Embed Size (px)
Citation preview

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Infrastructure crossroads
Richard Eckart de Castilho UKP LAB
Technische Universität Darmstadt
...and the way we walked them in dkpro

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
PRESENTER
Dr. Richard Eckart de Castilho
• Interoperability WP lead @ OpenMinTeD • Technical Lead @ UKP • Java developer • Open source guy • NLP software infrastructure researcher • Apache UIMA developer • DKPro person
@i_am_rec https://github.com/reckart
Ubiquitous Knowledge Processing Lab Technische Universität Darmstadt

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Ubiquitous knowledge
Processing LAB
• Argumentation Mining • Language Technology for Digital Humanities • Lexical-Semantic Resources &Algorithms • Text Mining & Analytics • Writing Assistance and Language Learning
@UKPLab http://www.ukp.tu-darmstadt.de
Prof. Dr. Iryna Gurevych Technische Universität Darmstadt

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
DKPro – reuse not reinvent • What?
• Collection of open-source projects related to NLP • Community of communities • Interoperability between projects • Target group: programmers, researchers, application developers
• Why? • Flexibility and control – liberal licensing and redistributable software • Sustainability – open community not bound to specific grants • Replicability – portable software distributed through repositories • Usability – the the edge out of installation
• Projects • DKPro Core – linguistic preprocessing, interoperable third-party tools • DKPro TC – text classification experimentation suite • UBY – unified semantic resource • CSniper – integrated search and annotaton • … https://github.io/dkpro

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
… but why like this? … how else could it be done?
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
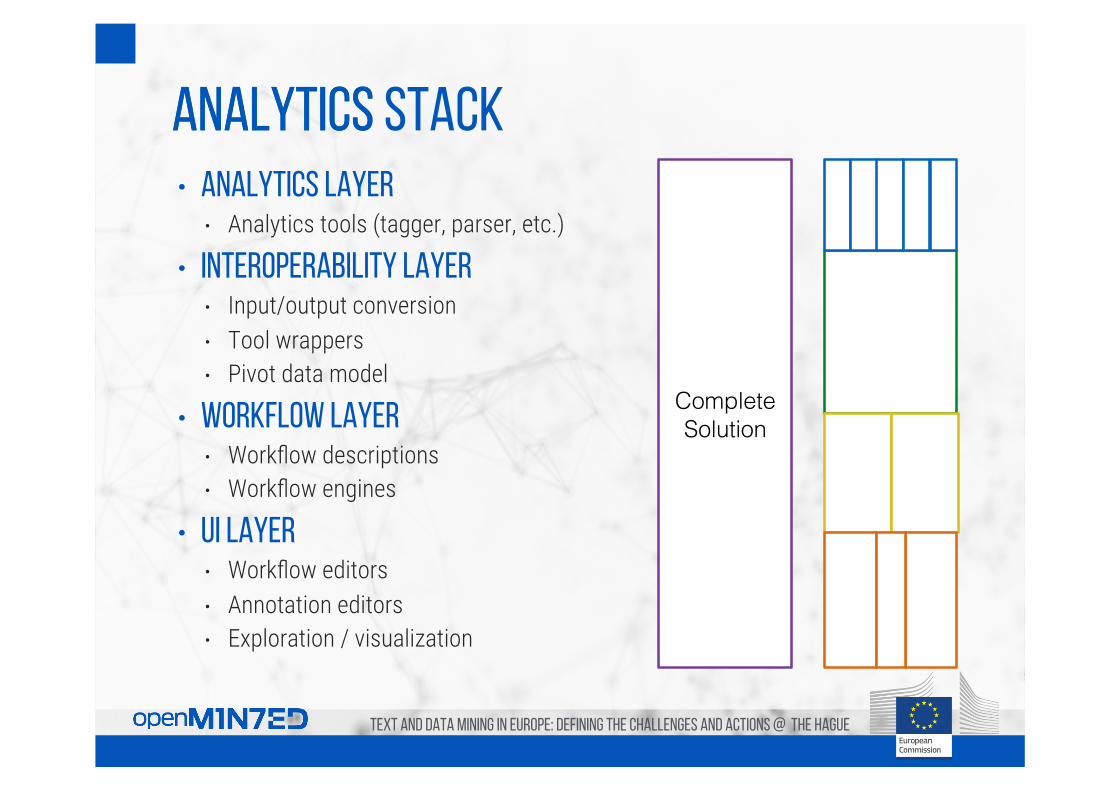
Analytics • Analytics layer
• Analytics tools (tagger, parser, etc.)
• Interoperability layer • Input/output conversion • Tool wrappers • Pivot data model
• Workflow layer • Workflow descriptions • Workflow engines
• UI layer • Workflow editors • Annotation editors • Exploration / visualization
Complete!Solution!
Analytics stack

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Automatic text analysis • pragmatic
• Gain insight about a particular field of interest • Investigate data • Use latest data available • Results relevant for the moment • No need for reproducibility
• principled • Interest in reproducibility • Investigate methods • Use a fixed data set • Results should be reproducible

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Manual text analysis • pragmatic
• Collaborative analysis • Get as much done as quickly as possible • All see/edit the same data / annotations • No means of measuring quality / single truth
• Principled • Training data for supervised machine learning • Evaluation of automatic methods • Distributed analysis • Guideline-driven process • Multiple independent analyses/annotations • Inter-annotator agreement as quality indicator
• Human in the loop • Analytics make suggestions / guide human • Human input guides analystics
Human!Machine!
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
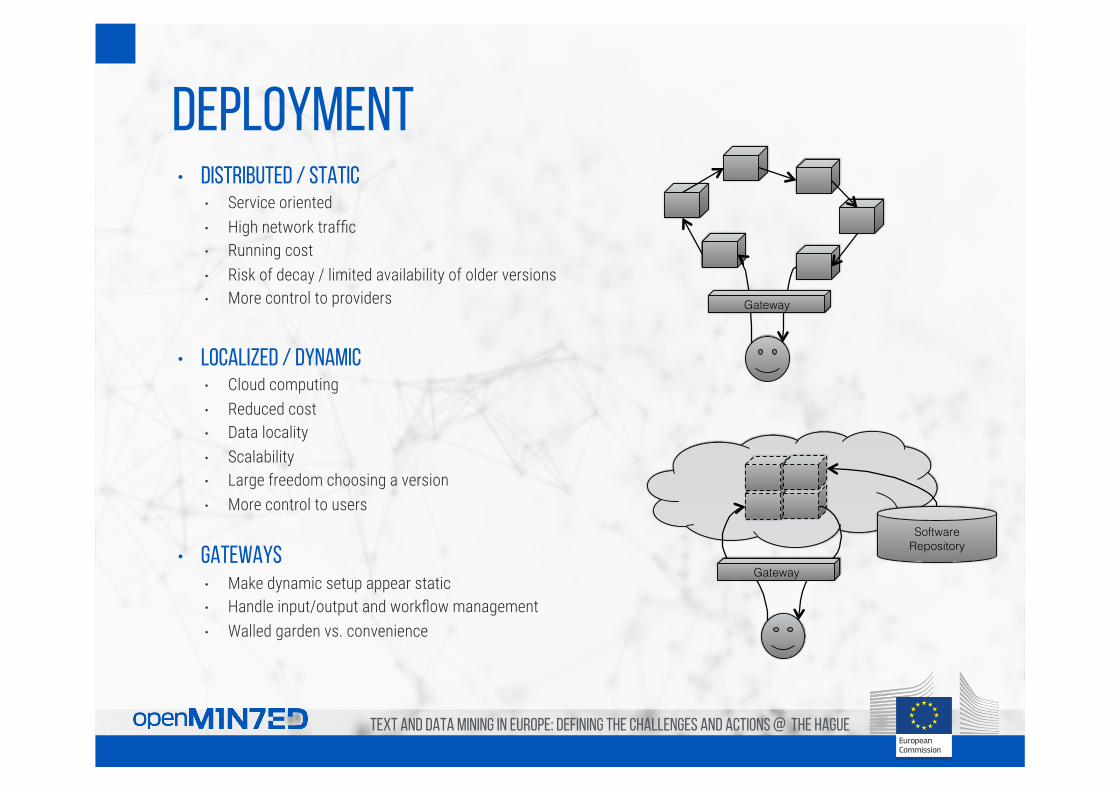
deployment • Distributed / static
• Service oriented • High network traffic • Running cost • Risk of decay / limited availability of older versions • More control to providers
• Localized / dynamic • Cloud computing • Reduced cost • Data locality • Scalability • Large freedom choosing a version • More control to users
• Gateways • Make dynamic setup appear static • Handle input/output and workflow management • Walled garden vs. convenience
Software!Repository!
Gateway!
Gateway!

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
“openness” • Open
• Liberal licensing • Freedom to choose deployment • Integrate custom resources/analytics • Control to the user
• Not open/closed • Copyleft/proprietary licensing • Prescribed deployment • Difficult to customize for the user • Control to the provider

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
A peek at the landscape Service-based
• ARGO* • Pipeline builder, annotation editor • Online platform accessible through
gateway • Internally dynamic deployment (afaik) • Closed source
• Weblicht / Alveo / LAPPS • Pipeline builder • Online platform accessible through
gateway • Many services distributed over multiple
locations/stakeholders • Some offer access to non-public
content/analytics • Some are partially open source
Software-based • DKPro Core* / ClearTK
• Component collection • Pipeline scripting / programming • Repository-based • Easy to deploy/embed anywhere • Open source
• GATE workbench* • Pipeline builder, annotation editor,
+++ • Desktop application • GATE Cloud • Open source • …

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
DKPro Core – Runnable example #!/usr/bin/env groovy @Grab(group='de.tudarmstadt.ukp.dkpro.core', module='de.tudarmstadt.ukp.dkpro.core.opennlp-asl', version='1.5.0')
import de.tudarmstadt.ukp.dkpro.core.opennlp.*; import org.apache.uima.fit.factory.JCasFactory; import org.apache.uima.fit.pipeline.SimplePipeline; import de.tudarmstadt.ukp.dkpro.core.api.segmentation.type.*; import de.tudarmstadt.ukp.dkpro.core.api.syntax.type.*; import static org.apache.uima.fit.util.JCasUtil.*; import static org.apache.uima.fit.factory.AnalysisEngineFactory.*;
def jcas = JCasFactory.createJCas(); jcas.documentText = "This is a test"; jcas.documentLanguage = "en";
SimplePipeline.runPipeline(jcas, createEngineDescription(OpenNlpSegmenter), createEngineDescription(OpenNlpPosTagger), createEngineDescription(OpenNlpParser, OpenNlpParser.PARAM_WRITE_PENN_TREE, true));
select(jcas, Token).each { println "${it.coveredText} ${it.pos.posValue}" } select(jcas, PennTree).each { println it.pennTree }
Fetches all required!dependencies!
No manual installation!!
Input!
Analytics pipeline.!Language-specific!resources fetched !
automatically!
Output!

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
DKPro Core – Runnable example #!/usr/bin/env groovy @Grab(group='de.tudarmstadt.ukp.dkpro.core', module='de.tudarmstadt.ukp.dkpro.core.opennlp-asl', version='1.5.0')
import de.tudarmstadt.ukp.dkpro.core.opennlp.*; import org.apache.uima.fit.factory.JCasFactory; import org.apache.uima.fit.pipeline.SimplePipeline; import de.tudarmstadt.ukp.dkpro.core.api.segmentation.type.*; import de.tudarmstadt.ukp.dkpro.core.api.syntax.type.*; import static org.apache.uima.fit.util.JCasUtil.*; import static org.apache.uima.fit.factory.AnalysisEngineFactory.*;
def jcas = JCasFactory.createJCas(); jcas.documentText = "This is a test"; jcas.documentLanguage = "en";
SimplePipeline.runPipeline(jcas, createEngineDescription(OpenNlpSegmenter), createEngineDescription(OpenNlpPosTagger), createEngineDescription(OpenNlpParser, OpenNlpParser.PARAM_WRITE_PENN_TREE, true));
select(jcas, Token).each { println "${it.coveredText} ${it.pos.posValue}" } select(jcas, PennTree).each { println it.pennTree }
Fetches all required!dependencies!
No manual installation!!
Input!
Analytics pipeline.!Language-specific!resources fetched !
automatically!
Output!
Why is this cool?!
This is an actual running example!!
Requires only !JVM + Groovy (+ Internet connection)!
Easy to parallelize / scale!
Trivial to embed in applications!Trivial to wrap as a service!

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Conclusion / Challenges • Data is growing / analytics get more complex
• Need more powerful systems to process it
• Human in the loop • Human interaction influences analytics and vice versa
• Need to move data and analytics around • Often conflicts with interest in protection of investment
• Need interoperability • To discover data, resources, and analytics • To access data and resources • To deploy analytics • To retrieve and further use results

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
What comes next?
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
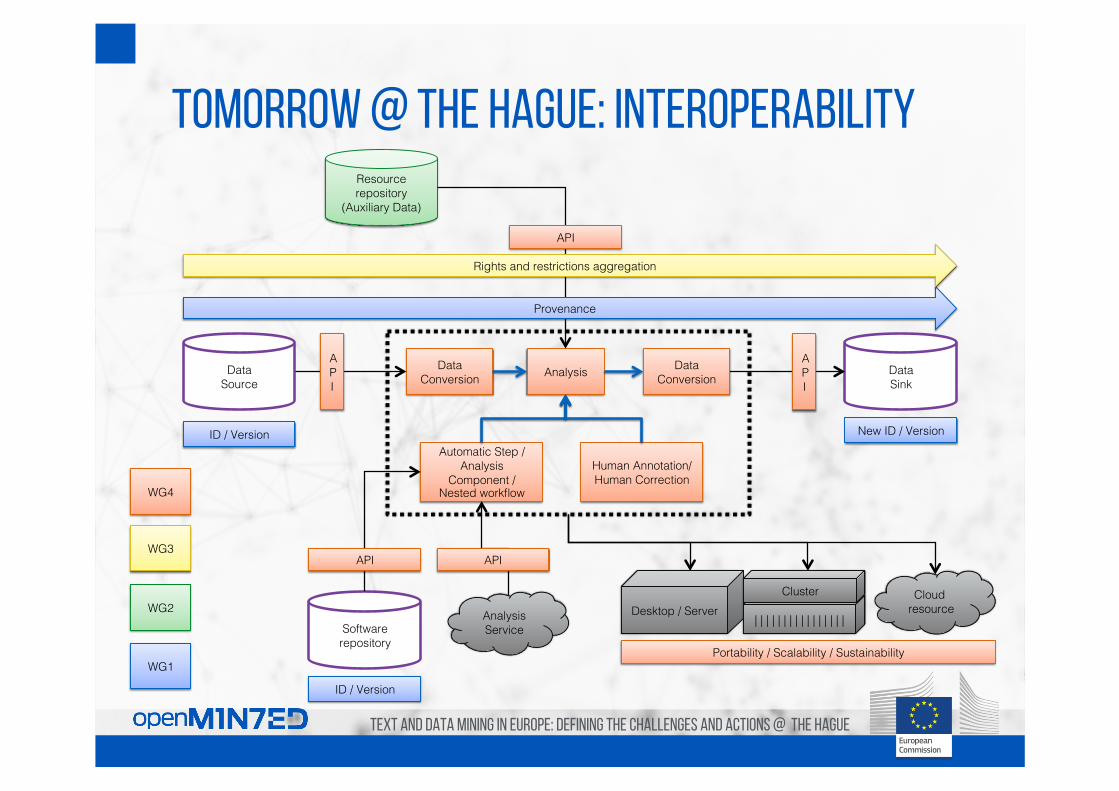
tomorrow @ the hague: interoperability
Data Conversion! Analysis!
Automatic Step /!Analysis
Component /!Nested workflow!
Human Annotation/Human Correction!
Resource repository!
(Auxiliary Data)!
Data!Source!
Data!Sink!
Provenance!
WG1!
WG2!
WG3!
WG4!
Data Conversion!
API!
API!
API!
Software repository!
API!
ID / Version!
ID / Version!
New ID / Version!
Desktop / Server!Cloud !
resource!| | | | | | | | | | | | | | | | !
Cluster!
Portability / Scalability / Sustainability!
Analysis!Service!
API!
Rights and restrictions aggregation!

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
Thanks
Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague

Text and Data Mining in Europe: Defining the Challenges and Actions @ The Hague
References • Alveo http://alveo.edu.au/
• Argo http://argo.nactem.ac.uk
• CLEARTK http://cleartk.github.io/cleartk/
• DKPro https://dkpro.github.io
• Gate https://gate.ac.uk
• Lapps http://www.lappsgrid.org
• UIMA http://uima.apache.org
• Weblicht https://weblicht.sfs.uni-tuebingen.de/