Embed Size (px)
Citation preview

NEXT GENERATION DATA PLATFORMS!
Beyond the traditional view


What is Big Data ?
A new generation of technologies and architectures designed to economically extract value from very large volumes of a wide variety of data, by enabling high velocity capture,
discovery and/or analysis.
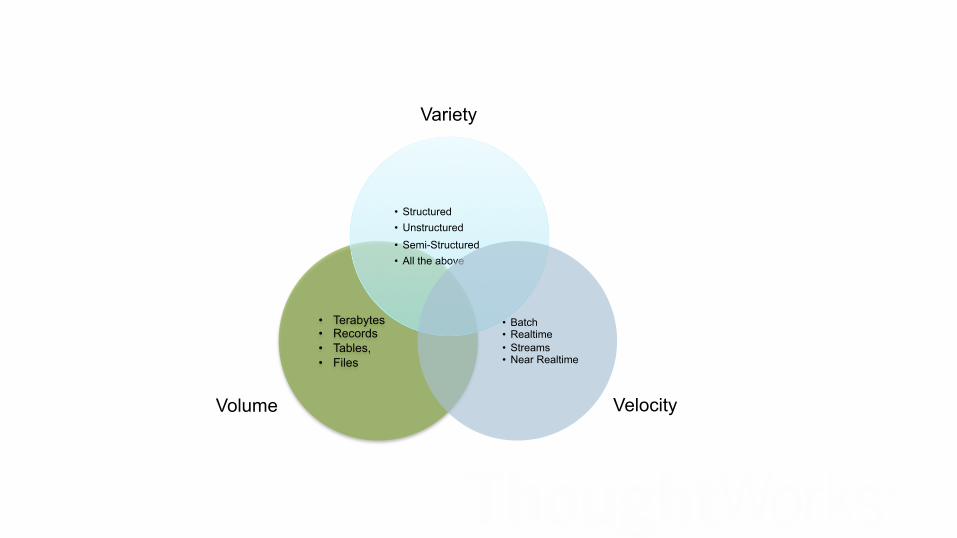
• Terabytes • Records • Tables, • Files
• Structured • Unstructured • Semi-Structured • All the above
• Batch • Realtime • Streams • Near Realtime
Velocity
Variety
Volume
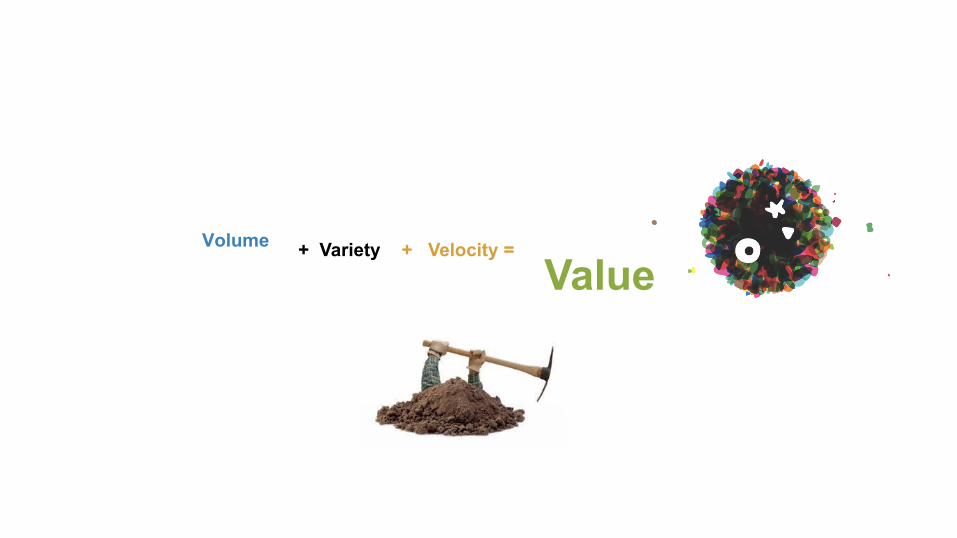
Volume! + Velocity =
Value
+ Variety

Beyond the traditional view

1. Variety!
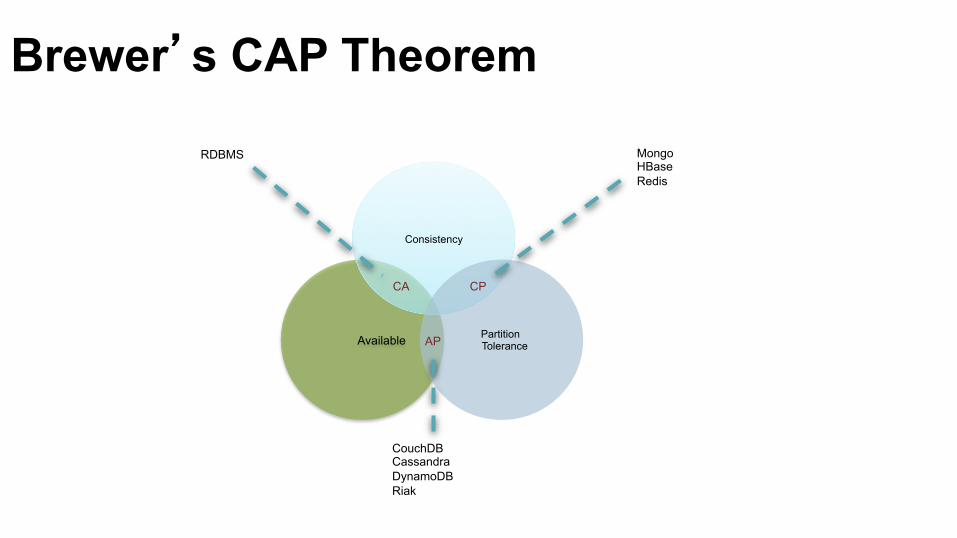
Available
Consistency
Partition Tolerance
Mongo HBase Redis
CP
RDBMS
CA
AP
CouchDB Cassandra DynamoDB Riak
Brewer’s CAP Theorem
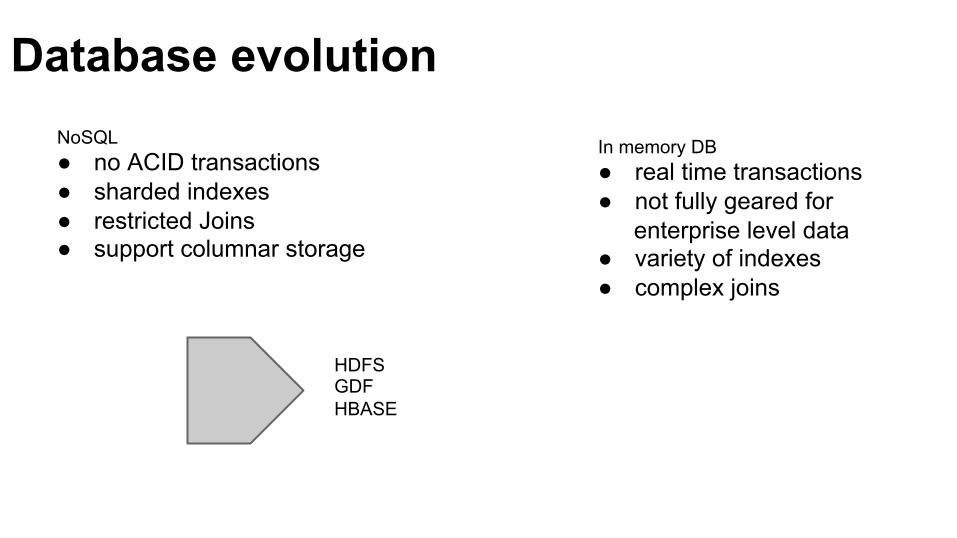
NoSQL ● no ACID transactions ● sharded indexes ● restricted Joins ● support columnar storage!
In memory DB ● real time transactions ● not fully geared for
enterprise level data ● variety of indexes ● complex joins
HDFS GDF HBASE
Database evolution
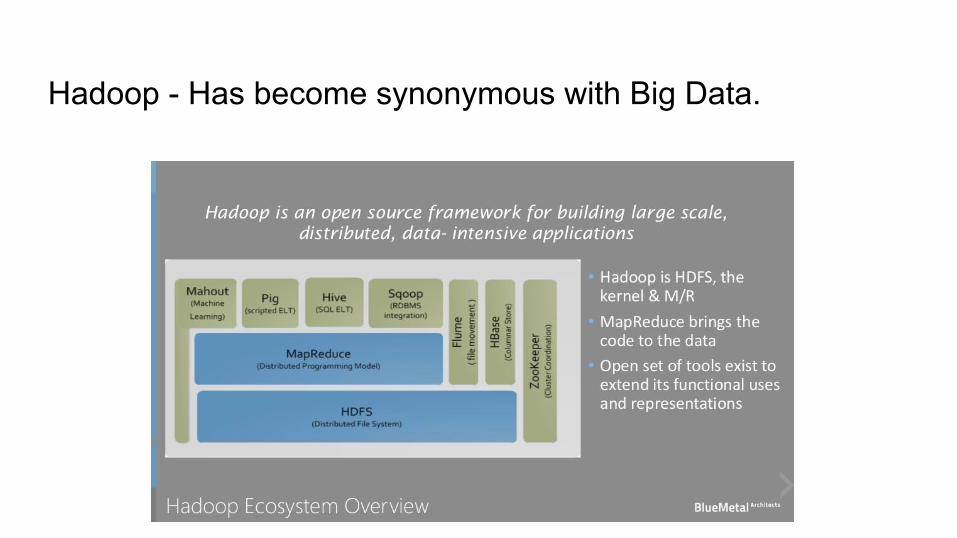
Hadoop - Has become synonymous with Big Data.!
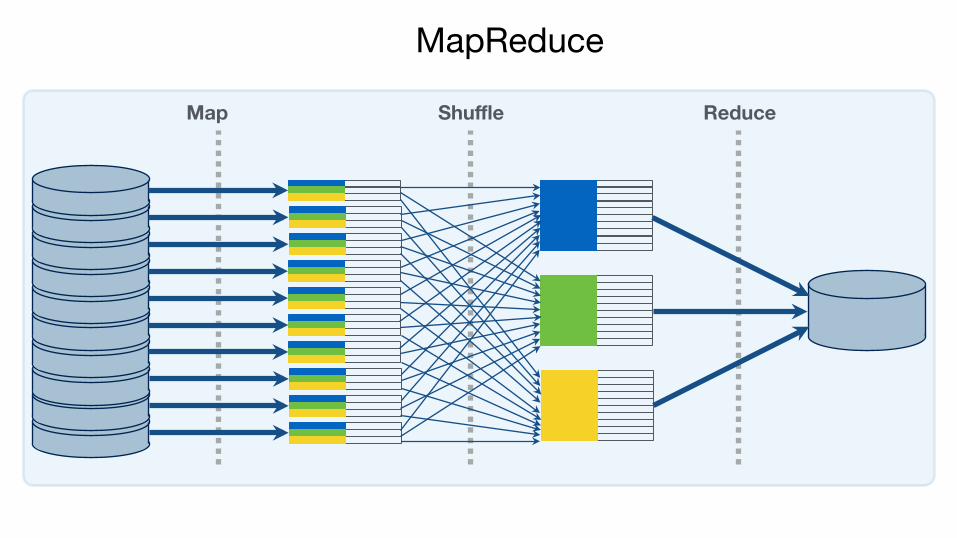
MapReduce!
Map Shuffle Reduce

2. Velocity!
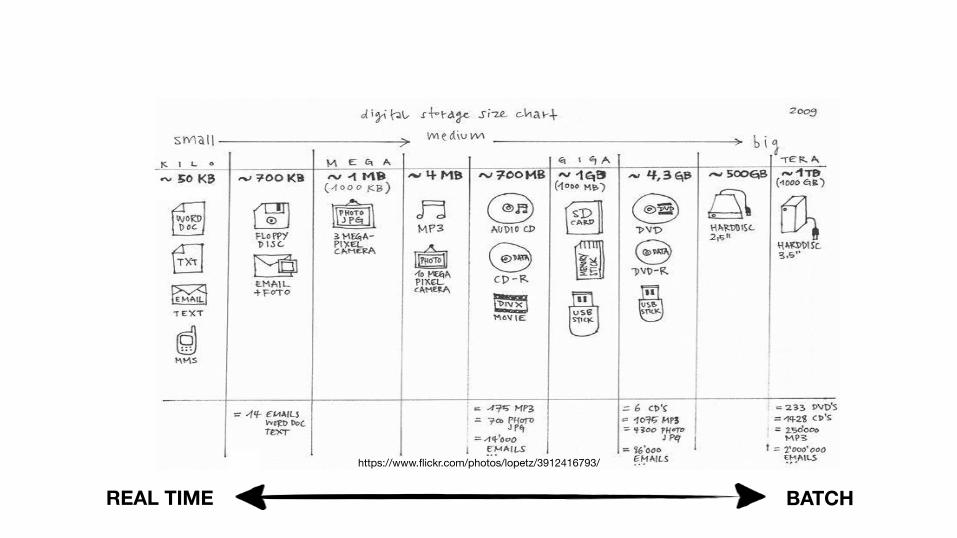
https://www.flickr.com/photos/lopetz/3912416793/
REAL TIME BATCH
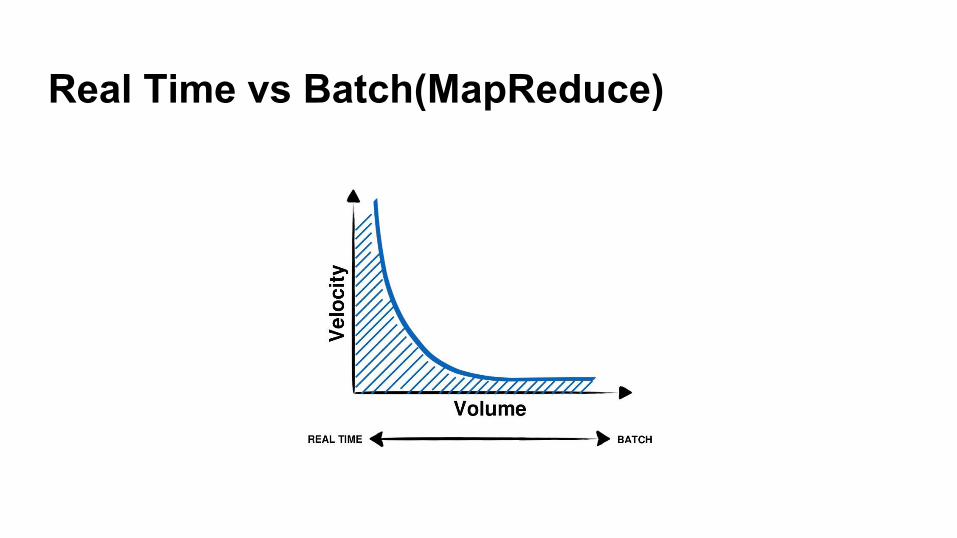
Real Time vs Batch(MapReduce)!
15
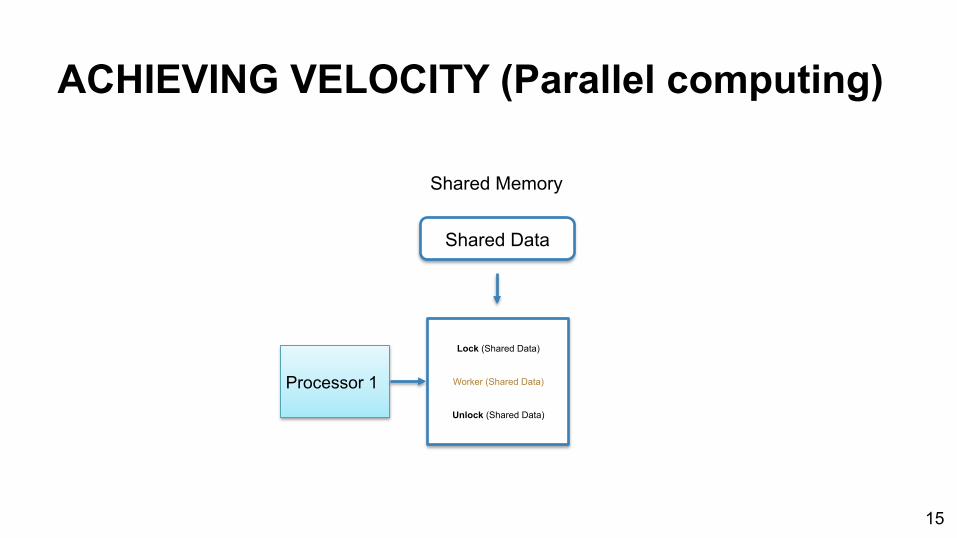
ACHIEVING VELOCITY (Parallel computing)
Shared Memory
Processor 1
Shared Data
Lock (Shared Data)
Worker (Shared Data)
Unlock (Shared Data)
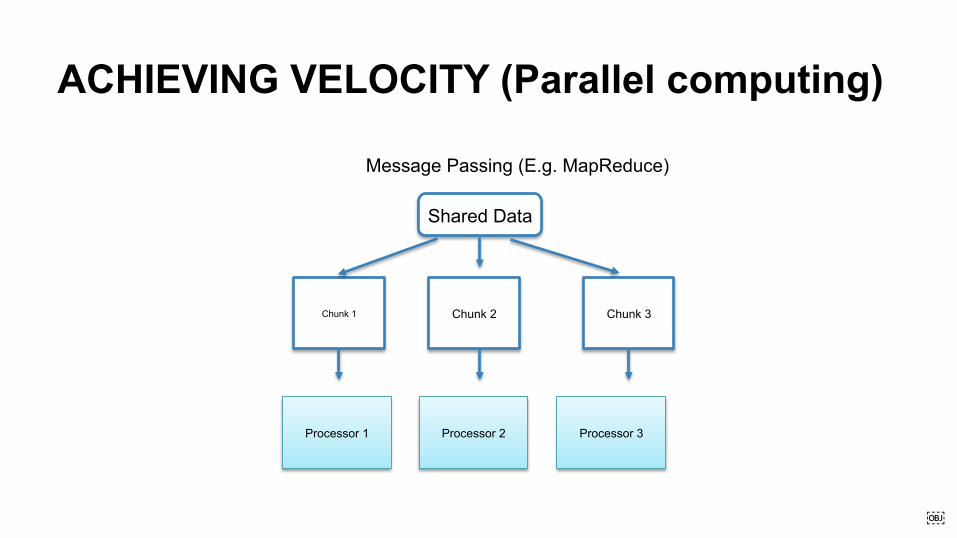

ACHIEVING VELOCITY (Parallel computing)
Shared Data
Chunk 1 Chunk 2 Chunk 3
Message Passing (E.g. MapReduce)
Processor 1 Processor 2 Processor 3

3. Volume!


4. Value!

Analytics

Pull-based Batch Loads
Enterprise Data Models
Complex ETL Logic
Poorly Suited to
Non-Relational Data
Emergent design is difficult
Conventional Architectures!

OLAP (Online Analytical processing)
SELECT SUM(s.dollar_cost), s.product_key, p.description FROM SALES_FACT s
… … …
GROUP BY s.product_key, p.description

Why Databases!
● Transaction processing (ACID properties) ● SQL - Indexes and queries OLAP ● Transaction processing not needed for analytics
o Moving of data via ETL ● Large volumes of data, indexes become irrelevant ● Schema or Write vs Schema Read!

Analytics is not just SQL queries

There is more to analytics than you think!

Do we lose hope, how do we move forward!

1. Variety - How to we deal with different kinds of data ?
2. Volume - How to we cope with large volume of data?
3. Velocity - How do we solve realtime problems?
4. Value - What is our value ?!
Summary!

Lambda Architecture!
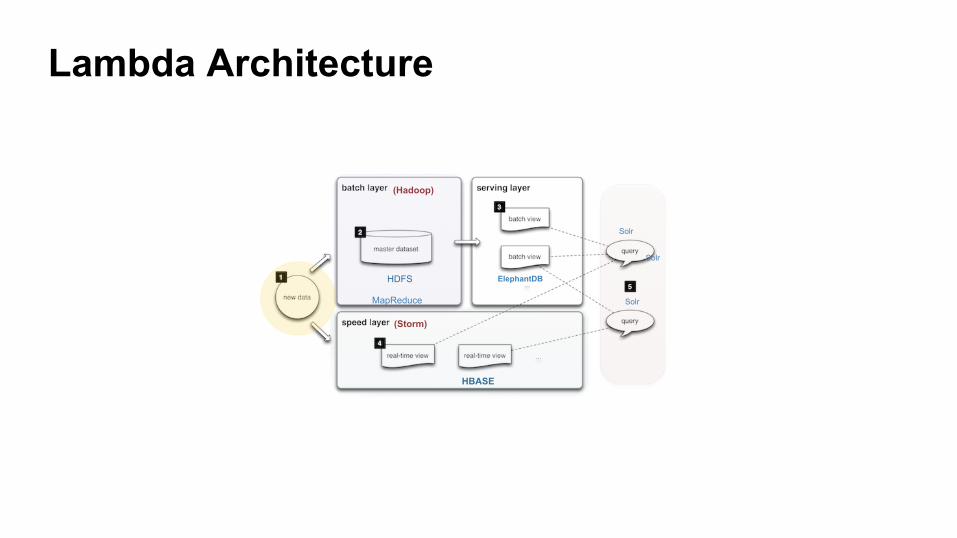
Lambda Architecture!
HDFS
(Hadoop)
MapReduce
HBASE
(Storm)
ElephantDB
Solr
Solr
Solr

Real time processing + Batch since 1983!

Should i adopt or should i not!


“Change before you have to”
Jack Welch
Questions
thoughtworks.com
@DuffleDoe
http://deonthomas.blogspot.com
we’re hiring ...




























