Embed Size (px)
Citation preview

Neural Network
Hanna Gábor & Dániel DarabosLynx Analytics
Huge GraphThat Learns From a

Who is Lynx Analytics?
Big data analytics with a focus on graph data.
Our core product is a graph-oriented analytics application called LynxKite.
• Web UI for fluid exploration workflow with rapid visualization.• API and automation for autonomous operation.• Implemented with Apache Spark.• Machine learning toolbox.
Telecommunications Financial Services Smart City Transport
START the challenge the prior solutions the novel solution END

Problem statement
A single giant graph, such as relations in a social graph.
A partially populated vertex attribute, such as age.
Predict the missing attribute values!
START the challenge the prior solutions the novel solution END

Old approach I: Machine Learning
Prediction? Use machine learning! Vertex attributes ⇒ label.
How does it perform?
Entirely ignores edges.25%accuracy
START the challenge the prior solutions the novel solution END

Anonymized friendship data from now-defunct social network.
• Filtered to single city for faster experimentation• 27,783 profiles• 1,095,707 friendships
Age & gender attributes
Experiment setup
START the challenge the prior solutions the novel solution END
The challenge: Multi-class classification by age
• Age is bucketed into quartiles.
• Model is trained on training data (85%).
• Accuracy is evaluated on test data (15%).
• Accuracy =
• Final number is the median accuracy from 11 trials.
Experiment setup
correct predictionstest set size
START the challenge the prior solutions the novel solution END

Old approach II: ML with graph metrics
To present the graph structure to the ML algorithm calculate every graph metric we can think of! Degree, PageRank, clustering coefficient, harmonic centrality, graph coloring... (Easy with LynxKite.)
How does it perform?
Expert has to find metrics that are good predictors.Network neighborhood still largely ignored.
32%accuracy
START the challenge the prior solutions the novel solution END

Old approach III: Neighborhood
Take average value of neighbors.
How does it perform?
Not adaptive. (Average not best option in all cases.)70%accuracy
START the challenge the prior solutions the novel solution END

How does it perform?
Expert has to pick good way to identify communities.Not adaptive. (Why average? Why most homogeneous?)
73%accuracy
Old approach IV: Communities
Find communities. (E.g. connected components in overlapping maximal cliques.)
Take average value from most homogeneous community that meets minimal criteria.
START the challenge the prior solutions the novel solution END

Old approach V: ML with neighborhood data
In addition to metrics, provide the machine learning with the neighborhood average.
How does it perform?
Expert has to manufacture features for ML.Not perfectly adaptive. (Why average?)
75%accuracy
START the challenge the prior solutions the novel solution END
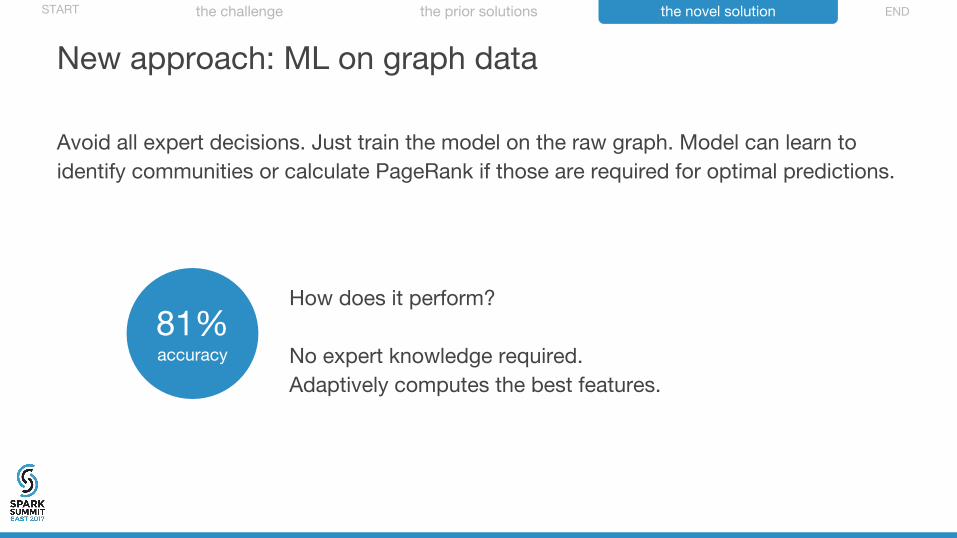
New approach: ML on graph data
Avoid all expert decisions. Just train the model on the raw graph. Model can learn to identify communities or calculate PageRank if those are required for optimal predictions.
How does it perform?
No expert knowledge required.Adaptively computes the best features.
81%accuracy
START the challenge the prior solutions the novel solution END

Strong recent results with deep learning on graphs with graph convolutional networks.
Yujia Li, Daniel Tarlow, Marc Brockschmidt, Richard Zemel (2016).Gated Graph Sequence Neural Networks. arXiv:1511.05493 [cs.LG]
A recurrent neural network (GRU) in every vertex with shared parameters. State is communicated along edges.
Trained on many small labeled graphs. Gives prediction on small unlabeled graph.
Model
START the challenge the prior solutions the novel solution END
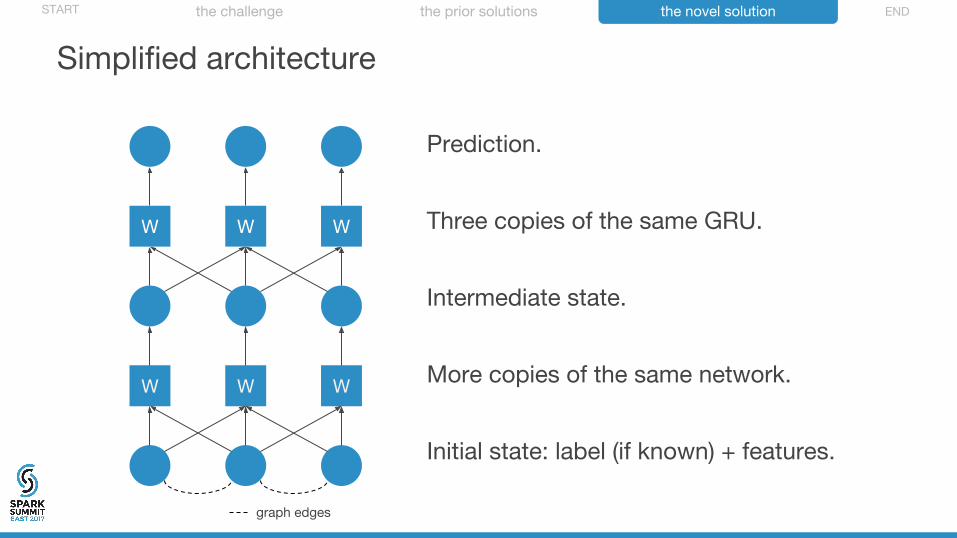
WW W
WW W
Prediction.
Three copies of the same GRU.
Intermediate state.
More copies of the same network.
Initial state: label (if known) + features.
graph edges
Simplified architecture
START the challenge the prior solutions the novel solution END
• Hard to apply supervised learning when we have a single graph.
• Hard to do anything when this graph does not fit on a single machine.
Problems
START the challenge the prior solutions the novel solution END

Solution:• Show some of the known labels.• Backpropagate error only from the vertices where the label was hidden.• Hide different labels in each iteration.
Network sees none of the known labels. Model ignores existing labels.
Network sees all the known labels. Model learns to just return own label.
Supervised learning on a single graph
START the challenge the prior solutions the novel solution END

• Pick representative subgraphs.
• Train in parallel locally on subgraphs. Periodically combine adjustments.
• Prediction on the whole graph is fully distributed.
• Accuracy impact depends on amount of computational resources. Great for scaling.
Distributed training and prediction
START the challenge the prior solutions the novel solution END

Closed-source. Sorry.
Evaluating classical methods and preparing data: LynxKite on Spark
Researching and prototyping neural networks: TensorFlow
Distributed forward pass: LynxKite on Spark
Distributed training:in development
LynxKite on Spark + TensorFlow (TensorFrames?)
Implementation
START the challenge the prior solutions the novel solution END

@LynxAnalytics @Hanna_Gabor @DanielDarabos
You can find us at booth K2. Swing by to see if we have any swag left!
Special thanks to Gabor Olah, Andras Nemeth,and many others at Lynx for their contributions.





























