Embed Size (px)
Citation preview

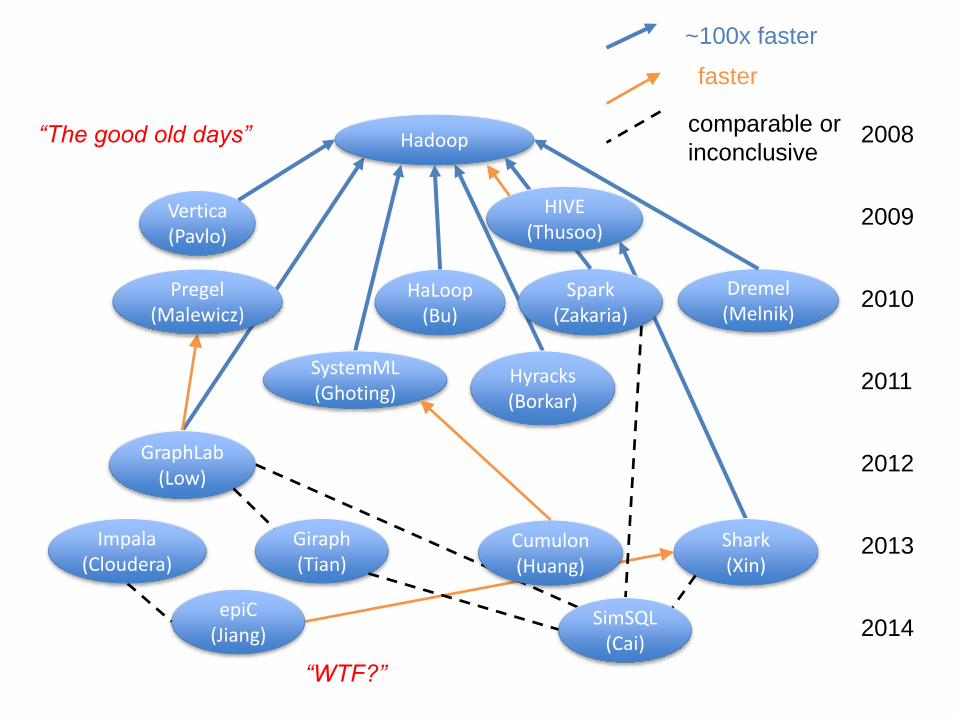
• SIGMOD 2009: Vertica 100x < Hadoop (Grep, Aggregation, Join)
• VLDB 2010: HaLoop ~100x < Hadoop (PageRank, ShortestPath)
• SIGMOD 2010: Pregel (no comparisons)
• HotCloud 2010: Spark ~100x < Hadoop (logistic regression, ALS)
• ICDE 2011: SystemML ~100x < Hadoop
• ICDE 2011: Asterix ~100x < Hadoop (K-Means)
• VLDB 2012: Graphlab ~100x < Hadoop, GraphLab 5x > Pregel, Graphlab ~
MPI (Recommendation/ALS, CoSeq/GMM, NER)
• NSDI 2012: Spark 20x < Hadoop (logistic regression, PageRank)
• VLDB 2012: Asterix (no comparisons)
• SIGMOD 2013: Cumulon 5x < SystemML
• VLDB 2013: Giraph ~ GraphLab (Connected Components)
• SIGMOD 2014: SimSQL vs. Spark vs. GraphLab vs. Giraph (GMM,
bayesian regression, HMM, LDA, imputation)
• VLDB 2014: epiC ~ Impala, epiC ~ Shark, epiC 2x < Hadoop (Grep, Sort,
TPC-H Q3, PageRank)
A quick and dirty meta-analysis of
Big Data systems literature
Pregel (Malewicz)
Hadoop 2008
2009
2010
2011
2012
2013
2014
HaLoop (Bu)
Spark (Zakaria)
Vertica (Pavlo)
~100x faster
SystemML (Ghoting)
Hyracks (Borkar)
GraphLab (Low)
faster
Cumulon (Huang)
comparable or
inconclusive
Giraph (Tian)
Dremel (Melnik)
SimSQL (Cai)
epiC (Jiang)
Impala (Cloudera)
Shark (Xin)
HIVE (Thusoo)
“The good old days”
“WTF?”

• …to facilitate experiments to determine who performs well at what
• …to orchestrate multiple systems in production (assuming there is no dominant winner)
3
We need big data middleware

• Relational stuff
• but also
– linear algebra?
– graph algorithms?
– signal/image processing?
• Appears to imply at least tables and arrays
So what does this middleware need to afford?

Big Data Middleware
Syntaxes
Common IntermediateRepresentation
Clients
Data andAnalyticsPlatforms
Goals:• Comparability• Portability• Reasoning• Multi-Server
Applications
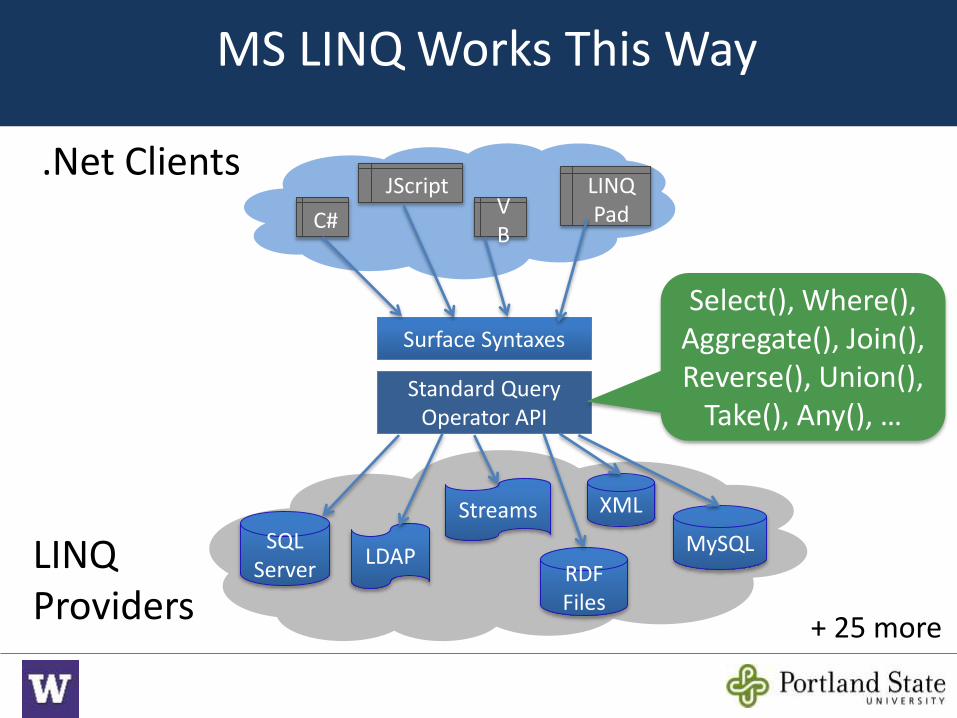
MS LINQ Works This Way
Surface Syntaxes
Standard Query Operator API
.Net Clients
LINQ Providers
SQLServer RDF
Files
MySQL
Streams
LDAP
C#
JScriptVB
LINQPad
Select(), Where(), Aggregate(), Join(), Reverse(), Union(),
Take(), Any(), …
XML
+ 25 more

Translate Everything to Operator Exprs
Surface Syntax
Standard Query Operator API
.Net Clients
LINQ Providers
SQLServer RDF
Files
MySQL
Streams
LDAP
C#
JScriptVB
LINQPad
XML
from b in DNA
where b.call = ‘G’
select b.prob
DNA
.Where(b.call = ‘G’)
.Select(b.prob)
Select
Where
DNA

Why Wasn’t Previous Slide the Last One?
• LINQ model is ordered collections
We need multi-D arrays and appropriate operations
• LINQ doesn’t handle multi-provider queries
Want a single query that maps to SciDB + ScaLAPACK, say
LINQ client would have to move intermediates
• LINQ doesn’t support (control) iteration
Common in graph algs and machine learning (e.g., K-means)
LINQ client has to orchestrate computation

Advocating a Similar Approach
• Standard set of operators
• But a broader data model
• Spans at least tables and arrays
• Includes iteration

Top Dog API (TDA)
TDA
MyriaX
SciDBRDBMS
ScaLAPACKBLAS
SQL
BQL
AQLMyriaQ
Translators
Compilers

Basis for TDA: Tarrays
• Table model with 0 or more DIMENSION attributes
• Operators act appropriately on dimensions
• Trying to capture enough semantics to find correct translations
• Dimensions + key declaration = arrays

Example Tarray Declarations
Create TARRAY DNA
Integer Dimension pos Range 1 to 300000;
Char call;
Float probability;
Primary Key(I)
Create TARRAY myMatrix
Integer Dimension J Range 1 to 100;
Integer Dimension K;
Float Val;
Primary Key (J, K);

Example Tarray Operator: Filter
Must respect DIMENSION attributesFilter(call = ‘G’) Filter(pos >
3)
DNA(ps cl prb)
1 A .8
2 G .9
3 T .7
4 G .8
5 G .5
6 C .6
7 A .9
…
DNA(ps cl prb)
1 - -
2 G .9
3 - -
4 G .8
5 G .5
6 - -
7 - -
…
DNA(ps cl prb)
4 G .8
5 G .5
6 C .6
7 A .9
…

Dimension Info Guides Translation
Filter(T, A > 2)
SELECT *
FROM T
WHERE A > 2
SELECT I,
(if A>2 then A else -) AS A
FROM T
AA is DIMENSION(or no dims)
AA is not DIMENSION

1/31/2015 Bill Howe, UW 15
Stop the madness
At scale, arrays are sparse
A sparse array is just a relation

select A.i, B.k, sum(A.val*B.val)
from A, B
where A.j = B.j
group by A.i, B.k
Matrix multiply in RA
Matrix multiply
That doesn’t seem so bad so far.

sparsity exponent (r s.t. m=nr)
Complexity
exponent
n2.38
mn
m0.7n1.2+n2
slide adapted from ZwickR. Yuster and U. Zwick, Fast Sparse Matrix Multiplication
n = number of rows
m = number of non-zerosComplexity of matrix multiply
naïve sparse algorithm
best known sparse algorithm
best known dense algorithmlots of room
here

select AB.i, C.m, sum(AB.val*C.val)
from
(select A.i, B.k, sum(A.val*B.val)
from A, B
where A.j = B.j
group by A.i, B.k
) AB,
C
where AB.k = C.k
group by AB.i, C.m
A x B x C
select A.i, C.m, sum(A.val*B.val*C.val)
from A, B, C
where A.j = B.j
and B.k = C.k
group by A.i, C.m
A(i, j, val)B(j, k, val)C(k, m, val)
take three sparse matrices
Now compute
multiway hypercube join:O (|A|/p + |B|/p^2 + |C|/p)
Group by:~O (N)
But wait, there’s more…..

2 seconds, balanced
Hypercube shuffle
Partitioned hash join
43 seconds, tons of skew
Task: self-multiply with 1M non-zeros

Maybe just forget databases – let’s compile RA to bare metal PGAS programs and let the HPC folks work their magic RADISH
[B. Myers, PLDI 15]
Does it work?Beats up on Shark/Spark. Competitive with hand-coded PR, Naïve Bayes

Last Slide
• We need middleware to bring order out of chaos
– …to expose and exploit common idioms and capabilities, to
afford reasoning, to make experimental comparisons tractable
• The right abstraction seems to be some form of
“extended RA” (iteration, dimension attributes, etc.)
• But new optimization ideas are warranted (arithmetic-
aware rewrites, compiler tricks)
http://myria.cs.washington.edu





























