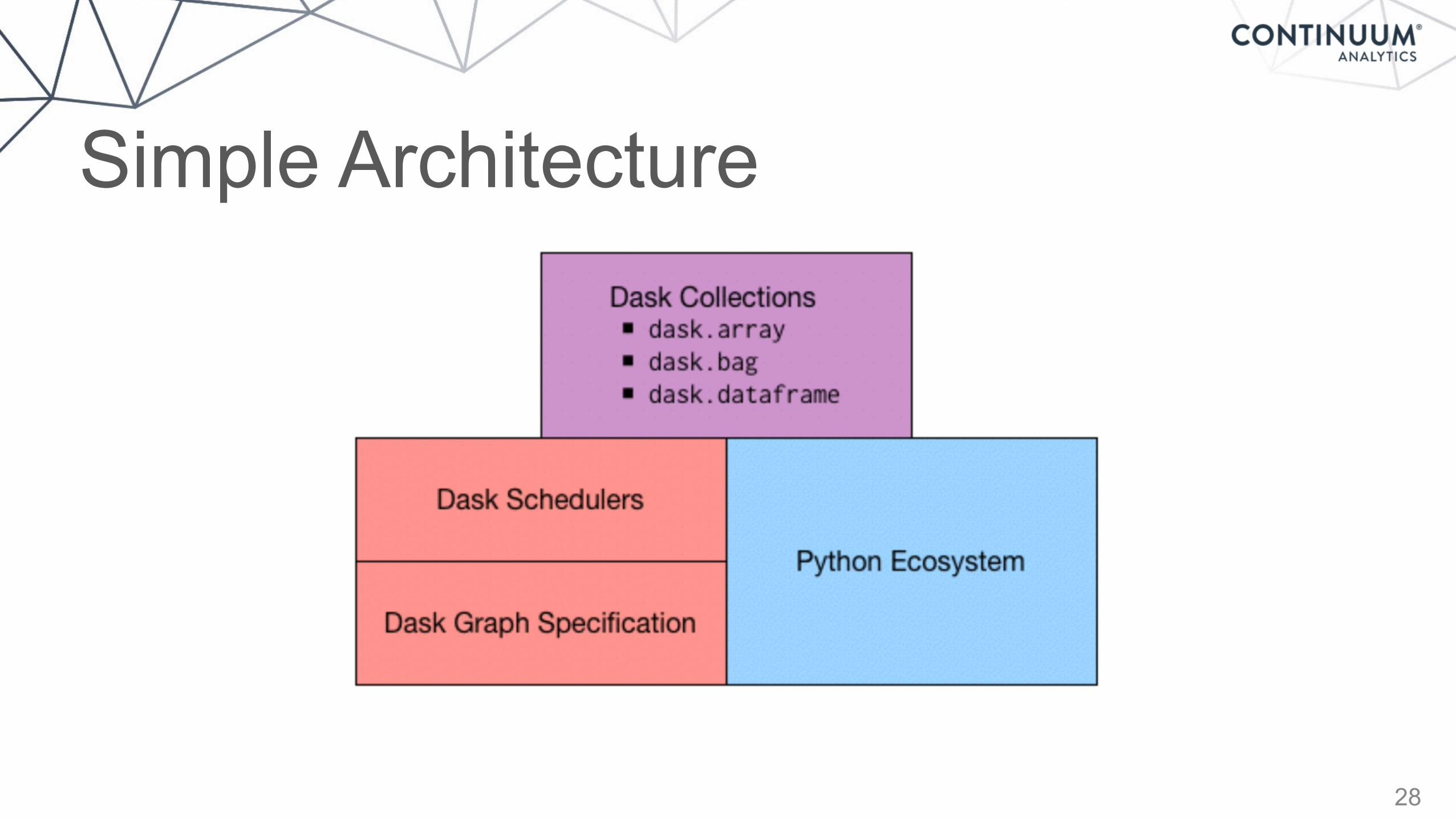
Simple Architecture
28
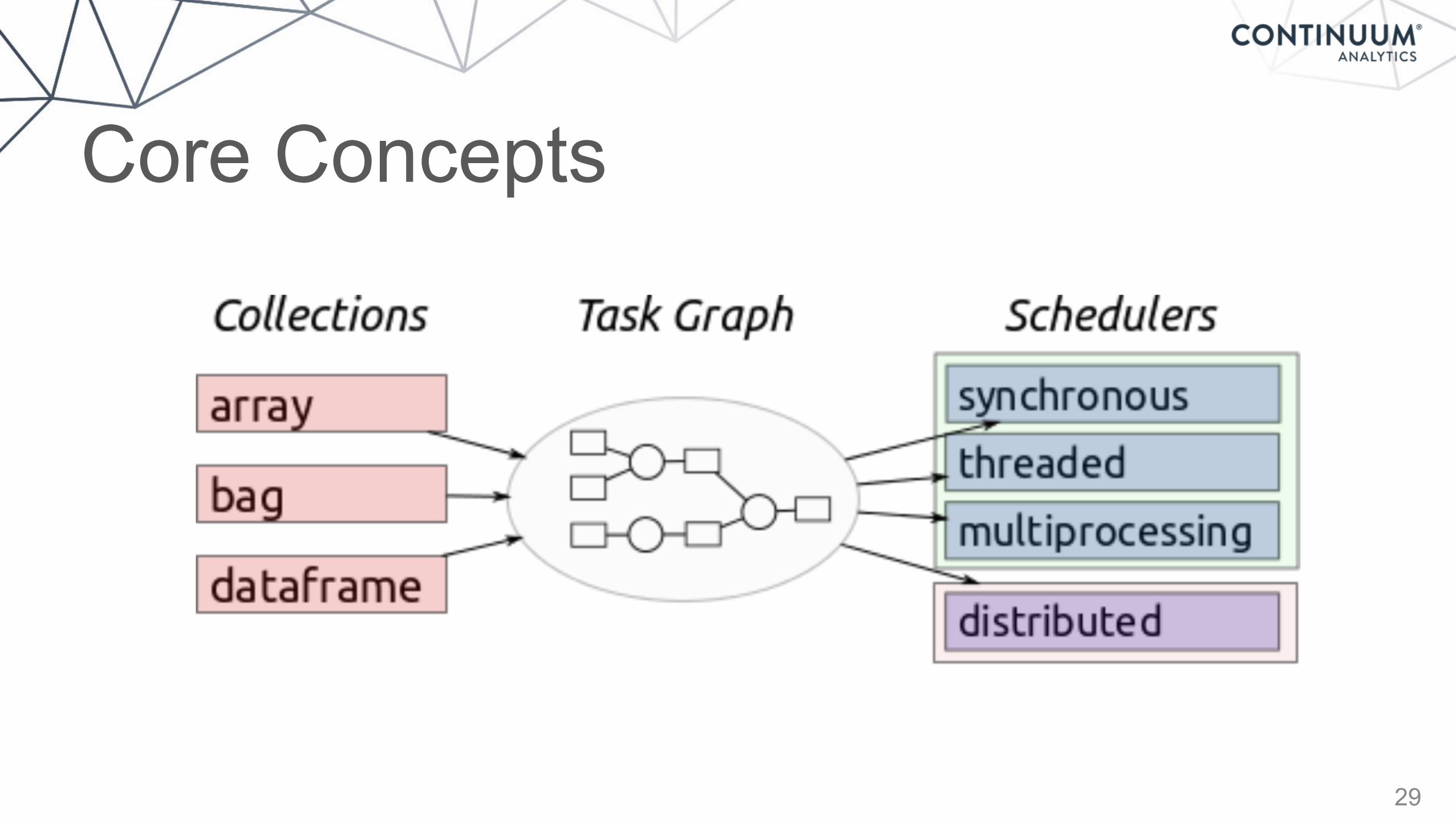
Core Concepts
29

dask.array: OOC, parallel, ND array
30
Arithmetic: +, *, ...
Reductions: mean, max, ...
Slicing: x[10:, 100:50:-2]Fancy indexing: x[:, [3, 1, 2]] Some linear algebra: tensordot, qr, svdParallel algorithms (approximate quantiles, topk, ...)
Slightly overlapping arrays
Integration with HDF5

dask.dataframe: OOC, parallel, ND array
31
Elementwise operations: df.x + df.yRow-wise selections: df[df.x > 0] Aggregations: df.x.max()groupby-aggregate: df.groupby(df.x).y.max() Value counts: df.x.value_counts()Drop duplicates: df.x.drop_duplicates()Join on index: dd.merge(df1, df2, left_index=True, right_index=True)
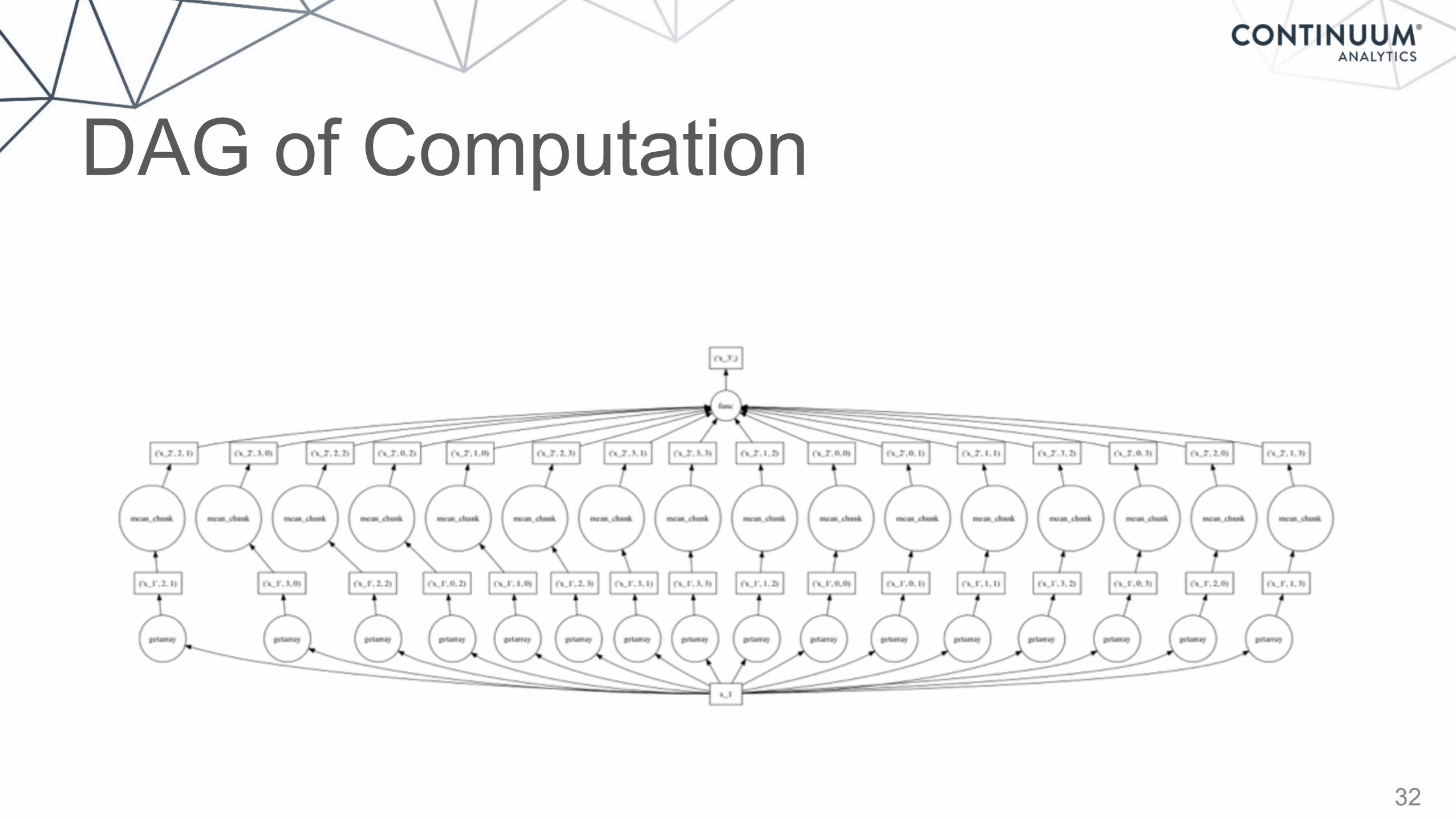
DAG of Computation
32

More Complex Graphs
34
cross validation

LU Decomposition
35
dA = da.from_array(A, (3, 3))dP, dL, dU = da.linalg.lu(dA)assert np.allclose(dL.compute(), L) assert np.allclose(dU.compute(), U)dL.visualize()
36
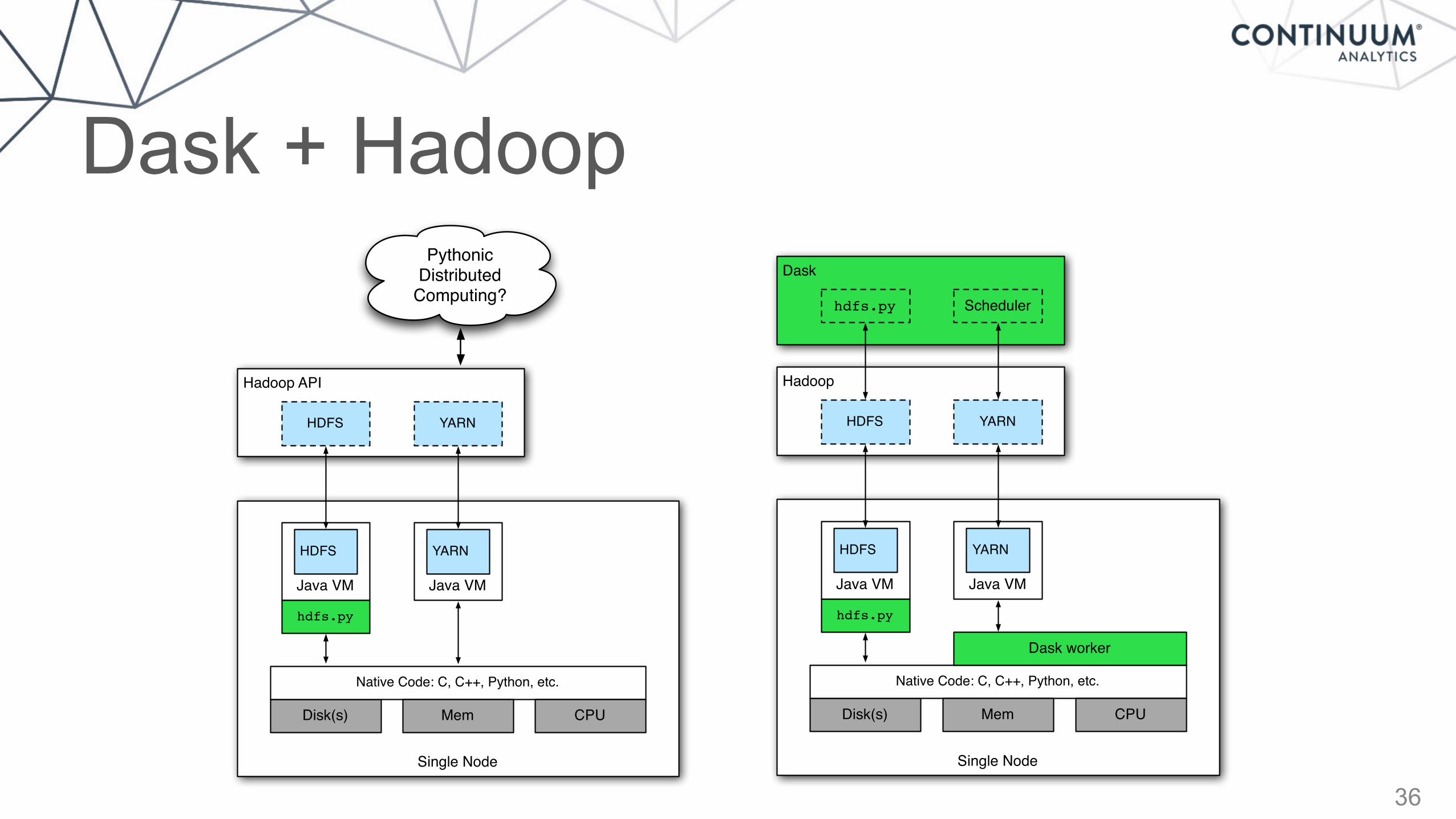
Dask + Hadoop
Hadoop API
Single Node
Disk(s)
Java VM
YARN
Native Code: C, C++, Python, etc.
Mem CPU
HDFS
hdfs.py
YARN
Java VM
HDFS
Pythonic Distributed
Computing?Dask
Hadoop
Single Node
Disk(s)
Java VM
YARN
Native Code: C, C++, Python, etc.
Mem CPU
HDFS
hdfs.py
YARN
Scheduler
Java VM
HDFS
Dask worker
hdfs.py

NYC Taxi Dataset
37http://matthewrocklin.com/blog/work/2016/02/22/dask-distributed-part-2
• Total 50 GB on disk, 120 GB in memory • Creates ~400 sharded Pandas dataframes (128MB each)
Familiar Programming Model
38
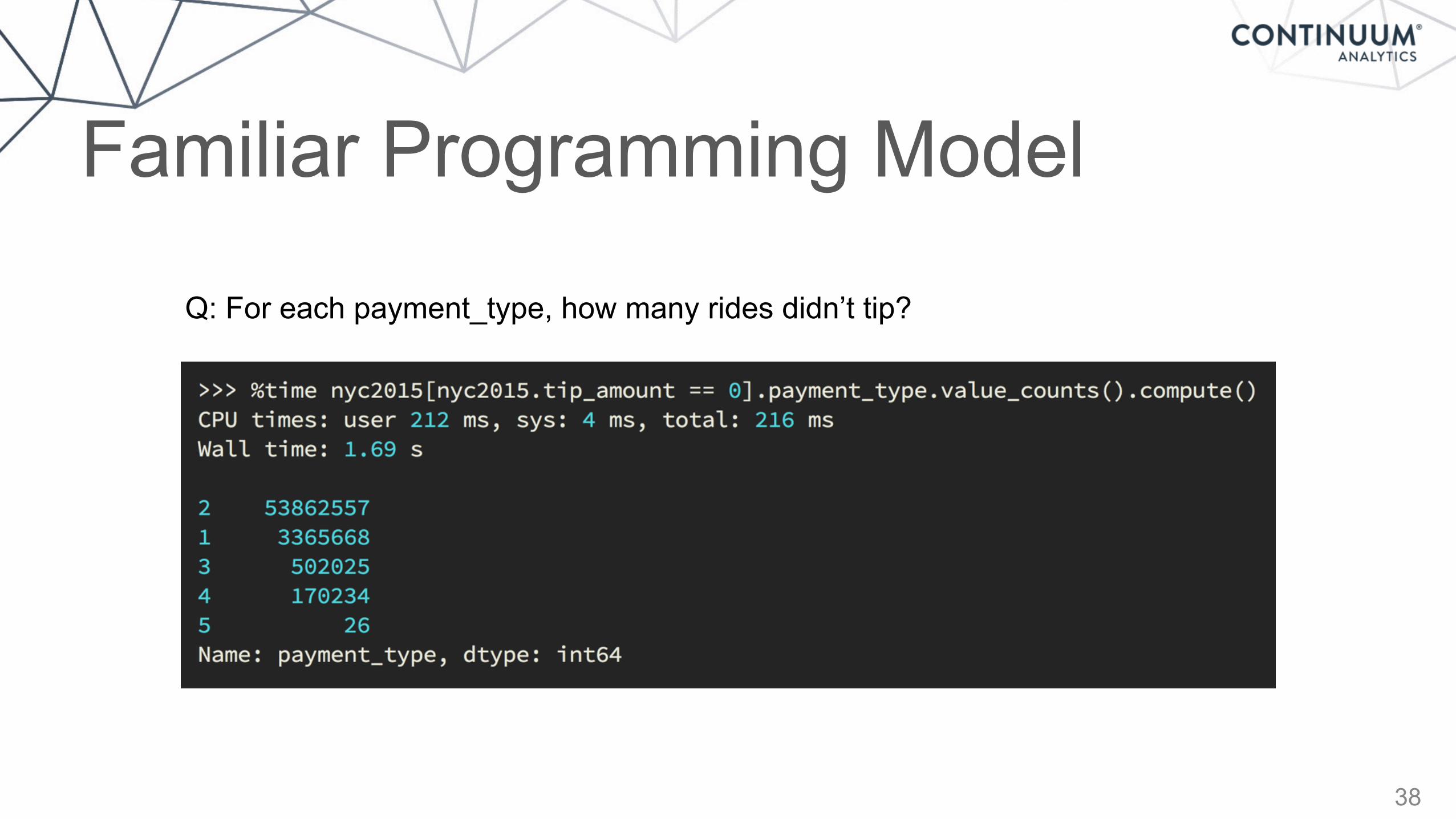
Q: For each payment_type, how many rides didn’t tip?
Familiar Programming Model
39
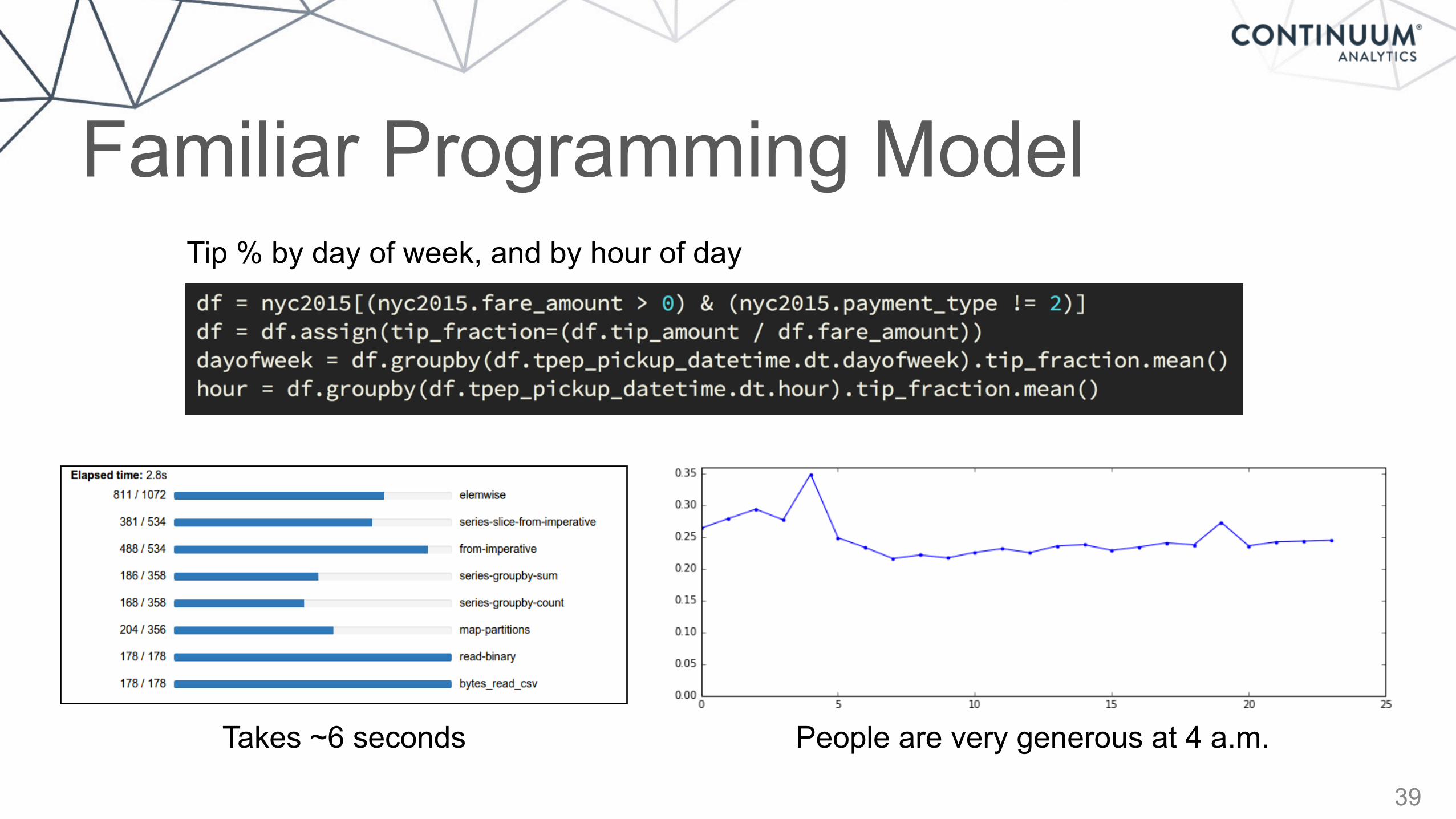
Takes ~6 seconds
Tip % by day of week, and by hour of day
People are very generous at 4 a.m.

Reddit Comments Dataset (240 GB)
40

Easy Text Processing with NLTK
41

42
• Pythonic spelling for parallel arrays and dataframes • Direct access to Hadoop data, without paying cost of
JVM serialization, via hdfs3 library • Excited about Cloudera’s Arrow project, which will
further improve direct data access • Load data into distributed memory via persist(), in
fast and data-local fashion • Direct scheduling with YARN via knit library
Take aways
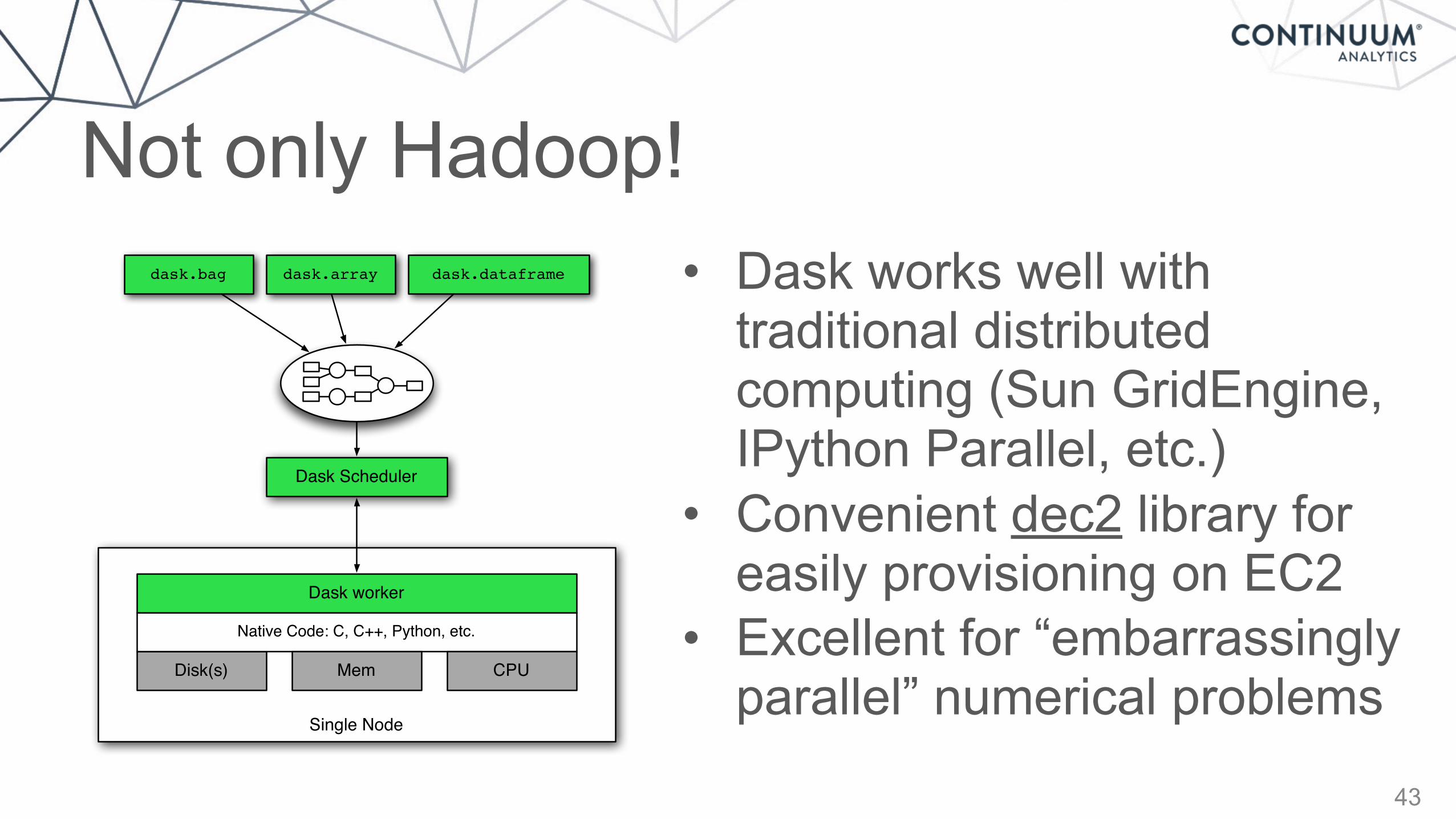
Not only Hadoop!
43
Dask Scheduler
Single Node
Disk(s)
Native Code: C, C++, Python, etc.
Mem CPU
Dask worker
dask.bag dask.array dask.dataframe • Dask works well with traditional distributed computing (Sun GridEngine, IPython Parallel, etc.)
• Convenient dec2 library for easily provisioning on EC2
• Excellent for “embarrassingly parallel” numerical problems
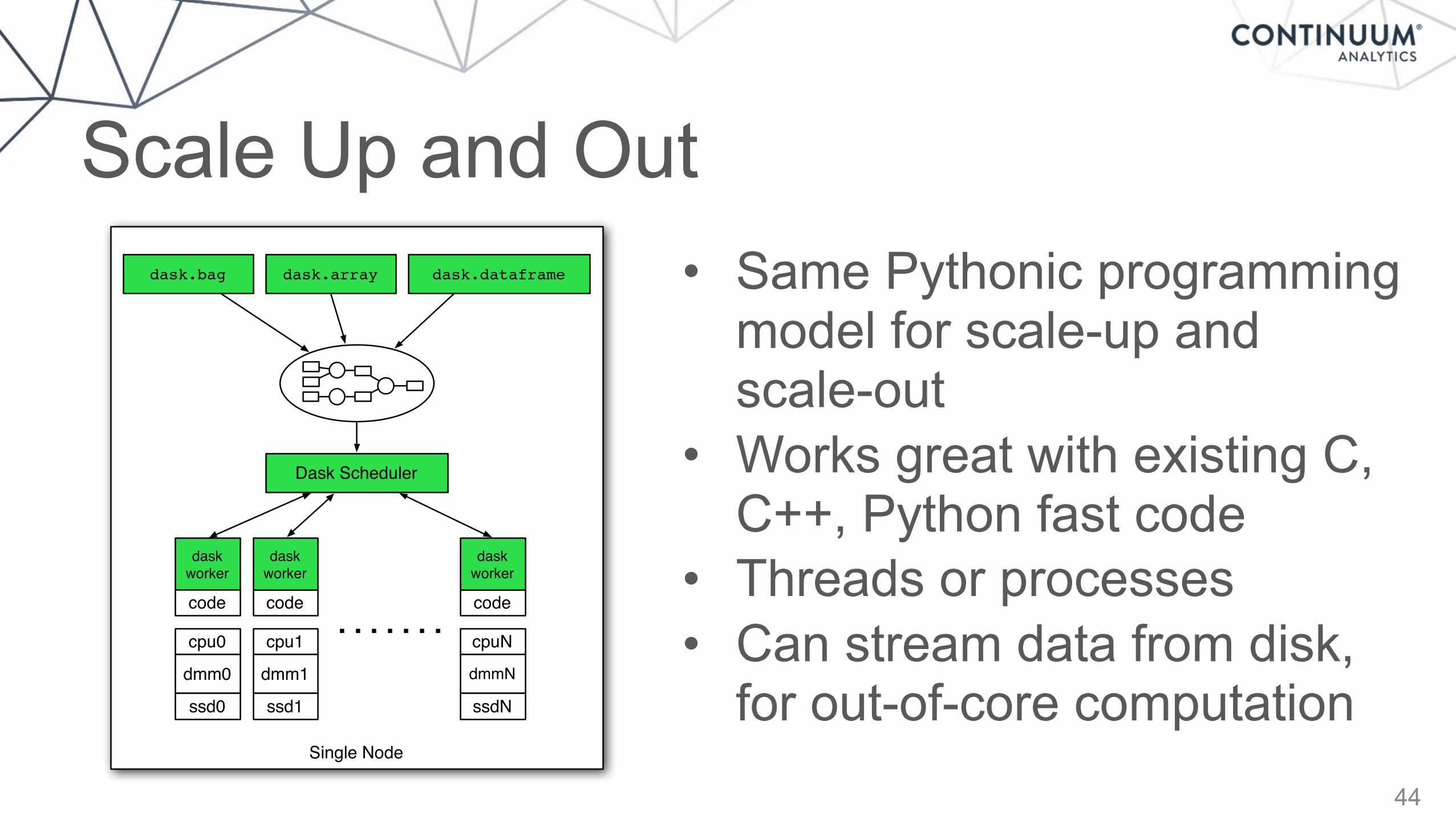
Scale Up and Out
44
• Same Pythonic programming model for scale-up and scale-out
• Works great with existing C, C++, Python fast code
• Threads or processes • Can stream data from disk,
for out-of-core computationSingle Node
Dask Scheduler
dask.bag dask.array dask.dataframe
cpu0
dmm0
ssd0
cpu1
dmm1
ssd1
cpuN
dmmN
ssdN
daskworker
code code code
daskworker
daskworker
. . . . . . .

ZEN OF PYDATA
45

Productivity at All Scales
46
• “Scaling out” is important for production and data processing • “Scaling down” and “Scaling up” is important for agile, fast
iterations in data exploration and modeling • Don’t compromise agility for the sake of future-proofing
scalability • Real wins in being able to use the same language and API
across scales

About Me
47
• Travis'Oliphant@teoliphantCEO/&/co2founder/Continuum/AnalyticsPh.D./Mayo/Clinic/ in/Biomedical/EngineeringB.S.,/M.S./BYU/Mathematics/&/Electrical/Eng./Open/Source/contributor/and/leader/since/1997
Creator/of/NumPy/and/SciPyStarted/Numba
Author/Guide&to&NumPy






























