Embed Size (px)
Citation preview

Where Search Meets Machine Learning Diana Hu @sdianahu — Data Science Lead, Verizon
Joaquin Delgado @joaquind — Director of Engineering, Verizon

Disclaimer
2
The content of this presentation are of the authors’ personal statements and does not officially represent their employer’s view in anyway. Included content is especially not intended to convey the views of OnCue or Verizon
01

Index
1. Introduction 2. Search and Information Retrieval 3. ML problems as Search-based Systems 4. ML Meets Search!

Introduction

Scaling learning systems is hard!
• Millions of users, items
• Billions of features
• Imbalanced Datasets
• Complex Distributed Systems
• Many algorithms have not been tested at “Internet Scale”

Typical approaches
• Distributed systems – Fault tolerance, Throughput vs. latency
• Parallelization Strategies – Hashing, trees
• Processing – Map reduce variants, MPI, graph parallel
• Databases – Key/Value Stores, NoSQL
Such a custom system requires TLC

Search and Information Retrieval
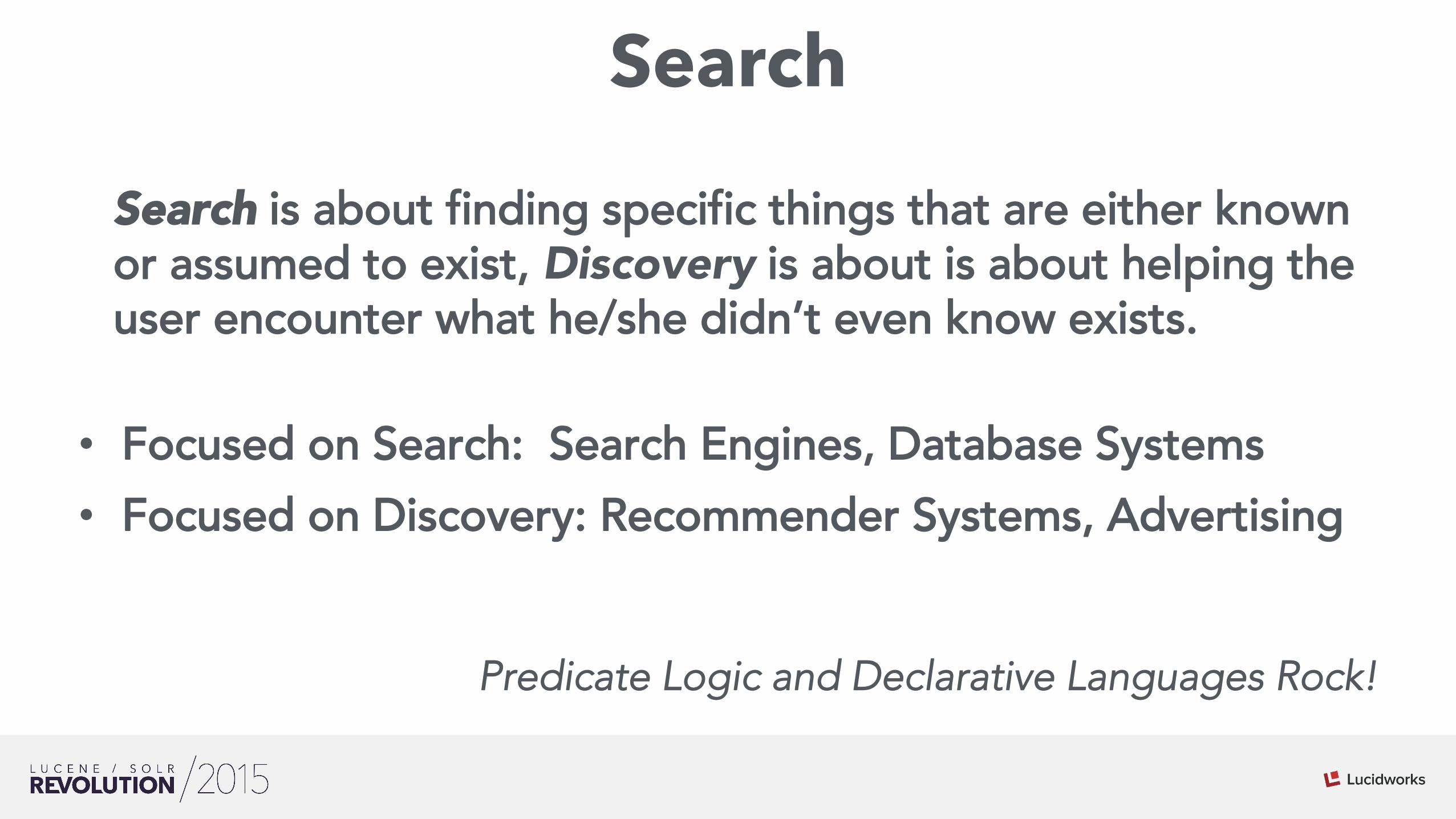
Search
Search is about finding specific things that are either known or assumed to exist, Discovery is about is about helping the user encounter what he/she didn’t even know exists.
• Focused on Search: Search Engines, Database Systems • Focused on Discovery: Recommender Systems, Advertising
Predicate Logic and Declarative Languages Rock!
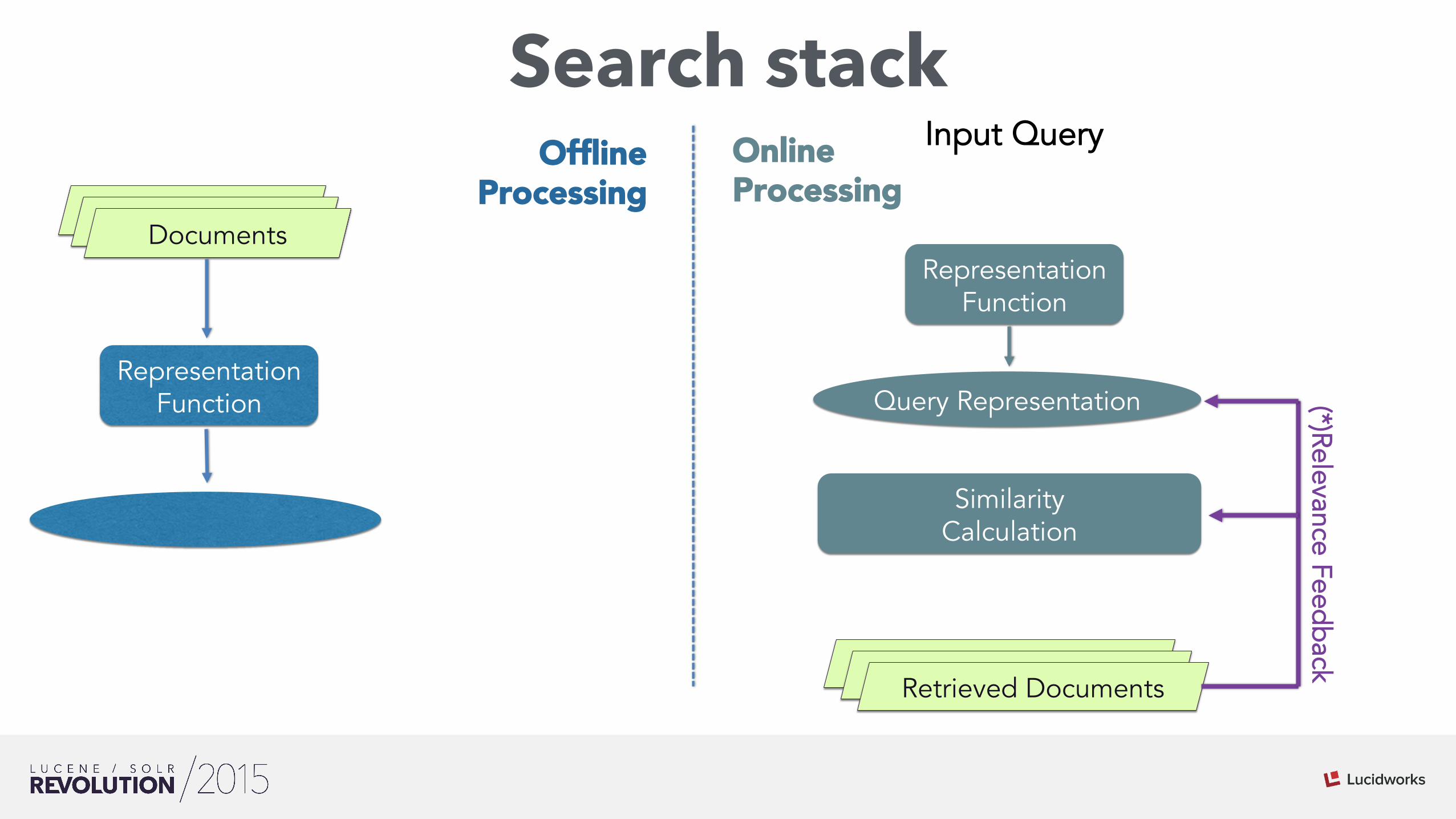
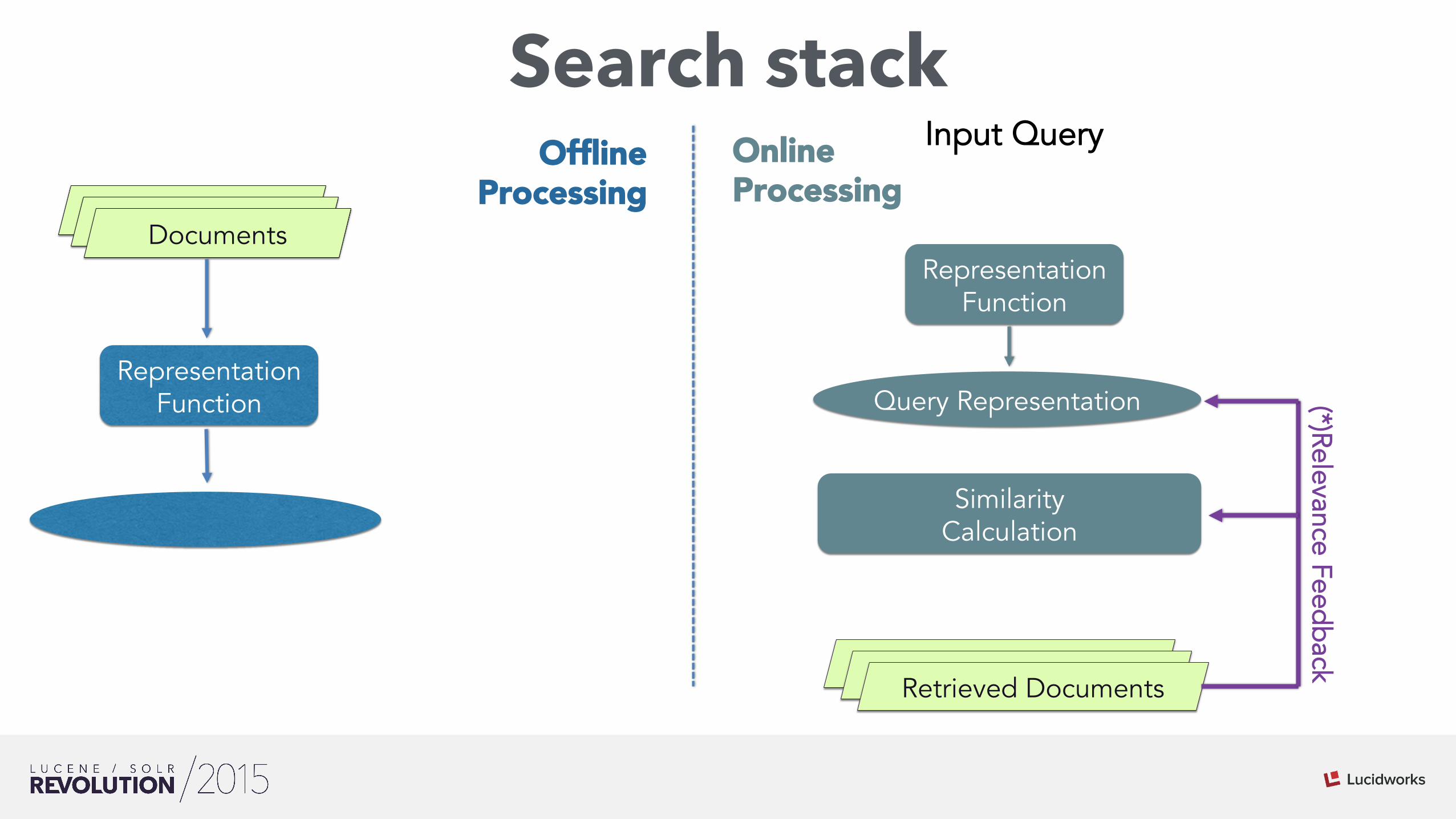
Search stack
Matched Hits
Representation Function
Similarity Calculation
Matched Hits Documents
Representation Function
Input Query
Matched Hits Matched Hits Retrieved Documents
Online Processing
Offline Processing
(*)Relevance Feedback
Query Representation
Doc Representation Index
*Metadata Engineering
(*) Optional

Relevance: Vector Space Model

Search Engines: the big hammer
• Search engines are largely used to solve non-IR search problems, because: • Widely Available
• Fast and Scalable
• Integrates well with existing data stores
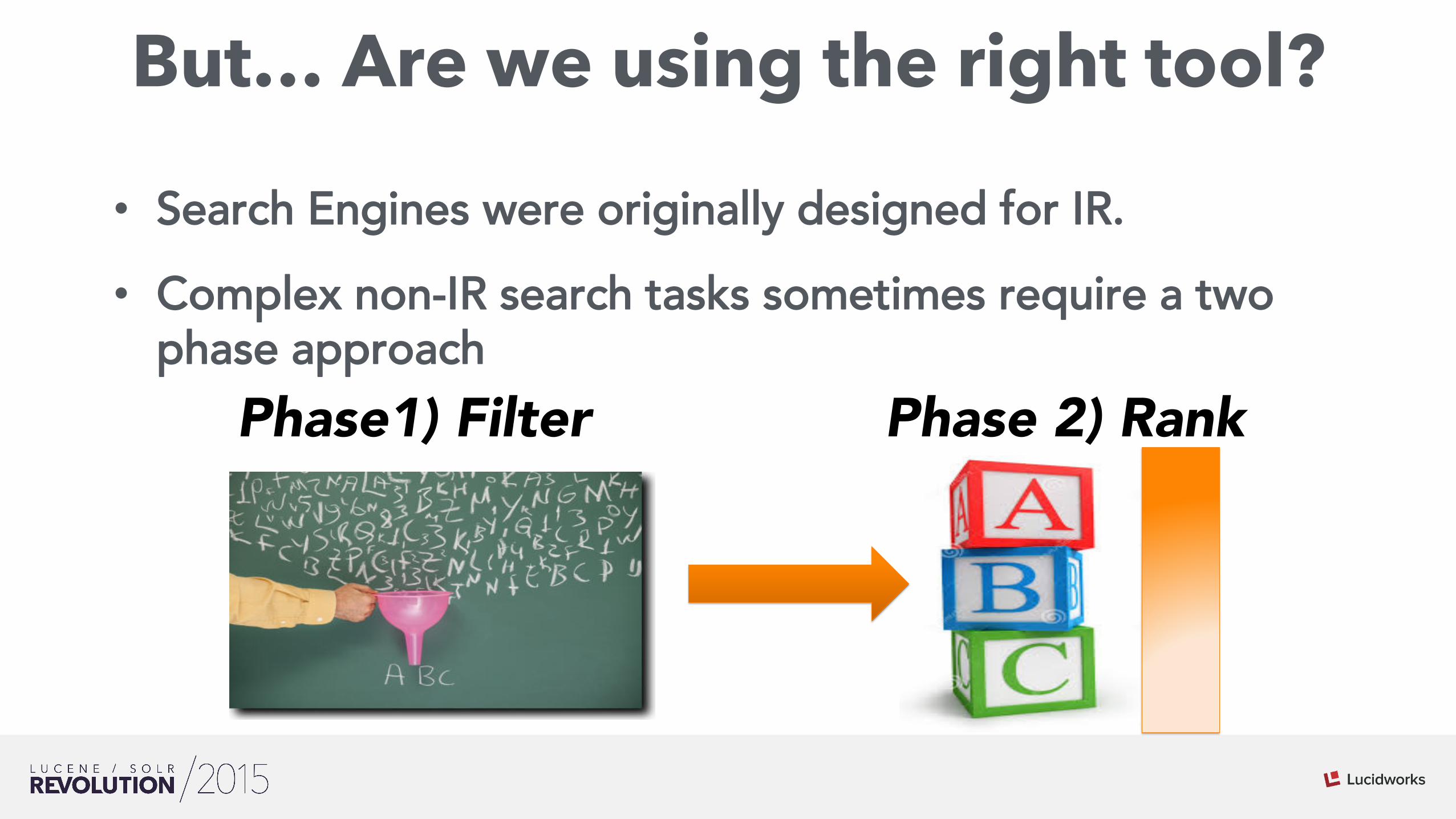
But… Are we using the right tool?
• Search Engines were originally designed for IR. • Complex non-IR search tasks sometimes require a two
phase approach
Phase1) Filter Phase 2) Rank
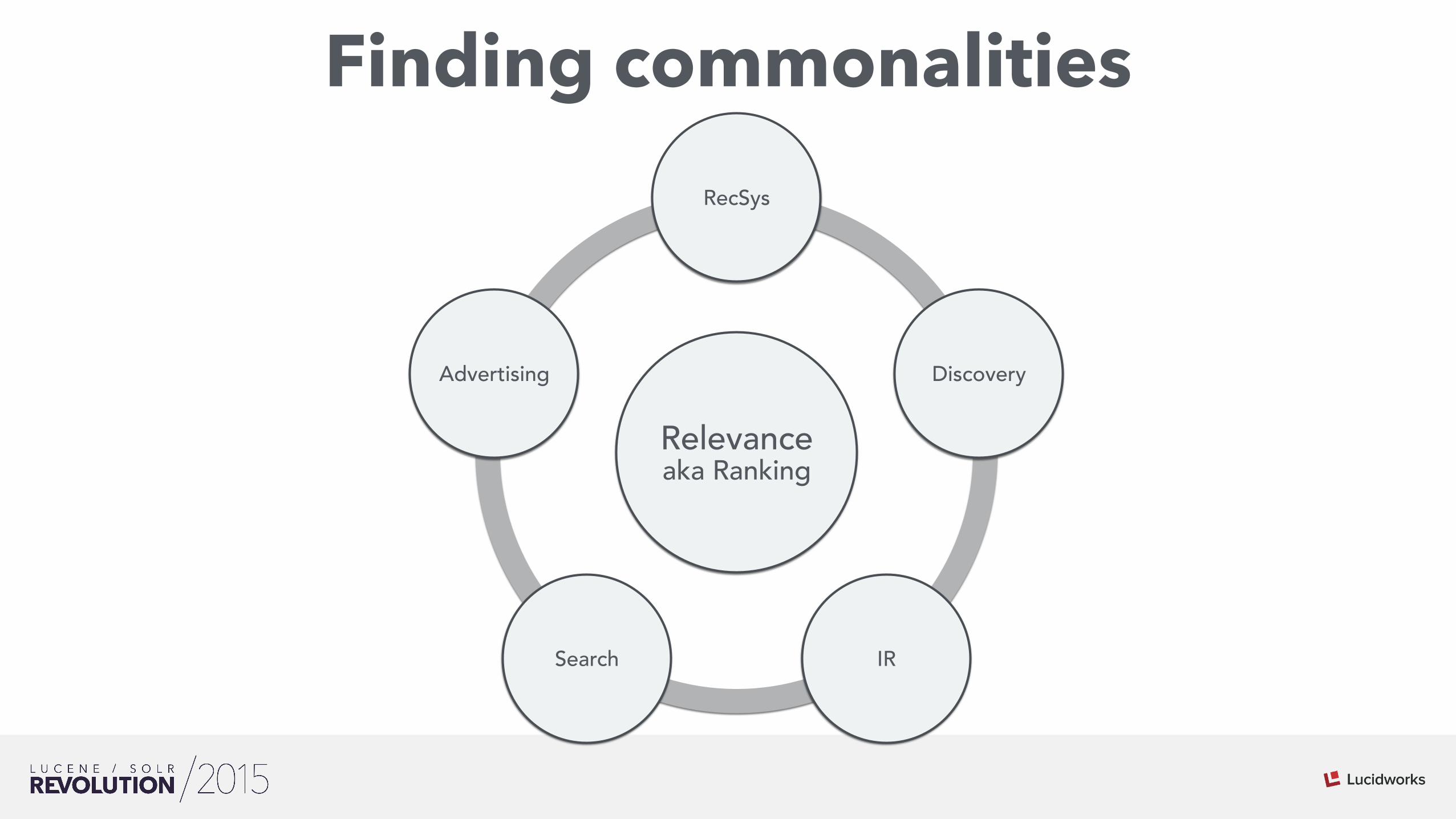
Finding commonalities
Relevance aka Ranking
RecSys
Discovery
IR Search
Advertising
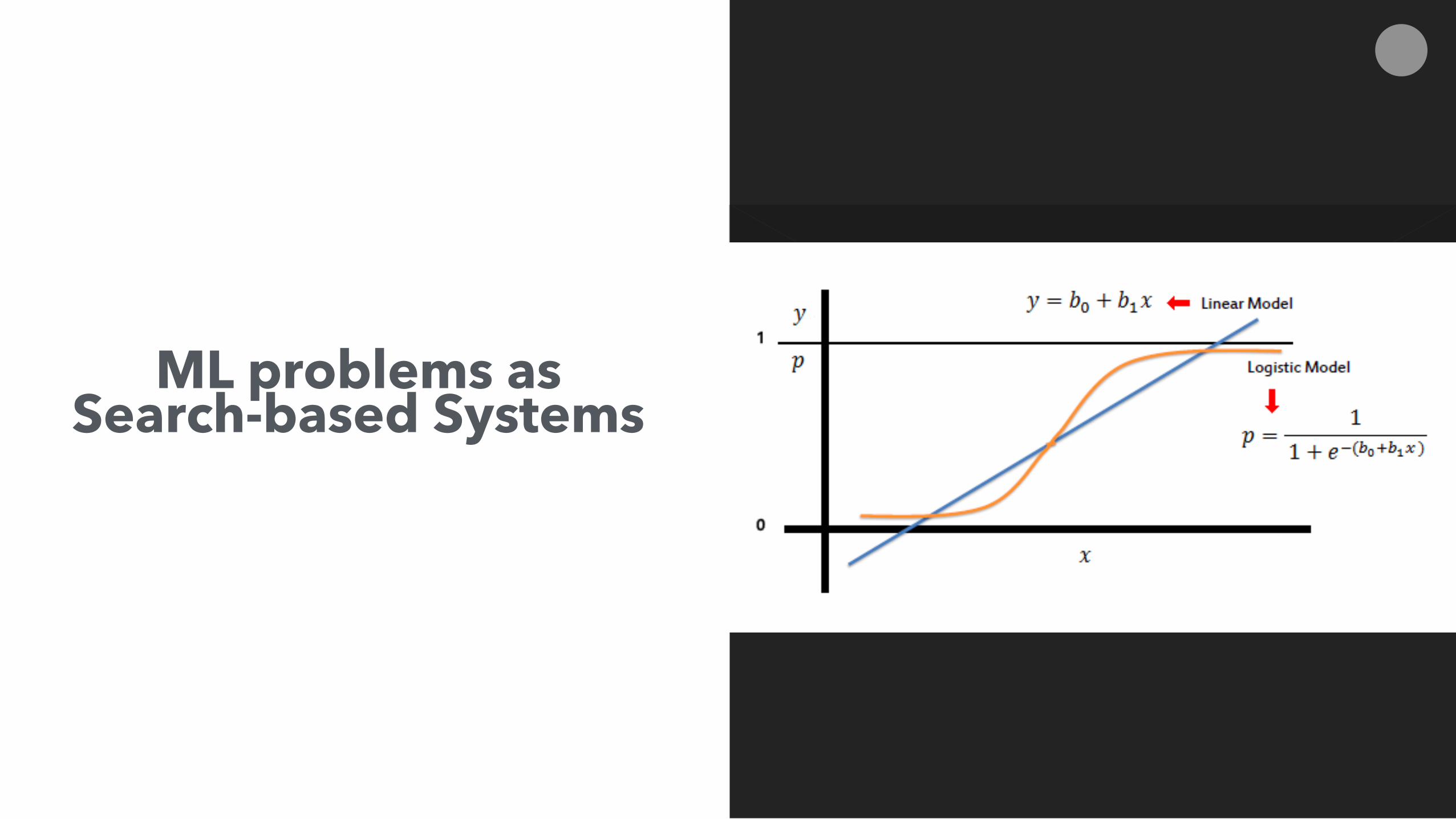
ML problems as Search-based Systems

Machine Learning
Machine Learning in particular supervised learning refer to techniques used to learn how to classify or score previously unseen objects based on a training dataset
Inference and Generalization are the Key!
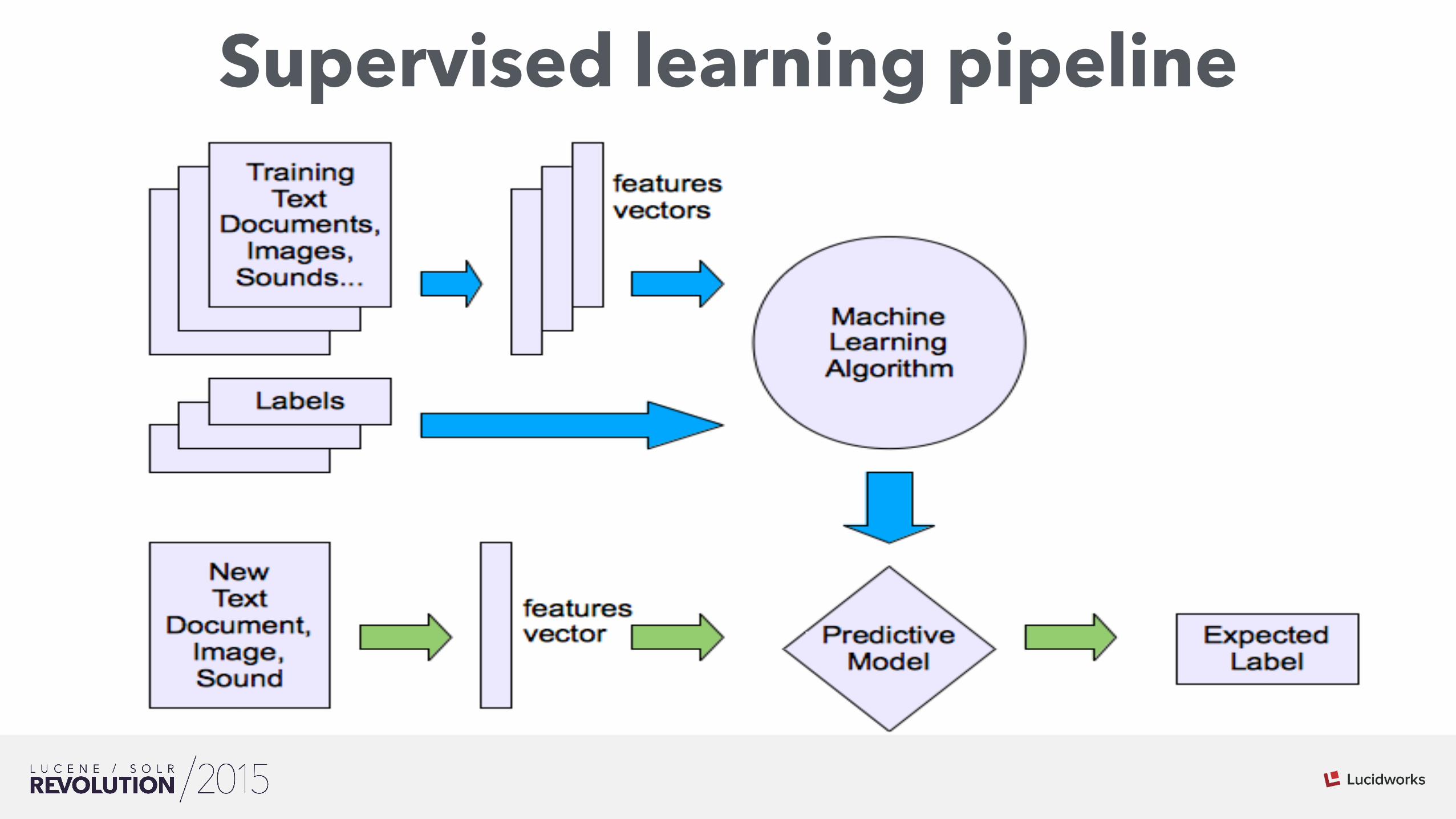
Supervised learning pipeline
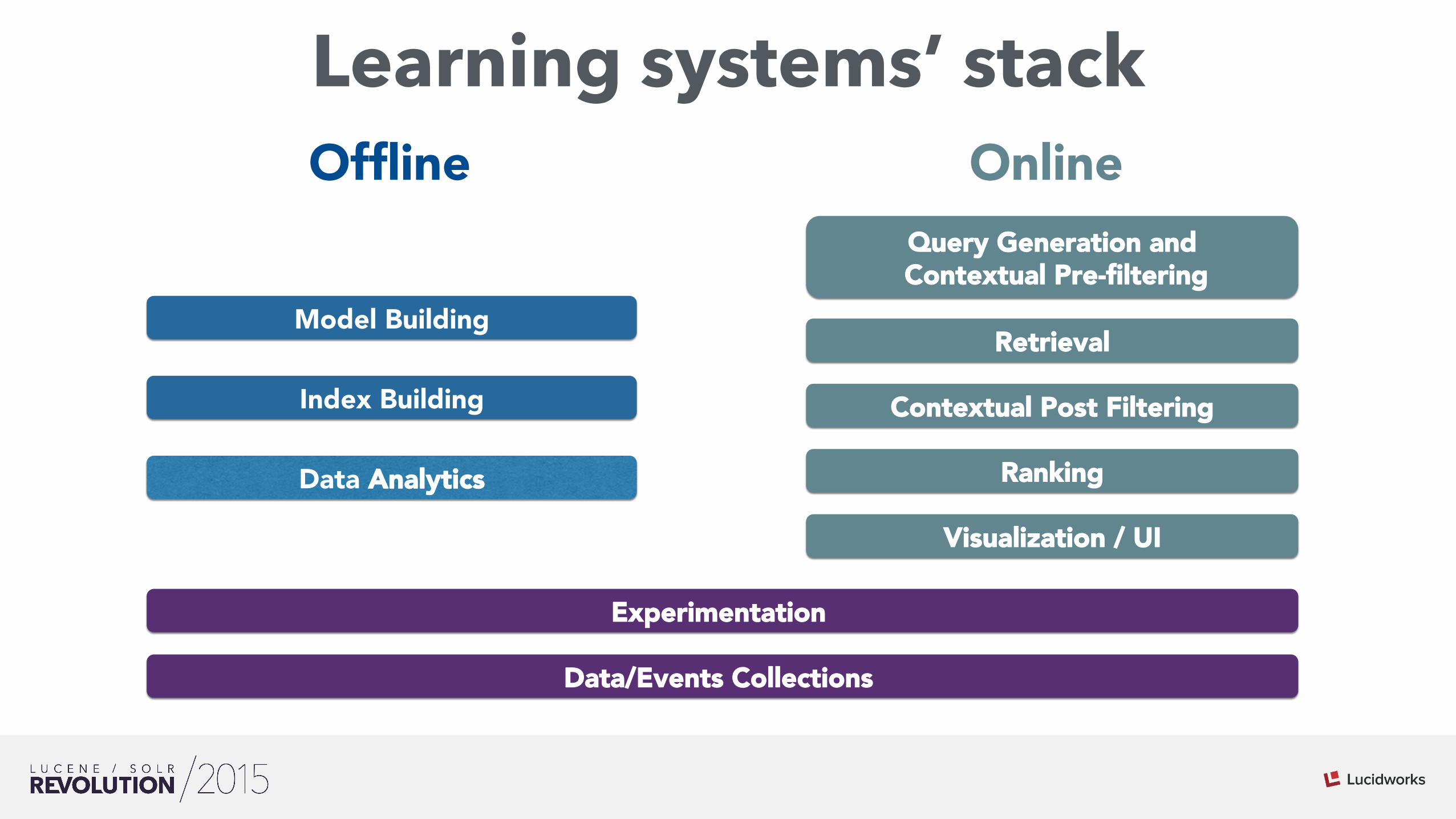
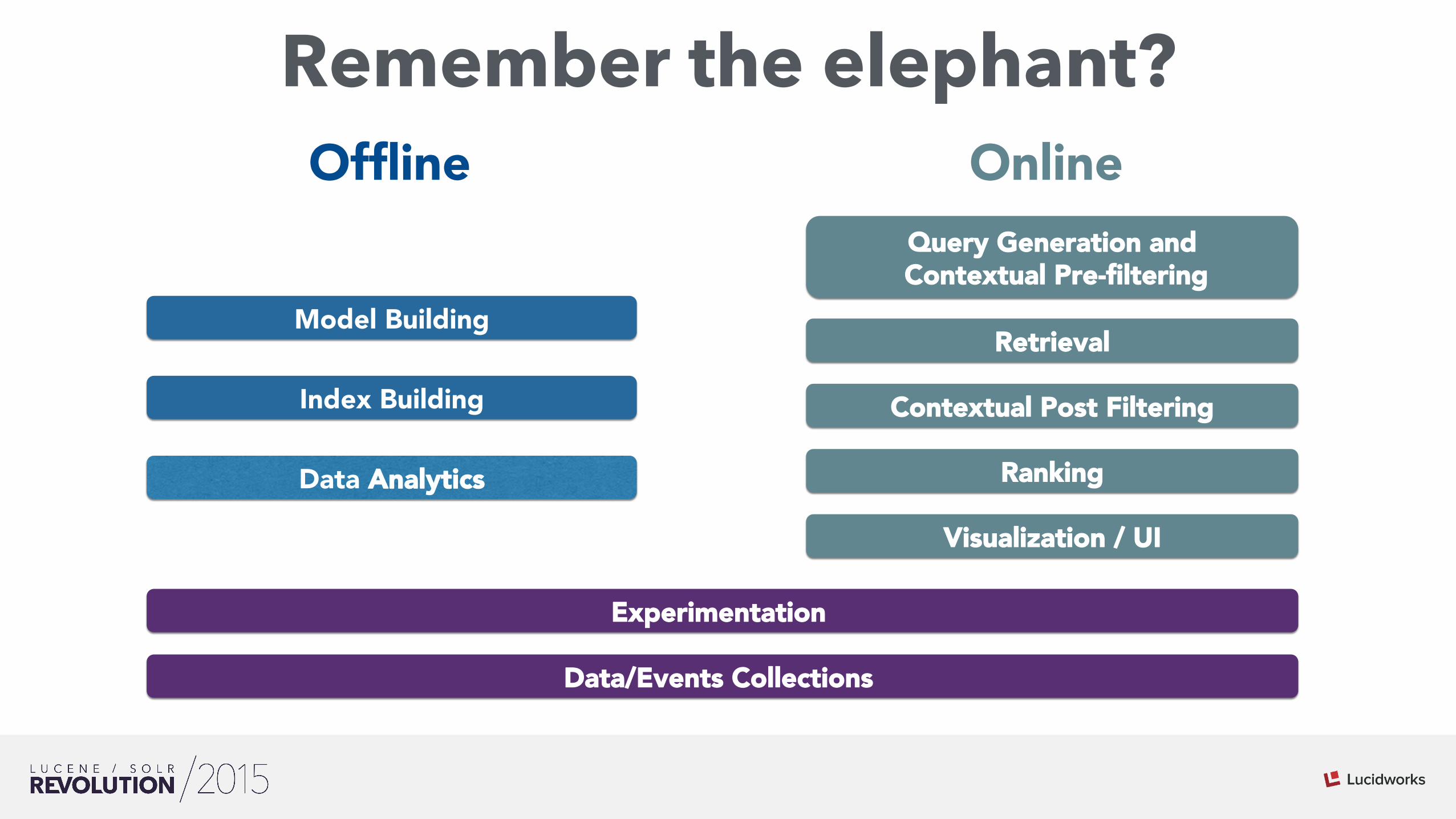
Learning systems’ stack
Visualization / UI
Retrieval
Ranking
Query Generation and Contextual Pre-filtering
Model Building
Index Building
Data/Events Collections
Data Analytics
Contextual Post Filtering
OnlineOffline
Experimentation

Case study: Recommender Systems
• Reduce information load by estimating relevance • Ranking (aka Relevance) Approaches: • Collaborative filtering• Content Based• Knowledge Based• Hybrid
• Beyond rating prediction and ranking • Business filtering logic• Low latency and Scale

RecSys: Content based models • Rec Task: Given a user profile find the best matching items by their
attributes • Similarity calculation: based on keyword overlap between user/items • Neighborhood method (i.e. nearest neighbor)
• Query-based retrieval (i.e Rocchio’s method)
• Probabilistic methods (classical text classification)
• Explicit decision models
• Feature representation: based on content analysis • Vector space model
• TF-IDF
• Topic Modeling
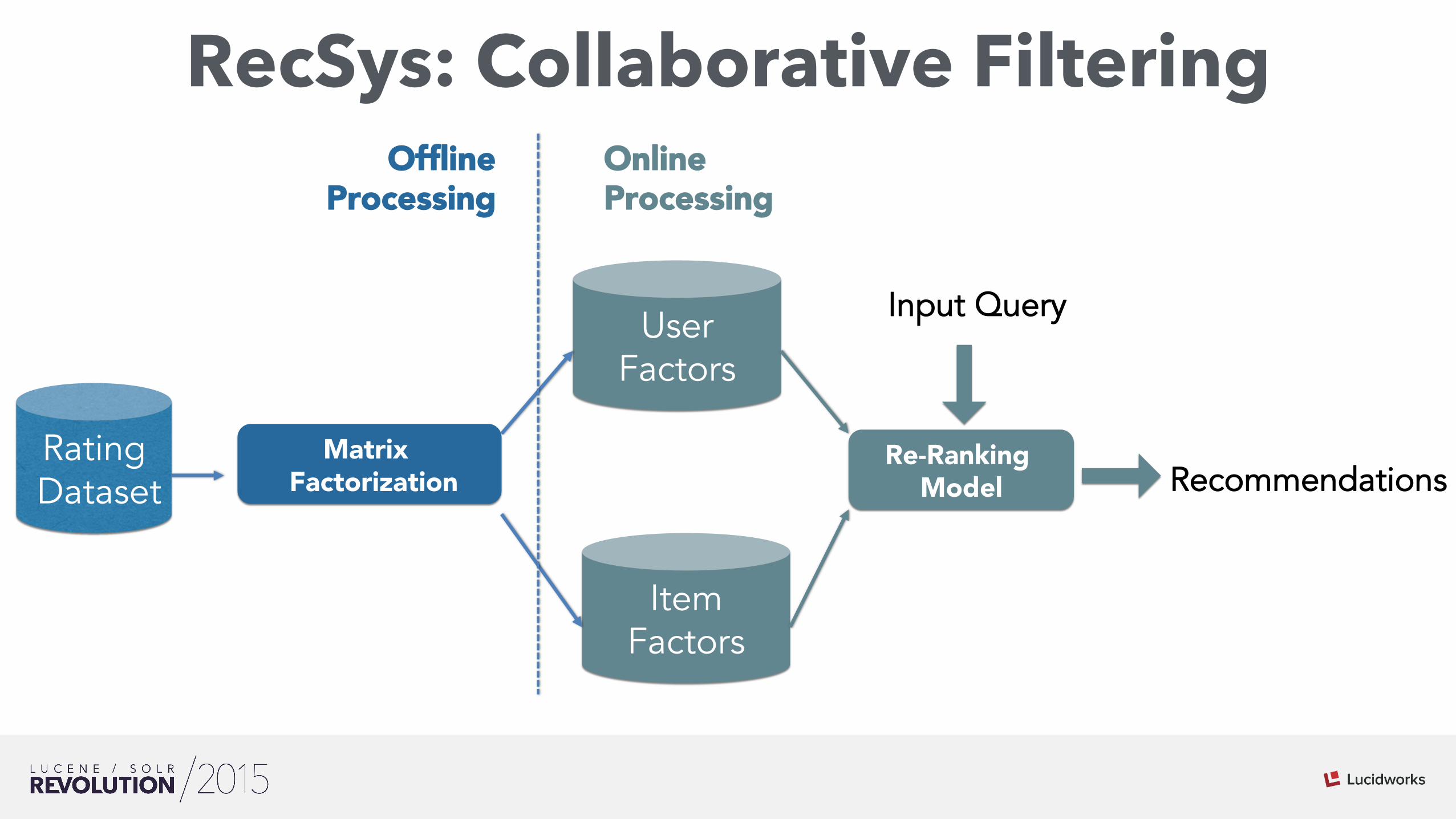
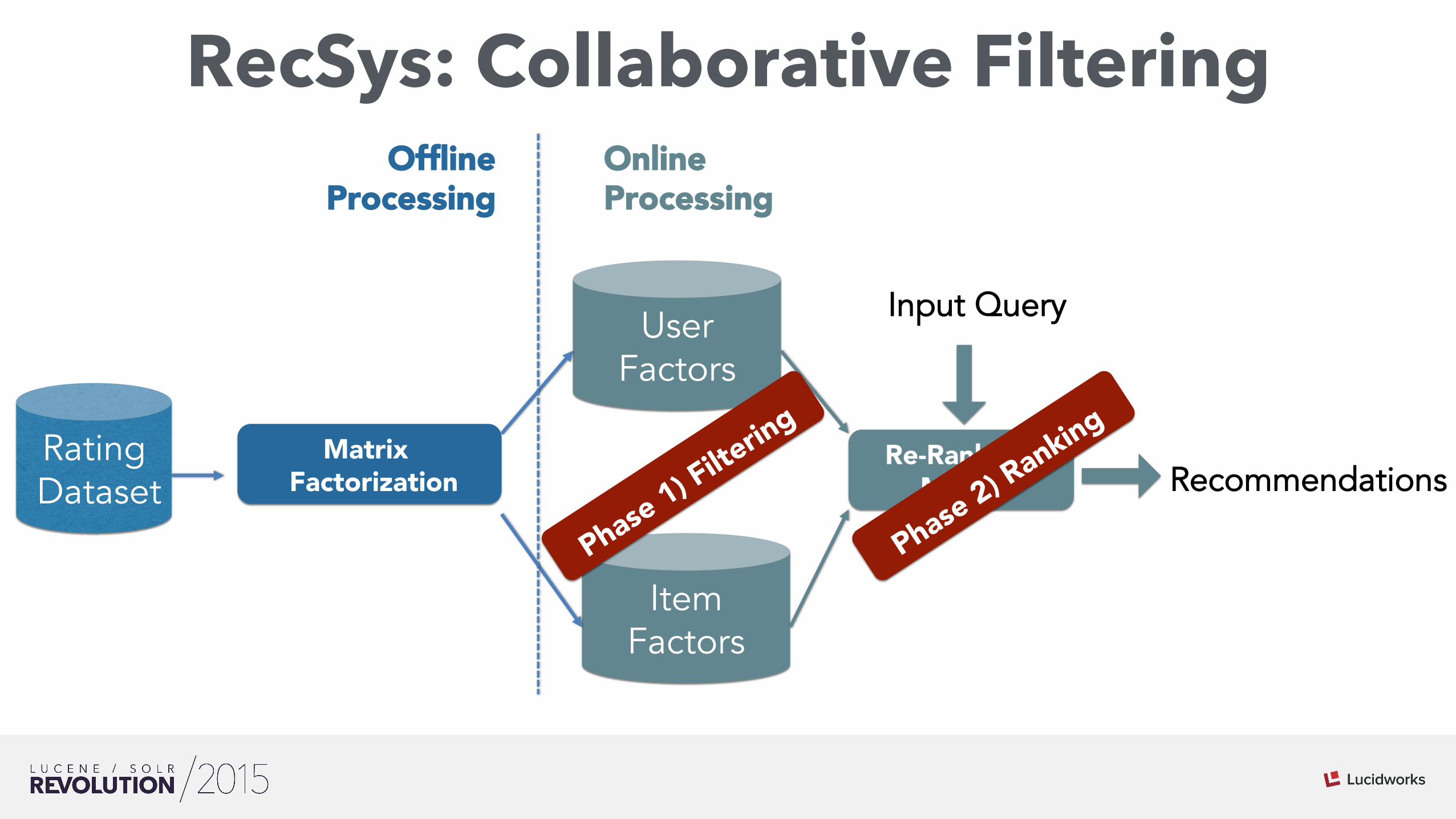
RecSys: Collaborative Filtering
Matrix Factorization
Rating Dataset
User Factors
Item Factors
Re-Ranking Model
Input Query
Online Processing
Offline Processing
Recommendations
RecSys: Collaborative Filtering
Matrix Factorization
Rating Dataset
User Factors
Item Factors
Re-Ranking Model
Input Query
Online Processing
Offline Processing
Recommendations

ML Meets Search! ML Search
Remember the elephant?
Visualization / UI
Retrieval
Ranking
Query Generation and Contextual Pre-filtering
Model Building
Index Building
Data/Events Collections
Data Analytics
Contextual Post Filtering
OnlineOffline
Experimentation
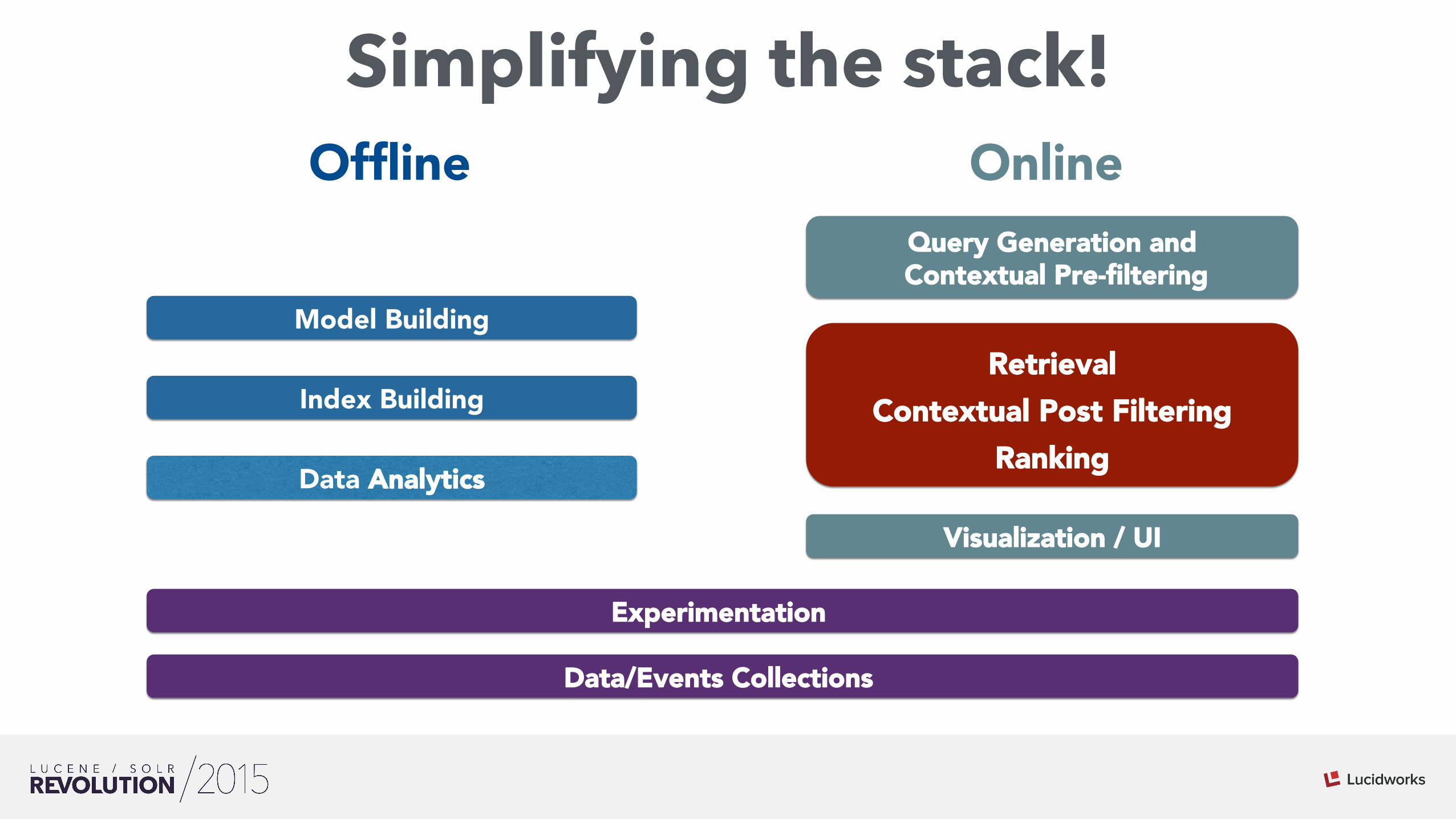
Simplifying the stack!
Visualization / UI
Query Generation and Contextual Pre-filtering
Model Building
Index Building
Data/Events Collections
Data Analytics
OnlineOffline
Experimentation
RetrievalContextual Post Filtering
Ranking
Search stack
Matched Hits
Representation Function
Similarity Calculation
Matched Hits Documents
Representation Function
Input Query
Matched Hits Matched Hits Retrieved Documents
Online Processing
Offline Processing
(*)Relevance Feedback
Query Representation
Doc Representation Index
*Metadata Engineering
(*) Optional
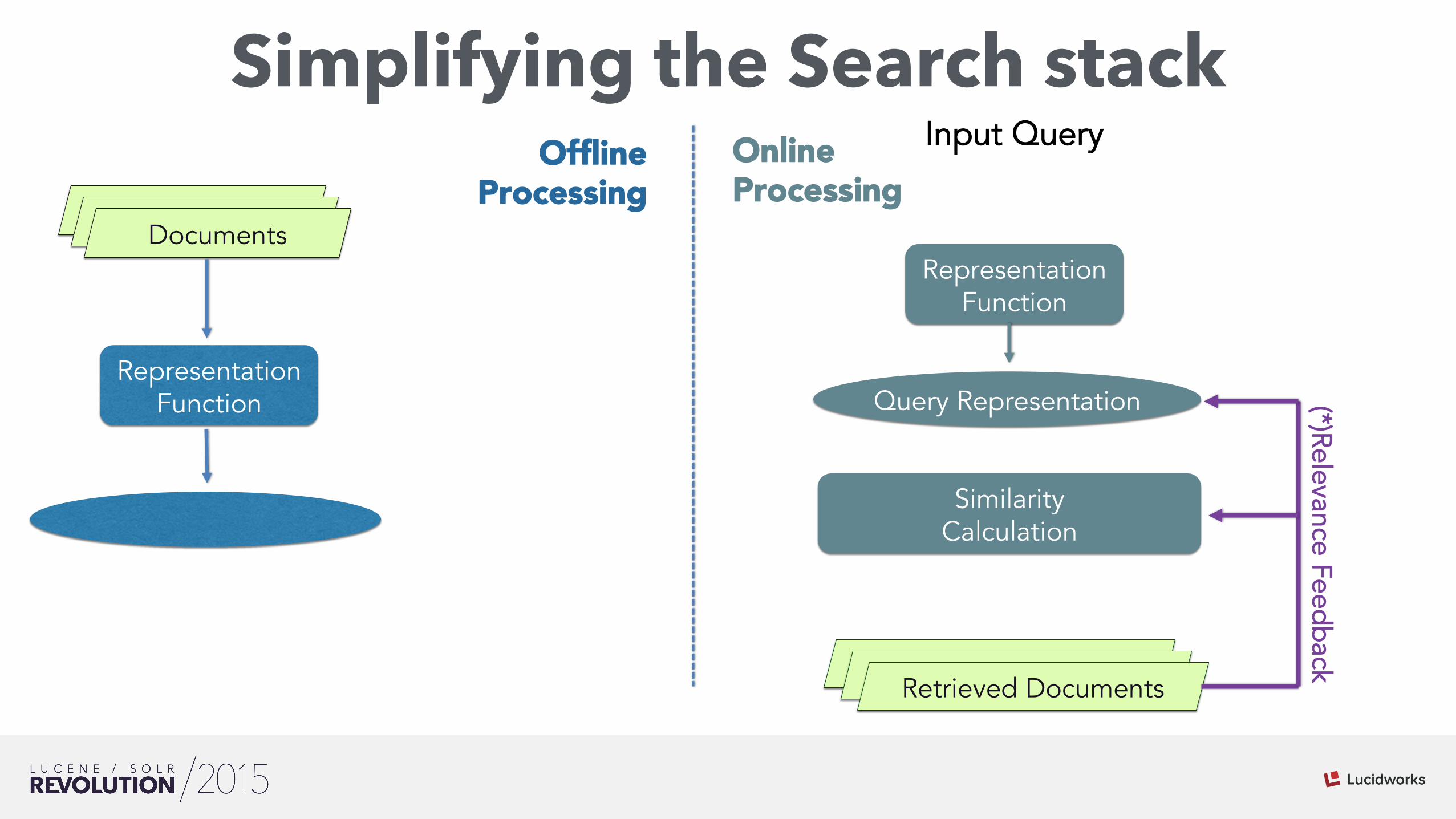
Simplifying the Search stack
Matched Hits
Representation Function
Similarity Calculation
Matched Hits Documents
Representation Function
Input Query
Matched Hits Matched Hits Retrieved Documents
Online Processing
Offline Processing
(*)Relevance Feedback
Query Representation
Doc Representation Index
*Metadata Engineering
(*) Optional
Retrieval Contextual Post Filtering
Ranking
ML-Scoring PluginSerialized ML Model
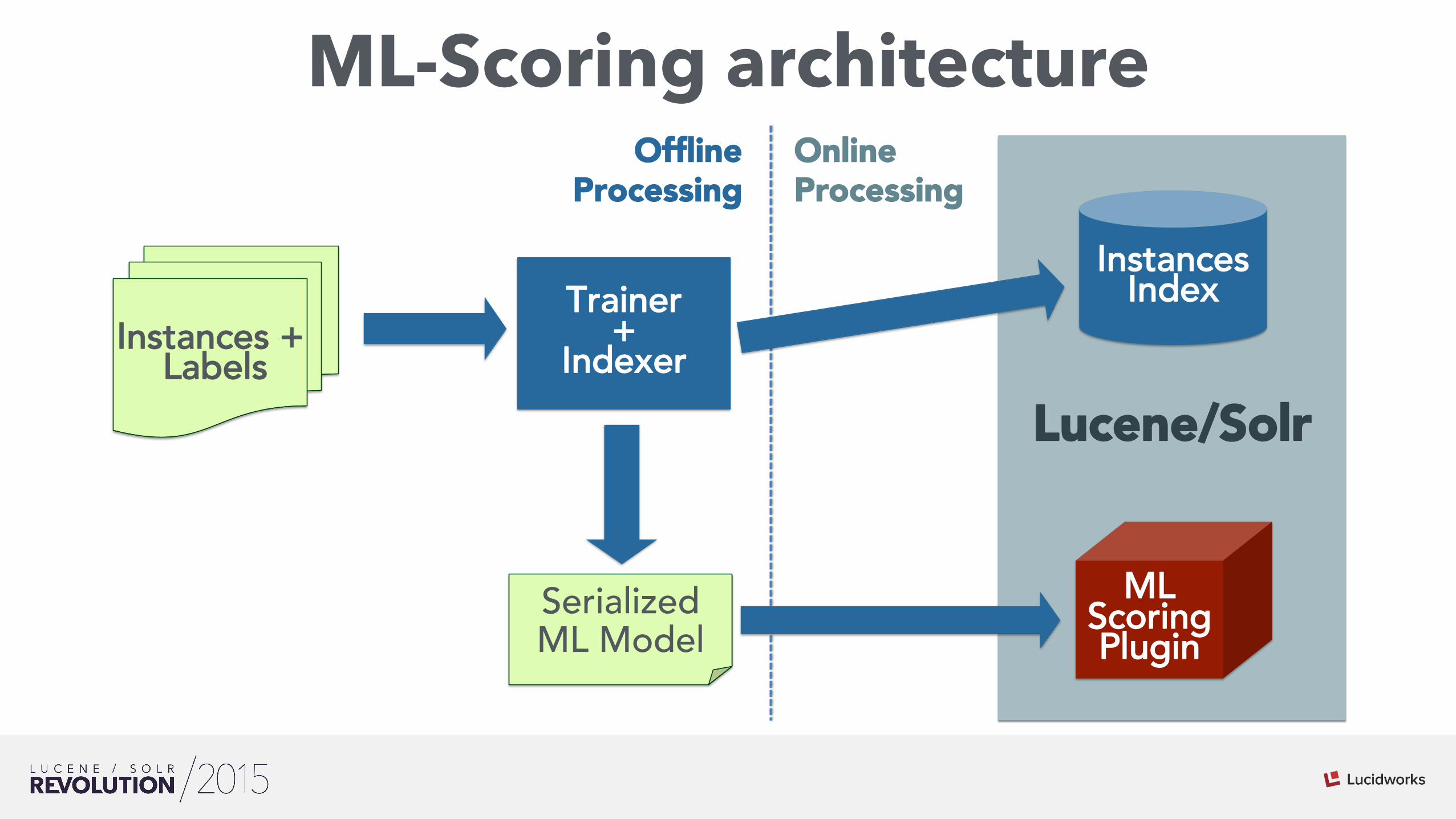
ML-Scoring architecture
Lucene/Solr
Instances + Labels
Instances Index
ML Scoring Plugin
Serialized ML Model
Online Processing
Offline Processing
Trainer +
Indexer

ML-Scoring Options • Option A: Solr FunctionQuery • Pro: Model is just a query!• Cons: Limits expressiveness of models
• Option B: Solr Custom Function Query • Pro: Loading any type of model (also PMML)• Cons: Memory limitations, also multiple model reloading
• Option C: Lucene CustomScoreQuery • Pro: Can use PMML and tune how PMML gets loaded• Cons: No control on matches• Option D: Lucene Low level Custome Query • *Mahout vectors from Lucene text (only trains, so not an option)

Real-life Problem
• Census database that contains documents with the following fields: 1. Age: continuous; 2. Workclass: 8 values; 3. Fnlwgt: continuous.; 4. Education: 16 values; 5. Education-num: continuous.; 6. Marital-status: 7 values; 7. Occupation: 14 values; 8. Relationship: 6 values; 9. Race: 5 values; 10. Sex: Male, Female; 11. Capital-gain: continuous.;12. Capital-loss: continuous.; 13. Hours-per-week: continuous.; 14. Native-country: 41 values; 15. >50K Income: Yes, No.
• Task is to predict whether a person makes more than 50k a year based on their attributes
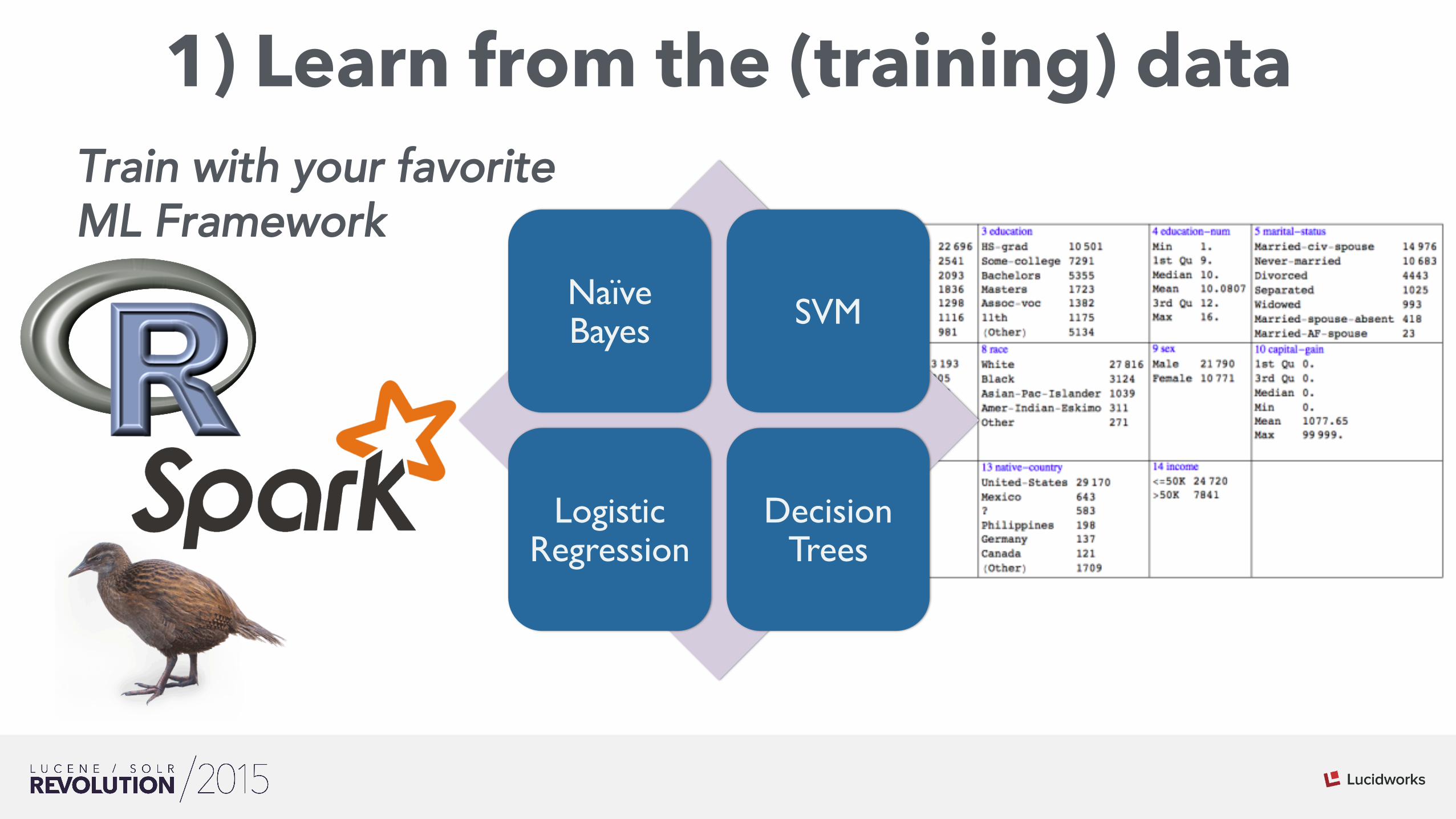
1) Learn from the (training) data
Naïve Bayes SVM
Logistic Regression
Decision Trees
Train with your favorite ML Framework
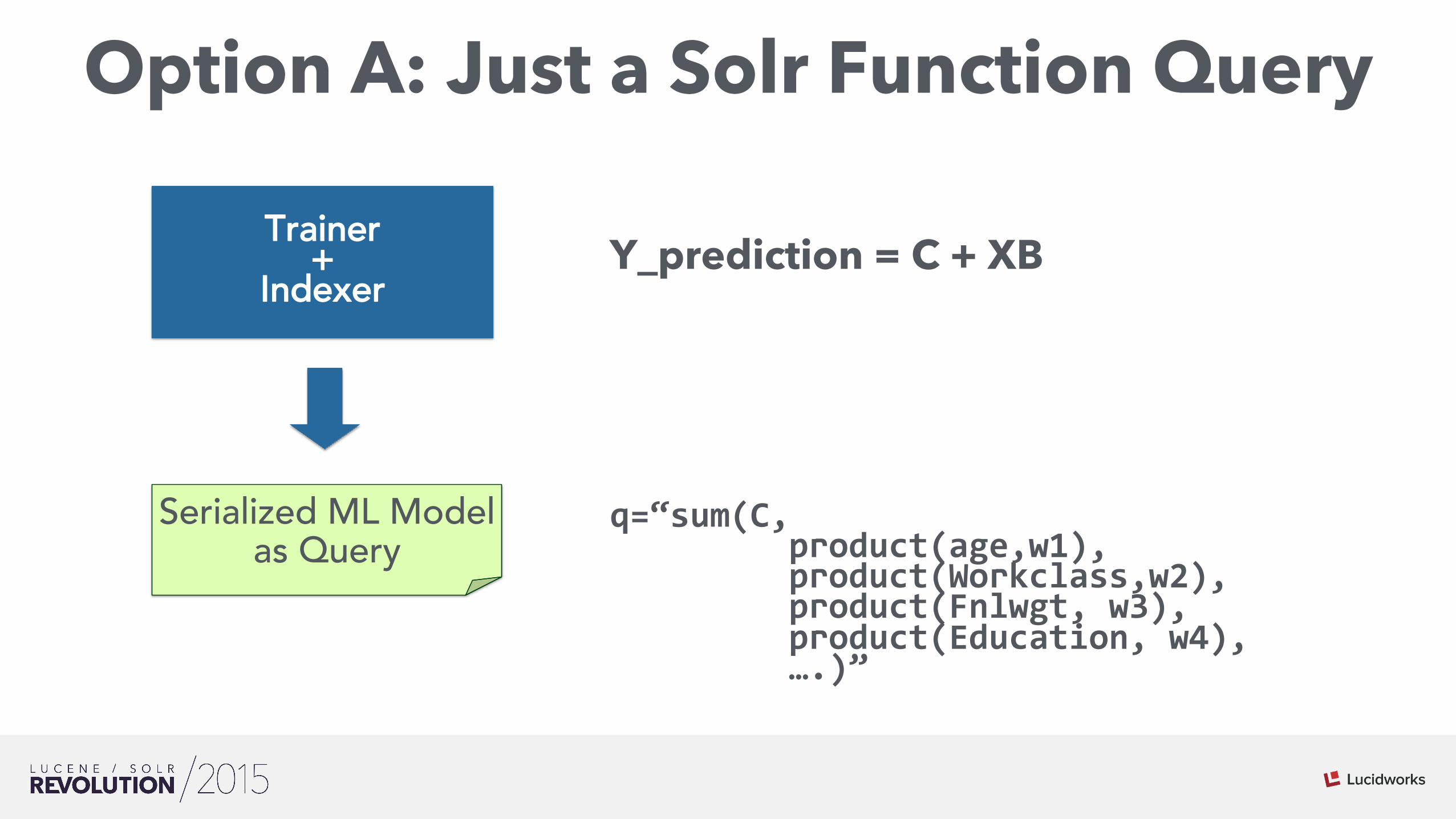
Option A: Just a Solr Function Query
q=“sum(C, product(age,w1), product(Workclass,w2), product(Fnlwgt, w3), product(Education, w4), ….)”
Serialized ML Model as Query
Trainer +
Indexer Y_prediction = C + XB
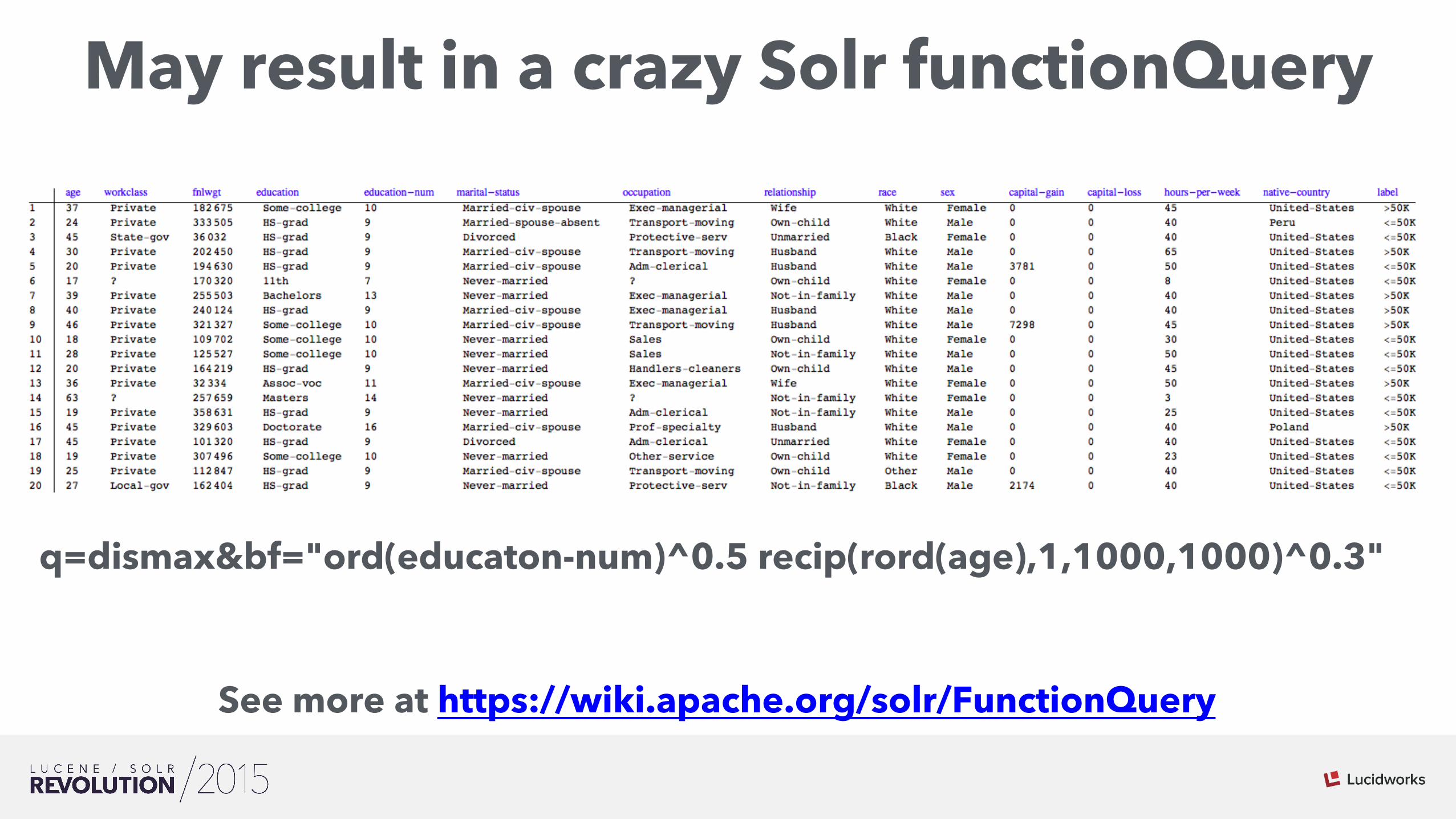
May result in a crazy Solr functionQuery
See more at https://wiki.apache.org/solr/FunctionQuery
q=dismax&bf="ord(educaton-num)^0.5 recip(rord(age),1,1000,1000)^0.3"
What about models like this?
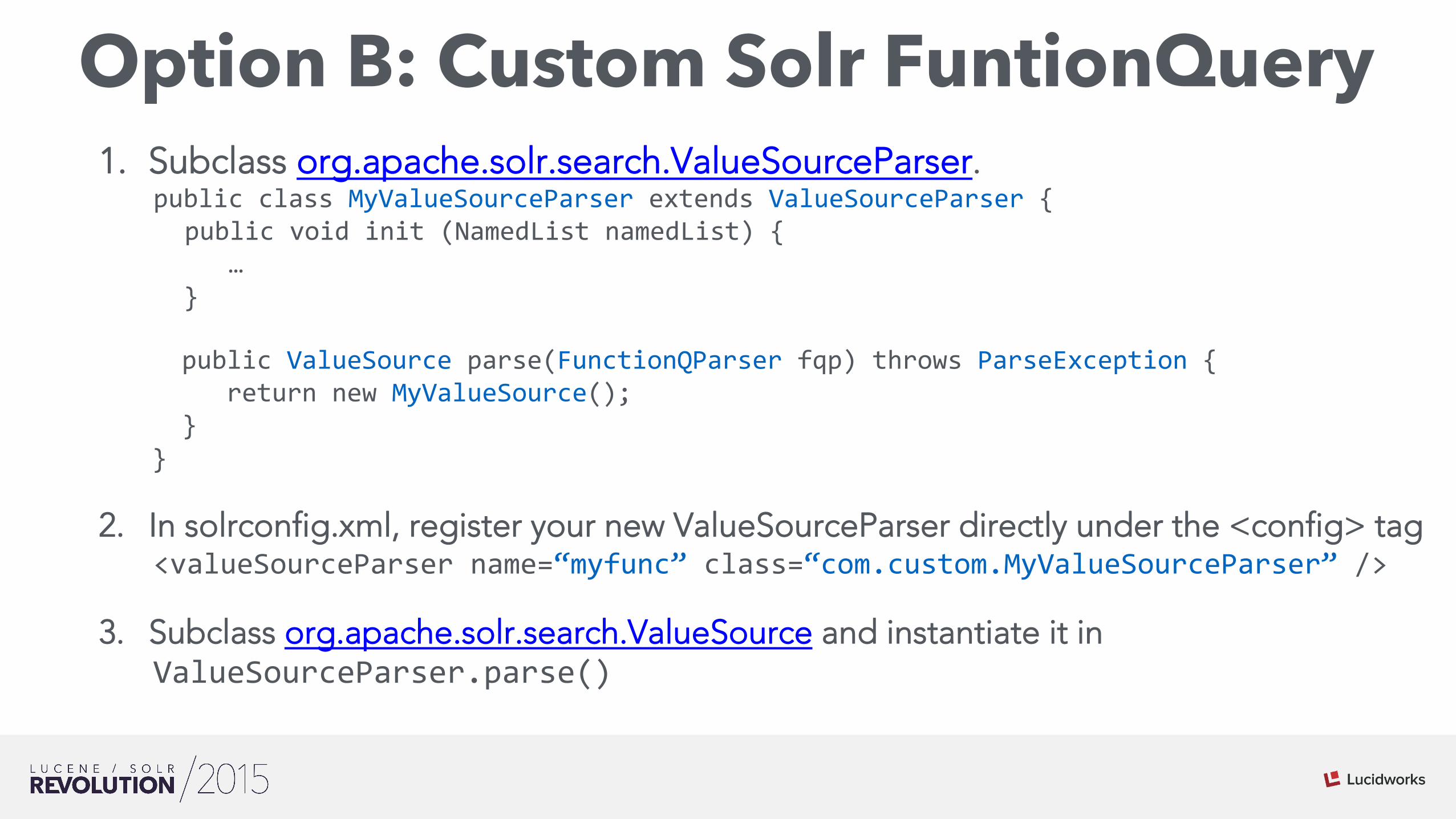
Option B: Custom Solr FuntionQuery 1. Subclass org.apache.solr.search.ValueSourceParser.
public class MyValueSourceParser extends ValueSourceParser { public void init (NamedList namedList) {
… }
public ValueSource parse(FunctionQParser fqp) throws ParseException { return new MyValueSource(); } }
2. In solrconfig.xml, register your new ValueSourceParser directly under the <config> tag <valueSourceParser name=“myfunc” class=“com.custom.MyValueSourceParser” />
3. Subclass org.apache.solr.search.ValueSource and instantiate it in ValueSourceParser.parse()

Option C: Lucene CustomScoreQuery
2C) Serialize model with PMML • Can use JPMML library to read serialized model in Lucene
• On Lucene will need to implement an extension with JPMML-evaluator to take vectors as expected
3C) In Lucene: • Override CustomScoreQuery: load PMML
• Create CustomScoreProvider: do model PMML data marshaling
• Rescoring: PMML evaluation

Predictive Model Markup Language
• Why use PMML • Allows users to build a model in one system• Export model and deploy it in a different environment for prediction• Fast iteration: from research to deployment to production
• Model is a XML document with: • Header: description of model, and where it was generated
• DataDictionary: defines fields used by model
• Model: structure and parameters of model
• http://dmg.org/pmml/v4-2-1/GeneralStructure.html

Example: Train in Spark to PMML import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors // Load and parse the data val data = sc.textFile("/path/to/file") .map(s => Vectors.dense(s.split(',').map(_.toDouble))) // Cluster the data into three classes using KMeans val numIterations = 20 val numClusters = 3 val kmeansModel = KMeans.train(data, numClusters, numIterations) // Export clustering model to PMML kmeansModel.toPMML("/path/to/kmeans.xml")

PMML XML File
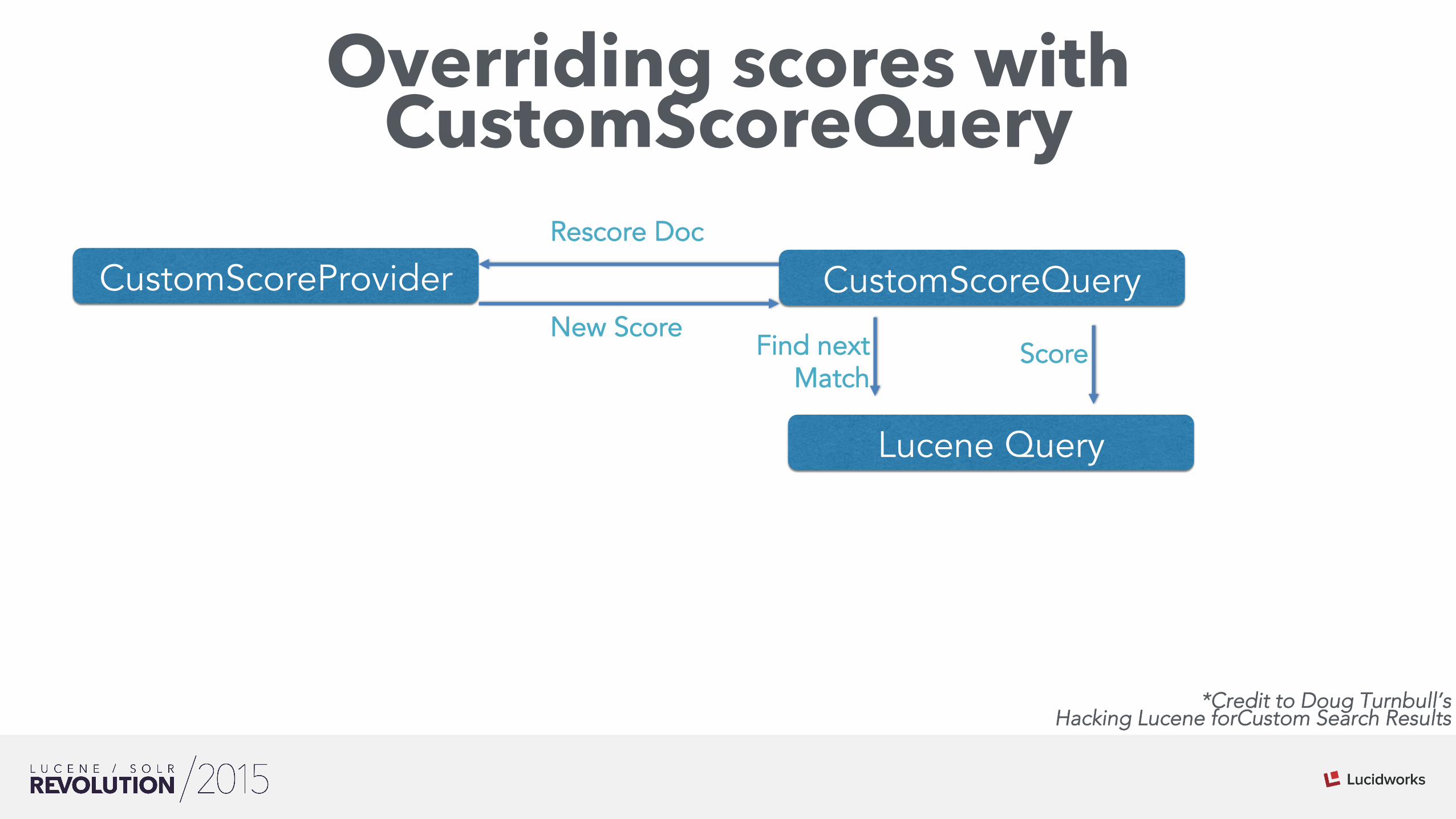
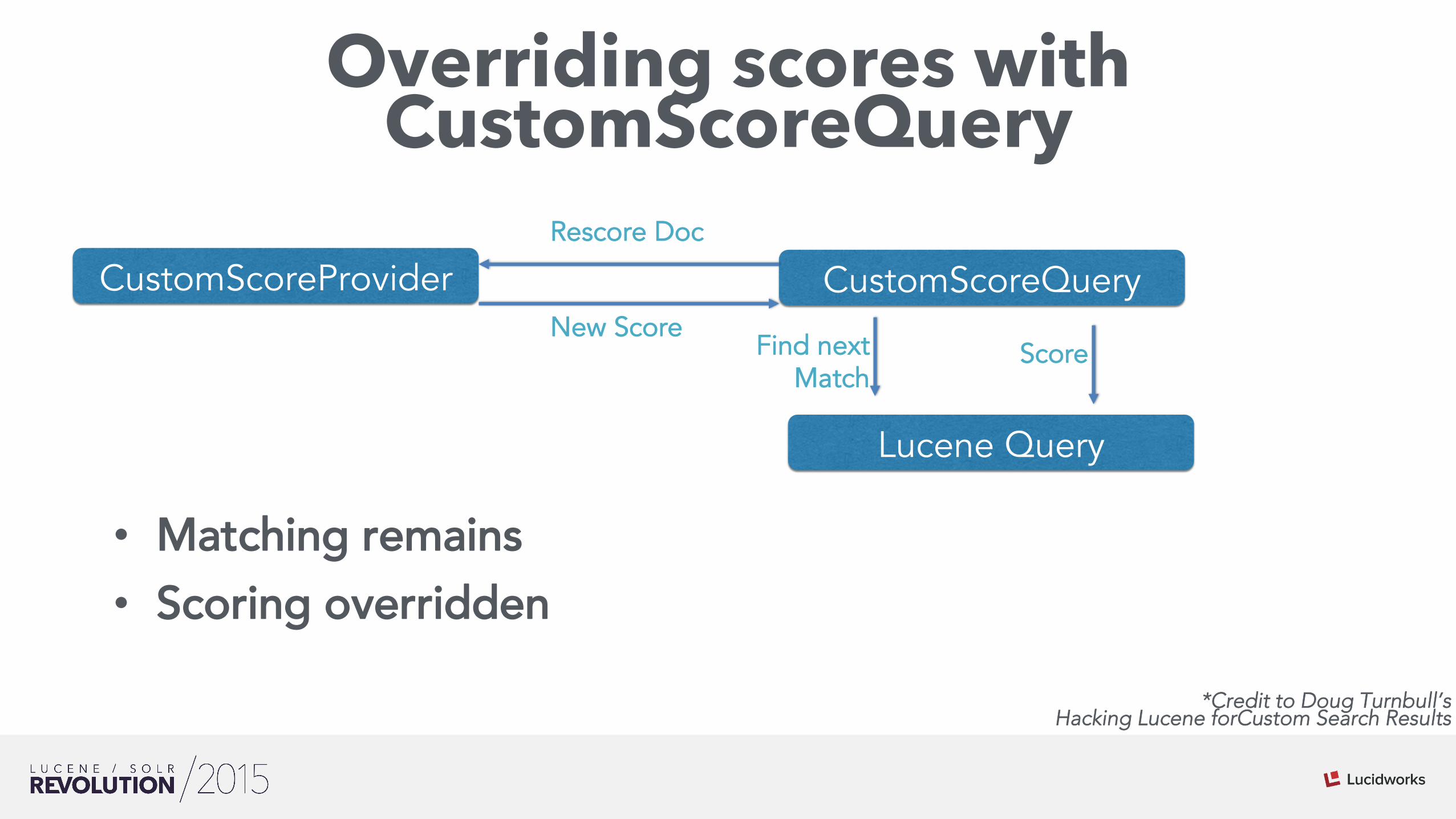
Overriding scores with CustomScoreQuery
CustomScoreProvider CustomScoreQuery
Lucene Query
Find next Match
Score
Rescore Doc
New Score
*Credit to Doug Turnbull’s Hacking Lucene forCustom Search Results
Overriding scores with CustomScoreQuery
• Matching remains • Scoring overridden
CustomScoreProvider CustomScoreQuery
Lucene Query
Find next Match
Score
Rescore Doc
New Score
*Credit to Doug Turnbull’s Hacking Lucene forCustom Search Results
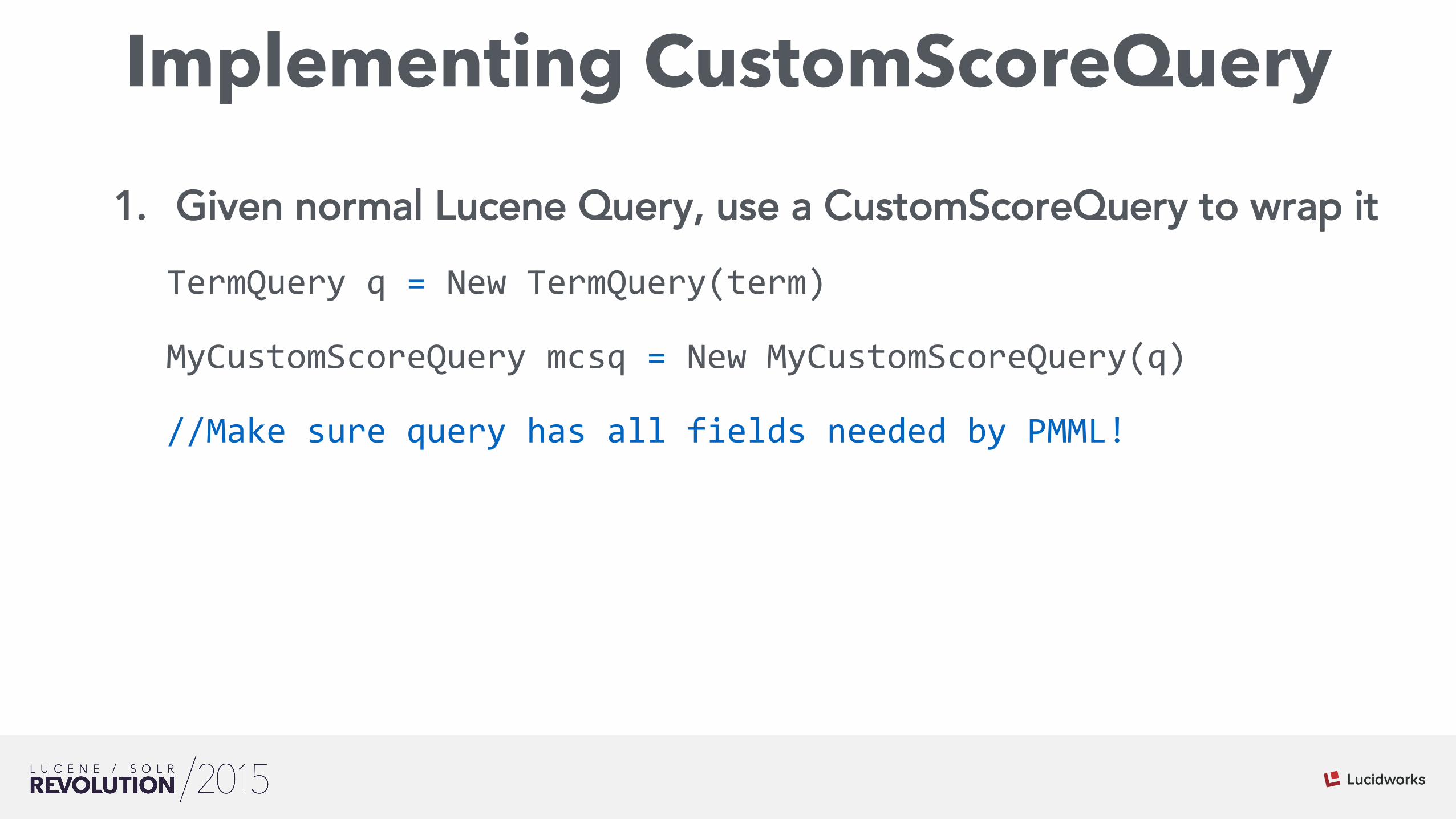
Implementing CustomScoreQuery
1. Given normal Lucene Query, use a CustomScoreQuery to wrap it TermQuery q = New TermQuery(term)
MyCustomScoreQuery mcsq = New MyCustomScoreQuery(q)
//Make sure query has all fields needed by PMML!

Implementing CustomScoreQuery
2. Initialize PMML
PMML pmml = ...;
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance();
ModelEvaluator<?> modelEvaluator = modelEvaluatorFactory.newModelManager(pmml);
Evaluator evaluator = (Evaluator)modelEvaluator;

Implementing CustomScoreQuery
2. Rescore each doc with IndexReader and docID
public float customScore(int doc, float subQueryScore, float valSrcScores[]) throws IOException {
//Lucene reader IndexReader r = context.reader(); Terms tv = r.getTermVector(doc, _field); TermsEnum tenum = null; tenum = tv.iterator(tenum); //convert the iterator order to fields needed by model
TermsEnum tenumPMML = tenum2PMML(tenum, evaluator.getActiveFields());

Implementing CustomScoreQuery
2. Rescore each doc with IndexReader and docID //Marshall Data into PMML
Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>(); List<FieldName> activeFields = evaluator.getActiveFields();
for(FieldName activeField : activeFields){ // The raw is value has been sorted with number of fields needed Object rawValue = tenumPMML.next; FieldValue activeValue = evaluator.prepare(activeField, rawValue); arguments.put(activeField, activeValue); }

Implementing CustomScoreQuery
2. Rescore each doc with IndexReader and docID //Rescore and evaluate with PMML
Map<FieldName, ?> results = evaluator.evaluate(arguments);
FieldName targetName = evaluator.getTargetField();
Object targetValue = results.get(targetName);
return (float) targetValue;

Potential issues
• Performance • If search space is very large
• If model complexity explodes (i.e. kernel expansion)
• Operations • Code is running on key infrastructure
• Versioning
• Binary Compatibility
Option D: Low Level Lucene • CustomScoreQuery or Custom FunctionScore can’t control
matches • If you want custom matches and scoring…. • Implement:
• Custom Query Class
• Custom Weight Class
• Custom Scorer Class
• http://opensourceconnections.com/blog/2014/03/12/using-customscorequery-for-custom-solrlucene-scoring/

Conclusion
• Importance of the full picture – Learning systems from the lenses of the whole elephant
• Reducing the time from science to production is complicated
• Scalability is hard! • Why not have ML use Search in its core during online eval?
• Solr and Lucene are a start to customize your learning system

O C T O B E R 1 3 - 1 6 , 2 0 1 6 • A U S T I N , T X






























