Embed Size (px)
Citation preview

Ideas for Managing your AWS Costs
AWS Cost Control

Top 6 CostsEc2, RDS, SQS, S3, Support, Data Xfer
Also in ProductionDynamoDB, Elasticache, EMR, Lambda
On OccasionRedshift, Aurora, Kinesis, Data Pipeline
Of CourseIAM, Cloudfront, Route53, CloudTrail, SNS,
CWPlanning to Use
EFS, EC2 Container Service
We are “All In” on AWS

Some Useful Services to Gain VisibilityAWS Cost ExplorerNetflix ICE (via Teevity)CloudYN, Cloudability, Cloudcheckr,
CloudHealthTechAWS Billing and Detailed Billing CVS FilesCustom
Where are we?
Teevity is still building Teevity and welcomes any user that wants to register to go to http://teevity.com – they can register for free. More users provides data to help may Teevity better.
Teevity does not compete with the OSS version of Ice. They are building on top of it and around it (adding things to make it better) . The plan is to release a large and rich use-case oriented documentation on both NetflixOSS/Ice and Teevity in the coming month (http://docs.teevity.com)
Teevity plans to release a version on the AWS Marketplace a called "Teevity Incognito" so users can have their own instances.
Most Graphs are from Teevity
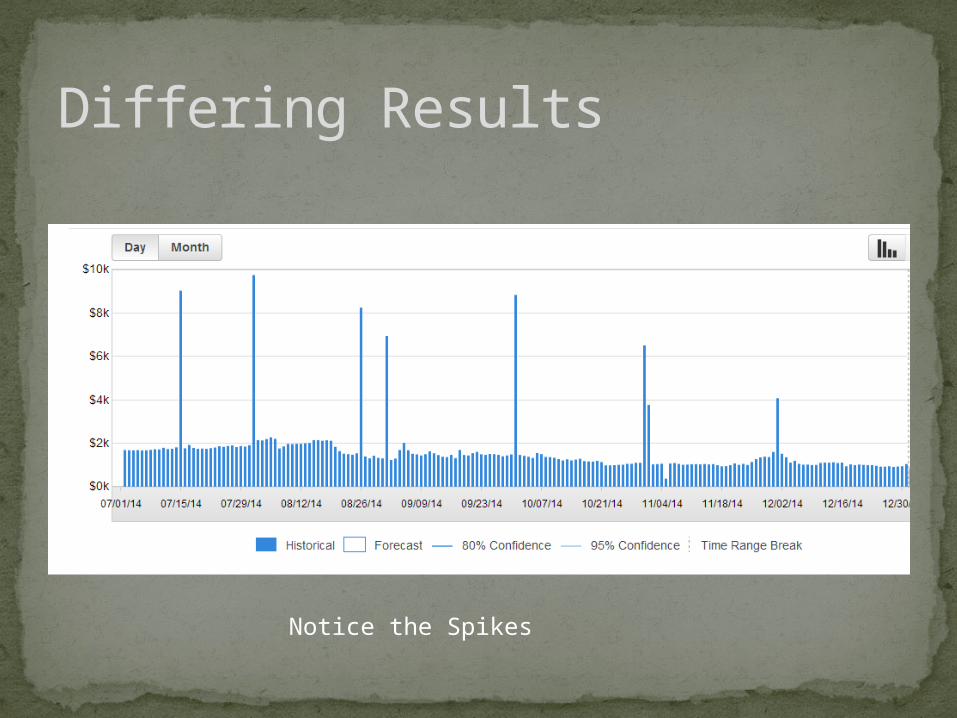
Differing Results
Notice the Spikes
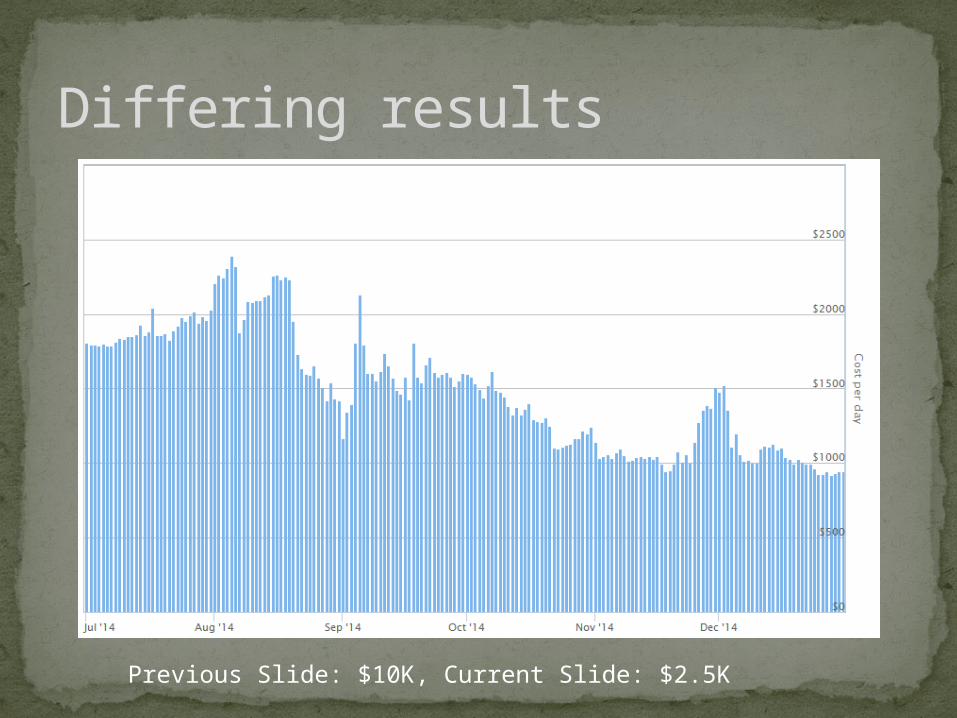
Differing results
Previous Slide: $10K, Current Slide: $2.5K
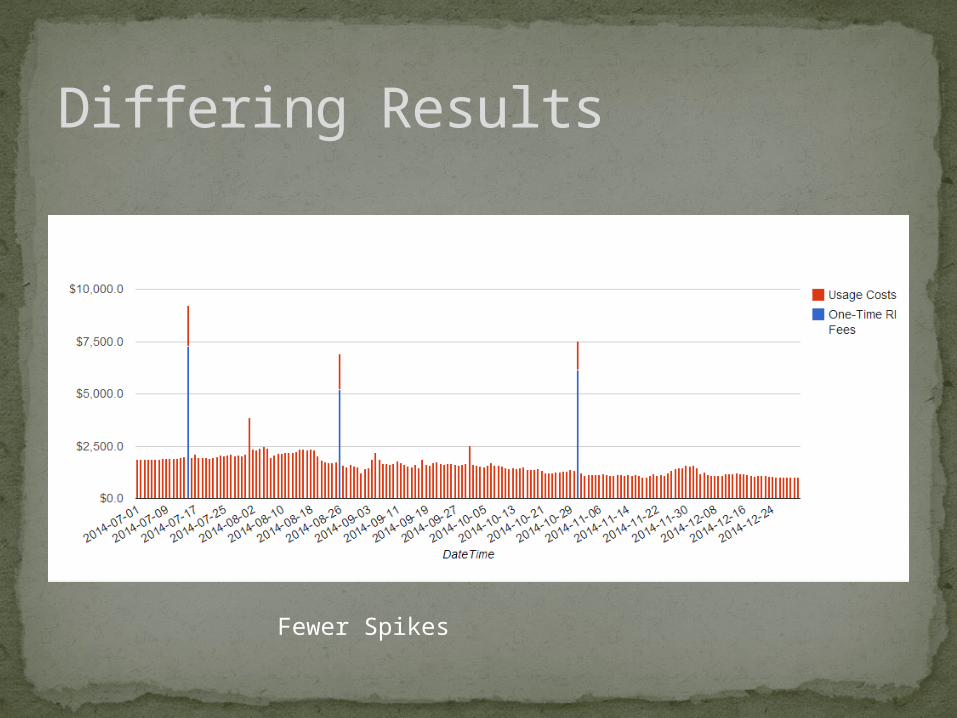
Differing Results
Fewer Spikes
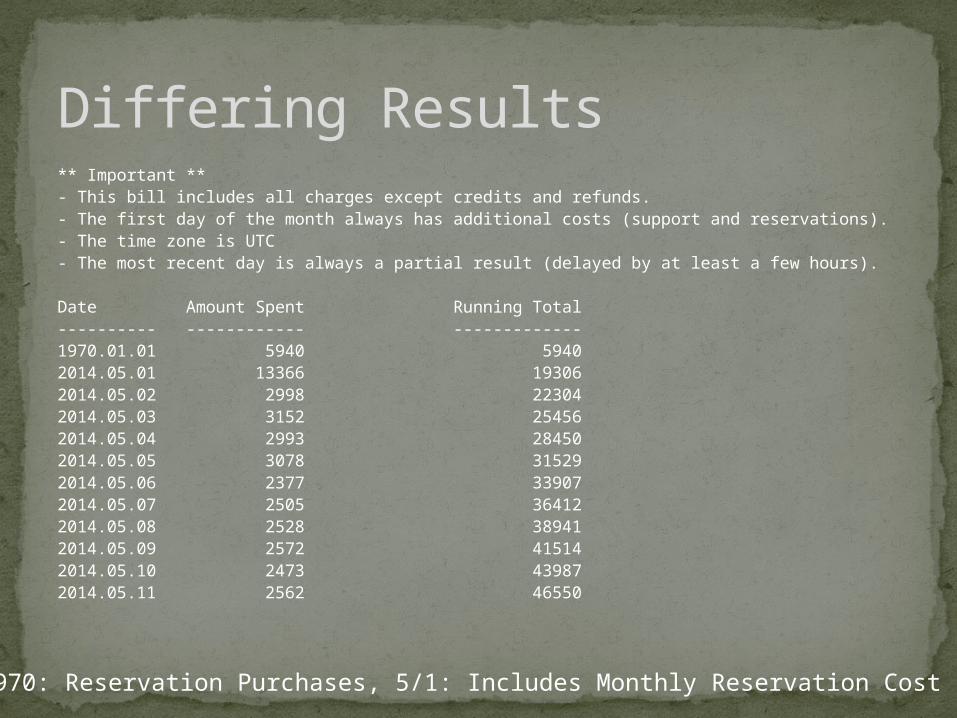
** Important **- This bill includes all charges except credits and refunds.- The first day of the month always has additional costs (support and reservations).- The time zone is UTC- The most recent day is always a partial result (delayed by at least a few hours). Date Amount Spent Running Total---------- ------------ -------------1970.01.01 5940 59402014.05.01 13366 193062014.05.02 2998 223042014.05.03 3152 254562014.05.04 2993 284502014.05.05 3078 315292014.05.06 2377 339072014.05.07 2505 364122014.05.08 2528 389412014.05.09 2572 415142014.05.10 2473 439872014.05.11 2562 46550
Differing Results
1970: Reservation Purchases, 5/1: Includes Monthly Reservation Cost
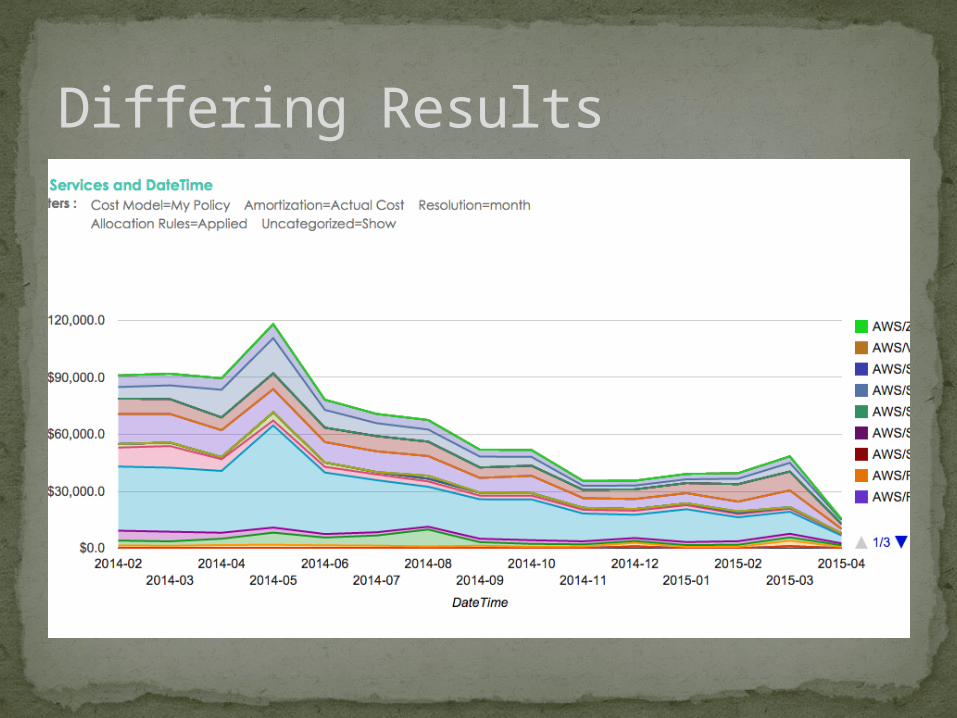
Differing Results
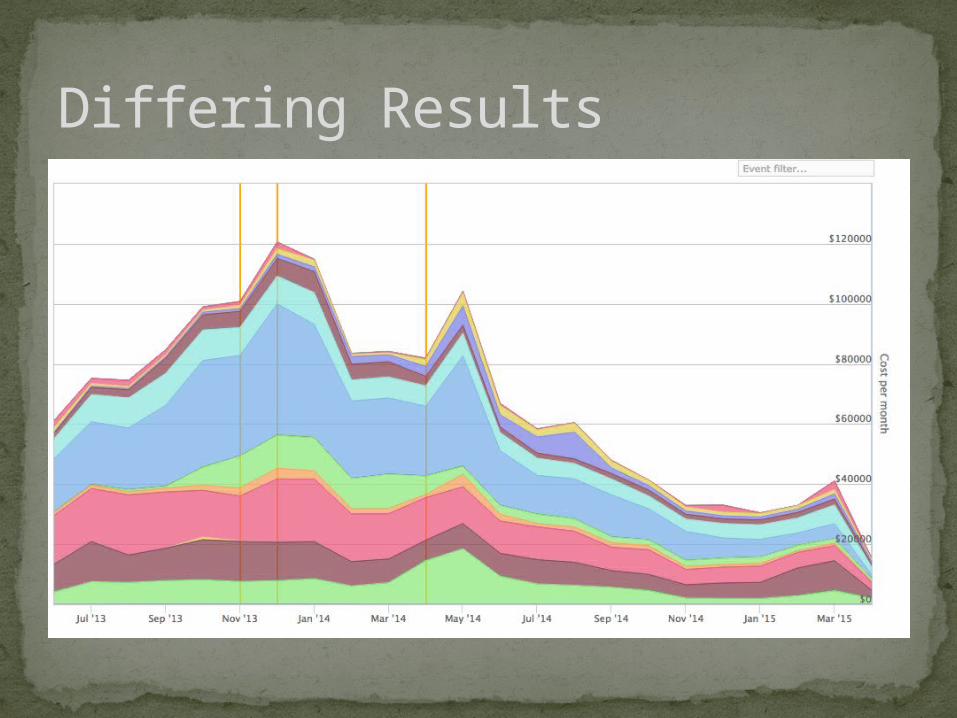
Differing Results
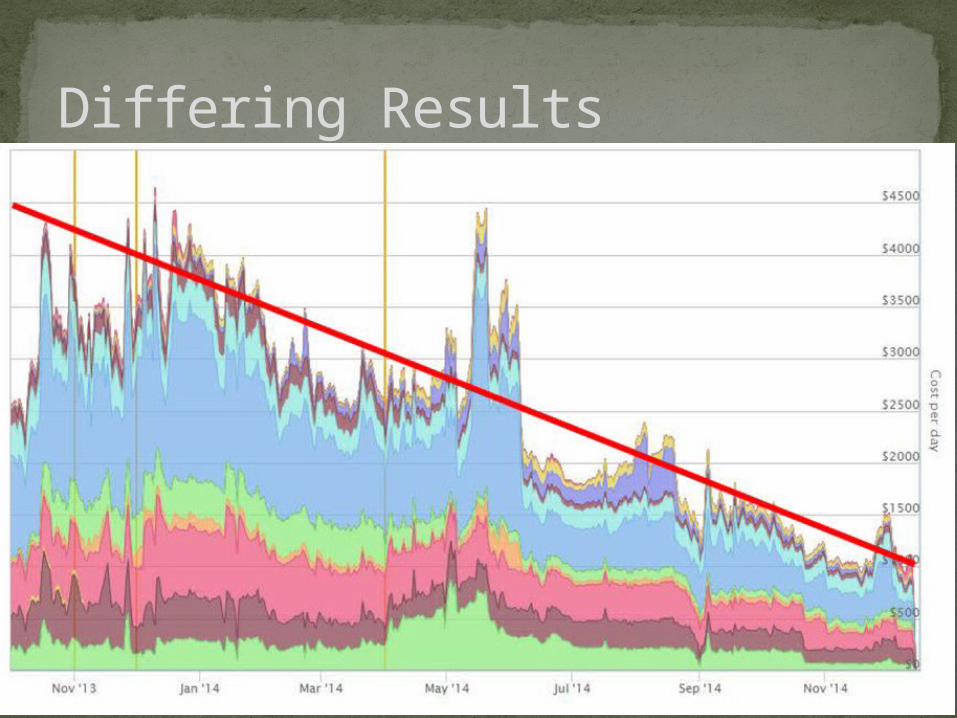
Differing Results

Amortized/Not AmortizedNew Services not IncludedSupport Included/Not IncludedDelayed ReportingReport Handling ErrorsConsolidation by Time ErrorsRefund/Credit HandlingTimeZone
Used Billing Invoice for AccuracyUsed Other Reports for Trends/ComparisonLet Accounting Sort out Amortization
Differing Results
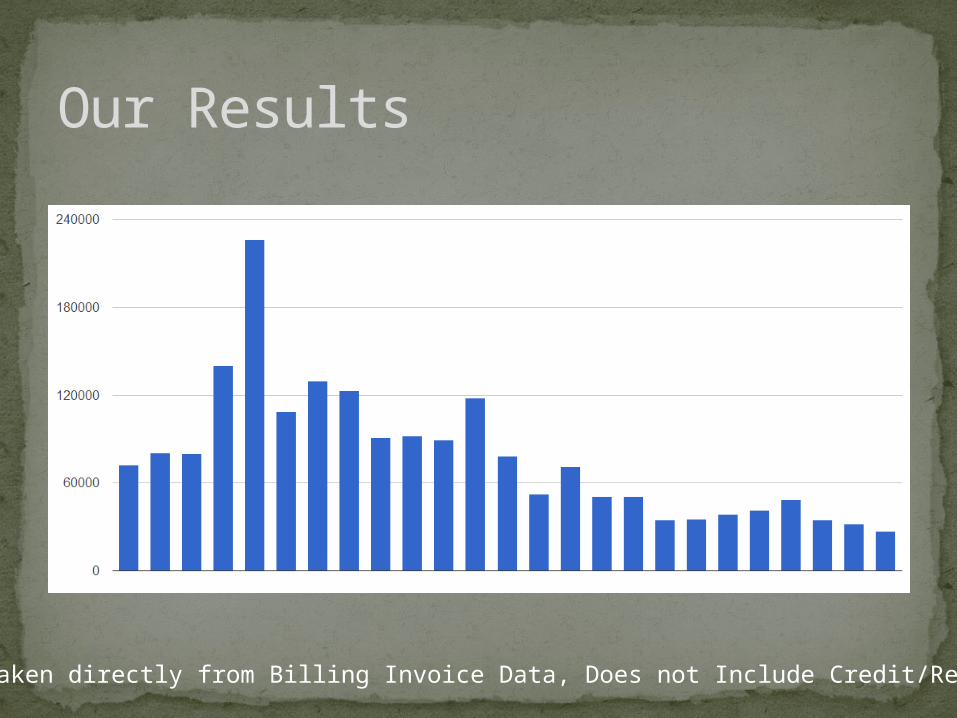
Our Results
Taken directly from Billing Invoice Data, Does not Include Credit/Refunds
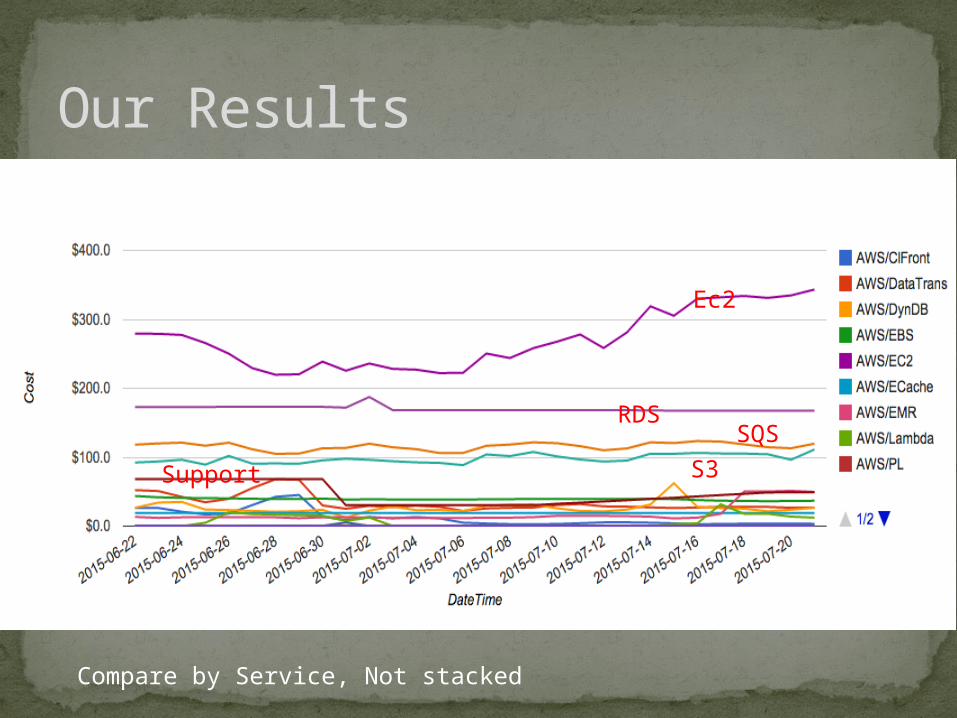
Our Results
Compare by Service, Not stacked
Ec2
RDSSQS
S3Support
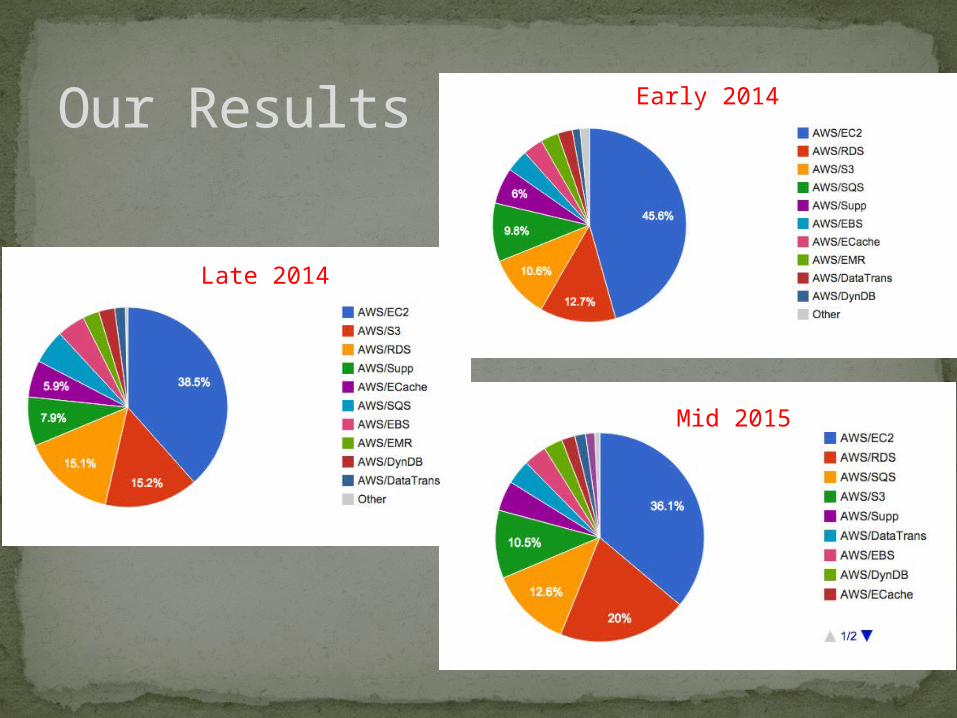
Our Results Early 2014
Late 2014
Mid 2015

Tags are your friendTag by
StackEnvironmentApplication
Scripts based on tagCost Control and Management Reports by
Tag
Identify Everything
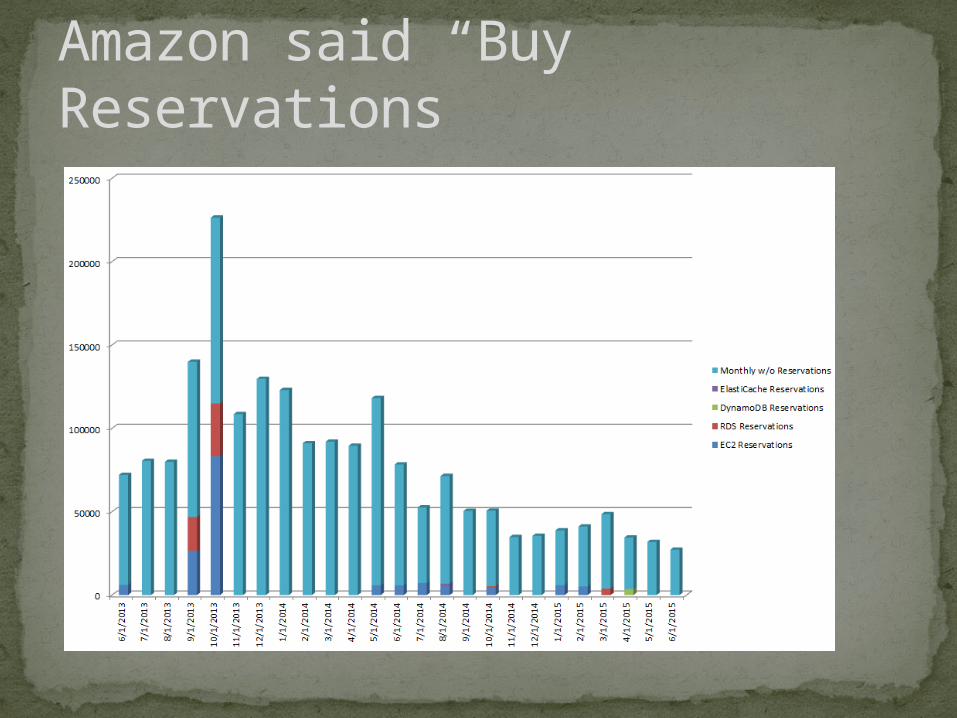
Amazon said “Buy Reservations”
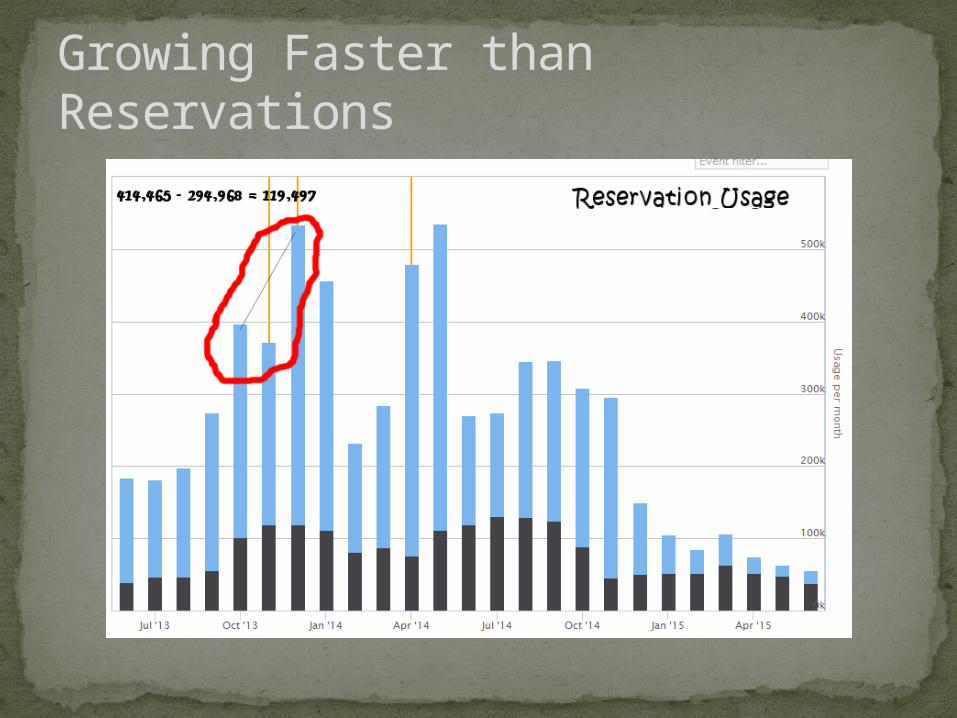
Growing Faster than Reservations
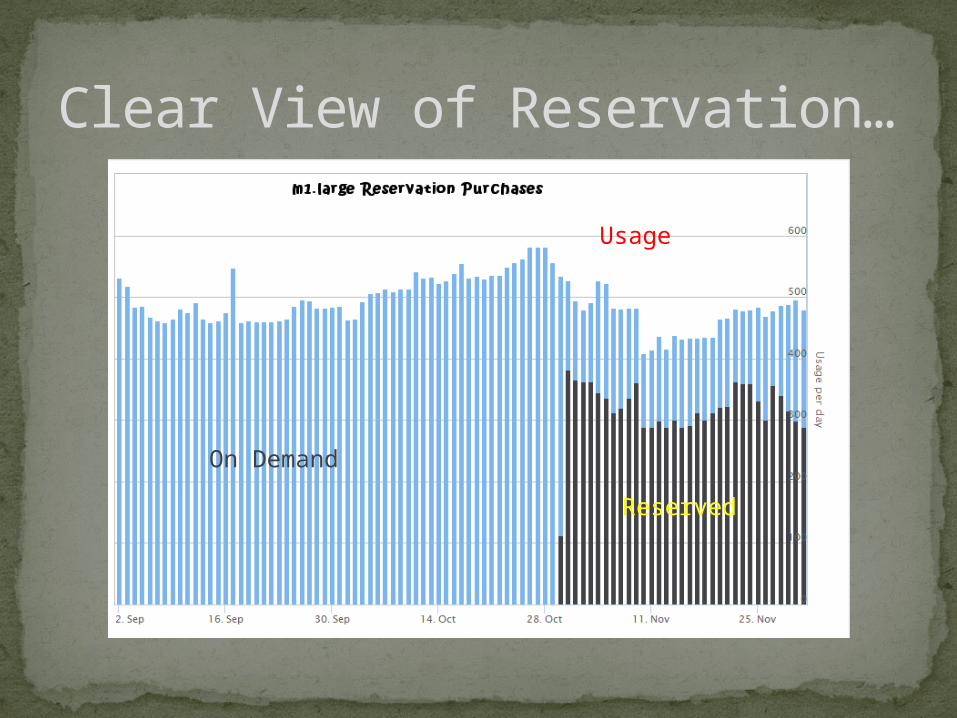
Clear View of Reservation…
On Demand
Reserved
Usage
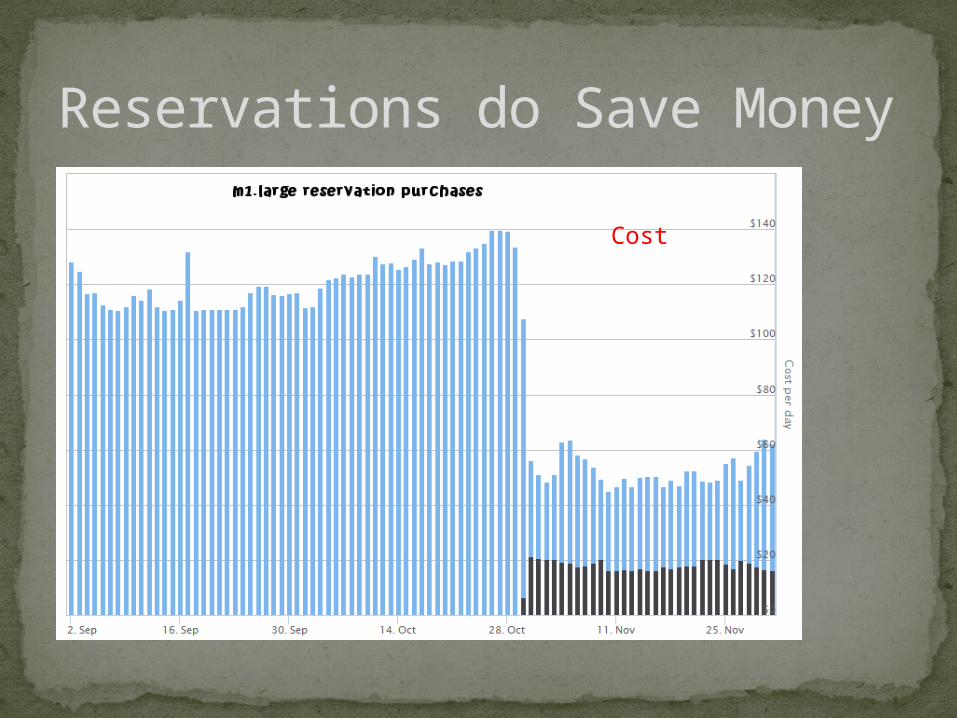
Reservations do Save Money
Cost
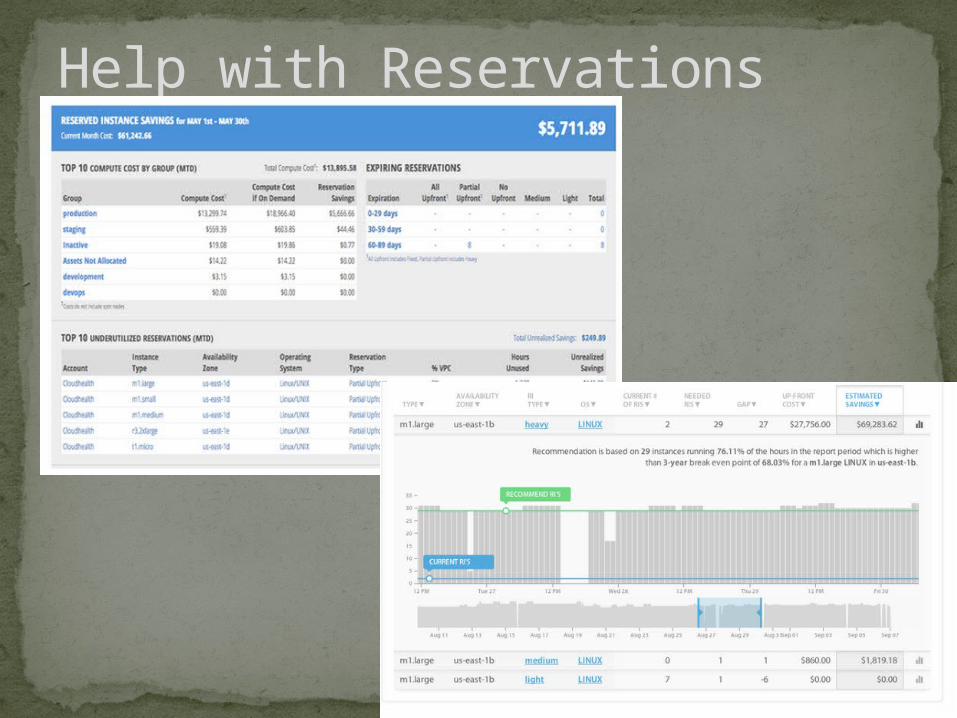
Help with Reservations
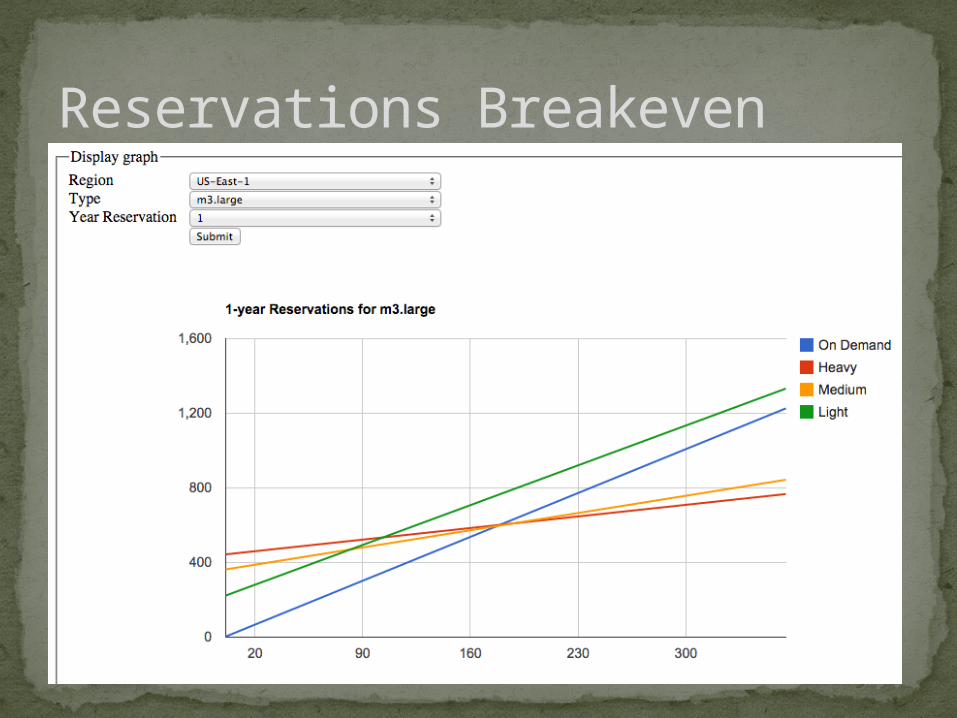
Reservations Breakeven
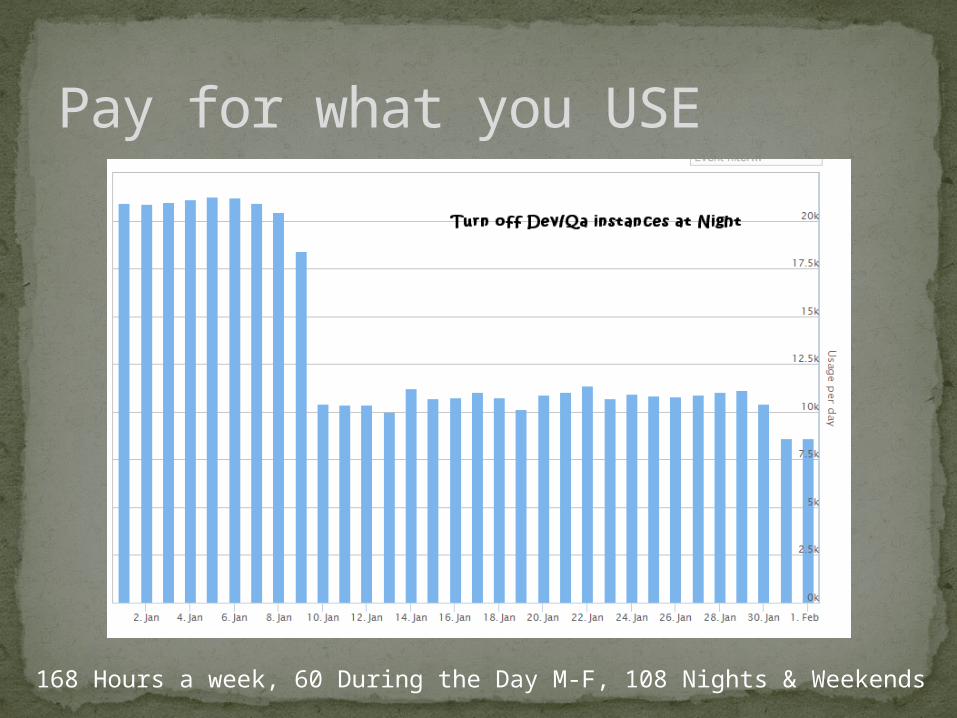
Pay for what you USE
168 Hours a week, 60 During the Day M-F, 108 Nights & Weekends
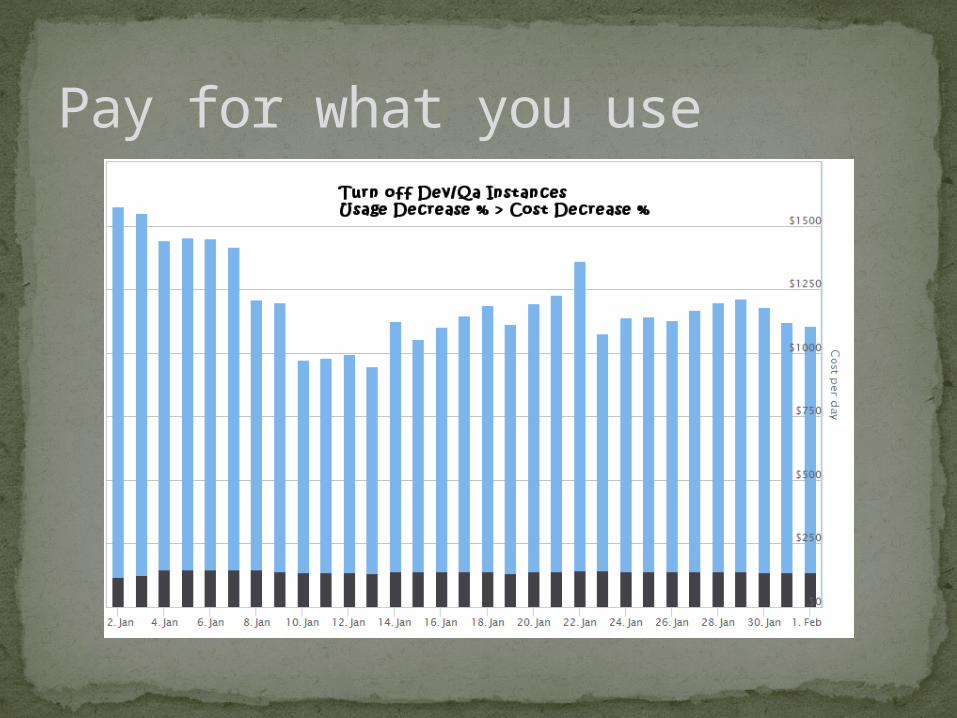
Pay for what you use

We saw the savings in turning off instancesWrote a script to turn off and on dailyComplaints about unavailability to work
Work from homeWork late/earlyData Loss from Instance Shutdowns
Went from 14 hours off to 3 hours offNeeded a way allow developers to start stop
instances
Culture plays an issue

usage: listASGs.py [-h] [-v] [-e ENVIRONMENT] [-n NAME] [-r REGION] [-a {suspend,resume,set,start,stop,store}] [-w] [-c CAPACITY] [--excludes EXCLUDES] [-k]
List Autoscaling Groups and Act on themoptional arguments: -h, --help show this help message and exit -v, --verbose Up the displayed messages or provide more detail -e ENVIRONMENT, --environment ENVIRONMENT Set the environment variable for the filter. You can chose 'all' as well as dev/qa/prd/ops/int/... -n NAME, --name NAME Set the base stack name for the filter. Default is everything -r REGION, --region REGION Set the region. Default is everything -a {suspend,resume,set,start,stop,store}, --action {suspend,resume,set,start,stop,store} Determines the action for the script to take -w, --html Print output in HTML format rather than text -c CAPACITY, --capacity CAPACITY Specifies the value for capacity. Enter as '#/#/#' in min, desired, max order --excludes EXCLUDES Enter a regular expression to exclude matchnames -k, --kind Display the underlaying Instance Type
Developed script “listASGs.py”
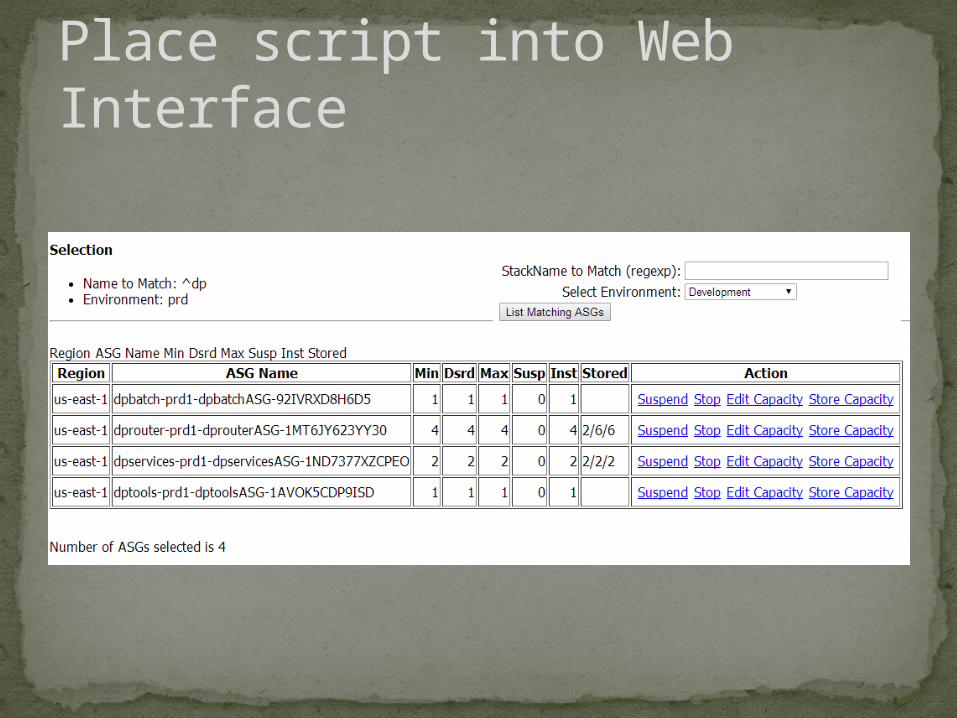
Place script into Web Interface
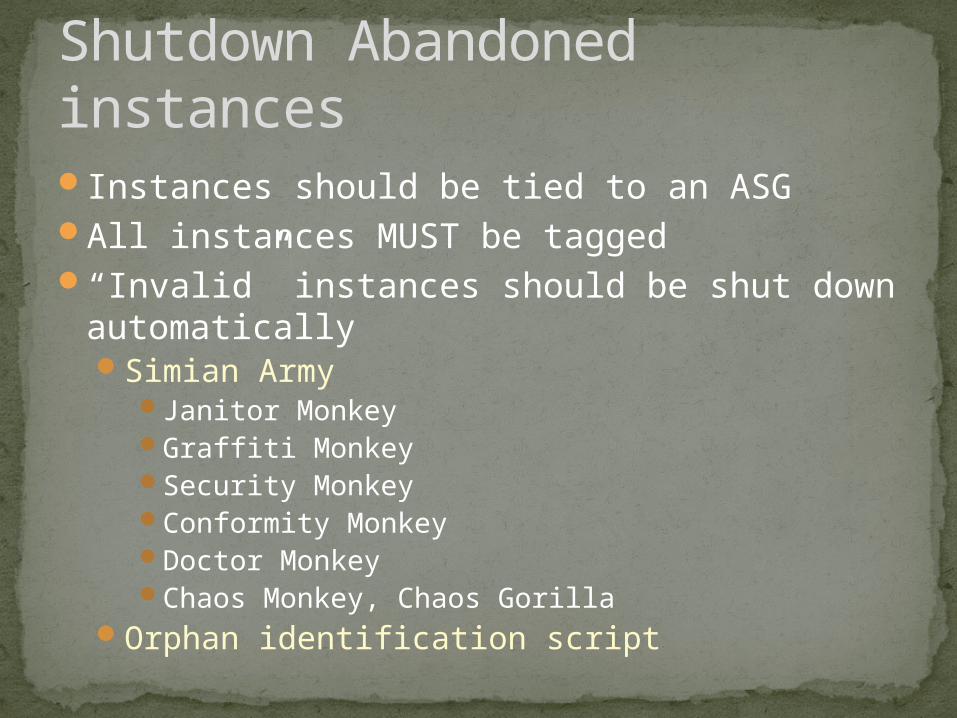
Instances should be tied to an ASGAll instances MUST be tagged“Invalid” instances should be shut down
automaticallySimian Army
Janitor MonkeyGraffiti MonkeySecurity MonkeyConformity MonkeyDoctor MonkeyChaos Monkey, Chaos Gorilla
Orphan identification script
Shutdown Abandoned instances
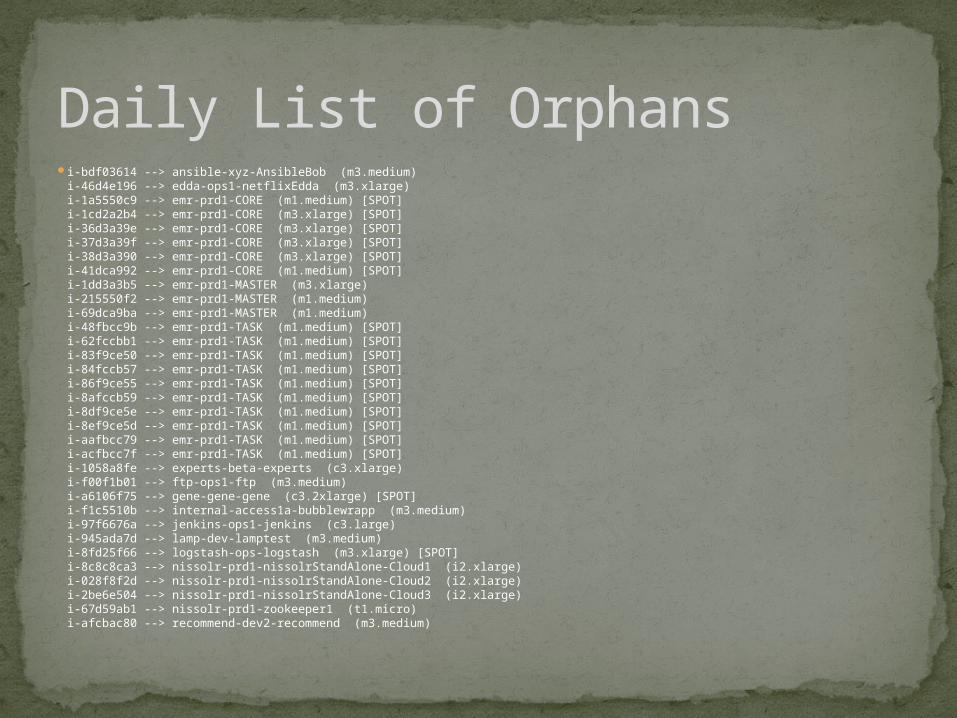
i-bdf03614 --> ansible-xyz-AnsibleBob (m3.medium)i-46d4e196 --> edda-ops1-netflixEdda (m3.xlarge)i-1a5550c9 --> emr-prd1-CORE (m1.medium) [SPOT]i-1cd2a2b4 --> emr-prd1-CORE (m3.xlarge) [SPOT]i-36d3a39e --> emr-prd1-CORE (m3.xlarge) [SPOT]i-37d3a39f --> emr-prd1-CORE (m3.xlarge) [SPOT]i-38d3a390 --> emr-prd1-CORE (m3.xlarge) [SPOT]i-41dca992 --> emr-prd1-CORE (m1.medium) [SPOT]i-1dd3a3b5 --> emr-prd1-MASTER (m3.xlarge)i-215550f2 --> emr-prd1-MASTER (m1.medium)i-69dca9ba --> emr-prd1-MASTER (m1.medium)i-48fbcc9b --> emr-prd1-TASK (m1.medium) [SPOT]i-62fccbb1 --> emr-prd1-TASK (m1.medium) [SPOT]i-83f9ce50 --> emr-prd1-TASK (m1.medium) [SPOT]i-84fccb57 --> emr-prd1-TASK (m1.medium) [SPOT]i-86f9ce55 --> emr-prd1-TASK (m1.medium) [SPOT]i-8afccb59 --> emr-prd1-TASK (m1.medium) [SPOT]i-8df9ce5e --> emr-prd1-TASK (m1.medium) [SPOT]i-8ef9ce5d --> emr-prd1-TASK (m1.medium) [SPOT]i-aafbcc79 --> emr-prd1-TASK (m1.medium) [SPOT]i-acfbcc7f --> emr-prd1-TASK (m1.medium) [SPOT]i-1058a8fe --> experts-beta-experts (c3.xlarge)i-f00f1b01 --> ftp-ops1-ftp (m3.medium)i-a6106f75 --> gene-gene-gene (c3.2xlarge) [SPOT]i-f1c5510b --> internal-access1a-bubblewrapp (m3.medium)i-97f6676a --> jenkins-ops1-jenkins (c3.large)i-945ada7d --> lamp-dev-lamptest (m3.medium)i-8fd25f66 --> logstash-ops-logstash (m3.xlarge) [SPOT]i-8c8c8ca3 --> nissolr-prd1-nissolrStandAlone-Cloud1 (i2.xlarge)i-028f8f2d --> nissolr-prd1-nissolrStandAlone-Cloud2 (i2.xlarge)i-2be6e504 --> nissolr-prd1-nissolrStandAlone-Cloud3 (i2.xlarge)i-67d59ab1 --> nissolr-prd1-zookeeper1 (t1.micro)i-afcbac80 --> recommend-dev2-recommend (m3.medium)
Daily List of Orphans
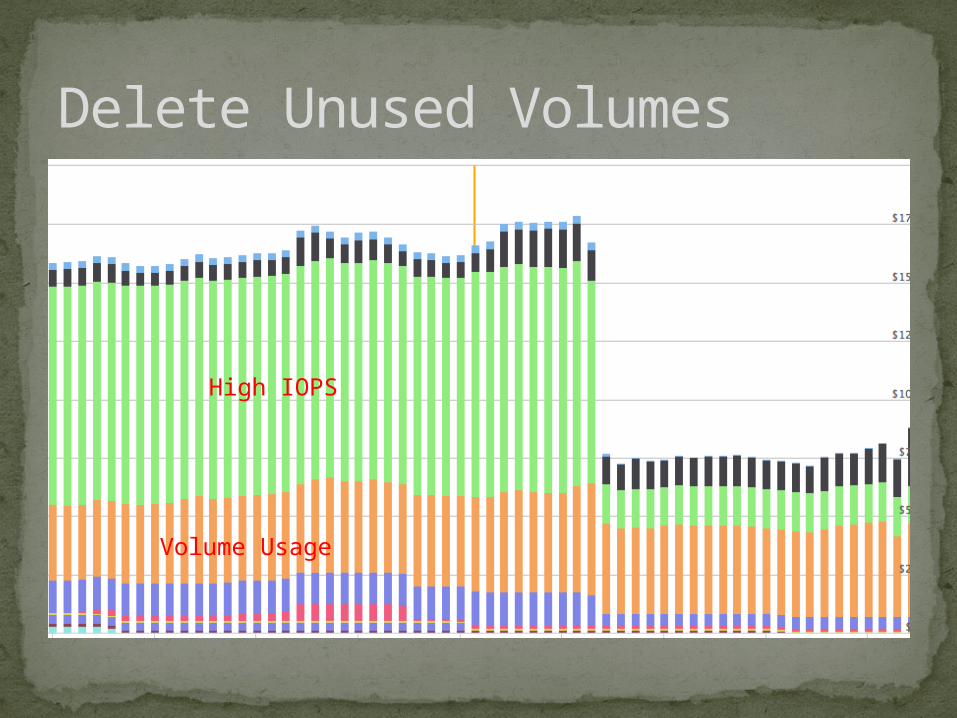
Delete Unused Volumes
High IOPS
Volume Usage
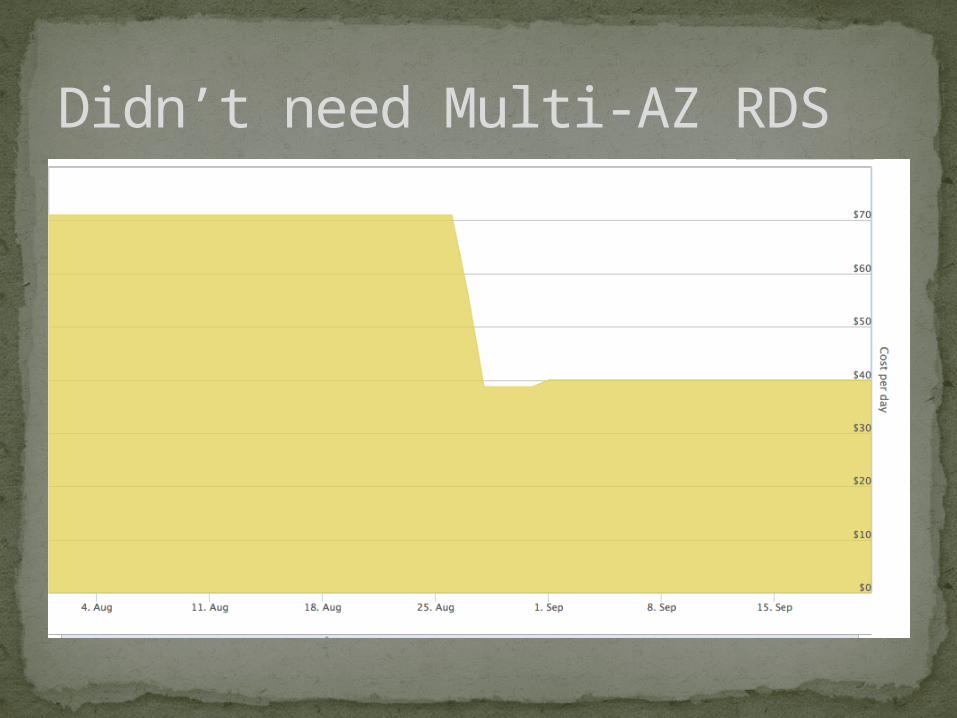
Didn’t need Multi-AZ RDS
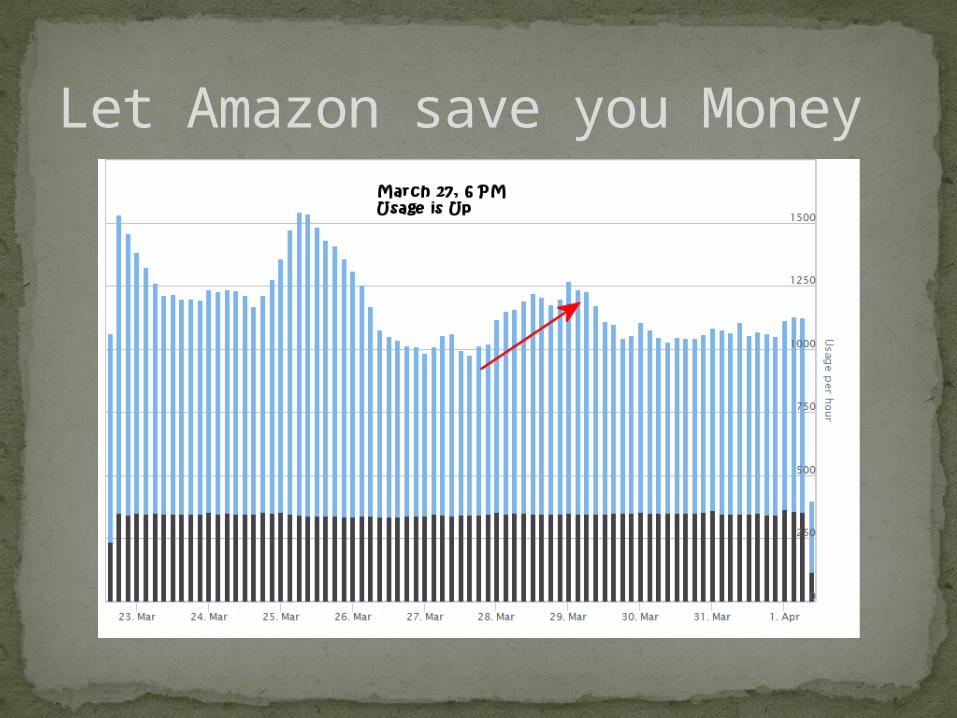
Let Amazon save you Money
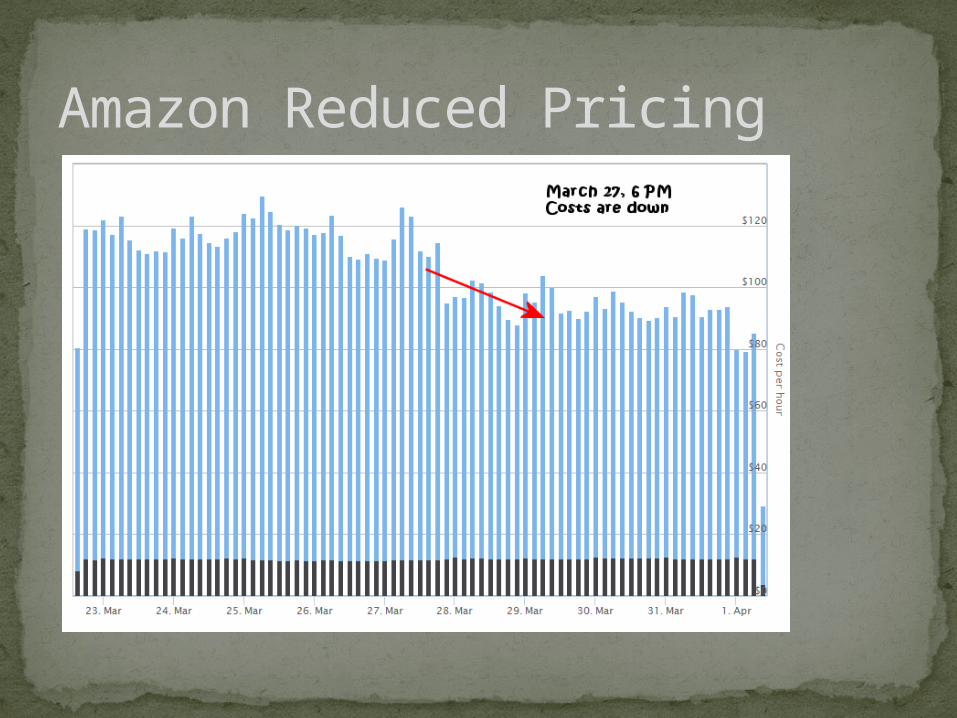
Amazon Reduced Pricing
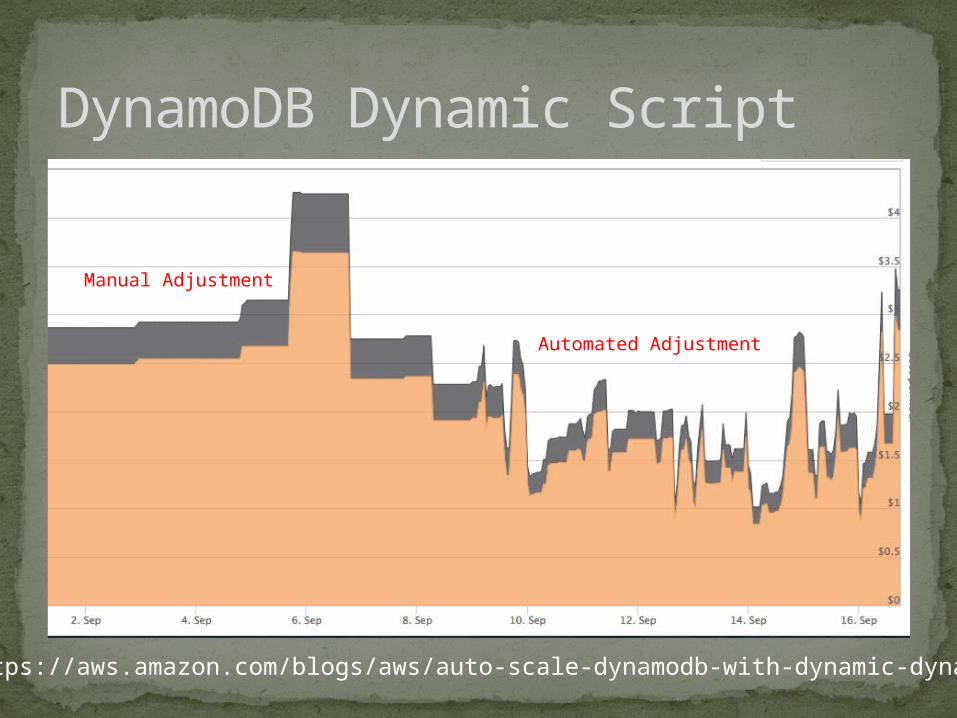
DynamoDB Dynamic Script
Manual Adjustment
Automated Adjustment
https://aws.amazon.com/blogs/aws/auto-scale-dynamodb-with-dynamic-dynamodb/
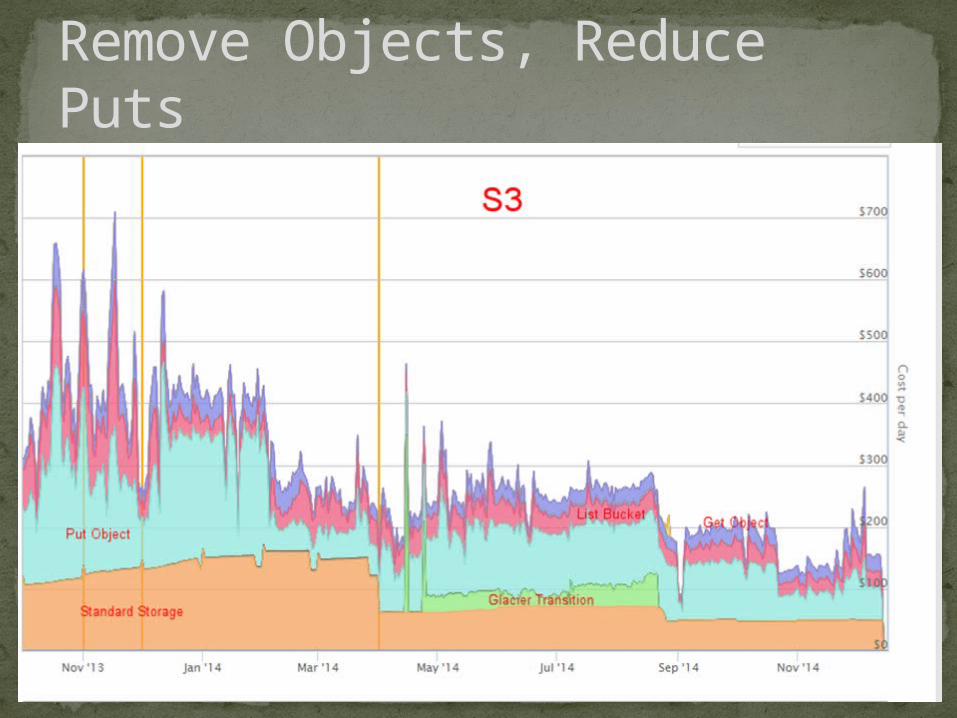
Remove Objects, Reduce Puts

Refactor the Code for Efficiencies
RDS
DynamoDB
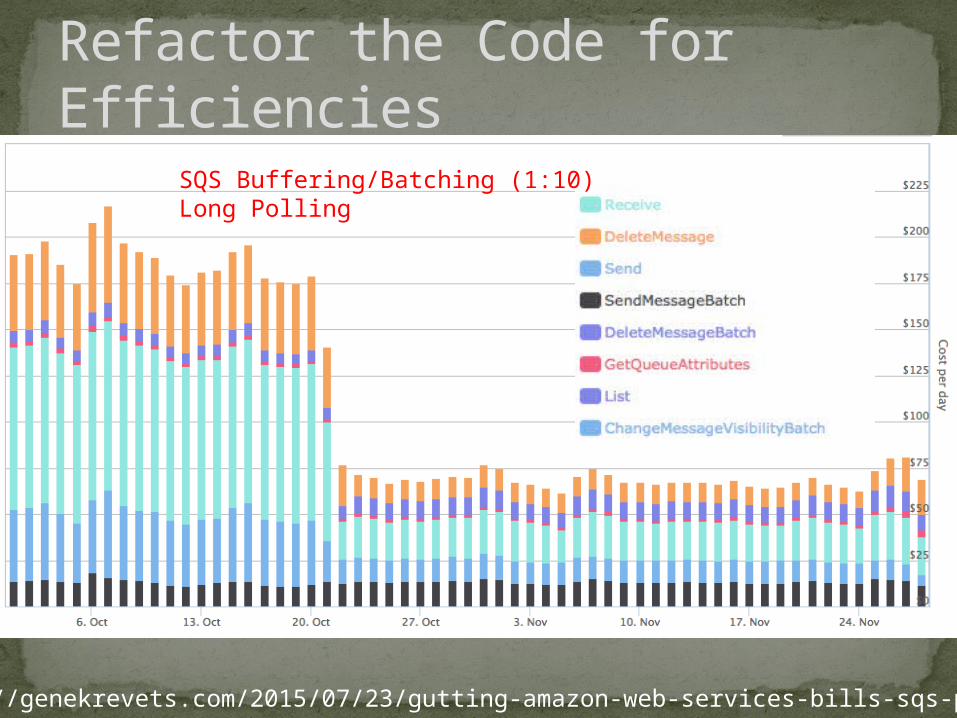
Refactor the Code for Efficiencies
SQS Buffering/Batching (1:10)Long Polling
http://genekrevets.com/2015/07/23/gutting-amazon-web-services-bills-sqs-part-1/
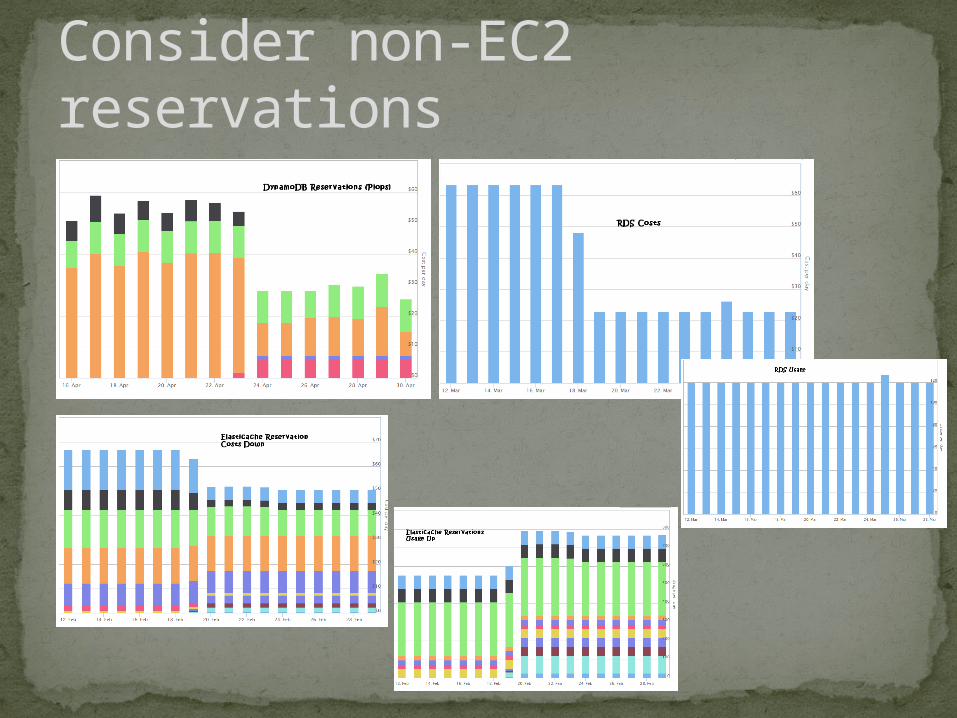
Consider non-EC2 reservations

Can’t change across FamiliesCan’t Sell
Non-EC2 Reservations
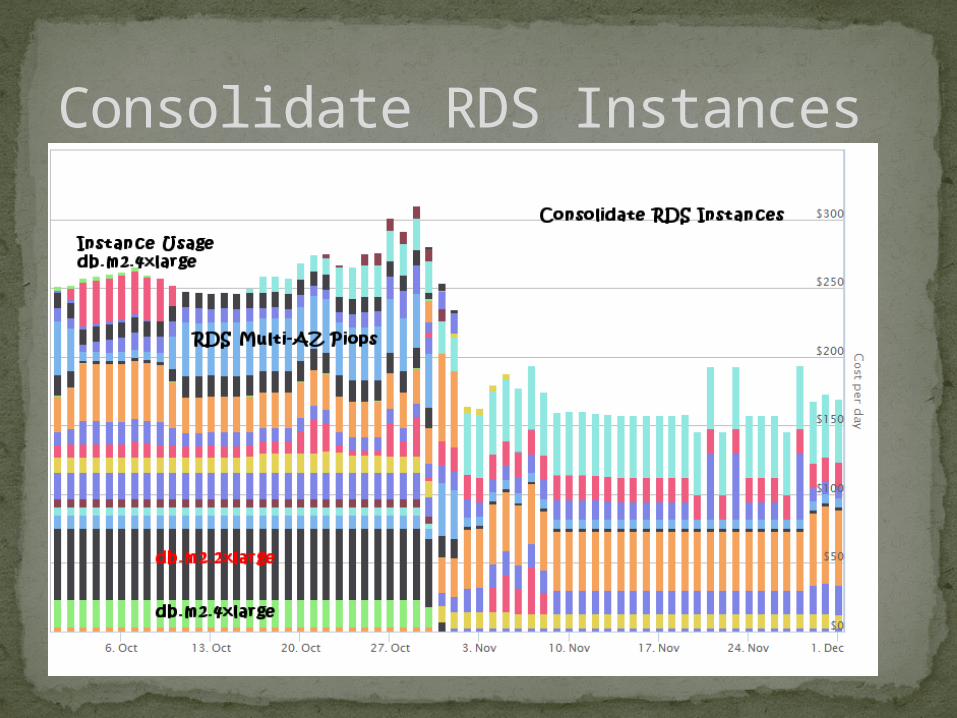
Consolidate RDS Instances
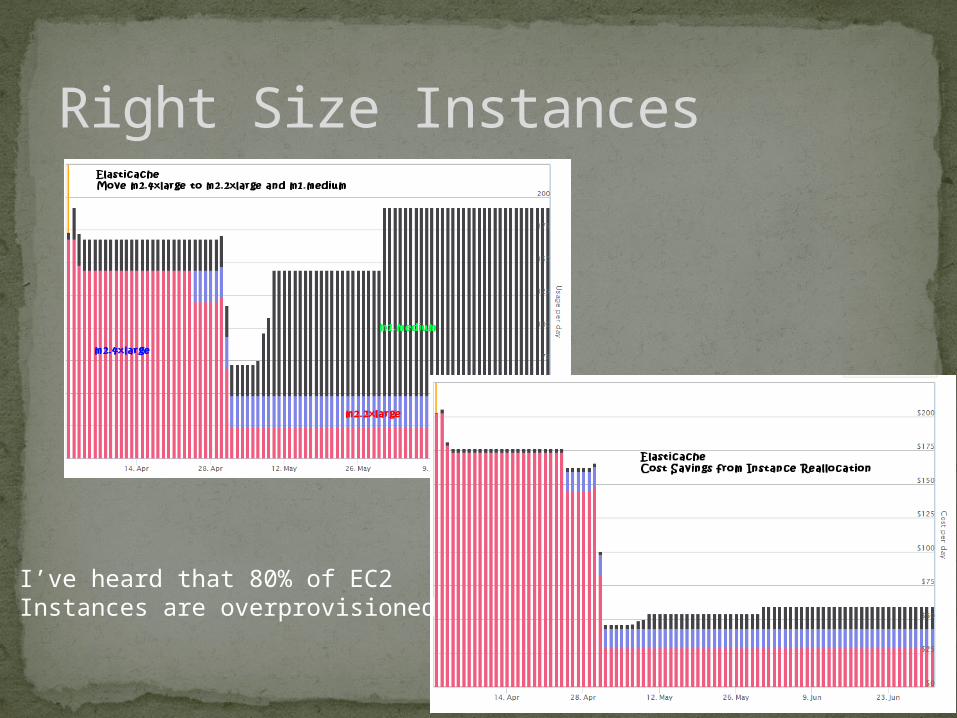
Right Size Instances
I’ve heard that 80% of EC2Instances are overprovisioned
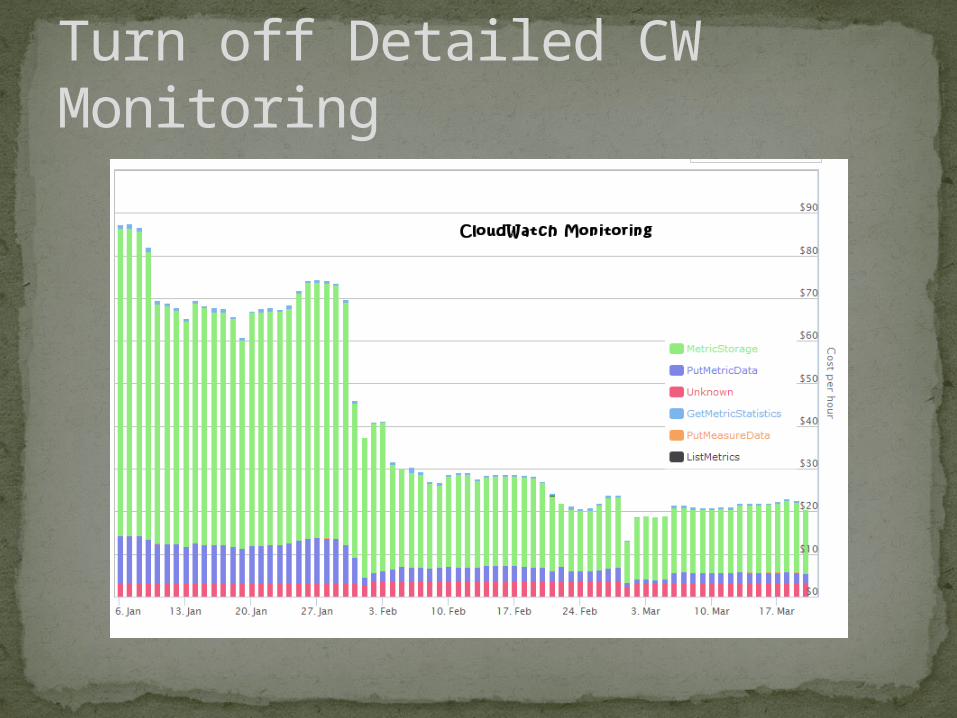
Turn off Detailed CW Monitoring

Create Separate Accounts for DEV/QA/ProdOnly pay for Support on Prod
Reduce Support Costs
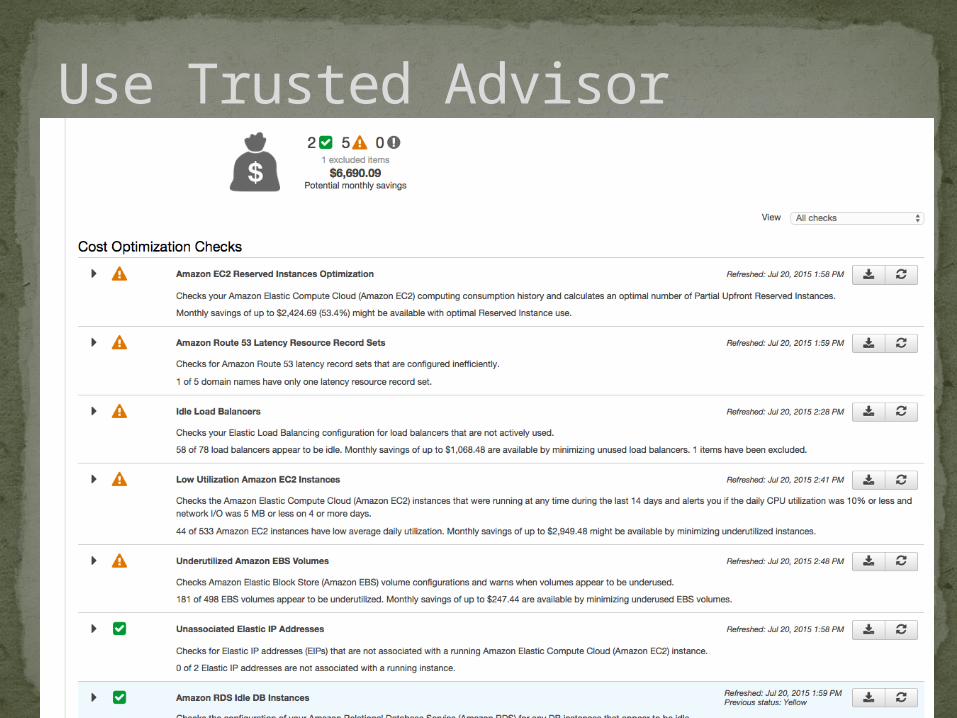
Use Trusted Advisor
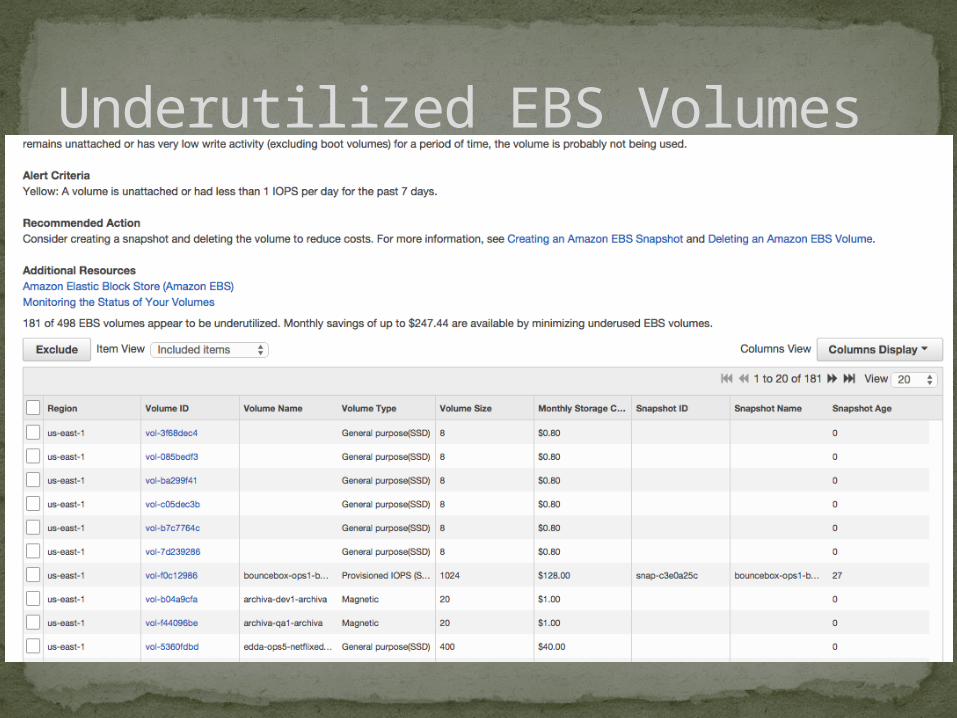
Underutilized EBS Volumes

Unattached Volumes can easily growYou can view unattached volumes by runningthe AWS cli command:
aws ec2 describe-volumes –output text | grep available
us-east-1a False 20 snap-5c4b92de available vol-f44096be standard
us-east-1a False 20 snap-5c4b92de available vol-b04a9cfa standard
us-east-1a False 60 20 snap-bf8db125 available vol-baae0c54 gp2
us-east-1a False 1200 400 snap-4629e4de available vol-5360fdbd gp2
us-east-1e False 48 16 snap-e49eb646 available vol-6c918e74 gp2
Review Unattached Volumes

Reservations
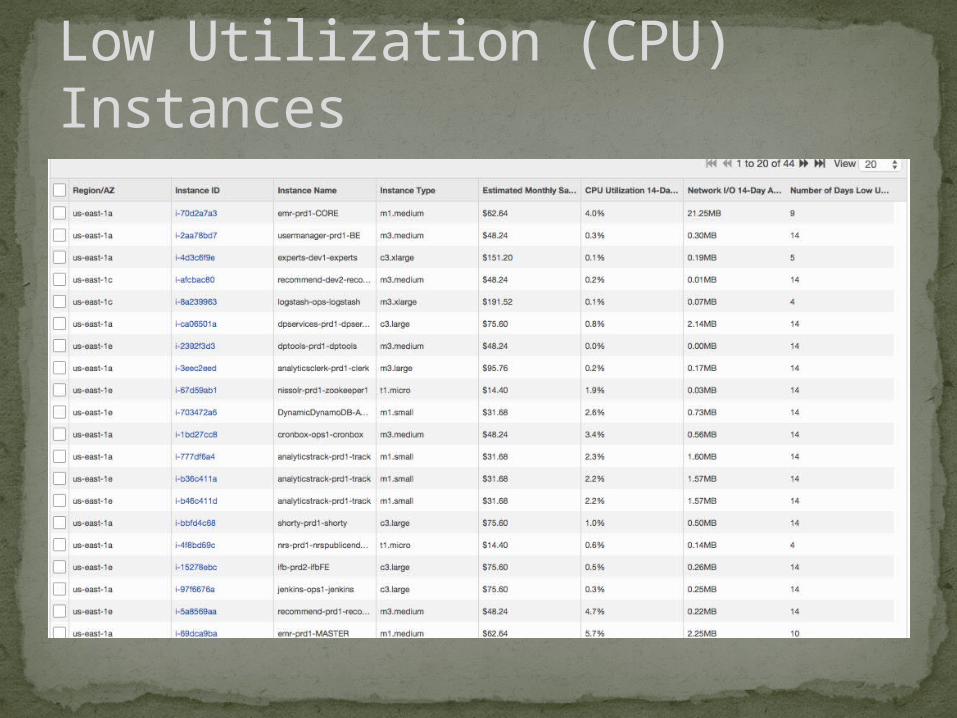
Low Utilization (CPU) Instances
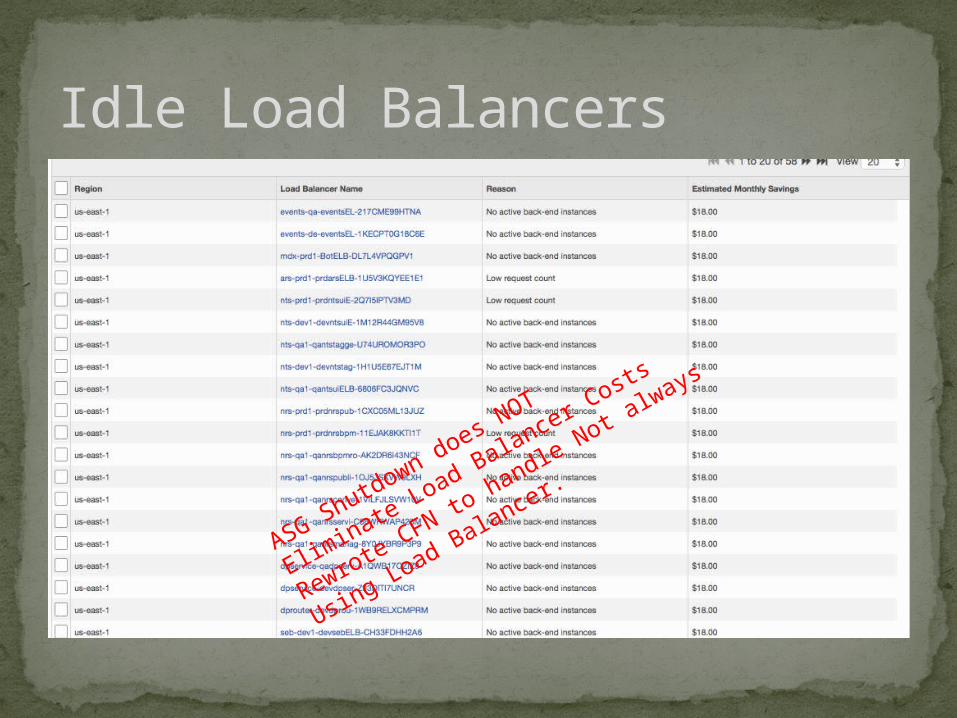
Idle Load Balancers
ASG Shutdown does NOT
Eliminate Load Balancer C
osts
Rewrote CFN to handle Not a
lways
Using Load Balancer.
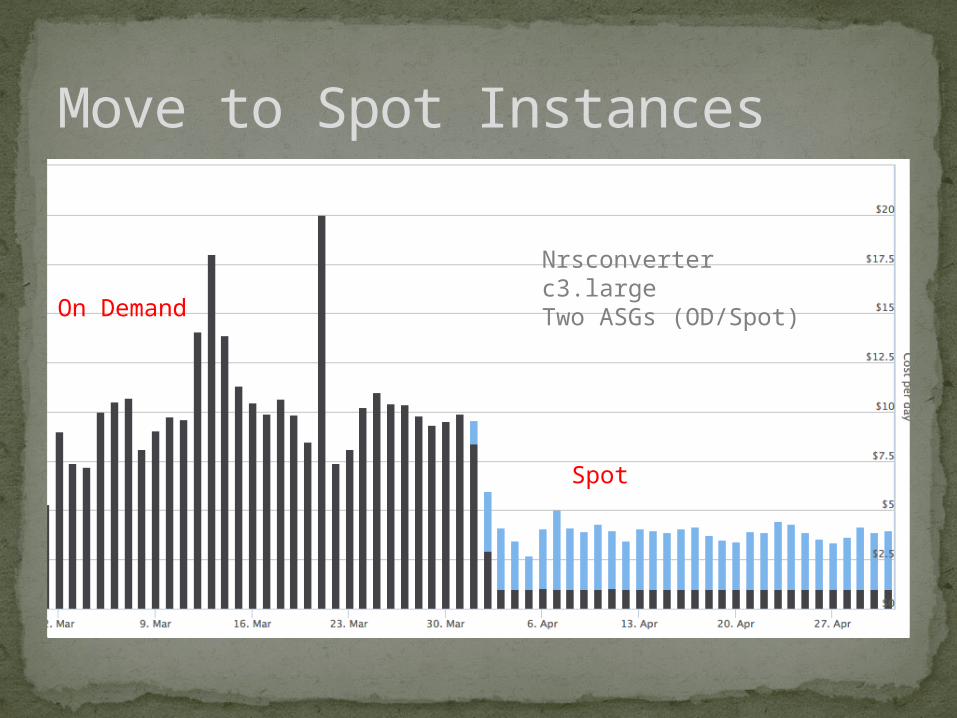
Move to Spot Instances
Nrsconverterc3.largeTwo ASGs (OD/Spot)On Demand
Spot
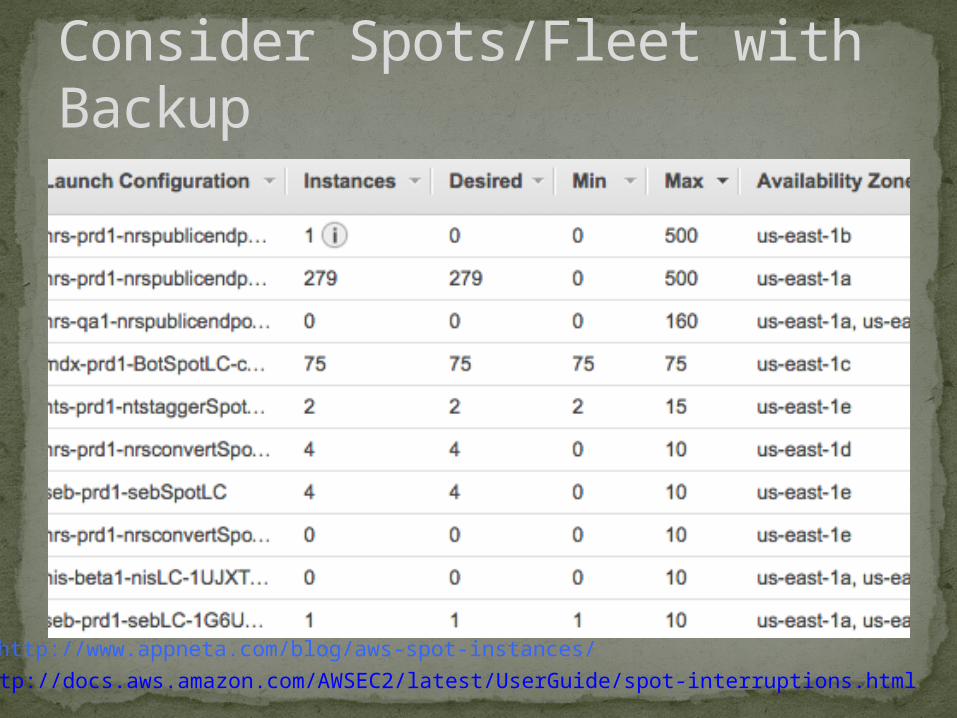
Consider Spots/Fleet with Backup
http://www.appneta.com/blog/aws-spot-instances/
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-interruptions.html

Initially, Multiple ASGs with Minimum On Demand
Discovered Spots stay up for long periodsMove all in to Spots with OnDemand BackupSwitching to Fleet with OnDemand BackupOnDemand Backup (Spots)
Two Minute Warning FlagSeparate ASG for On Demand is updated
Spots
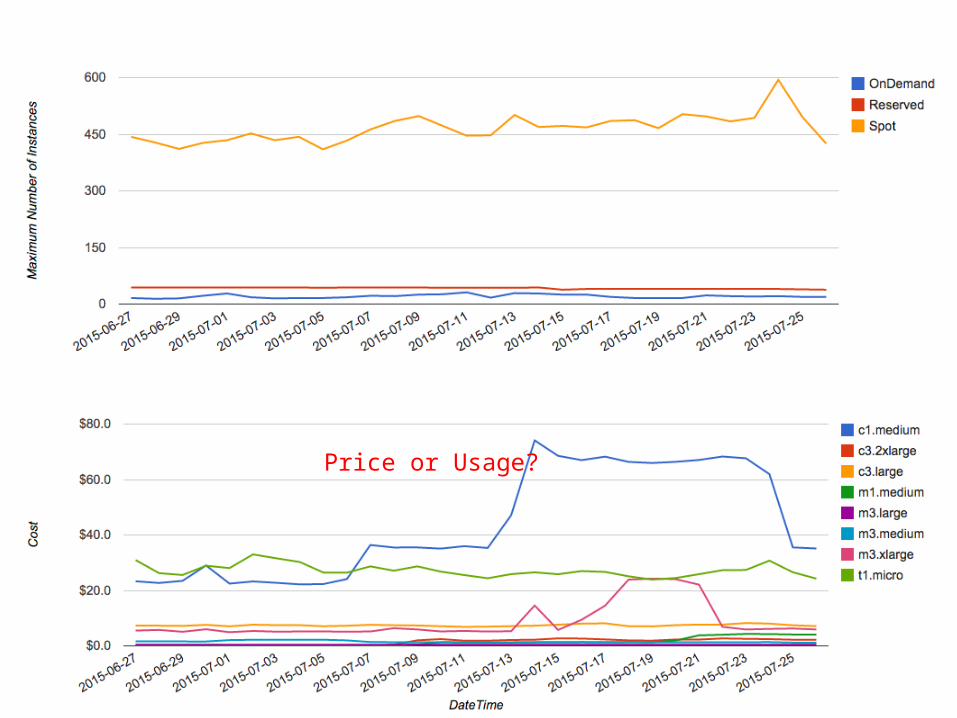
Price or Usage?
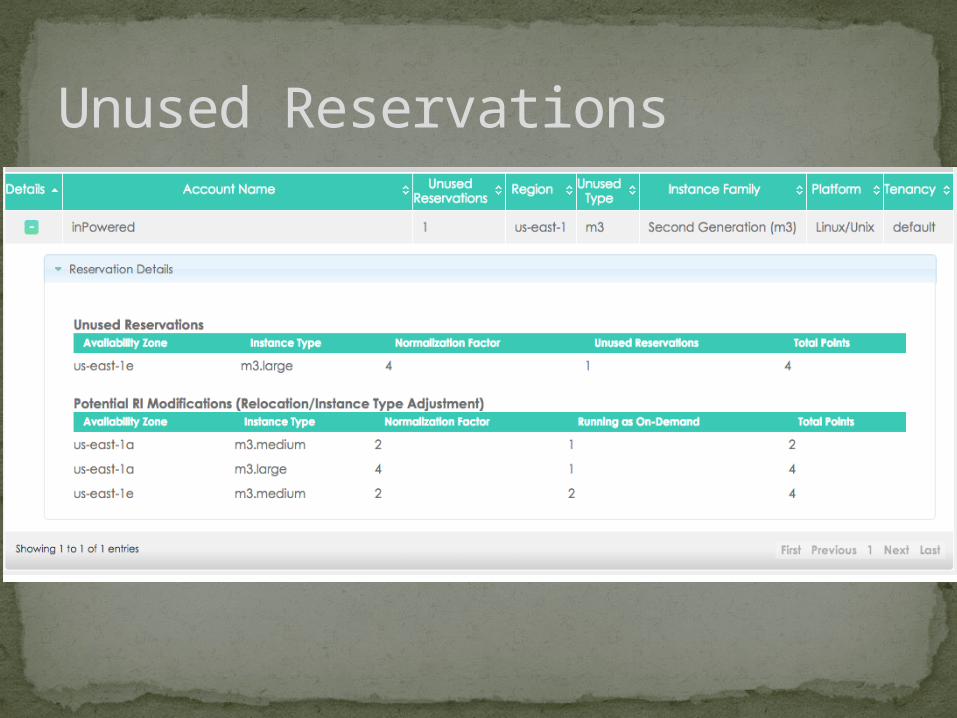
Unused Reservations
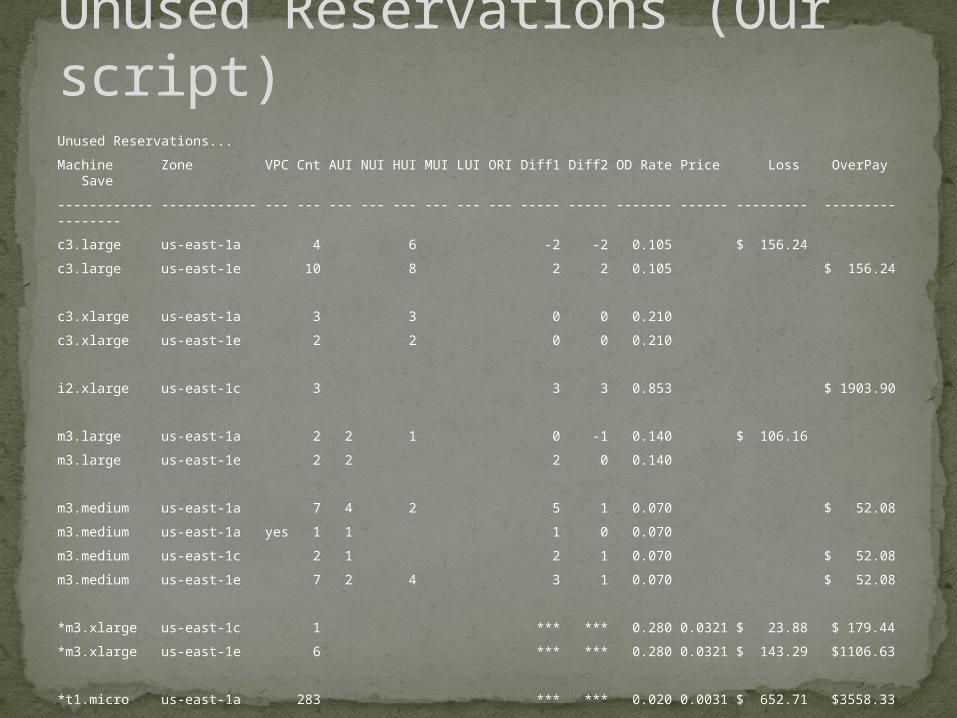
Unused Reservations...
Machine Zone VPC Cnt AUI NUI HUI MUI LUI ORI Diff1 Diff2 OD Rate Price Loss OverPay Save
------------ ------------ --- --- --- --- --- --- --- --- ----- ----- ------- ------ --------- --------- --------
c3.large us-east-1a 4 6 -2 -2 0.105 $ 156.24
c3.large us-east-1e 10 8 2 2 0.105 $ 156.24
c3.xlarge us-east-1a 3 3 0 0 0.210
c3.xlarge us-east-1e 2 2 0 0 0.210
i2.xlarge us-east-1c 3 3 3 0.853 $ 1903.90
m3.large us-east-1a 2 2 1 0 -1 0.140 $ 106.16
m3.large us-east-1e 2 2 2 0 0.140
m3.medium us-east-1a 7 4 2 5 1 0.070 $ 52.08
m3.medium us-east-1a yes 1 1 1 0 0.070
m3.medium us-east-1c 2 1 2 1 0.070 $ 52.08
m3.medium us-east-1e 7 2 4 3 1 0.070 $ 52.08
*m3.xlarge us-east-1c 1 *** *** 0.280 0.0321 $ 23.88 $ 179.44
*m3.xlarge us-east-1e 6 *** *** 0.280 0.0321 $ 143.29 $1106.63
*t1.micro us-east-1a 283 *** *** 0.020 0.0031 $ 652.71 $3558.33
Unused Reservations (Our script)

What can we do?Transfer between Availability ZonesTransfer within a FamilyModify Instance Type to match reservationMove to Spot or Fleet
Unused Reservations
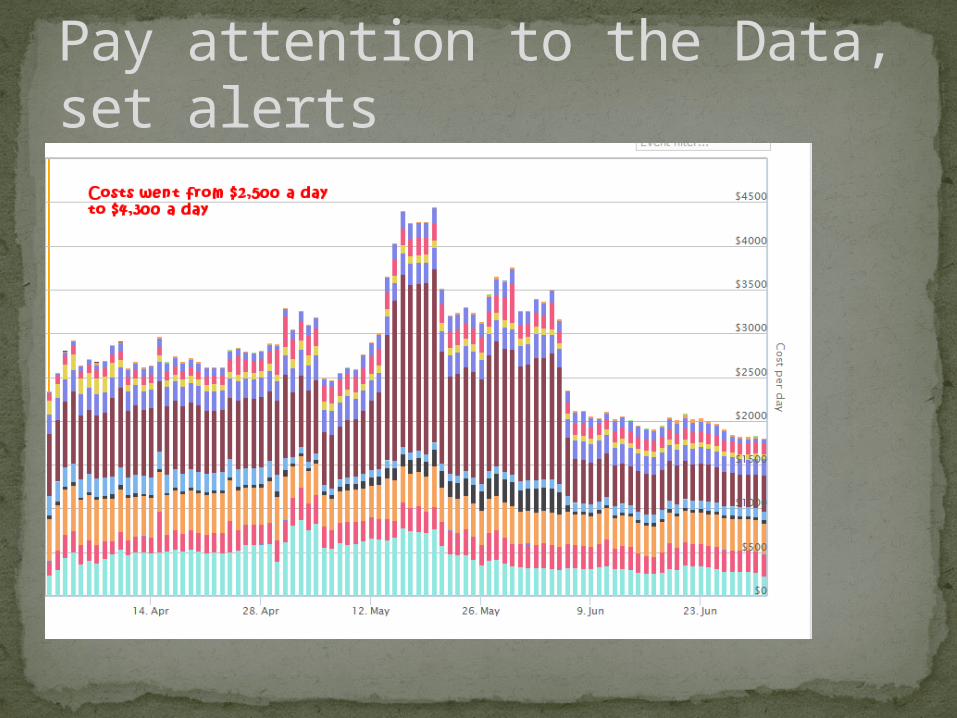
Pay attention to the Data, set alerts
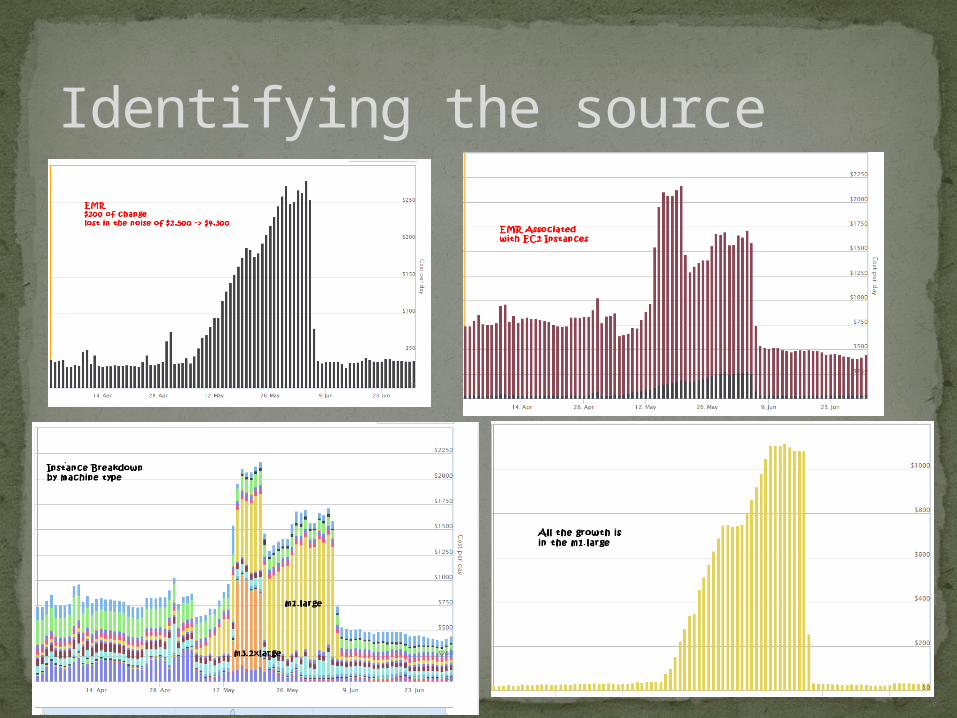
Identifying the source

DetailsSpecify how AWS is responsible
Unable to View EMRsOnly Site Admin Root Accounts can see all EMRsDid log tickets to help resolve but no answerAmazon recommends not using root accounts
Detailed steps of process to discoverWork with your account representative
Credit full amount requested, $21,560
Request a Refund

1. Set up Standards (Multiple Accounts, Tagging Names)2. Gain Visibility – Get a tool to visualize Costs and Assets3. Tag Assets (Use CloudFormation, Scripts, Graffiti Monkey)4. Turn off Unused Instances (We started with QA/Dev)5. Use ASGs to turn off instances when less traffic6. Buy EC2 Reservations, not once a year, monthly. Try to use
fewer instance families7. Give Developers a way to Easily Turn On/Off ASGs/Instances8. Set Rules - must have tags, must be tied to an ASG9. Use Simian Army (Janitor Monkey) to automatically handle
cleanup10. Evaluate Price/Time/Need for Failover (Multi-AZ, Instances
across Regions, Geography)
Recap

11. Take advantage of drop in prices with Amazon12. Use the DynamoDB Dynamic Script to manage Read/Write
Capacity13. Understand how you are charged and refactor code as
needed14. Use SQS batch requests15. Use SQS long polling16. Buy non-EC2 Reservations - DynamoDB, RDS, Elasticache,
Redshift17. Consolidate Instances (RDS, EC2, Elasticache)18. Put alarms in place, pay attention to the Data19. Where appropriate, ask Amazon for a Refund20. Right Size Instances (Low Usage/Memory to Smaller
Instances), Avoid overprovisioning
Recap

21. Turn off Detailed Cloud Watch Monitoring if Not Needed22. Consider moving Cloud Watch Linux Data to cheaper
service (Librato, Self Hosted Graphite, etc)23. Look at Trusted Advisor Reports24. Delete Unattached Volumes25. Right Size Low Utilization (CPU/Memory) instances, move
to smaller instances26. Consider moving legacy instances to current instance types
(more powerful and at a lower cost)27. Modify Setup to convert Unneeded Load Balancers28. Convert to Spot and/or Fleet Instances (Bidding Strategies)29. Monitor Unused Reservations30. Move cloudwatch alarms/tracking elsewhere
Recap

31. Optimize Cloudfront (do you need to be close to all of the edges?)32. Move into VPC33. Use Placement34. Use Docker, Consolidate Containers to fewer instances35. Pay attentions to EIPs36. Know/Understand your EMR usage and expectations37. Pay attention to Data Transfer costs38. Use the Right Storage: S3, Normal or Reduced Redundancy,
Glacier, AutoDelete Policies, etc.39. Leverage Services (CloudSearch, DynamoDB, Lambda,
ElastiCache, etc)40. Set Termination by ASG to be "Closest to Instance Hour“ (Saves
10-15%)41. Use “burstable” instances when appropriate (when it’s good you
can save 20-50% going from m3.medium or c3.large to t2.medium)
Recap

Incremental Fixes, Rome wasn’t built in a dayReview Data PeriodicallyEngage Developers in the process(es)Create a culture of cost awarenessHave the users of the resource own some of the
responsibility for costsGet some cost data visibility to stakeholders dailyCustomize cost data for stakeholder’s needsCost isn’t everything, get metrics that compare to
subscribers, pageviews, customers, api calls, urls processed. Increased usage means increased costs and if traffic means revenue, that could be very good.
Have a Plan





























