Embed Size (px)
Citation preview

Its Place Within a Big Data Stack
Junjun Olympia

Image from http://mattturck.com/2016/02/01/big-data-landscape/

A Quick Review of What Spark Is

Spark is a fast, large-scale data processing engine● Runs both in-memory and on-disk● 10x-100x faster than Hadoop MapReduce● Can be written in Java, Scala, Python, R, & SQL● Supports both batch and streaming workflows● Has several modules
○ Spark Core○ Spark Streaming○ Spark MLLib○ GraphX
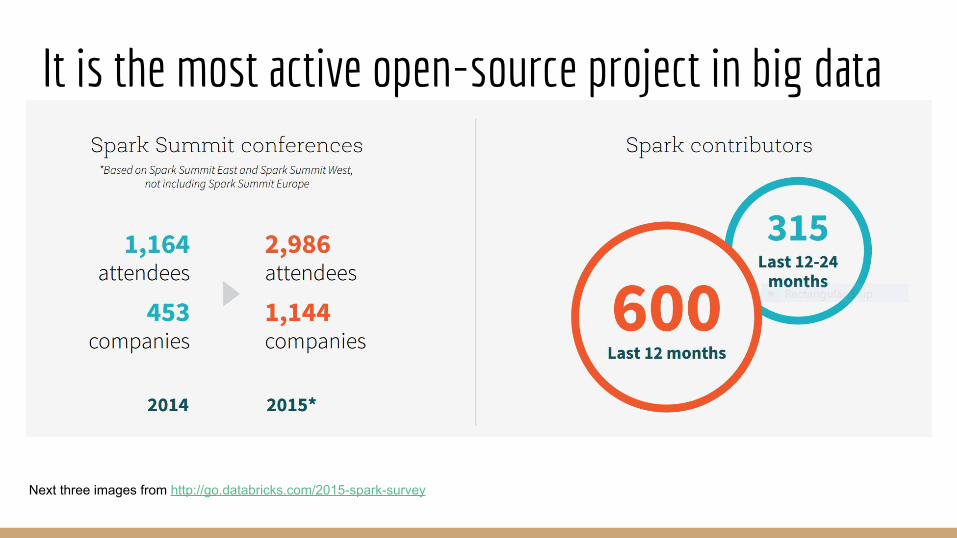
It is the most active open-source project in big data
Next three images from http://go.databricks.com/2015-spark-survey
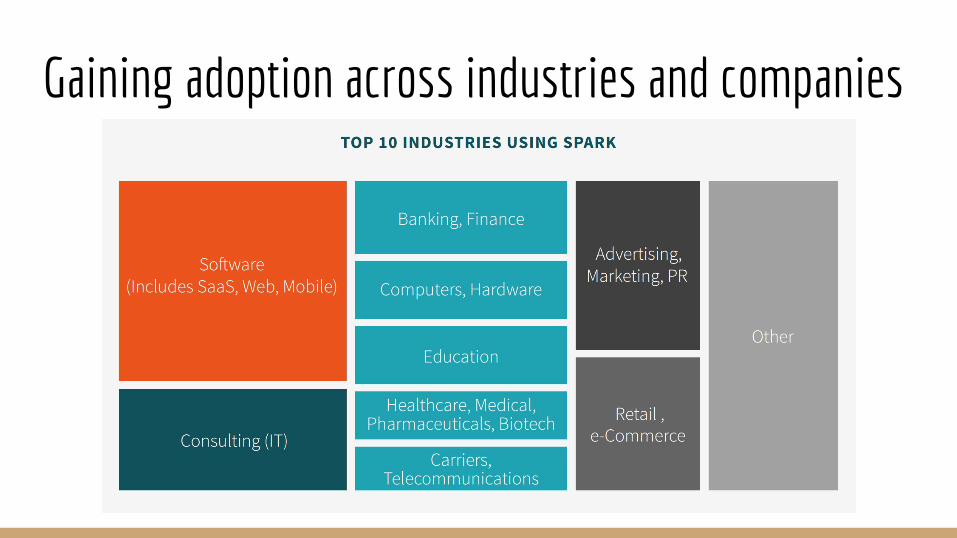
Gaining adoption across industries and companies
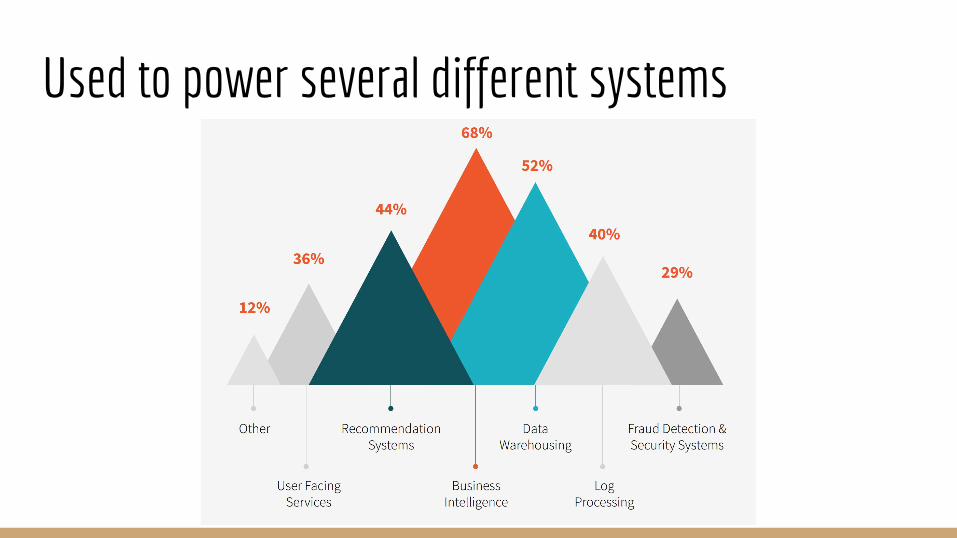
Used to power several different systems

(Big) Data systems perform common functions

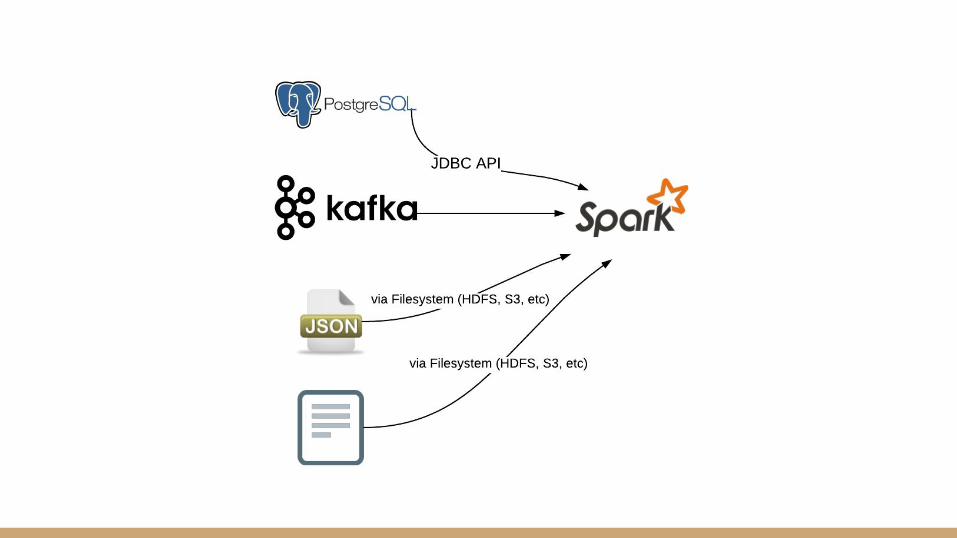
Capture and extract data

Data can come from several sources● Existing databases and data warehouses● Flat files from legacy systems● Web, mobile, and application logs● Data feeds from social media● IoT devices

Extract from database: Sqoop vs Spark JDBC API$ sqoop import --connect jdbc:postgresql:dbserver --table schema.tablename \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--optionally-enclosed-by '\"
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url" -> "jdbc:postgresql:dbserver",
"dbtable" -> "schema.tablename")).load()
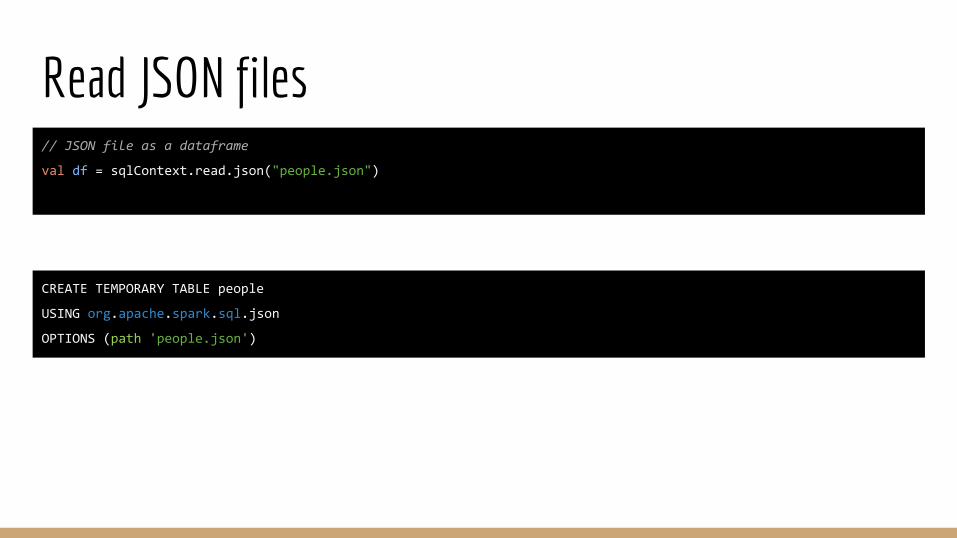
Read JSON files// JSON file as a dataframe
val df = sqlContext.read.json("people.json")
CREATE TEMPORARY TABLE people
USING org.apache.spark.sql.json
OPTIONS (path 'people.json')

Ingest streaming data from Kafkaimport org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])
var offsetRanges = Array[OffsetRange]()
directKafkaStream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.map {...}.foreachRDD { rdd => ... }

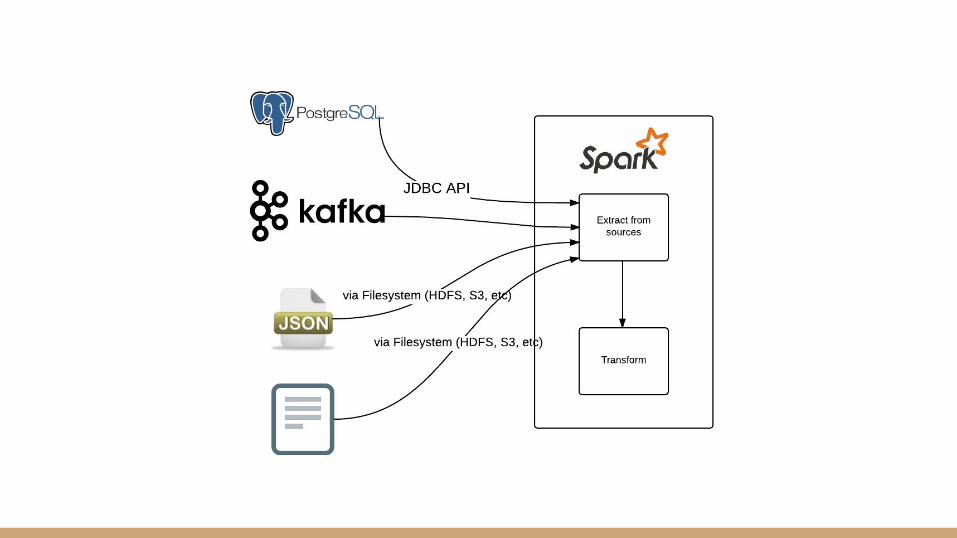
Transform Data

Data in an analytic pipeline usually need transformation● Check and/or correct for data quality issues● Handle missing values● Cast values into specific data types or formats● Compute derived fields● Split or merge records to achieve desired granularity● Join with another dataset (i.e. reference lookups)● Restructure as required by downstream applications or target databases

There’s plenty of tools that do this● Before big data
○ Informatica PowerCenter○ Pentaho Kettle○ Talend○ SSIS○ OWB
● Early Hadoop○ Apache Pig○ Hive via HQL○ Plain ol’ MapReduce
● Spark core, Streaming, DataFrames

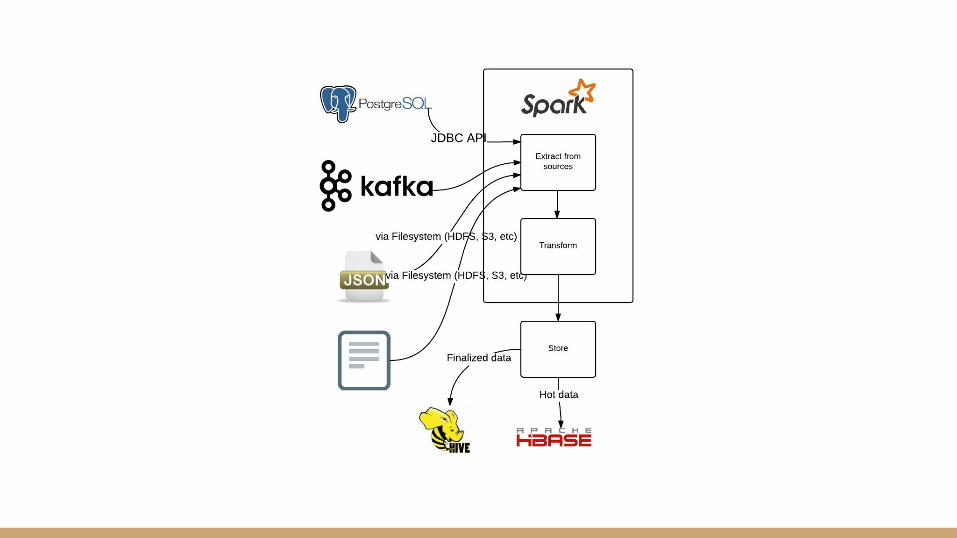
Store data

Data can then be stored several different ways● As self-describing files like Parquet, Avro, JSON, XML● Hive metastore-managed tables● Other low-latency SQL-on-Hadoop engines (i.e. Impala, Drill, Kudu)● Key-value and wide-table databases for fast random access (i.e. HBase,
Cassandra)● Search databases (i.e. ElasticSearch, Solr)● Conventional data warehouses and databases

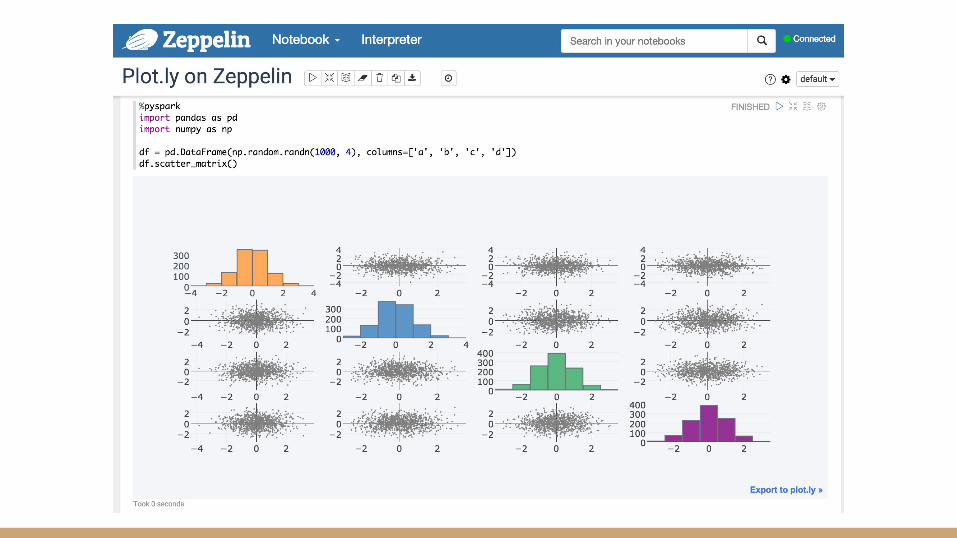
Query, analyze, visualize

There’s plenty of tools here, too● Databases offering JDBC/ODBC connectivity
○ Hive, Impala, Drill○ MPP data warehouses○ Spark SQL via JDBC Thrift Server
● BI Tools via SQL○ Qlikview○ Tableau○ Pentaho BI
● For richer analyses beyond Spark SQL○ Spark shell○ Better with notebooks (i.e. Zeppelin, Jupyter)
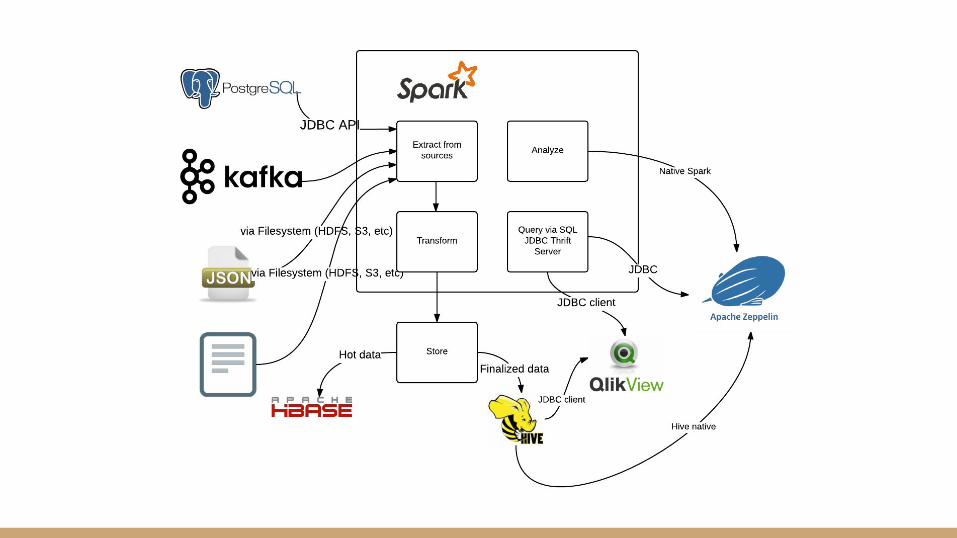

Spark is an essential part of the modern big data stack.

A unified framework such as Spark offers benefits, too● Fewer moving pieces● Smaller stack to administer and manage● Common languages● Familiar patterns● Encourages team members to become cross-functional

Some common questions about Spark

Is Spark a database?

Fine; is it a data warehouse then?

Is Spark a Hadoop replacement?

Are there other technologies similar to Spark?

Questions?





























