Embed Size (px)
Citation preview

10 things I wish I knew……about Machine Learning Competitions

Introduction• Theoretical competition run-down• The list of things I wish I knew• Code samples for a running competition
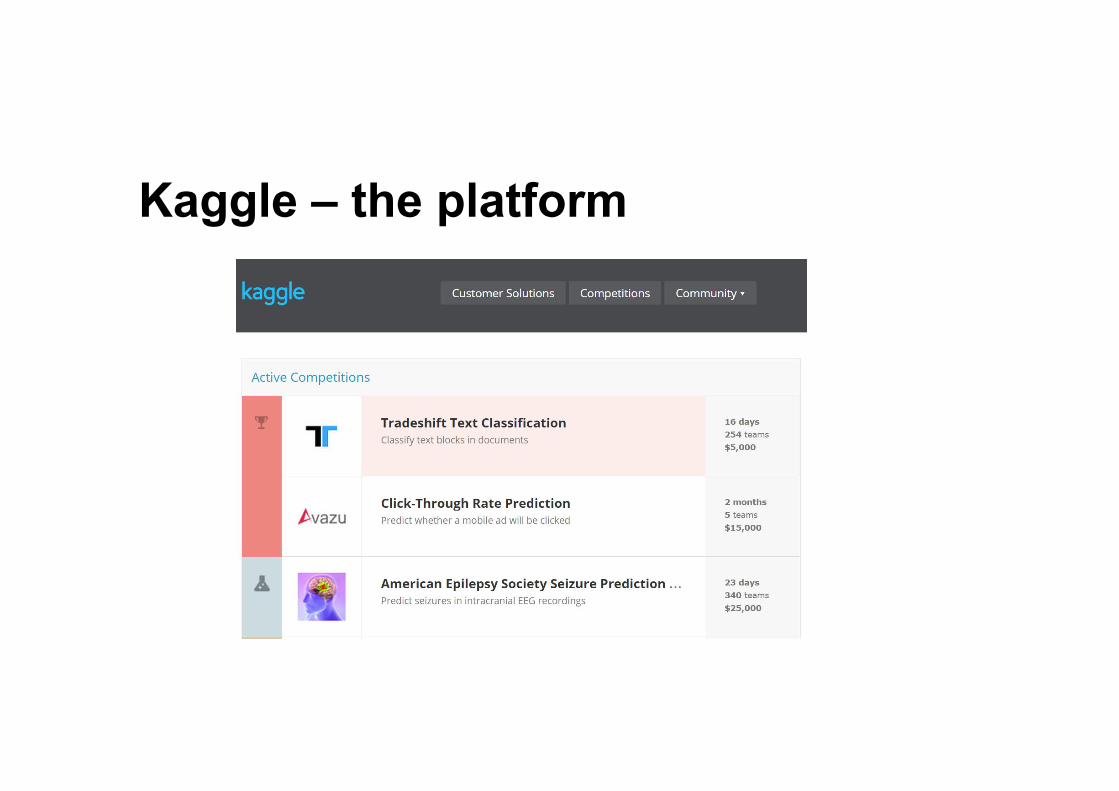
Kaggle – the platform

Reasons to compete• Money• Fame• Learning experience• Tough challenge• Fun

Competition run-down• Head over to kaggle.com• Read the competition description• Download the train/test set

Preparations• Plot the data• Look at the distributions• Start simple (all-zeroes benchmark)• Make sure to optimize the correct metric• Read up on the specific propertiesà e.g. Logarithmic Loss, extremepredictionshttps://www.kaggle.com/wiki/Metrics

Preprocessing• Replace missing values• Remove duplicates from the training set• One-Hot encode categorical features• Decide what to do with outliers• Scaling/Standardizing

Building the model• Start with a baseline or simple modelà Random predictionsà LogisticRegressionà Decision treesà KNearestNeighbours
• Establish a cross-validation scheme

Submit• Leaderboard score vs. local score
• Mismatch?à Check your scoring functionà Check the sample size of the public LBà Ignore the LB

Kaggle isn’t real world ML• Trade-off:
Accuracy vs. Interpretability vs. Speed• Interpretability/speed is often more important
than accuracy• "Arrow splitting“• "Netflix Problem"http://fastml.com/kaggle-vs-industry-as-seen-through-lens-of-the-avito-competition/http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.htmlhttp://machinelearningmastery.com/building-a-production-machine-learning-infrastructure/

1) Timing• Don’t start too early
«Beat the benchmark», sharing, motivation
• Don’t start too lateYou’ll certainly run out of time
• ~ 30 Days before the deadline

2) Learn a tool, stick with it• Python• R• Matlab/Octave
“The grass is always greener on the other side”

3) Make sure your result are reproducible
• Fix the seeds for algorithms that involverandomization
• Automate your pipeline• Preferably one script from input to output

4) Make sure your result are reproducible
Examples:• Weight initialization (Neural Networks)• Data subsampling (e.g. Random Forest)
# scikit-learntrain_test_split(X, y, random_state=42)
# numpynp.random.seed(42)

5) Don’t trust the Leaderboard• Danger of overfitting when tuning your
models according to feedback of the publicleaderboard
• Use cross-validation to estimate theperformance of your model
• Don’t, if computationally to expensiveà Train/Test split might cut it too

6) Avoid LeakageCommon Sources• PCA• TfIdf• Imputation (Mean/Median)• Duplicate rows in the training set• Inappropriate Cross-validation Scheme
Row, Person, Time, Location
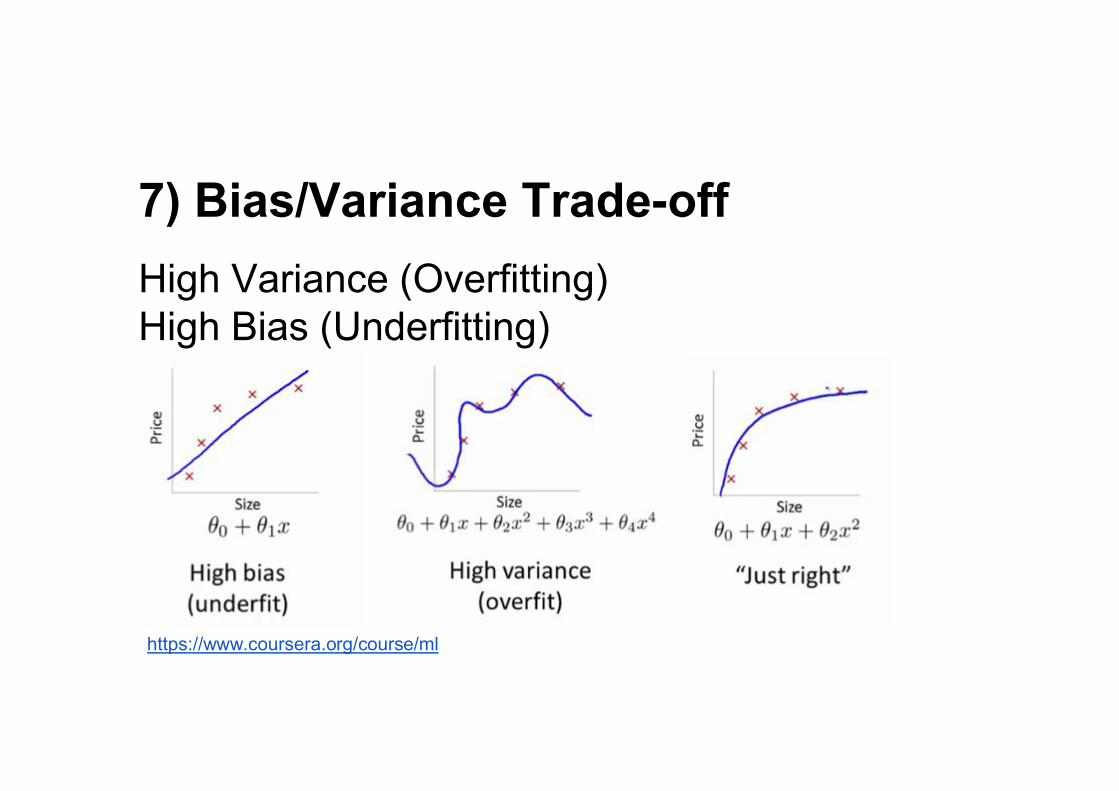
7) Bias/Variance Trade-offHigh Variance (Overfitting)High Bias (Underfitting)
https://www.coursera.org/course/ml

8) Think outside the box
• «Don’t get stuck in local minima»• Stop doing what you’re doing if you’re not
making significant progress• Read-up relevant papers on the problem• Explore a different model• Try more feature engineering

9) Spend your time wisely• Feature Engineering vs. Hyper-parameter
tuning• Read up on Error Analysis• Read up on Learning Curves

9) Improving a learning algorithm• Get more training examples (V)• Try smaller sets of features (V)• Try getting additional features (B)• Try adding polynomial features (B)• Increase regularization (V)• Decrease regularization (B)

10) Make use of ensembling• Six bad models are usually better than one
really good model [1, 2]à KNN, SVM, NeuralNet, RF,LogisticRegression, Ridgeà Neural Nets (structurally, seed)
• Make yourself familiar with:Bagging, Boosting, Blending, Stacking[1] http://www.tandfonline.com/doi/abs/10.1080/095400996116839#.VEebN_nkcyN[2] http://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml04.icdm06long.pdf

An example would be handy…
…right about now.
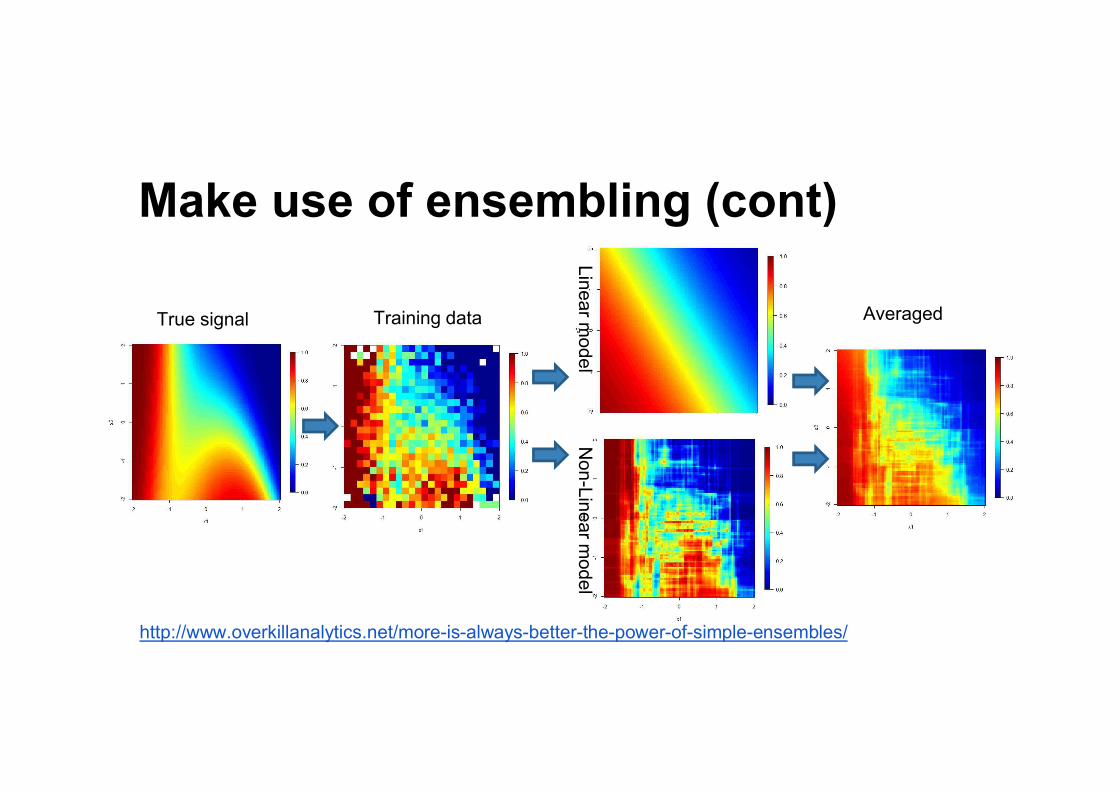
Make use of ensembling (cont)
http://www.overkillanalytics.net/more-is-always-better-the-power-of-simple-ensembles/
True signal
Linearmodel
Non-Linearm
odel
Training data Averaged

Working with features
• Feature selection• Feature engineeringà categoricalà numericalà textual

Examples of feature selection/engineering
• Remove correlated features• Remove features using statistical tests
• Try pair-wise feature interactionsa*b, a-b, a+b, a/b
• Try feature transformationssqrt(a), log(a), abs(a)

Feature engineering (categorical)
• CabinID into deck and room number‘A25’à (‘A’, 25)‘B16’à (‘B’, 16)
• Recode number of siblings to binary (family)• Decompose Dates
Year, month, dayDay of the weekDay of the month

Feature engineering (Textual)
• Lowercase• Stemming (‘rainy’à ‘rain’)• Spelling correction
«I wsa hungray»à «I was hungry»«It’s hotttt outside»à «It’s hot outside»
• Remove stopwords• N-Grams• TfIdf, Count, Hashing

What usually doesn’t work (for me)• Dimensionality reduction (information loss)• Feature elimination (information loss)• Tree-based methods on High-
dimensional/Sparse data (by design)

There is always a twist• Feature engineeringà a.k.a. “Golden Features”
• How exciting is this project?à linear decay towards the end
• Removing useless/noisy features

Dataset Trends• Datasets become larger (millions of
samples, thousands of features)• Datasets are anonymizedà Black-Box Machine Learning

Interesting stuff to keep an eye on• Caffe, cuDNN• Vowpal Wabbit (Wee-Dub)• h2o from 0xdata• Regularized Greedy Forests• Factorization models


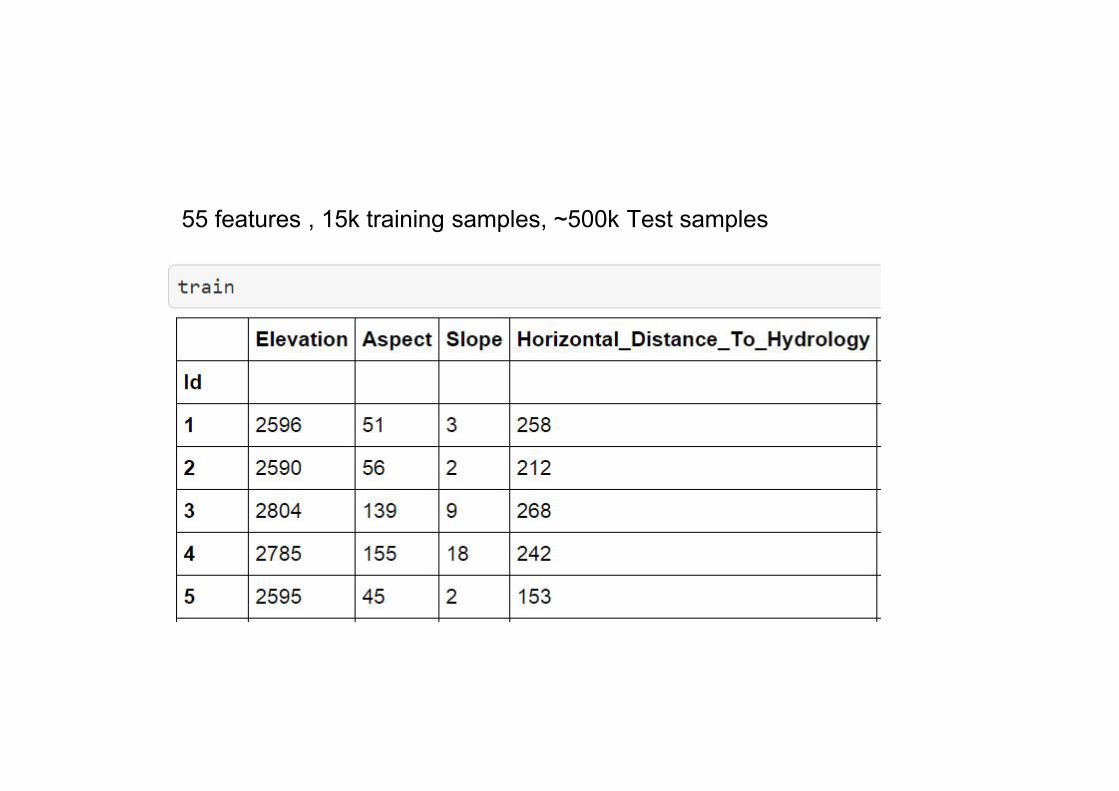
55 features , 15k training samples, ~500k Test samples

Random predictions

Start simple: Decision tree

A little more complex

Let’s see what the model thinks

Next: SVM!
What?!

Feature scaling!

Enough playing, let’s get real.
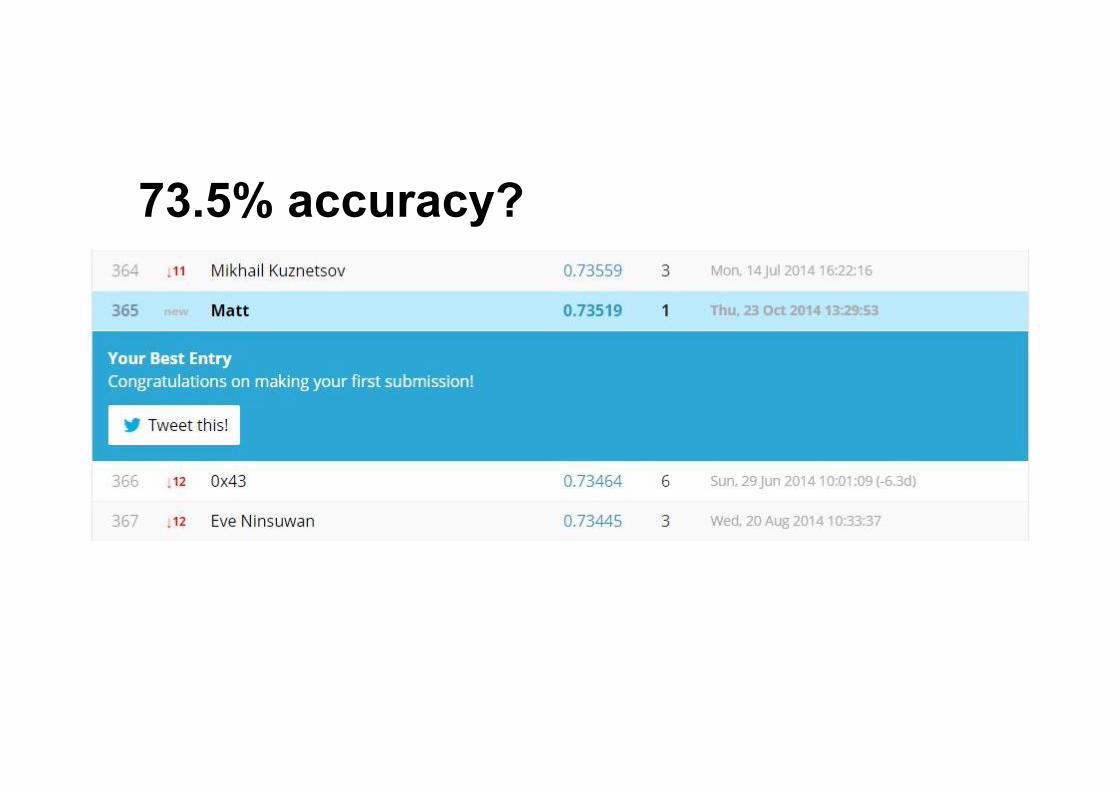
73.5% accuracy?

Class distribution

Scale it up!
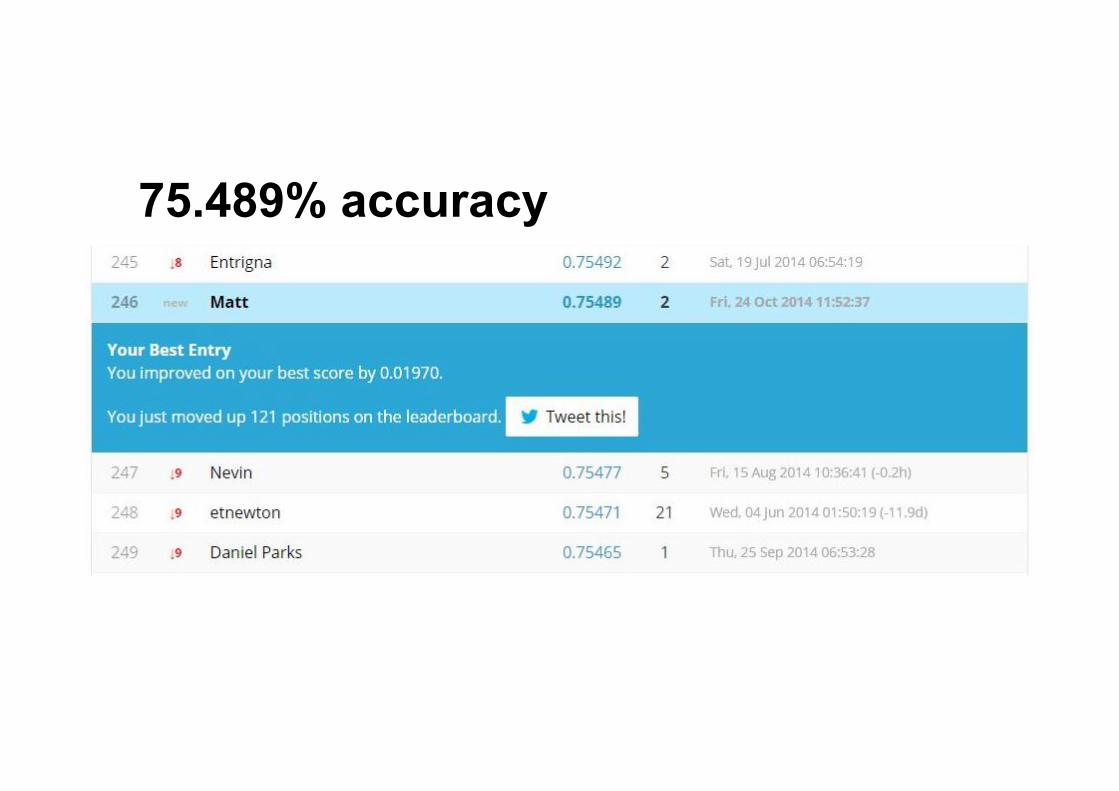
75.489% accuracy

Even more?
Nope, no more progress! Time to switch tactics.

Feature Engineering
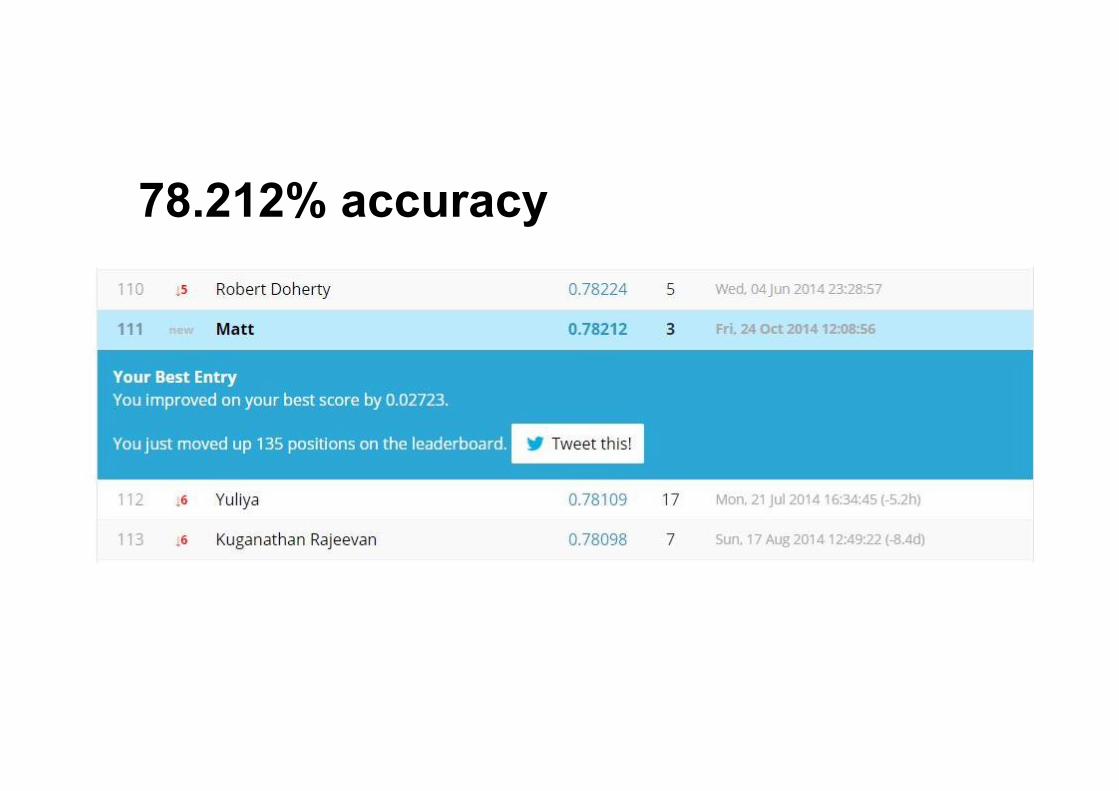
78.212% accuracy
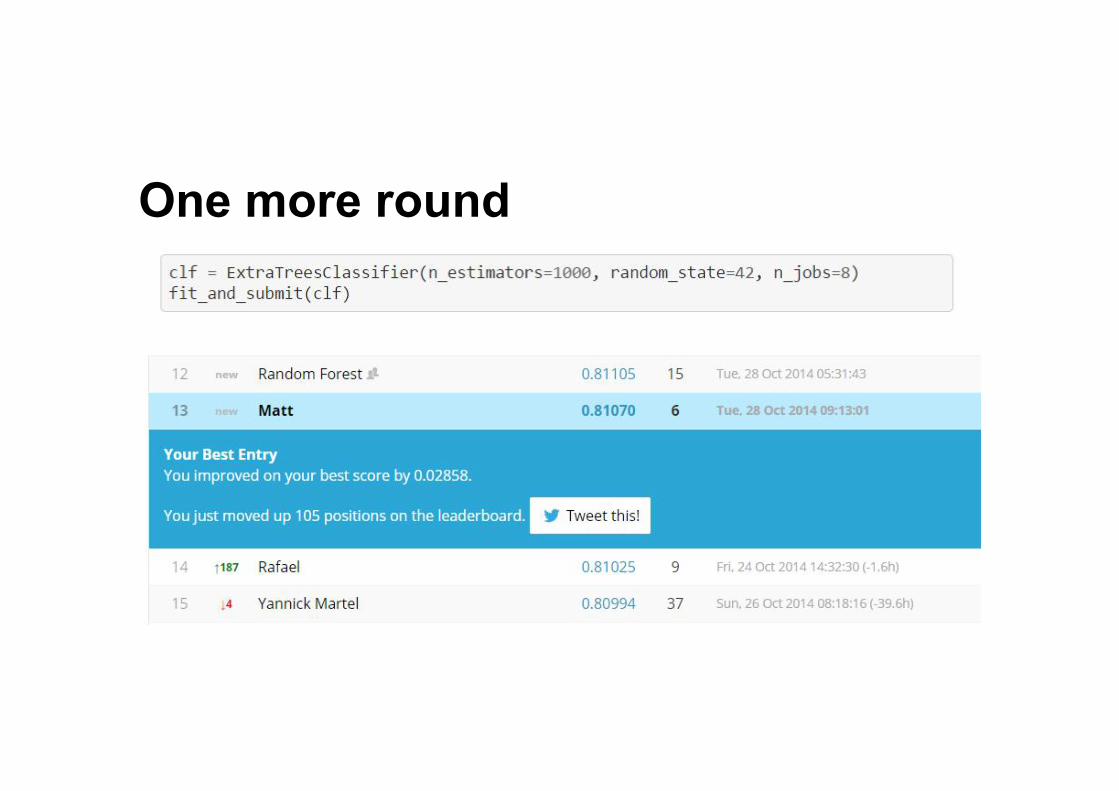
One more round

Mail [email protected]: @mattvonrohrLinkedIn: ch.linkedin.com/in/mattvonrohr/Kaggle: kaggle.com/users/8376/matt





























