Embed Size (px)
Citation preview

Building Scalable
Aggregation Systems
Boulder/Denver Big Data Meetup
April 15, 2015
Jared Winick
jaredwinick @ koverse.com
@jaredwinick

Outline
• The Value of Aggregations
• Abstractions
• Systems
• Demo
• References/Additional Information

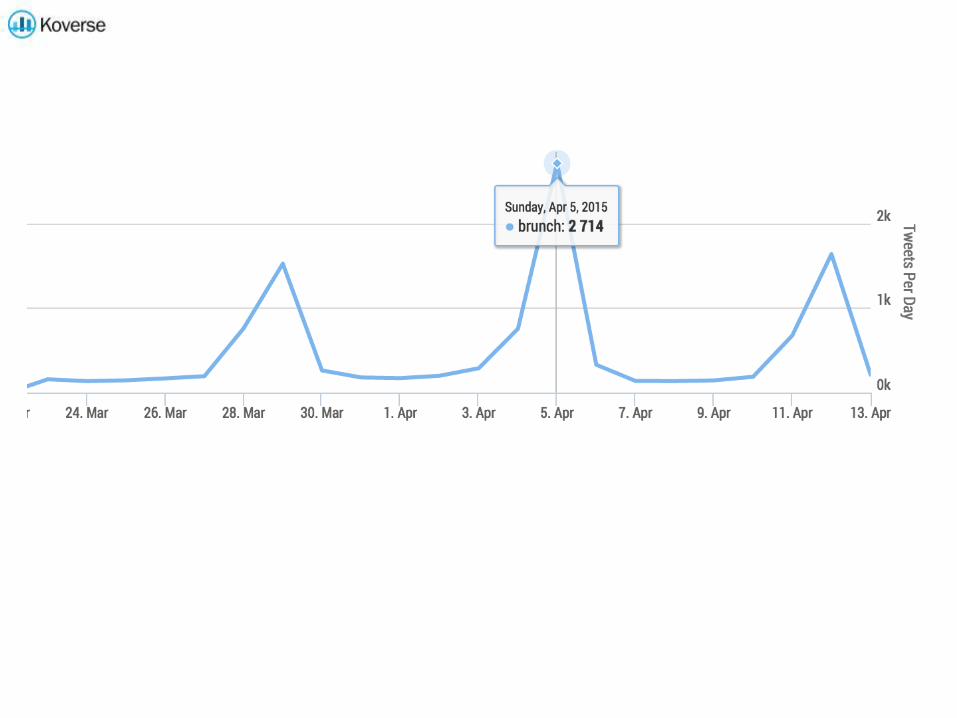

Aggregation provides a means of turning billions of pieces of raw data into condensed, human-consumable
information.
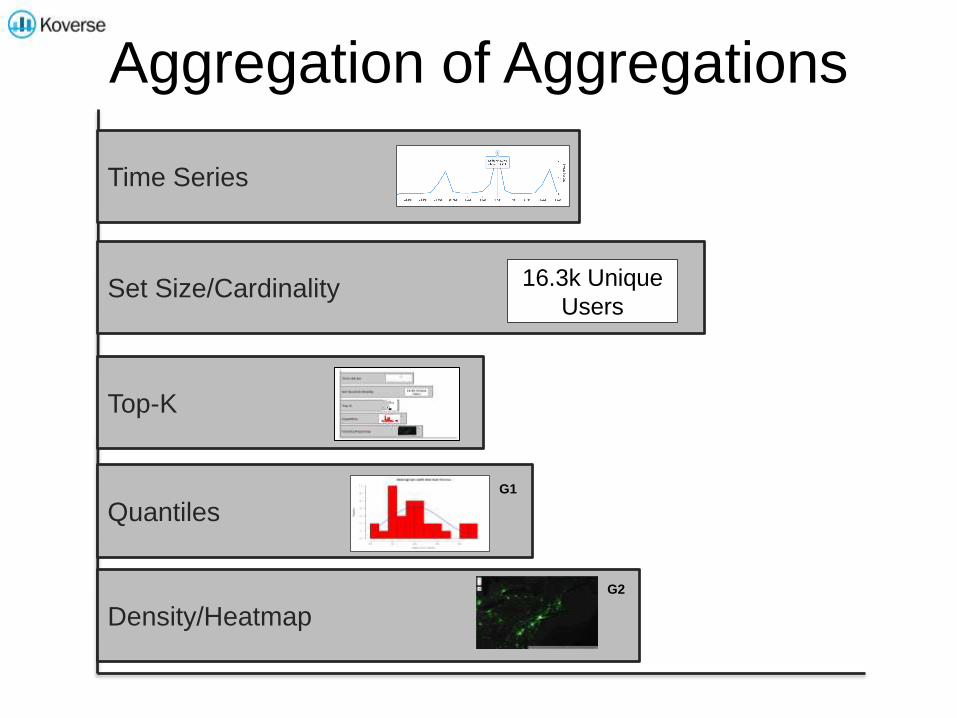
Aggregation of Aggregations
Time Series
Set Size/Cardinality
Top-K
Quantiles
Density/Heatmap
16.3k Unique
Users
G1
G2

TimeSeries
Top-K
Sum
Cardinality
Quantiles

Abstractions
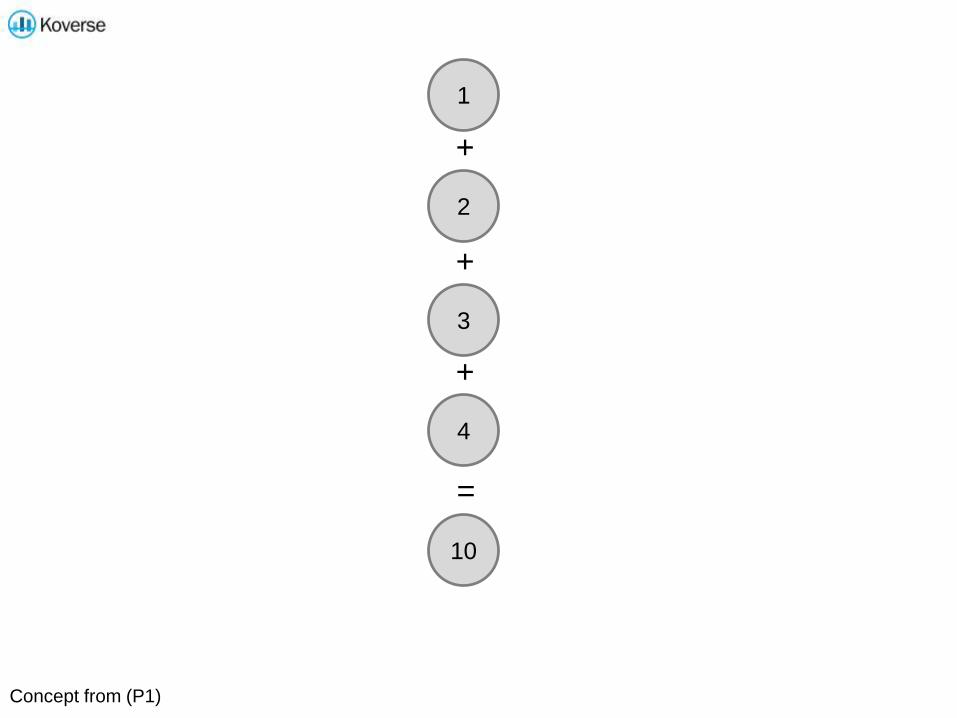
1
2
3
4
10
+
+
+
=
Concept from (P1)
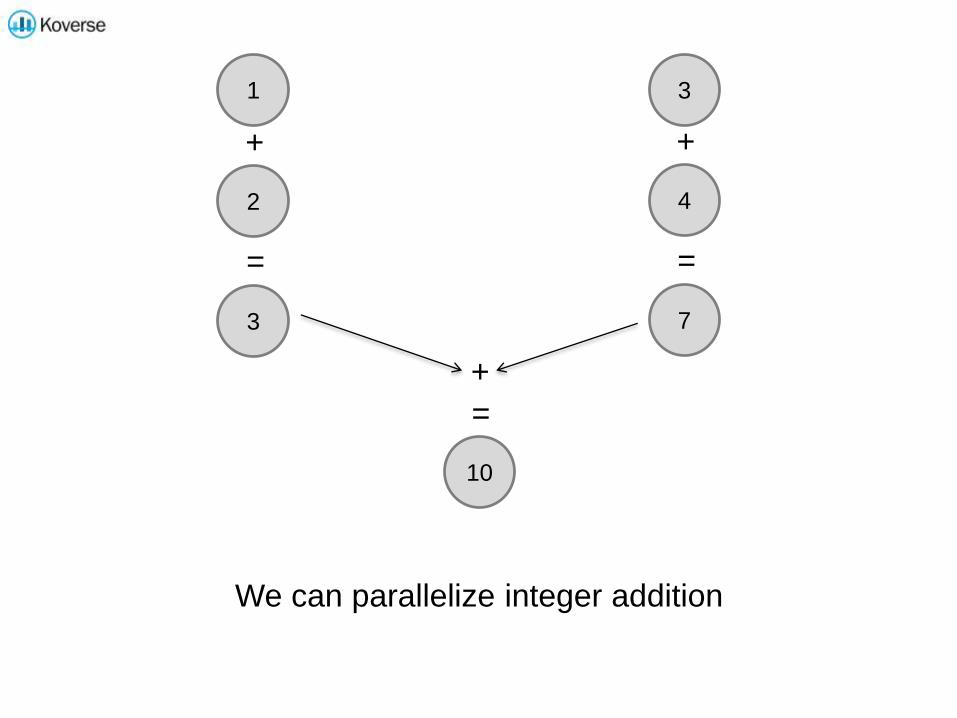
1
2
3
4
3
+ +
=
7
=
10
=
+
We can parallelize integer addition

Associative + Commutative
Operations
• Associative: 1 + (2 + 3) = (1 + 2) + 3
• Commutative: 1 + 2 = 2 + 1
• Allows us to parallelize our reduce (for
instance locally in combiners)
• Applies to many operations, not just
integer addition.
• Spoiler: Key to incremental aggregations
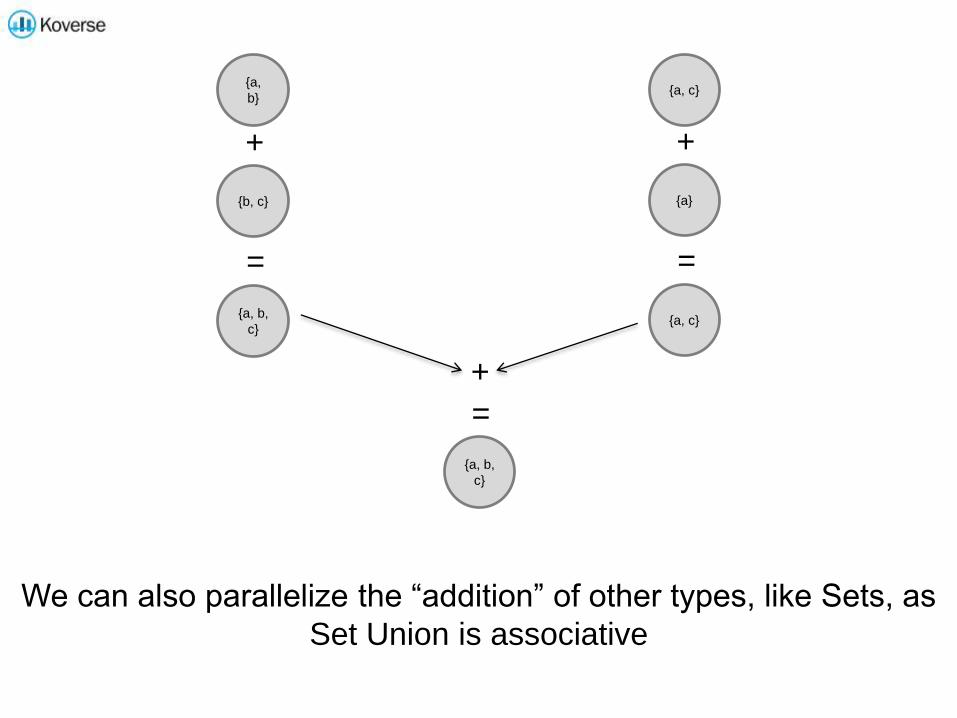
{a,
b}
{b, c}
{a, c}
{a}
{a, b,
c}
+ +
=
{a, c}
=
{a, b,
c}
=
+
We can also parallelize the “addition” of other types, like Sets, as
Set Union is associative

Monoid Interface
• Abstract Algebra provides a formal foundation for what we can casually observe.
• Don’t be thrown off by the name, just think of it as another trait/interface.
• Monoids provide a critical abstraction to treat aggregations of different types in the same way

Monoid Examples

Monoid Examples

Many Monoid Implementations
Already Exist
• https://github.com/twitter/algebird/
• Long, String, Set, Seq, Map, etc…
• HyperLogLog – Cardinality Estimates
• QTree – Quantile Estimates
• SpaceSaver/HeavyHitters – Approx Top-K
• Also easy to add your own with libraries
like stream-lib [C3]
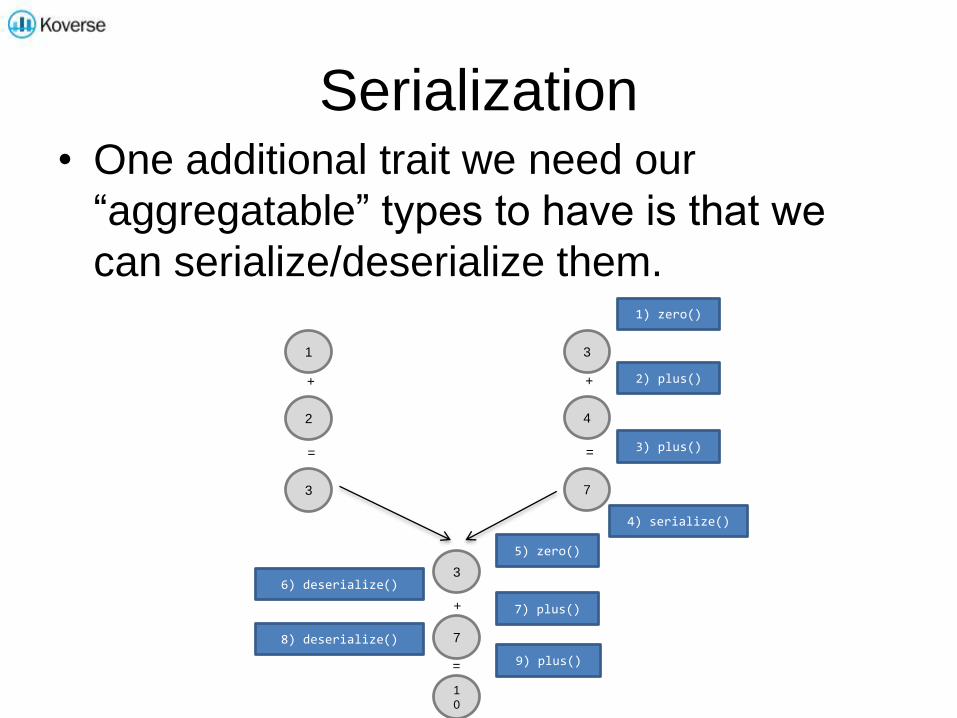
Serialization• One additional trait we need our
“aggregatable” types to have is that we
can serialize/deserialize them.
1
2
3
4
3
+ +
=
7
=
1
0
=
+
1) zero()
2) plus()
3) plus()
4) serialize()
6) deserialize()
5) zero()
7) plus()
9) plus()
3
78) deserialize()

These abstractions enable a
small library of reusable code to
aggregate data in many parts of
your system.

Systems

Requirements and Tradeoffs
Query
Latency
milliseconds seconds minutes
• Results are pre-computed• requires compute and
storage resources
• Supported queries must be
known in advance
• Results are computed at query
time
• No resources used except
for executed queries
• Ad-hoc queries

Requirements and Tradeoffs
Number of
Users
large many few
• Resources required per query
must be small
• Requires scalable query
handling/storage
• Queries can be
expensive

Requirements and Tradeoffs
Freshness of
Results
seconds minutes hours
• May require streaming
platform in addition to batch
• Smaller, more frequent
updates is more work
• Single batch platform
• Less frequent
computation

Requirements and Tradeoffs
Amount of
Data
billions millions thousands
• Requires parallelized
computation and storage
• Single server is
sufficient
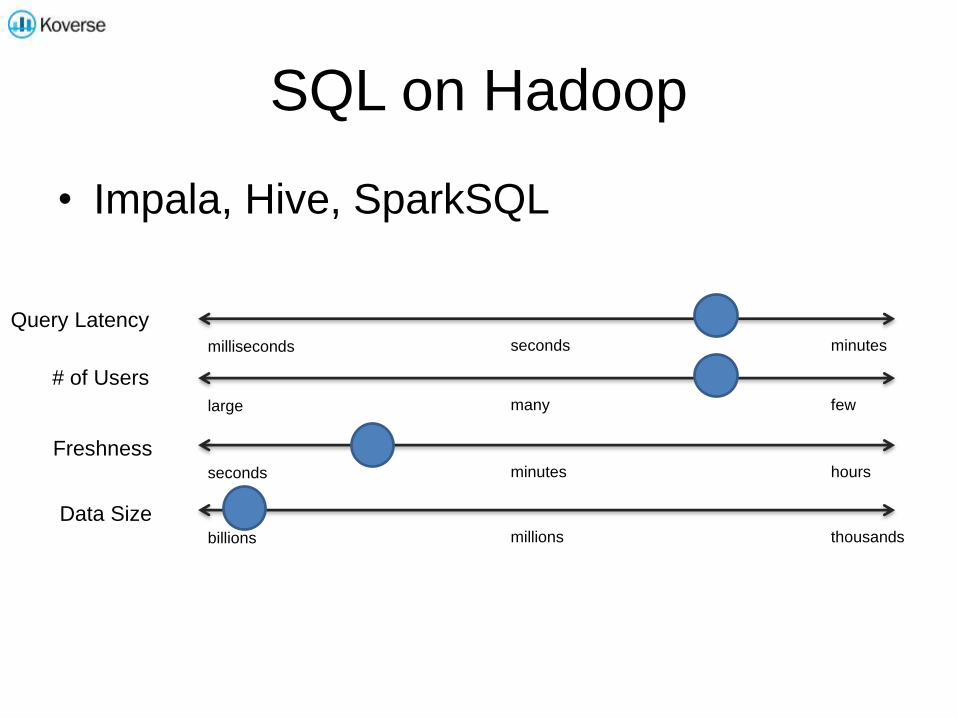
SQL on Hadoop
• Impala, Hive, SparkSQL
milliseconds seconds minutes
large many few
seconds minutes hours
billions millions thousands
Query Latency
# of Users
Freshness
Data Size

Batch Jobs
• Spark, Hadoop MapReduce
milliseconds seconds minutes
large many few
seconds minutes hours
billions millions thousands
Query Latency
# of Users
Freshness
Data Size
Dependent on
where you put the
job’s output
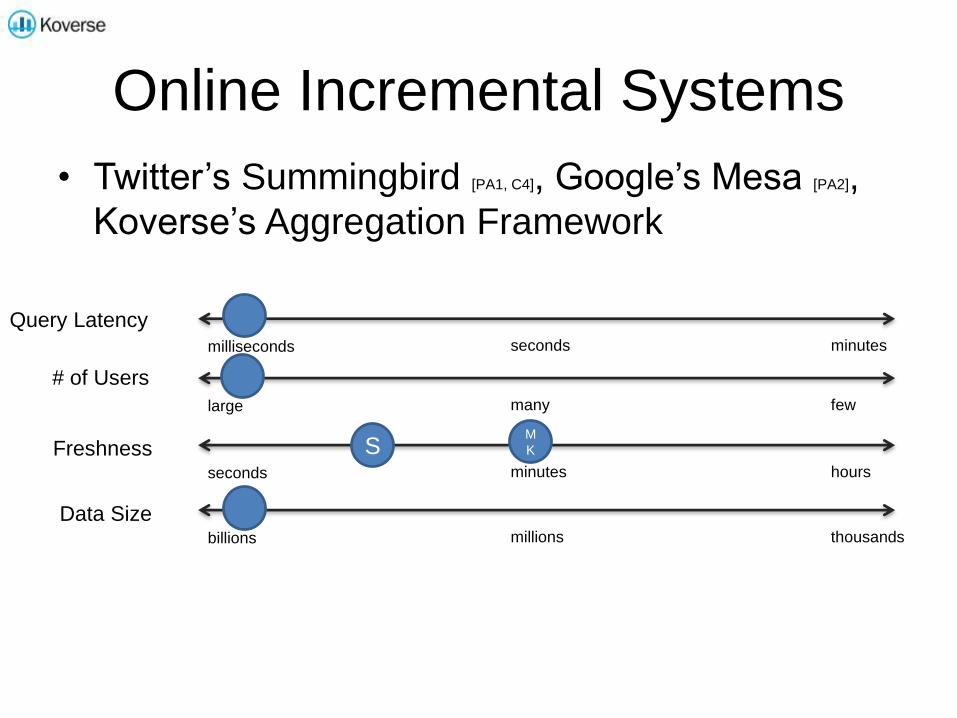
Online Incremental Systems
• Twitter’s Summingbird [PA1, C4], Google’s Mesa [PA2],
Koverse’s Aggregation Framework
milliseconds seconds minutes
large many few
seconds minutes hours
billions millions thousands
Query Latency
# of Users
Freshness
Data Size
SM
K

Online Incremental Systems:
Common Components
• Aggregations are computed/reduced
incrementally via associative operations
• Results are mostly pre-computed for so
queries are inexpensive
• Aggregations, keyed by dimensions, are
stored in low latency, scalable key-value
store
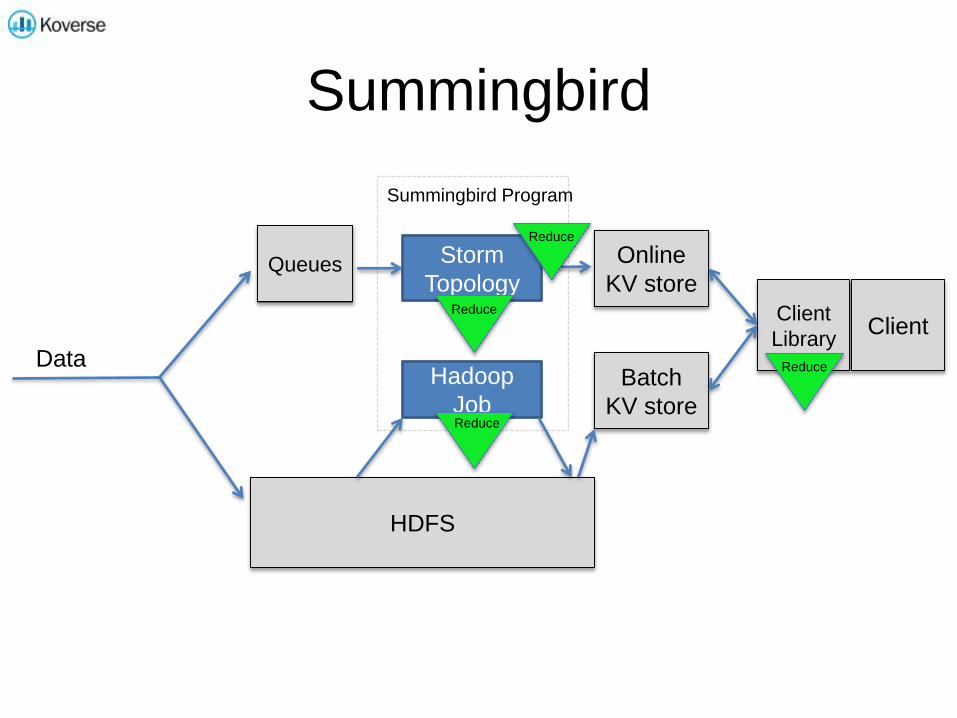
Summingbird Program
Summingbird
Data
HDFS
Queues Storm
Topology
Hadoop
Job
Online
KV store
Batch
KV store
Client
LibraryClient
Reduce
Reduce
Reduce
Reduce
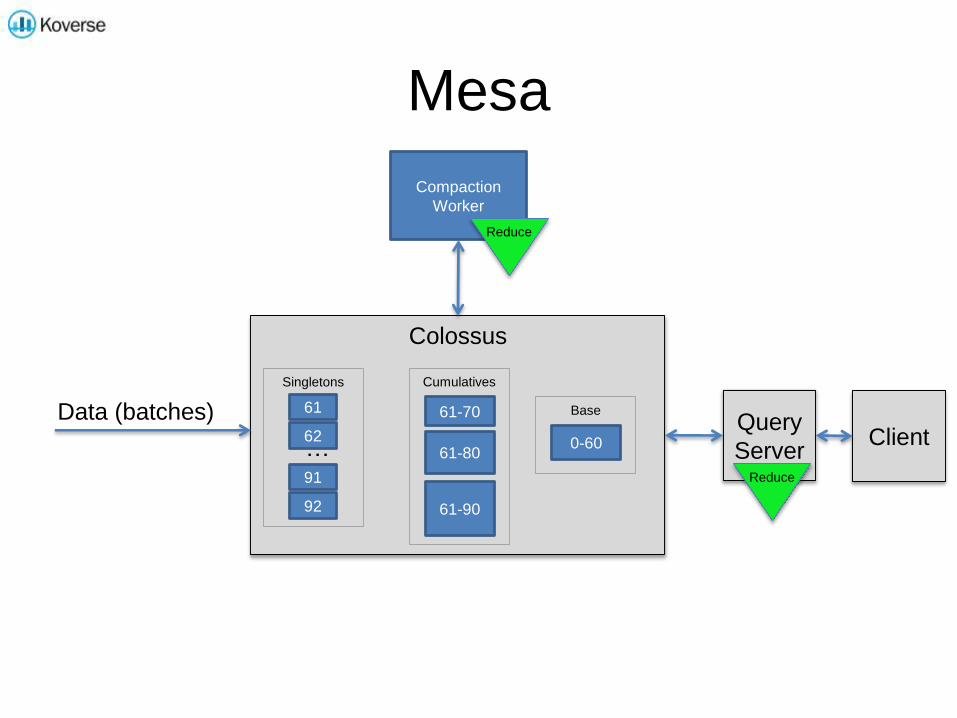
Mesa
Data (batches)
Colossus
Query
Server
61
62
91
92
…
Singletons
61-70
Cumulatives
61-80
61-90
0-60
Base
Compaction
Worker
Reduce
Reduce
Client
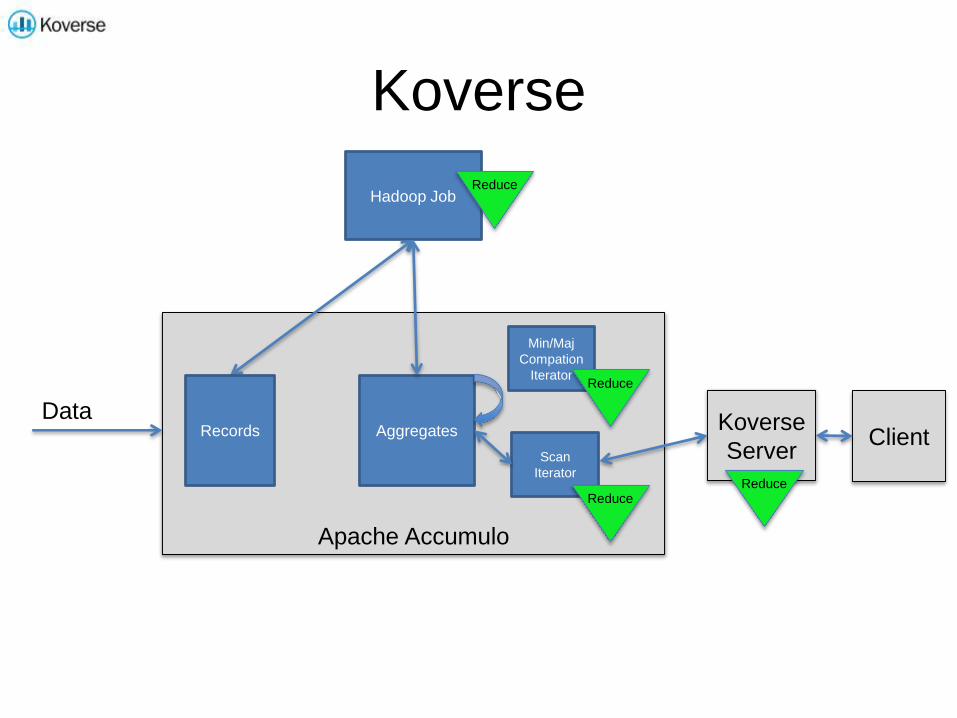
Koverse
Data
Apache Accumulo
Koverse
Server
Hadoop JobReduce
Reduce
ClientRecords Aggregates
Min/Maj
Compation
IteratorReduce
Scan
Iterator
Reduce
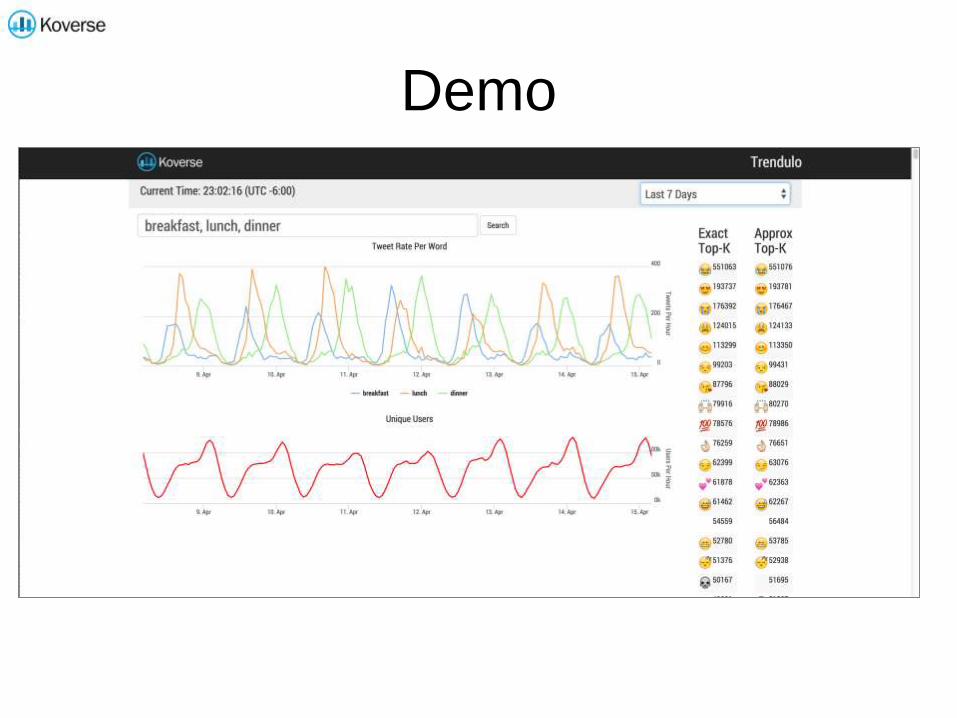
Demo

References
Presentations
P1. Algebra for Analytics - https://speakerdeck.com/johnynek/algebra-for-analytics
Code
C1. Algebird - https://github.com/twitter/algebird
C2. Simmer - https://github.com/avibryant/simmer
C3. stream-lib https://github.com/addthis/stream-lib
C4. Summingbird - https://github.com/twitter/summingbird
Papers
PA1. Summingbird: A Framework for Integrating Batch and Online MapReduce Computations http://www.vldb.org/pvldb/vol7/p1441-boykin.pdf
PA2. Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/42851.pdf
PA3. Monoidify! Monoids as a Design Principle for Efficient MapReduce Algorithms http://arxiv.org/abs/1304.7544
Video
V1. Intro To Summingbird - https://engineering.twitter.com/university/videos/introduction-to-summingbird
Graphics
G1. Histogram Graphic - http://www.statmethods.net/graphs/density.html
G2. Heatmap Graphic - https://www.mapbox.com/blog/twitter-map-every-tweet/
G3. The Matrix Background - http://wall.alphacoders.com/by_sub_category.php?id=198802

















![[ScalaByTheBay2016] Implement a scalable statistical aggregation system using Akka](https://img.pdfslide.us/doc/110x75/5899b3c71a28aba11e8b5571/scalabythebay2016-implement-a-scalable-statistical-aggregation-system-using.jpg)











