Embed Size (px)
Citation preview

Bridging the Semantic Gap in Multimedia Information Retrieval
Top-down and Bottom-up ApproachesJonathon S. Hare, Patrick A.S. Sinclair,
Paul H. Lewis and Kirk MartinezIntelligence, Agents, Multimedia Group
School of Electronics and Computer ScienceUniversity of Southampton
{jsh2 | pass | phl | km}@ecs.soton.ac.uk&
Peter G.B. Enser and Christine J. SandomSchool of Computing, Mathematical and Information Sciences
University of Brighton{p.g.b.enser | c.sandom}@bton.ac.uk

Introduction
What is the semantic gap in image retrieval?
The gap between information extractable automatically from the visual data and the interpretation a user may have for the same data
…typically between low level features and the image semantics
Two approaches to solving this:
Top-down:- Metadata driven
Bottom-up:- Image features

Motivation
Hallmark of a good retrieval system is its ability to respond to queries posed by a user
We have been collecting numerous real queries for images from different collections in order to investigate how we need to bridge the semantic gap in order to answer the queries

Users’ queries should be the driver
User queries may specify unique features
A member of parliament with a beard
May involve temporal or spatial facets
A 1950s fridge in the background
Particular significance
Bannister breaking the 4 min mile
The absence of features
George V’s Coronation but no procession or royals

Top-down Approaches
Ontologies can improve accuracy of retrieval
Simple keyword-based retrieval
Concept-based retrieval
Reasoning
Integration of different sources
Cultural heritage
Browsing and visualisation
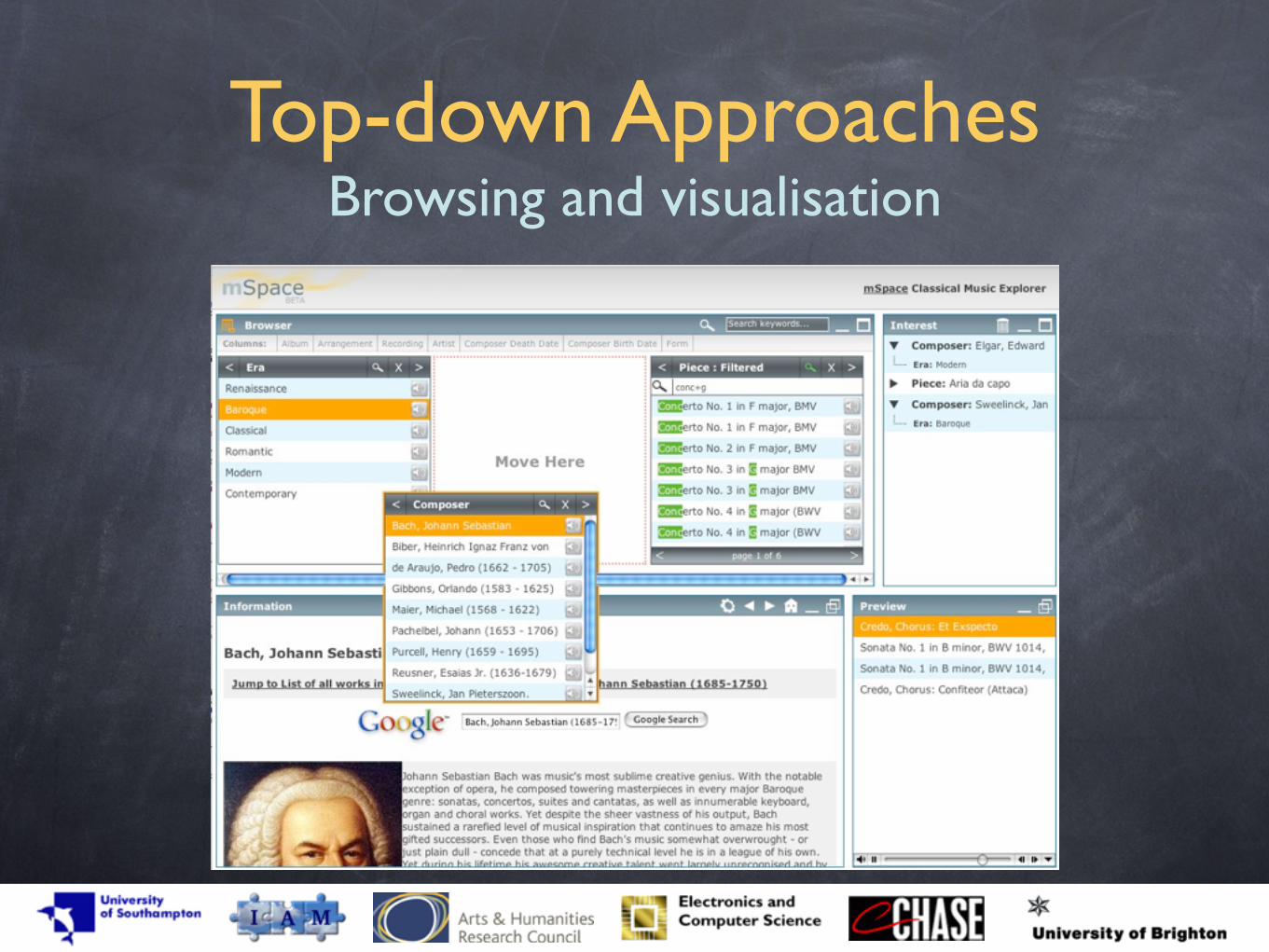
Top-down Approaches Browsing and visualisation

Poodle Demo

Issues
Manual annotation is expensive
Use of context to annotate
Keyword-based:
Problems if a predefined vocabulary is not used
Keyword-Concept matching is difficult!
Especially with inconsistent keywords
What if there is no metadata?

Bottom-up Approaches Content-based Retrieval
In the past, content-based retrieval has been used as a means to provide bottom-up searching of (unannotated) image collections
For example, Query by Image Content Paradigm
Demo...
However, it doesn’t tend to work well w.r.t to real image searchers

Bottom-up Approaches Auto-annotation
Lots of techniques proposed, using different descriptor morphologies (global, region-based [segmented, salient, ...])
Co-occurrence of keywords and image features
Machine translation
Statistical, maximum entropy, ...
Probabilistic methods
Inference networks, density estimation, ...
Latent-spaces
Keyword propagation
Simple classifiers using low level features
Almost all of these techniques involve explicitly annotating the media with a keyword, phrase or concept
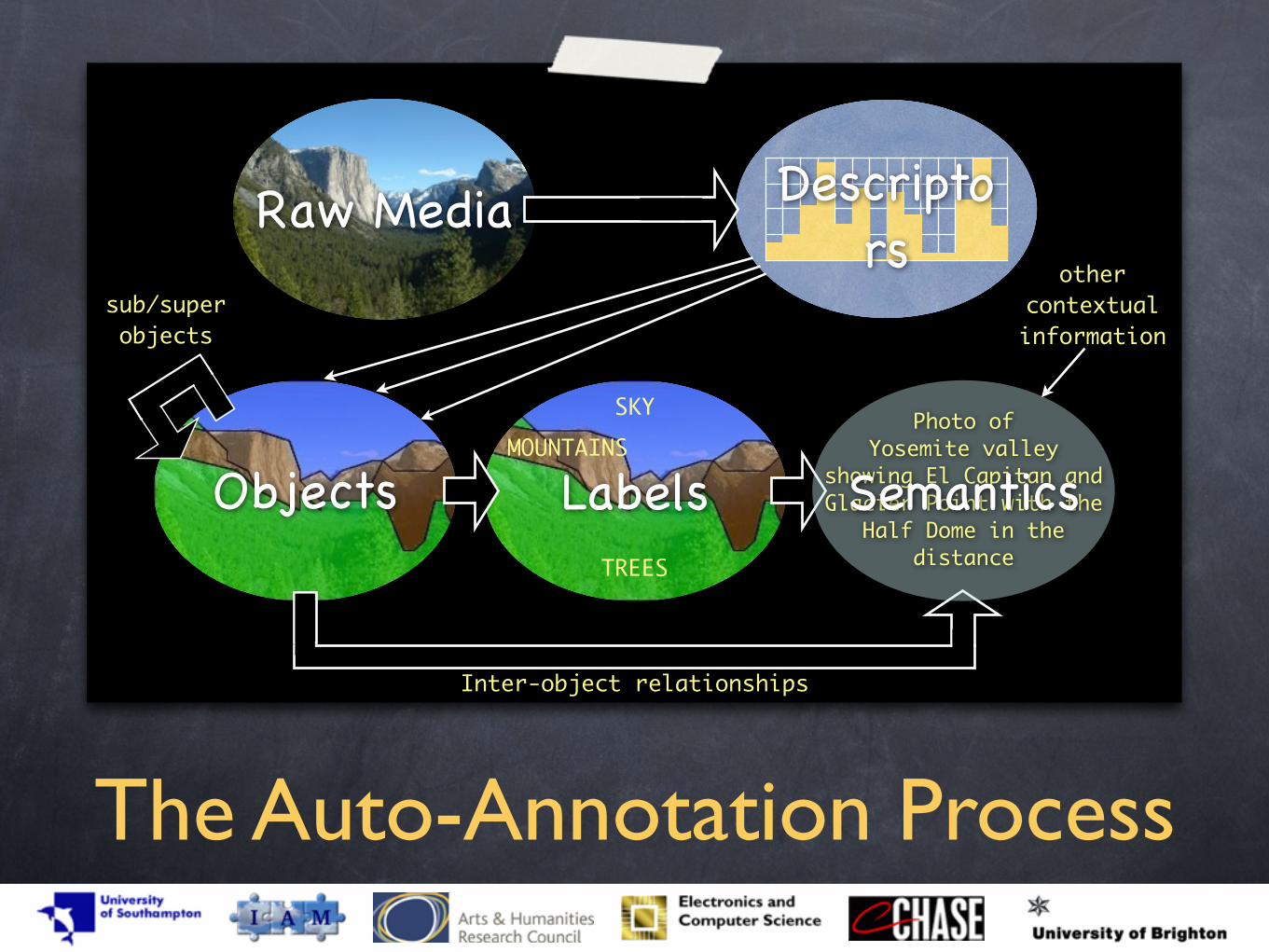
The Auto-Annotation Process
Descriptors
Raw Media
Objects Labels
SKYMOUNTAINS
TREES
Photo of Yosemite valley
showing El Capitan and Glacier Point with the
Half Dome in the distance
Semantics
Inter-object relationships
sub/superobjects
other contextual information

Bottom-up Approaches Semantic Spaces
Simple idea based on factorisation and dimensionality reduction of a vector-space of keywords/phrases/concepts and visual terms created from feature-vectors calculated from the media
Doesn’t allow explicit annotation, but does provide search

Semantic Space Demo

Issues
The biggest problems come from:
Biased training data
Noisy/poor keywording, as with top-down approaches
The semantic space should be able to cope with this by learning from co-occurrence, but this is difficult with keywords
Proper full-text captions would be better...
Image noise...

Image Noise
video/ss search for ‘cups’

Image Noise Possible solution: Automatic Region-of-Interest Detection

Integration
Concept-augmented Semantic Spaces
Less clutter, better training
Better classifiers and auto-annotators
Safer annotation or classification using ontological reasoning
e.g. image is either ‘horse’ or ‘foal’ according to classifier. Which is safer?

Conclusions
Have discussed some techniques and issues with current top-down and bottom-up techniques
Top-down techniques work well, but can’t help us find metadata-less media
Bottom-up approaches allow us to locate media without metadata, however performance is variable
Hopefully demo’s have illustrated where we are taking this and how we are beginning to integrate both approaches

Any Questions?





























