Embed Size (px)
Citation preview

Faces in Places: compound query retrievalY. Zhong, R. Arandjelovic and A. Zisserman: Paper LinkBMVC 2016
1Slides by Eva Mohedano and Andrea Calafell [GDoc]UPC Computer Vision Reading Group (14/10/2016)

Outline
2
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary
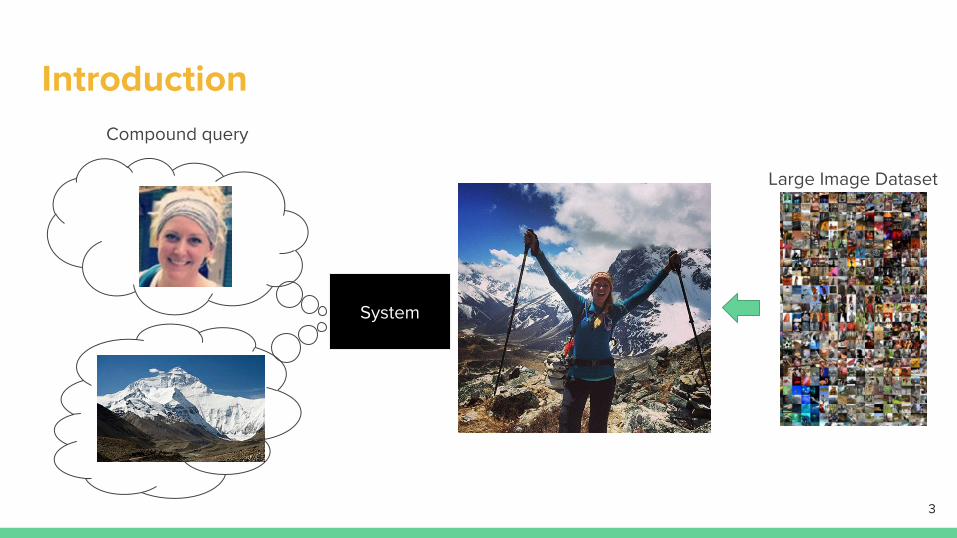
Introduction
Large Image Dataset
System
3
Compound query

Introduction
Three contributions:
1. Hybrid CNN to produce place descriptors that are aware of faces and their descriptors.
2. Collect and annotate a dataset of real images containing celebrities in different places.
3. Image synthesis system to render high quality fully-labelled face-and-place images to train the network.
4

Outline
5
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary
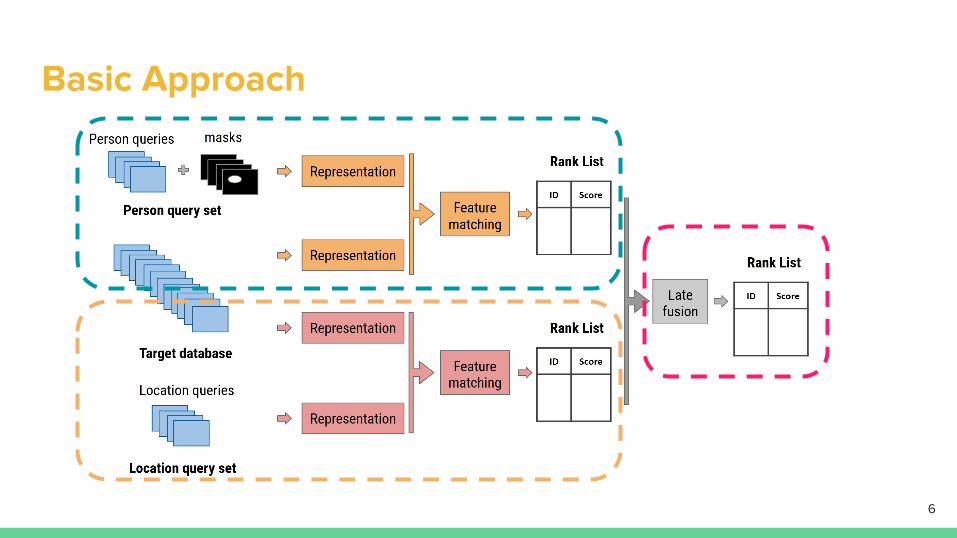
Basic Approach
6
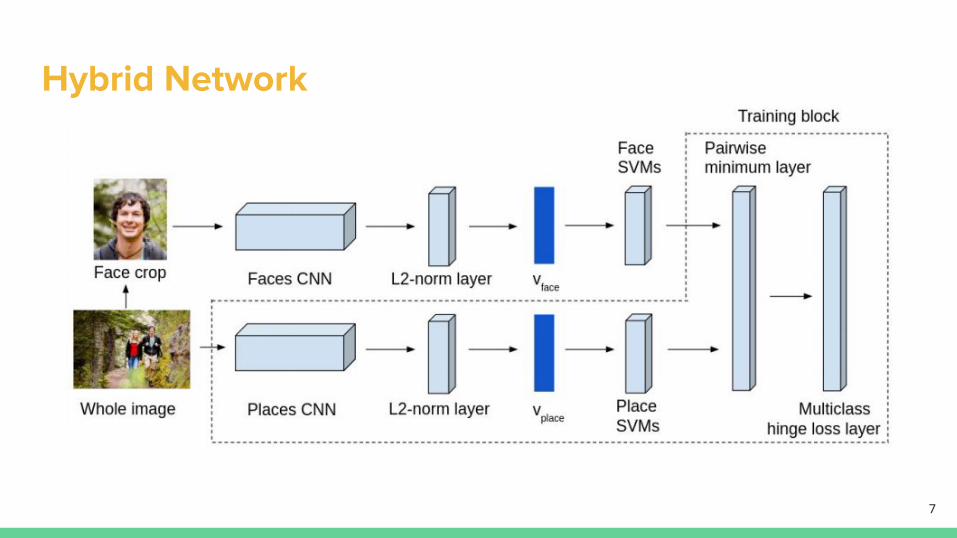
Hybrid Network
7
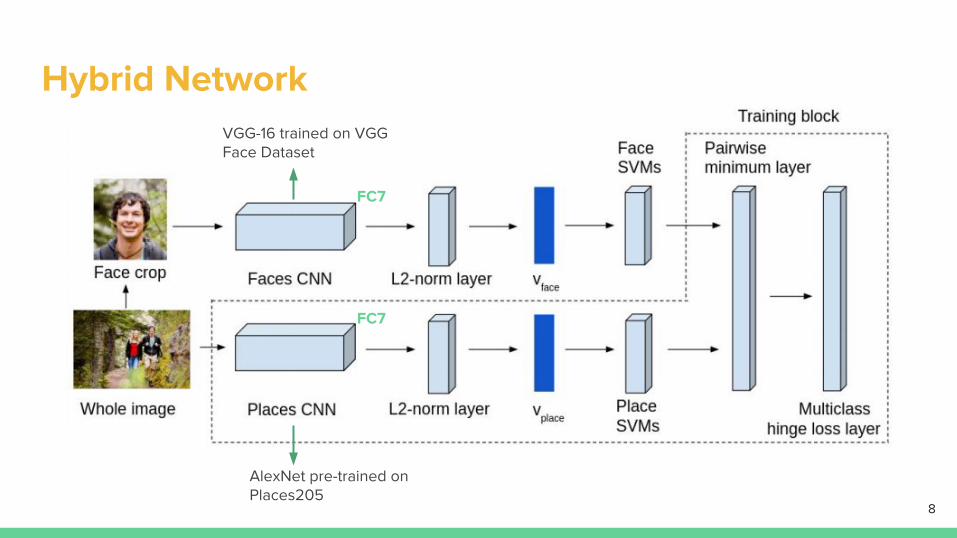
Hybrid Network
8
AlexNet pre-trained on Places205
VGG-16 trained on VGG Face Dataset
FC7
FC7

Outline
9
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary

The “Celebrity in Places” Dataset
10
Example images from the CIP dataset
Includes:● 4611 celebrities● 16 places
Query texts in Google Image
Search
2,5M images Duplicate
removal
170K images Mechanical
Turk annotation
38K images
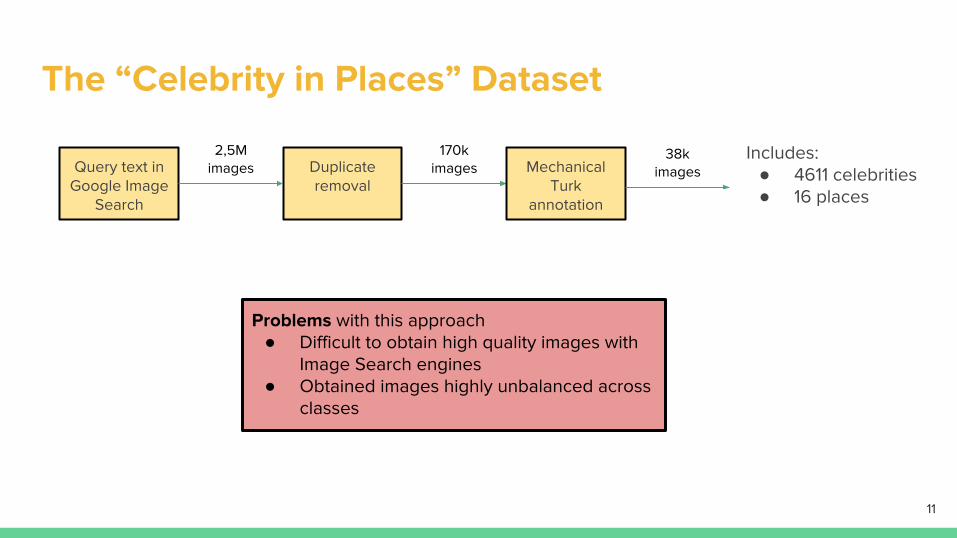
The “Celebrity in Places” Dataset
11
Includes:● 4611 celebrities● 16 places
Query text in Google Image
Search
2,5M images Duplicate
removal
170k images Mechanical
Turk annotation
38k images
Problems with this approach● Difficult to obtain high quality images with
Image Search engines● Obtained images highly unbalanced across
classes

Outline
12
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary

Synthetic Training Images
13

Synthetic Training Images
14
178k training images8.7k validation images
Includes:● 500 faces● 16 places

Outline
15
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary
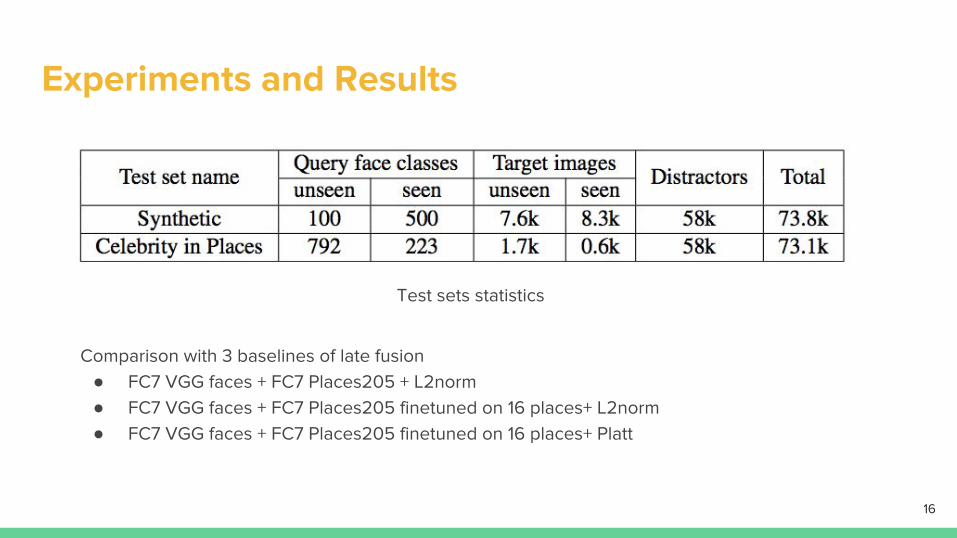
Experiments and Results
16
Comparison with 3 baselines of late fusion● FC7 VGG faces + FC7 Places205 + L2norm● FC7 VGG faces + FC7 Places205 finetuned on 16 places+ L2norm● FC7 VGG faces + FC7 Places205 finetuned on 16 places+ Platt
Test sets statistics

Experiments and Results
17

Outline
18
1. Introduction
2. Hybrid Network
3. The “Celebrity in Places” Dataset
4. Synthetic Training Images
5. Experiments and Results
6. Summary

Summary
19
● They have presented a hybrid network for compound queries, where place descriptors are aware of faces and face descriptors. This network outperforms the baselines.
● They have designed an automatic pipeline to synthesize training images.
● They have collected a new dataset of real images to evaluate their methods.

Questions?
20









![Content Based Image Retrieval using Query by Approximate … · Retrieval (KBIR), Semantic Based Image Retrieval (SBIR) and Content Based Image Retrieval (CBIR) [1]. The KBIR methods](https://img.pdfslide.us/doc/110x75/604cc727f7fc662d1d5e1fe3/content-based-image-retrieval-using-query-by-approximate-retrieval-kbir-semantic.jpg)



















