Embed Size (px)
Citation preview
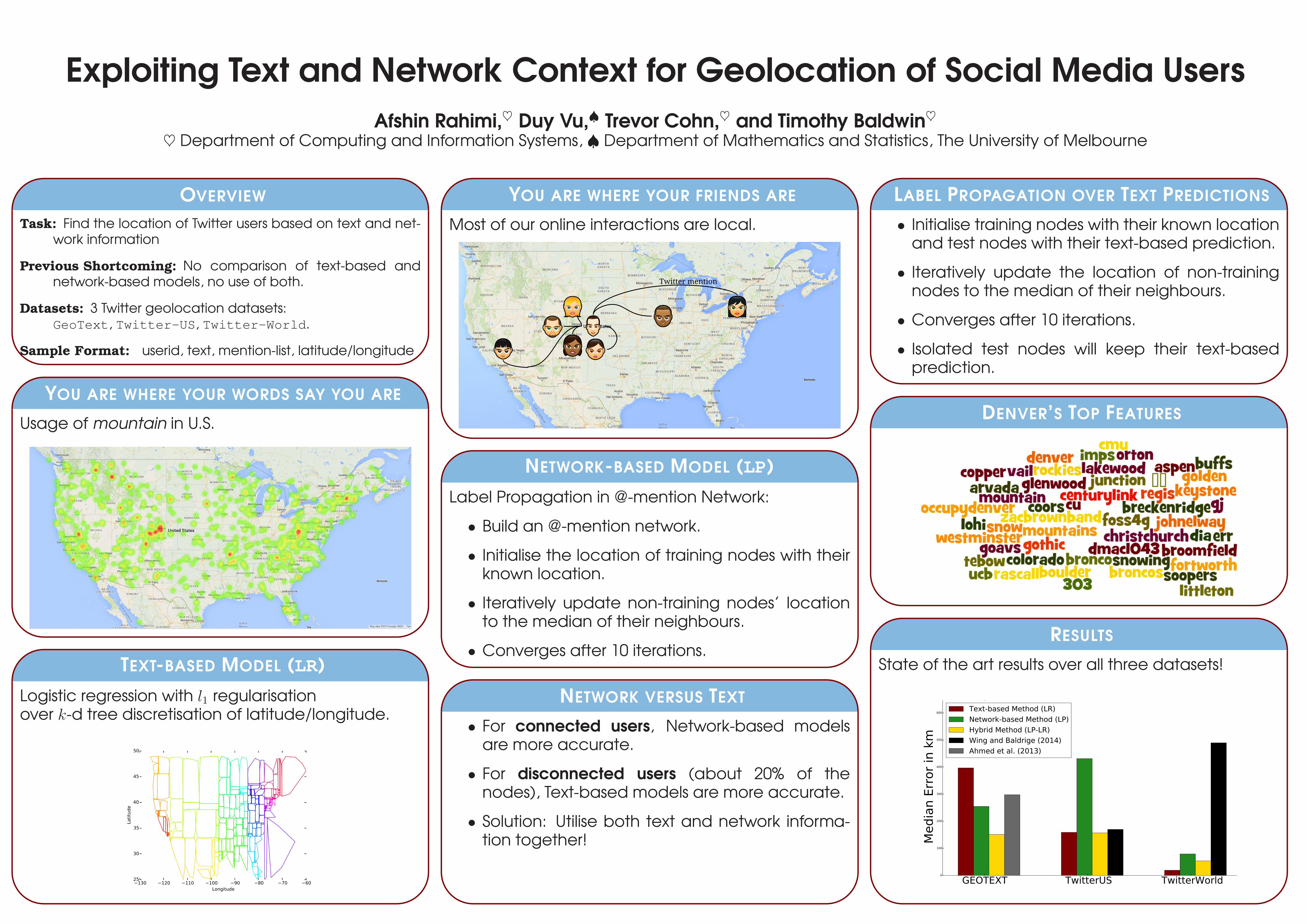
Exploiting Text and Network Context for Geolocation of Social Media UsersAfshin Rahimi,♥ Duy Vu,♠ Trevor Cohn,♥ and Timothy Baldwin♥
♥ Department of Computing and Information Systems, ♠ Department of Mathematics and Statistics, The University of Melbourne
OVERVIEW
Task: Find the location of Twitter users based on text and net-work information
Previous Shortcoming: No comparison of text-based andnetwork-based models, no use of both.
Datasets: 3 Twitter geolocation datasets:GeoText, Twitter-US, Twitter-World.
Sample Format: userid, text, mention-list, latitude/longitude
YOU ARE WHERE YOUR WORDS SAY YOU ARE
Usage of mountain in U.S.
TEXT-BASED MODEL (LR)
Logistic regression with l1 regularisationover k-d tree discretisation of latitude/longitude.
130 120 110 100 90 80 70 60Longitude
25
30
35
40
45
50
Lati
tude
YOU ARE WHERE YOUR FRIENDS ARE
Most of our online interactions are local.
Twitter mention
NETWORK-BASED MODEL (LP)
Label Propagation in @-mention Network:
• Build an @-mention network.
• Initialise the location of training nodes with theirknown location.
• Iteratively update non-training nodes’ locationto the median of their neighbours.
• Converges after 10 iterations.
NETWORK VERSUS TEXT
• For connected users, Network-based modelsare more accurate.
• For disconnected users (about 20% of thenodes), Text-based models are more accurate.
• Solution: Utilise both text and network informa-tion together!
LABEL PROPAGATION OVER TEXT PREDICTIONS
• Initialise training nodes with their known locationand test nodes with their text-based prediction.
• Iteratively update the location of non-trainingnodes to the median of their neighbours.
• Converges after 10 iterations.
• Isolated test nodes will keep their text-basedprediction.
DENVER’S TOP FEATURES
RESULTS
State of the art results over all three datasets!
GEOTEXT TwitterUS TwitterWorld0
100
200
300
400
500
600
Med
ian
Erro
r in
km
Text-based Method (LR)Network-based Method (LP)Hybrid Method (LP-LR)Wing and Baldrige (2014)Ahmed et al. (2013)




























