Embed Size (px)
Citation preview

Architectural evolution starting from Hadoop
Monica Franceschini Solution Architecture Manager
Big Data Competency Center Engineering Group

Experiences
ENERGY
Predictive analysis using
geo-spatial sensors data
FINANCE
Big Data architecture for
advanced CRM
Measure of energy
consumption for 15M
users
P.A.
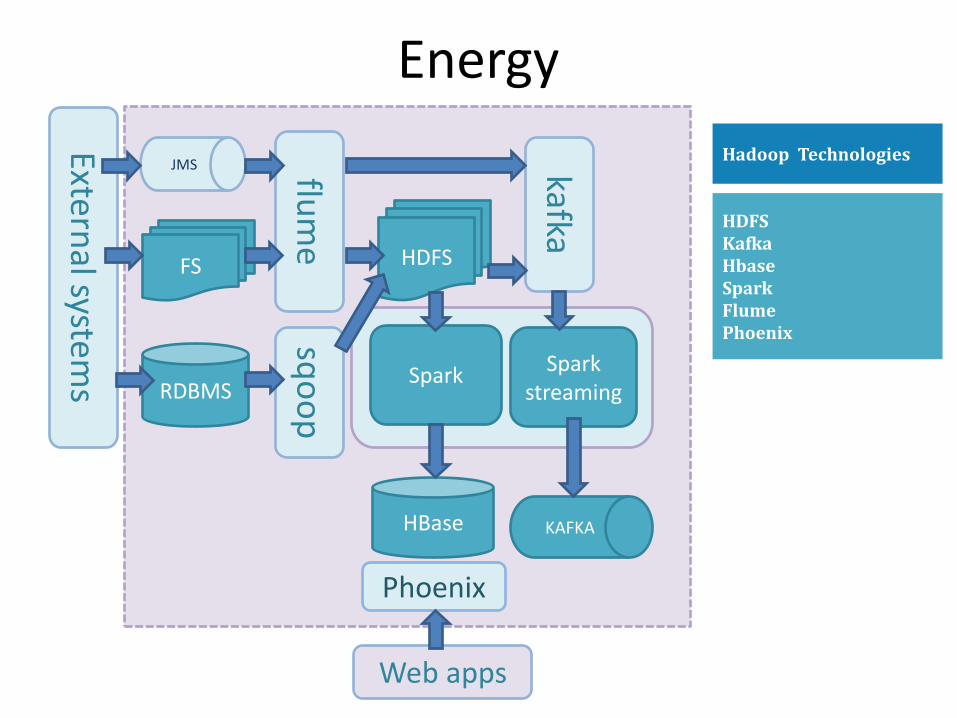
Energy
HDFS Kafka Hbase Spark Flume Phoenix
Hadoop Technologies External system
s
JMS
FS
flum
e HDFS
kafka
HBase KAFKA
Spark Spark streaming
Phoenix
Web apps
RDBMS
sqo
op

Finance
NFS Hbase Spark Phoenix
Hadoop Technologies External system
s
NFS HBase
Spark
Phoenix
Web apps
HD
FS

P.A.
HDFS Hbase Spark Spark MLlib Flume Phoenix
Hadoop Technologies External system
s
JMS flum
e
HDFS
HBase
Spark
Phoenix
Web apps
Spark MLlib

Data:
Lots of small files (data coming from sensors or stuctured/semi-structured data)

Ingestion:
Fast data Event driven Near real-time

Storage:
Update single records

Considerations
Similar scenarios: Flume, HBase & Spark
Online performances
HBase instead of HDFS
Similar data
High throughput

Moreover…
• Adoption of a well-established solution
• Availability of support services
• Community, open source or … free version!
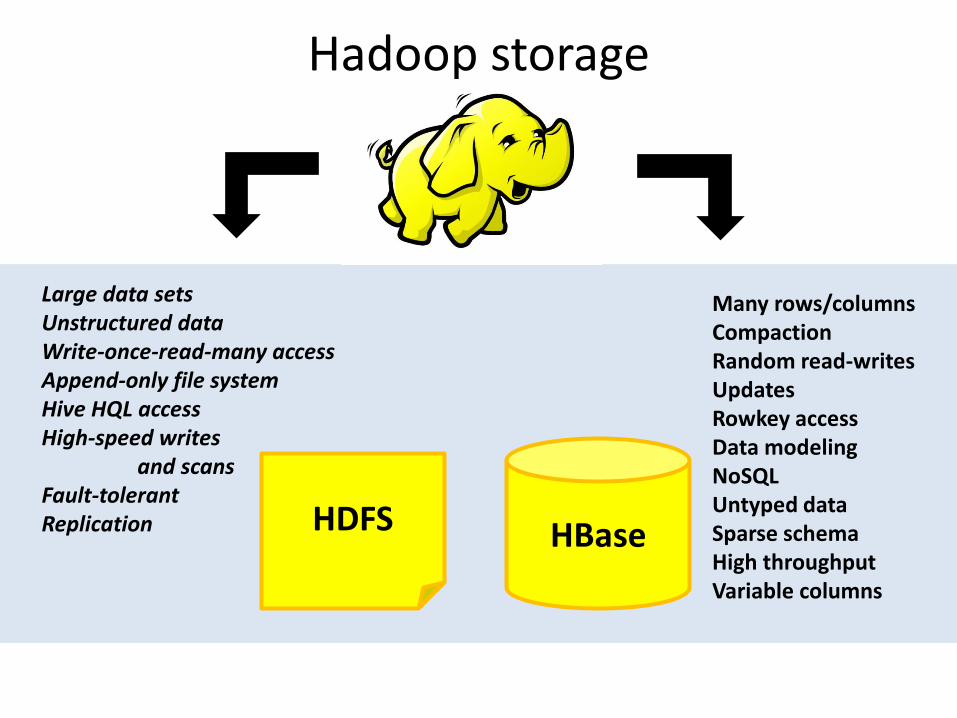
Hadoop storage
HBase HDFS
Large data sets Unstructured data Write-once-read-many access Append-only file system Hive HQL access High-speed writes and scans Fault-tolerant Replication
Many rows/columns Compaction Random read-writes Updates Rowkey access Data modeling NoSQL Untyped data Sparse schema High throughput Variable columns

The solution:
HBase
Random read-writes Updates
Compaction Granular data
STORAGE

Problem:

Some Hbase features:
• Just one index or primary key
• Rowkey composed by other fields
• Big denormalized tables
• Horizontal partitioning rowkey-based
• Focus on the rowkey design and table schema (data modeling)
• The ACCESS PATTERN must be known in advance!

Warning!!!
Using HBase as RDBMS doesn’t work at all!!!

What’s missed?
• SQL language
• Analytic queries
• Secondary index
Performances
for online applications

Solutions:

• Phoenix is fast: Full table scan of 100M rows usually executed in 20 seconds (narrow table on a medium sized cluster). This time comes down to few milliseconds if query contains filter on key columns.
• Phoenix follows the philosophy of bringing the computation to the data by using: • coprocessors to perform operations on the server-side thus minimizing client/server
data transfer • custom filters to prune data as close to the source as possible. In addition, Phoenix
uses native Hbase to minimize any startup costs. Query chunks: Phoenix chunks up your query using the region boundaries and runs them in parallel on the client using a configurable number of threads. The aggregation will be done in a coprocessor on the server-side

• OLTP
• Analytic queries
• Hbase specific
• A lightweight solution
• Who else is going to use it?

• Query engine + metadata store + JDBC driver
• Database over HDFS (for bulk loads and full-table scans queries)
• HBase APIs (not accessing Hfiles directly)
• …what about performances?…
Query: select count(1) from table over 1M and 5M
rows. Data is 3 narrow columns. Number of Region
Server: 1 (Virtual Machine, HBase heap: 2GB,
Processor: 2 cores @ 3.3GHz Xeon)
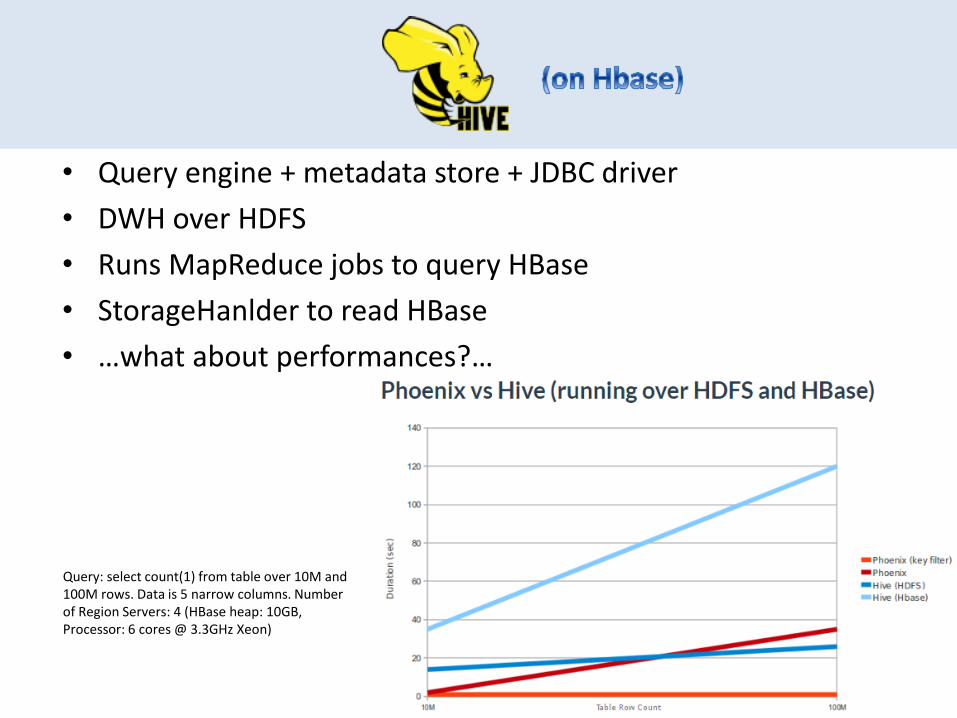
• Query engine + metadata store + JDBC driver
• DWH over HDFS
• Runs MapReduce jobs to query HBase
• StorageHanlder to read HBase
• …what about performances?…
Query: select count(1) from table over 10M and 100M rows. Data is 5 narrow columns. Number of Region Servers: 4 (HBase heap: 10GB, Processor: 6 cores @ 3.3GHz Xeon)

• Cassandra + Spark as lightweight solution (replacing Hbase+ Spark)
• SQL-like language (CQL) + secondary indexes
• …what about the other Hadoop tools?...

• Converged data platform: batch+NoSQL+streaming
• MapR-FS: great for throughput and files of every size + singolar updates
• Apache Drill as SQL-layer on Mapr-FS
• …proprietary solution…

• Developed by Cloudera is Open Source (->integrated with Hadoop Ecosystem)
• Low-latency random access
• Super-fast Columnar Storage
• Designed for Next-Generation Hardware (storage based on IO of solid state drives + experimental cache implementation)
• …beta version…
With Kudu, Cloudera promises to solve Hadoop's infamous storage problem InfoWorld | Sep 28, 2015

HBase HDFS
Hadoop storage
highly scalable in-memory database per MPP workloads
Fast writes, fast updates, fast reads, fast everything
Structured data SQL+scan use cases
Unstructured data Deep storage
Fixed column schema SQL+scan use cases
Any type column schema
Gets/puts/micro scans

Conclusions • One size doesn’t fit all the different
requirements
• The choice between different Open Source solutions is driven by the context
• Technology evolves
• So what? • REQUIREMENTS
• NO LOCK-IN
• PEER-REVIEWS

Thank you!
Monica Franceschini Twitter @twittmonique Linkedin mfranceschini
Skype monica_franceschini Email [email protected]





























