Embed Size (px)
Citation preview

Low-Latency Streaming Data Processing in Hadoop
InSemble Inc. http://www.insemble.com

Agenda
Reference Architecture for Low Latency Streaming1
Storm 4
Kafka3
Flume2
Demo5

Hadoop Ecosystem
Source: Apache Hadoop Documentation

Cloudera Platform
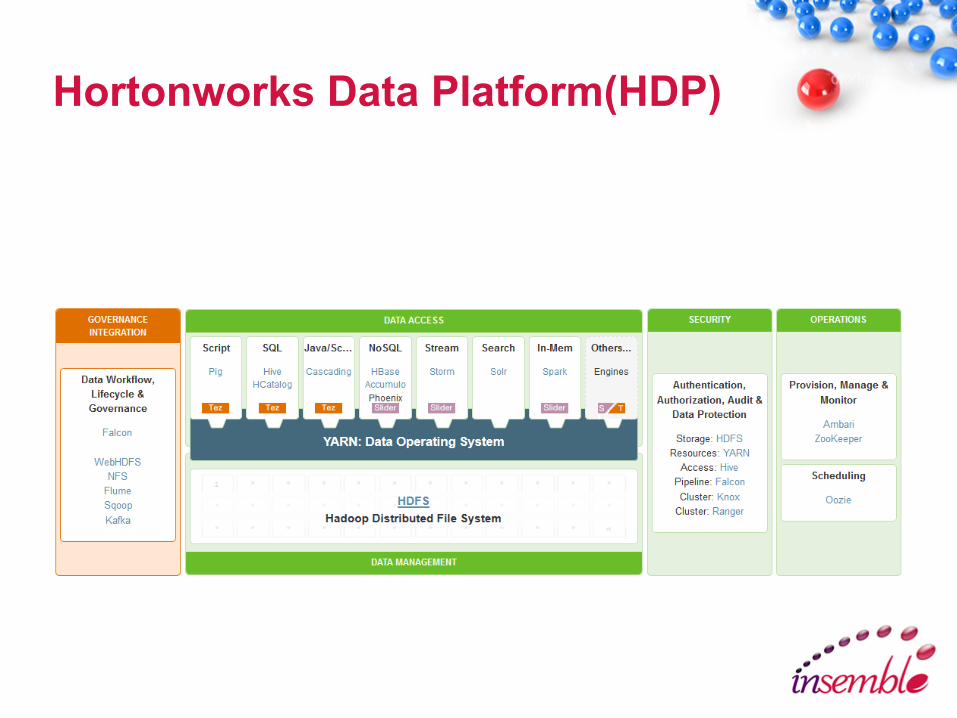
Hortonworks Data Platform(HDP)

Real time Stream Processing Architecture with Hadoop

Flume Architecture
• Distributed system for collecting and aggregating from multiple data stores to a centralized data store
• Agent is a JVM that hosts the Flume components
• Channel will store message until picked by a sink
• Different types of Flume sources
• Source and Sink are decoupled
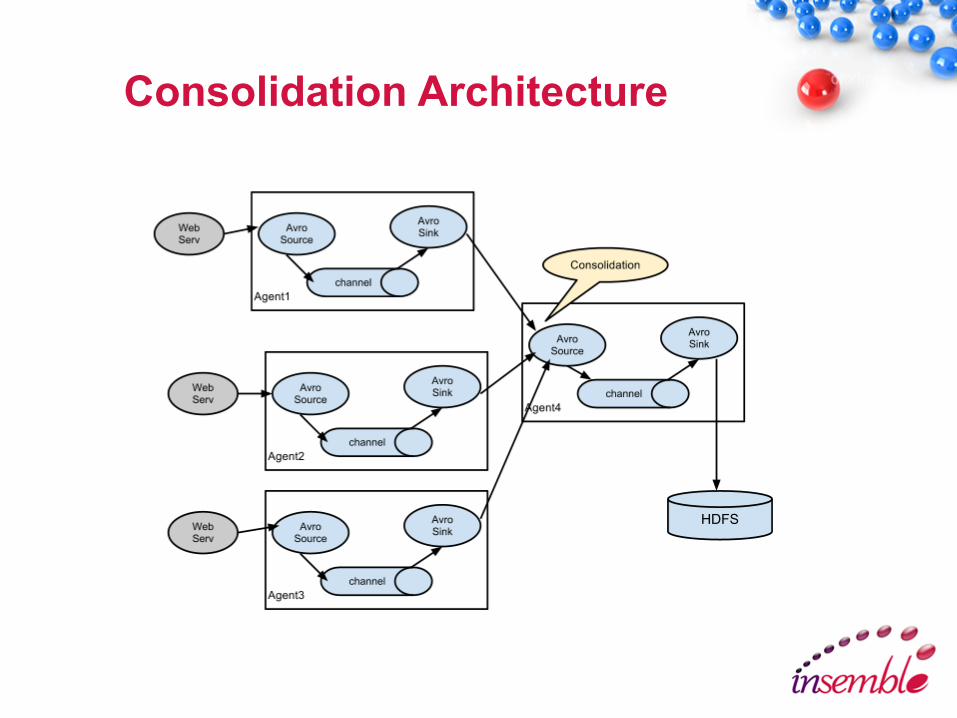
Consolidation Architecture

Multiplexing Architecture

Kafka Introduction
• Messaging System which is distributed, partitioned and replicated• Kafka brokers run as a cluster• Producers and Consumers can be written in any language

Topic
• Ordered, immutable sequence numbers• Retains messages until a period of time• “Offset” of where they are is controlled by the consumer• Each partition is replicated and has “leader” and 0 or more “follower”. R/W
only done on leader

Producers and Consumers
• Producer controls which partition messages goes to• Supports both Queuing and Pub/Sub
– Abstraction called Consumer group• Ordering within Partition
– Ordering for subscriber has to be done with only one subscriber to that partition

Storm Introduction
• Distributed real time computational system– Process unbounded streams of data– Can use multiple programming languages– Scalable, fault-tolerant and guarantees that data will be processed
• Use Cases– Real time analytics, online machine learning– Continuous Computation– Distributed RPC– ETL
• Concepts– Topology– Spouts– Bolts

Concepts
• Storm Cluster– Master node(Nimbus)
• Distributing code• Assigns tasks to machines• Monitors for failures
– Worker nodes(Supervisor)• Starts/stops worker processes• Each worker process executes subset of a topology
– Zookeeper• Coordinates between Nimbus and Supervisors• Nimbus and Supervisors completely stateless• State maintained by Zookeeper or local disks

Details
• Stream – Unbounded sequence of tuples
• Spout(write logic)– Source of stream. Emits tuples
• Bolt(write logic)– Processes streams and emits tuples
• Topology– DAG of spouts and bolts– Submit a topology to a Storm cluster– Each node runs in parallel and parallelism is controlled
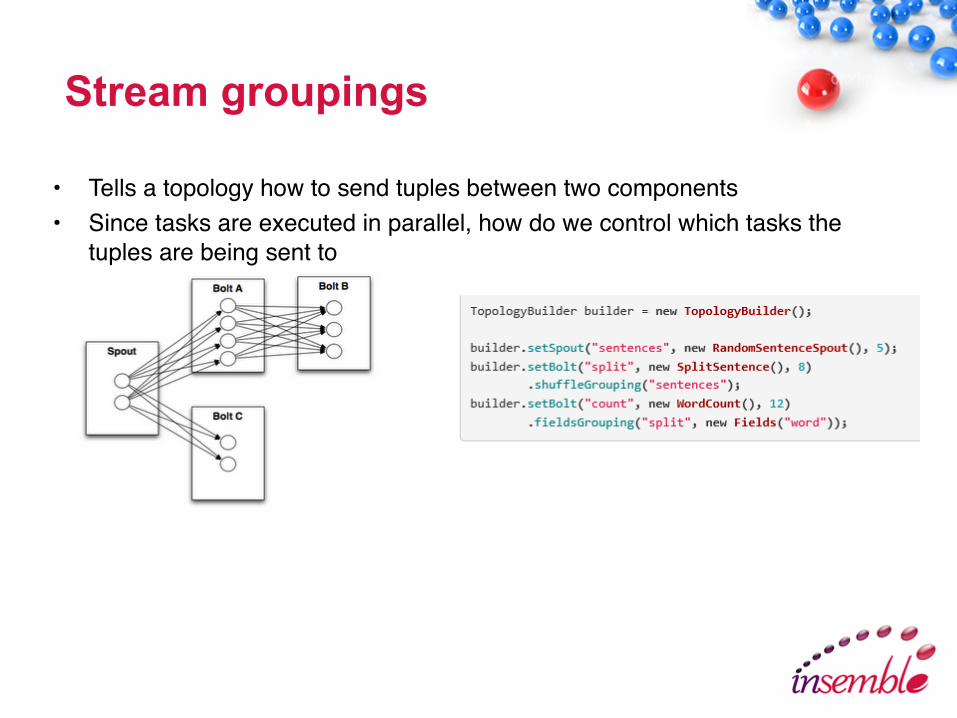
Stream groupings
• Tells a topology how to send tuples between two components• Since tasks are executed in parallel, how do we control which tasks the
tuples are being sent to

Demo - Twitter TopN Trending Topic
• Use Flume Twitter Source to ingest data and publish event to Kafka topic
• Use Storm as an Real-Time event processing system to calculate TopN trending topic
• Use Redis to store the TopN Result• Use Node.js/JQuery for visualization

Flow Chart
Twitter Twitter Source
Flume Agent
Mem Channel Kafka Sink
KafkaKafka SpoutParse Twitter BoltCount Bolt
TopN Ranker Bolt Report Bolt
Storm
RedisNode.js + JQuery
Twitter Source Mem Channel Kafka Sink

Flume Agent — Source

Flume Agent — Channel

Flume Agent — Sink

Storm Topology Design
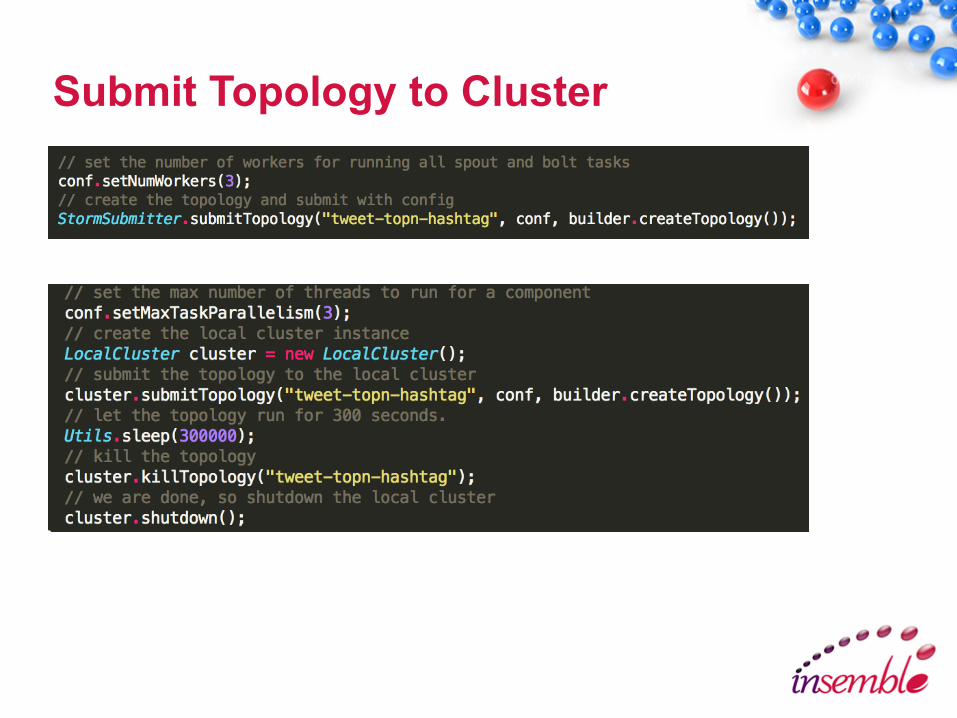
Submit Topology to Cluster

ParseTweetBolt Code

ParseTweetBolt Code

ParseTweetBolt Code






![Experimental Study of Low-Latency HD VoD Streaming Flexible …web.engr.oregonstate.edu/~benl/Publications/Conferences/CCNC201… · Streaming [5], Apple’s HTTP Live Streaming (HLS)](https://img.pdfslide.us/doc/110x75/5ffd40c42f9a673c45486251/experimental-study-of-low-latency-hd-vod-streaming-flexible-webengr-benlpublicationsconferencesccnc201.jpg)






















