Embed Size (px)
Citation preview

Location:
QuantUniversity Meetup
February 23rd 2017
Boston MA
Deep Learning & SparkPart III
2017 Copyright QuantUniversity LLC.
Presented By:
Sri Krishnamurthy, CFA, CAP
www.QuantUniversity.com
2
Slides and Code will be available at: http://www.analyticscertificate.com/DeepLearning
- Analytics Advisory services- Custom training programs- Architecture assessments, advice and audits- Trained more than 500 students in Quantitative methods, Data Science and Big Data Technologies using MATLAB, Python and R

• Founder of QuantUniversity LLC. and www.analyticscertificate.com
• Advisory and Consultancy for Financial Analytics• Prior Experience at MathWorks, Citigroup and
Endeca and 25+ financial services and energy customers.
• Regular Columnist for the Wilmott Magazine• Author of forthcoming book
“Financial Modeling: A case study approach”published by Wiley
• Charted Financial Analyst and Certified Analytics Professional
• Teaches Analytics in the Babson College MBA program and at Northeastern University, Boston
Sri KrishnamurthyFounder and CEO
4

5
• March 2017▫ QuantUniversity Meetup – March 23rd
▫ Deep Learning Workshop – Boston – March 27-28
• April 2017▫ Deep Learning Workshop – New York - April 5-6
▫ Anomaly Detection Workshop – Boston – April 24-25
• May 2017
▫ Anomaly Detection Workshop- New York - May 2-3
Events of Interest
http://www.analyticscertificate.com/DeepLearning

6
• Part 1: Deep Neural Networks and CNNs▫ https://www.slideshare.net/QuantUniversity/deep-learning-70411004
• Part 2 : RNNs and AutoEncoders▫ https://www.slideshare.net/QuantUniversity/deep-learning-tutorial-
part-2
Slides from past presentations
7
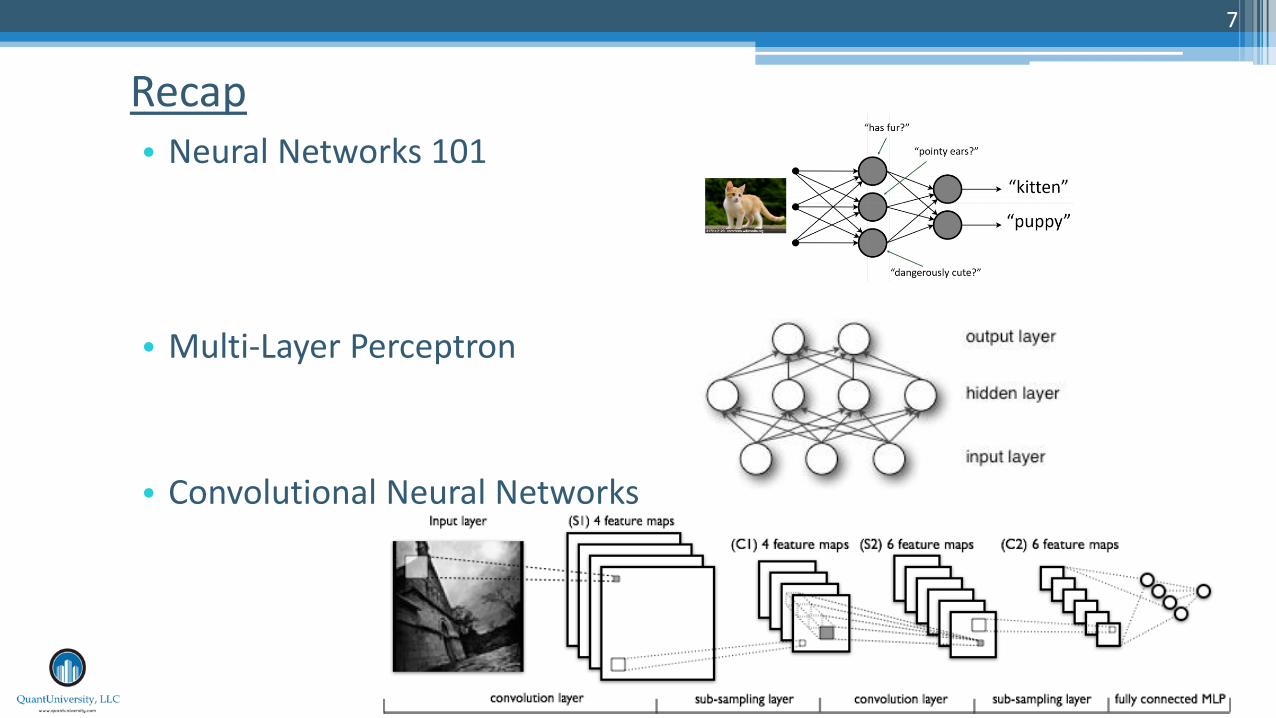
• Neural Networks 101
• Multi-Layer Perceptron
• Convolutional Neural Networks
Recap
8
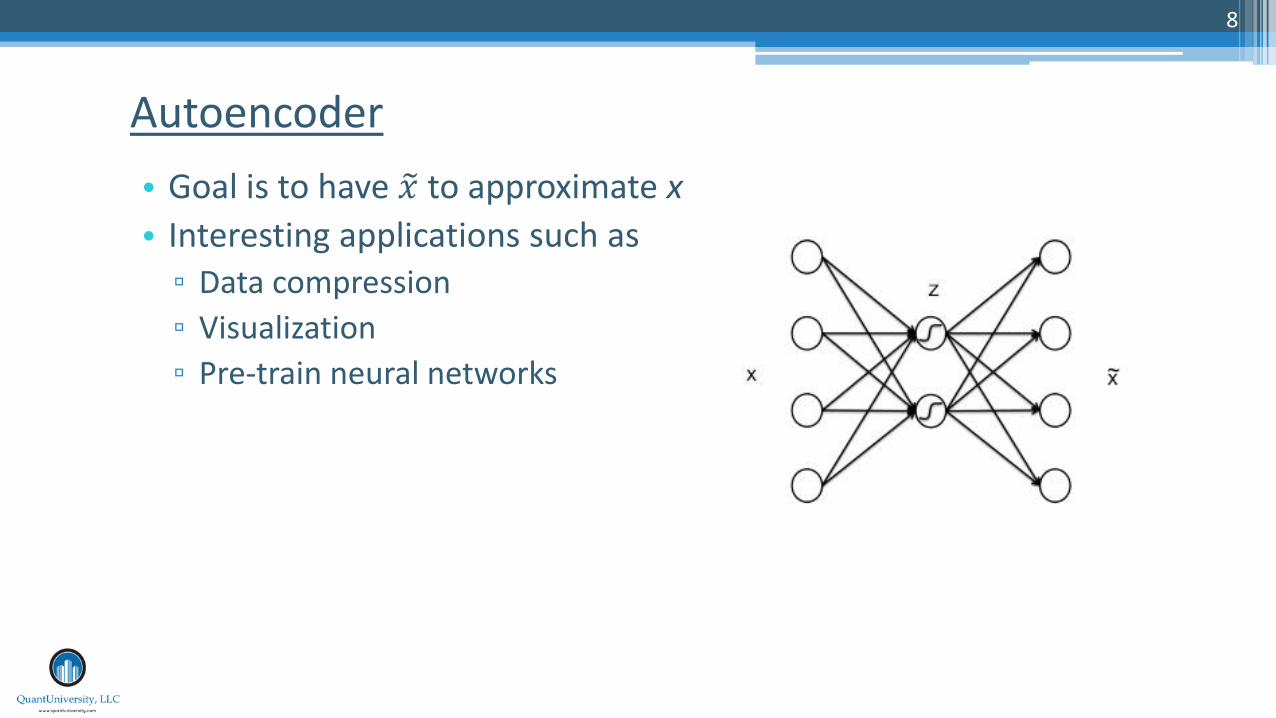
• Goal is to have 𝑥 to approximate x
• Interesting applications such as ▫ Data compression
▫ Visualization
▫ Pre-train neural networks
Autoencoder

9
• Has 3 types of parameters▫ W – Hidden weights
▫ U – Hidden to Hidden weights
▫ V – Hidden to Label weights
• All W,U,V are shared
Recurrent Neural Networks1
1. http://ai.stanford.edu/~quocle/tutorial2.pdf

10
• Neural Networks are resource intensive▫ Typically require huge dedicated hardware (RAM, GPUs)
• Parameter space huge! – 100s of thousands of parameters▫ Tuning is important
• Architecture choice is important:▫ See http://www.asimovinstitute.org/neural-network-zoo/
Key takeaways from modeling Deep Neural Networks

What is Spark ?
• Apache Spark™ is a fast and general engine for large-scale data processing.
• Run programs up to 100x faster than Hadoop MapReduce
in memory, or 10x faster on disk.
Lightning-fast cluster computing
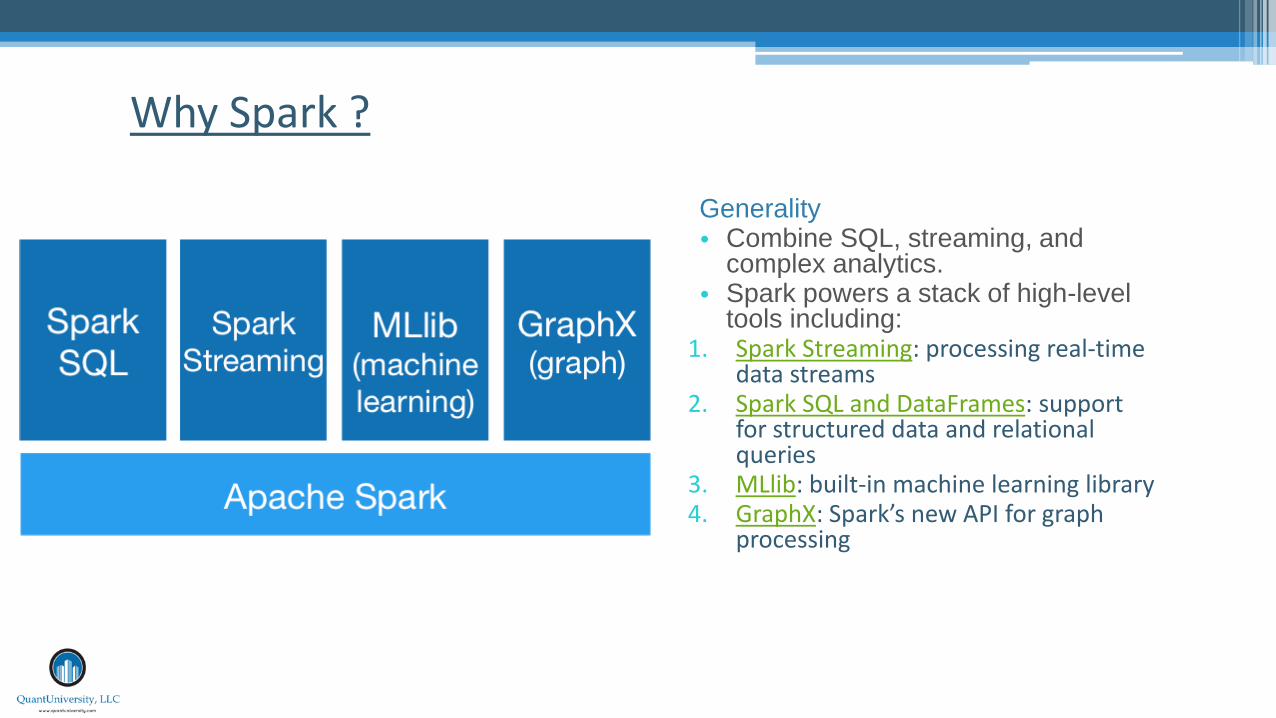
Why Spark ?
Generality• Combine SQL, streaming, and
complex analytics.• Spark powers a stack of high-level
tools including:1. Spark Streaming: processing real-time
data streams2. Spark SQL and DataFrames: support
for structured data and relational queries
3. MLlib: built-in machine learning library4. GraphX: Spark’s new API for graph
processing

13
• Investment : Enterprises have significantly invested in Big-Data infrastructure
• GPUs – Require specialized hardware – Niche Use-cases
• Can enterprises reuse existing infrastructure for deep learning applications?
• What use-cases in Deep learning can leverage Apache Spark?
Deep Learning + Apache Spark ?

14
• Databricks – Platform for running Spark applications
• BigDL – Intel’s library for deep learning on existing data frameworks.
• TensorflowOnSpark – Yahoo’s Distributed Deep Learning on Big Data Clusters
• The Rest:▫ SparkNet – AMPLab’s framework for training deep networks in Spark
▫ DeepLearning4J – Uses Data parallism to train on separate neural networks
▫ DeepDist - Lightning-Fast Deep Learning on Spark Via parallel stochastic gradient updates
Efforts on using Deep Learning Frameworks with Spark

15
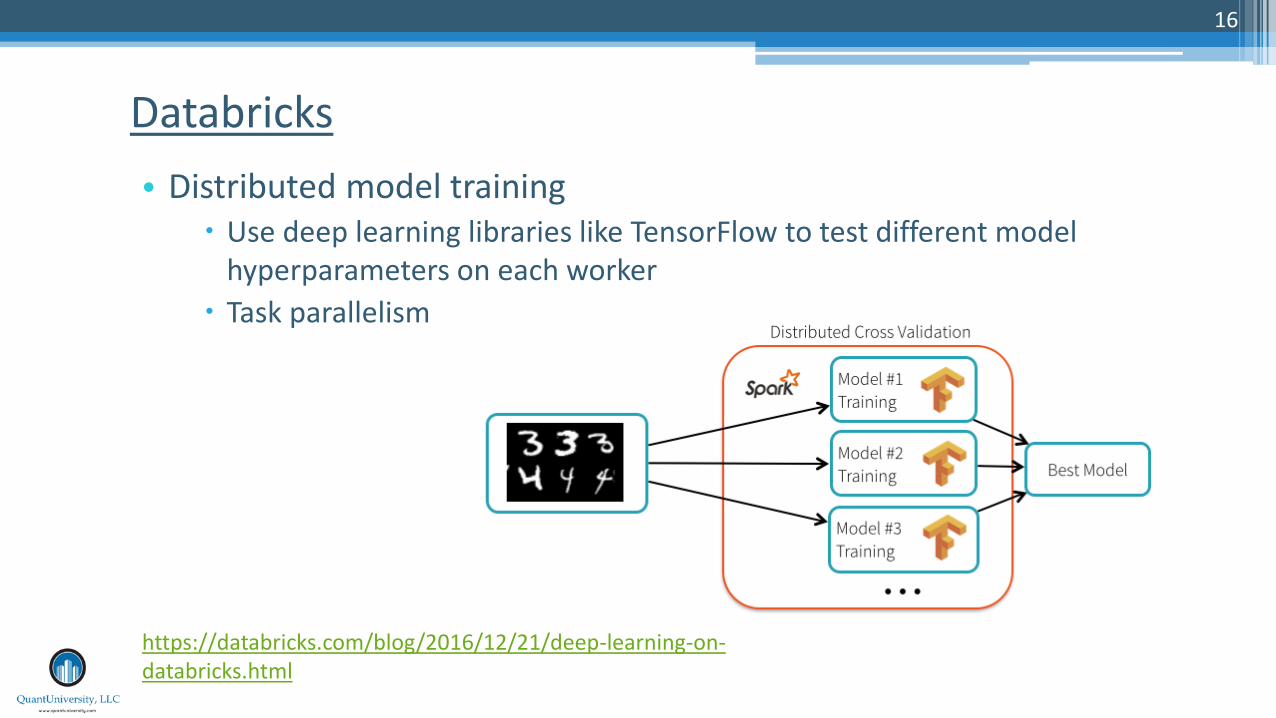
• Deploying trained models to make predictions on data stored in Spark RDDs or Dataframes
Inception model: https://www.tensorflow.org/tutorials/image_recognition
Each prediction requires about 4.8 billion operations
Parallelizing with Spark helps scale operations
Databricks
https://databricks.com/blog/2016/12/21/deep-learning-on-databricks.html
16
• Distributed model training Use deep learning libraries like TensorFlow to test different model
hyperparameters on each worker
Task parallelism
Databricks
https://databricks.com/blog/2016/12/21/deep-learning-on-databricks.html

17
• Tensorframes Experimental TensorFlow binding for Scala and Apache Spark.
TensorFrames (TensorFlow on Spark Dataframes) lets you manipulate Apache Spark's DataFrames with TensorFlow programs.
TensorFrames is available as a Spark package.
Databricks
https://github.com/databricks/tensorframes

18
• BigDL is an open source, distributed deep learning library for Apache Spark that has feature parity with existing popular deep learning frameworks like Torch and Caffe
• BigDL is a standalone Spark package
Intel’s BigDL library
https://www.oreilly.com/ideas/deep-learning-for-apache-spark

19
• BigDL uses Intel Math Kernel Library, a fast math library for Intel and compatible processors to facilitate multi-threaded programming in each Spark task.
• The MKL library facilitates efficiently train larger models across a cluster (using distributed synchronous, mini-batch SGD)
• Key Value proposition:▫ “The typical deep learning pipeline that involves data preprocessing
and preparation on a Spark cluster and model training on a server with multiple GPUs, now involves a simple Spark library that runs on the same cluster used for data preparation and storage.”
Intel’s BigDL library
https://www.oreilly.com/ideas/deep-learning-for-apache-spark
20
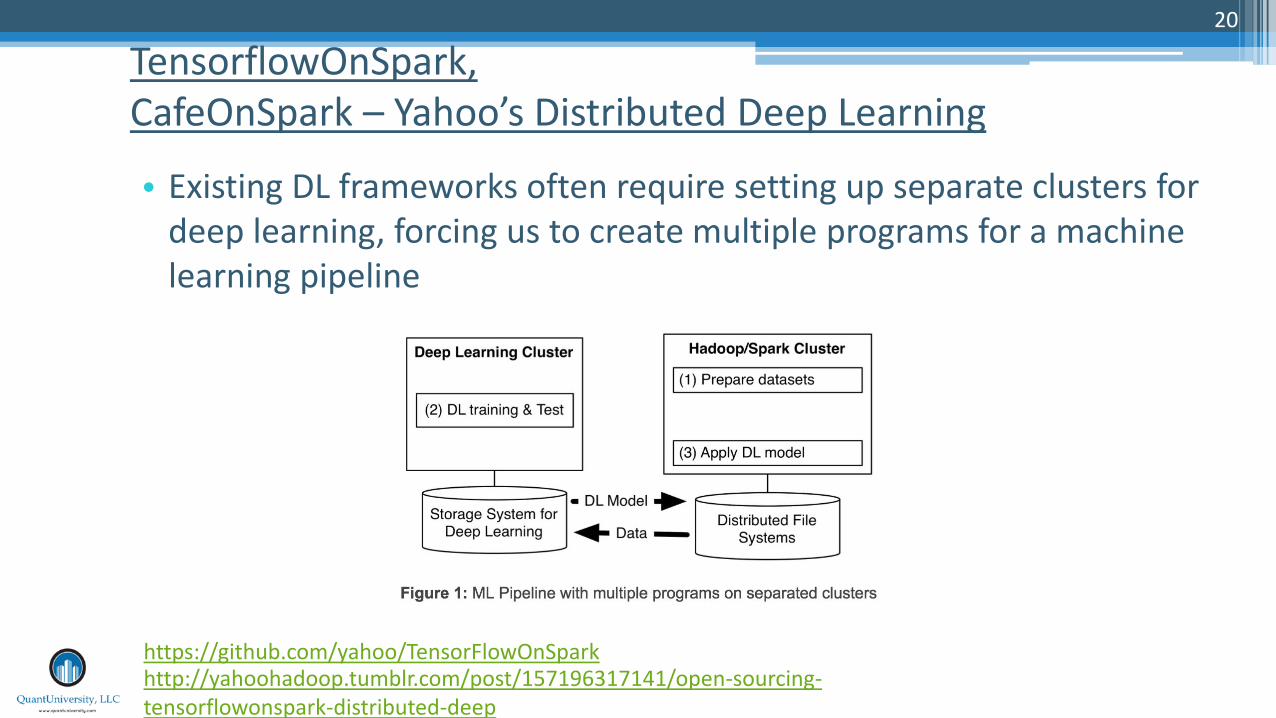
• Existing DL frameworks often require setting up separate clusters for deep learning, forcing us to create multiple programs for a machine learning pipeline
TensorflowOnSpark, CafeOnSpark – Yahoo’s Distributed Deep Learning
https://github.com/yahoo/TensorFlowOnSparkhttp://yahoohadoop.tumblr.com/post/157196317141/open-sourcing-tensorflowonspark-distributed-deep
21
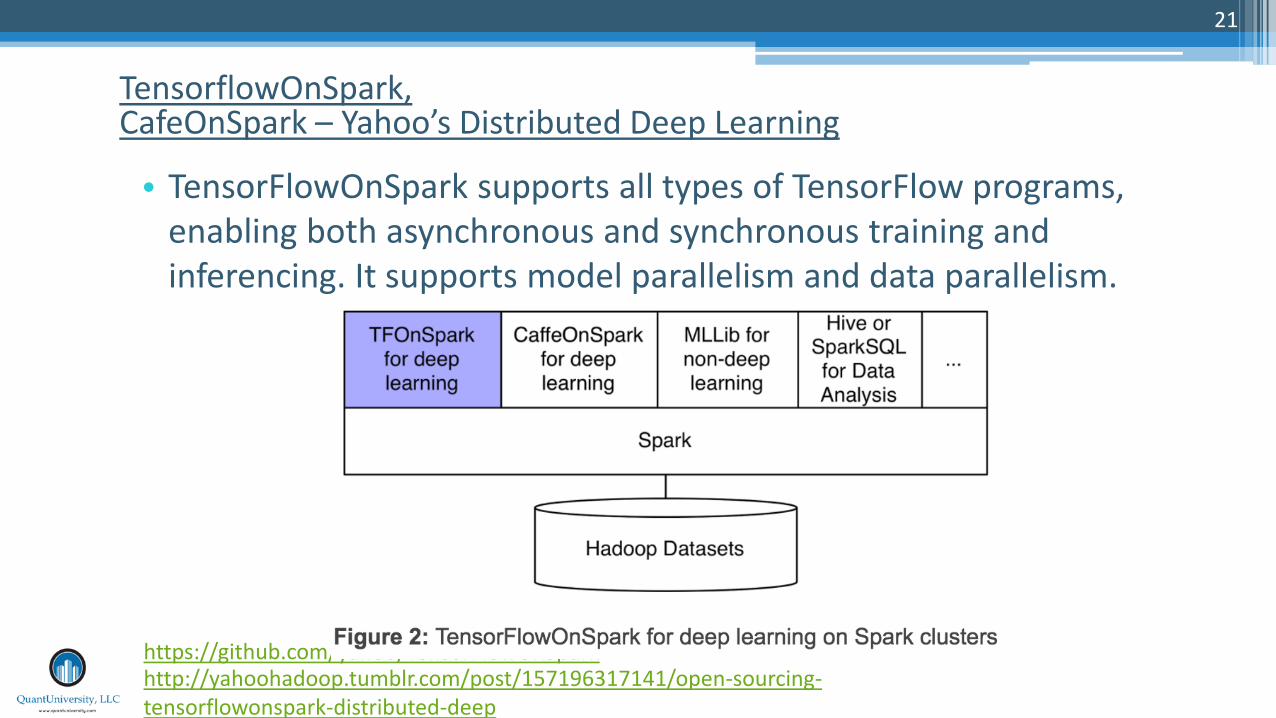
• TensorFlowOnSpark supports all types of TensorFlow programs, enabling both asynchronous and synchronous training and inferencing. It supports model parallelism and data parallelism.
https://github.com/yahoo/TensorFlowOnSparkhttp://yahoohadoop.tumblr.com/post/157196317141/open-sourcing-tensorflowonspark-distributed-deep
TensorflowOnSpark, CafeOnSpark – Yahoo’s Distributed Deep Learning
22
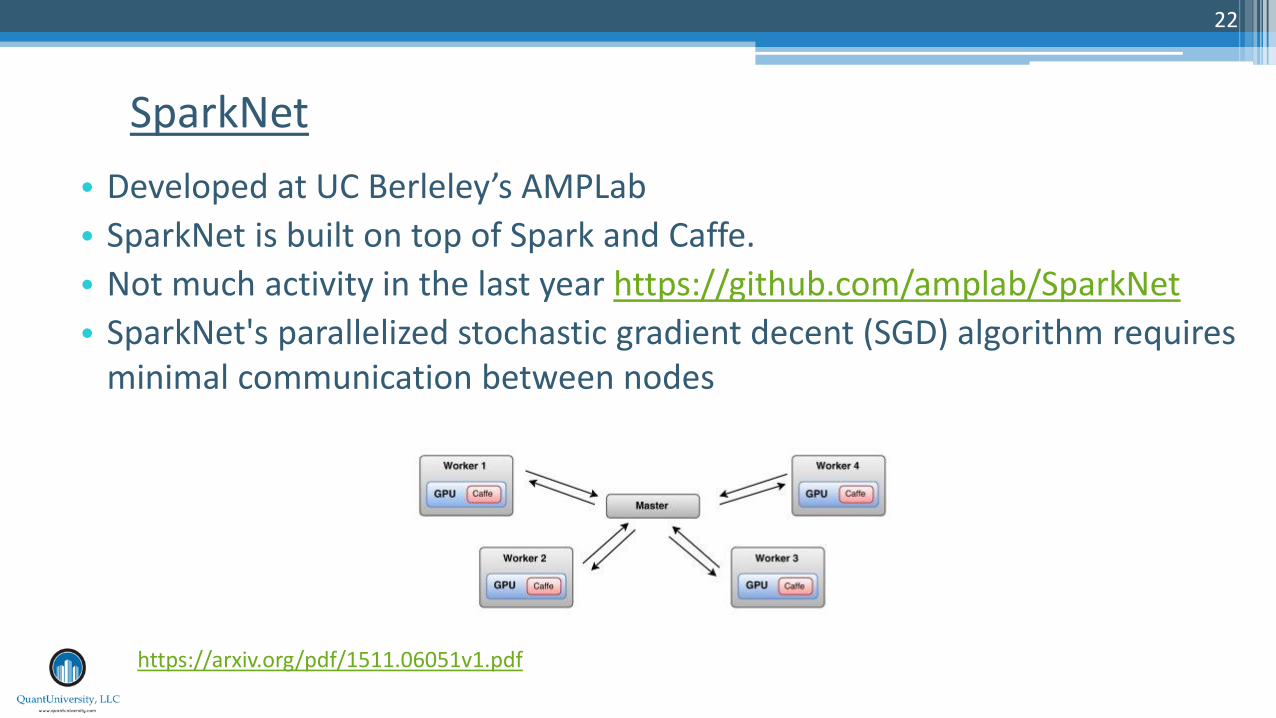
• Developed at UC Berleley’s AMPLab
• SparkNet is built on top of Spark and Caffe.
• Not much activity in the last year https://github.com/amplab/SparkNet
• SparkNet's parallelized stochastic gradient decent (SGD) algorithm requires minimal communication between nodes
SparkNet
https://arxiv.org/pdf/1511.06051v1.pdf
23
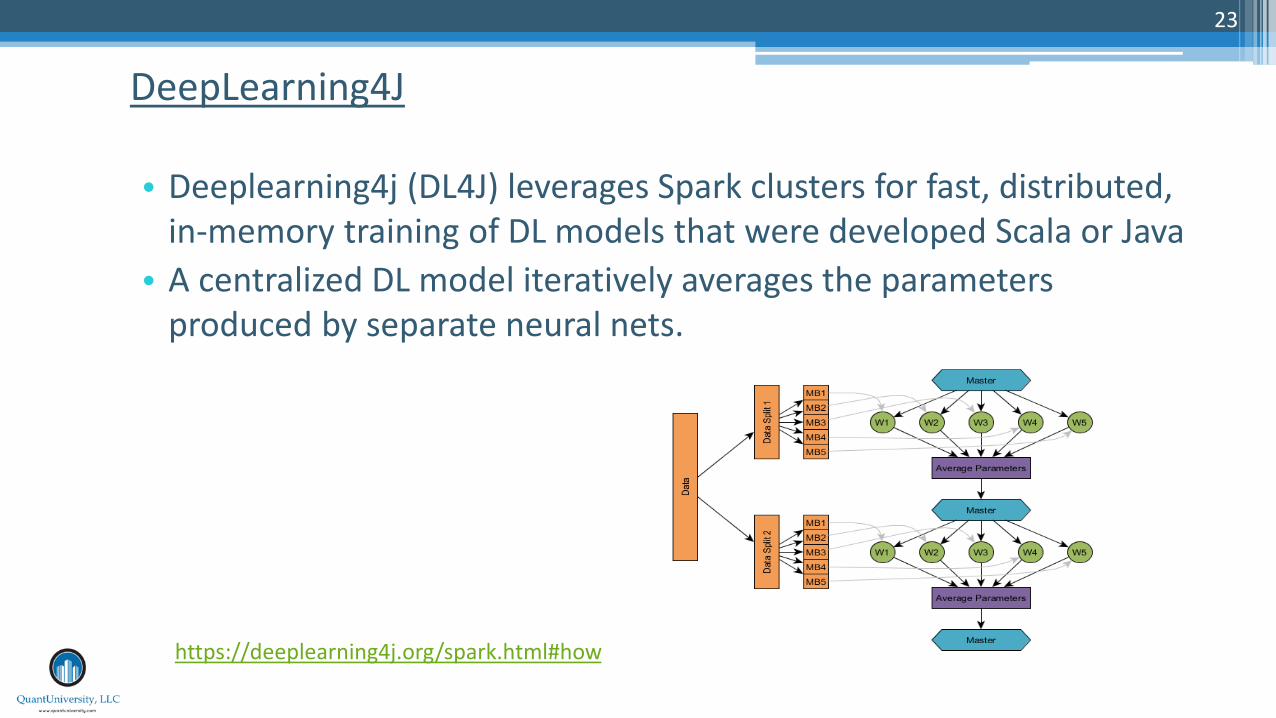
• Deeplearning4j (DL4J) leverages Spark clusters for fast, distributed, in-memory training of DL models that were developed Scala or Java
• A centralized DL model iteratively averages the parameters produced by separate neural nets.
DeepLearning4J
https://deeplearning4j.org/spark.html#how

24
• Leverages Spark and asynchronous SGD to accelerate Deep Learning training from HDFS/Spark data
• DeepDist fetches the model from the master and calls gradient(). After computing gradients on the data partitions, gradient updates are sent back the server. On the server, the master model is updated by descent() using the updates from the nodes..
DeepDist
http://deepdist.com/

25
• Databricks – Platform for running Spark applications
• BigDL – Intel’s library for deep learning on existing data frameworks.
• TensorflowOnSpark – Yahoo’s Distributed Deep Learning on Big Data Clusters
• The Rest:▫ SparkNet – AMPLab’s framework for training deep networks in Spark
▫ DeepLearning4J – Uses Data parallism to train on separate neural networks
▫ DeepDist - Lightning-Fast Deep Learning on Spark Via parallel stochastic gradient updates
Efforts on using Deep Learning Frameworks with Spark

26
• March 2017▫ QuantUniversity Meetup – March 23rd
▫ Deep Learning Workshop – Boston – March 27-28
• April 2017▫ Deep Learning Workshop – New York - April 5-6
▫ Anomaly Detection Workshop – Boston – April 24-25
• May 2017
▫ Anomaly Detection Workshop- New York - May 2-3
Events of Interest
http://www.analyticscertificate.com/DeepLearning

27
Q&A

Thank you!Members & Sponsors!
Sri Krishnamurthy, CFA, CAPFounder and CEO
QuantUniversity LLC.
srikrishnamurthy
www.QuantUniversity.com
Contact
Information, data and drawings embodied in this presentation are strictly a property of QuantUniversity LLC. and shall not bedistributed or used in any other publication without the prior written consent of QuantUniversity LLC.
28








![[@NaukriEngineering] Apache Spark](https://img.pdfslide.us/doc/110x75/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)




















