Embed Size (px)
Citation preview

The Life of Data @Altocloud
Maciej Dabrowski, Chief Data Scientist
Darragh Kirwan, Full Stack Engineer
1

2

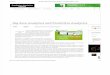
Complete view of your customers…
3
… and an ability to reach them in real-time
4

Focus on real-time analytics
Make predictions on live visitors in real-time (in seconds) by:
Ingesting customer actions (events) and context
Building predictive models
Actions offered to customers based on real-time predictions
5

18 people 1 dragon 2 locations 7 nationalities having fun …and growing!
6

The life of data @Altocloud
Data platform
Use cases real-time analytics machine learning Ad hoc analysis
7

Engineering challenges
Product complexity Communication platform Data platform
Scale Millions of events per day Billions of events overall Typically no stable schemas
8
Real-time aspects Response in second(s) Streaming nature
Reliability 24/7 availability Services go down Servers disappear

Data
Demographic device location organisation contact details, and more
JSON
9
Events: page views form fills searches purchases custom events

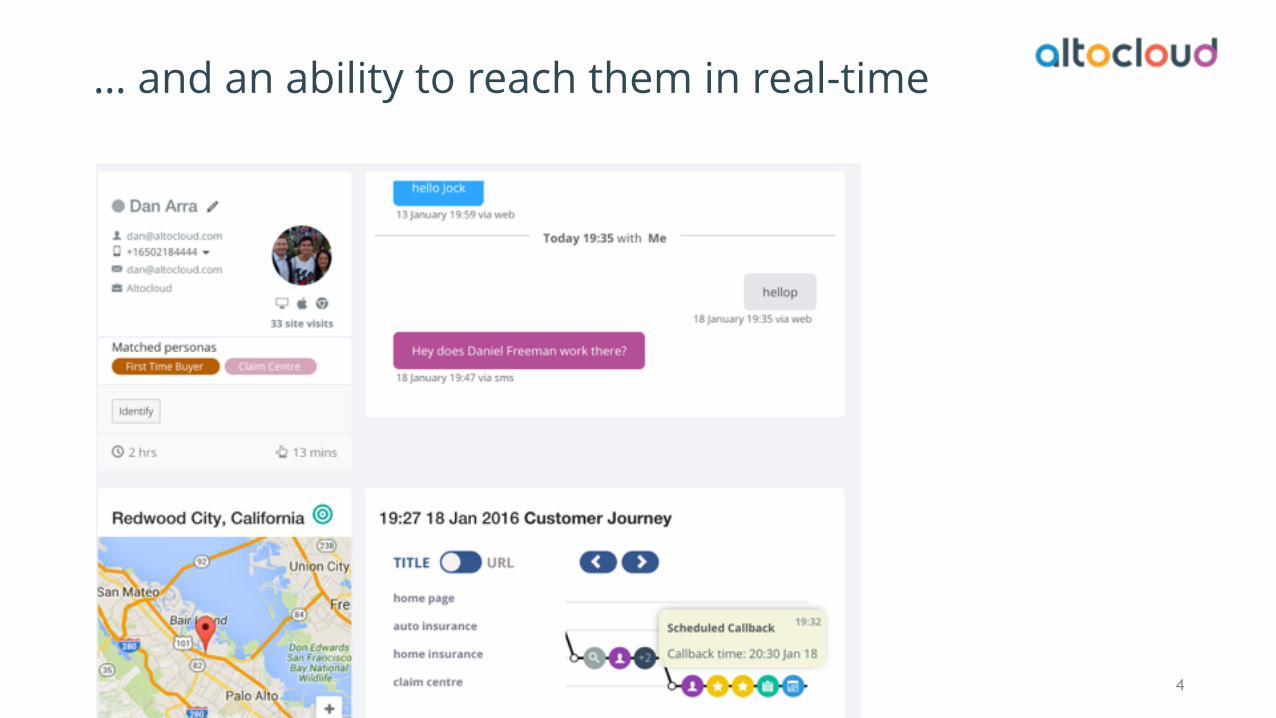
ALTOCLOUD DATA PLATFORM
ALTOCLOUD PLATFORM
Altocloud Platform
10
APIs
MESSAGE QUEUES
DATA PROCESSORS
STORAGE
APIsAPIs
APIs

Tools that we use
Focus on open source (Apache)
11
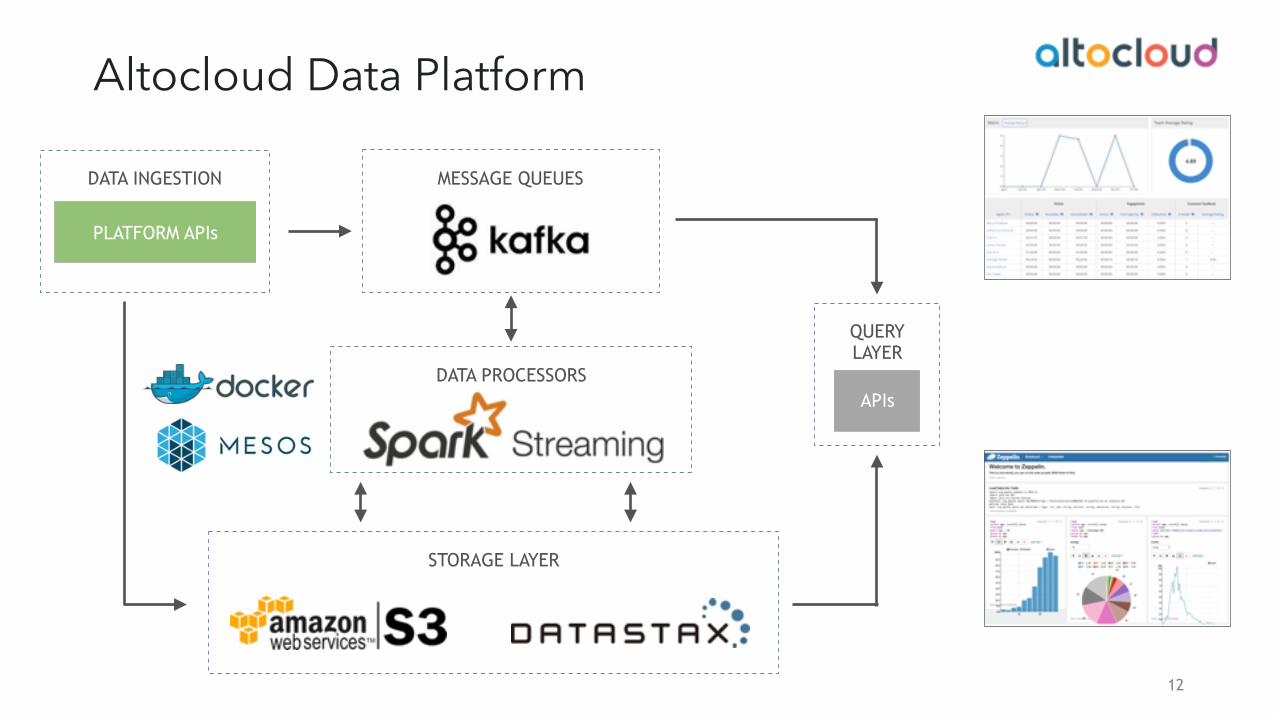
MESSAGE QUEUES
DATA PROCESSORS
DATA INGESTION
QUERY LAYER
STORAGE LAYER
Altocloud Data Platform
12
PLATFORM APIs
APIs

Why Spark
Fast for iterative algorithms (important for Machine Learning)
Good integration with other tools (Kafka and Cassandra)
One code base for streaming and batch processing
Easy to deploy and maintain
Growing ecosystem (SQL, MLlib, GraphX, …)
Large open-source community
13
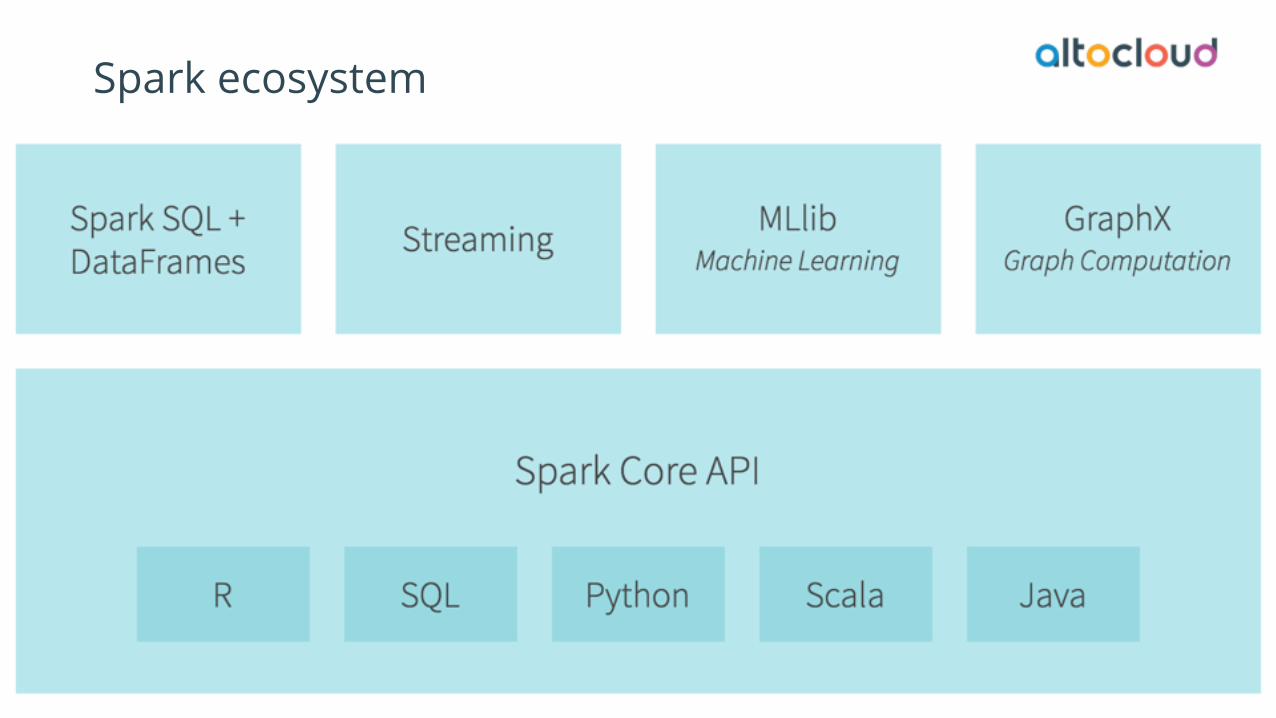
Spark ecosystem
Support for various workloads out of the box
14

Data source: Kafka
Pub-sub message broker
Fast: 100s MBs /s on a single broker
Scalable: partitioned data streams
Durable: messages persisted and replicated
Distributed: Strong durability and fault-tolerance
Downside: requires ZooKeeper
15

Scalable storage
Easy to setup
High availability - no master
Great performance
CQL - SQL like querying
Great support and bug-free drivers from Datastax
Key: Design your schema around queries;
16

Use case: Real-time Analytics
Analytics Fully distributed Idempotent - Spark, Cassandra and Kafka Powered by in-house solution
Highly scalable and performant Minutely roll ups on raw events, hourly on pre-aggregates 1bn+ events / day on a 3 node cluster Sub-second query time
17
PREDICTIONS
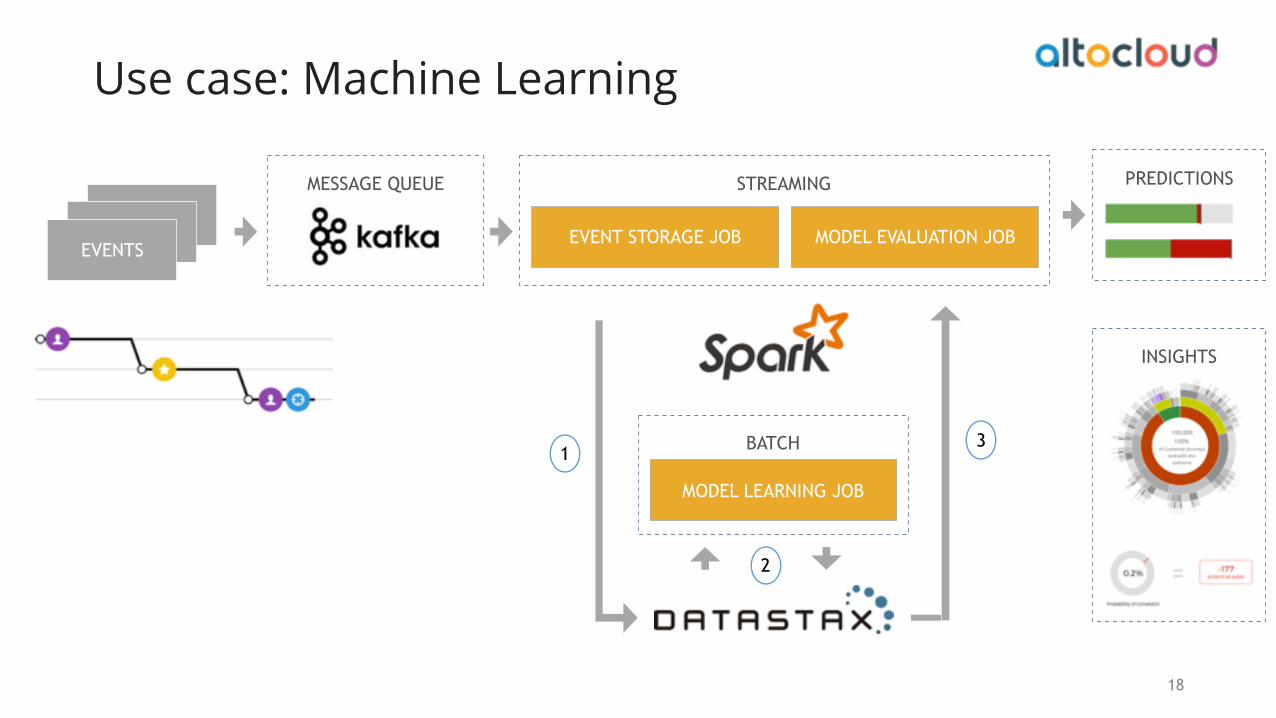
Use case: Machine Learning
18
MESSAGE QUEUE
EVENTSEVENTS
EVENTS
STREAMING
BATCH
MODEL LEARNING JOB
EVENT STORAGE JOB MODEL EVALUATION JOB
1
2
3
INSIGHTS

Outcome Probabilities
Which customers are likely to achieve a specific outcome?
19
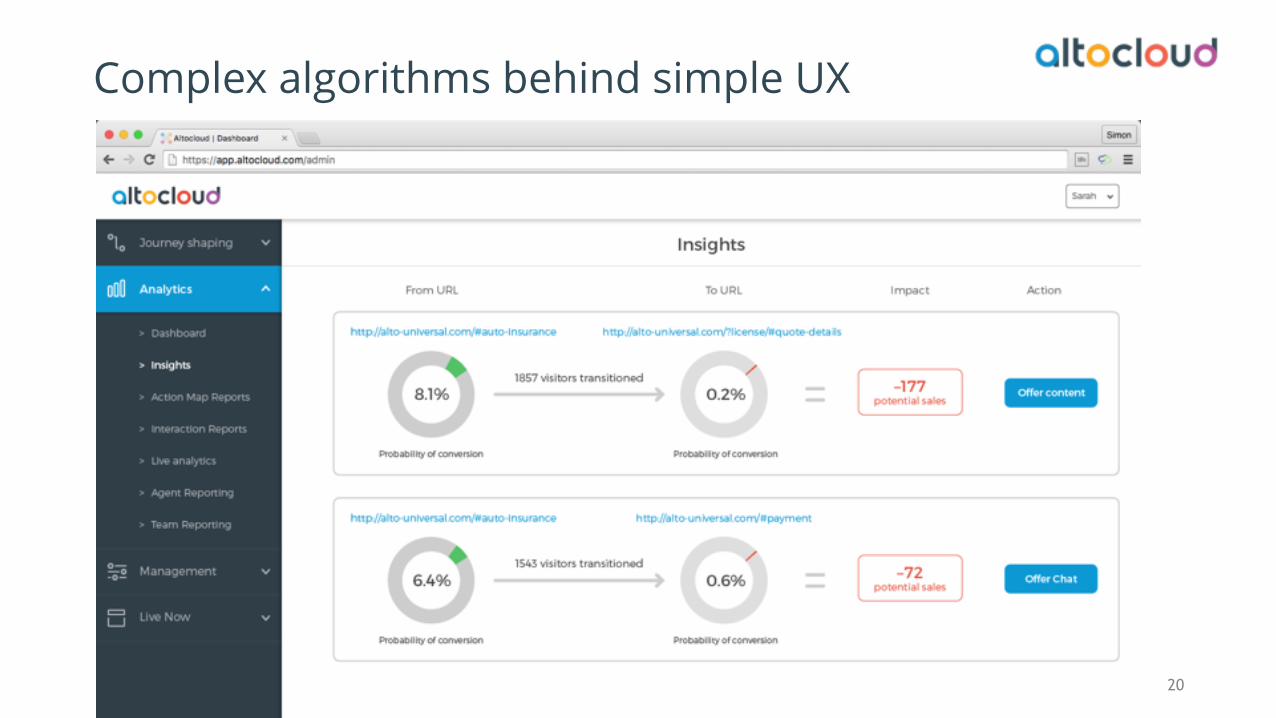
Complex algorithms behind simple UX
20

Apache Zeppelin Workbooks
Browser-based notebook with access to cluster compute power
Support for Scala, Python, SparkSQL, Hive and more
Data Analytics, visualisation and collaboration tool
21
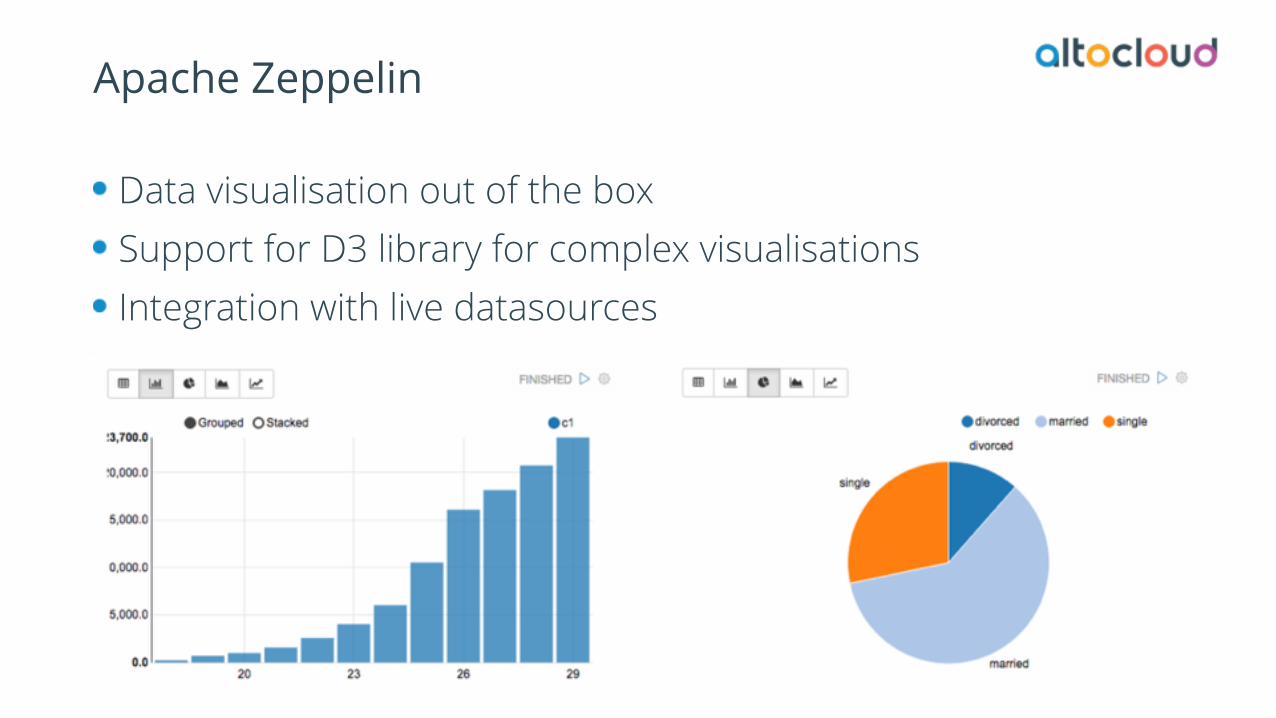
Apache Zeppelin
Data visualisation out of the box Support for D3 library for complex visualisations Integration with live datasources
22

Zeppelin demo
Cassandra integration local-mode read events from Cassandra
S3 integration Cluster mode (Mesos) analyse 1m events easy visualisation with D3
23