Embed Size (px)
Citation preview

Growing a Data Pipeline for Analytics
Roberto Vitillo, Staff Data Engineer @ Mozilla26th PyData London Meetup



brew install apache-spark


Don’t do it yourself!

Input OutputETL
Storage

JSON
JSON?




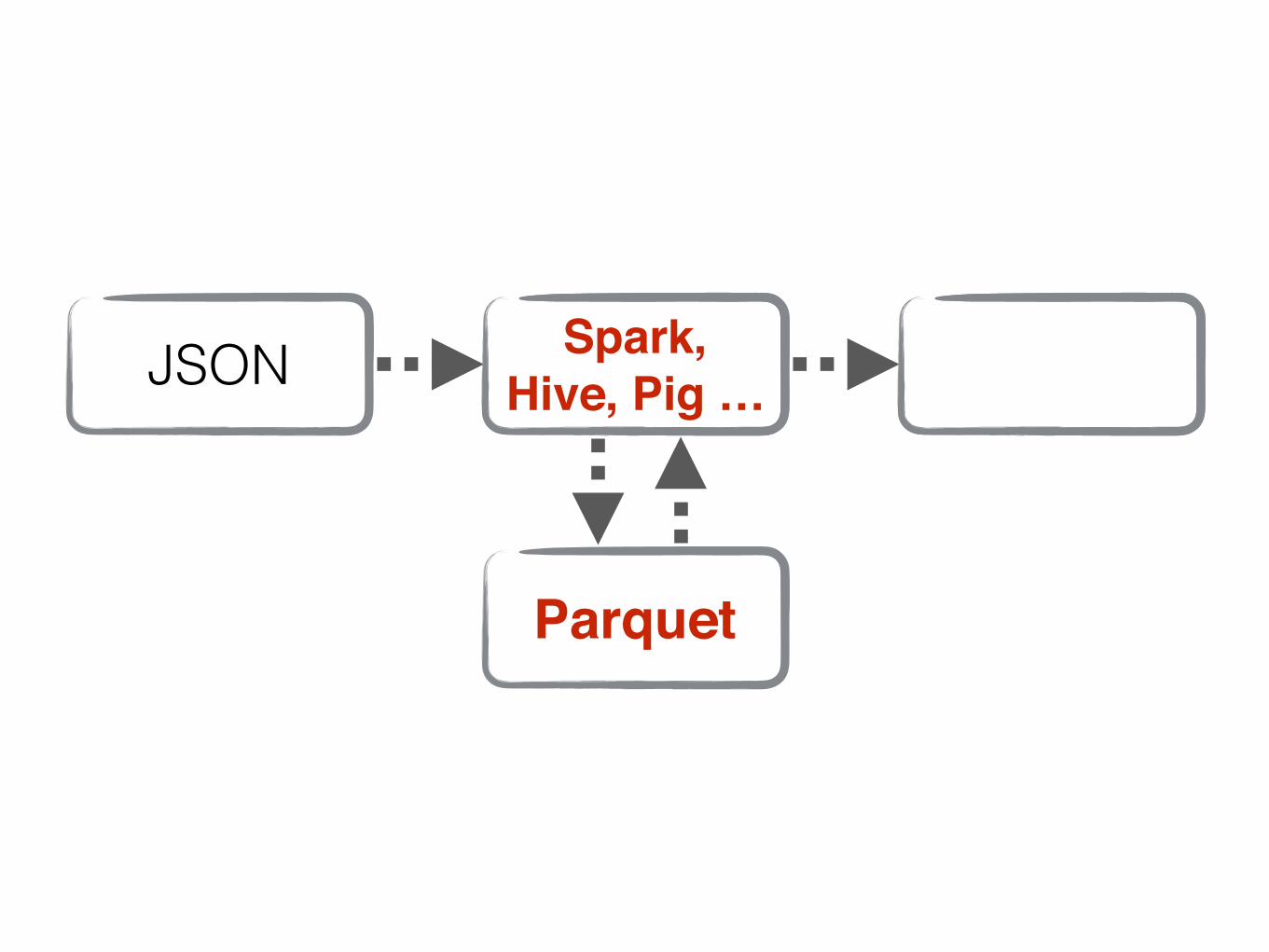
JSON
Parquet
Spark, Hive, Pig …

JSON
Parquet
Spark, Hive, Pig … ???

“The easier it is to ask questions, the more questions will be asked”


Modern SQL supports Map, Arrays & Structs

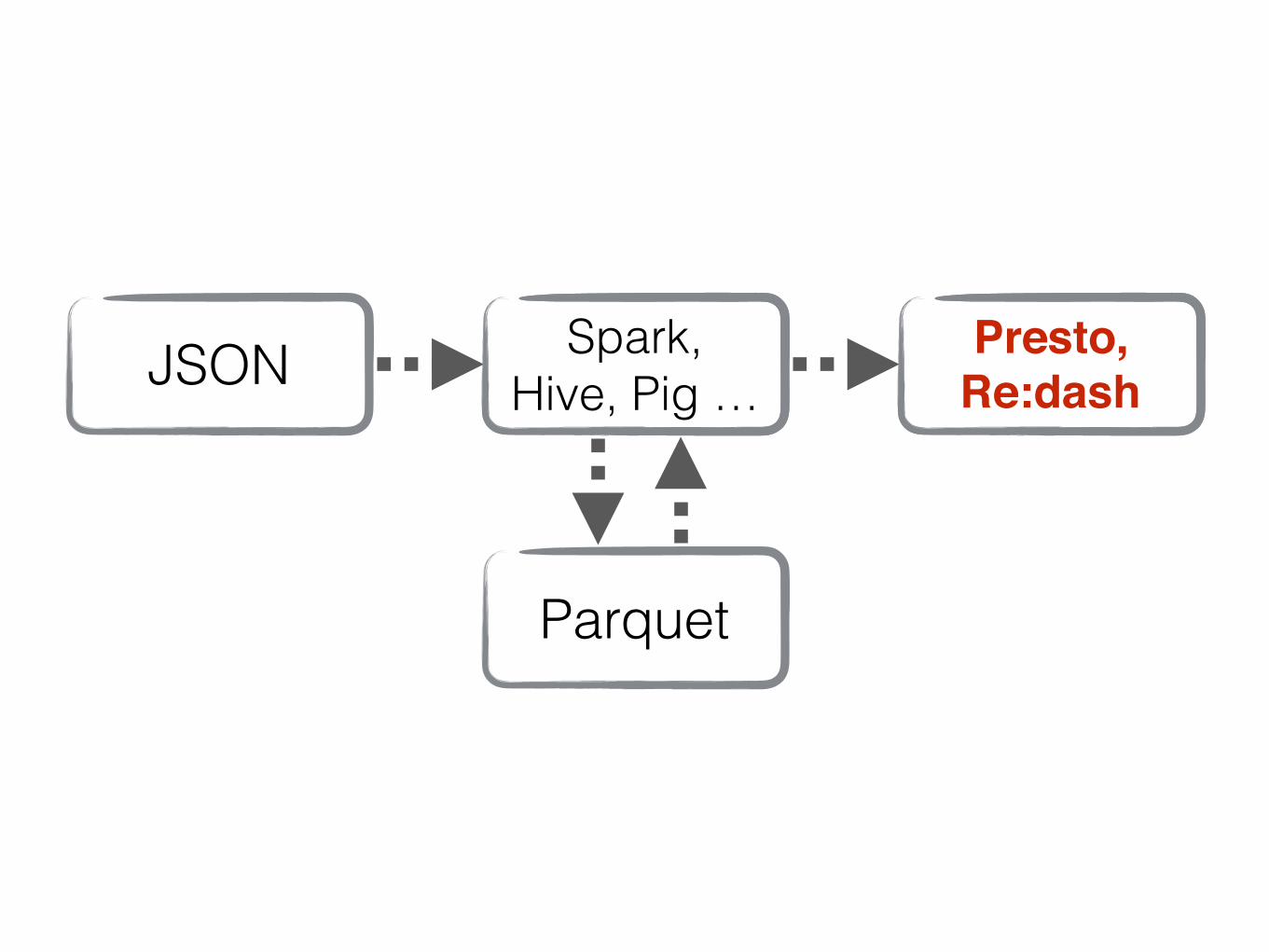
JSON
Parquet
Spark, Hive, Pig …
Presto, Re:dash

TLDR;
• Don’t build your own pipeline unless you really have to
• Use schemas
• Exploit columnar storage
• Use SQL





























