Embed Size (px)
Citation preview

RuntimeImprovementsinBlinkforLargeScaleStreamingatAlibaba
FengWang
Zhijiang Wang
April,2017

Outline
1 Blink Introduction
2 Improvements to Flink Runtime
3 Future Plans

Blink IntroductionSection1

Blink – Alibaba’s version of Flink
üLooked into Flink two since 2 years ago• best choice of unified computing engine• a few of issues inflink that can be problems for large scale applications
üStarted Blink project• aimed to makeFlink workreliablyandefficientlyattheverylargescaleatAlibaba
üMade various improvements in Flink runtime• Runs natively on yarn cluster• failover optimizations for fast recovery• incremental checkpoint for large states• async operatorfor high throughputs
üWorkingwithFlink communitytocontribute changes back sincelast August• several key improvements• hundreds of patches

BlinkEcosystem in Alibaba
Hadoop YARN (Resource Management)
Search
HDFS(Persistent Storage)
Table APIBlink
Alibaba Apps Recommendation BI Security
DataStream API
Runtime Engine
Ads
DataSet API
Machine Learning Platform
SQL

Blink in Alibaba Production
üIn production for almost one year
üRun on thousands of nodes• hundreds of jobs
• The biggest cluster is more than 1000 nodes
• the biggest job has 10s TB states and thousands of subtasks
üSupported key production services on last Nov 11th, China Single’s Day• China Single’s Day is by far the biggest shopping holiday in China, similar to Black Friday in US
• Last year it recorded $17.8 billion worth of gross merchandise volumes in one day
• Blink is used to do real time machine learning and increased conversion by around 30%
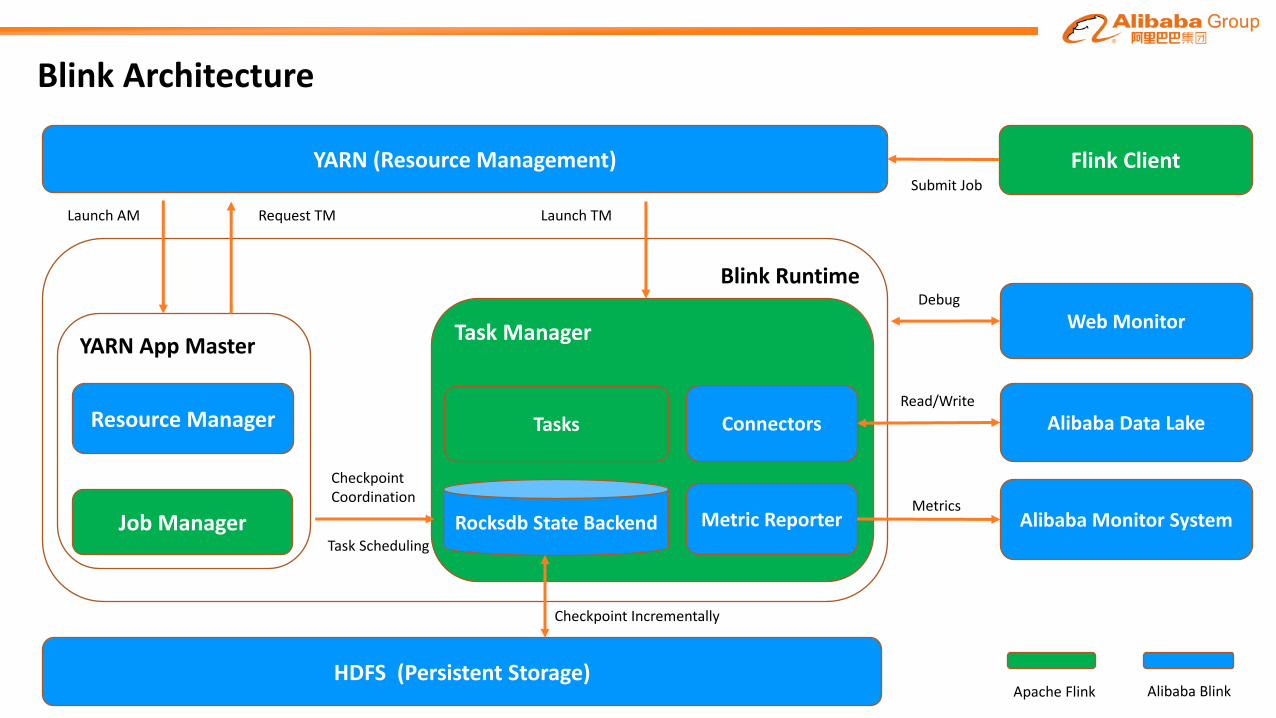
BlinkArchitecture
YARN (Resource Management)
HDFS (Persistent Storage)
Blink Runtime
YARN AppMaster
Resource Manager
Job Manager
Task Manager
Tasks
Rocksdb State Backend
Web Monitor
Flink Client
Alibaba Data Lake
Submit Job
LaunchAM Request TM LaunchTM
Metrics
Apache Flink Alibaba Blink
Alibaba MonitorSystemMetric Reporter
ConnectorsRead/Write
Checkpoint Incrementally
Debug
Task Scheduling
CheckpointCoordination

Improvements to Flink RuntimeSection2

Improvements to Flink Runtime
üNative integration with Resource Management• Take YARN for an Example
üPerformance Improvements• Incremental Checkpoint
• Asynchronous Operator
üFailover Optimization• Fine-grained RecoveryforTaskFailures
• Allocation ReuseforTaskRecovery
• Non-disruptiveJobManager failurerecovery

Native integration with Resource Management
üBackground• Cluster resource is allocated upfront. The resource utilization can benotefficient
• A single JobManager handles all the jobs, which limits the scale of the cluster

Native integration with Resource Management
ResourceManager(Standalone, YARN, Mesos,…)
JobManager (Per Job) TaskManager
1. Request Slot (Resource Spec) 2. Launch
3. Register
4. Request Slot
5. Offer Slot

Native integration with YARN
YARN ClusterYARN ResourceManager
TaskManagerYARN Application Master
ResourceManager
JobManager TaskManager
Client2. Submit Job(JobGraph, Libraries)
3. Launch YARN AM(JobGraph, Libraries)
5. Start RM
4. Start JM
6. Requests Slots(Resource Spec)
7. Requests Container
8. Launch TM container(Libraries)
9. Register
10. Request Slot
11. Offer Slot
1. Execute Job
JobGraph Libraries

Incremental Checkpoint
üBackground• The job state could beverylarge(many TBs)
• Thestatesizeofindividualtaskcan be many GBs
üThe problems of Full Checkpoint• Materializeallthestatestopersistentstoreateachcheckpoint
• Asthestatesgetbigger,materialization maytaketoo much timetofinish
• One of the biggest blocking issues in large scale production
üBenefits of Incremental Checkpoint• Only the modified states since last checkpoint needtobe materialized
• The checkpoint will be fasterand more efficient
Task Manager
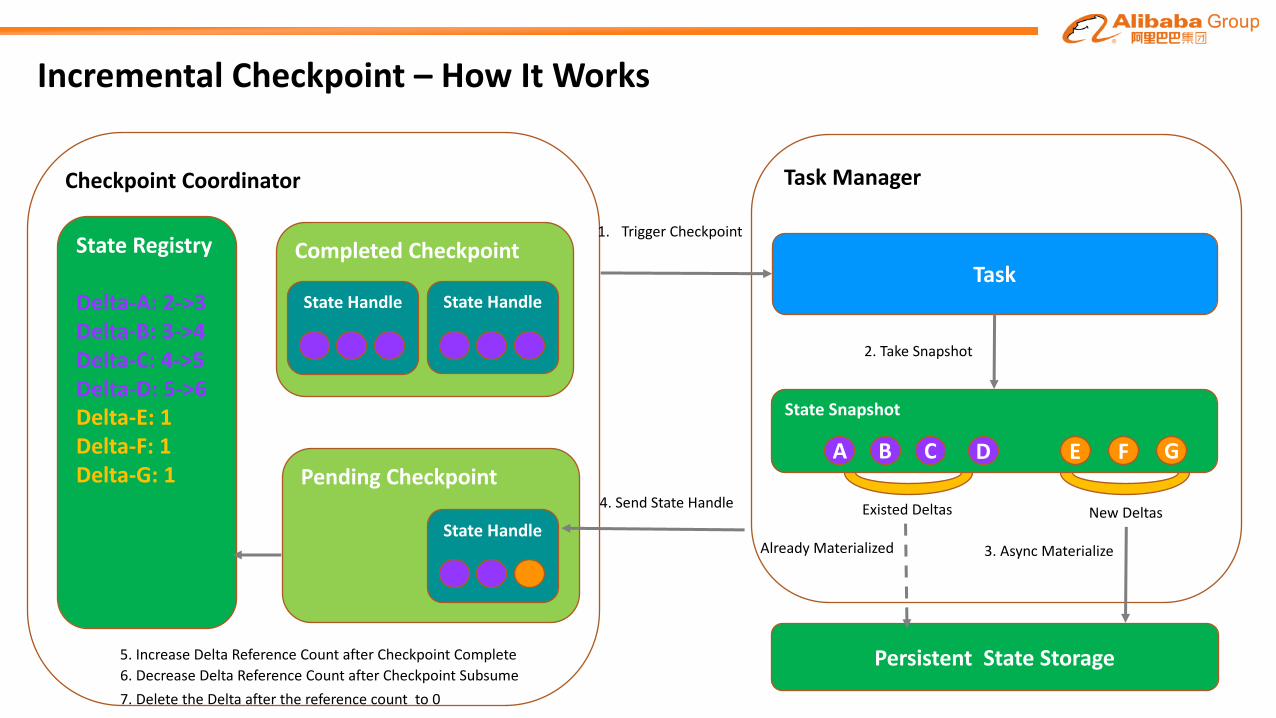
Incremental Checkpoint – How ItWorks
Checkpoint Coordinator
State Registry
Delta-A:2->3Delta-B:3->4Delta-C:4->5Delta-D:5->6Delta-E:1Delta-F:1Delta-G: 1
State Snapshot
A B C D E F G
Persistent State Storage
Task
1. Trigger Checkpoint
Pending Checkpoint
5. Increase Delta Reference Count after Checkpoint Complete
4. Send State Handle
3. Async Materialize
2. Take Snapshot
Existed Deltas New Deltas
Already Materialized
Completed Checkpoint
State Handle State Handle
State Handle
6. Decrease Delta Reference Count after Checkpoint Subsume7. Delete the Delta after the reference count to 0

Incremental Checkpoint - RocksDB State Backend Implementation
RocksDB Instance in TM for KeyGroups[0-m]
.sst .sst .sst
data
1.sst 2.sst 3.sst
chk-1
2.sst 3.sst 4.sst
chk-2
HDFS://user/JobID/OperatorID/KeyGroup_[0-m]data
3.sst.chk-1 4.sst.chk-21.sst.chk-1 2.sst.chk-1
JobManager
Completed Checkpoint 1
State Handles
Completed Checkpoint 2
State Handles

Asynchronous Operator
üBackground• Flink task use a singlethreadto process events
• Flink tasksometimes need to accessexternalservices (hbase, redis,…)
üProblem• The high latency may block the event processing
• Throughput can be limited by latency
üBenefits of Asynchronous Operator• Decouple thethroughputoftaskfrom the latencyofexternalsystem
• Improve the CPU utilizationofthe Flink tasks
• Simplify resource specification for Flink jobs

Asynchronous Operator– HowItWorks
AsyncOperator(ordered/unordered)
AsyncQueue (Ordered/UnOrdered)
AsyncFunction
3. asyncInvoke(InputRecord, StreamRecordQueueEntry)
ListenableFunture
1. processElement(InputRecord)
Listener
Emit Thread
11. notify
InputRecord
OutputRecord
ExternalSystem
4. asyncRequest(request)
9. notify
UserAsyncClient5. send request
8. asyncResponse
12. emit(OutputRecord)
10. StreamRecordQueueEntry.collect(OutputRecord)
2.add(StreamRecordQueueEntry)
HBase
Cassandra
Redis
… 6. return
StreamRecordQueueEntry
OutputRecordInputRecord
Sync ASync
AsyncCollector
Implements
7. add listener
StreamRecordQueueEntry
OutputRecordInputRecord

Asynchronous Operator– How ItManages State
State Backend
AsyncOperator
AsyncFunction
1. open2. Get Uncompleted InputRecords
3. asyncInvoke
1. snapshotState
2. Scan
3. Persist Uncompleted InputRecords
AsyncQueue
StreamRecordQueueEntry StreamRecordQueueEntry
OutputRecordInputRecord InputRecordOutputRecord
Task
RecoverySnapshot

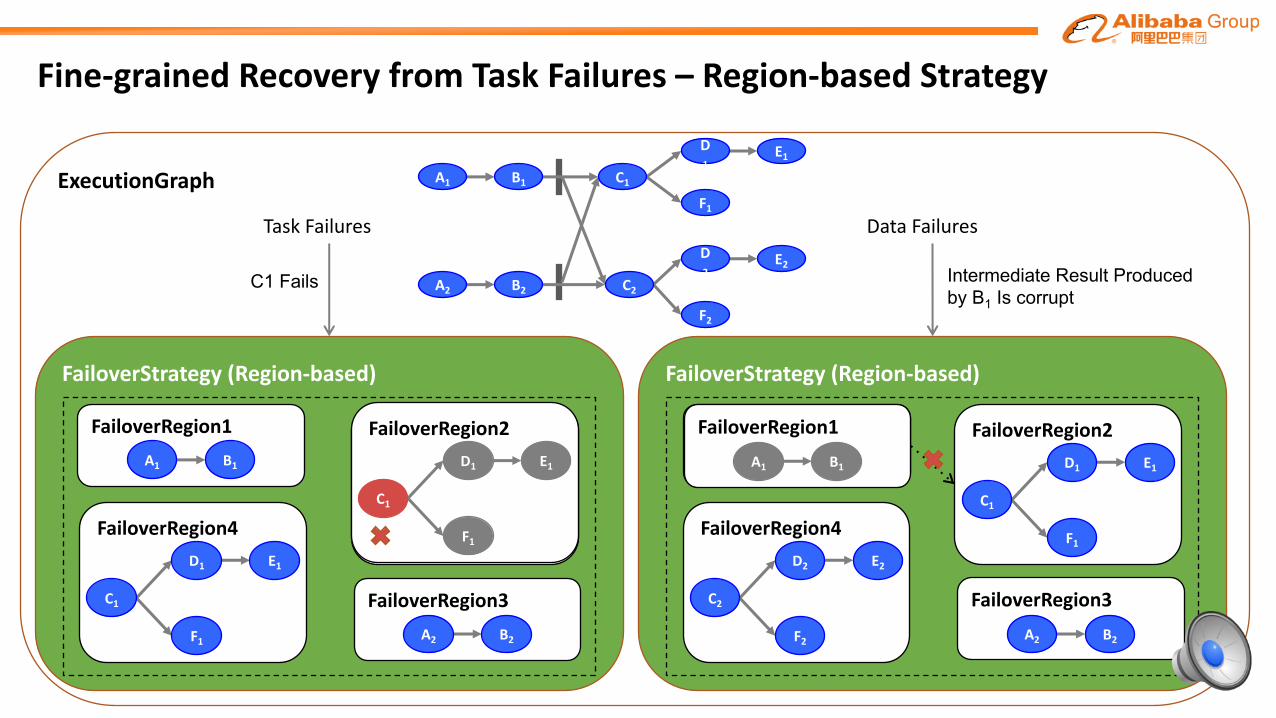
Fine-grainedRecoveryfromTaskFailures
üStatusofbatchjob• Largescaletothousandsofnodes
• Nodefailuresarecommoninlargeclusters
• Prefernon-pipelinedmodeduetolimitedresource
üProblems• Onetaskfailureneedstorestarttheentireexecutiongraph
• Itisespeciallycriticalforbatchjobs
üBenefit• Makerecoverymoreefficientbyrestartingonlywhatneedstoberestarted

Fine-grainedRecoveryfromTaskFailures– Restart-allStrategy
ExecutionGraph
A1 B1 C1
D1 E1
F1
B2 C2
D2 E2
F2
A2
CachingResult
PipelinedResult
JobLevelCommands
FailoverStrategy (Restart-all)
TaskLevelFailures
A1 B1 C1
D1 E1
F1
B2 C2
D2 E2
F2
A2
(C1Fails)Fail,Cancel
FailoverStrategy (Region-based)
FailoverRegion4gion
C2
D2 E2
F2
FailoverRegion3gionB2A2
FailoverRegion1nB1A1
FailoverRegion2gion
C1
D1 E1
F1
Fine-grainedRecoveryfromTaskFailures– Region-basedStrategy
ExecutionGraph A1 B1 C1
D1
E1
F1
B2 C2
D2
E2
F2
A2
FailoverStrategy (Region-based)
FailoverRegion3gion
C2
D2 E2
F2
FailoverRegion1nB1A1
FailoverRegion3gionB2A2
FailoverRegion4ion
C1
D1 E1
F1
TaskFailures
C1 Fails
FailoverRegion2gion
C1
D1 E1
F1
DataFailures
Intermediate Result Produced by B1 Is corrupt
FailoverRegion1nB1A1

AllocationReuseforTaskRecovery
üBackground• ThejobstatecanbeverybiginAlibaba,henceuseRocksDB asstatebackend
• StaterestorebyRocksDB backendinvolvesincopyingdatafromHDFS
üProblem• ItisexpensivetorestorestatefromHDFSduringtaskrecovery
üBenefitsofAllocationReuse• Deploytherestartedtaskinpreviousallocationtospeeduprecovery
• RestorestatefromlocalRocksDB toavoidcopyingdatafromHDFS

ExecutionVertex
Execution(Attempt=1)
JobManager
AllocationReuseforTaskRecovery– HowItWorks
PriorExecutionList
Execution(Attempt=1)
4.AddExecutionExecution(Attempt=2)
5.GetPreferredLocation
6.AllocateSlot(TMLocation,ResourceProfile)
SlotPool
1.ReturnAllocatedSlot
AllocatedSlotgion
2.RemoveSlot
AvailableSlotgion
Map<TMLocation,Set<AllocatedSlot>>
3.AddAllocatedSlot
7.Match&ReturnSlot

Non-disruptiveJobManagerFailuresviaReconciliation
üBackground• Thejobislargescaletothousandsofnodes
• ThejobstatecanbeverybiginTBlevel
üProblems• Allthetasksarerestartedforjobmanagerfailures
• Thecostishighforrecoveringstates
üBenefit• Improvejobstabilitybyautomaticreconciliationtoavoidrestartingtasks

JobManager
ExecutionGraphreconcile
RECONCILING
Non-disruptiveJobManagerFailuresviaReconciliation– HowItworks
RunningJobsRegistry
isJobRunning =true
RUNNING|FINISHED|FAILING
StateTransition ExecutionGraph
Timer
JobManagerRunner
LeaderChange
Register&ReportTaskSlotStatusRegister&OfferSlots
TaskManager
Slot
Task
Slot
Task
TaskManager
Slot
Task
Slot
Task
JobManager
ExecutionGraph
JobManagerRunner
ScheduleRunningJobsRegistry
isJobRunning =false
Schedule

Future PlansSection3

Future Plans
üBlinkisalreadypopularinthestreamingscenarios• more and more streaming applications will run on blink
üMakebatch applicationsrun on production• increasetheresourceutilizationoftheclusters
üBlink as Service• AlibabaGroupWide
üClusterisgrowingveryfast• clustersize will double
• thousandsofjobs run on production